

Bright Data es la plataforma de scraping web más completa del mercado. Combina la mayor red de proxies comerciales con APIs de scraper estructuradas y conjuntos de datos listos para usar. También incluye un Navegador de scraping, APIs SERP e integración con agentes de IA. Zyte es la alternativa nativa de Scrapy, construida en torno a una única API de scraping gestionada.
Zyte (antes Scrapinghub) creó Scrapy, el framework Python de código abierto. Ahora vende tres productos: Zyte API, Zyte Data y Scrapy Cloud. Probamos ambas plataformas y revisamos datos de benchmarks independientes. Las comparamos en tasa de éxito, precios, profundidad de producto y usabilidad real. Bright Data gana en todos los aspectos excepto en un caso de precios muy concreto.
TL;DR: Bright Data vs. Zyte
Conclusión: Bright Data es la mejor opción para la mayoría de los equipos. Obtiene mejores resultados en sitios protegidos, ofrece muchos más productos y tiene precios predecibles. Zyte es adecuado para equipos nativos de Scrapy que hacen scraping en sitios simples y sin protección. Las cifras del benchmark provienen de la prueba independiente de Scrape.do de 2026.
| Característica | Bright Data | Zyte |
|---|---|---|
| Tasa de éxito | 98,87% | 91,43% |
| Alcance del producto | APIs de Web Scraper, Web Unlocker, Navegador de scraping, API SERP, proxies, conjuntos de datos, MCP | Zyte API, Zyte Data, Scrapy Cloud |
| Acceso a proxies | Directo: residencial, centro de datos, ISP en 195 países | Ninguno: gestionado internamente por Zyte API |
| Conjuntos de datos prediseñados | Sí, más de 100 dominios | No |
| Integración con agentes de IA | Servidor MCP | Ninguna |
| Modelo de precios | Fijo: $1,5/1K registros | Por niveles según dificultad del sitio: $0,06 a $16,08/1K |
| Plan gratuito | 5.000 registros/mes, sin tarjeta | $5 de crédito, tarjeta requerida |
| Ideal para | Fiabilidad a escala, conjuntos de datos, control de proxies, agentes de IA | Equipos nativos de Scrapy en sitios simples |
Tasa de éxito: los datos del benchmark
La fiabilidad es lo primero que importa en el scraping. El benchmark de Scrape.do de 2026 probó ambas plataformas contra siete objetivos difíciles, entre ellos Amazon, Indeed, Zillow, Google y X. Bright Data obtuvo un 98,87%, la puntuación más alta de todos los proveedores evaluados. Zyte obtuvo un 91,43%.
Esa diferencia de 7 puntos se amplifica a escala. En 100.000 solicitudes, supone la diferencia entre 1.130 y 8.570 fallos. Cada fallo implica cómputo desperdiciado y un nuevo rastreo. En sitios protegidos, Bright Data es simplemente más fiable.
Los tiempos de respuesta fueron similares en la prueba, alrededor de 10 a 11 segundos cada uno. La velocidad no es el factor diferenciador aquí. La fiabilidad en objetivos difíciles sí lo es.
Precios: tarifa plana frente a niveles por dificultad
Aquí es donde las plataformas difieren más en filosofía. Bright Data cobra una tarifa plana única. Zyte cobra según la dificultad del sitio objetivo.
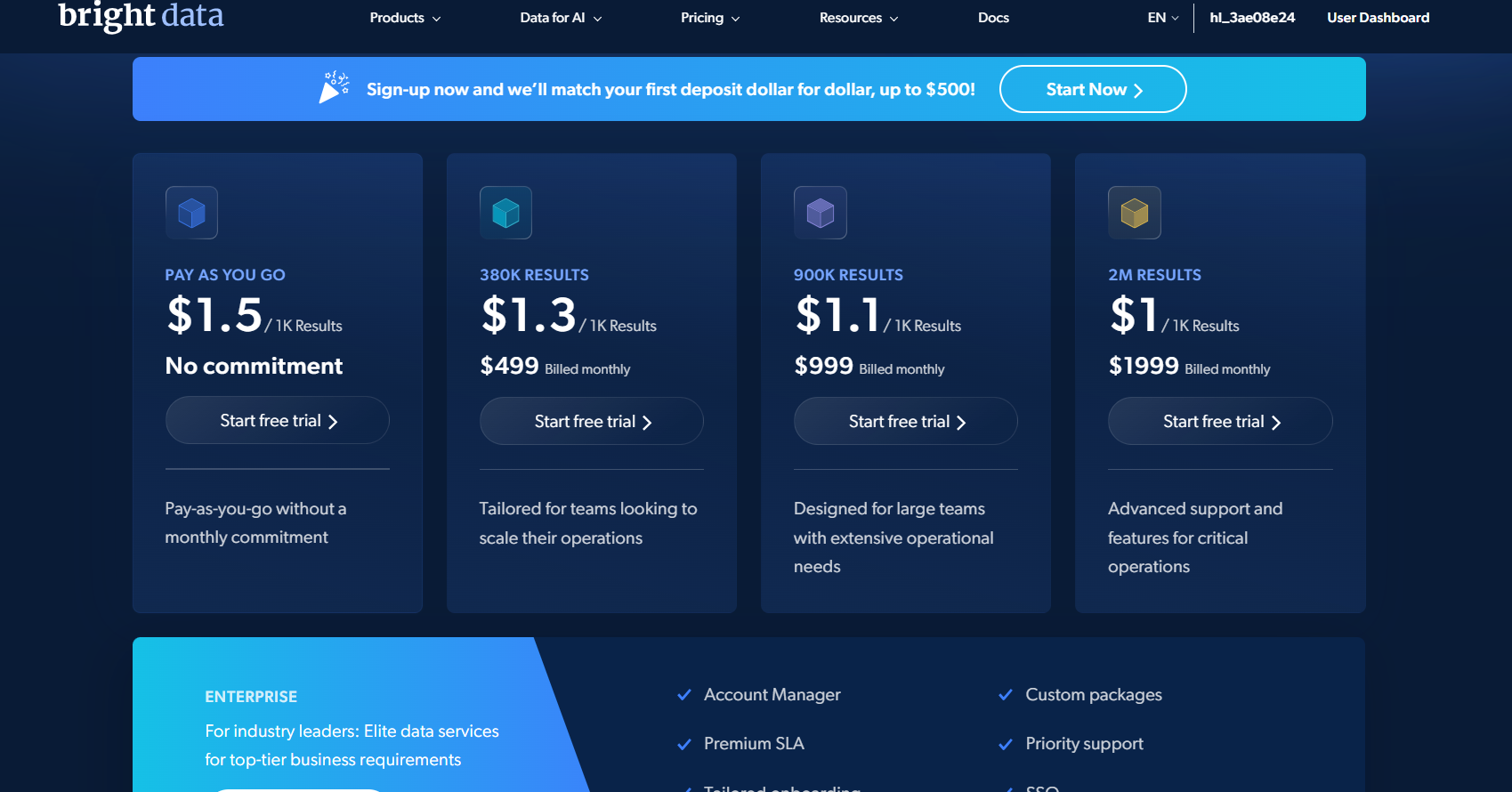
Bright Data: precios de tarifa plana
La API de Web Scraper de Bright Data cuesta $1,5 por cada 1.000 registros en pago por uso. Solo pagas por los resultados exitosos. El plan gratuito incluye 5.000 registros al mes sin tarjeta de crédito. El plan Scale cuesta $499 al mes por 384.000 registros.
Zyte: cinco niveles de dificultad
Zyte clasifica cada sitio en cinco niveles de dificultad. Las solicitudes HTTP van de $0,06 a $1,27 por cada 1.000. Las solicitudes con renderizado de navegador van de $0,48 a $16,08 por cada 1.000. La tarifa exacta depende del nivel y del compromiso mensual.
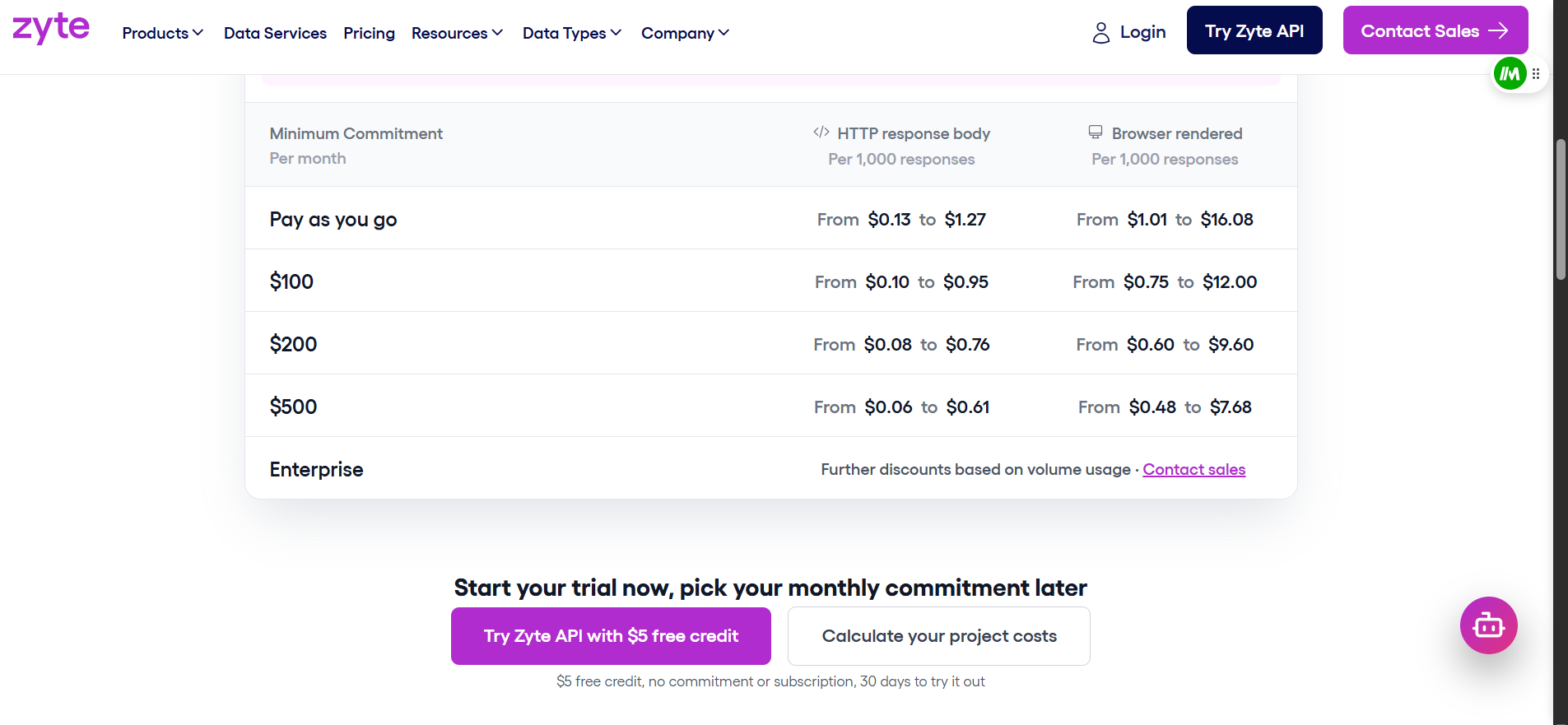
El cálculo de precios en la práctica
Tomemos 100.000 solicitudes contra un sitio difícil con renderizado de navegador. Bright Data cuesta $150 en pago por uso. Zyte cuesta $402 en un nivel intermedio, y hasta $1.608 en su nivel más difícil.
Ahora tomemos 100.000 solicitudes contra un sitio simple solo con HTTP. Zyte cuesta tan solo $13. Bright Data sigue costando $150. Zyte gana en sitios triviales, pero estos raramente necesitan una API de scraping de pago.
El problema más profundo es la previsibilidad. A menudo no sabes el nivel de un sitio antes de hacer scraping. Presupuestar se complica cuando los objetivos abarcan distintos niveles. La tarifa plana de Bright Data elimina esa variable por completo.
Profundidad de producto: un stack completo frente a una sola API
Esta es la mayor ventaja estructural de Bright Data. Zyte ofrece tres productos. Bright Data ofrece un stack completo de infraestructura de datos. Su red abarca 400M+ IPs residenciales, 1,300,000+ IPs de centro de datos y 1,300,000+ IPs ISP en 195 países.
Lo que Bright Data tiene y Zyte no
1. Conjuntos de datos prediseñados. Bright Data mantiene conjuntos de datos listos para usar en más de 100 dominios, incluyendo LinkedIn, Amazon, Zillow y Google Maps. Consultas un conjunto de datos con filtros y obtienes registros estructurados. Sin scraper, sin rastreo, sin parseo.
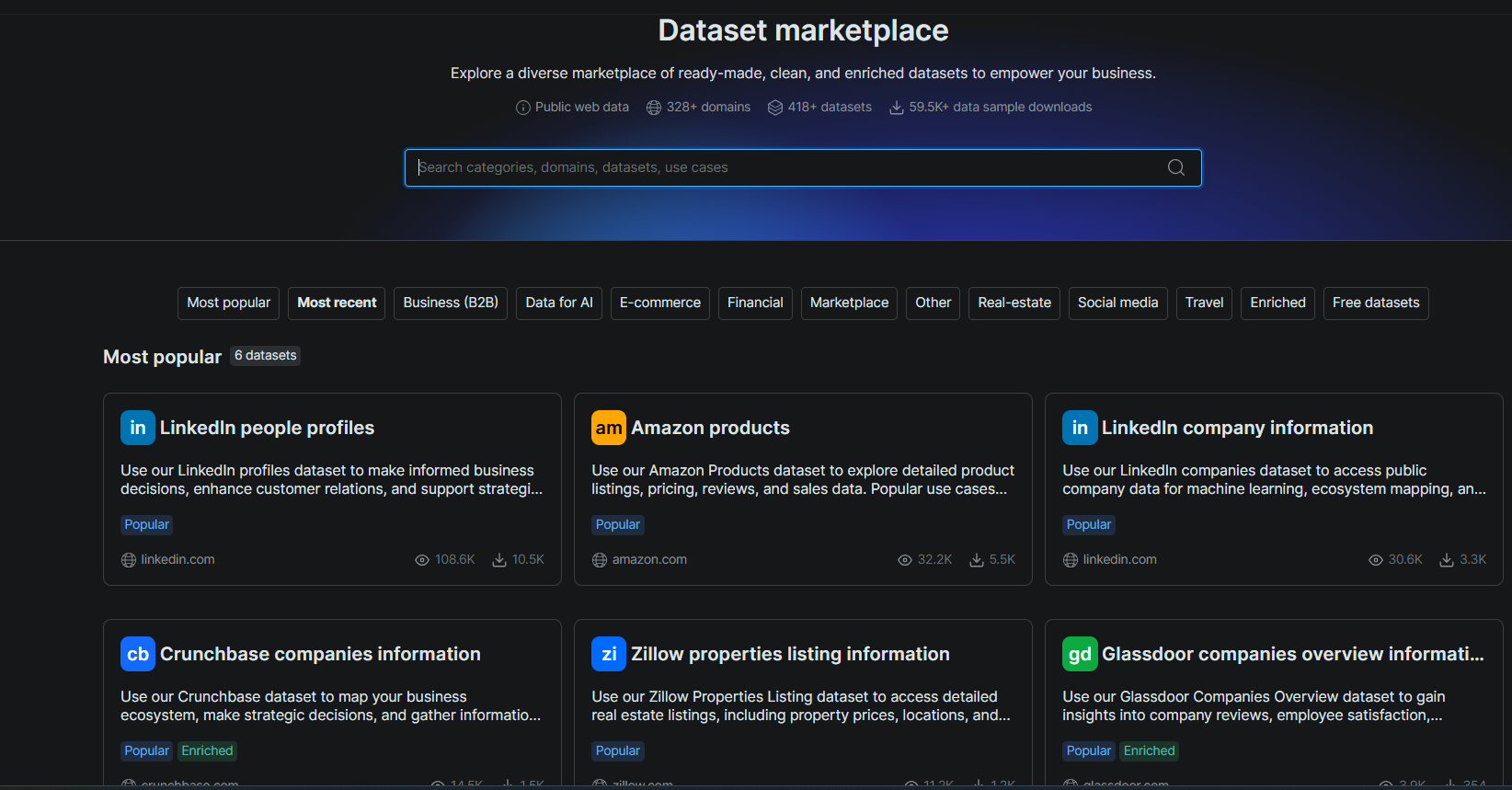
En nuestras pruebas, la API de filtro de conjuntos de datos devolvió 100 empresas de LinkedIn en 46,5 segundos. Cada registro incluía datos firmográficos, historial de financiación y una URL de Crunchbase. Zyte no tiene equivalente. La misma tarea en Zyte implica construir y mantener un scraper personalizado.

2. Acceso directo a proxies. Bright Data te permite usar su red de proxies directamente. Controlas el targeting por país, ciudad y ASN. Zyte gestiona los proxies internamente, por lo que no tienes control sobre el tipo, la ubicación o la rotación.
3. Navegador de scraping. El Navegador de scraping conecta tus scripts existentes de Playwright, Puppeteer o Selenium a una infraestructura gestionada. Gestiona la rotación de proxies, la resolución de CAPTCHA y las huellas digitales. Zyte requiere reescribir esa lógica como solicitudes de API.
4. API SERP. La API SERP devuelve resultados de búsqueda estructurados de Google, Bing y otros. Zyte no tiene ningún producto de búsqueda dedicado.
5. Integración MCP. El servidor MCP proporciona a los agentes de IA herramientas nativas de datos web. Los agentes creados con LangChain, CrewAI o LlamaIndex pueden llamarlo directamente. Zyte no tiene integración MCP.
Lo que Zyte tiene y Bright Data no
1. Scrapy Cloud. Zyte creó Scrapy y gestiona el mejor host administrado para spiders de Scrapy. Maneja el despliegue, la programación y el monitoreo desde $9 por unidad al mes. Los equipos con uso intensivo de Scrapy encuentran aquí su hogar natural.
2. Extracción sin código con IA. La IA de Zyte devuelve datos estructurados para tipos de página compatibles sin selectores. Funciona bien para productos, artículos y páginas de empleo. El Scraper Studio de Bright Data cubre la construcción sin código, pero el enfoque de configuración cero de Zyte es más fluido para esos esquemas.
3. Zyte Data. Zyte Data es un servicio de extracción totalmente gestionado desde $500 al mes. Su equipo construye y mantiene el pipeline por ti. Los conjuntos de datos de Bright Data son de autoservicio en lugar de completamente gestionados.
Práctica: API de Web Scraper de Bright Data
Bright Data devuelve JSON estructurado directamente. Envías una URL y obtienes campos parseados, sin necesidad de gestionar HTML:
import requests
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": "gd_l7q7dkf244hwjntr0", "format": "json"},
headers={"Authorization": "Bearer YOUR_API_TOKEN"},
json=[{"url": "https://www.amazon.com/dp/B0D1XD1ZV3"}],
)
product = response.json()
Esto devolvió el título del producto, precio, valoración, número de reseñas y disponibilidad. El resultado fue JSON estructurado limpio, listo para usar.
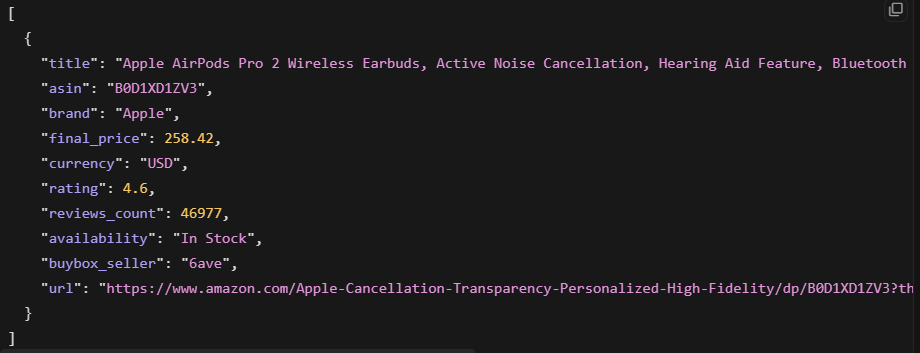
Para sitios sin un scraper prediseñado, el Web Unlocker devuelve HTML desbloqueado para parsear tú mismo:
response = requests.post(
"https://api.brightdata.com/request",
headers={"Authorization": "Bearer YOUR_API_TOKEN"},
json={"zone": "YOUR_ZONE_NAME", "url": "https://example.com/page", "format": "json"},
)
html = response.json().get("body", "")
Web Unlocker gestiona la selección de proxies, la resolución de CAPTCHA y los reintentos. Mantienes el control sobre el tipo de proxy y el targeting geográfico.
Práctica: cómo funciona la API de Zyte
La API de Zyte devuelve HTML sin procesar o renderizado por navegador, y tú gestionas el parseo:
import requests
response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={"url": "https://books.toscrape.com/", "browserHtml": True},
)
html = response.json().get("browserHtml")
La extracción con IA de Zyte añade salida estructurada para esquemas compatibles. Estableces un indicador y omites los selectores:
response = requests.post(
"https://api.zyte.com/v1/extract",
auth=("YOUR_ZYTE_API_KEY", ""),
json={"url": "https://books.toscrape.com/", "product": True},
)
product = response.json().get("product")
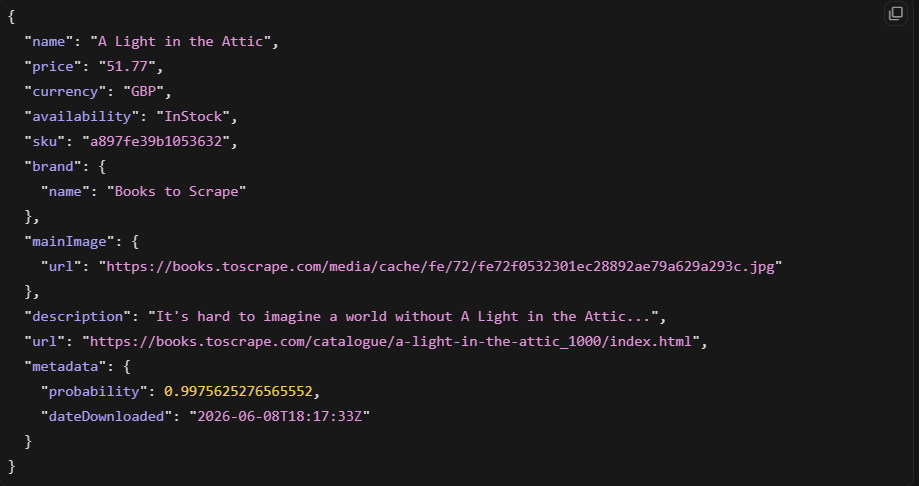
Esto devolvió un objeto de producto limpio en nuestra prueba. La extracción con IA es genuinamente útil para los tipos de página compatibles. El inconveniente es que solo funciona donde Zyte tiene modelos entrenados.
Cuándo elegir cada uno
- Elige Bright Data para altas tasas de éxito, conjuntos de datos prediseñados, control de proxies, agentes de IA y precios predecibles
- Elige Zyte si tu equipo está construido sobre Scrapy y hace scraping principalmente en sitios simples y sin protección
- Usa ambos si ejecutas spiders de Scrapy en Scrapy Cloud pero necesitas Bright Data para objetivos difíciles
Conclusión
Zyte es una plataforma capaz para equipos nativos de Scrapy en sitios simples. La diferencia aparece cuando el trabajo se vuelve más difícil. Bright Data obtiene mejores resultados en sitios protegidos, ofrece muchos más productos y tiene precios sin incertidumbre.
Para datos fiables a escala, Bright Data es la base más sólida y amplia. Cuenta con la certificación ISO 27001 y cumplimiento GDPR y CCPA. Consulta el Centro de confianza para más detalles. También puedes leer nuestra comparativa Bright Data vs. Apollo.
Inicia tu prueba gratuita hoy y prueba Bright Data en tus objetivos más difíciles.
Preguntas frecuentes
¿Es mejor Bright Data o Zyte para el scraping web?
Bright Data es mejor para la mayoría de los equipos. Obtuvo un 98,87% frente al 91,43% de Zyte en el benchmark de Scrape.do de 2026. También ofrece muchos más productos. Zyte es adecuado para equipos nativos de Scrapy que hacen scraping en sitios simples.
¿Cómo se comparan los precios de Bright Data y Zyte?
Bright Data cobra una tarifa plana de $1,5 por cada 1.000 registros, con 5.000 gratuitos al mes. Zyte cobra según la dificultad del sitio, de $0,06 a $16,08 por cada 1.000 solicitudes. Los precios de Bright Data son más predecibles.
¿Tiene Zyte conjuntos de datos prediseñados como Bright Data?
No. Bright Data ofrece conjuntos de datos listos para usar en más de 100 dominios, incluyendo LinkedIn y Amazon. Zyte no tiene equivalente. Tendrías que construir y mantener esos scrapers tú mismo.
¿Puedo usar mi código existente de Scrapy o Playwright?
Zyte ejecuta Scrapy Cloud, el mejor host gestionado para spiders de Scrapy. El Navegador de scraping de Bright Data conecta scripts existentes de Playwright, Puppeteer y Selenium a su infraestructura.
¿Cuál debo elegir, Bright Data o Zyte?
Elige Bright Data para fiabilidad a escala, conjuntos de datos, control de proxies y agentes de IA. Elige Zyte si tu equipo es nativo de Scrapy y hace scraping principalmente en sitios simples y sin protección.





