
En esta guía aprenderá:
- Qué es AWS Step Functions y por qué es importante para la automatización de flujos de trabajo.
- Por qué los flujos de trabajo de Scraping web son adecuados para este servicio de AWS.
- Cómo Bright Data ayuda a superar los retos inherentes al Scraping web.
- Cómo integrar Bright Data en AWS Step Functions, ya sea mediante llamadas directas a la API o a través de una función Lambda dedicada.
¡Empecemos!
Introducción a AWS Step Functions
Antes de mostrar cómo utilizar AWS Step Functions para organizar un flujo de trabajo de Scraping web, veamos más detalles sobre esta solución.
¿Qué es AWS Step Functions?
AWS Step Functions es un servicio totalmente gestionado que le permite coordinar y automatizar flujos de trabajo complejos en los servicios de AWS. Se trata de un servicio de orquestación visual que se utiliza para crear aplicaciones distribuidas y automatizar procesos conectando múltiples servicios de AWS en flujos de trabajo sin servidor.
En esencia, Step Functions se basa en máquinas de estado, que son flujos de trabajo compuestos por una serie de pasos, denominados estados. Cada estado realiza una tarea, como invocar un servicio de AWS o ejecutar código personalizado.
Este enfoque simplifica la orquestación, la gestión de errores y la supervisión, lo que le permite centrarse en la lógica de la aplicación en lugar de en la infraestructura. En detalle, las principales ventajas que aportan son:
- Orquestación simplificada: gestione procesos de varios pasos y dependencias sin escribir código complejo.
- Gestión de errores integrada: los reintentos y los bloques de captura ayudan a que los flujos de trabajo se recuperen automáticamente de los fallos.
- Ejecución paralela y dinámica: ejecute tareas simultáneamente o itere sobre Conjuntos de datos para un procesamiento más rápido.
- Soporte humano en el bucle: incluya pasos de aprobación o devoluciones de llamada dentro de los flujos de trabajo.
- Integración de servicios: conéctese a la perfección con AWS Lambda, Glue, SQS, SNS, SageMaker y mucho más.
Obtenga más información en la documentación oficial.
Comprender cómo funciona AWS Step Functions
Para comprender realmente AWS Step Functions, es útil centrarse en sus conceptos básicos, que constituyen la base de cualquier flujo de trabajo:
- Máquina de estados: la columna vertebral de Step Functions. Una máquina de estados representa su flujo de trabajo, almacenando y actualizando su estado a medida que avanzan las tareas. Se define utilizando JSON y Amazon States Language. Puede elegir flujos de trabajo estándar para procesos de larga duración o que requieren intervención humana, o flujos de trabajo exprés para tareas cortas y de gran volumen.
- Estados: cada paso de un flujo de trabajo. Los estados pueden realizar tareas (Task), tomar decisiones (Choice), pausar la ejecución (Wait), gestionar fallos o éxitos (Fail/Succeed), ramificar la ejecución (Parallel) o repetir entradas (Map). La combinación de estados define la lógica de su flujo de trabajo.
- Estados de tareas: unidades de trabajo dentro de un flujo de trabajo. Las tareas de servicio automatizan las interacciones con servicios de AWS como Lambda o Glue. Por su parte, las tareas de actividad se conectan con código externo o personas, lo que resulta útil para pasos asíncronos o aprobaciones.
- Ejecución y supervisión: Step Functions registra las entradas, salidas, reintentos y errores de cada paso, lo que le permite rastrear problemas y verificar el comportamiento del flujo de trabajo.
Orquestación del flujo de trabajo de Scraping web sin servidor
AWS Step Functions proporciona una forma eficaz de orquestar flujos de trabajo de Scraping web sin servidor de forma escalable y fiable. En lugar de crear un script de Scraping web monolítico, puede dividir el proceso en pasos más pequeños, impulsados por eventos, y coordinarlos a través de una máquina de estados.
Por ejemplo, un flujo de trabajo podría comenzar activando una tarea de recopilación de datos, continuar con el parseo y la validación de los datos y, a continuación, almacenar los resultados en servicios como Amazon S3 o una base de datos. Step Functions puede coordinar estos pasos mientras se integra con otros servicios de AWS como AWS Lambda, AWS Glue o Amazon SQS.
Este enfoque aporta varias ventajas: mayor escalabilidad, reintentos y gestión de errores integrados, procesamiento paralelo de tareas de scraping y supervisión clara de cada ejecución del flujo de trabajo.
Sin embargo, el Scraping web a gran escala también presenta retos. La razón es que muchos sitios web implementan protecciones antibots y mecanismos antiscraping que pueden bloquear las solicitudes automatizadas. Algunos ejemplos son los limitadores de velocidad, las huellas digitales, los CAPTCHA, los retos de JavaScript y otros.
Recuperación impecable de datos web en AWS Step Functions
Para los equipos que organizan flujos de trabajo de Scraping web con AWS Step Functions, Bright Data ofrece una solución integral para respaldar la recuperación exitosa de datos web a gran escala.
Bright Data incluye varios servicios de scraping especializados que se integran a la perfección con Step Functions:
- API SERP: recopila resultados de motores de búsqueda a gran escala para obtener información sobre SEO o análisis de mercado.
- Web Unlocker: acceda a cualquier página web eludiendo las defensas antibots, como CAPTCHAs, obstáculos de JavaScript y restricciones de IP.
- API de Scraping web: recopile información estructurada de plataformas de comercio electrónico, redes sociales y otras fuentes web con una configuración mínima.
- API de rastreo: automatice la extracción completa del contenido de cualquier dominio a Markdown, texto sin formato, HTML o JSON.
Estas soluciones aprovechan una red de Proxies que supera los 150 millones de IP en más de 195 países, lo que ofrece una concurrencia ilimitada para casos de uso listos para la producción. Además, todos los servicios incorporan el kit de herramientas antibots de Bright Data para evitar CAPTCHAs y otras restricciones de acceso.
La integración de la orquestación de Step Functions con las herramientas de datos web de Bright Data permite crear canalizaciones totalmente automatizadas que gestionan la extracción, la transformación y el almacenamiento. Esto se traduce en un funcionamiento continuo incluso en escenarios complejos, a gran escala y preparados para empresas.
Cómo integrar las soluciones de Scraping web de Bright Data en AWS Step Functions
Para integrar Bright Data en AWS Step Functions para la recuperación automatizada de datos web, hay dos enfoques posibles:
- Utilizar el nodo «HTTP Endpoint – Call HTTPS APIs»: Conéctese directamente a las API de Bright Data (API Web Unlocker, API Scraping web, API SERP, API Crawl, etc.).
- Utilizar el nodo «AWS Lambda – Invoke»: crear código personalizado en una función Lambda (en Python u otro lenguaje compatible) para integrarse con los productos de Bright Data, recuperar datos y, opcionalmente, aplicar una lógica específica (por ejemplo, acceder solo a campos específicos, devolver datos en una estructura específica o aplicar una lógica de Parseo personalizada).
En las secciones siguientes, le guiaremos a través de ambos enfoques. Pero primero, exploremos las ventajas y desventajas de los dos métodos.
Punto final HTTP: nodo Call HTTPS APIs: ventajas y desventajas
👍 Ventajas:
- Rápido de configurar.
- Más fácil de gestionar y mantener.
- Funciona bien para extraer datos de páginas web individuales.
👎 Contras:
- Flexibilidad limitada para el procesamiento de datos personalizados.
- Más difícil de manejar flujos de trabajo complejos que requieren múltiples llamadas diferentes a la API de extracción de Bright Data.
AWS Lambda – Invoke Node: ventajas y desventajas
👍 Ventajas:
- Control total sobre el procesamiento y la transformación de datos web.
- Permite implementar lógica personalizada (por ejemplo, reintentos, flujos condicionales, etc.).
- Posibilidad de integrarse con múltiples servicios de Bright Data en una sola función.
👎 Desventajas:
- Requiere programación en Python, Node.js u otro lenguaje compatible.
- Añade un servicio adicional que hay que supervisar y mantener.
Requisitos previos
Para seguir las siguientes secciones guiadas, necesitas:
- Una cuenta AWS activa (incluso una prueba gratuita sirve).
- Una cuenta de Bright Data con una clave API lista.
- Conocimientos básicos sobre llamadas HTTP RESTful o habilidades básicas de programación en Python para la integración de Lambda.
Configure su cuenta de Bright Data
Si aún no tiene una cuenta de Bright Data, cree una primero. De lo contrario, inicie sesión y siga las instrucciones para configurar una clave API. Necesitará esta clave para autenticar sus llamadas HTTP (tanto si llama a Bright Data directamente desde llamadas HTTP como en una función Lambda).
Asegúrate de tener configurada una API de Bright Data Web Unlocker (y una API SERP si piensas seguir la sección del tutorial de Lambda):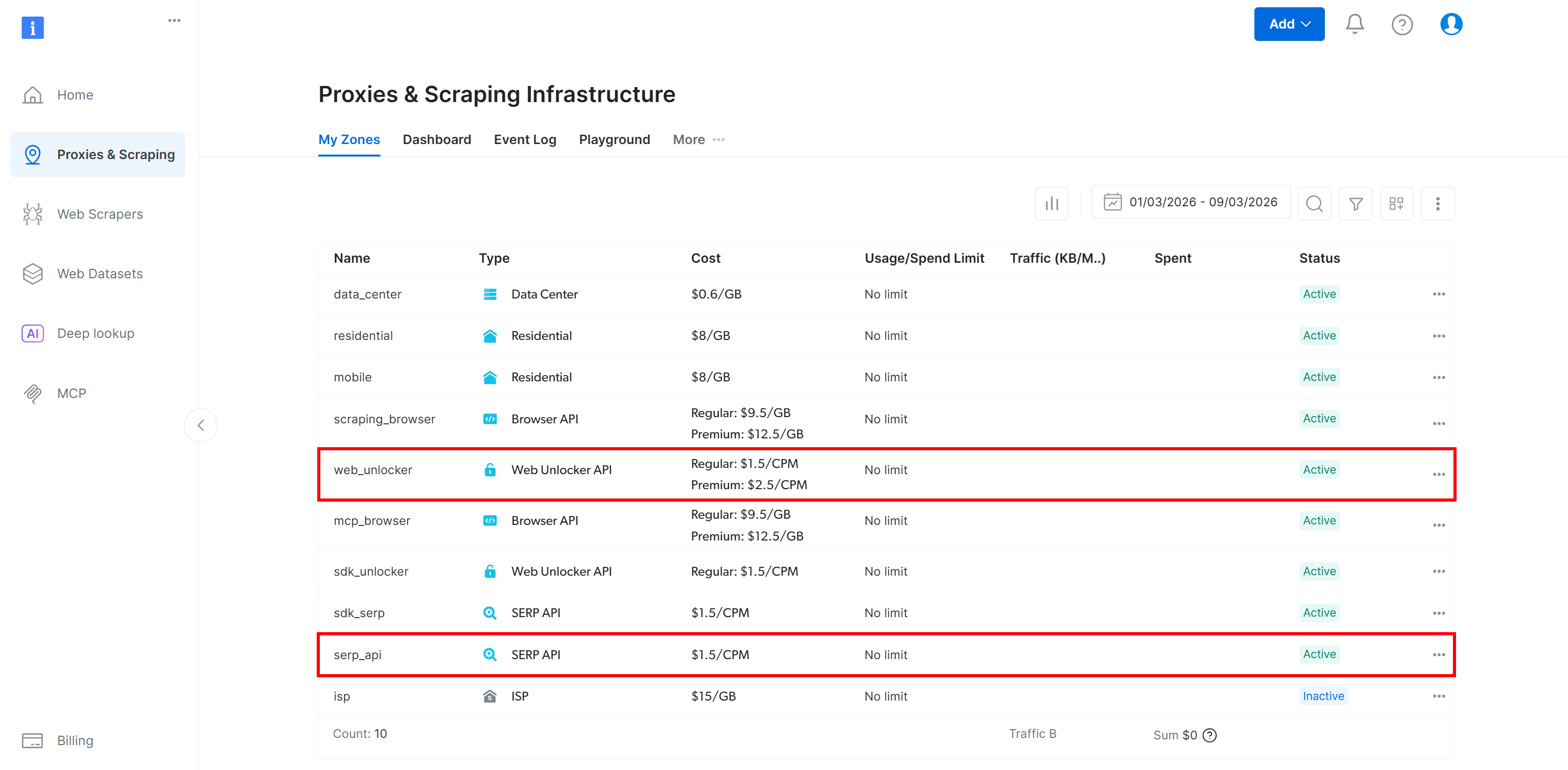
Para obtener más información, consulta las siguientes páginas de documentación:
Configure su flujo de trabajo de AWS Step Functions
Comience iniciando sesión en su consola de AWS y buscando el servicio «Step Functions». Abra la página del servicio: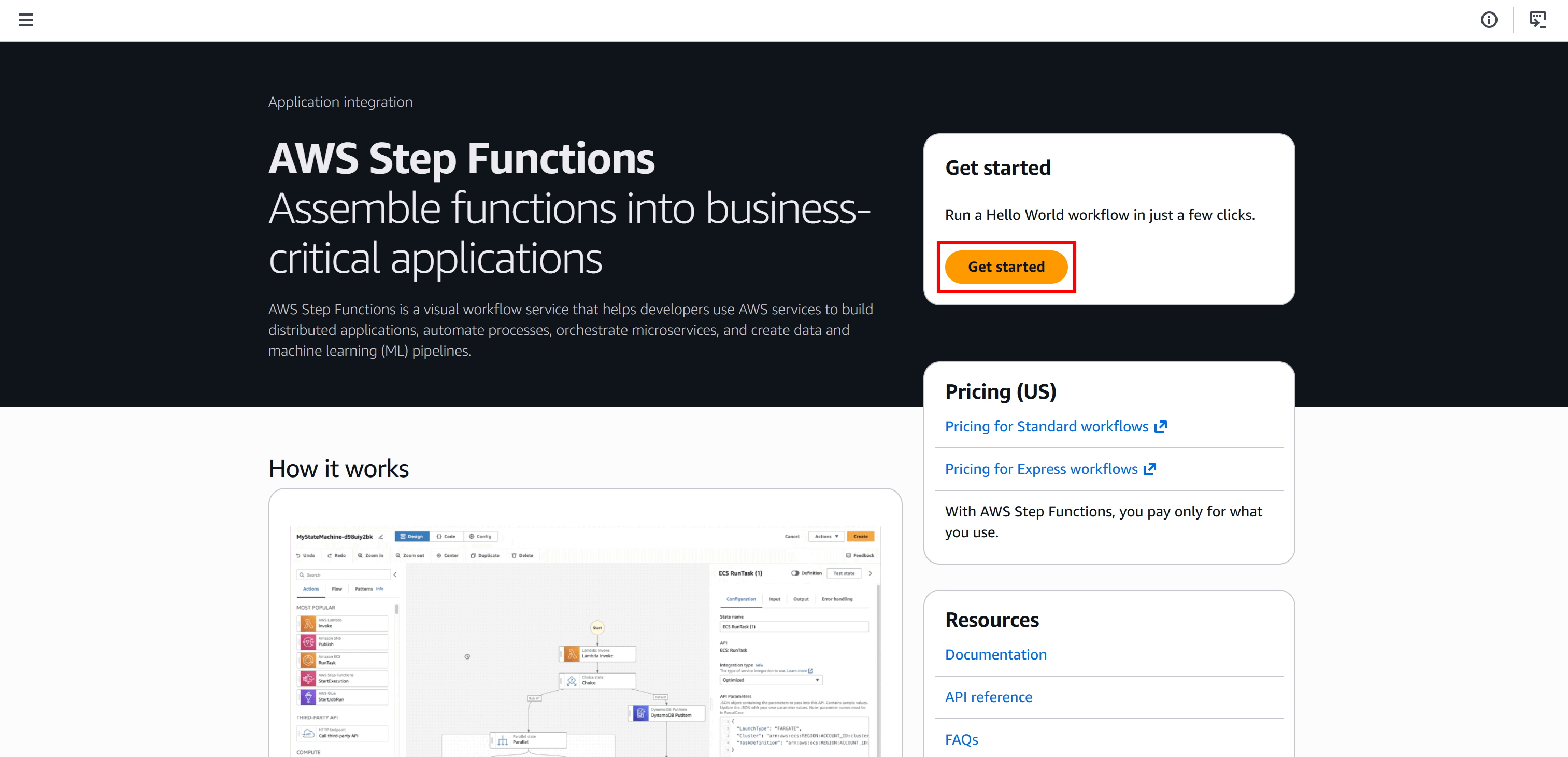
Aquí, haga clic en el botón «Empezar» y, a continuación, seleccione «Crear el suyo propio» para comenzar a crear un flujo de trabajo sin servidor desde cero: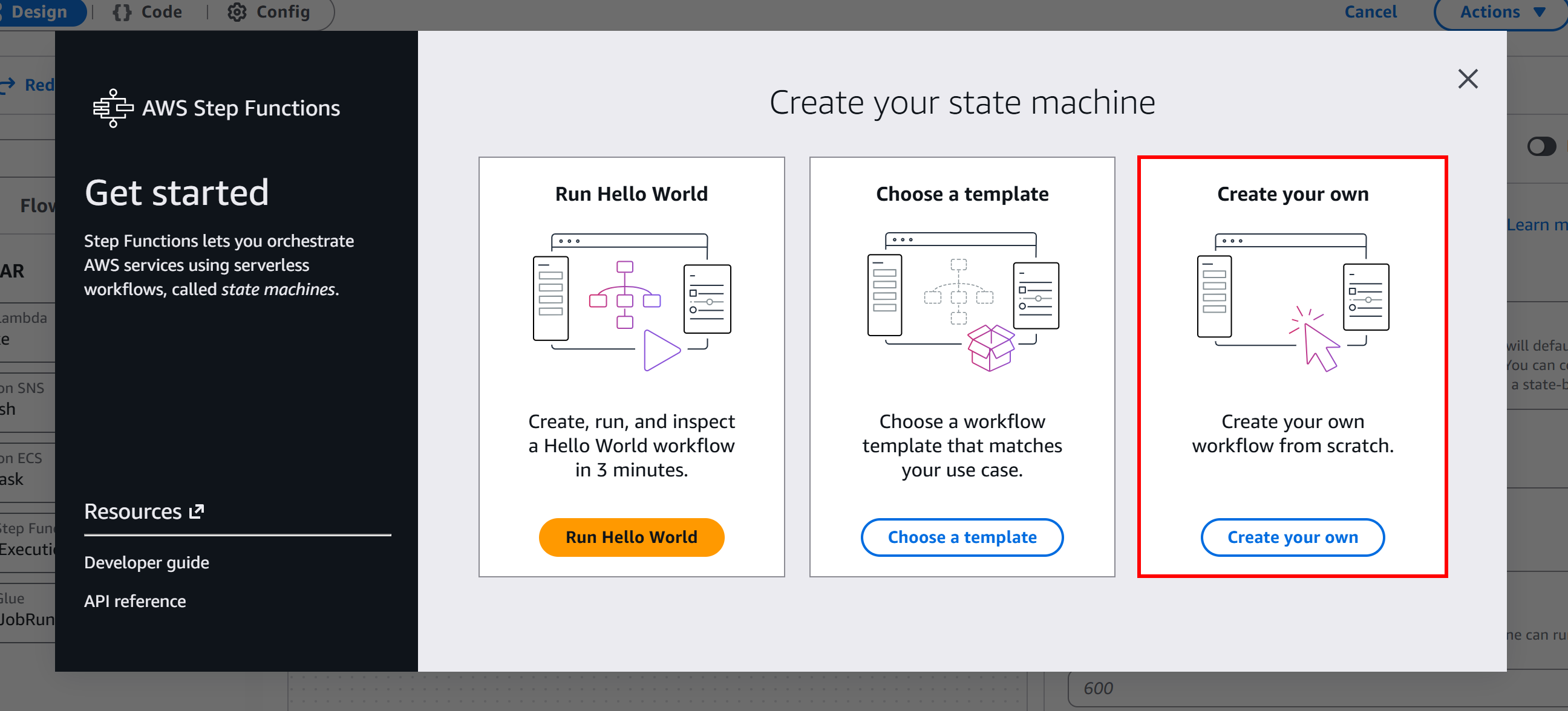
Asigne un nombre a su máquina de estados (por ejemplo, «BrightDataWebScrapingMachine») y elija el tipo de máquina de estados que desea crear. En este tutorial, utilizaremos una máquina «estándar»: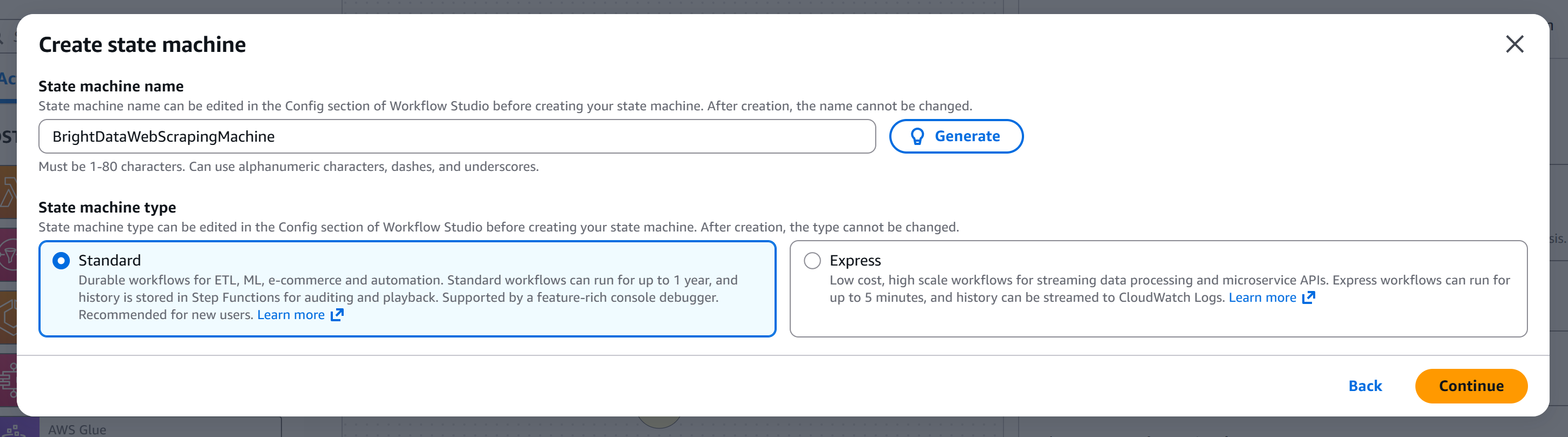
Haga clic en «Continuar» para acceder a la página del editor de flujos de trabajo: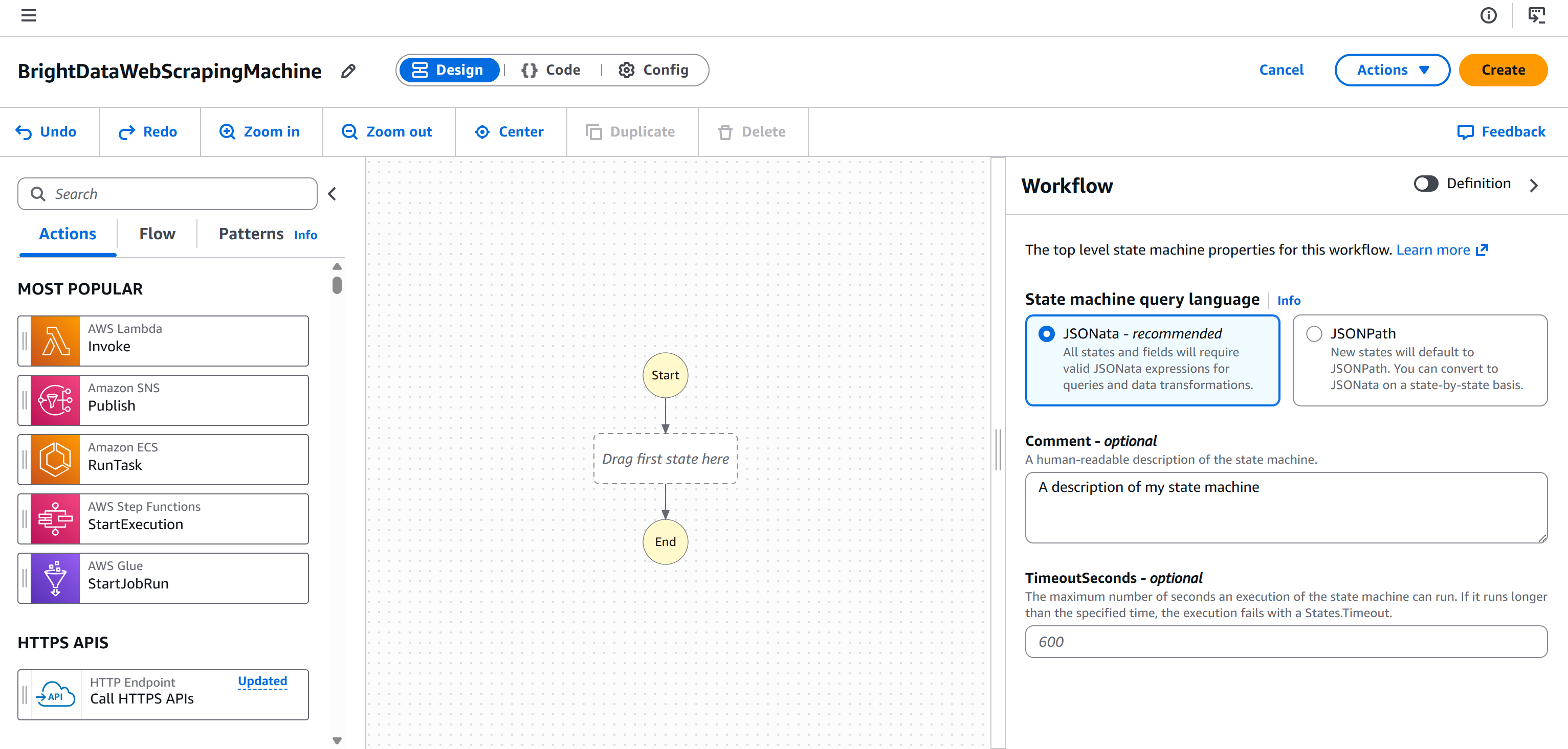
Ahora ya está todo configurado y listo para añadir un nodo de Scraping web de Bright Data a su flujo de trabajo de AWS Step Functions.
Enfoque n.º 1: utilice el nodo «Call HTTPS APIs»
Aquí aprenderá a definir un nodo que se conecta directamente a las API de Bright Data Web Unlocker a través de una llamada HTTP. Este nodo le permite extraer datos de cualquier página web mediante programación. En concreto, lo configuraremos para recuperar datos en formato Markdown, ideal para la ingestión de LLM.
Nota: Se puede aplicar un procedimiento muy similar para conectarse a cualquier otro producto de Bright Data basado en API.
Paso n.º 1: Añada un nodo «Punto final HTTP: llamar a API HTTPS»
Comience seleccionando el nodo «Punto final HTTP: llamar a API HTTPS» en el panel izquierdo y arrastrándolo a la sección «Arrastre aquí el primer estado»: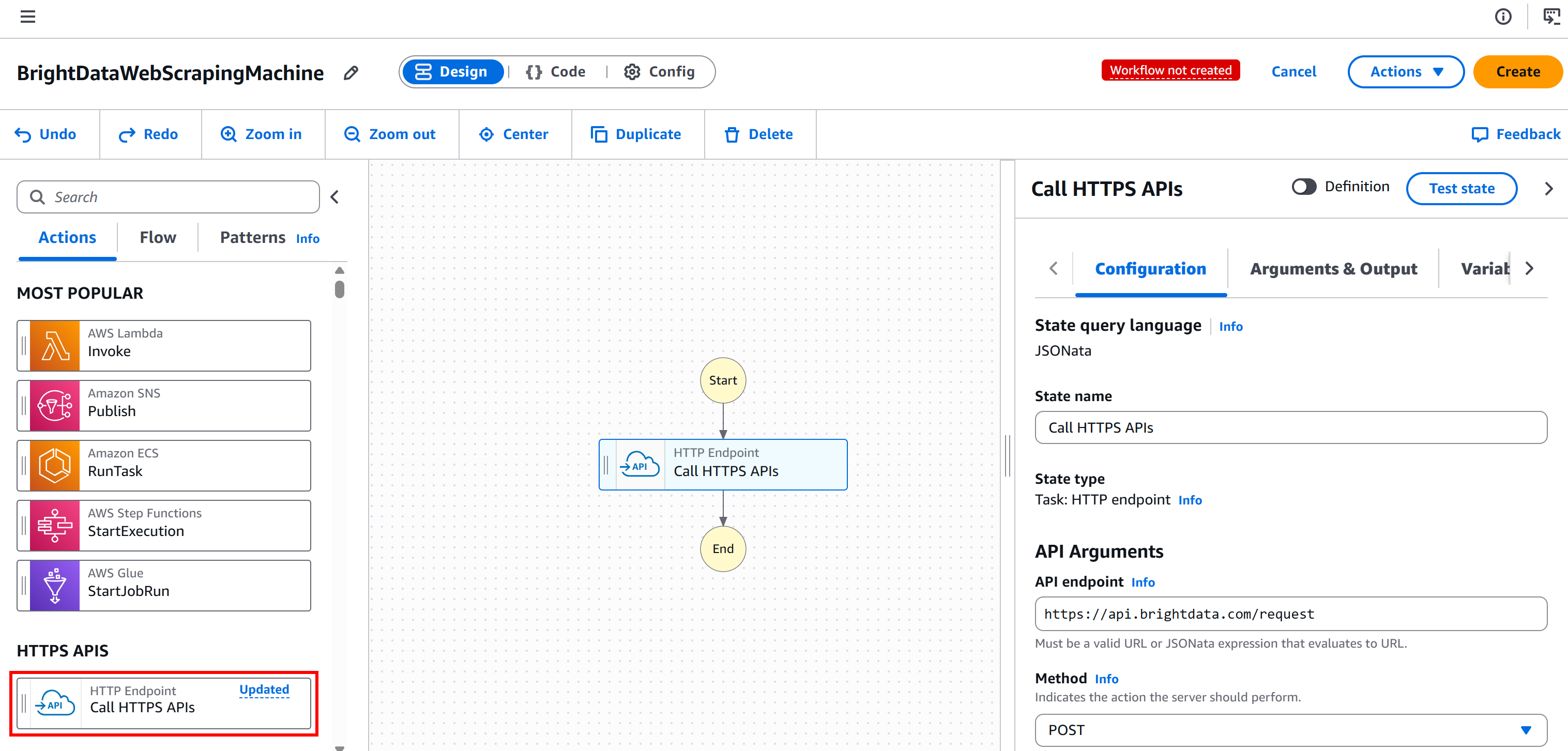
Seleccione el nodo y, en la pestaña «Configuración» de la derecha:
- Asigne un nombre a su estado.
- Establezca el «API endpoint» en
https://api.brightdata.com/request. - Establezca el «Método» en
POST.
Esto configura el nodo para conectarse al punto final POST https://api.brightdata.com/request, que es la API base de Bright Data para los servicios Web Unlocker y API SERP: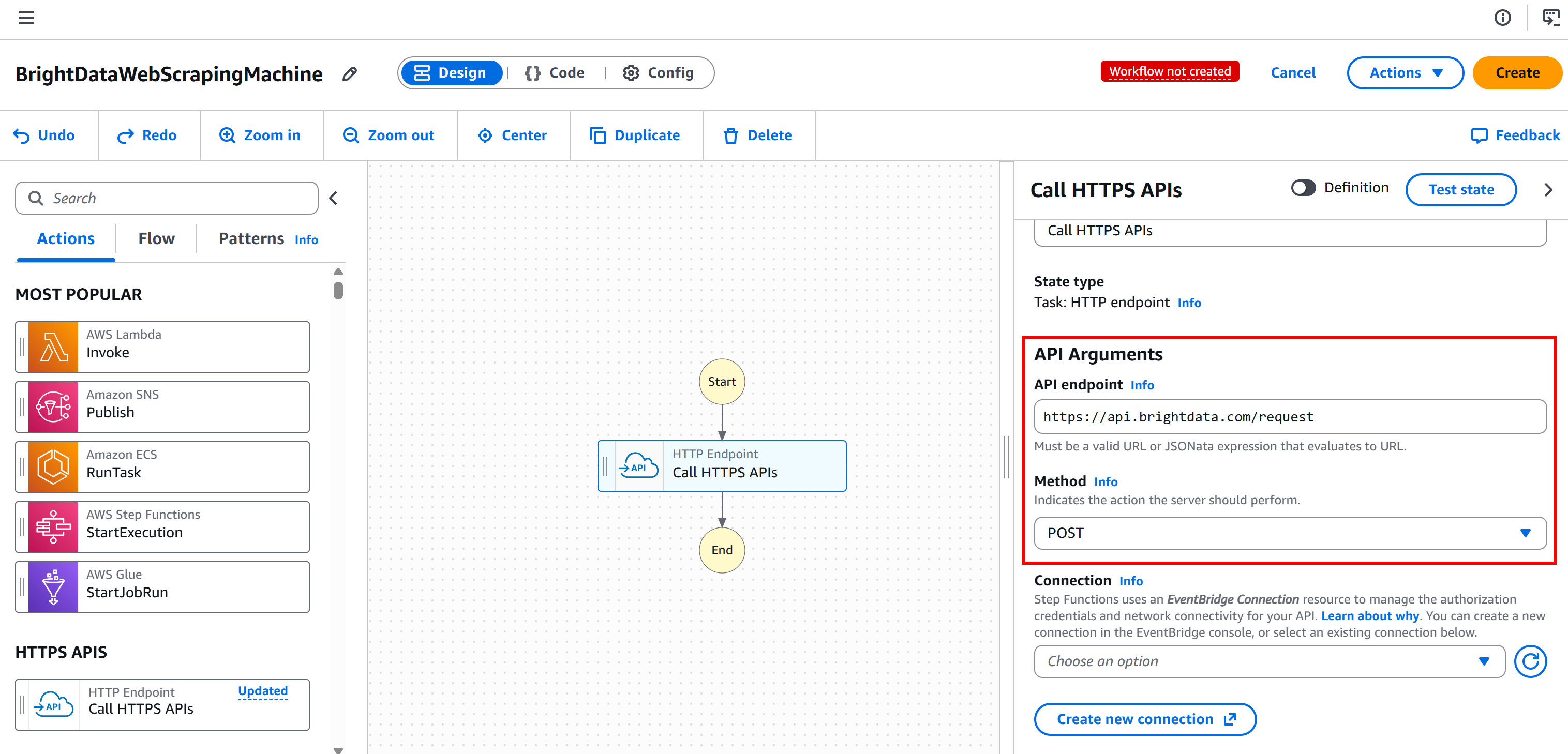
Paso n.º 2: Configurar la autenticación de la API
Las API de Bright Data se autentican utilizando su clave API de Bright Data. En concreto, debe incluirla en el encabezado de autorización con el siguiente formato:
Bearer <BRIGHT_DATA_API_KEY>Para evitar codificar su clave API en el nodo, debe crear una nueva conexión a través de Amazon EventBridge. Para ello, pulse el botón «Crear nueva conexión» en la sección «Conexión» de la pestaña «Configuración»:
Asigne un nombre a su conexión (por ejemplo, brightdata-api) y configúrela como «Pública» (ya que las claves API de Bright Data están expuestas públicamente).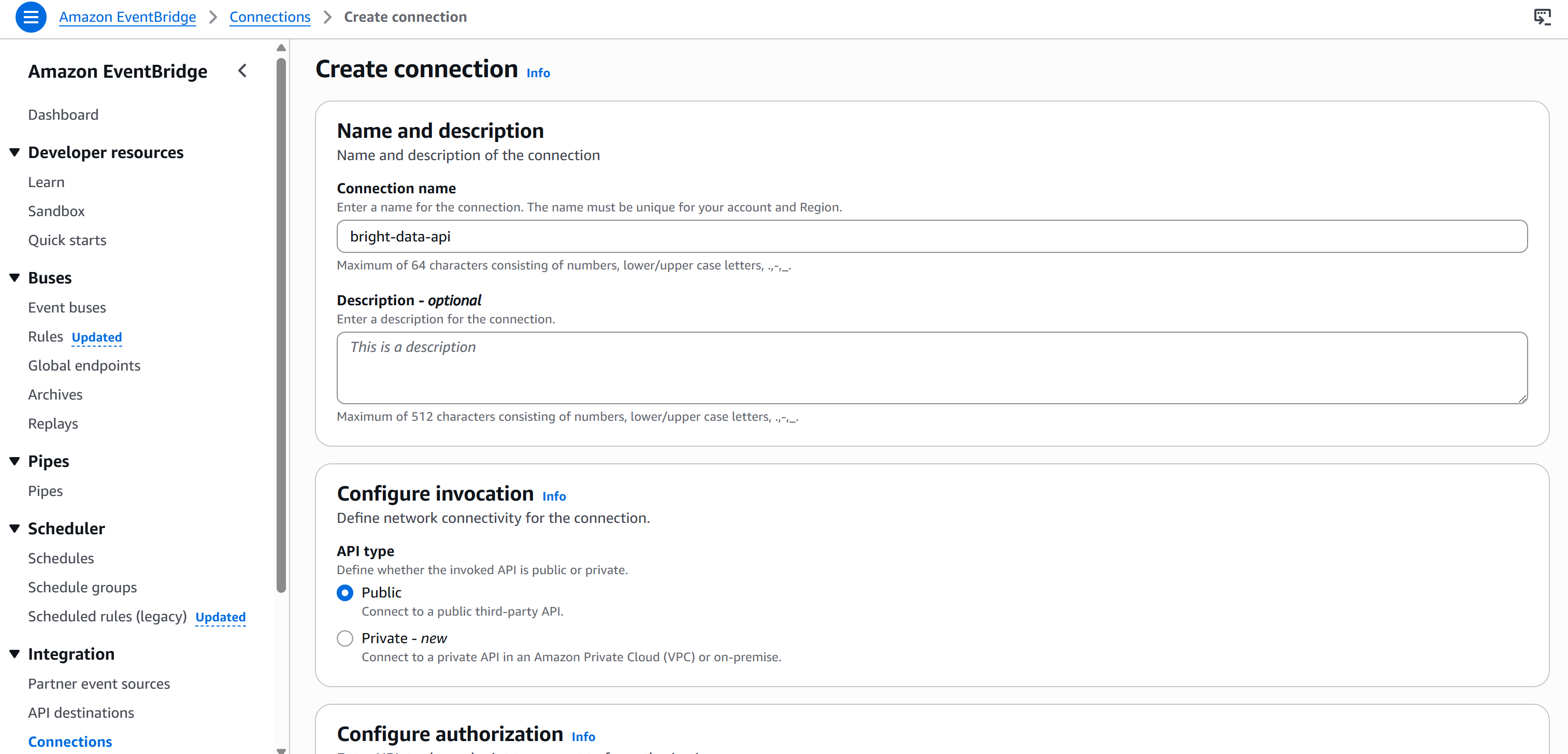
A continuación, seleccione el tipo de autenticación «Clave API» y configúrela de la siguiente manera:
- Nombre de la clave API:
Autorización(debe coincidir con el nombre del encabezado HTTP utilizado para la autenticación). - Valor:
Portador <BRIGHT_DATA_API_KEY>(sustituya el marcador de posición<BRIGHT_DATA_API_KEY>por su clave API real).
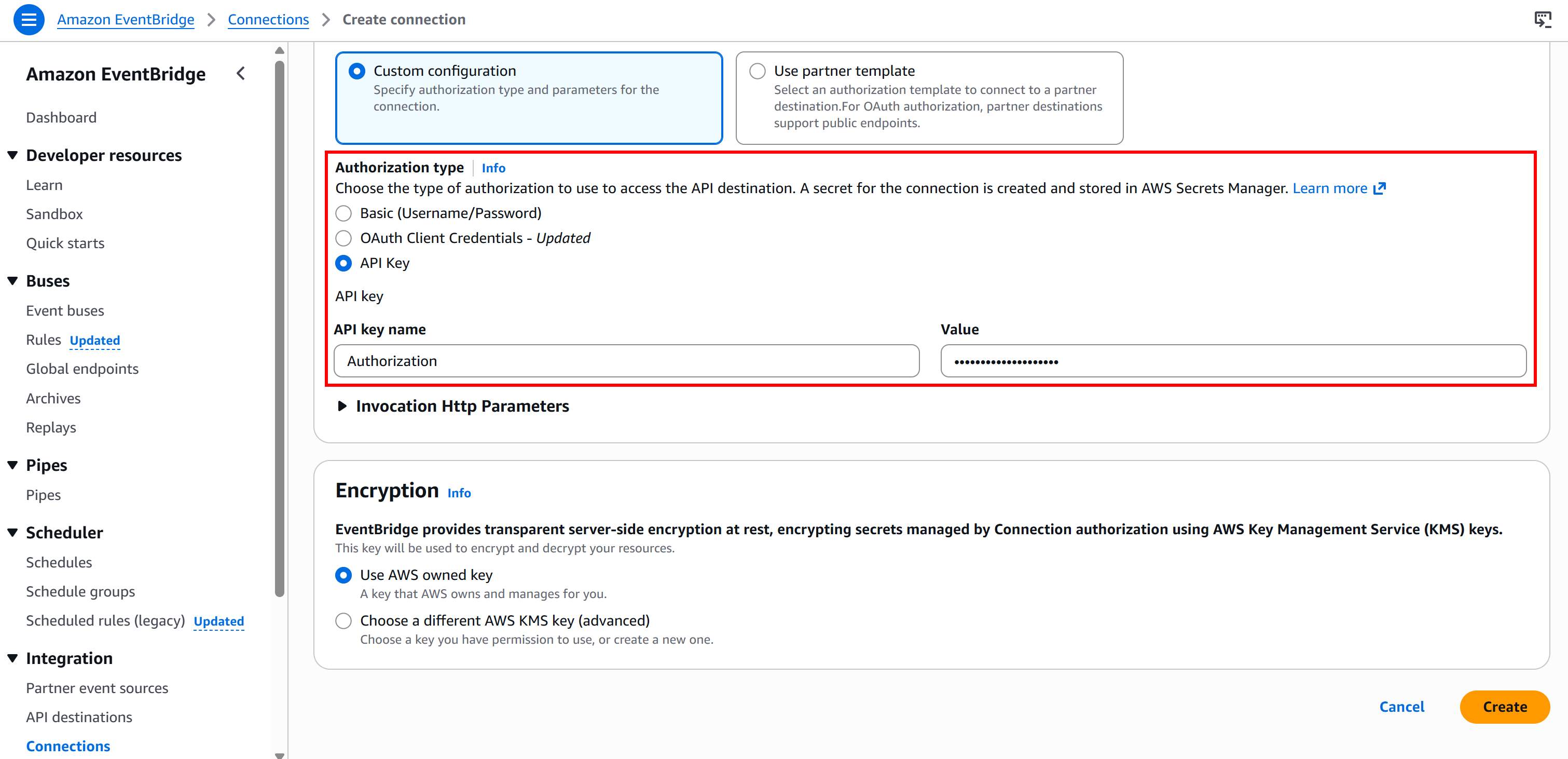
Por último, pulse «Crear» para configurar la conexión de EventBridge. Una vez creada, debería ver lo siguiente: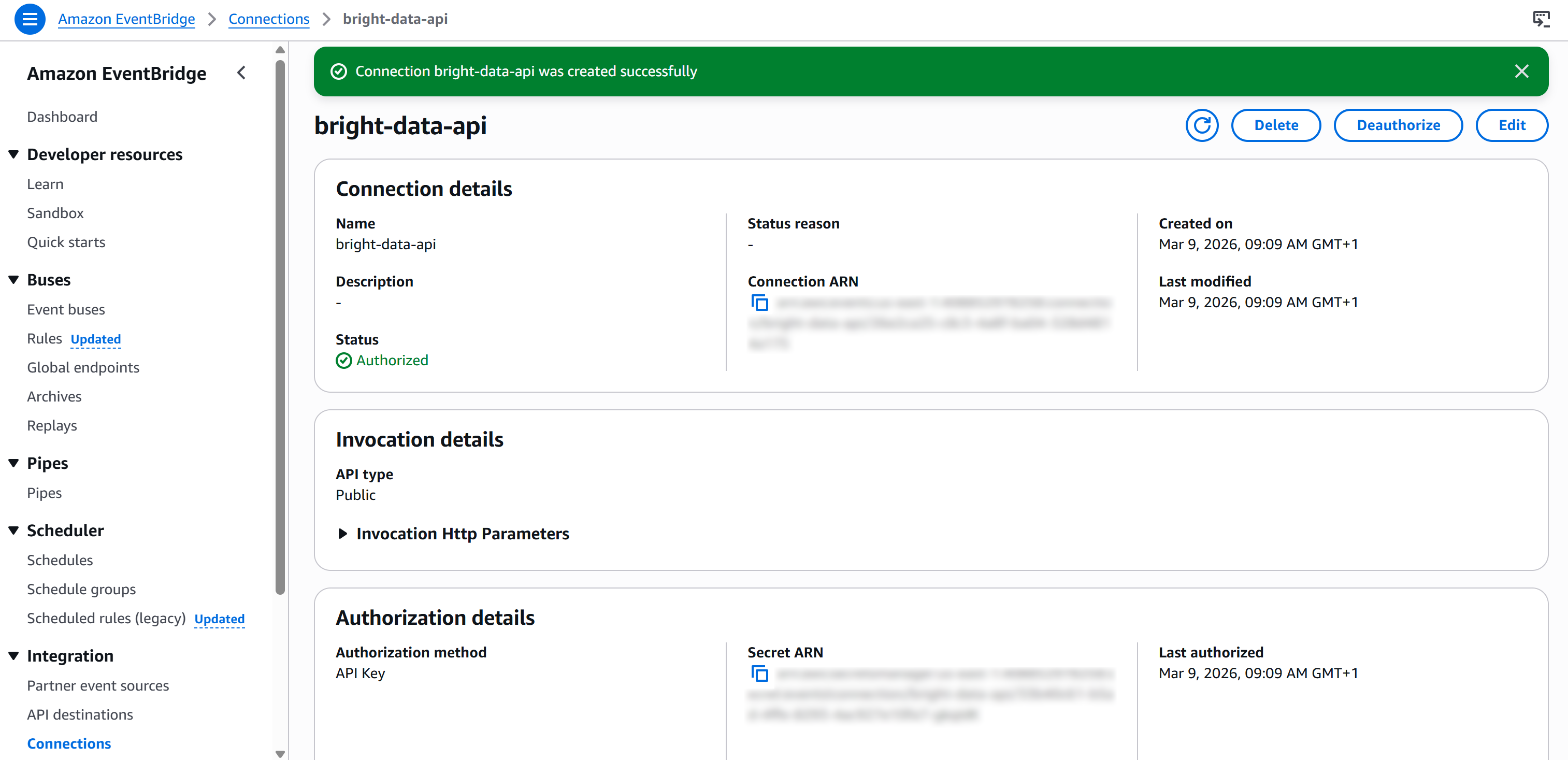
Paso n.º 3: Complete la configuración de la API
Vuelva a la página del editor de flujos de trabajo, seleccione el nodo «Punto final HTTP: llamar a API HTTPS» y vaya a la pestaña «Configuración». A continuación, seleccione la conexión que acaba de crear (bright-data-api):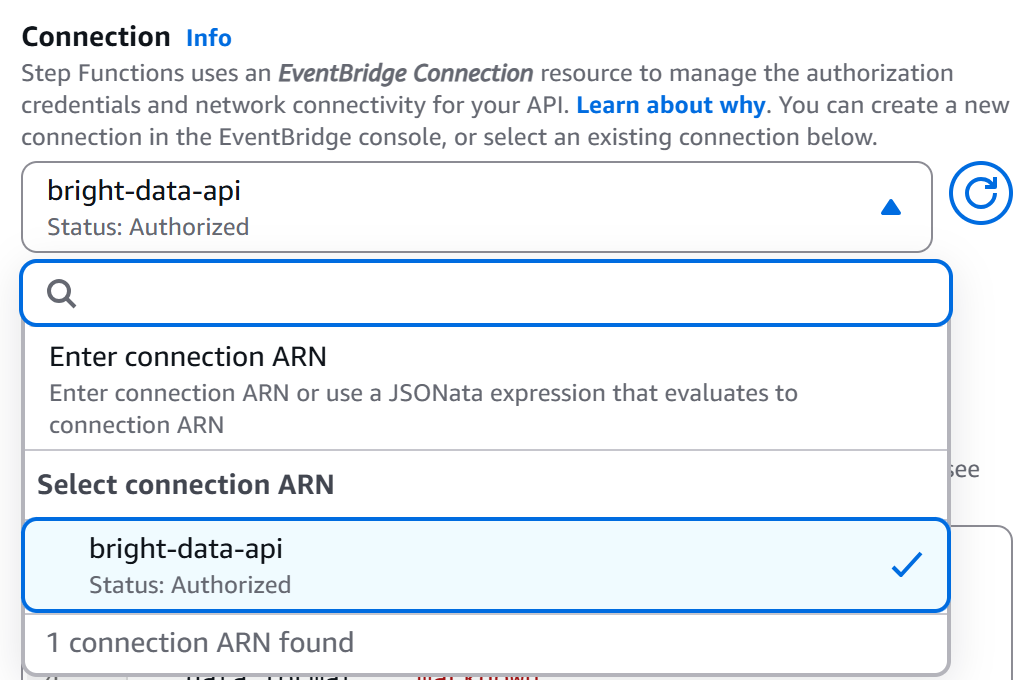
De esta manera, la clave API de Bright Data se añadirá al encabezado de autorización para la autenticación (en el formato requerido).
A continuación, define el cuerpo HTTP de la siguiente manera:
{
"zona": "<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONA_NAME>",
"url": "{% $states.input.url %}",
"format": "raw",
"data_format": "markdown"
}Reemplace el marcador de posición <YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE_NAME> con el nombre de su zona Web Unlocker de su cuenta Bright Data. El campo url se leerá dinámicamente desde la entrada del flujo de trabajo (gracias a la sintaxis {% $states.input.url %} ), lo que le permitirá extraer diferentes páginas sin necesidad de codificar la URL. En su lugar, data_format: "markdown" garantiza que la respuesta de la API se devuelva en formato Markdown listo para IA.
En nuestro ejemplo, la zona Web Unlocker se llama «``web_unlocker``», por lo que el cuerpo queda así: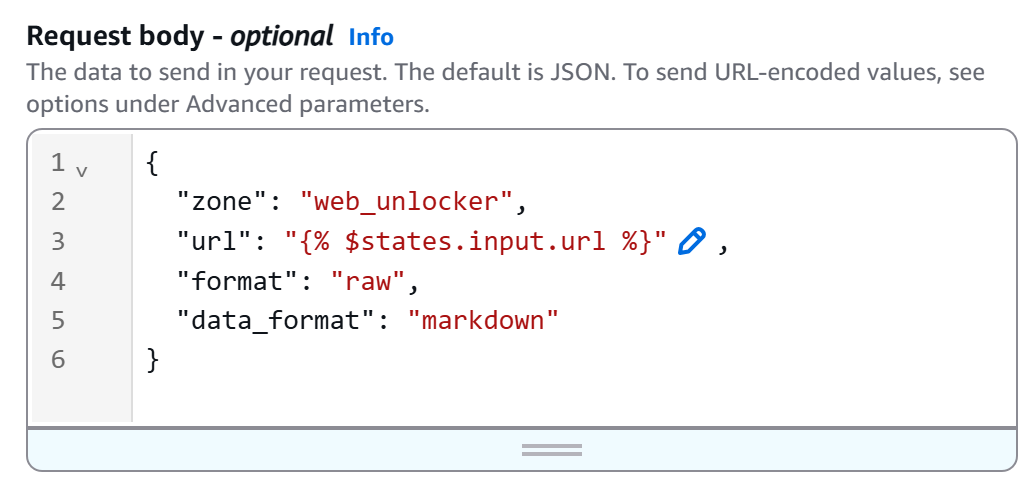
Así es como se verá ahora su flujo de trabajo: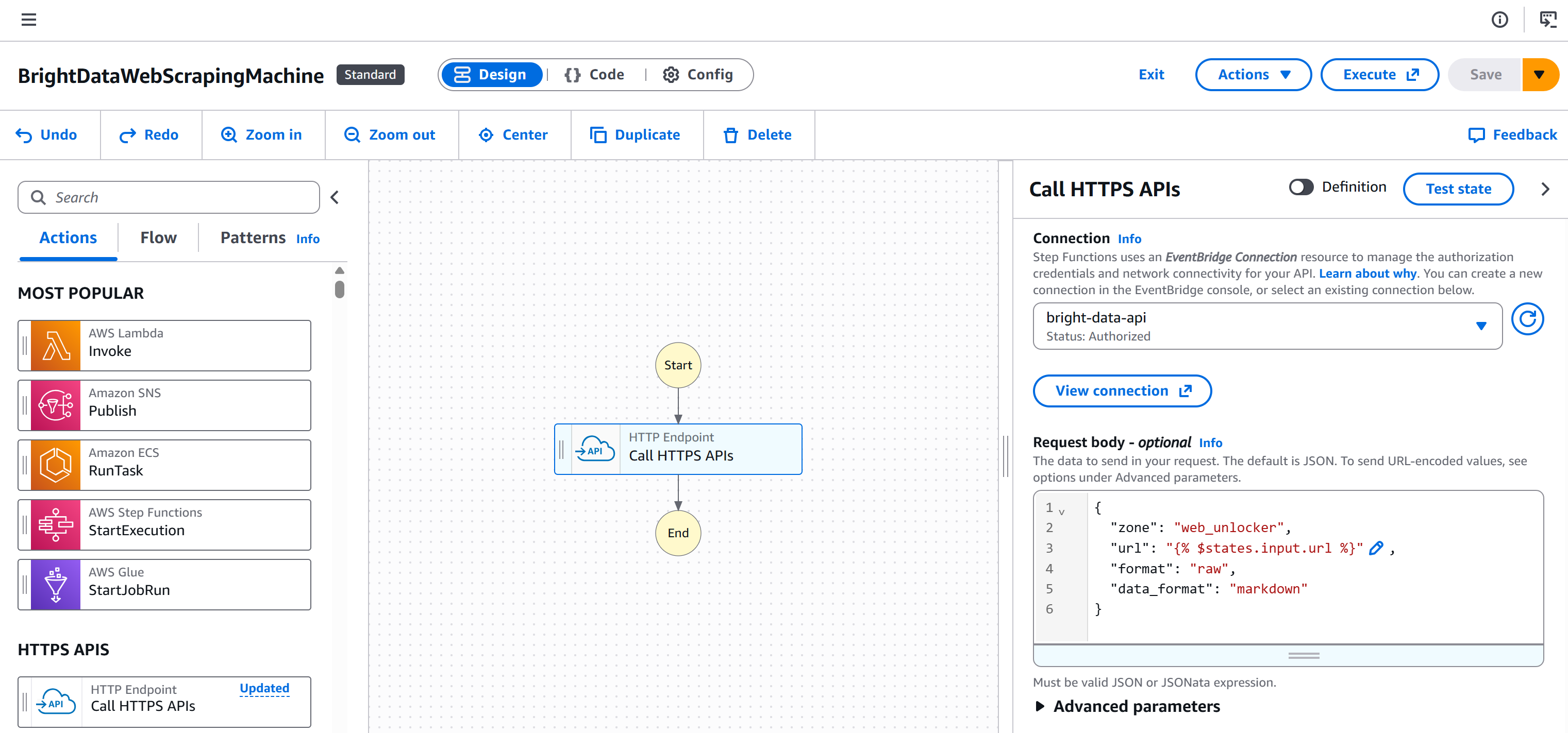
¡Fantástico! La configuración está completa. Solo queda probar la integración de Bright Data en tu flujo de trabajo de AWS Step Functions.
Paso n.º 4: Prueba el nodo de Scraping web con tecnología Bright Data
Comience pulsando el botón «Crear» para generar la función IAM requerida y todos los demás elementos necesarios en su consola de AWS para la prueba:
A continuación, pulse el botón «Estado de prueba» en su nodo: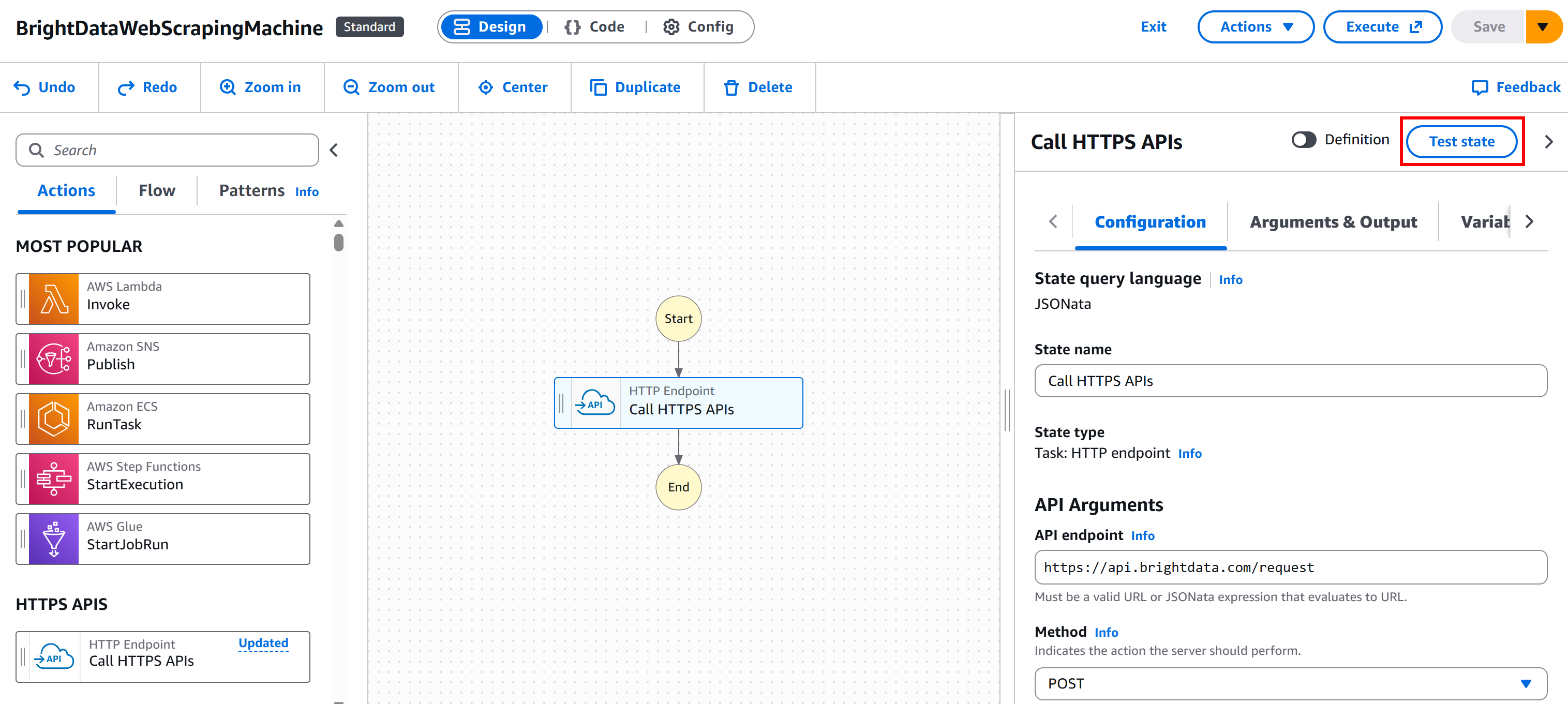
Llegará al modal «Probar estado»: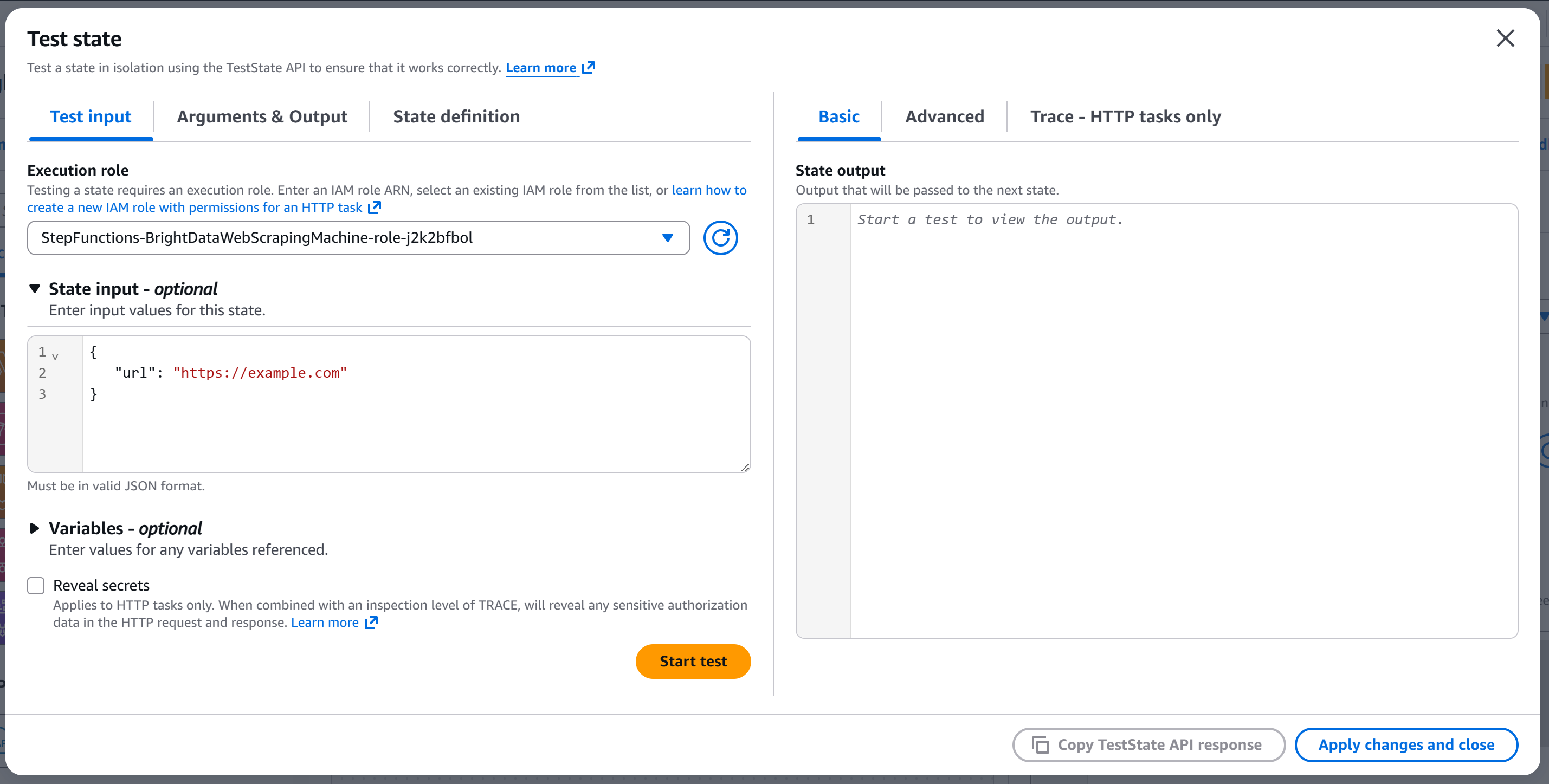
Configure la entrada de estado con algo como:
{
"url": "https://example.com"
}El campo url se pasará al cuerpo de la API (porque el nodo se configuró para leer el campo url body de la entrada).
Pulse «Iniciar prueba» para ejecutar el nodo. Debería ver un resultado similar a este: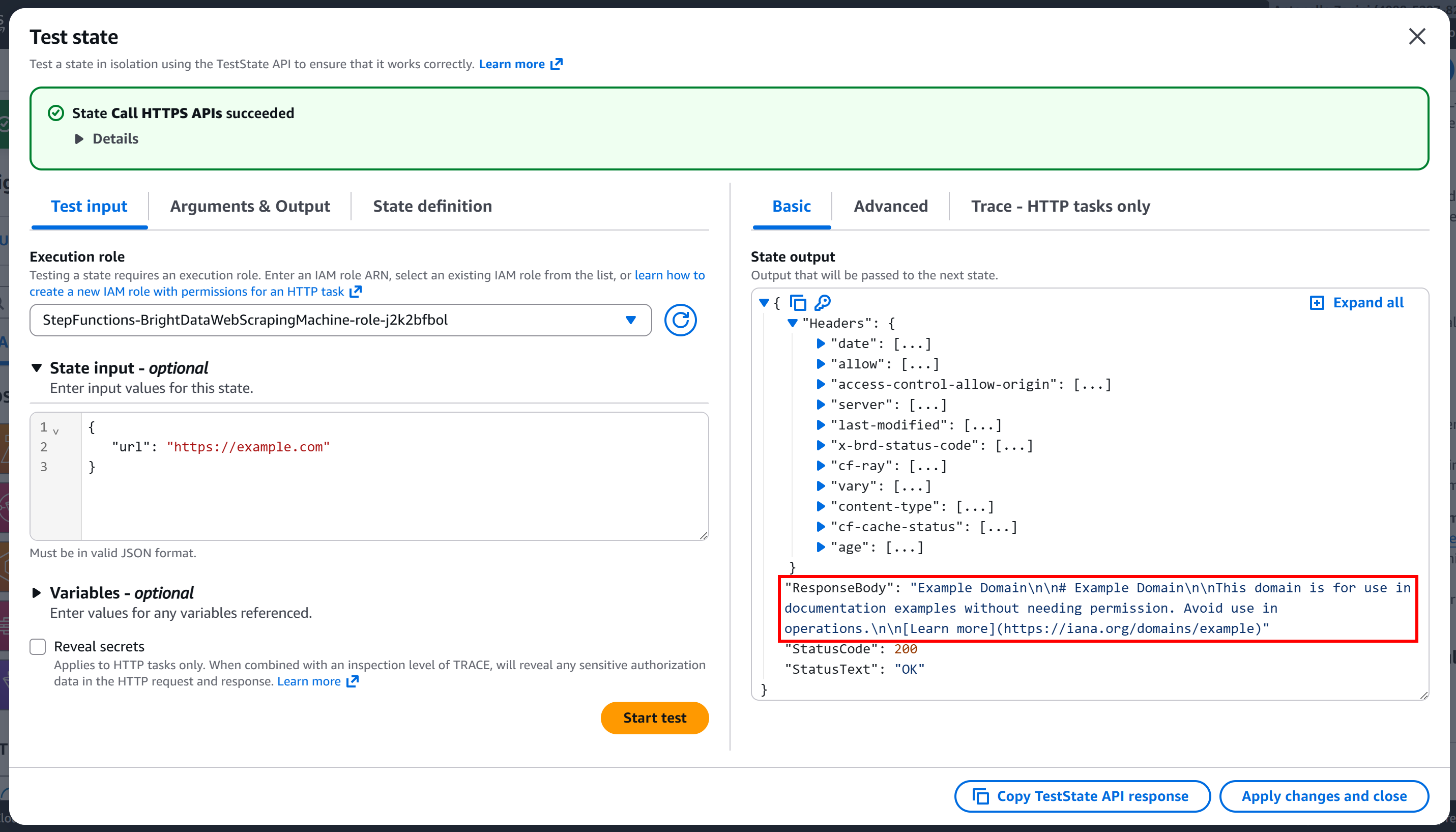
Como puede ver, la solicitud se ha realizado correctamente y el cuerpo de la respuesta contiene la versión Markdown de la página de destino: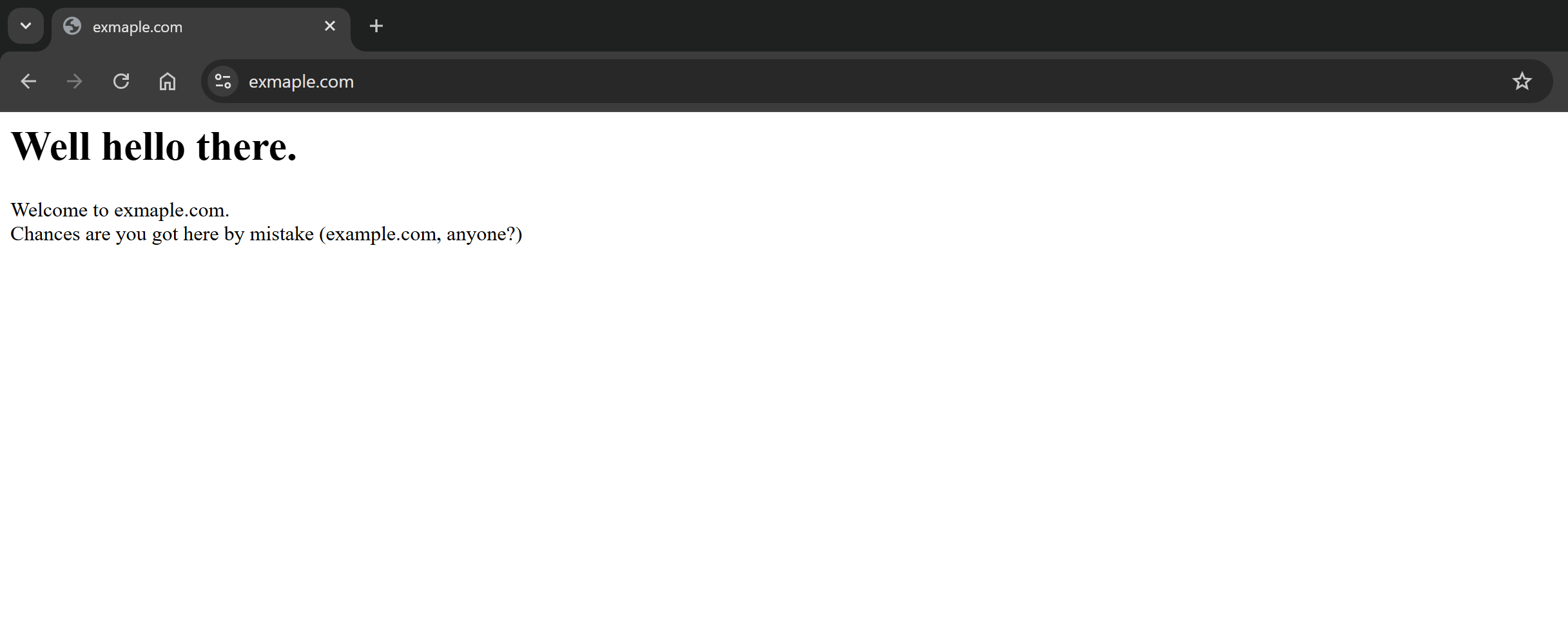
¡Et voilà! Su integración de Bright Data en AWS Step Functions ya funciona completamente y está lista para su uso en producción.
Enfoque n.º 2: utilizar una función Lambda
En esta sección, aprenderá a conectarse a los servicios de Bright Data a través de una función AWS Lambda personalizada.
Para simplificar la integración y acelerar el proceso, puede seguir los pasos 5, 6 y 7 del artículo «Dar a los agentes de AWS Bedrock la capacidad de buscar en la web a través de la API SERP de Bright Data». Estos pasos le guiarán a través de la creación de una función Lambda en Python que se conecta a la API SERP de Bright Data.
A continuación, verá cómo integrar esa función Lambda en su flujo de trabajo de Scraping web a través de AWS Step Functions.
Paso n.º 1: añadir un nodo «AWS Lambda – Invoke»
Comience seleccionando el nodo «AWS Lambda – Invoke» en el panel izquierdo. A continuación, arrástrelo a la sección «Drag first state here» (Arrastre aquí el primer estado) de su flujo de trabajo.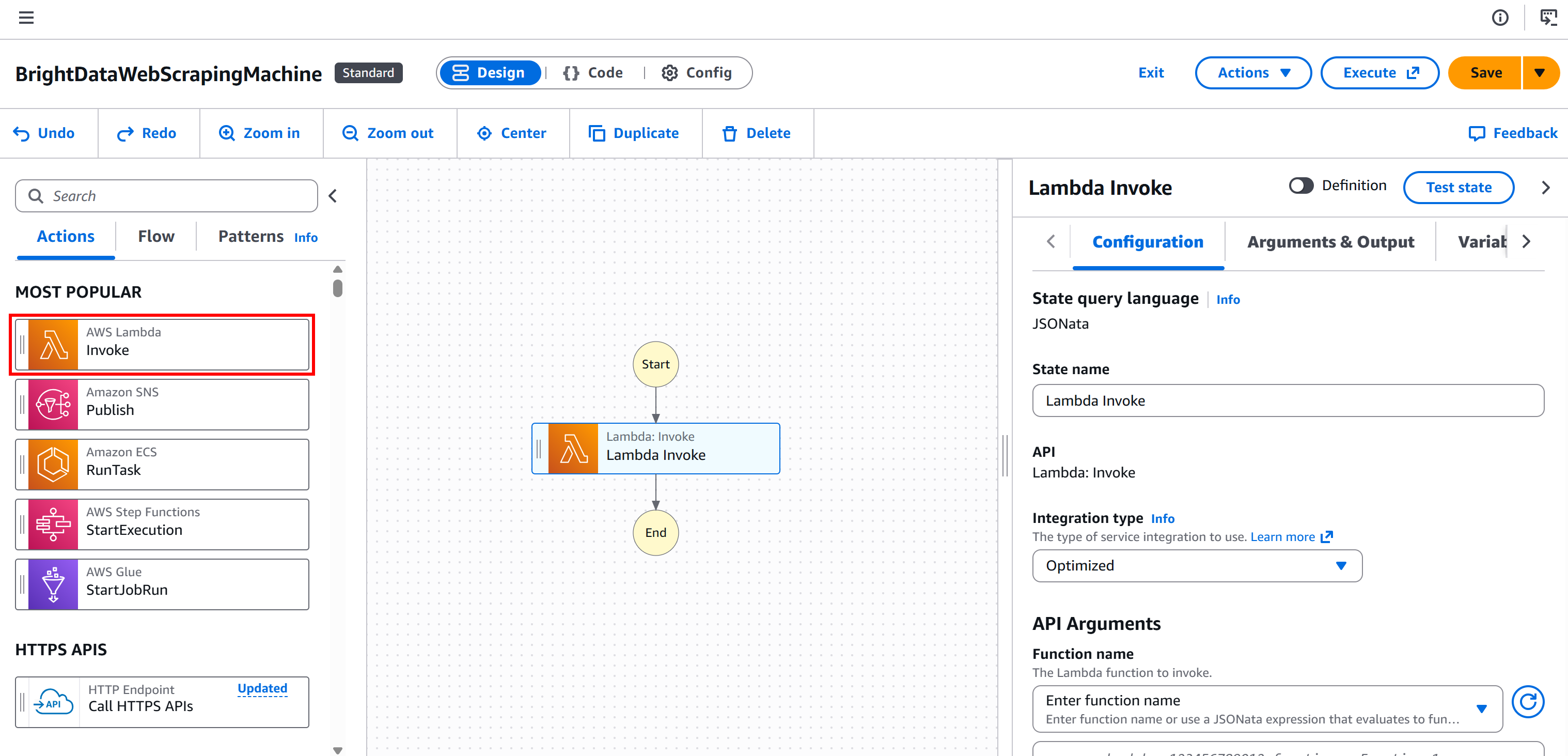
Paso n.º 2: Configure la función Lambda
En la sección «Configuración» del nodo «AWS Lambda – Invoke», en el bloque «Argumentos de la API – Nombre de la función», seleccione la función Lambda que desea invocar: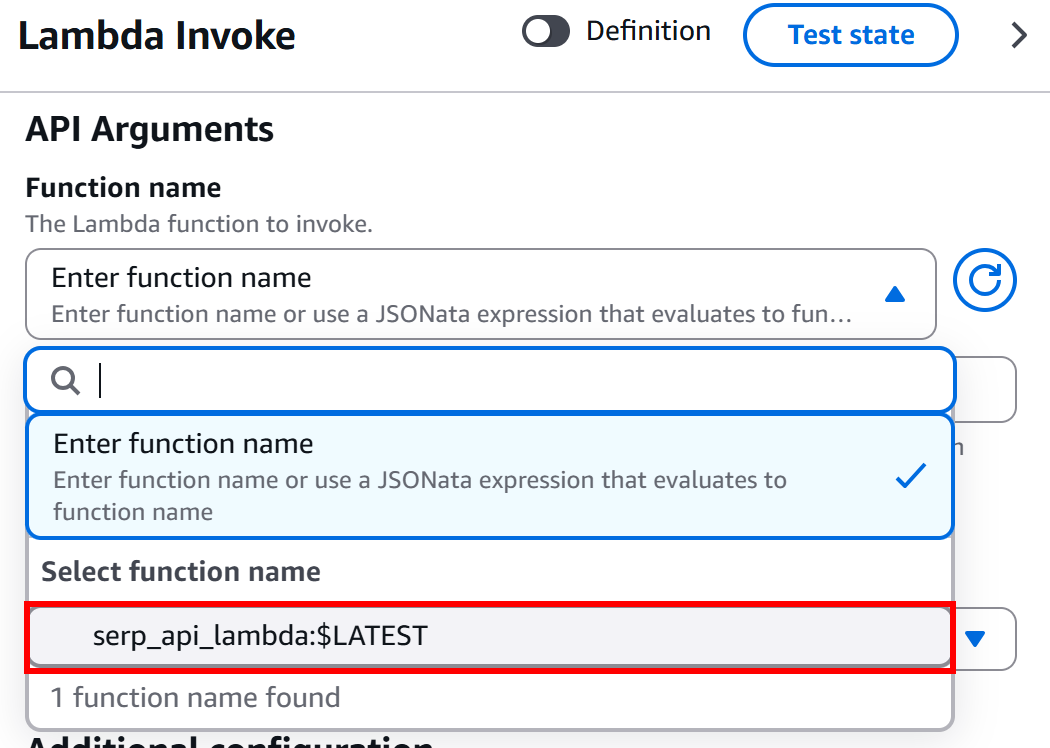
En este ejemplo, la función es serp_api_lambda, que se creó tal y como se explicó anteriormente en la introducción de este capítulo. Esa función se integra con la API SERP de Bright Data.
¡Genial! Ahora tienes una función Lambda impulsada por Bright Data para el scraping de SERP integrada en tu flujo de trabajo de AWS Step Functions.
Conclusión
En esta guía, ha aprendido qué es AWS Step Functions y por qué es ideal para orquestar flujos de trabajo automatizados de Scraping web.
Has visto cómo Step Functions simplifica la gestión de flujos de trabajo con máquinas de estado, ejecución paralela, reintentos y soporte humano en el bucle. Has explorado cómo Bright Data mejora este proceso a través de las integraciones de Web Unlocker y API SERP, superando las medidas antibots y garantizando una recuperación de datos web ininterrumpida y de nivel empresarial.
Al integrar Bright Data en Step Functions, puede crear canalizaciones de extremo a extremo que se encarguen de la recopilación, validación y almacenamiento de datos en S3 u otros servicios de AWS, todo ello manteniendo la escalabilidad, la resiliencia y la supervisión.
¡Regístrese hoy mismo para obtener una cuenta de Bright Data y pruebe nuestras soluciones de datos web de forma gratuita!





