

En este artículo, aprenderás:
- Qué es Ruflo, sus principales características y capacidades, y sus mayores limitaciones.
- Cómo abordar esas limitaciones con una solución de infraestructura de datos web preparada para la IA, como Bright Data.
- Las dos formas principales de integrar Bright Data y Ruflo en una configuración de Claude Code u OpenAI Codex.
- Cómo empezar a utilizar Ruflo configurándolo en un proyecto local basado en Claude Code.
- Cómo añadir la búsqueda web, la recuperación de datos y la interacción con sitios web de nivel empresarial de Bright Data a la configuración a través de MCP.
- Cómo lograr la misma integración utilizando las habilidades de Bright Data para Claude.
- Qué permite esta configuración de Ruflo + Bright Data en un asistente de programación autónomo.
¡Vamos a ello!
Introducción a Ruflo: la plataforma de orquestación de agentes para Claude
Pronto verás cómo y por qué combinar Ruflo con las capacidades de búsqueda y recuperación de datos web de Bright Data. Pero primero, tómate un momento para entender qué es Ruflo y qué aporta.
¿Qué es Ruflo?
Ruflo (antes conocido como Claude Flow) es un marco de orquestación de IA diseñado para convertir Claude Code (y OpenAI Codex) en un marco de orquestación multiagente con numerosas funciones.
En concreto, dota a los asistentes de programación con agentes de un conjunto coordinado de unos 100 agentes de IA especializados que trabajan en paralelo. Esto permite a Claude Code y OpenAI Codex gestionar tareas de software complejas mediante enrutamiento inteligente, memoria compartida y flujos de trabajo de autoaprendizaje.
Como proyecto de código abierto, Ruflo cuenta con más de 27 000 estrellas en GitHub y más de 6000 commits. Este rápido crecimiento pone de manifiesto la rapidez con la que Ruflo ha ganado popularidad entre la comunidad de desarrolladores.
Cómo Ruflo lleva a los asistentes de codificación con IA a un nuevo nivel
A grandes rasgos, las principales características que ofrece Ruflo son:
- Orquestación multiagente a gran escala: implementa y coordina unos 100 agentes de IA especializados que trabajan en paralelo en tareas de desarrollo complejas.
- Colaboración basada en enjambres: los agentes operan en «enjambres» estructurados con coordinación jerárquica, mecanismos de consenso y objetivos compartidos.
- Autoaprendizaje y enrutamiento adaptativo: aprende de ejecuciones anteriores y enruta dinámicamente las tareas a los agentes más eficaces mediante el reconocimiento de patrones.
- Memoria persistente y grafos de conocimiento: combina la búsqueda vectorial (HNSW), la memoria compartida y los grafos de conocimiento para conservar el contexto entre sesiones.
- Optimización inteligente de costes y rendimiento: utiliza el enrutamiento de varios niveles (WASM + LLM) para reducir la latencia y recortar los costes de API hasta en un 75 %.
- Compatibilidad con múltiples LLM con conmutación por error: funciona con Claude, GPT, Gemini y modelos locales, seleccionando automáticamente el mejor proveedor para cada tarea.
- Seguridad y extensibilidad listas para producción: protecciones integradas (inyección de prompts, validación) más un sistema de plugins para ampliar agentes, hooks y flujos de trabajo.
Esto supone una diferencia importante al comparar Claude Code con y sin Ruflo:
| Claude Code solo | Claude Code + Ruflo | |
|---|---|---|
| Colaboración entre agentes | Los agentes trabajan de forma independiente | Los agentes colaboran con memoria compartida |
| Coordinación | Gestión manual de tareas | Jerarquía dirigida por una reina con coordinación automatizada |
| Mente colmena | No disponible | Inteligencia colectiva entre agentes |
| Consenso | Sin decisiones multiagente | Votación tolerante a fallos con reglas de mayoría |
| Memoria | Solo sesión | Memoria vectorial persistente + gráfico de conocimiento |
| Base de datos vectorial | Ninguna | RuVector PostgreSQL, búsqueda rápida y alto QPS |
| Grafo de conocimiento | Listas planas | Destaca las ideas clave utilizando PageRank y la detección de comunidades |
| Memoria colectiva | Sin conocimiento compartido | Base de conocimientos compartida entre agentes |
| Aprendizaje | Estático, sin adaptación | Autoaprendizaje con rápida adaptación y transferencia de conocimientos |
| Ámbito de actuación del agente | Solo un proyecto | Memoria multinivel (proyecto/local/usuario) con transferencia entre agentes |
| Enrutamiento de tareas | Selección manual de agentes | Enrutamiento inteligente basado en patrones aprendidos |
| Tareas complejas | Se requiere desglose manual | Descomposición automática en múltiples ámbitos |
| Trabajadores en segundo plano | Ninguno | Envío automático ante desencadenantes como cambios en archivos o patrones |
| Proveedor de LLM | Solo Anthropic | Varios proveedores con conmutación por error y optimización de costes |
| Seguridad | Protecciones estándar | Reforzadas: validación, cifrado, mitigación de CVE |
| Rendimiento | Referencia | Más rápido gracias a enjambres paralelos y enrutamiento inteligente |
Principales limitaciones y cómo abordarlas
Independientemente de lo completos y versátiles que sean los aproximadamente 100 agentes y las capacidades generales de Ruflo, existe una limitación fundamental. Esta radica en la propia naturaleza de los modelos de lenguaje grande (LLM). Estos modelos se entrenan con Conjuntos de datos estáticos que se detienen en un momento específico, lo que limita de forma inherente su conocimiento.
Es cierto que Ruflo incluye un agente de automatización del navegador dedicado a la búsqueda web, la interacción y la extracción de datos. Ahora bien, el problema es que la mayoría de los sitios web actuales cuentan con sistemas antibots que bloquean las solicitudes automatizadas. Esto incluye las solicitudes procedentes de agentes de navegador impulsados por IA. Por lo tanto, la recuperación de conocimientos de Ruflo puede fallar o acceder solo a una parte del contenido que necesita.
Se trata de un problema crítico, ya que el conocimiento preciso, actualizado y contextual es lo que hace que los sistemas multiagente sean verdaderamente eficaces. Para superar este problema, su asistente de programación de IA necesita herramientas diseñadas específicamente para la búsqueda web en tiempo real, la extracción de datos y la interacción web sin bloqueos.
¡Eso es exactamente lo que ofrece Bright Data!
Las herramientas de datos web de Bright Data como solución
Como plataforma de datos web líder en el mercado, Bright Data ofrece herramientas preparadas para agentes de IA, tales como:
- API SERP: recopila resultados de motores de búsqueda de Google, Bing y otros para generar respuestas fundamentadas.
- API Web Unlocker: Accede a HTML sin procesar o Markdown desde cualquier sitio, eludiendo CAPTCHAs, bloqueos de IP y medidas antibots.
- API de navegador: controla mediante programación un navegador remoto para una interacción automatizada y sin bloqueos con cualquier sitio web.
- API de Scraping web: recopila datos estructurados de plataformas como Amazon, Instagram, LinkedIn, Yahoo Finance y muchas otras.
- API de rastreo: Convierte sitios web completos en Conjuntos de datos estructurados para flujos de trabajo de IA posteriores.
Lo que distingue a Bright Data es su infraestructura de nivel empresarial. Basada en una red global de Proxies con más de 400 millones de direcciones IP en 195 países, admite una escalabilidad ilimitada al tiempo que mantiene un tiempo de actividad del 99,99 % y una tasa de éxito del 99,95 %.
Bright Data colabora con Ruflo para dotar a tu sistema de codificación agentica de la capacidad de explorar, recuperar y razonar sobre datos web en tiempo real. ¡Todo ello a gran escala y sin encontrar bloqueos!
Cómo combinar Bright Data y Ruflo: dos enfoques
Técnicamente, puedes integrar Bright Data directamente en Ruflo utilizando el SDK del plugin. Tendrías que definir herramientas personalizadas que se conecten a cada producto de Bright Data que quieras utilizar. Sin embargo, ¡ese no es el enfoque más rápido!
En lugar de reinventar la rueda, es mucho más fácil confiar en:
- Bright Data Web MCP: un servidor todo en uno de código abierto que ofrece más de 60 herramientas para la búsqueda web, la navegación, la extracción de datos y la interacción sin bloqueos.
- Habilidades de Bright Data: capacidades preconfiguradas que enseñan a su agente de programación a realizar scraping web, búsquedas y recuperación de datos estructurados impulsados por IA. Incluyen una conexión con el Web MCP.
Estas pueden añadirse directamente a Claude Code (o OpenAI Codex), lo que da lugar a una configuración de programación unificada que combina tanto Ruflo como Bright Data. El LLM subyacente puede entonces utilizar herramientas de ambas soluciones de forma coordinada y sinérgica.
Nota: Los ejemplos que siguen utilizan Claude Code, pero puedes adaptarlos fácilmente a OpenAI Codex.
Ahora veamos cómo ampliar Claude Code con Bright Data y Ruflo utilizando MCP o habilidades. Pero primero, ¡configura Ruflo!
Introducción a Ruflo
Sigue las instrucciones que aparecen a continuación para aprender a configurar Ruflo en tu proyecto de programación.
Requisitos previos
Para seguir esta sección, asegúrate de tener:
- Claude Code instalado y configurado localmente.
- Node.js 20+ instalado localmente (se recomienda la última versión LTS).
Paso n.º 1: Configurar Ruflo
Crea una nueva carpeta para tu proyecto de programación (por ejemplo, bright-data-ruflo-project). Ahí es donde inicializarás Ruflo. A continuación, accede a la carpeta en tu terminal:
mkdir bright-data-ruflo-project
cd bright-data-ruflo-projectNota: También puedes empezar desde una carpeta de proyecto existente. En la mayoría de los casos, esto es lo que harás. Añadirás Ruflo a tu proyecto para aprovechar sus funciones.
Ejecuta el siguiente comando en tu terminal para iniciar el asistente de instalación de Ruflo a través de npm:
npx ruflo@latest init --wizardLa instalación del paquete ruflo puede tardar unos minutos, así que ten paciencia.
Este es el resultado que deberías obtener: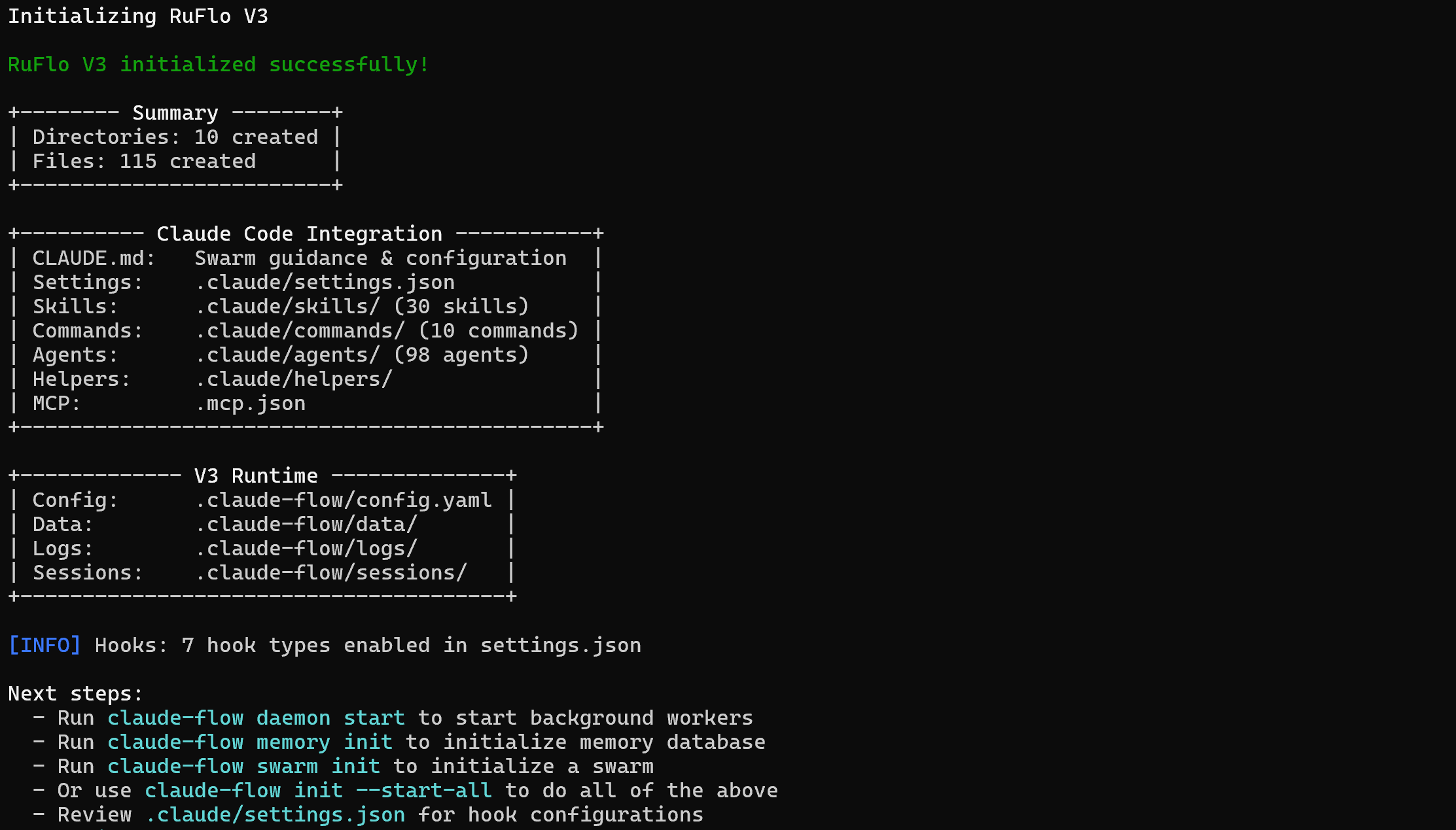
Nota: El resultado en la CLI puede sugerir el uso de comandos claude-flow para inicializar servicios de backend, bases de datos en memoria o enjambres. Sin embargo, eso no es correcto. Al instalar Ruflo a través de npm, el comando base correcto es:
npx ruflo@latestLa carpeta de tu proyecto ahora contendrá:
bright-data-ruflo-project/
├─── .claude/
│ ├─── agents/
│ ├─── commands/
│ ├─── helpers/
│ └─── skills/
├─── .claude-flow/
├─── .swarm/
├─── .mcp.json
└─── CLAUDE.mdBásicamente, bright-data-ruflo-project contiene todos los archivos que Claude Code necesita para acceder a nivel de proyecto a nuevas habilidades, comandos y agentes. En otras palabras, Ruflo se ha integrado completamente en tu configuración local de Claude Code. ¡Bien hecho!
Paso n.º 2: Iniciar Ruflo
Ruflo ha añadido varios agentes, comandos y habilidades. Sin embargo, para que Claude Code pueda ejecutarlos, primero debes iniciar Ruflo. Hazlo con:
npx ruflo@latest startDeberías ver un resultado como este: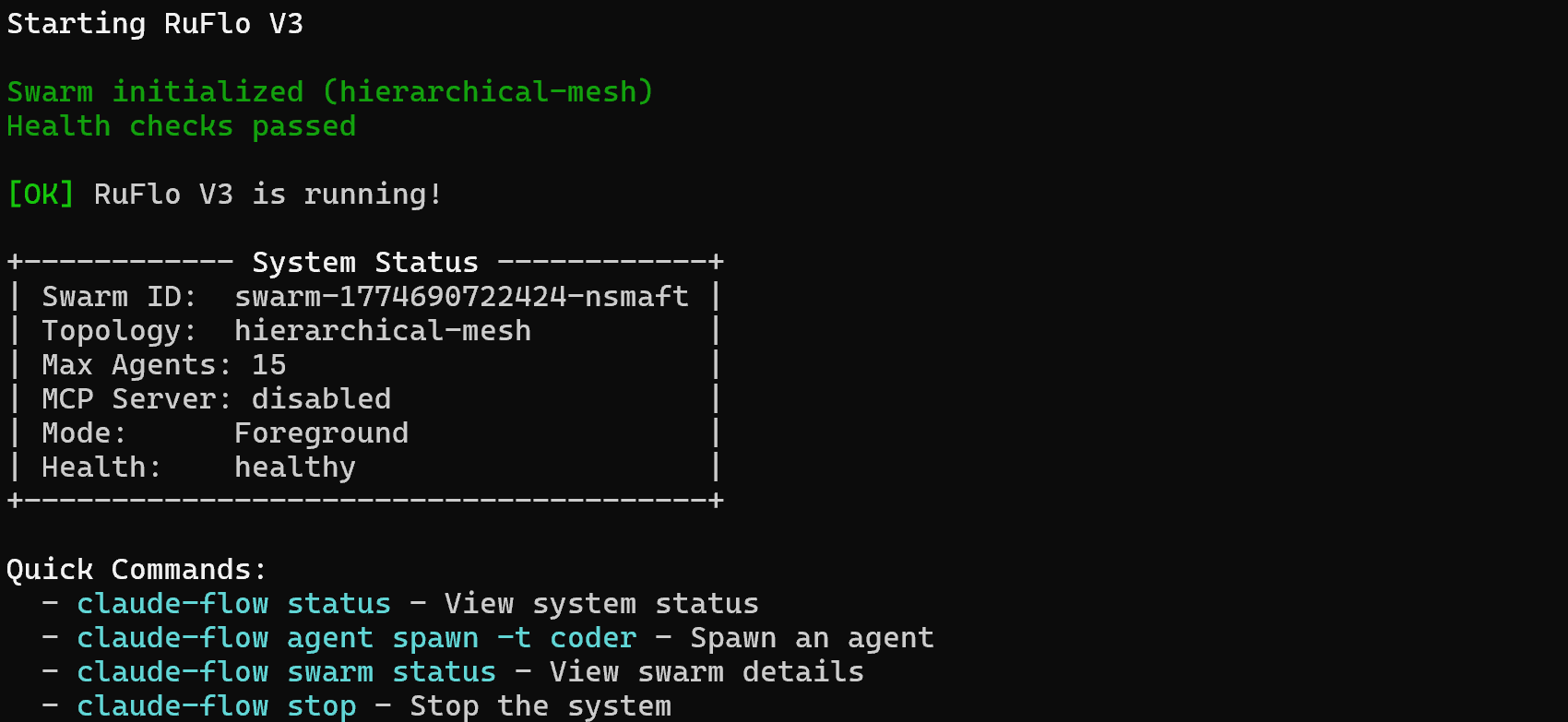
¡Fantástico! Tu configuración de Claude Code ya puede aprovechar la funcionalidad ampliada que ofrece Ruflo.
Paso n.º 3: Verifica la integración
En el directorio de tu proyecto, inicia Claude Code:
claudeEs posible que recibas un mensaje como este:
Selecciona la opción 1 o la opción 2. De esta forma, Claude Code iniciará el servidor MCP de Ruflo y se conectará a él al iniciarse.
A continuación, verás registros que muestran claramente que Ruflo está disponible en Claude Code: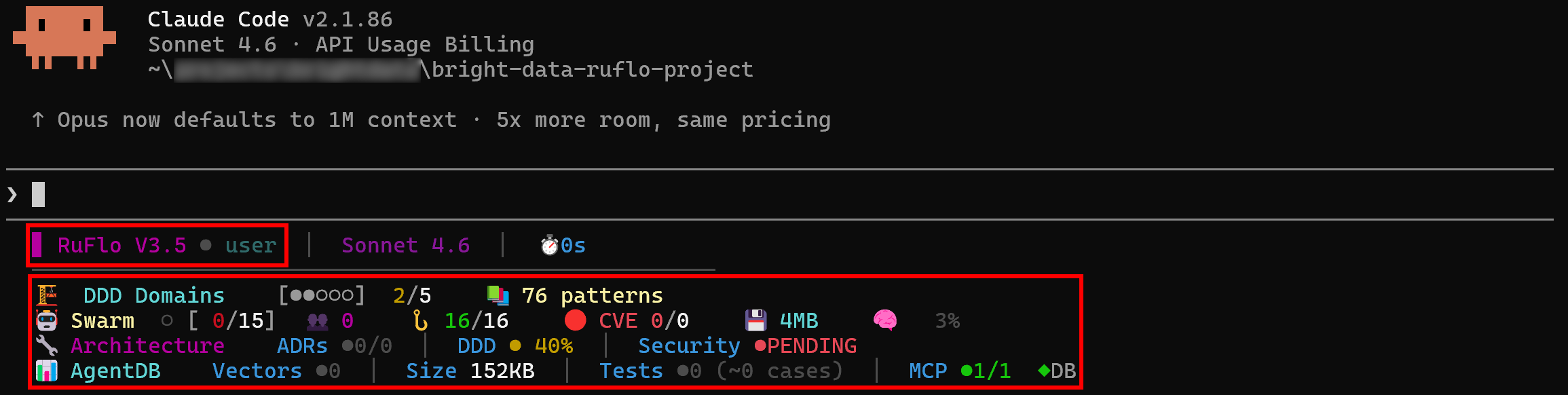
Escribe «/agent» y deberías ver algunos de los comandos adicionales de Ruflo:
¡Genial! Claude Code se ha conectado correctamente a Ruflo, lo que confirma que la integración funciona.
Enfoque de integración n.º 1: Ruflo MCP + Bright Data MCP
En esta sección, aprenderás a añadir las capacidades de Ruflo y Bright Data a tu configuración de Claude Code a través de MCP.
Requisitos previos
Para que esta sección sea concisa, daremos por hecho que ya has integrado Bright Data Web MCP en tu configuración de Claude Code.
Si aún no lo has hecho, sigue el tutorial detallado«Integración de Claude Code con el Web MCP de Bright Data»o la guía de documentación«Integración del servidor MCP de Claude Code». Solo asegúrate de añadir la configuración necesaria al archivo .mcp.json local creado por Ruflo durante el comando init.
También es imprescindible estar familiarizado con el funcionamiento de MCP y con cómo conectar servidores MCP a Claude Code.
Paso n.º 1: Comprueba los servidores MCP disponibles
Por defecto, el servidor MCP de Ruflo está configurado en el archivo .mcp.json local. Este archivo también debe contener la configuración para conectarse al Web MCP de Bright Data.
Lo normal es que Claude Code detecte automáticamente ambos servidores MCP y se conecte a ellos. Para verificarlo, inicia Claude Code en la carpeta de tu proyecto y ejecuta el comando /mcp:
Deberías ver:
bright-data-web-mcp(o el nombre que le hayas dado al MCP web de Bright Data en la configuración.mcp.json).claude-flow(el nombre del servidor MCP de Ruflo).
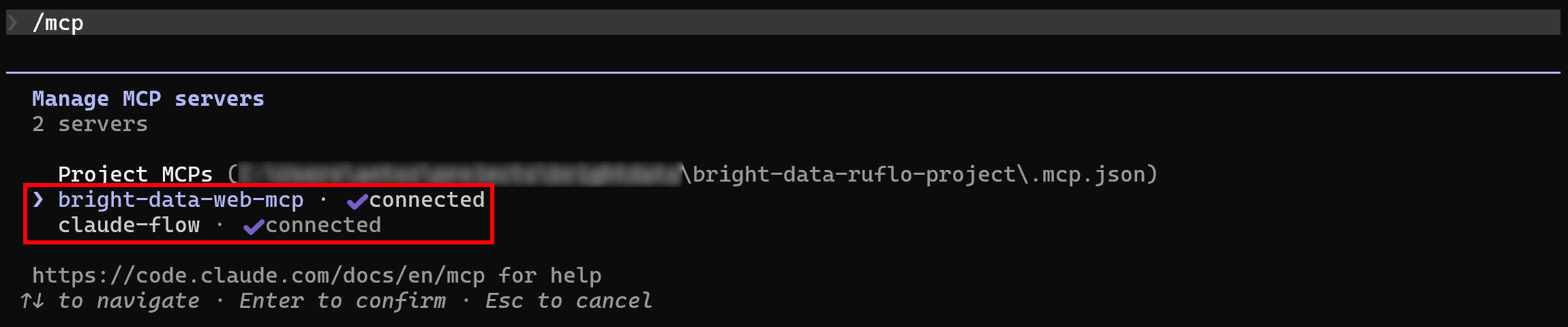
¡Genial! Claude Code ya está conectado a ambos servidores MCP tal y como se esperaba.
Paso n.º 2: Inspecciona el servidor MCP de Bright Data Web
Selecciona la entrada bright-data-web-mcp (o el nombre que le hayas dado):
Elige la opción «Ver herramientas» para ver todas las herramientas disponibles. Si lo has configurado en modo Pro, obtendrás las más de 65 herramientas:
De lo contrario, solo verás 4 herramientas (scrape_as_markdown, search_engine y sus 2 versiones por lotes).
¡Excelente! El MCP de Bright Data Web está mostrando sus herramientas tal y como se esperaba.
Paso n.º 3: Inspecciona el servidor MCP de Ruflo
Repite el mismo procedimiento que antes, pero para el MCP de claude-flow. Deberías ver:
Fíjate en cómo el MCP de Ruflo muestra un impresionante total de 254 herramientas. ¡Vaya!
Enfoque de integración n.º 2: Habilidades de Ruflo + Habilidades de Bright Data
Aquí se te guiará a través del proceso de añadir capacidades de Ruflo y Bright Data a tu configuración de Claude Code mediante habilidades.
Requisitos previos
Para seguir esta sección, asegúrate de tener:
- Claude Code configurado en un sistema operativo basado en Unix (macOS, Linux o WSL).
- Git instalado localmente.
- Una cuenta de Bright Data con una zona de Web Unlocker configurada y una clave API configurada.
- Conocimientos básicos sobre qué son las habilidades de Claude y cómo configurarlas en Claude Code.
- Familiaridad con las habilidades disponibles en el repositorio oficial de habilidades de Bright Data Claude.
Nota: No te preocupes por crear una cuenta de Bright Data todavía, ya que se te guiará a través del proceso en el siguiente paso.
A continuación, instala curl y jq, los dos requisitos previos que exigen las habilidades de Bright Data Claude. En macOS, ejecuta:
brew install curl jqDe forma equivalente, en Linux, ejecuta:
sudo apt-get install curl jqPor defecto, tras configurar Ruflo en tu proyecto local, Claude Code ya mostrará sus 118 habilidades. Compruébalo ejecutando el comando /skills: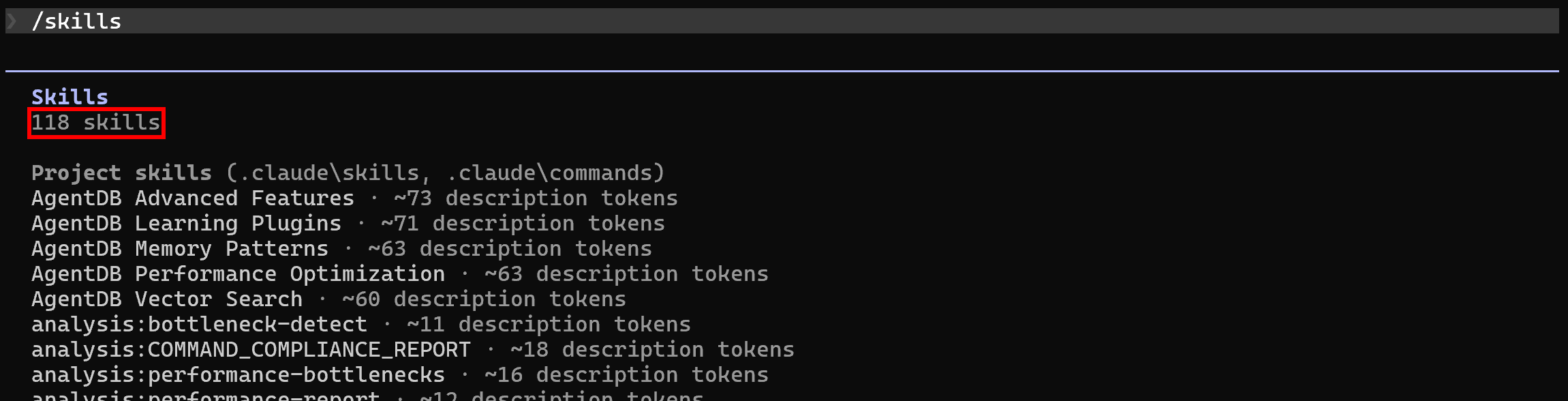
Paso n.º 1: Configura tu cuenta de Bright Data
Tal y como se explica en la documentación, las habilidades de Bright Data Claude requieren que se establezcan las dos claves secretas siguientes como variables de entorno globales:
BRIGHTDATA_API_KEY: Tu clave API de Bright Data.BRIGHTDATA_UNLOCKER_ZONE: El nombre de la zona de Web Unlocker configurada en tu cuenta.
Para obtener orientación, puedes consultar la página de documentación«Guía de inicio rápido para la API de Web Unlocker de Bright Data».También puedes seguir las instrucciones que se indican a continuación.
Si no tienes una cuenta de Bright Data, crea una. De lo contrario, simplemente inicia sesión. Accede al panel de control y ve a la página «Proxies y scraping». Echa un vistazo a la tabla «Mis zonas»: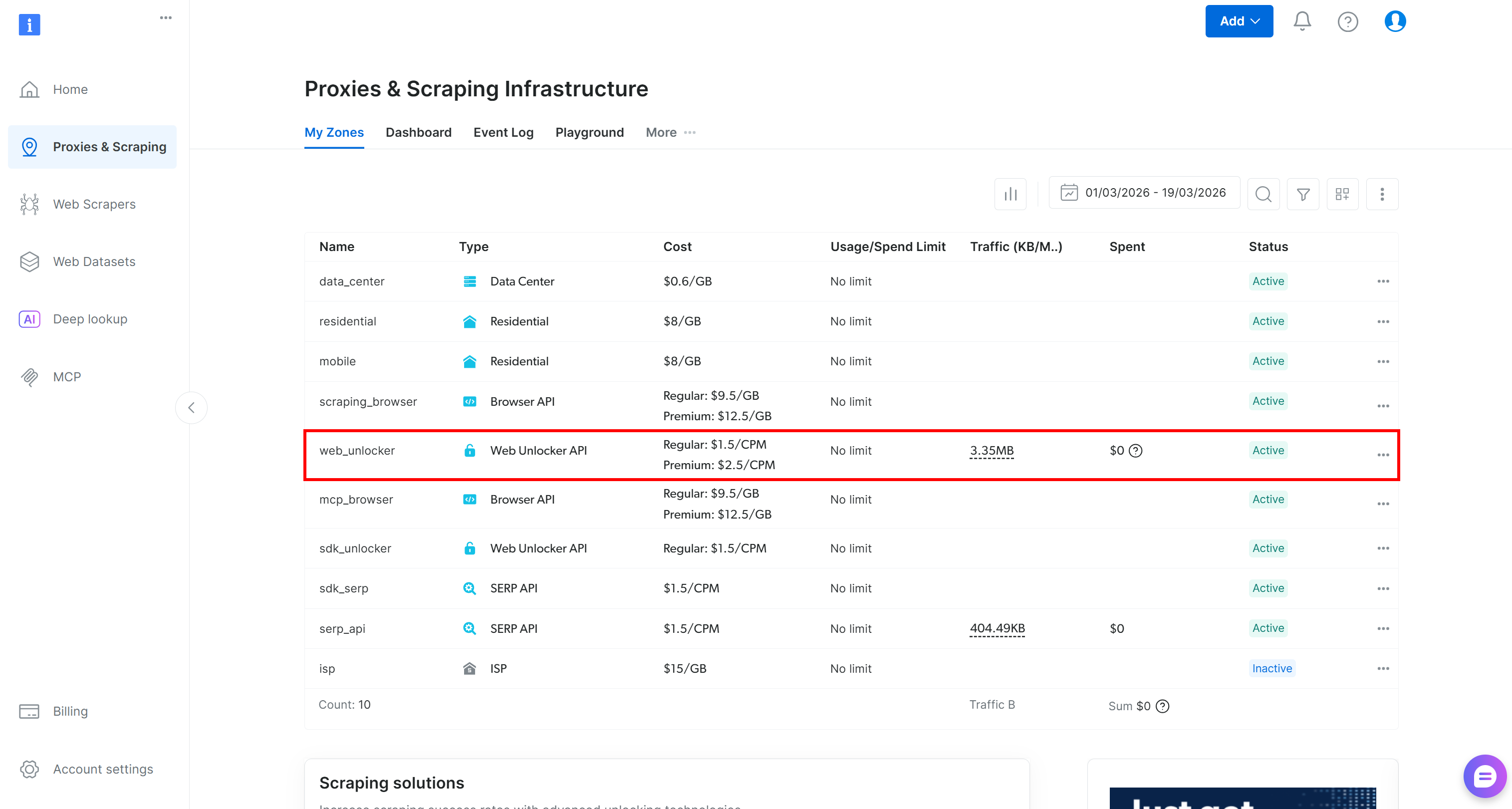
Si existe una zona de la API de Web Unlocker (por ejemplo, web_unlocker), puedes continuar con la definición de la clave API.
Si no la hay, crea una nueva. Para ello, desplázate hasta la tarjeta «API de desbloqueo», haz clic en «Crear zona» y sigue el asistente.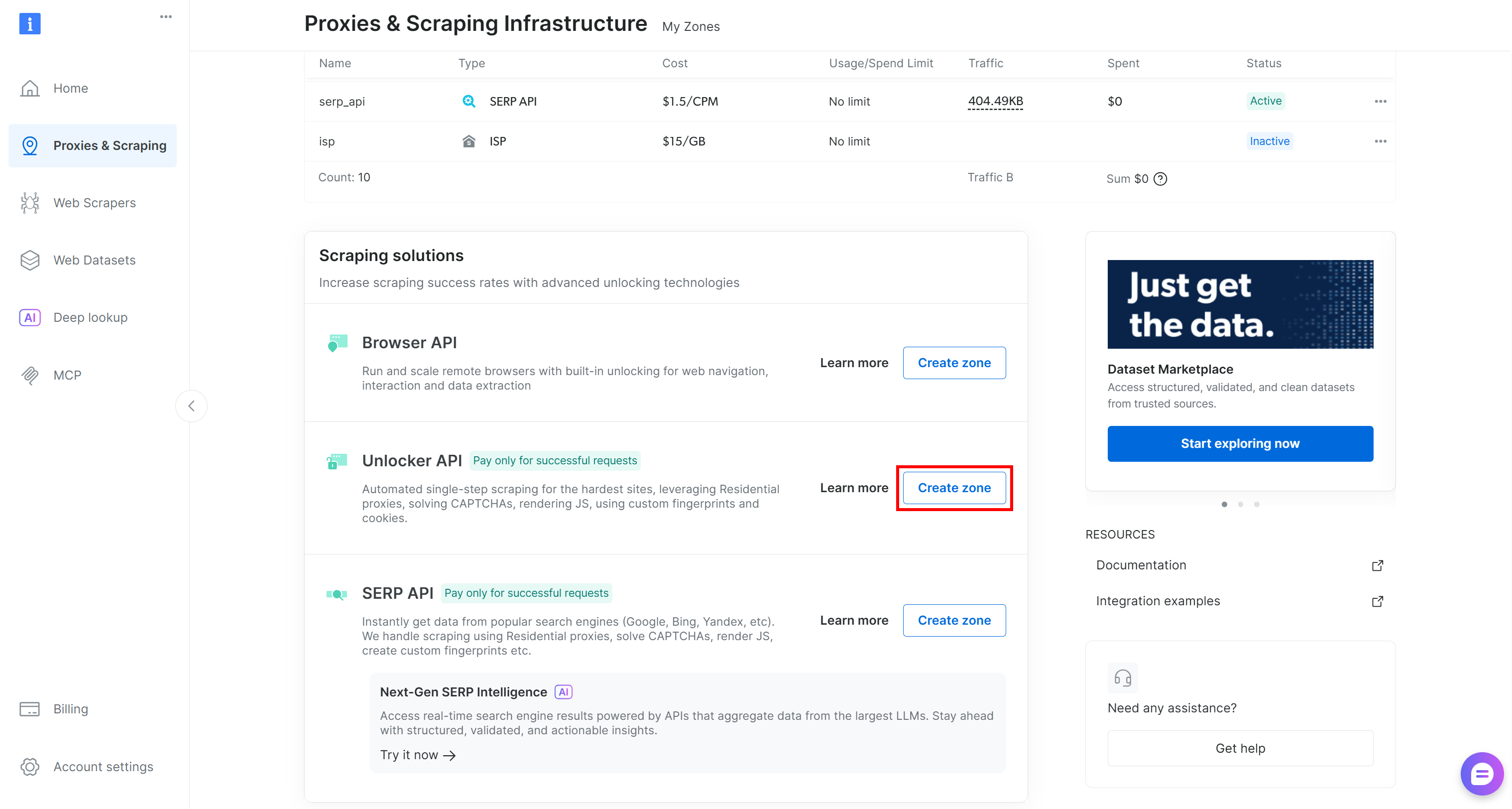
Sigue las instrucciones del asistente y asigna a tu zona un nombre significativo (por ejemplo, web_unlocker).
Por último, genera tu clave API de Bright Data. Ahora, con tu token API y el nombre de la zona, define dos variables de entorno globales de la siguiente manera:
export BRIGHTDATA_API_KEY="<TU_CLAVE_API_DE_BRIGHTDATA>"
export BRIGHTDATA_UNLOCKER_ZONE="<TU_ZONA_DE_UNLOCKER_DE_BRIGHTDATA>"¡Genial! Las habilidades de Bright Data en Claude ya pueden conectarse a tu cuenta y funcionar correctamente.
Paso n.º 2: Recupera las habilidades de Bright Data
Para añadir nuevas habilidades a tu configuración, copia sus carpetas en el directorio local .claude/skills.
Empieza clonando el repositorio de habilidades de Bright Data Claude en una carpeta de tu elección:
git clone https://github.com/brightdata/skillsLa estructura clonada debería tener este aspecto:
skills/
├── .claude-plugin
├── skills/
│ ├── bright-data-best-practices/
│ ├── bright-data-mcp/
│ ├── brightdata-cli/
│ ├── data-feeds/
│ ├── design-mirror/
│ ├── python-sdk-best-practices/
│ ├── scrape/
│ ├── scraper-builder/
│ └── search/
├── .gitignore
├── LICENSE
└── README.mdLas habilidades de Bright Data Claude son:
search: Realiza consultas en Google y devuelve resultados JSON estructurados que incluyen títulos, enlaces y descripciones.scrape: extrae cualquier página web como Markdown limpio, evitando automáticamente la detección de bots.data-feeds: extrae datos estructurados de más de 40 sitios web con sondeos y actualizaciones automatizados.bright-data-mcp: Coordina más de 60 herramientas de Bright Data MCP para búsqueda, scraping, extracción estructurada y automatización del navegador.scraper-builder: Crea rastreadores listos para producción, incluyendo análisis de sitios, selección de API, selectores, paginación e implementación.bright-data-best-practices: Referencia para Web Unlocker, SERP, Web Scraper y las API de navegador.python-sdk-best-practices: Guía para el paquete Pythonbrightdata-sdk: clientes asíncronos/sincrónicos, Scrapers, Conjuntos de datos, gestión de errores y patrones.brightdata-cli: Guía de terminal para la CLI de Bright Data: rastrear, buscar, extraer datos, gestionar zonas de Proxy y comprobar la cuenta.design-mirror: Replica los tokens y componentes del sistema de diseño para una implementación de la interfaz de usuario coherente y de alta calidad.
Copia las carpetas que hay dentro de skills/ (bright-data-best-practices/, bright-data-mcp/, etc.) en la carpeta local .claude/skills del directorio de tu proyecto. Hazlo manualmente o mediante este comando:
cp -r skills/skills/* <PATH_TO_YOUR_PROJECT>/.claude/skills/¡Perfecto! Las habilidades de Bright Data Claude se han añadido a tu proyecto.
Paso n.º 3: Comprueba las habilidades disponibles
Inicie de nuevo Claude Code en la carpeta de su proyecto y ejecute el comando /skills: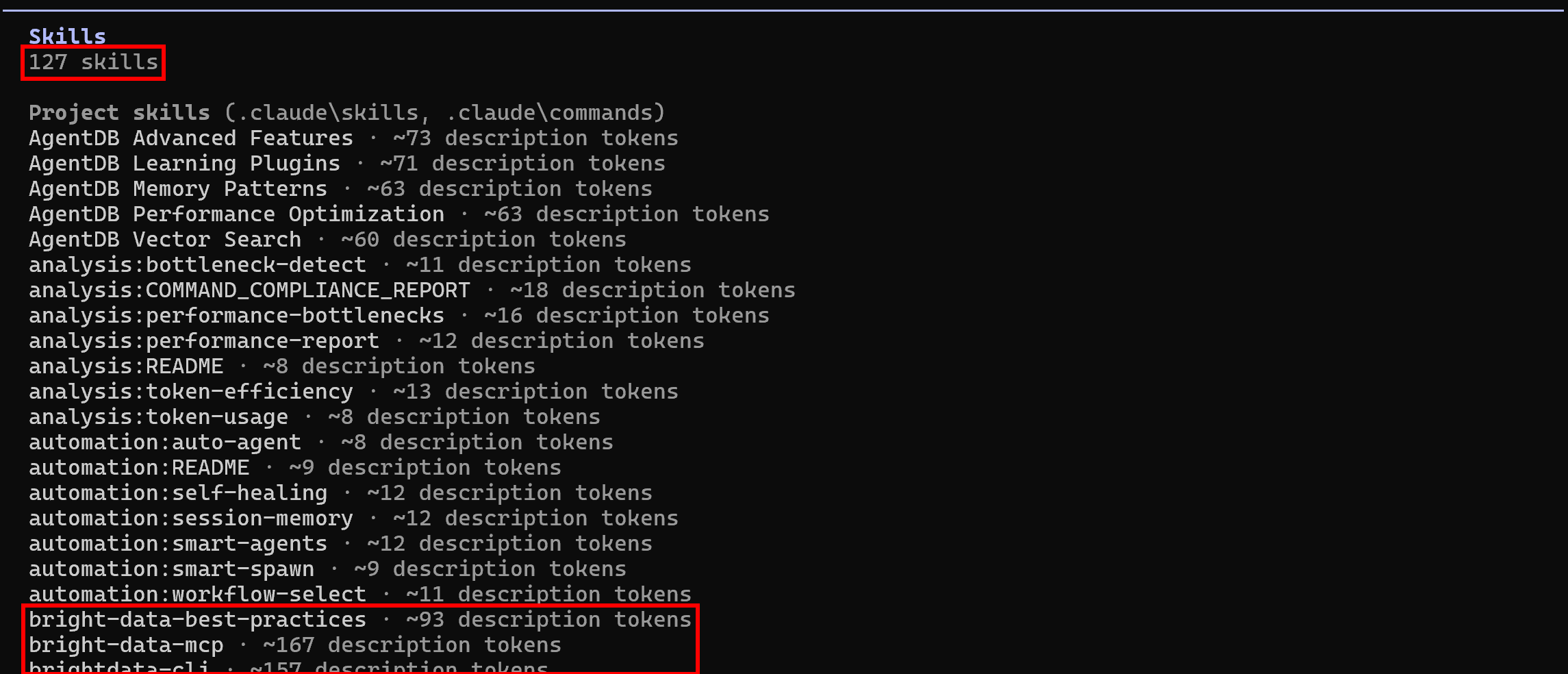
Esta vez, las habilidades disponibles deberían ser 127 (frente a las 118 iniciales), lo que indica que las habilidades de Bright Data se están leyendo correctamente. ¡Misión cumplida! Tu sistema de codificación agentica ya puede aprovechar las habilidades de Bright Data para la extracción programática de datos web, la exploración web y mucho más.
Ruflo + Bright Data: poniéndolo todo en práctica
Tu configuración de Claude Code tiene ahora acceso a más de 300 herramientas MCP o más de 125 habilidades. Estas permiten coordinar los esfuerzos de programación, al tiempo que permiten a los agentes buscar de forma autónoma en la web, extraer datos e interactuar con páginas web, todo ello sin bloqueos ni limitaciones de escalabilidad.
Esto abre muchas nuevas posibilidades, entre las que se incluyen:
- Recuperar resultados de búsqueda en tiempo real (SERP) e incrustar enlaces contextuales en
README.mdy otras páginas de documentación. - Descubrir tutoriales o documentación relevantes basados en tus tareas de programación actuales para mejorar tu código de forma eficiente.
- Extraer datos públicos recientes de sitios web y guardarlos localmente para simulación, análisis o procesamiento posterior.
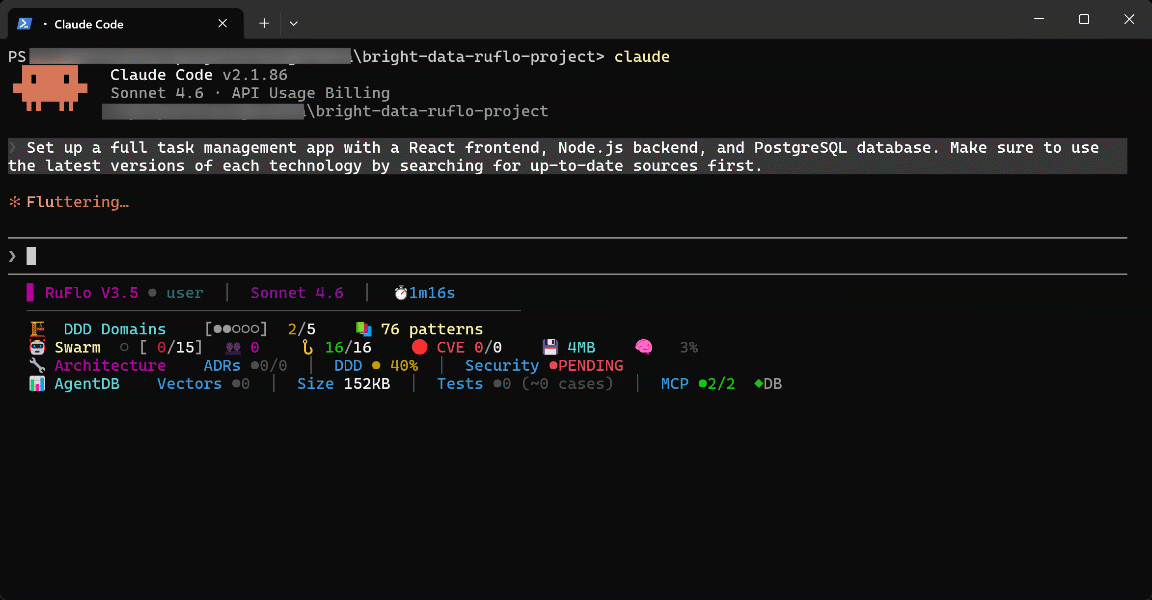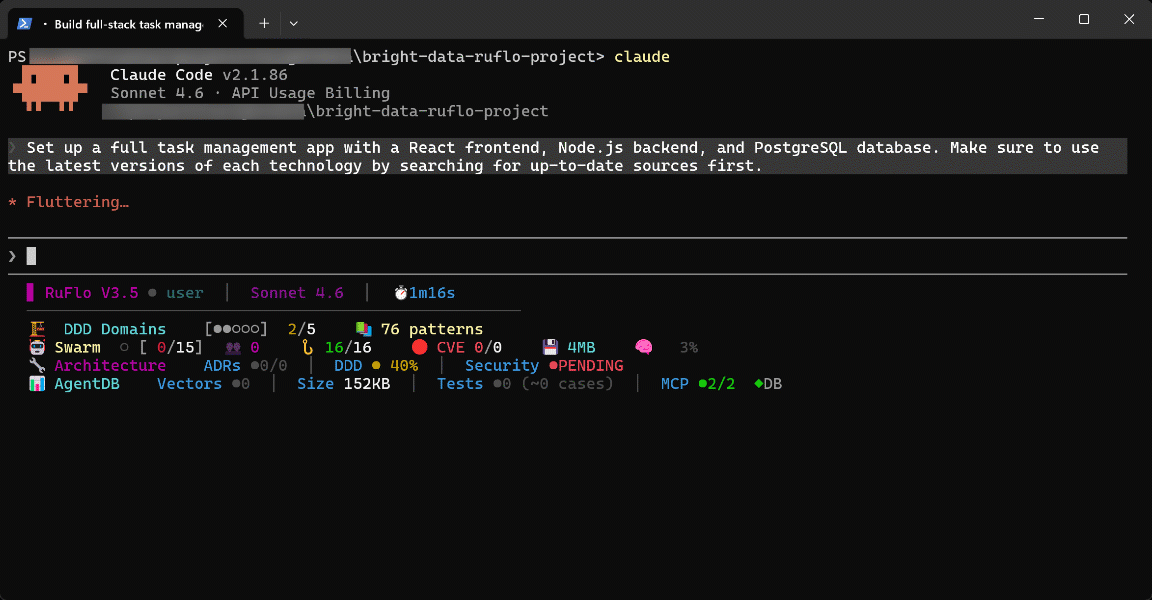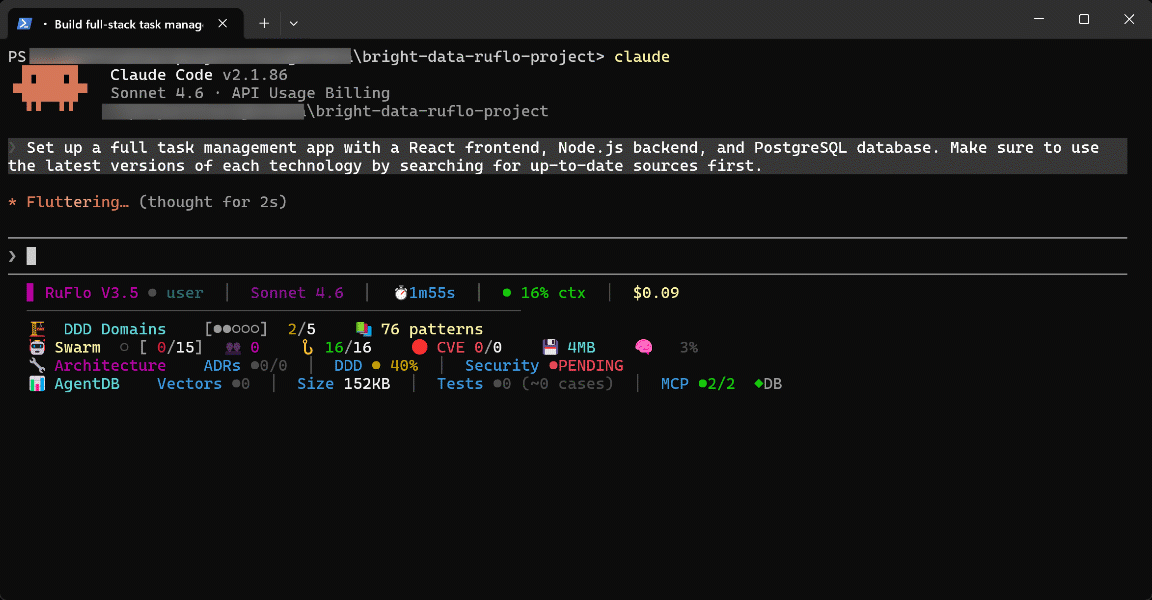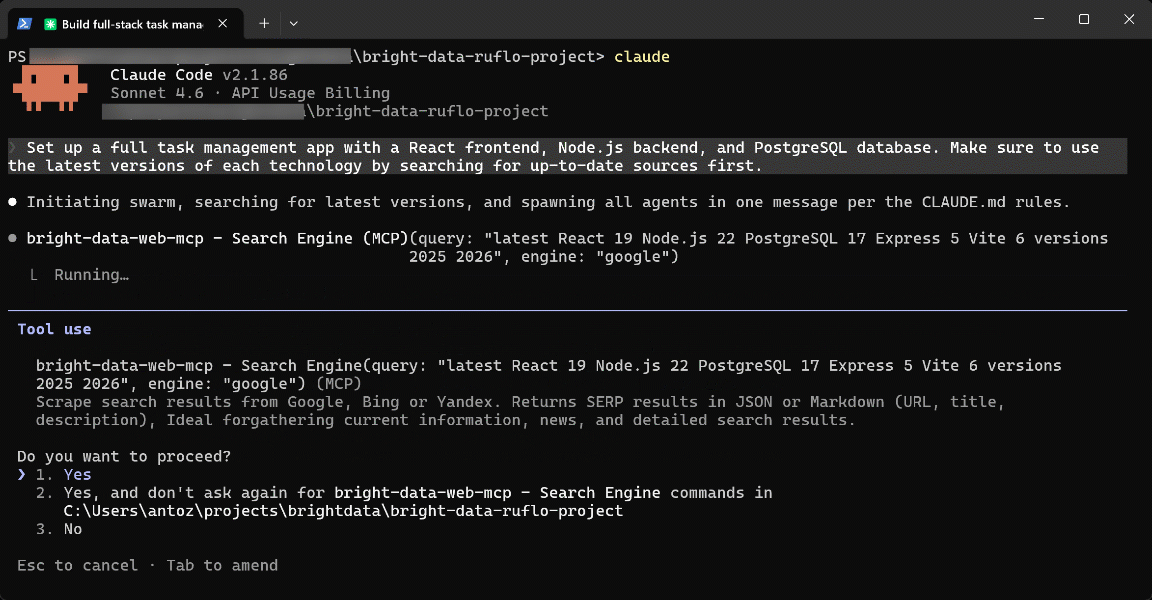
Estos ejemplos demuestran la ventaja sinérgica de utilizar Bright Data con Ruflo en tu configuración de Claude Code / OpenAI Codex. Esta integración amplía aún más el ya impresionante conjunto de funciones de Ruflo, al tiempo que da soporte a casos de uso de nivel empresarial gracias a la infraestructura de Bright Data.
Conclusión
En esta entrada del blog, has comprendido qué es Ruflo (antes conocido como Claude Flow) y cómo transforma la experiencia de los agentes en Claude Code y OpenAI Codex. Con una infraestructura de nivel empresarial de alrededor de 100 agentes trabajando en paralelo, Ruflo mejora drásticamente el rendimiento, incluyendo la velocidad, la eficiencia de los tokens y la calidad de la salida.
Sin embargo, estas herramientas carecen de una solución preparada para empresas en lo que respecta a la recuperación de datos web, la búsqueda en la web y la interacción programática con sitios web. Aquí es donde entra en juego Bright Data, gracias a un servidor Web MCP dedicado y a un conjunto oficial de Claude Skills. Estos facilitan la conexión con el conjunto completo de herramientas, servicios e infraestructura de Bright Data, diseñados para la IA.
Aquí has aprendido a configurar una potente combinación de Ruflo y Bright Data en Claude Code para maximizar la eficiencia y la eficacia de la asistencia en la codificación.
¡Crea hoy mismo una cuenta gratuita de Bright Data y empieza a explorar soluciones de datos web preparadas para la IA!





