En este tutorial, aprenderás lo siguiente:
- Qué es Cloudflare.
- Una mirada más profunda a su mecanismo WAF.
- Cómo funciona su sistema anti-bot desde un punto de vista técnico.
- Qué ocurre cuando se dirige a un sitio protegido por Cloudflare utilizando herramientas de automatización estándar.
- Enfoques de alto nivel para eludir Cloudflare.
- Cómo evitar la comprobación humana de Cloudflare en Python.
- Cómo evitar Cloudflare a gran escala.
Sumerjámonos.
¿Qué es Cloudflare?
Cloudflare es una empresa de infraestructura y seguridad web que opera una de las mayores redes de la Web. Ofrece un amplio conjunto de servicios diseñados para que los sitios web sean más rápidos y seguros.
En esencia, Cloudflare funciona principalmente como una CDN(Content Delivery Network), almacenando en caché el contenido del sitio en una red global para mejorar los tiempos de carga y reducir la latencia. Además, ofrece funciones como protección DDoS(denegación de servicio distribuida), un WAF (cortafuegos de aplicaciones web), gestión de bots, servicios DNS y mucho más.
Al integrarse en la red de Cloudflare, los sitios web pueden obtener rápidamente una mayor seguridad y un rendimiento optimizado. Esto ha convertido a Cloudflare en la solución preferida de millones de sitios web de todo el mundo.
Comprender los mecanismos anti-bot de Cloudflare
Una de las razones por las que Cloudflare es tan popular es su WAF(Web Application Firewall). Este puede habilitarse en cualquier página web servida a través de su red global. En detalle, representa una de las soluciones más eficaces contra scrapers, rastreadores no deseados y bots en general.
Más concretamente, el WAF de Cloudflare se sitúa delante de sus aplicaciones web. Inspecciona y filtra las solicitudes entrantes en tiempo real para detener ataques o tráfico no deseado antes de que lleguen a sus servidores o accedan a sus páginas web.
Como parte de su estrategia de defensa multicapa, el WAF de Cloudflare utiliza algoritmos propios para detectar y bloquear bots maliciosos. Estos algoritmos analizan varias características del tráfico entrante, entre ellas:
- Huellas digitales TLS: Inspecciona cómo el cliente HTTP o el navegador realiza el protocolo TLS. Examina detalles como los conjuntos de cifrado ofrecidos, el orden de negociación y otros rasgos de bajo nivel. Los bots y los clientes no estándar a menudo tienen firmas TLS inusuales, no propias de un navegador, que los delatan.
- Detalles de la solicitud HTTP: Examina las cabeceras HTTP, las cookies, las cadenas de agente de usuario y otros aspectos. Los bots suelen reutilizar configuraciones predeterminadas o sospechosas que difieren de las utilizadas por los navegadores reales.
- Huellas digitales deJavaScript: Ejecuta JavaScript en el navegador del cliente para recopilar información detallada sobre el entorno. Esto incluye la versión exacta del navegador, el sistema operativo, las fuentes o extensiones instaladas e incluso características sutiles del hardware. Estos datos forman una huella digital que ayuda a distinguir a los usuarios reales de los scripts automatizados.
- Análisis del comportamiento: Uno de los indicadores más potentes del tráfico automatizado es el comportamiento poco natural. Cloudflare supervisa patrones como solicitudes rápidas, falta de movimientos del ratón, rutas de clics idénticas, tiempos de inactividad y mucho más. Utiliza el aprendizaje automático para determinar si el comportamiento de navegación coincide con el de un humano o un bot. Esta es una de las técnicas anti-bot más complejas.
Cloudflare proporciona generalmente dos modos de verificación humana:
- Mostrar siempre el reto de verificación humana
- Reto de verificación humana automatizada (sólo cuando se detecta actividad sospechosa)
Explore ambas opciones a continuación.
Modo nº 1: Mostrar siempre el reto de verificación humana
El primer modo es menos común pero ofrece una protección más fuerte. La idea es exigir siempre la verificación humana en el primer acceso a un sitio.
Por ejemplo, así es como funciona StackOverflow en el momento de escribir este artículo. Intenta visitarlo en modo incógnito (para asegurar una sesión fresca sin cookies), y verás un CAPTCHA llamado Cloudflare Turnstile, incluso si eres un usuario humano real:
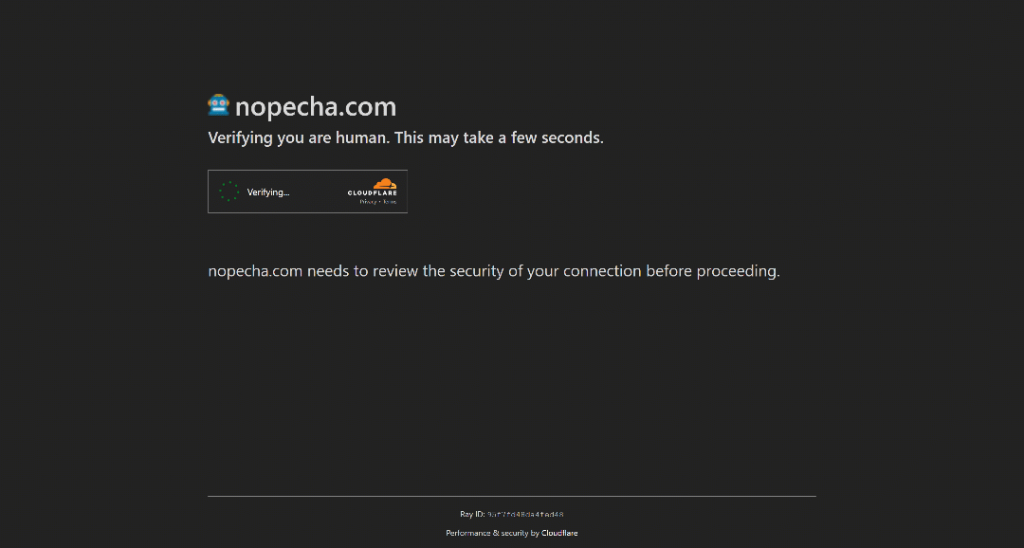
Nota: Para cuando leas este artículo, la protección contra bots de StackOverflow puede haber cambiado o funcionar de forma diferente.
En este caso, si está creando un script automatizado, la única opción es automatizar la interacción Turnstile CAPTCHA de forma similar a la humana. Ahora bien, eso es especialmente difícil, ya que Turnstile se basa en análisis de comportamiento entre bastidores y otras comprobaciones patentadas. Así es como consigue verificar que eres humano con un solo clic.
Modalidad nº 2: Reto de verificación humana automatizada
En este modo, Cloudflare sólo emite una impugnación si sospecha que una solicitud puede proceder de un bot. Para ello, presenta una impugnación JavaScript, que se ejecuta de forma invisible en el navegador para verificar que el cliente se comporta como un usuario legítimo:
Este proceso no presenta problemas y suele completarse automáticamente si usted es un humano que utiliza un navegador normal. Si pasa, puede seguir navegando por el sitio sin interrupción. Dado que esto causa una interrupción mínima a los usuarios normales, es con diferencia el modo más común de Cloudflare.
Sin embargo, si el desafío de JavaScript falla (lo que significa que Cloudflare concluye que es probable que el cliente sea un bot), pasará a mostrar un CAPTCHA de torniquete para la verificación humana:
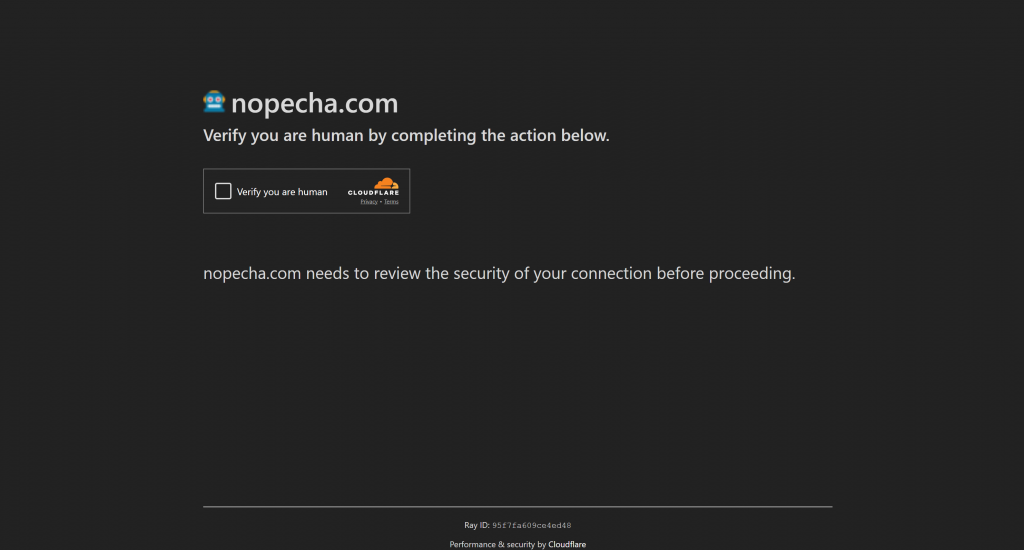
Ahora, usted está de vuelta a lo que vio en el escenario anterior. En este modo, utilizar un bot que presente huellas dactilares similares a las humanas puede ser suficiente para pasar la verificación inicial, evitando por completo el CAPTCHA de torniquete. Aún así, si aparece, necesitas una manera de lidiar con él.
Cómo funciona Cloudflare en detalle desde un punto de vista técnico
Prueba a abrir la página de prueba de Cloudflare de NopeCHA en modo incógnito con tu navegador. Esta página está protegida por el WAF de Cloudflare, por lo que el proceso de verificación automatizado basado en JavaScript comenzará inmediatamente.
En segundo plano, se intercambian una serie de solicitudes POST con los puntos finales de Cloudflare, transmitiendo datos cifrados dentro de sus cargas útiles:

El contenido exacto de estas cargas útiles no está documentado públicamente. Sin embargo, basándonos en las estrategias de detección conocidas de Cloudflare, es razonable suponer que incluyen varios tipos de huellas dactilares de navegadores y sistemas.
Dado que su navegador y configuración de hardware son legítimos, este desafío debería pasar automáticamente. En caso contrario, realice la interacción de usuario requerida (es decir, haga clic en la casilla de verificación).
Una vez que la verificación tiene éxito, el servidor de Cloudflare emite una cookie cf_clearance, que indica que esta sesión de usuario específica tiene permiso para acceder al sitio web:
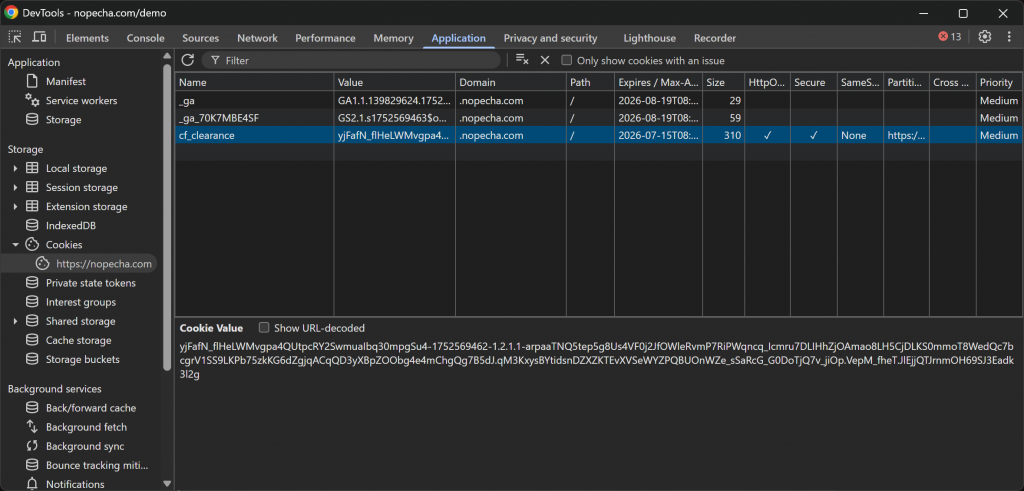
En este caso, la cookie es válida durante 15 días. Esto significa que, en teoría, podría ser reutilizada por un bot automatizado durante un par de semanas para acceder al sitio de destino sin tener que resolver de nuevo el proceso de verificación.
Qué ocurre cuando intenta conectarse a un sitio protegido por Cloudflare
Ahora, echemos un vistazo a lo que realmente sucede cuando un bot automatizado intenta visitar una página protegida por Cloudflare.
Nota: Los scripts de ejemplo que aparecen a continuación están escritos en Python, pero los mismos principios se aplican independientemente del lenguaje de programación, cliente HTTP o herramienta de automatización del navegador que elija.
Para esta demostración, utilizaremos la página del reto Cloudflare de ScrapingCourse:
Este es un sitio que requiere pasar la verificación de Cloudflare. Una vez resuelto el reto con éxito, muestra la siguiente página:
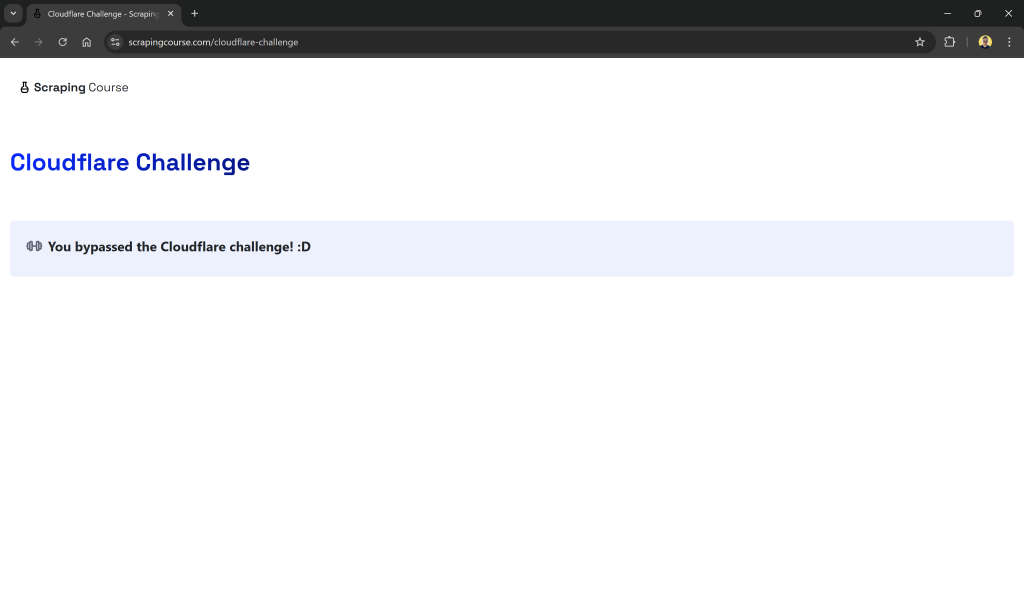
En los siguientes ejemplos, comprobaremos específicamente si el contenido de la página recuperada incluye la cadena:
"You bypassed the Cloudflare challenge! :D"Esto confirmará que el proceso de verificación se ha completado con éxito.
Como prueba básica, veremos lo que ocurre al visitar la página protegida por Cloudflare anterior utilizando dos enfoques diferentes:
- Con un cliente HTTP como Requests
- Con una herramienta de automatización del navegador como Playwright
Solicitudes dirigidas a páginas protegidas por Cloudflare
Compruebe si las solicitudes pueden eludir automáticamente la verificación humana de Cloudflare con:
# pip install requests
import requests
# Connect to the target page
response = requests.get(
"https://www.scrapingcourse.com/cloudflare-challenge"
)
# Raise exceptions in case of HTTP error status codes
response.raise_for_status()
# Verify if you received the success page
html = response.text
print("Cloudflare Bypassed:", "You bypassed the Cloudflare challenge! :D" in html) Observe que el script ni siquiera llegará a la sentencia final print(). En su lugar, fallará con:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://www.scrapingcourse.com/cloudflare-challengeComo puede ver, Cloudflare reconoció la solicitud como procedente de un script automatizado y la bloqueó con una respuesta 403 Forbidden.
Visitar páginas protegidas por Cloudflare con Playwright
Probemos ahora con una solución de automatización del navegador como Playwright:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# Go to the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# Wait for the desired text to be on the page
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Este script indica a un navegador Chromium que visite la página de destino. A continuación, utiliza un localizador para comprobar si aparece en la página un elemento que contenga el texto requerido, esperándolo automáticamente (por defecto, Playwright espera hasta 30 segundos).
Ejecute los comandos de instalación necesarios y ejecute el script anterior. Verá la siguiente salida:
Cloudflare Bypassed: FalseSi lo ejecutas en modo encabezado(headless=False), notarás que el script se queda atascado en la página de verificación de Cloudflare. Esto mostrará un CAPTCHA de Turnstile y espera a que se resuelva manualmente:

Nota: Si intenta automatizar el clic en la casilla Turnstile, la verificación fallará. Esto se debe a que Cloudflare es lo suficientemente inteligente como para detectar que se trata de un proceso automatizado y no de una interacción humana real.
Métodos de alto nivel para evitar Cloudflare
Explore tres enfoques que puede utilizar para eludir la protección de Cloudflare con su script automatizado.
Método nº 1: Evitar completamente Cloudflare
No olvide que Cloudflare actúa como una CDN, lo que significa que almacena en caché y distribuye el contenido del sitio a través de múltiples servidores dispersos geográficamente. Por lo tanto, los sitios distribuidos a través de Cloudflare normalmente solo son accesibles a través de los servidores de la red CDN.
Ahora, imagine que consigue descubrir la dirección IP del servidor del sitio detrás de la CDN. La consecuencia sería que podría interactuar con el sitio sin pasar por Cloudflare. Al fin y al cabo, Cloudflare solo puede evaluar las solicitudes que pasan por su red.
Eso es posible buscando en herramientas de búsqueda del historial DNS como SecurityTrails para identificar cualquier registro DNS histórico que revele la dirección IP del servidor original. Una vez obtenida la IP, puedes intentar enviar peticiones directamente al servidor, eludiendo Cloudflare.
El problema es que el servidor puede tener configuraciones adicionales para aceptar peticiones sólo desde el rango de IP de Cloudflare. Eso haría casi imposible conectarse al sitio directamente sin ser bloqueado. Además, encontrar con éxito la IP original del servidor es bastante difícil e improbable.
Método nº 2: Confiar en un solucionador de Cloudflare
En línea, puede encontrar varias bibliotecas gratuitas y de código abierto diseñadas para eludir Cloudflare. Algunas de las más populares son:
- cloudscraper: Un módulo Python que maneja los desafíos anti-bot de Cloudflare.
- Cfscrape: Un módulo PHP ligero para saltarse las páginas anti-bot de Cloudflare.
- Humanoid: Un paquete Node.js para eludir los retos anti-bot JavaScript de Cloudflare.
No es sorprendente que la mayoría de estos proyectos no hayan recibido actualizaciones en años. La razón es que los desarrolladores desistieron debido a la continua lucha por mantenerse al día con las actualizaciones de Cloudflare. Así que, por lo general, estas herramientas no funcionan durante mucho tiempo.
Método n.º 3: Utilizar una solución de automatización con funciones de desvío de Cloudflare
En la mayoría de los casos, la mejor solución para el scraping de un sitio protegido por Cloudflare es utilizar una solución de automatización todo en uno. Para ser eficaces, estas bibliotecas o servicios en línea deben ofrecer al menos las siguientes características:
- Renderizado de JavaScript, para que los retos de JavaScript de Cloudflare puedan ejecutarse correctamente.
- Falsificación de TLS, encabezado HTTP y huella digital del navegador para simular usuarios reales y evitar la detección.
- Capacidades de resolución de CAPTCHA de Turnstile, para manejar la verificación humana de Cloudflare cuando aparezca.
- Interacción simulada similar a la humana, como mover el ratón a lo largo de una curva B-spline para imitar el comportamiento natural del usuario.
Además, las soluciones premium suelen incluir una red proxy integrada para rotar las direcciones IP y reducir el riesgo de ser bloqueado.
En los dos capítulos siguientes, verá en acción soluciones de código abierto y, sobre todo, de pago.
Cómo evitar la comprobación humana de Cloudflare en Python
La mayoría de las soluciones de código abierto que pretenden eludir Cloudflare sólo consiguen hacerlo durante un periodo de tiempo limitado. Esto se debe a que es esencialmente un juego del gato y el ratón, y su naturaleza de código abierto (donde los ingenieros de Cloudflare pueden estudiar fácilmente su código) no ayuda.
Así que no es de extrañar que muchas herramientas que antes funcionaban (como Puppeteer Stealth) ya no consigan el objetivo. Aún así, en el momento de escribir este artículo, hay dos soluciones que realmente consiguen eludir las protecciones de Cloudflare:
- Camoufox: Un navegador Python antidetección de código abierto basado en una compilación personalizada de Firefox, diseñado para evadir la detección de bots y permitir el web scraping.
- SeleniumBase: Un conjunto de herramientas Python de código abierto y calidad profesional para la automatización web avanzada.
Veamos cómo se comportan ambos frente a la página de desafío de Cloudflare de ScrapingCourse.
Evitar el torniquete de Clouflare con Camoufox
Primero, instala Camoufox en tu proyecto Python con:
pip install camoufox[geoip]A continuación, recupere las dependencias adicionales necesarias con:
python -m camoufox fetchPara más información, consulte la guía oficial de instalación.
La biblioteca Camoufox Python está construida sobre Playwright, por lo que su API es muy similar. Visite el sitio de destino, espere a que aparezca el desafío Turnstile y gestiónelo (si realmente aparece) utilizando la siguiente lógica:
# pip install camoufox[geoip]
# python -m camoufox fetch
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
with Camoufox(
headless=False,
humanize=True,
window=(1280, 720) # So that the Turnstile checkbox is on coordinate (210, 290)
) as browser:
page = browser.new_page()
# Visit the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
# Wait for the Cloudflare Turnstile to appear and load
page.wait_for_load_state(state="domcontentloaded")
page.wait_for_load_state("networkidle")
page.wait_for_timeout(5000) # 5 seconds
# Ckick the Turnstile checkbox (if it is present)
page.mouse.click(210, 290)
try:
# Wait for the desired text to appear
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
# The text did not appear
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Observe que la lógica de manejo del torniquete es un poco complicada. Se basa en la suposición de que la casilla Torniquete aparecerá aproximadamente en la coordenada (210, 290) en una ventana de navegador de 1280×720.
Ejecute el script anterior y obtendrá el siguiente resultado:
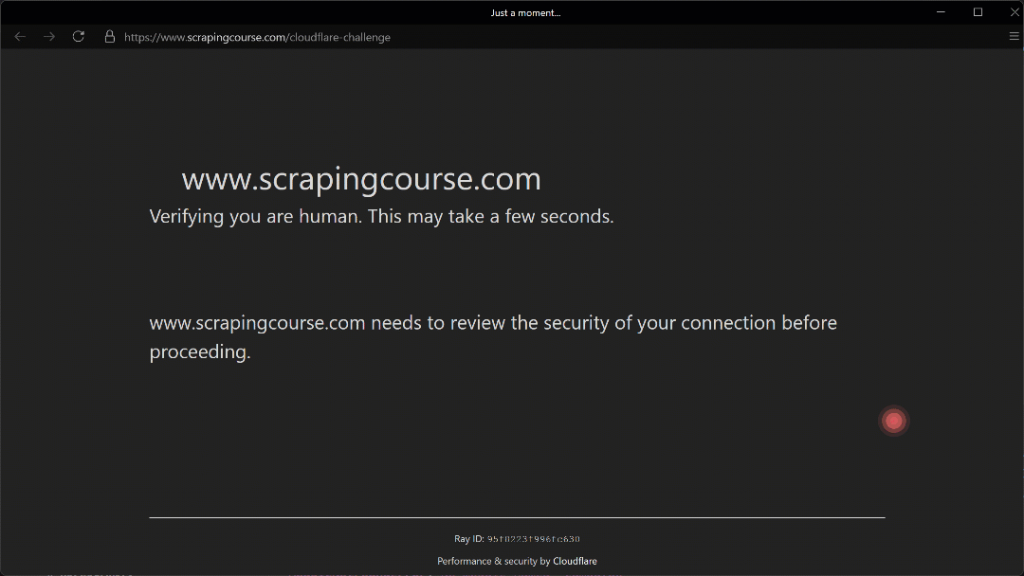
El movimiento automatizado del ratón hacia la coordenada (210, 290) parece realista gracias al parámetro Humanize=True.
Como se muestra aquí, Camoufox se las arregla con éxito para hacer clic en la casilla de verificación. Como resultado, en el terminal, verá esta salida:
Cloudflare Bypassed: TrueMisión cumplida.
Evite Clouflare con SeleniumBase
Instalar SeleniumBase con:
pip install seleniumbaseA continuación, utilizarlo para manejar Cloudflare con:
# pip install seleniumbase
from seleniumbase import Driver
from seleniumbase.common.exceptions import TextNotVisibleException
# Launch in undetected-chromedriver mode
driver = Driver(uc=True)
# Visit the target page
url = "https://www.scrapingcourse.com/cloudflare-challenge"
driver.uc_open_with_reconnect(url, 4)
# Click the Turnstile (if it is present) and reload the page
driver.uc_gui_click_captcha()
try:
# Wait for the desired text to appear
driver.wait_for_text("You bypassed the Cloudflare challenge! :D", "main")
challenge_bypassed = True
except TextNotVisibleException:
# The text did not appear
challenge_bypassed = False
# Close the browser and release its resources
driver.quit()
print("Cloudflare Bypassed:", challenge_bypassed) En el modo uc=True (que utiliza undetected-chromedriver bajo el capó), SeleniumBase puede aprovechar el método dedicado uc_gui_click_captcha () para manejar el CAPTCHA de Turnstile, si aparece. Esto significa que no hay necesidad de una lógica de clic personalizada esta vez.
Ejecute el script y debería verlo:
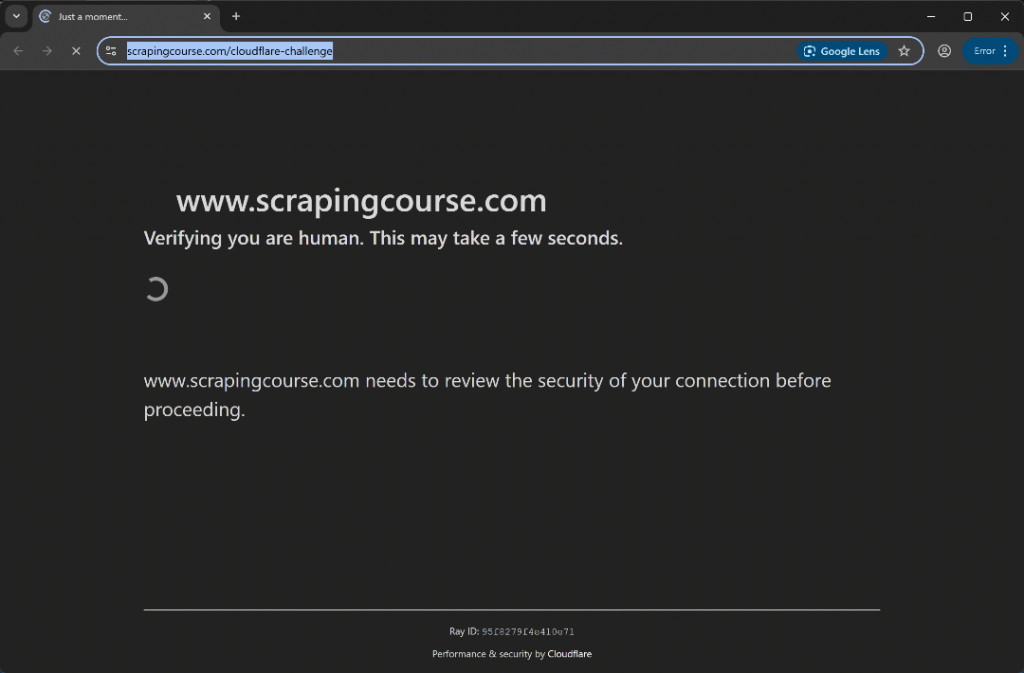
Esta vez, el script de automatización se salta la fase de verificación inicial sin siquiera activar el CAPTCHA de Turnstile. De cualquier forma, el método uc_gui_click_captcha () habría sido capaz de manejarlo con éxito. Esto es posible gracias al modo UC, del que puedes aprender más en nuestra guía de scraping de SeleniumBase.
¡Et voilà! Cloudflare puenteado una vez más.
Cómo evitar Cloudflare a gran escala
Las dos bibliotecas presentadas anteriormente funcionan bien para scripts de automatización sencillos, pero tienen tres inconvenientes importantes:
- Para lograr un alto porcentaje de resultados efectivos, necesitan ejecutar los navegadores en modo encabezado. Esto consume muchos recursos del sistema y dificulta la escalabilidad.
- Son inconsistentes y pueden dejar de funcionar temporalmente si Cloudflare actualiza su lógica de detección. Dado que estas soluciones son mantenidas por la comunidad, las actualizaciones pueden tardar días o incluso semanas en publicarse.
- No hay asistencia oficial. Debes confiar en los recursos online y en la ayuda de la comunidad.
Por estas razones, no se recomiendan las bibliotecas de código abierto con capacidades de derivación de Cloudflare para proyectos de producción. Para obtener resultados más escalables y coherentes, y el respaldo de un equipo de asistenciadedicado las 24 horas del día, los 7 días de la semana,necesita productos de primera calidad como los que ofrece Bright Data.
En concreto, aquí nos centraremos en las dos soluciones siguientes:
- Desbloqueador Web: Un endpoint de scraping todo en uno que incluye todas las capacidades de bypass anti-bot para recuperar HTML de cualquier sitio.
- Navegador API: Un navegador en la nube infinitamente escalable construido para soportar cualquier flujo de trabajo de automatización. Se integra con Puppeteer, Selenium, Playwright y cualquier otra herramienta de automatización del navegador. Incluye gestión avanzada de huellas dactilares, solución CAPTCHA integrada y rotación automática de proxy.
Vea cómo integrar estas herramientas en Python (aunque admiten cualquier lenguaje de programación) en sus scripts de automatización.
Evitar Cloudflare con Web Unlocker
Antes de empezar, siga la guía oficial para configurar Web Unlocker de forma gratuita en su cuenta de Bright Data. También necesitará generar una clave API de Bright Data para autenticar sus solicitudes al punto final de Web Unlocker.
Aquí, asumiremos que el nombre de su zona Web Unlocker es web_unlocker.
Una vez que haya completado los pasos anteriores, pruebe Web Unlocker con la página de destino utilizada en este artículo:
# pip install requests
import requests
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
data = {
"zone": "web_unlocker", # Replace with the name of your Web Unlocker zone
"url": "https://www.scrapingcourse.com/cloudflare-challenge",
"format": "raw"
}
# Perform a request to the Web Unlocker endpoint
response = requests.post(
"https://api.brightdata.com/request",
json=data,
headers=headers
)
# Get the response and check if Cloudflare was bypassed
html = response.text
print("Cloudflare Bypassed:", "You bypassed the Cloudflare challenge! :D" in html)Web Unlocker devolverá el contenido HTML de la página detrás del muro de verificación de Cloudflare. En concreto, la variable html contendrá contenido como este:
<!doctype html>
<html lang="en"><head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Cloudflare Challenge - ScrapingCourse.com</title>
<!-- omitted for brevity ... -->
<main class="page-content py-4" id="main-content" data-testid="main-content" data-content="main">
<div class="container" id="content-container" data-testid="content-container" data-content="container">
<div class="cloudflareChallenge">
<h1 id="page-title" class="page-title text-4xl font-bold mb-2 text-left gradient-text highlight gradient-text leading-10" data-testid="page-title" data-content="title">
Cloudflare Challenge
</h1>
<div class="challenge-info bg-[#EDF1FD] rounded-md p-4 mb-8 mt-5" id="challenge-info" data-testid="challenge-info" data-content="challenge-info">
<div class="info-header flex items-center gap-2 pb-2" id="info-header" data-testid="info-header" data-content="info-header">
<img width="25" height="15" src="https://www.scrapingcourse.com/assets/images/challenge.svg" data-testid="challenge-image" data-content="challenge-image">
<h2 class="challenge-title text-xl font-bold" id="challenge-title" data-testid="challenge-title" data-content="challenge-title">
You bypassed the Cloudflare challenge! 😀
</h2>
</div>
</div>
</div>
</div>
</main>
<!-- omitted for brevity ... -->
</html>Este es exactamente el contenido HTML de la página detrás del muro de verificación humana de Cloudflare. Por lo tanto, no es de extrañar que la salida de la secuencia de comandos será:
Cloudflare Bypassed: TrueTenga en cuenta que sólo se le cobrará por las solicitudes aceptadas y que puede probarlo gratis.
Automatización de Cloudflare con la API del navegador
Como requisito previo, configure un producto Browser API en su cuenta de Bright Data. En la página de zona, copie la URL de conexión CDP de Playwright:
Esta URL contiene sus credenciales y le permite indicar a cualquier solución de automatización del navegador que admita CDP remoto(Chrome DevTools Protocol) que se conecte a la API del navegador de Bright Data. En otras palabras, su herramienta de automatización funcionará en una instancia de navegador alojada remotamente y gestionada por Bright Data. Esto significa que la escalabilidad y el mantenimiento del navegador se gestionan por usted.
Amplíe el script Playwright mostrado anteriormente para conectarse a la API del navegador a través de la URL CDP:
# pip install playwright
# python install -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
BRIGHT_DATA_API_CDP_URL = "<YOUR_BRIGHT_DATA_API_CDP_URL>" # Replace with your Browser API Playwright CDP URL
with sync_playwright() as p:
# Connect to the remote Browser API
browser = p.chromium.connect_over_cdp(BRIGHT_DATA_API_CDP_URL)
page = browser.new_page()
# Go to the target page
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# Wait for the desired text to be on the page
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# Close the browser and release its resources
browser.close()
print("Cloudflare Bypassed:", challenge_bypassed)Esta vez, el script evitará con éxito la verificación de Cloudflare gracias a las capacidades avanzadas de la API del navegador. Verás la siguiente salida en el terminal:
Cloudflare Bypassed: True¡Bien hecho! Cloudflare bypass ya no es un problema.
Conclusión
En este artículo, has aprendido cómo funciona Cloudflare y has explorado soluciones prácticas para evitarlo en tus flujos de trabajo de automatización. Como has visto aquí, eludir las medidas anti-scraping de Cloudflare es un reto, pero ciertamente posible.
Independientemente del enfoque que elija, todo resulta más fácil con soluciones profesionales, rápidas y fiables como:
- Desbloqueador Web: Un endpoint que se salta automáticamente la limitación de velocidad, la huella digital y otras restricciones anti-bot por ti.
- Navegador API: Un navegador totalmente alojado que permite automatizar la interacción con cualquier página web.
Regístrese ahora gratuitamente y descubra cuál de las soluciones de Bright Data se adapta mejor a sus necesidades.