

En esta guía aprenderás:
- Qué es Undetected ChromeDriver y cómo puede ser útil
- Cómo minimiza la detección de bots
- Cómo utilizarlo con Python para el Scraping web
- Usos y métodos avanzados
- Sus principales limitaciones e inconvenientes
- Tecnologías similares
¡Empecemos!
¿Qué es Undetected ChromeDriver?
Undetected ChromeDriveres una biblioteca de Python que proporciona una versión optimizada del ChromeDriver de Selenium. Se ha parcheado para limitar la detección por parte de servicios antibots como:
- Imperva
- DataDome
- Distil Networks
También puede ayudar a eludir ciertas protecciones de Cloudflare, aunque eso puede ser más complicado. Para obtener más detalles, siga nuestra guía sobrecómo eludir Cloudflare.
Si alguna vez ha utilizadoherramientas de automatización de navegadorescomo Selenium, sabrá que le permiten controlar los navegadores mediante programación. Para que eso sea posible, configuran los navegadores de forma diferente a las configuraciones habituales de los usuarios.
Los sistemas antibots buscan esas diferencias, o «fugas», para identificar los bots de navegador automatizados. ChromeDriver, que pasa desapercibido, parchea los controladores de Chrome para minimizar estos signos reveladores, lo que reduce la detección de bots. Esto lo hace ideal para sitios web protegidos pormedidas antirraspado.
Cómo funciona
Undetected ChromeDriver reduce la detección de Cloudflare, Imperva, DataDome y soluciones similares mediante el empleo de las siguientes técnicas:
- Renombrar las variables de Selenium para imitar las utilizadas por los navegadores reales.
- Utilizar cadenas de agente de usuario legítimas y reales para evitar la detección.
- Permitir al usuario simular una interacción humana natural.
- Gestionar correctamente las cookies y las sesiones mientras se navega por los sitios web.
- Habilitar el uso de Proxies para eludir el bloqueo de IP y evitar la limitación de velocidad
Estos métodos ayudan al navegador controlado por la biblioteca a eludir eficazmente diversas defensas contra el scraping.
Uso de ChromeDriver no detectado para el Scraping web: guía paso a paso
La mayoría de los sitios utilizan medidas avanzadas contra los bots para bloquear el acceso de scripts automatizados a sus páginas. Estos mecanismos también detienen eficazmente alos bots de Scraping web.
Por ejemplo, supongamos que desea extraer el título y la descripción de la siguientepágina de productos de GoDaddy:
Con Selenium simple en Python, su script de scraping tendrá un aspecto similar a este:
# pip install selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# configurar una instancia de Chrome para que se inicie en modo sin interfaz gráfica
options = Options()
options.add_argument("--headless")
# crear una instancia del controlador web Chrome
driver = webdriver.Chrome(service=Service(), options=options)
# conectarse a la página de destino
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
# lógica de scraping...
# cerrar el navegador
driver.quit()
Si no estás familiarizado con esta lógica, echa un vistazo a nuestra guía sobreel Scraping web con Selenium.
Cuando ejecute el script, fallará debido a esta página de error:

En otras palabras, el script de Selenium ha sido bloqueado por una solución antibots (Akamai, en este ejemplo).
Entonces, ¿cómo se puede solucionar esto? ¡La respuesta es Undetected ChromeDriver!
Siga los pasos que se indican a continuación para aprender a utilizar la biblioteca Python undetected_chromedriver para el Scraping web.
Paso n.º 1: Requisitos previos y configuración del proyecto
Undetected ChromeDriver tiene los siguientes requisitos previos:
- Última versión de Chrome
- Python 3.6+: si no tienes instalado Python 3.6 o posterior en tu equipo,descárgalo desde el sitio web oficialy sigue las instrucciones de instalación.
Nota: La biblioteca descarga y parchea automáticamente el binario del controlador, por lo que no es necesario descargarChromeDriver manualmente.
Ahora, utilice el siguiente comando para crear un directorio para su proyecto:
mkdir undetected-chromedriver-Scraper
El directorio undetected-chromedriver-scraper servirá como carpeta de proyecto para su Scraper Python.
Acceda a él e inicialice unentorno virtual:
cd undetected-chromedriver-Scraper
python -m venv env
Abra la carpeta del proyecto en su IDE de Python preferido.Visual Studio Code con la extensión PythonoPyCharm Community Editionson dos excelentes opciones.
A continuación, crea un archivoscraper.pydentro de la carpeta del proyecto, siguiendo la estructura que se muestra a continuación:
Actualmente,scraper.pyes un script Python vacío. En breve, le añadirás la lógica de rastreo.
En la terminal de tu IDE, activa el entorno virtual. En Linux o macOS, utiliza:
./env/bin/activate
De forma equivalente, en Windows, ejecuta:
env/Scripts/activate
¡Genial! Ahora ya tienes un entorno Python listo para el Scraping web mediante la automatización del navegador.
Paso n.º 2: Instalar Undetected ChromeDriver
En un entorno virtual activado, instala Undetected ChromeDriver a través del paquete pipundetected_chromedriver:
pip install undetected_chromedriver
En segundo plano, esta biblioteca instalará automáticamente Selenium, ya que es una de sus dependencias. Por lo tanto, no es necesario instalar Selenium por separado. Esto también significa que tendrás acceso a todas las importaciones de Selenium de forma predeterminada.
Paso n.º 3: configuración inicial
Importe undetected_chromedriver:
import undetected_chromedriver as uc
A continuación, puede inicializar un Chrome WebDriver con:
driver = uc.Chrome()
Al igual que Selenium, esto abrirá una ventana del navegador que podrá controlar mediante la API de Selenium. Esto significa que el objeto driver expone todos los métodos estándar de Selenium, junto con algunas características adicionales que exploraremos más adelante.
La diferencia clave es que esta versión del controlador Chrome está parcheada para ayudar a eludir ciertas soluciones antibots.
Para cerrar el controlador, simplemente llame al método quit():
driver.quit()
Así es como se ve una configuración básica de Undetected ChromeDriver:
import undetected_chromedriver as uc
# Inicializar una instancia de Chrome
driver = uc.Chrome()
# Lógica de scraping...
# Cerrar el navegador y liberar sus recursos
driver.quit()
¡Fantástico! Ahora ya está listo para realizar el Scraping web directamente en el navegador.
Paso n.º 4: utilizarlo para el Scraping web
Advertencia: esta sección sigue los mismos pasos que una configuración estándar de Selenium. Si ya está familiarizado con el Scraping web de Selenium, puede pasar directamente a la siguiente sección con el código final.
En primer lugar, utiliza el método get() para navegar con el navegador hasta la página de destino:
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
A continuación, visite la página en modo incógnito en su navegador e inspeccione el elemento que desea extraer:
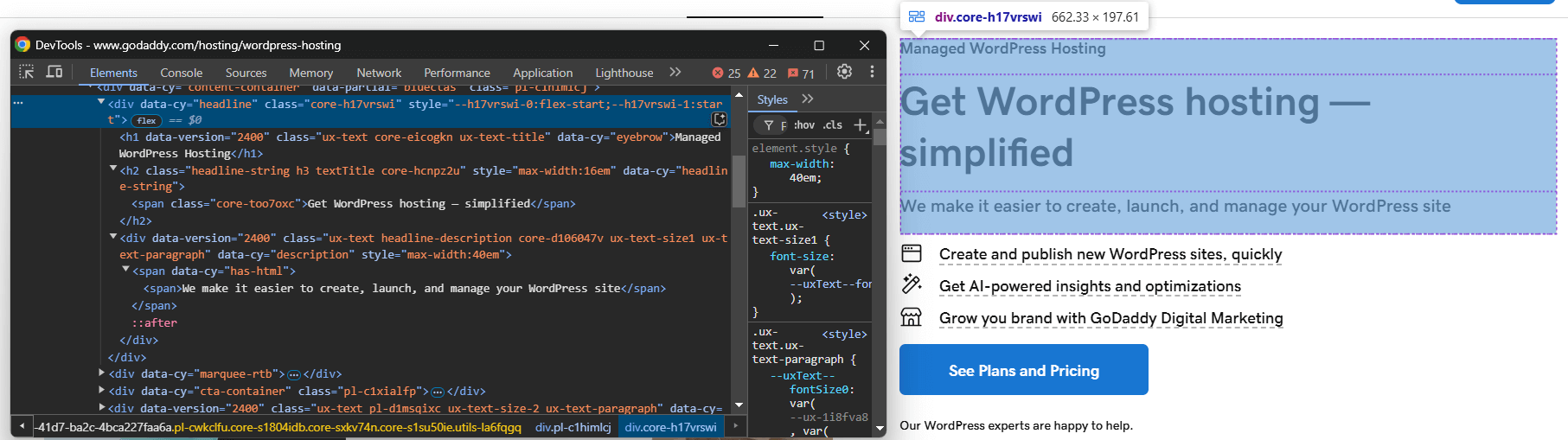
Supongamos que desea extraer el título, el eslogan y la descripción del producto.
Puede extraer todo esto con el siguiente código:
headline_element = driver.find_element(By.CSS_SELECTOR, "[data-cy="headline"]")
title_element = headline_element.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
tagline_element = headline_element.find_element(By.CSS_SELECTOR, "h2")
tagline = tagline_element.text
description_element = headline_element.find_element(By.CSS_SELECTOR, "[data-cy="description"]")
description = description_element.text
Para que el código anterior funcione, es necesario importar By desde Selenium:
from selenium.webdriver.common.by import By
Ahora, almacene los datos extraídos en un diccionario de Python:
product = {
"title": title,
"tagline": tagline,
"description": description
}
Por último, exporte los datos a un archivo JSON:
with open("product.json", "w") as json_file:
json.dump(product, json_file, indent=4)
No olvides importar json desde la biblioteca estándar de Python:
import json
¡Y ya está! Acaba de implementar la lógica básica de Scraping web de Undetected ChromeDriver.
Paso n.º 5: Ponlo todo junto
Este es el script de scraping final:
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
# Crear una instancia del controlador web Chrome
driver = uc.Chrome()
# Conectarse a la página de destino
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
# Lógica de scraping
headline_element = driver.find_element(By.CSS_SELECTOR, "[data-cy="headline"]")
title_element = headline_element.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
tagline_element = headline_element.find_element(By.CSS_SELECTOR, "h2")
tagline = tagline_element.text
description_element = headline_element.find_element(By.CSS_SELECTOR, "[data-cy="description"]")
description = description_element.text
# Rellenar un diccionario con los datos extraídos
producto = {
"título": título,
"eslogan": eslogan,
"descripción": descripción
}
# Exportar los datos extraídos a JSON
con open("producto.json", "w") como archivo_json:
json.dump(producto, archivo_json, sangría=4)
# Cerrar el navegador y liberar sus recursos
driver.quit()
Ejecutarlo con:
python3 Scraper.py
O, en Windows:
python Scraper.py
Esto abrirá un navegador que mostrará la página web de destino, no la página de error como ocurre con Selenium vanilla:
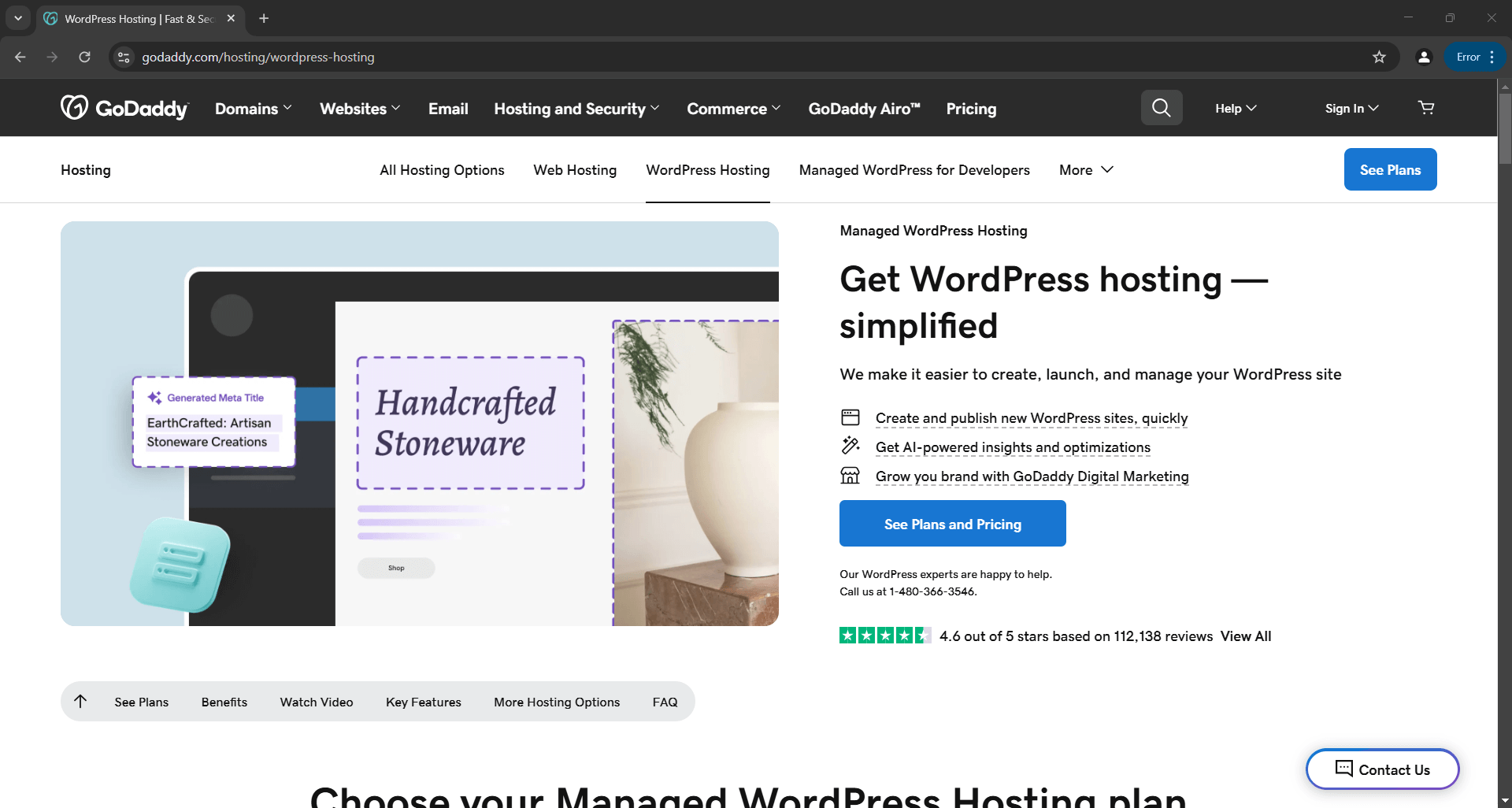
El script extraerá los datos de la página y generará el siguiente archivo product.json:
{
"title": "Alojamiento gestionado de WordPress",
"tagline": "Consigue alojamiento para WordPress de forma simplificada",
"description": "Facilitamos la creación, el lanzamiento y la gestión de tu sitio de WordPress"
}
undetected_chromedriver: uso avanzado
Ahora que ya sabe cómo funciona la biblioteca, está listo para explorar algunos escenarios más avanzados.
Elija una versión específica de Chrome
Puede especificar una versión concreta de Chrome para que la utilice la biblioteca configurando el argumento version_main:
import undetected_chromedriver as uc
# Especifica la versión de Chrome deseada
driver = uc.Chrome(version_main=105)
Tenga en cuenta que la biblioteca también funciona con otros navegadores basados en Chromium, pero eso requiere algunos ajustes adicionales.
con Sytnax
Para evitar llamar manualmente al métodoquit()cuando ya no necesite el controlador, puede utilizar la sintaxiswithcomo se muestra a continuación:
import undetected_chromedriver as uc
with uc.Chrome() as driver:
driver.get("<YOUR_URL>")
Cuando se complete el código dentro del bloque with, Python cerrará automáticamente el navegador por usted.
Nota: Esta sintaxis es compatible a partir de la versión 3.1.0.
Integración de Proxy
La sintaxis para añadir un Proxy a Undetected ChromeDriver es similar a la de Selenium normal. Simplemente pase la URL de su Proxy al indicador --proxy-server como se muestra a continuación:
import undetected_chromedriver as uc
proxy_url = "<YOUR_PROXY_URL>"
options = uc.ChromeOptions()
options.add_argument(f"--proxy-server={proxy}")
Nota: Chrome no admite proxies autenticados a través del indicador --proxy-server.
API ampliada
undetected_chromedriver amplía la funcionalidad habitual de Selenium con algunos métodos, entre los que se incluyen:
WebElement.click_safe(): utilice este método si al hacer clic en un enlace se produce una detección. Aunque no se garantiza que funcione, ofrece un enfoque alternativo para hacer clics más seguros.WebElement.children(tag=None, recursive=False): este método le ayuda a encontrar fácilmente elementos secundarios. Por ejemplo:
# Obtenga el sexto elemento secundario (de cualquier etiqueta) dentro del cuerpo y, a continuación, busque todos los elementos <img> de forma recursiva.
images = body.children()[6].children("img", True)
Limitaciones de la biblioteca Python undetected_chromedriver
Aunque undetected_chromedriver es una potente biblioteca de Python, tiene algunas limitaciones conocidas. ¡Estas son las más importantes que debes tener en cuenta!
Bloqueos de IP
La página de GitHub de la biblioteca lo deja claro:el paquete no oculta tu dirección IP. Por lo tanto, si estás ejecutando un script desde un centro de datos, es muy probable que se produzca la detección. Del mismo modo, si la IP de tu casa tiene mala reputación, ¡también es posible que te bloqueen!

Para ocultar tu IP, debes integrar el navegador controlado con un Proxy, como se ha mostrado anteriormente.
No es compatible con la navegación GUI
Debido al funcionamiento interno del módulo, debes navegar mediante programación utilizando el método get(). Evita utilizar la GUI del navegador para la navegación manual, ya que interactuar con la página mediante el teclado o el ratón aumenta el riesgo de detección.
La misma regla se aplica al manejo de nuevas pestañas. Si necesita trabajar con varias pestañas, abra una nueva pestaña con una página en blanco utilizando la URL data: ( sí, incluyendo la coma) , que el controlador acepta. Después, continúe con su lógica de automatización habitual.
Solo si sigue estas directrices podrá minimizar la detección y disfrutar de sesiones de Scraping web más fluidas.
Compatibilidad limitada con el modo sin interfaz gráfica
Oficialmente, el modo sin interfaz no es totalmente compatible con la biblioteca undetected_chromedriver. Sin embargo, puede probarlo utilizando la siguiente sintaxis:
driver = uc.Chrome(headless=True)
El autor anunció en el registro de cambios de la versión 3.4.5 que el modo sin interfaz debería funcionar y garantizar la capacidad de elusión de bots. Sin embargo, sigue siendo inestable. Utilice esta función con precaución y realice pruebas exhaustivas para asegurarse de que satisface sus necesidades de scraping.
Problemas de estabilidad
Como se menciona en la página PyPI del paquete, los resultados pueden variar debido a numerosos factores. No se ofrecen garantías, salvo el esfuerzo continuo por comprender y contrarrestar los algoritmos de detección.
Esto significa que un script que hoy elude con éxito Distil, Cloudflare, Imperva, DataDome o hCaptcha podría fallar mañana si las soluciones antibots reciben actualizaciones:
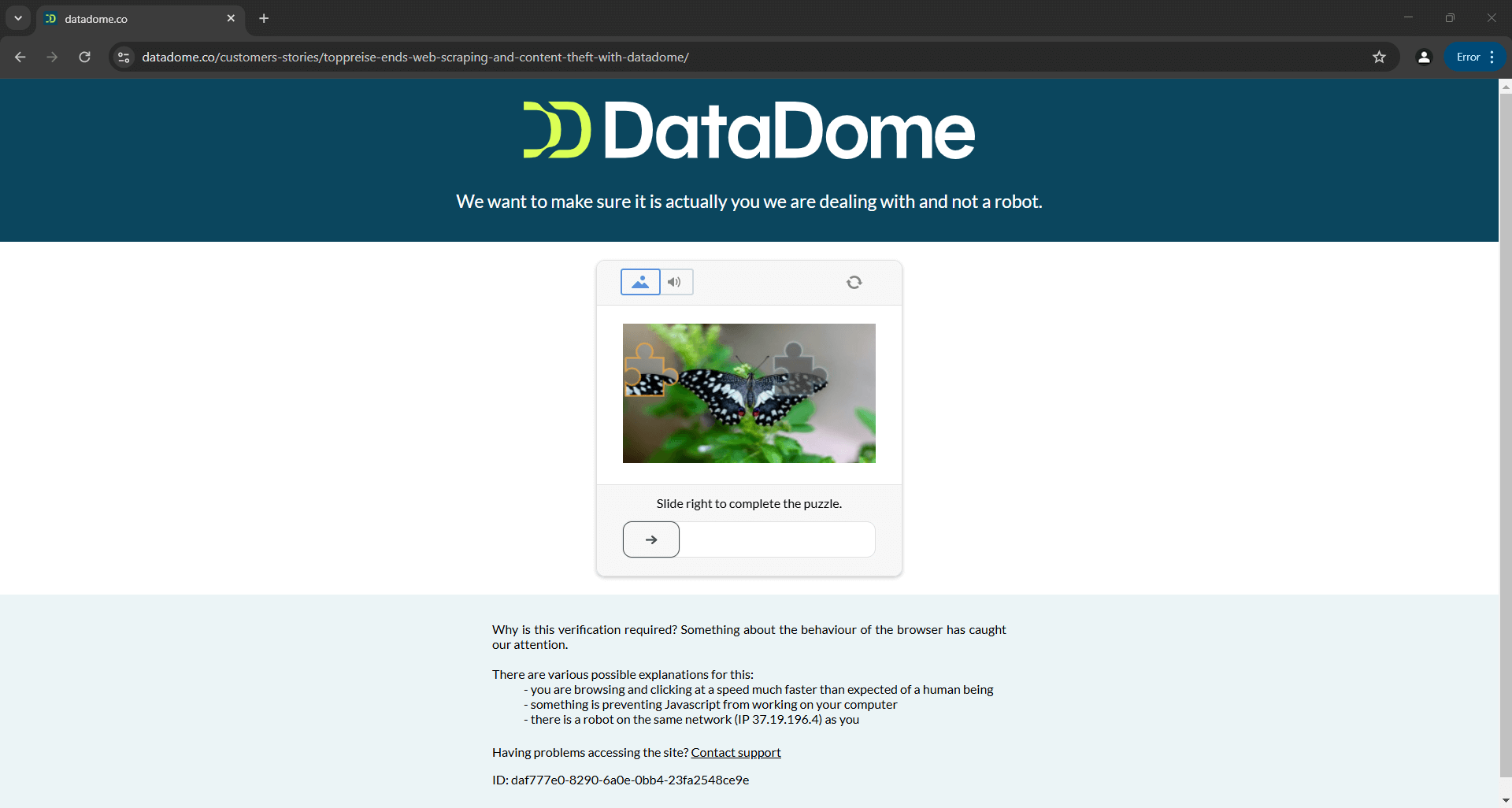
La imagen anterior es el resultado de un script proporcionado en la documentación oficial. Esto demuestra que incluso los scripts creados por los desarrolladores de la herramienta pueden no funcionar siempre como se espera. En concreto, el script activó un CAPTCHA, que puede detener fácilmente su lógica de automatización.
Obtenga más información en nuestra guía sobrecómo eludir los CAPTCHA en Python.
Lecturas adicionales
Undetected ChromeDriver no es la única biblioteca que modifica los controladores del navegador para evitar su detección. Si te interesa explorar herramientas similares u obtener más información sobre este tema, lee estas guías:
- Evita que te bloqueen con Puppeteer Stealth
- Evite la detección de bots con Playwright Stealth
- Guía para el Scraping web con SeleniumBase
Conclusión
En este artículo, ha aprendido a lidiar con la detección de bots en Selenium utilizando Undetected ChromeDriver. Esta biblioteca proporciona una versión parcheada de ChromeDriver para el Scraping web sin ser bloqueado.
El problema es que las tecnologías antibots avanzadas, como Cloudflare, seguirán siendo capaces de detectar y bloquear tus scripts. Las bibliotecas como undetected_chromedriver son inestables: aunque hoy funcionen, es posible que mañana no lo hagan.
El problema no radica en la API de Selenium para controlar un navegador, sino en la propia configuración del navegador. Esto implica que la solución es un navegador basado en la nube, siempre actualizado y escalable, con una función integrada para eludir los antibots. Ese navegador existe y se llamaNavegador de scraping.
El Navegador de scraping de Bright Data es un navegador en la nube altamente escalable que funciona conSelenium,Puppeteer,Playwright y muchos más. Puede gestionar las huellas digitales del navegador, la resolución de CAPTCHA y los reintentos automáticos por usted. Además, rota automáticamente la IP de salida en cada solicitud. Esto es posible gracias a la red mundial de proxies que incluye:
- Proxy de centro de datos: más de 770 000 IP de centros de datos.
- Proxies residenciales: más de 72 millones de IPs residenciales en más de 195 países.
- Proxies ISP: más de 700 000 IP de ISP.
Cree hoy mismo una cuenta gratuita en Bright Data para probar nuestro navegador de scraping o nuestros Proxies.




