

En esta guía aprenderás:
- Qué es LlamaIndex.
- Por qué los agentes de IA creados con LlamaIndex deberían poder realizar búsquedas en la web.
- Cómo crear un agente de IA LlamaIndex con capacidades de búsqueda web.
Sumerjámonos.
¿Qué es LlamaIndex?
LlamaIndex es un framework Python de código abierto para construir aplicaciones alimentadas por LLMs. Sirve de puente entre los datos no estructurados y los LLM. En particular, facilita la orquestación de flujos de trabajo LLM a través de una variedad de fuentes de datos.
Con LlamaIndex, puede crear flujos de trabajo y agentes de IA listos para la producción. Estos pueden buscar y recuperar información relevante, sintetizar conocimientos, generar informes detallados, realizar acciones automatizadas y mucho más.
En el momento de escribir este artículo, es una de las bibliotecas de más rápido crecimiento en el ecosistema de la IA, con más de 42.000 estrellas en GitHub.
Por qué integrar los datos de búsqueda web en su agente de IA LlamaIndex
En comparación con otros marcos de agentes de IA, LlamaIndex se ha creado para resolver una de las mayores limitaciones de los LLM. Se trata de su falta de conocimientos actualizados del mundo real.
Para solucionar este problema, LlamaIndex proporciona integraciones con varios conectores de datos que le permiten ingerir contenido de múltiples fuentes. Ahora bien, cabe preguntarse: ¿cuál es la fuente de datos más valiosa para un agente de IA?
Para responder a esta pregunta, es útil considerar qué fuentes de datos se utilizan para entrenar a los LLM. Los LLM exitosos recibieron la mayoría de sus datos de entrenamiento de la web, la mayor y más diversa fuente de datos públicos.
Si quiere que su agente de IA LlamaIndex supere sus datos estáticos de entrenamiento, la capacidad clave que necesita es la capacidad de buscar en la web y aprender de lo que encuentra. Así, su agente debe ser capaz de extraer información estructurada de las páginas de búsqueda resultantes (denominadas “SERPs“). A continuación, las procesa y aprende de ellas.
El reto es que el raspado de SERP se ha vuelto mucho más difícil debido a las recientes medidas enérgicas de Google contra los scripts de raspado simples. Esta es la razón por la que necesita una herramienta que se integre con LlamaIndex y simplifique este proceso. Aquí es donde entra en juego la integración de Bright Data de LlamaIndex.
Bright Data se encarga del complejo trabajo de SERP scraping. A través de su herramienta search_engine, permite a su agente LlamaIndex realizar consultas de búsqueda y recibir resultados estructurados en formato Markdown o JSON.
Esto es lo que tu agente de IA necesita para estar preparado para responder preguntas, tanto ahora como en el futuro. Descubre cómo funciona esta integración en el próximo capítulo.
Construir un agente LlamaIndex que pueda buscar en la Web utilizando herramientas de Bright Data
En esta guía paso a paso, verás cómo construir un agente Python AI con LlamaIndex que puede buscar en la web.
Al integrarse con Bright Data, permitirá a su agente acceder a datos de búsqueda web frescos, contextuales y enriquecidos. Para más detalles, consulte nuestra documentación oficial.
Siga los pasos que se indican a continuación para crear su agente SERP AI impulsado por Bright Data utilizando LlamaIndex.
Requisitos previos
Para seguir este tutorial, necesitas lo siguiente:
- Python 3.9 o superior instalado en su máquina (recomendamos utilizar la última versión).
- Una clave API de Bright Data para integrarse con las API de SERP de Bright Data.
- Una clave API de un LLM compatible. (En esta guía, utilizaremos Gemini, que admite la integración mediante API de forma gratuita. Al mismo tiempo, puede utilizar cualquier proveedor LLM soportado por LlamaIndex).
No se preocupe si aún no dispone de una clave API de Gemini o Bright Data. Le mostraremos cómo crear ambas en los próximos pasos.
Paso 1: Inicializar el proyecto Python
Empieza por iniciar tu terminal y crear una nueva carpeta para tu proyecto de agente de IA LlamaIndex:
mkdir llamaindex-bright-data-serp-agentllamaindex-bright-data-serp-agent/ contendrá todo el código para su agente de IA con capacidades de búsqueda web impulsadas por Bright Data.
A continuación, navega hasta el directorio del proyecto y crea un entorno virtual Python dentro de él:
cd llamaindex-bright-data-serp-agent
python -m venv venvAhora, abre la carpeta del proyecto en tu IDE de Python favorito. Recomendamos Visual Studio Code con la extensión Python o PyCharm Community Edition.
Crea un nuevo archivo llamado agent.py en la raíz del directorio de tu proyecto. La estructura de tu proyecto debería ser la siguiente:
llamaindex-bright-data-serp-agent/
├── venv/
└── agent.pyEn el terminal, active el entorno virtual. En Linux o macOS, ejecute:
source venv/bin/activateDe forma equivalente, en Windows, ejecute:
venv/Scripts/activateEn los siguientes pasos, se le guiará a través de la instalación de los paquetes necesarios. Sin embargo, si desea instalar todo por adelantado, ejecute:
pip install python-dotenv llama-index-tools-brightdata llama-index-llms-google-genai llama-indexNota: Instalamos llama-index-llms-google-genai porque este tutorial utiliza Gemini como proveedor LLM de LlamaIndex. Si piensas utilizar un proveedor diferente, asegúrate de instalar la integración LLM correspondiente.
¡Buen trabajo! Su entorno de desarrollo Python está listo para construir un agente de IA con la integración SERP de Bright Data utilizando LlamaIndex.
Paso nº 2: Integrar la lectura de variables de entorno
Su agente LlamaIndex se conectará a servicios externos como Gemini y Bright Data a través de la API. Por motivos de seguridad, nunca debes codificar las claves API directamente en tu código Python. En su lugar, utiliza variables de entorno para mantenerlas privadas.
Instale la biblioteca python-dotenv para facilitar la gestión de las variables de entorno. En su entorno virtual activado, ejecute:
pip install python-dotenvA continuación, abra su archivo agent.py y añada las siguientes líneas en la parte superior para cargar envs desde un archivo .env:
from dotenv import load_dotenv
load_dotenv()load_dotenv() busca un archivo .env en el directorio raíz de su proyecto y carga sus valores en el entorno.
Ahora, crea un archivo .env junto a tu archivo agent.py. La estructura de archivos de tu nuevo proyecto debería ser la siguiente:
llamaindex-bright-data-serp-agent/
├── venv/
├── .env # <-------------
└── agent.py¡Impresionante! Acabas de configurar una forma segura de gestionar credenciales API sensibles para servicios de terceros.
Continúe la configuración inicial rellenando su archivo .env con las variables de entorno necesarias.
Paso nº 3: Configurar Bright Data
Para conectarse a las API de SERP de Bright Data en LlamaIndex a través del paquete de integración oficial, primero debe:
- Active la solución Web Unlocker en su panel de Bright Data.
- Recupere su token de API de Bright Data.
Siga los pasos que se indican a continuación para completar la configuración.
Si aún no tiene una cuenta de Bright Data, [cree una](). Si ya tiene una cuenta, inicie sesión. En el panel de control, haga clic en el botón “Obtener productos proxy”:
Accederá a la página “Proxies & Scraping Infrastructure”:
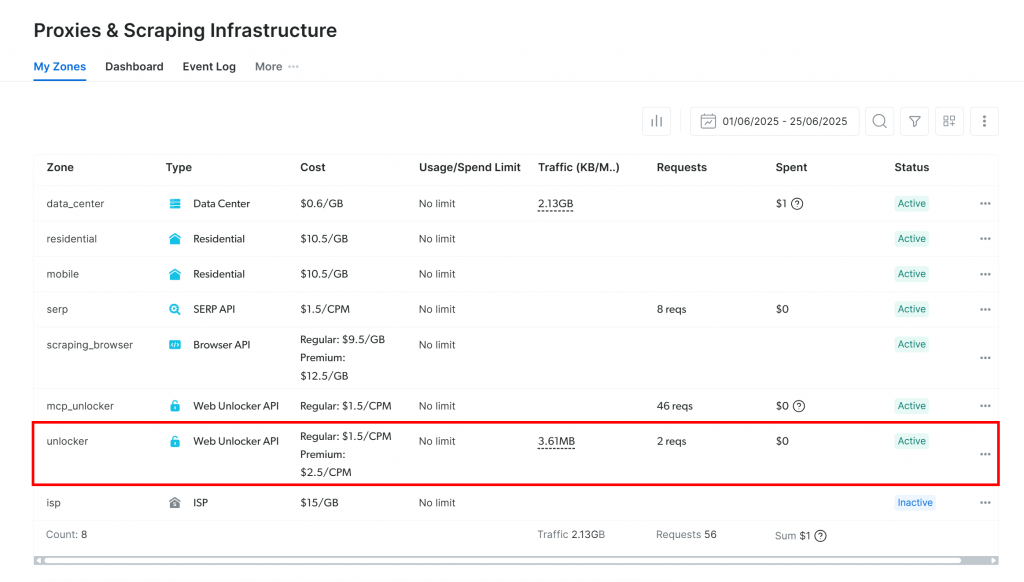
Si ya ve una zona API de Web Unlocker activa (como en la imagen de arriba), ya está todo listo. Anote el nombre de la zona (por ejemplo, unlocker), ya que lo utilizará en su código más adelante.
Si aún no dispone de una zona Web Unlocker, desplácese hasta la sección “API Web Unlocker” y pulse el botón “Crear zona”:
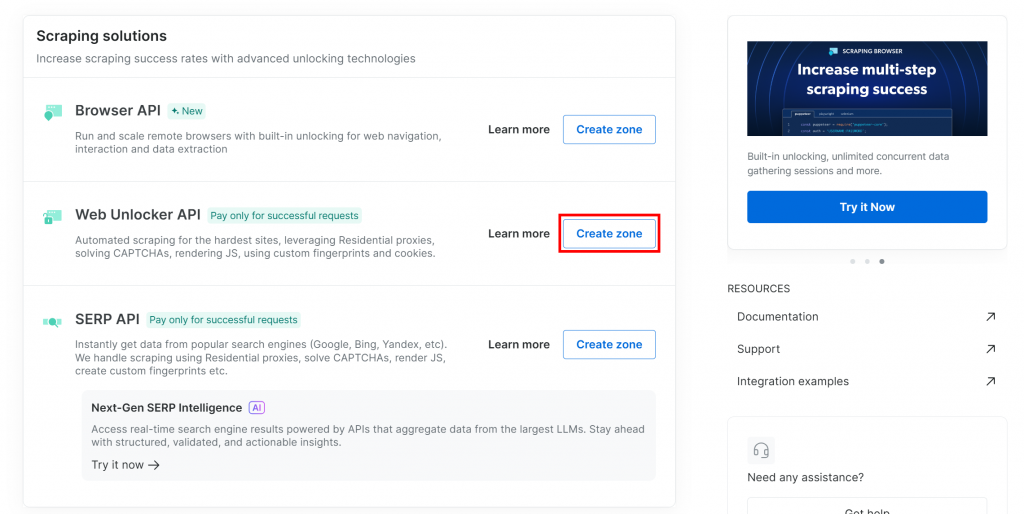
¿Por qué utilizar la API de Web Unlocker en lugar de la API SERP dedicada?
La integración LlamaIndex SERP de Bright Data funciona a través de la API Web Unlocker. En concreto, cuando se configura correctamente, Web Unlocker funciona del mismo modo que las API SERP dedicadas. En resumen, al configurar una zona API de Web Unlocker con la integración de Bright Data de LlamaIndex, automáticamente también obtiene acceso a las API de SERP.
Dale un nombre a tu nueva zona, por ejemplo desbloqueador, habilita cualquier función avanzada para un mejor rendimiento y haz clic en “Añadir”:
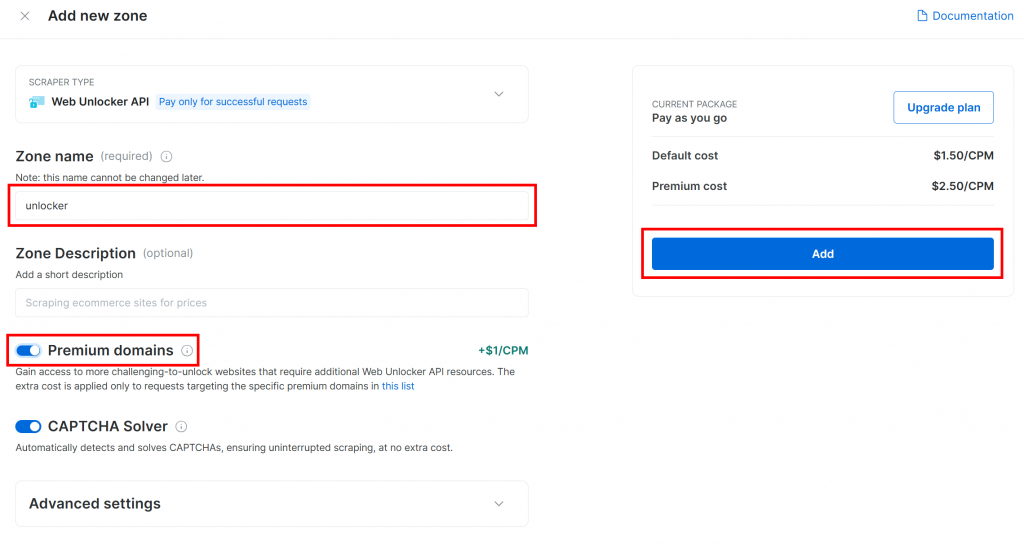
Una vez creada, se le redirigirá a la página de configuración de la zona:
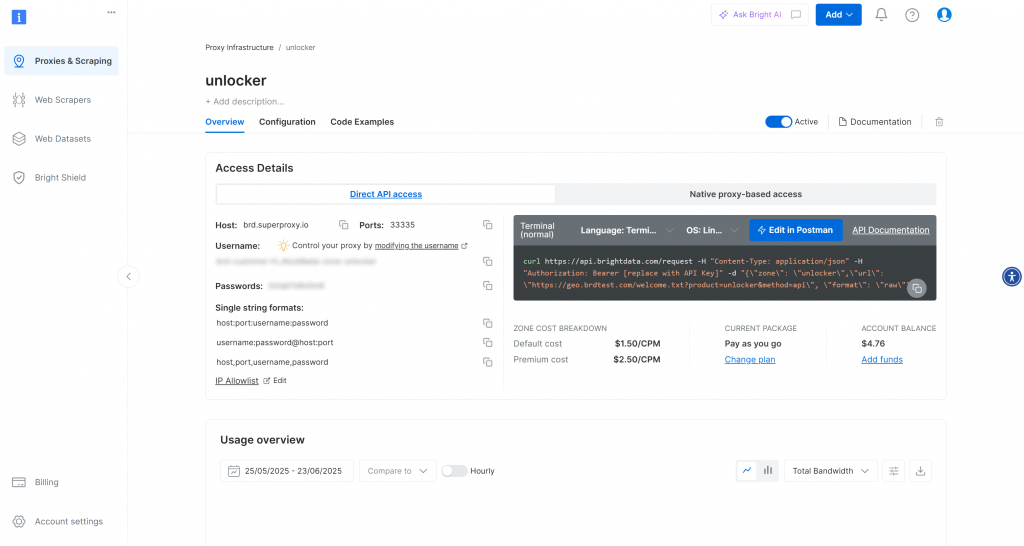
Asegúrese de que el conmutador de activación está en estado “Activo”. Esto confirma que su zona está lista para su uso.
A continuación, siga la guía oficial de Bright Data para generar su clave API. Una vez que tenga su clave, guárdela de forma segura en su archivo .env de la siguiente manera:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Sustituya el con el valor real de su clave API.
Impresionante Configure la herramienta SERP de Bright Data en su script de agente de LlamaIndex.
Paso nº 4: Acceder a la herramienta SERP LlamaIndex de Bright Data
En agent.py, comience cargando su clave API de Bright Data desde el entorno:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Asegúrese de importar os de la biblioteca estándar de Python:
import osEn su entorno virtual activado, instale el paquete de herramientas LlamaIndex Bright Data:
pip install llama-index-tools-brightdataA continuación, importe la clase BrightDataToolSpec en su archivo agent.py:
from llama_index.tools.brightdata import BrightDataToolSpecCree una instancia de BrightDataToolSpec, proporcionando su clave API y el nombre de la zona Web Unlocker:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker", # Replace with the name of your Web Unlocker zone
verbose=True,
)Sustituya el valor de la zona por el nombre de la zona API de Web Unlocker que configuró anteriormente (en este caso, es unlocker).
Tenga en cuenta que establecer verbose=True es útil durante el desarrollo. De esta forma, la biblioteca imprimirá registros útiles cuando su agente LlamaIndex realice solicitudes a través de Bright Data.
BrightDataToolSpec proporciona varias herramientas, pero aquí nos centraremos en la herramienta search_engine. Esta puede consultar Google, Bing, Yandex, y más, devolviendo los resultados en Markdown o JSON.
Para extraer sólo esa herramienta, escribe:
brightdata_serp_tools = brightdata_tool_spec.to_tool_list(["search_engine"])El array pasado a to_tool_list() actúa como un filtro, incluyendo sólo la herramienta llamada search_engine.
Nota: Por defecto, LlamaIndex elegirá la herramienta más apropiada para una solicitud de usuario determinada. Por lo tanto, el filtrado de herramientas no es estrictamente necesario. Dado que este tutorial trata específicamente sobre la integración de las capacidades SERP de Bright Data, tiene sentido limitarlo a la herramienta search_engine para mayor claridad.
¡Estupendo! Bright Data ya está integrado y listo para potenciar su agente LlamaIndex con capacidades de búsqueda web.
Paso nº 5: Conectar un modelo LLM
Las instrucciones de este paso utilizan Gemini como proveedor de LLM para esta integración. Una buena razón para elegir Gemini es que ofrece acceso API gratuito a algunos de sus modelos.
Para empezar a utilizar Gemini en LlamaIndex, instale el paquete de integración necesario:
pip install llama-index-llms-google-genaiA continuación, importa la clase GoogleGenAI en agent.py:
from llama_index.llms.google_genai import GoogleGenAIAhora, inicializa el LLM Gemini así:
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)En este ejemplo, estamos utilizando el modelo gemini-2.5-flash. Siéntase libre de elegir cualquier otro modelo Gemini compatible.
Entre bastidores, la clase GoogleGenAI busca automáticamente una variable de entorno denominada GEMINI_API_KEY. Utiliza la clave de API leída de ese entorno para conectarse a las API de Gemini.
Configúrelo abriendo su archivo .env y añadiendo:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Sustituya el con su clave Gemini API real. Si aún no tiene una, puede obtenerla gratuitamente siguiendo la guía oficial de recuperación de la API de Gemini.
Nota: Si desea utilizar un proveedor LLM diferente, LlamaIndex admite muchas opciones. Consulte la documentación oficial de LlamaIndex para obtener instrucciones de configuración.
Bien hecho. Ya tienes todas las piezas básicas para construir un agente de IA LlamaIndex que pueda buscar en la web.
Paso nº 6: Definir el agente LlamaIndex
En primer lugar, instale el paquete principal de LlamaIndex:
pip install llama-indexA continuación, en tu archivo agent.py, importa la clase FunctionAgent:
from llama_index.core.agent.workflow import FunctionAgentFunctionAgent es un agente especializado de LlamaIndex AI que puede interactuar con herramientas externas, como la herramienta SERP de Bright Data que configuró anteriormente.
Inicialice el agente con su LLM y la herramienta SERP de Bright Data de la siguiente manera:
agent = FunctionAgent(
tools=brightdata_serp_tools,
llm=llm,
verbose=True, # Useful while developing
system_prompt="""
You are a helpful assistant that can retrieve SERP results in JSON format.
"""
)Esto crea un agente de IA que procesa la entrada del usuario a través de su LLM y puede llamar a las herramientas SERP de Bright Data para realizar búsquedas web en tiempo real cuando sea necesario. Observe el argumento system_prompt, que define el papel y el comportamiento del agente. De nuevo, el indicador verbose=True es útil para inspeccionar la actividad interna.
¡Maravilloso! La integración de LlamaIndex + Bright Data SERP está completa. El siguiente paso es implementar el REPL para uso interactivo.
Paso 7: Construir el REPL
REPL, abreviatura de “Read-Eval-Print Loop” (bucle de lectura, evaluación e impresión), es un patrón de programación interactivo en el que se introducen comandos, se evalúan y se ven los resultados.
En este contexto, el REPL funciona del siguiente modo:
- Describa la tarea que desea que realice el agente de IA.
- El agente de IA realiza la tarea, efectuando búsquedas en línea si es necesario.
- Verás la respuesta impresa en el terminal.
Este bucle continúa indefinidamente hasta que tecleas "exit".
En agent.py, añade esta función asíncrona para manejar la lógica REPL:
async def main():
print("Gemini-based agent with web searching capabilities powered by Bright Data. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = await agent.run(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")Esta función REPL:
- Acepta la entrada del usuario desde la línea de comandos a través de
input(). - Procesa la entrada utilizando el agente LlamaIndex impulsado por Gemini y Bright Data a través de
agent.run(). - Muestra la respuesta en la consola.
Debido a que agent.run() es asíncrono, la lógica REPL debe estar dentro de una función asíncrona. Ejecútala así al final de tu archivo:
if __name__ == "__main__":
asyncio.run(main())No olvides importar asyncio:
import asyncioYa está aquí. El agente LlamaIndex AI con herramientas de SERP scraping está listo.
Paso 8: Ponerlo todo junto y ejecutar el agente de IA
Esto es lo que debe contener tu archivo agent.py:
from dotenv import load_dotenv
import os
from llama_index.tools.brightdata import BrightDataToolSpec
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.core.agent.workflow import FunctionAgent
import asyncio
# Load environment variables from the .env file
load_dotenv()
# Read the Bright Data API key from the envs
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Set up the Bright Data Tools
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker", # Replace with the name of your Web Unlocker zone
verbose=True, # Useful while developing
)
# Get only the "search_engine" (SERP scraping) tool
brightdata_serp_tools = brightdata_tool_spec.to_tool_list(["search_engine"])
# Configure the connection to Gemini
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)
# Create the LlamaIndex agent powered by Gemini and connected to Bright Data tools
agent = FunctionAgent(
tools=brightdata_serp_tools,
llm=llm,
verbose=True, # Useful while developing
system_prompt="""
You are a helpful assistant that can retrieve SERP results in JSON format.
"""
)
# Async REPL loop
async def main():
print("Gemini-based agent with web searching capabilities powered by Bright Data. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = await agent.run(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")
if __name__ == "__main__":
asyncio.run(main())Ejecute su agente LlamaIndex SERP con:
python agent.pyCuando se inicie el script, verá un mensaje como este en su terminal:

Intente pedir a su agente algo que requiera información reciente, por ejemplo:
Write a short Markdown report on the new AI protocols, including some real-world links for further reading.Para realizar esta tarea con eficacia, el agente de IA necesita buscar información actualizada en Internet.
El resultado será:
Eso fue bastante rápido, así que vamos a desglosar lo que pasó:
- El agente detecta la necesidad de buscar “nuevos protocolos de IA” y llama a la API SERP de Bright Data a través de la herramienta search_engine utilizando esta URL de entrada:
https://www.google.com/search?q=new%20AI%20protocols&num=10&brd_json=1. - La herramienta obtiene de forma asíncrona los datos de las SERP en formato JSON desde la API de búsqueda de Google de Bright Data.
- El agente pasa la respuesta JSON al Gemini LLM.
- Gemini procesa los datos frescos y genera un informe Markdown claro y preciso con los enlaces pertinentes.
En este caso, el agente de IA regresó:
## New AI Protocols: A Brief Report
The rapid advancement of Artificial Intelligence has led to the emergence of new protocols designed to enhance interoperability, communication, and data handling among AI systems and with external data sources. These protocols aim to standardize how AI agents interact, leading to more scalable and integrated AI deployments.
Here are some of the key new AI protocols:
### 1. Model Context Protocol (MCP)
The Model Context Protocol (MCP) is an open standard that facilitates secure, two-way connections between AI-powered tools and various data sources. It fundamentally changes how AI assistants interact with the digital world by allowing them to access and utilize external information more effectively. This protocol is crucial for enabling AI models to communicate with external data sources and for building more capable and context-aware AI applications.
**Further Reading:**
* **Introducing the Model Context Protocol:** [https://www.anthropic.com/news/model-context-protocol](https://www.anthropic.com/news/model-context-protocol)
* **How A Simple Protocol Is Changing Everything About AI:** [https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/](https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/)
* **The New Model Context Protocol for AI Agents:** [https://evergreen.insightglobal.com/the-new-model-context-protocol-for-ai-agents/](https://evergreen.insightglobal.com/the-new-model-context-protocol-for-ai-agents/)
* **Model Context Protocol: The New Standard for AI Interoperability:** [https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/](https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/)
* **Hot new protocol glues together AI and apps:** [https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source](https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source)
### 2. Agent2Agent Protocol (A2A)
The Agent2Agent Protocol (A2A) is a cross-platform specification designed to enable AI agents to communicate with each other, securely exchange information, and coordinate actions. This protocol is vital for fostering collaboration among different AI agents, allowing them to work together on complex tasks and delegate responsibilities across various enterprise systems.
**Further Reading:**
* **Announcing the Agent2Agent Protocol (A2A):** [https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/](https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/)
* **What Every AI Engineer Should Know About A2A, MCP & ACP:** [https://medium.com/@elisowski/what-every-ai-engineer-should-know-about-a2a-mcp-acp-8335a210a742](https://medium.com/@elisowski/what-every-ai-engineer-should-know-about-a2a-mcp-acp-8335a210a742)
* **What a new AI protocol means for journalists:** [https://www.dw.com/en/what-coding-agents-and-a-new-ai-protocol-mean-for-journalists/a-72976193](https://www.dw.com/en/what-coding-agents-and-a-new-ai-protocol-mean-for-journalists/a-72976193)
### 3. Agent Communication Protocol (ACP)
The Agent Communication Protocol (ACP) is an open standard specifically for agent-to-agent communication. Its purpose is to transform the current landscape of siloed AI agents into interoperable agentic systems, promoting easier integration and collaboration between them. ACP provides a standardized messaging framework for structured communication.
**Further Reading:**
* **MCP, ACP, and Agent2Agent set standards for scalable AI:** [https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html](https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html)
* **What is Agent Communication Protocol (ACP)?** [https://www.ibm.com/think/topics/agent-communication-protocol](https://www.ibm.com/think/topics/agent-communication-protocol)
* **MCP vs A2A vs ACP: AI Protocols Explained:** [https://www.bluebash.co/blog/mcp-vs-a2a-vs-acp-agent-communication-protocols/](https://www.bluebash.co/blog/mcp-vs-a2a-vs-acp-agent-communication-protocols/)
These emerging protocols are crucial steps towards a more interconnected and efficient AI ecosystem, enabling more sophisticated and collaborative AI applications across various industries.Obsérvese que la respuesta del agente de IA incluye protocolos recientes y enlaces actualizados publicados después de la última actualización de formación de Gemini. Esto pone de relieve el valor de integrar capacidades de búsqueda web en directo.
Más concretamente, la respuesta incluye enlaces contextuales que se asemejan mucho a lo que se encontraría buscando “nuevos protocolos ai” en Google:
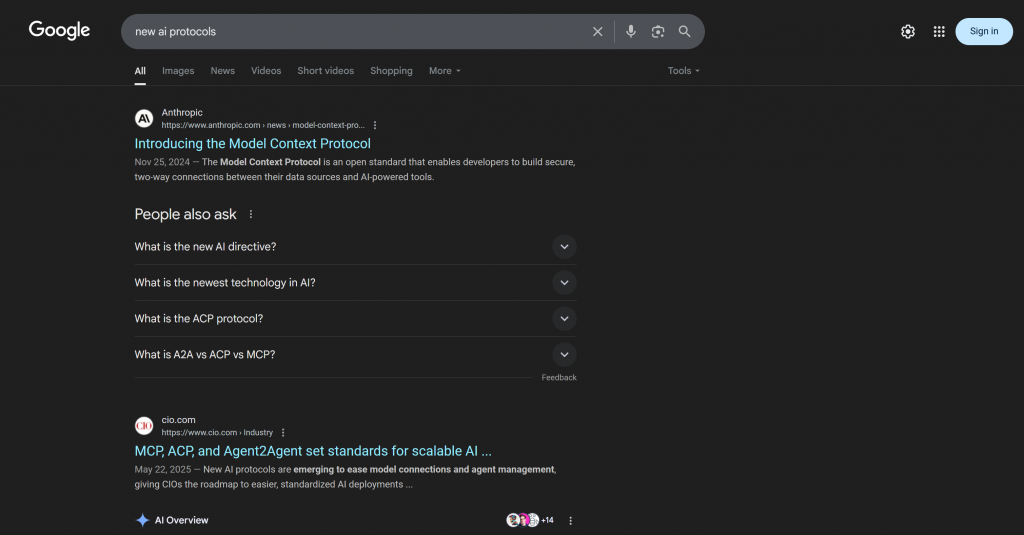
Fíjate en que la respuesta incluye muchos de los mismos enlaces que encontrarías en la SERP real de “nuevos protocolos de IA” (al menos en el momento de escribir este artículo).
¡Et voilà! Ahora tiene un agente de IA LlamaIndex con capacidades de raspado de motores de búsqueda, impulsado por Bright Data.
Paso nº 9: Próximos pasos
El actual agente LlamaIndex SERP AI es sólo un ejemplo sencillo que utiliza únicamente la herramienta search_engine de Bright Data.
En escenarios más avanzados, probablemente no quiera restringir su agente a una sola herramienta. En su lugar, es mejor dar a su agente acceso a todas las herramientas disponibles y escribir un aviso claro del sistema que ayude al LLM a decidir cuáles utilizar para cada objetivo.
Por ejemplo, podrías ampliar tu pregunta para ir un paso más allá y:
- Realice múltiples consultas de búsqueda.
- Seleccione los N enlaces principales de los resultados de las SERP.
- Visita esas páginas y raspa su contenido en Markdown.
- Aprende de esa información para producir un resultado más rico y detallado.
Para obtener más orientación sobre la integración con todas las herramientas disponibles, consulte nuestro tutorial sobre la creación de agentes de IA con LlamaIndex y Bright Data.
Conclusión
En este artículo, ha aprendido a utilizar LlamaIndex para construir un agente de IA capaz de buscar en la web a través de Bright Data. Esta integración permite a su agente ejecutar consultas de búsqueda en los principales motores de búsqueda, incluyendo Google, Bing, Yandex y muchos otros.
Tenga en cuenta que el ejemplo que aquí se presenta es sólo un punto de partida. Si planea desarrollar agentes más avanzados, necesitará herramientas sólidas para recuperar, validar y transformar datos web en directo. Eso es exactamente lo que proporciona la infraestructura de IA para agentes de Bright Data.
Cree una cuenta gratuita en Bright Data y empiece hoy mismo a explorar nuestras herramientas de datos de inteligencia artificial.




