
En esta guía aprenderás:
- Qué es Pydantic AI y qué la hace única como marco para construir agentes de IA.
- Por qué Pydantic AI se empareja bien con el servidor Web MCP de Bright Data para construir agentes que puedan acceder a la web.
- Cómo integrar Pydantic con el Web MCP de Bright Data para crear un agente de IA respaldado por datos reales.
Sumerjámonos.
¿Qué es la IA pydántica?
Pydantic AI es un framework de agentes para Python desarrollado por los creadores de Pydantic, la biblioteca de validación de datos más utilizada para Python.
En comparación con otros marcos de agentes de IA, Pydantic AI hace hincapié en la seguridad de tipos, las salidas estructuradas y la integración con datos y herramientas del mundo real. En detalle, algunas de sus principales características son:
- Compatibilidad con OpenAI, Anthropic, Gemini, Cohere, Mistral, Groq, HuggingFace, Deepseek, Ollama y otros proveedores de LLM.
- Validación estructurada de resultados mediante modelos pydánticos.
- Depuración y supervisión a través de Pydantic Logfire.
- Inyección de dependencia opcional para herramientas, avisos y validadores.
- Respuestas LLM en tiempo real con validación de datos sobre la marcha.
- Soporte multiagente y gráfico para flujos de trabajo complejos.
- Integración de herramientas a través de MCP e incluyendo llamadas HTTP.
- Flujo Pythonic familiar para construir agentes de IA como aplicaciones Python estándar.
- Soporte integrado para pruebas unitarias y desarrollo iterativo.
La biblioteca es de código abierto y ya ha alcanzado más de 11 000 estrellas en GitHub.
Por qué combinar Pydantic AI con un servidor MCP para la recuperación de datos web
Los agentes de IA construidos con Pydantic AI heredan las limitaciones del LLM subyacente. Entre ellas, la falta de acceso a información en tiempo real, que puede dar lugar a respuestas imprecisas. Afortunadamente, este problema puede solucionarse fácilmente dotando al agente de datos actualizados y de la capacidad de explorar la web en tiempo real.
Aquí es donde entra en juego el MCP web de Bright Data. Construido sobre Node.js, este servidor MCP se integra con el conjunto de herramientas de recuperación de datos preparadas para IA de Bright Data. Estas herramientas permiten a su agente acceder a contenido web, consultar conjuntos de datos estructurados, buscar en la web e interactuar con páginas web sobre la marcha.
A partir de ahora, las herramientas MCP del servidor incluyen:
| Herramienta | Descripción |
|---|---|
scrape_as_markdown |
Raspe el contenido de una URL de una sola página web con opciones avanzadas de extracción, devolviendo los resultados como Markdown. Puede evitar la detección de bots y CAPTCHA. |
motor_de_busqueda |
Extrae los resultados de búsqueda de Google, Bing o Yandex, devolviendo los datos SERP en formato markdown (URL, título, snippet). |
scrape_as_html |
Recupera el contenido de una página web desde una URL con opciones avanzadas de extracción, devolviendo el HTML completo. Puede evitar la detección de bots y CAPTCHA. |
estadísticas_sesión |
Proporciona estadísticas sobre el uso de la herramienta durante la sesión actual. |
scraping_browser_go_back |
Vuelva a la página anterior en la sesión del navegador de raspado. |
scraping_browser_go_forward |
Avanzar a la página siguiente en la sesión del navegador de raspado. |
scraping_browser_click |
Realizar una acción de clic en un elemento específico por selector. |
scraping_browser_links |
Recupera todos los enlaces, incluyendo texto y selectores, de la página actual. |
scraping_browser_type |
Introducir texto en un elemento especificado dentro del navegador de raspado. |
scraping_browser_wait_for |
Espere a que un elemento concreto sea visible en la página antes de continuar. |
scraping_browser_screenshot |
Captura una pantalla de la página actual del navegador. |
scraping_browser_get_html |
Recupera el contenido HTML de la página actual en el navegador. |
scraping_browser_get_text |
Extrae el contenido de texto visible de la página actual. |
Además, existen más de 40 herramientas especializadas para recopilar datos estructurados de una amplia gama de sitios web (por ejemplo, Amazon, Yahoo Finance, TikTok, LinkedIn, etc.) mediante las API de Web Scraper. Por ejemplo, la herramienta web_data_amazon_product recopila información detallada y estructurada de productos de Amazon aceptando como entrada una URL válida del producto.
Ahora, echa un vistazo a cómo puedes utilizar estas herramientas MCP en Pydantic AI.
Cómo integrar Pydantic AI con el servidor Bright MCP en Python
En esta sección, aprenderás a utilizar Pydantic AI para construir un agente de IA. El agente estará equipado con capacidades de raspado, recuperación e interacción de datos en vivo desde el servidor Web MCP.
Como ejemplo, demostraremos cómo el agente puede recuperar datos de productos de Amazon sobre la marcha. Tenga en cuenta que éste es sólo uno de los muchos casos de uso posibles. El agente de IA puede aprovechar cualquiera de las más de 50 herramientas disponibles a través del servidor MCP para realizar una amplia gama de tareas.
Siga este tutorial guiado para crear su agente Gemini + Bright Data MCP-powered AI con Pydantic AI.
Requisitos previos
Para reproducir el ejemplo de código, asegúrese de tener instalado localmente lo siguiente:
- Python 3.10 o superior.
- Node.js (recomendamos la última versión LTS).
También necesitarás:
- Una cuenta de Bright Data.
- Una clave API de Gemini (o una clave API de otro proveedor de LLM compatible, como OpenAI, Anthropic, Deepseek, Ollama, Groq, Cohere y Mistral).
No se preocupe por configurar las claves API todavía. Los pasos siguientes le guiarán en la configuración de las credenciales de Bright Data y Gemini cuando llegue el momento.
Aunque no es estrictamente necesario, estos conocimientos previos le ayudarán a seguir el tutorial:
- Comprensión general del funcionamiento de MCP.
- Familiaridad básica con el funcionamiento de los agentes de IA.
- Cierto conocimiento del servidor Web MCP y sus herramientas disponibles.
- Conocimientos básicos de programación asíncrona en Python.
Paso 1: Cree su proyecto Python
Abre tu terminal y crea una nueva carpeta para tu proyecto:
mkdir pydantic-ai-mcp-agentLa carpeta pydantic-ai-mcp-agent contendrá todo el código para tu agente Python de IA.
Navega hasta la carpeta recién creada y configura un entorno virtual dentro de ella:
cd pydantic-ai-mcp-agent
python -m venv venvAhora, abre la carpeta del proyecto en tu IDE de Python preferido. Recomendamos Visual Studio Code con la extensión Python o PyCharm Community Edition.
Crea un archivo llamado agent.py en la raíz de tu proyecto. En este punto, la estructura de carpetas debería ser la siguiente:
pydantic-ai-mcp-agent/
├── venv/
└── agent.pyEl archivo agent. py está actualmente vacío, pero pronto contendrá la lógica para integrar Pydantic AI con el servidor MCP de Bright Data Web.
Active el entorno virtual utilizando el terminal de su IDE. En Linux o macOS, ejecute este comando:
source venv/bin/activateDe forma equivalente, en Windows, ejecute:
venv/Scripts/activate¡Ya está todo listo! Ahora tienes un entorno Python listo para construir un agente de IA con acceso a datos web.
Paso 2: Instalar Pydantic AI
En su entorno virtual activado, instale todos los paquetes Pydantic AI necesarios con:
pip install "pydantic-ai-slim[google,mcp]" Esto instala pydantic-ai-slim, una versión ligera del paquete completo pydantic-ai que evita tirar de dependencias innecesarias.
En este caso, dado que planea integrar su agente con el servidor MCP de Bright Data Web, necesitará la extensión mcp. Y como integraremos Gemini como proveedor LLM, también necesitará la extensión google.
Nota: Para otros modelos o proveedores, consulte la documentación del modelo para ver qué dependencias opcionales son necesarias.
A continuación, añade estas importaciones en tu archivo agent.py:
from pydantic_ai import Agent
from pydantic_ai.mcp import MCPServerStdio
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProvider¡Genial! Ya puedes usar la IA de Pydantic para construir agentes.
Paso nº 3: Configurar las variables de entorno Lectura
Su agente de IA interactuará con servicios de terceros como Bright Data y Gemini a través de la API. No codifique sus claves API en su código Python. En su lugar, cárgalas desde variables de entorno para mejorar la seguridad y la facilidad de mantenimiento.
Para simplificar el proceso, aprovecha la biblioteca python-dotenv. Con tu entorno virtual activado, instálala ejecutando:
pip install python-dotenvA continuación, en su archivo agent.py, importe la biblioteca y cargue las variables de entorno con load_dotenv():
from dotenv import load_dotenv
load_dotenv()Esto permite al script leer variables de entorno desde un archivo local .env. Así que adelante y crear un archivo .env dentro de la carpeta del proyecto:
pydantic-ai-mcp-agent/
├── venv/
├── agent.py
└── .env # <---------------Ahora puedes acceder a las variables de entorno de la siguiente manera:
env_value = os.getenv("<ENV_NAME>")No olvides importar el módulo os de la biblioteca estándar de Python:
import osYa está. Ahora está configurado para cargar de forma segura las claves Api desde el archivo .env.
Paso 4: Empezar a utilizar el servidor MCP de Bright Data
Si aún no lo ha hecho, cree una cuenta de Bright Data. Si ya tiene una, simplemente inicie sesión.
A continuación, siga las instrucciones oficiales para configurar su clave de API de Bright Data. Para simplificar, asumimos que está utilizando un token con permisos de administrador en esta sección.
Instale el MCP Web de Bright Data de forma global a través de npm:
npm install -g @brightdata/mcpA continuación, comprueba que todo funciona con el siguiente comando Bash:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpO, en Windows, el comando PowerShell equivalente es:
$env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpEn el comando anterior, sustituya el marcador de posición por la API real de Bright Data que recuperó anteriormente. Ambos comandos establecen la variable de entorno API_TOKEN necesaria e inician el servidor MCP a través del paquete @brightdata/mcp npm.
Si todo funciona correctamente, su terminal mostrará registros similares a este:

La primera vez que inicie el servidor MCP, creará automáticamente dos zonas predeterminadas en su cuenta de Bright Data:
mcp_unlocker: Una zona para Web Unlocker.mcp_browser: Una zona para la API del navegador.
Estas dos zonas permiten al servidor MCP ejecutar todas las herramientas que expone.
Para comprobarlo, inicie sesión en su panel de Bright Data y vaya a la página“Proxies & Scraping Infrastructure“. Verá que se han creado automáticamente las siguientes zonas:
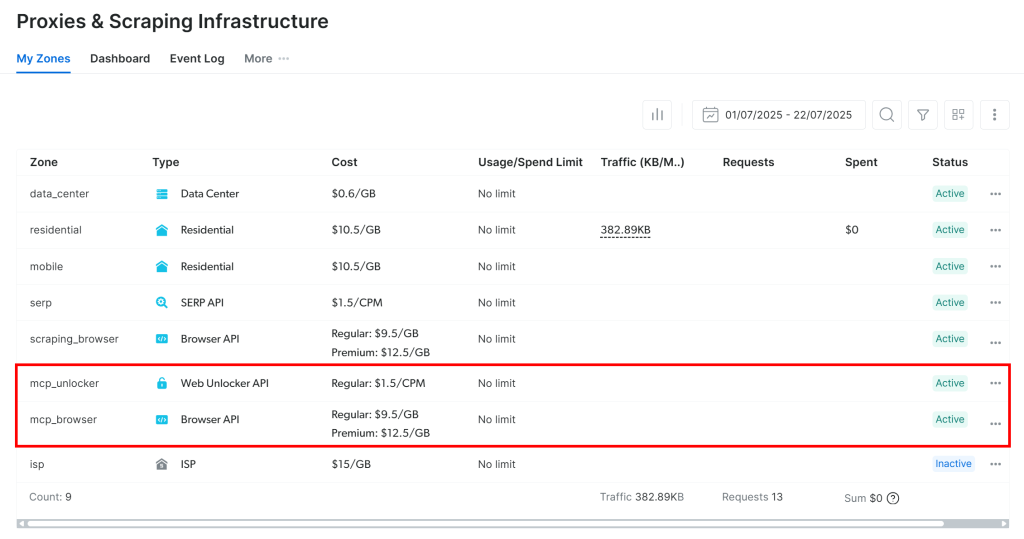
Nota: Si no está utilizando un token de API con permisos de administrador, tendrá que crear las zonas manualmente. De todas formas, siempre puedes especificar los nombres de las zonas en los envs como se explica en la documentación oficial.
Por defecto, el MCP Web sólo expone las herramientas search_engine y scrape_as_markdown. Para desbloquear capacidades avanzadas como la automatización del navegador y la extracción de datos estructurados, tienes que activar el modo Pro estableciendo la variable de entorno PRO_MODE=true.
¡Estupendo! El Web MCP funciona a las mil maravillas.
Paso nº 5: Conectarse a la Web MCP
Ahora que has confirmado que tu máquina puede ejecutar Web MCP, ¡conéctate a ella!
Empiece añadiendo su clave de API de Bright Data al archivo .env:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Sustituya el por la clave real de la API de Bright Data que obtuvo anteriormente.
Luego, léelo en el archivo agent.py con:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Tenga en cuenta que Pydantic AI admite tres métodos de conexión a un servidor MCP:
- Utilización del transporte HTTP Streamable.
- Utilización del transporte HTTP SSE.
- Ejecutar el servidor como un subproceso y conectarse a través de
stdio.
Si no está familiarizado con los dos primeros métodos, lea nuestra guía sobre SSE vs Streamable HTTP para obtener una explicación más detallada.
En este caso, desea ejecutar el servidor como un subproceso (tercer método). Para ello, inicialice una instancia MCPServerStdio como se muestra a continuación:
server = MCPServerStdio(
"npx",
args=[
"-y",
"@brightdata/mcp",
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Enable the Pro Mode to access all Bright Data tools
},
)Lo que hacen estas líneas de código es esencialmente lanzar el Web MCP utilizando el mismo comando npx que ejecutó anteriormente. Establece la variable de entorno API_TOKEN utilizando su clave API de Bright Data para la autenticación. Además, habilita PRO_MODE para que tenga acceso a todas las herramientas disponibles, incluidas las avanzadas.
Perfecto. Ahora ha configurado correctamente la conexión a su Web MCP local en código.
Paso nº 6: Configurar el LLM
Nota: Esta sección se refiere a Gemini, el LLM elegido para el tutorial. Sin embargo, puedes adaptarlo fácilmente a OpenAI o a cualquier otro LLM soportado siguiendo la documentación oficial.
Comience por recuperar su clave API Gemini y añádala a su archivo .env de la siguiente manera:
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"Sustituya el con su clave API real.
A continuación, importe las bibliotecas Pydantic AI necesarias para la integración de Gemini:
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProviderEstas importaciones le permiten conectarse a las API de Google y configurar un modelo Gemini. Fíjate en que no necesitas leer manualmente la GOOGLE_API_KEY del archivo .env. La razón es que GoogleProvider utiliza google-genai bajo el capó, que lee automáticamente la clave de API de la env GOOGLE_API_KEY.
Ahora, inicialice las instancias del proveedor y del modelo:
provider = GoogleProvider()
model = GoogleModel("gemini-2.5-flash", provider=provider)¡Asombroso! Esto permitirá al agente Pydantic AI conectarse al modelo gemini-2.5-flash a través de la API de Google, que es de uso gratuito.
Paso 7: Definir el agente Pydantic AI
Definir un Agente Pydantic AI que utilice el LLM previamente configurado y se conecte al servidor Web MCP:
agent = Agent(model, toolsets=[server])Perfecto. Con una sola línea de código, acabas de instanciar un objeto Agente. Esto representa un agente AI que puede manejar sus tareas usando las herramientas expuestas por el servidor Web MCP.
Paso 8: Ponga en marcha su agente
Para probar su agente de IA, debe escribir una solicitud que implique una tarea de extracción de datos web (en interacción). Esto le ayudará a verificar si el agente utiliza las herramientas de Bright Data como se espera.
Un buen punto de partida es pedirle que recupere los datos de un producto de una página de Amazon, así:
“Dame los datos del producto de https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/”
Normalmente, si envías una solicitud como ésta directamente a Géminis, sucedería una de dos cosas:
- La solicitud fallaría debido a los sistemas anti-bot de Amazon (por ejemplo, el CAPTCHA de Amazon), que impiden a Gemini acceder al contenido de la página.
- Devolvería información alucinada o inventada sobre el producto, ya que no puede acceder a la página en directo.
Pruebe la solicitud directamente en Géminis. Es probable que aparezca un mensaje diciendo que no se pudo acceder a la página de Amazon, seguido de los detalles del producto fabricado, como a continuación:

Gracias a la integración con el servidor Web MCP, esto no debería ocurrir en tu configuración. En lugar de fallar o adivinar, tu agente debería utilizar la herramienta web_data_amazon_product para recuperar datos de producto estructurados y en tiempo real de la página de Amazon y devolverlos después en un formato limpio y legible.
Dado que el método para interrogar al agente Pydantic AI es asíncrono, envuelve la lógica de ejecución en una función asíncrona como esta:
async def main():
async with agent:
result = await agent.run("Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/")
output = result.output
print(output)
if __name__ == "__main__":
asyncio.run(main())No olvides importar asyncio de la biblioteca estándar de Python:
import asyncioMisión cumplida. Sólo queda ejecutar el código completo y ver si el agente está a la altura de las expectativas.
Paso 9: Póngalo todo junto
Este es el código final en agent.py:
from pydantic_ai import Agent
from pydantic_ai.mcp import MCPServerStdio
from pydantic_ai.models.google import GoogleModel
from pydantic_ai.providers.google import GoogleProvider
from dotenv import load_dotenv
import os
import asyncio
# Load the environment variables from the .env file
load_dotenv()
# Read the API key from the envs for integration with the Bright Data Web MCP server
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Connect to the Bright Data Web MCP server
server = MCPServerStdio(
"npx",
args=[
"-y",
"@brightdata/mcp",
],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Enable the Pro Mode to access all Bright Data tools
},
)
# Configure the Google LLM model
provider = GoogleProvider()
model = GoogleModel("gemini-2.5-flash", provider=provider)
# Initialize the AI agent with Gemini and Bright Data's Web MCP server integration
agent = Agent(model, toolsets=[server])
async def main():
async with agent:
# Ask the AI Agent to perform a scraping task
result = await agent.run("Give me product data from https://www.amazon.com/AmazonBasics-Pound-Neoprene-Dumbbells-Weights/dp/B01LR5S6HK/")
# Get the result produced by the agent and print it
output = result.output
print(output)
if __name__ == "__main__":
asyncio.run(main())¡Guau! Gracias a Pydantic AI y Bright Data, en unas 50 líneas de código, acabas de construir un potente agente de IA potenciado por MCP.
Ejecutar el agente AI con:
python agent.pyEn el terminal, debería ver una salida como la siguiente:

Como puede comprobar comprobando la página de productos de Amazon mencionada en la solicitud, la información devuelta por el agente de IA es exacta:
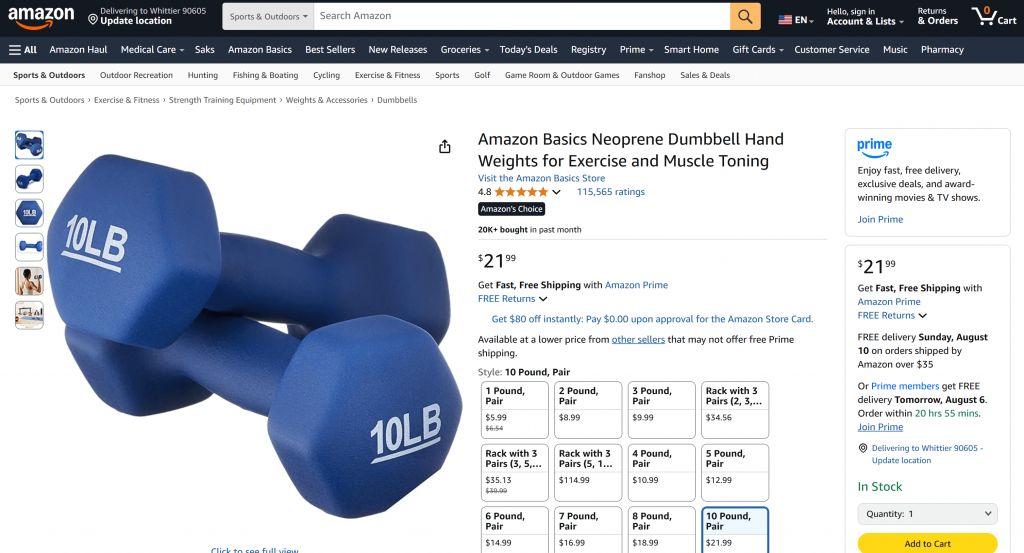
Esto se debe a que el agente utilizó la herramienta web_data_amazon_product proporcionada por el servidor Web MCP para recuperar datos de productos frescos y estructurados de Amazon en formato JSON.
¡Et voilà! Se cumplieron las expectativas y la integración de Pydantic AI + MCP funcionó exactamente como estaba previsto.
Próximos pasos
El agente de IA construido aquí es funcional, pero sólo sirve como punto de partida. Considera la posibilidad de llevarlo al siguiente nivel:
- Implementar un bucle REPL para chatear con el agente en la CLI o integrarlo con herramientas de chat GUI como Gradio.
- Ampliación de las herramientas MCP de Bright Data mediante la definición de sus propias herramientas personalizadas.
- Añadir depuración y monitorización usando Pydantic Logfire.
- Transformación de su agente en un agente autónomo RAG dentro de un flujo de trabajo multiagente.
- Definición de validadores de funciones personalizados para la integridad de los datos de salida.
Conclusión
En este artículo, has aprendido cómo integrar Pydantic AI con el servidor Web MCP de Bright Data para construir un agente de IA capaz de acceder a la web. Esta integración es posible gracias al soporte integrado de Pydantic AI para MCP.
Para crear agentes más sofisticados, explore toda la gama de servicios disponibles en la infraestructura de IA de Bright Data. Estas soluciones pueden alimentar una amplia variedad de escenarios de agentes.
Cree una cuenta gratuita en Bright Data y empiece a experimentar con nuestras herramientas de datos web preparadas para la IA.




