

En esta entrada del blog, verás:
- Qué es Convex, cómo funciona su modelo mental y cómo se compara con otras bases de datos.
- Cómo funciona en detalle y los componentes básicos en los que se basa.
- Por qué destaca Convex cuando se utiliza para almacenar datos web en tiempo real.
- Los principales obstáculos y retos a la hora de obtener datos en directo de la web.
- Cómo Bright Data ayuda a superar esos retos proporcionando datos web estructurados y en tiempo real listos para su almacenamiento en Convex.
- Cómo empezar con una demostración completa que combina Bright Data para la recuperación de datos web y Convex para el almacenamiento de datos y actualizaciones fluidas de la interfaz de usuario.
¡Vamos a ello!
Una introducción a Convex
El primer paso es explorar Convex para comprender qué es, qué aporta y el modelo mental subyacente que lo sustenta.
¿Qué es Convex?
Convex es una plataforma de backend reactiva y de código abierto diseñada para mantener sincronizadas tus aplicaciones web y móviles.
En su interior, combina una base de datos, funciones sin servidor, autenticación y bibliotecas de cliente en un único sistema. Al igual que los componentes de React responden a los cambios de estado, las consultas de Convex reaccionan automáticamente a las actualizaciones de la base de datos, lo que la hace ideal para aplicaciones dinámicas en tiempo real.
Las consultas se escriben en TypeScript y se ejecutan directamente en la base de datos, lo que simplifica el desarrollo y permite crear aplicaciones rápidas y reactivas con una sobrecarga mínima de infraestructura. La solución también admite componentes modulares, sincronización de datos en tiempo real, programación y generación de código asistida por IA. Se integra con marcos como React, Next.js, Vue, Svelte y Nuxt, al tiempo que es compatible con aplicaciones en Python, Swift (para iOS), Kotlin (para Android) y Rust.
Su flexibilidad la ha hecho popular entre los desarrolladores, con más de 10 900 estrellas en GitHub y más de 400 000 descargas semanales en npm.
La idea central detrás de Convex: comprender su modelo mental
A diferencia de las bases de datos tradicionales, Convex trata la base de datos como un sistema activo y reactivo, en lugar de un mero almacenamiento pasivo de datos. Cada vez que se añaden, actualizan o eliminan datos, el cambio se registra en un registro de transacciones inmutable. Se trata de un historial permanente, con marca de tiempo, de todas las operaciones. Al mismo tiempo, las consultas no se limitan a recuperar datos. Realizan un seguimiento automático de los datos que han leído, lo que se conoce como sus «conjuntos de lectura».
Esto permite a Convex detectar inmediatamente cuando cambia alguno de los datos de los que depende una consulta, lo que permite al sistema actualizar los resultados en tiempo real. Esta arquitectura admite suscripciones en tiempo real y mantiene una fuerte consistencia a través de transacciones determinísticas y un mecanismo de control de concurrencia optimista. Gracias a estas características, varios usuarios pueden interactuar simultáneamente con la base de datos sin conflictos.
Convex frente a otras bases de datos
Para comprender mejor cómo se posiciona Convex frente a otras bases de datos populares, consulte la tabla comparativa a continuación:
| Característica | Convex | Firebase | Supabase | Bases de datos SQL tradicionales |
|---|---|---|---|---|
| Tipo de base de datos | Almacén de documentos transaccional | NoSQL / Firestore | PostgreSQL | SQL relacional |
| En tiempo real | ✔️ (Integrado, suscripciones automáticas) | ✔️ (Integrado) | ➖ (Opcional, a través de un servidor independiente) | ❌ (No nativo) |
| Transacciones | Siempre transaccional | Limitadas | Compatible | Compatible |
| Esquema | Opcional, gradual, generado automáticamente desde TypeScript | Flexible / sin esquema | Obligatorio (Postgres) | Estricto, manual |
| Compatibilidad con SQL | ❌ | ❌ | ✔️ | ✔️ |
| Integración con TypeScript | Completa | Limitada | Parcial, del lado del servidor | Depende del ORM |
| Auth/OAuth | Estándar + nativo | Estándar + Autenticación de Firebase | Estándar + nativo | Configuración personalizada |
| Responsabilidad de la base de datos | Gestionada íntegramente por Convex | Compartida | Compartida | Gestionado íntegramente por el desarrollador |
Cómo funciona Convex: arquitectura, componentes y flujo de datos
La arquitectura de Convex se basa en una plataforma de backend full-stack con tres componentes principales:
- Base de datos: un almacén reactivo y relacional de documentos donde los objetos de tipo JSON se organizan en tablas. La base de datos de Convex se aprovisiona automáticamente en la nube para cada proyecto, sin necesidad de configurar manualmente la conexión ni gestionar clústeres.
- Funciones de servidor: Las consultas y mutaciones se escriben como funciones de TypeScript, lo que elimina la necesidad de SQL u ORM. Las consultas son puras y de solo lectura, mientras que las mutaciones se ejecutan en transacciones totalmente gestionadas con garantías ACID, aislamiento serializable y control de concurrencia optimista.
- Bibliotecas de cliente: Bibliotecas específicas para cada marco (Next.js, React, Vue, Svelte, etc.) que se suscriben a las funciones de servidor, sincronizando automáticamente los resultados y gestionando las colas de mutaciones. Garantizan actualizaciones consistentes de la interfaz de usuario en tiempo real sin necesidad de suscripciones manuales ni gestión del estado.
Con estos tres componentes, los datos fluyen de forma reactiva desde la base de datos al cliente a través de funciones de servidor. Las consultas rastrean automáticamente las dependencias, volviendo a ejecutarse cuando los datos cambian y enviando las actualizaciones en tiempo real. Las mutaciones se ejecutan como transacciones totalmente gestionadas, actualizando la base de datos y las consultas dependientes, lo que garantiza que los clientes vean siempre el estado actualizado sin necesidad de sincronización manual.
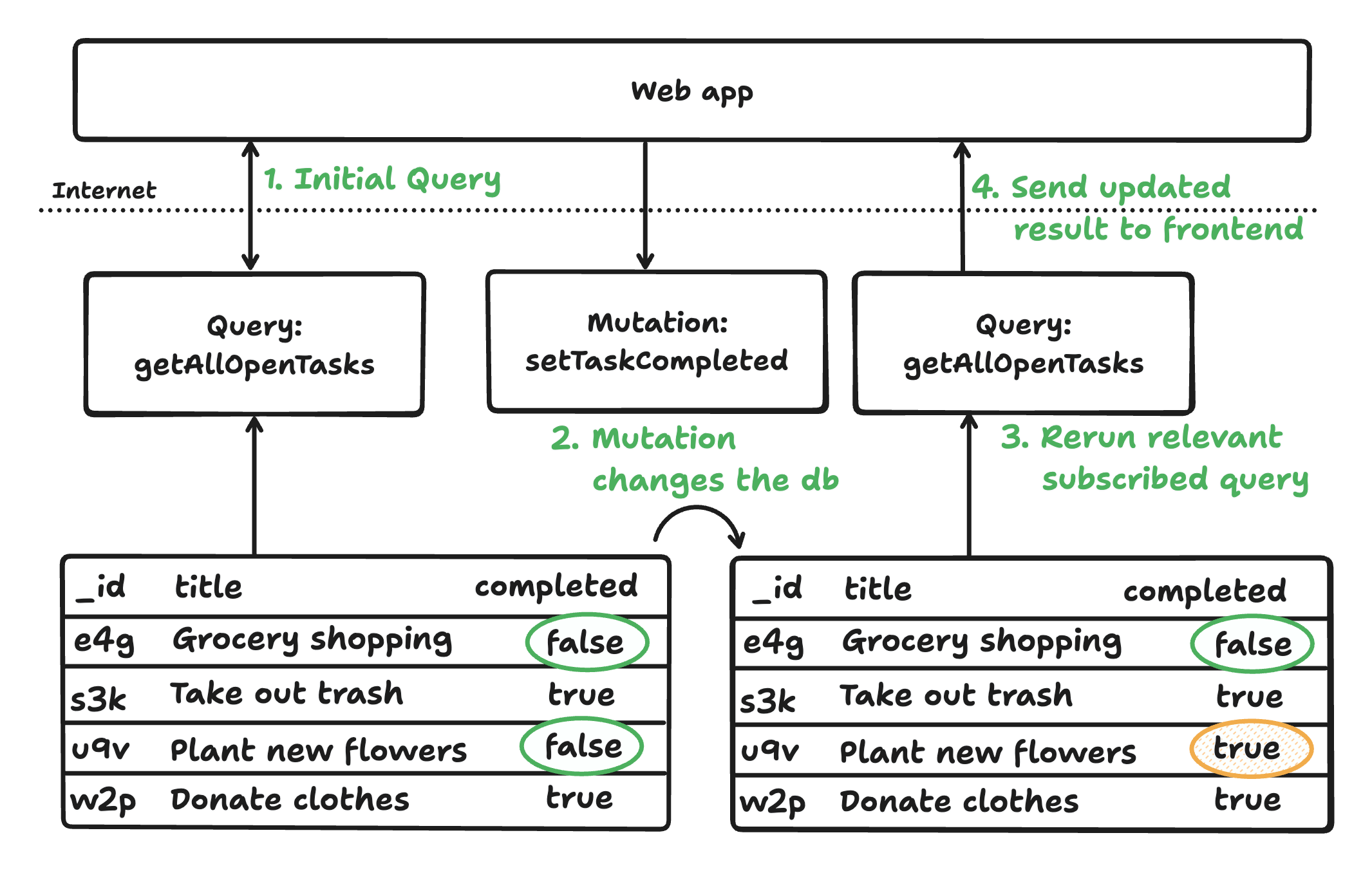
La arquitectura cohesionada de Convex garantiza aplicaciones reactivas, coherentes y seguras en cuanto a tipos con un mínimo de código repetitivo. Admite el desarrollo rápido tanto de código generado por humanos como por IA, abstrayendo el ajuste y la sincronización de la base de datos. Convex también ofrece autenticación, programación y mucho más.
Por qué Convex y los datos web en tiempo real son la combinación perfecta
Una base de datos en tiempo real como Convex solo alcanza su máximo potencial cuando la propia fuente de datos es en tiempo real. En otras palabras, su arquitectura reactiva es perfecta para aplicaciones que necesitan reflejar condiciones en directo (por ejemplo, cotizaciones bursátiles, feeds de redes sociales, actualizaciones de noticias o inventarios de comercio electrónico).
Ahora bien, ¿cuál es la mayor fuente de datos dinámicos y en constante cambio del planeta? ¡La web! Los datos web fluyen desde millones de fuentes en tiempo real, lo que los convierte en la entrada ideal para una aplicación reactiva basada en Convex.
Al conectar Convex a flujos de datos web en tiempo real, tu aplicación puede reaccionar inmediatamente a las actualizaciones sin necesidad de sondeos complejos, sincronización manual ni gestión de estados. Esto elimina la latencia entre la información y la interfaz de usuario, creando una experiencia de usuario fluida y siempre actualizada.
Retos a la hora de conectar datos web a una aplicación Convex
Ahora ya entiendes por qué los datos web en tiempo real son la combinación perfecta para una solución como Convex. La siguiente pregunta es: ¿cómo se recuperan realmente? La respuesta es el Scraping web, el proceso de extraer información de páginas web mediante programación.
El scraping web es un enfoque potente, pero conlleva varios retos. Estos van desde obstáculos técnicos hasta complejidad operativa, incluyendo:
- Contenido dinámico: los sitios web modernos se basan en JavaScript, AJAX y patrones complejos de navegación e interacción, lo que dificulta la extracción de datos estructurados.
- Medidas anti-bot: muchos sitios web utilizan CAPTCHAs, límites de frecuencia, huellas digitales y otras defensas para detectar y bloquear el acceso automatizado.
- Cambios frecuentes: los diseños, las estructuras HTML y las URL cambian a menudo, lo que inutiliza los Scrapers y requiere una supervisión y un mantenimiento continuos.
- Escalabilidad: la recopilación de datos a gran escala exige una infraestructura sólida, la integración con un proveedor de Proxy de confianza para la rotación de IP y un manejo robusto de los errores.
- Consistencia de los datos: Garantizar la precisión, la integridad y la actualidad de los datos es un reto, especialmente en el caso de los datos que se actualizan con frecuencia.
Como resultado, crear una aplicación Convex totalmente reactiva basada en datos web es una tarea abrumadora. En lugar de lidiar con estos obstáculos por tu cuenta, el enfoque perfecto es confiar en un proveedor de datos web en tiempo real preparado para empresas, como Bright Data.
Bright Data + Convex para aplicaciones reactivas basadas en datos web en tiempo real
A la hora de desarrollar aplicaciones reactivas impulsadas por datos web en tiempo real, destaca la combinación de Bright Data y Convex. Juntos, crean una clara separación de responsabilidades: Bright Data se centra en la recopilación de datos a gran escala, mientras que Convex se encarga de la sincronización del estado en tiempo real y las actualizaciones de la interfaz de usuario.
Bright Data le permite buscar y extraer información de la web en tiempo real mediante programación. Los datos extraídos se devuelven como JSON estructurado, que se puede incorporar fácilmente a Convex. A continuación, este se encargará de propagarlos instantáneamente a todos los clientes conectados a través de consultas reactivas.
Lo que hace que Bright Data resulte especialmente atractivo es su infraestructura de nivel empresarial. Opera en una de las redes de proxies más grandes del mundo, con más de 150 millones de direcciones IP en 195 países, lo que permite una concurrencia ilimitada. Esta base garantiza una alta fiabilidad, con un tiempo de actividad del 99,99 %, una tasa de éxito del 99,95 % y asistencia 24/7.
Todas las soluciones de recuperación de datos en tiempo real de Bright Data se basan en esa infraestructura. Las principales ofertas incluyen:
- API de Scraper: puntos de conexión API listos para usar que permiten extraer datos estructurados en tiempo real de sitios web populares.
- API Unlocker: gestiona automáticamente los CAPTCHA, los mecanismos de bloqueo y los sistemas antibots, lo que le permite acceder al contenido de las páginas desbloqueadas.
- API SERP: proporciona resultados de búsqueda en tiempo real de múltiples motores, con tiempos de respuesta de menos de un segundo de latencia.
- API de rastreo: Convierte sitios web completos en Conjuntos de datos estructurados.
La configuración de Convex + Bright Data permite un flujo continuo de datos actualizados desde la web hacia sus usuarios, sin la sobrecarga operativa típica del Scraping web. El resultado es un sistema escalable, fácil de mantener y totalmente reactivo, construido sobre datos web en tiempo real.
Ejemplo de arquitectura
A continuación se muestra un ejemplo de la arquitectura de una aplicación web o móvil reactiva construida con Convex, con datos web en tiempo real proporcionados por Bright Data:
- Activación de la recuperación de datos (Bright Data): Cuando un usuario realiza una acción específica (por ejemplo, hacer clic en un botón), el frontend envía una solicitud a su backend. A continuación, el servidor llama a una API de Bright Data para obtener datos actualizados de la web. Los datos extraídos pueden ser precios de productos, artículos de noticias, ofertas de empleo, etc.
- Procesamiento del backend (Convex): Una vez recibidos los datos JSON estructurados, se pasan a Convex a través de una mutación. En esta etapa, los datos se ingieren, normalizan, validan y almacenan en la base de datos de Convex. También puede enriquecer o transformar los datos aquí según la lógica de su aplicación.
- Actualizaciones en tiempo real de la interfaz de usuario (reactividad de Convex): El frontend se suscribe a las consultas en Convex. Tan pronto como se actualiza la base de datos, las consultas relevantes se vuelven a ejecutar automáticamente. Los resultados actualizados se envían al instante al cliente, y la interfaz de usuario se actualiza en tiempo real sin ninguna intervención manual.
Cómo crear un terminal de estudio de mercado con IA en tiempo real con Convex y Bright Data
Para ilustrar las posibilidades que ofrece la integración de Convex y Bright Data, veamos una demostración real: la terminal de estudio de mercado con IA de Bright Data.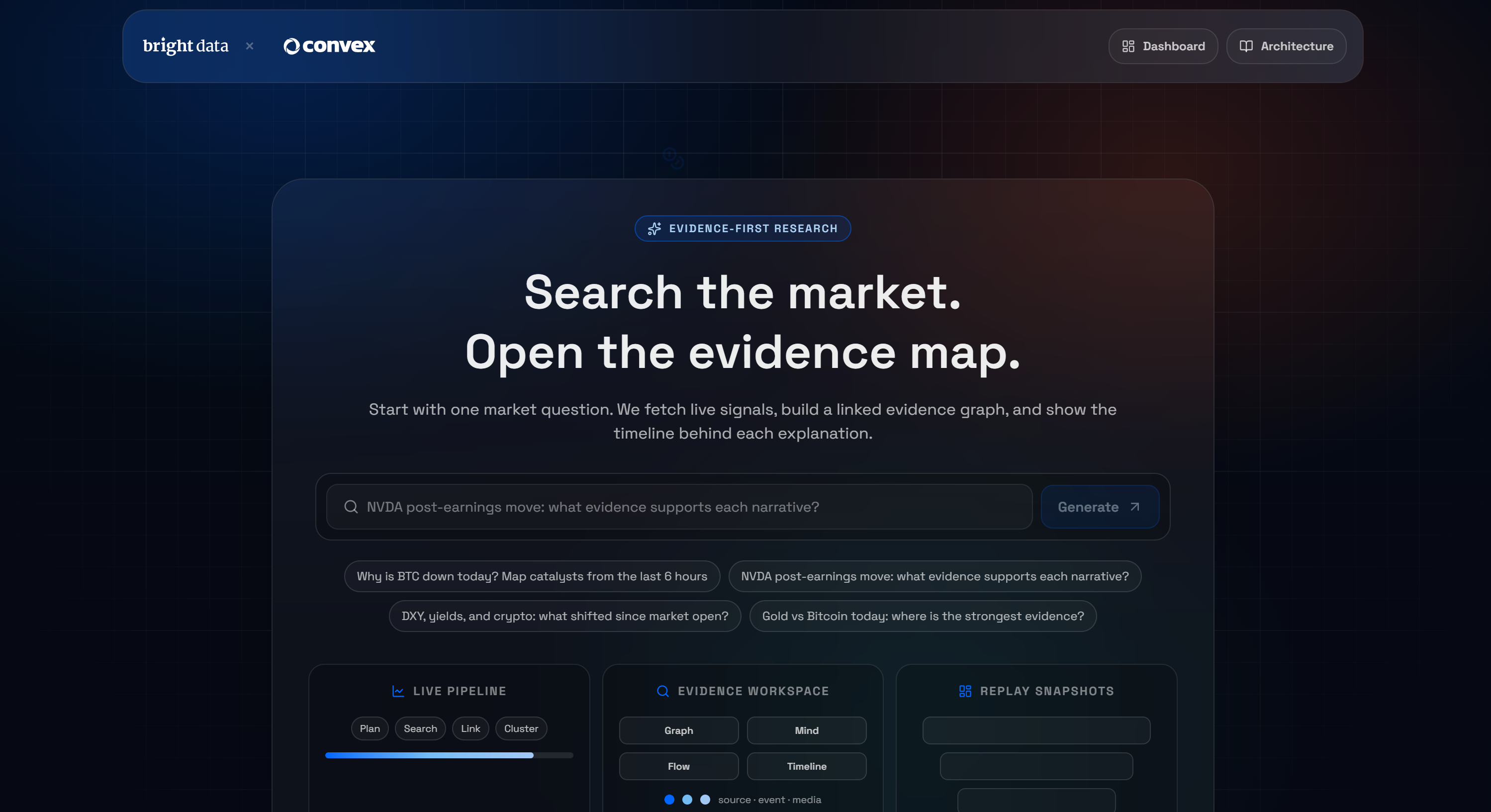
Se trata de una aplicación Next.js construida sobre Convex que permite formular una pregunta y recibir un gráfico de evidencia en directo, extraído mediante Scraping web. Si no estás familiarizado con ese concepto, un gráfico de evidencia es una representación estructurada que muestra las relaciones entre datos, afirmaciones y pruebas de apoyo.
En segundo plano, la aplicación sigue un proceso que consta de ocho etapas:
- Plan: Un LLM crea entre 4 y 6 consultas de búsqueda específicas basadas en tu tema.
- Búsqueda: envía de 4 a 6 solicitudes de la API SERP de Bright Data simultáneamente.
- Extracción: extrae las URL principales a Markdown utilizando la API Web Unlocker de Bright Data.
- Extracción: Combina fragmentos de SERP y Markdown en elementos de evidencia estructurados.
- Resúmenes: El LLM extrae los puntos clave, las entidades, los catalizadores y el sentimiento de cada elemento.
- Artefactos: Crea nodos y aristas del grafo de conocimiento con puntuaciones de confianza.
- Enlace: Aplica enriquecimiento heurístico, incluyendo correcciones de conectividad, etiquetado de dominios y eventos de cinta.
- Renderizar → Listo: Transmite los artefactos finales al cliente mientras mantiene la sesión en Convex.
¡Es hora de explorar esta demo y probarla localmente! Descubre cómo una aplicación real de Convex + Bright Data recopila, procesa y entrega datos web en tiempo real en un flujo de trabajo reactivo.
Requisitos previos
Para seguir esta sección del tutorial, asegúrate de tener:
- Node.js 20+ instalado localmente.
- Una clave API de OpenRouter.
- Una cuenta de Bright Data con las zonas SERP y Web Unlocker configuradas.
- Un proyecto de Convex configurado (el nivel gratuito es suficiente).
- Git instalado localmente.
No te preocupes todavía por configurar Bright Data y Convex. Se te guiará a través de ambos en dos subcapítulos específicos.
Paso n.º 1: Prepara tu cuenta de Bright Data
Como se mencionó en la introducción, la aplicación de demostración se basa en dos productos de Bright Data:
- API SERP
- API Web Unlocker
A continuación, se te guiará a través de su configuración en tu cuenta. Para obtener instrucciones más detalladas, también puedes consultar la documentación oficial de Bright Data:
Si aún no tienes una cuenta, crea una. De lo contrario, inicia sesión. Una vez que hayas iniciado sesión, ve a la página «Proxies y scraping» en el panel de control. En la sección «Mis zonas», busca una fila con el nombre «API SERP» y otra con el nombre «API Web Unlocker»: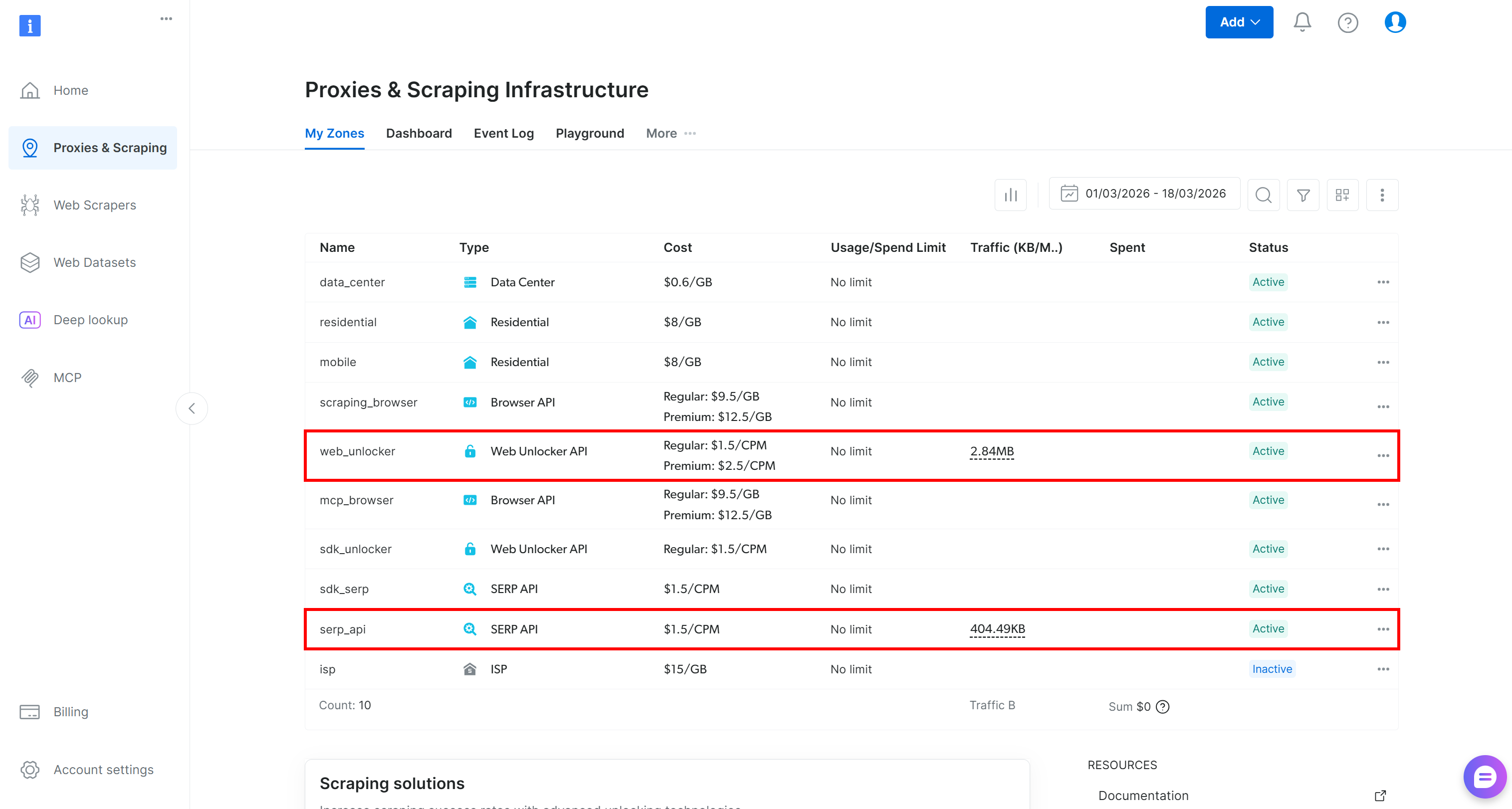
Si falta alguna de estas filas, significa que la zona correspondiente aún no se ha configurado. Por ejemplo, para crear una zona de la API SERP, desplázate hacia abajo hasta la sección «API SERP» y haz clic en «Crear zona»: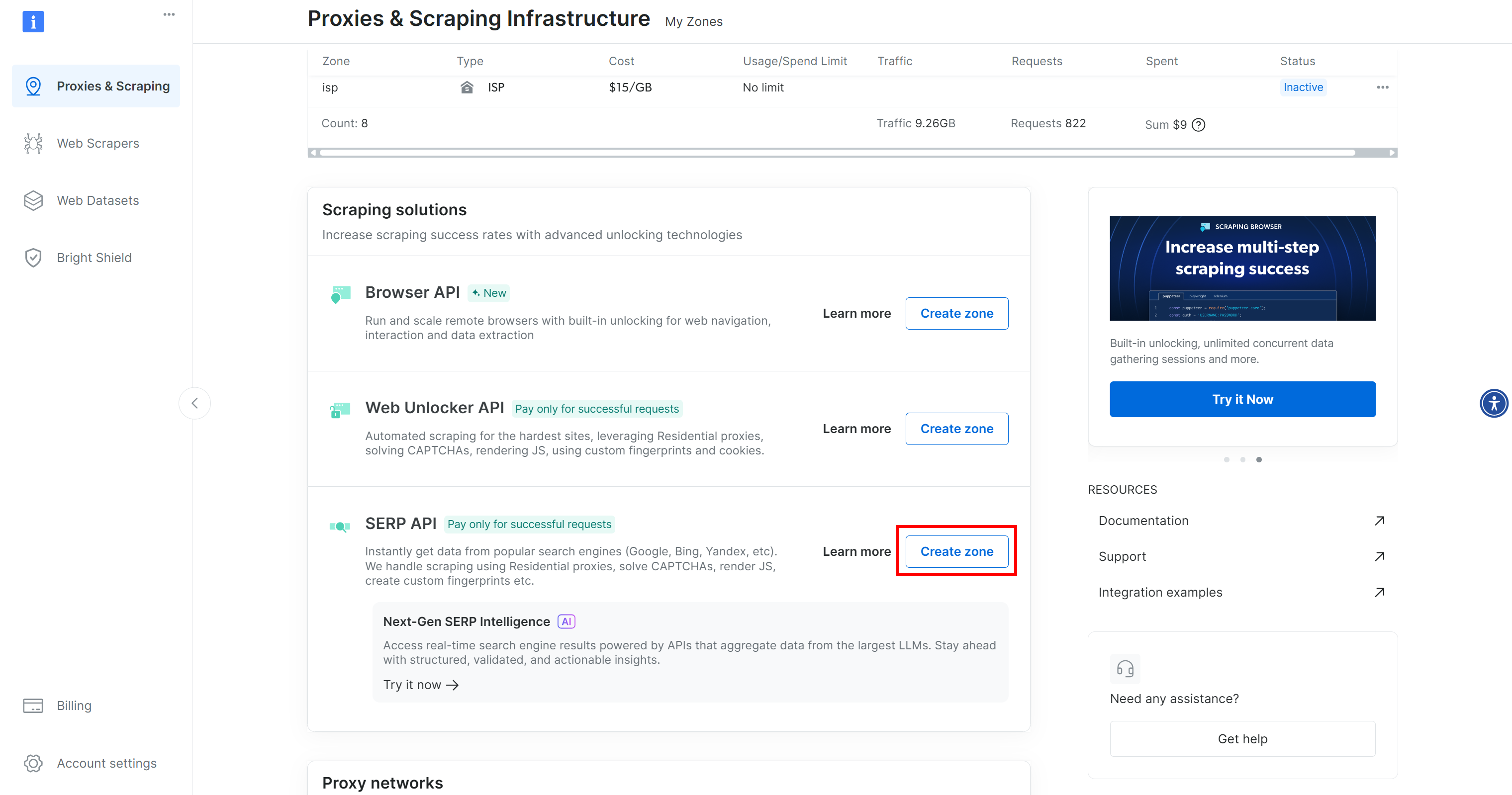
Crea una zona API SERP y asígnale un nombre, como serp_api (o cualquier nombre que prefieras). Anota el nombre de la zona, ya que lo necesitarás más adelante.
Repite el mismo proceso para la API de Web Unlocker. Para este tutorial, daremos por hecho que tu zona de Web Unlocker se llama web_unlocker.
Por último, sigue el tutorial oficial para generar tu clave API de Bright Data. Guárdala en un lugar seguro, ya que la necesitarás para autenticar las solicitudes API de la aplicación Next.js con tecnología Convex a la API SERP y a Web Unlocker.
¡Genial! Tu cuenta de Bright Data ya está totalmente configurada y lista para integrarse en la demo de AI Estudio de mercado Terminal.
Paso n.º 2: Configura tu cuenta de Convex
Empieza por iniciar sesión en Convex o crea una nueva cuenta si aún no lo has hecho. Llegarás a tu panel de control de Convex: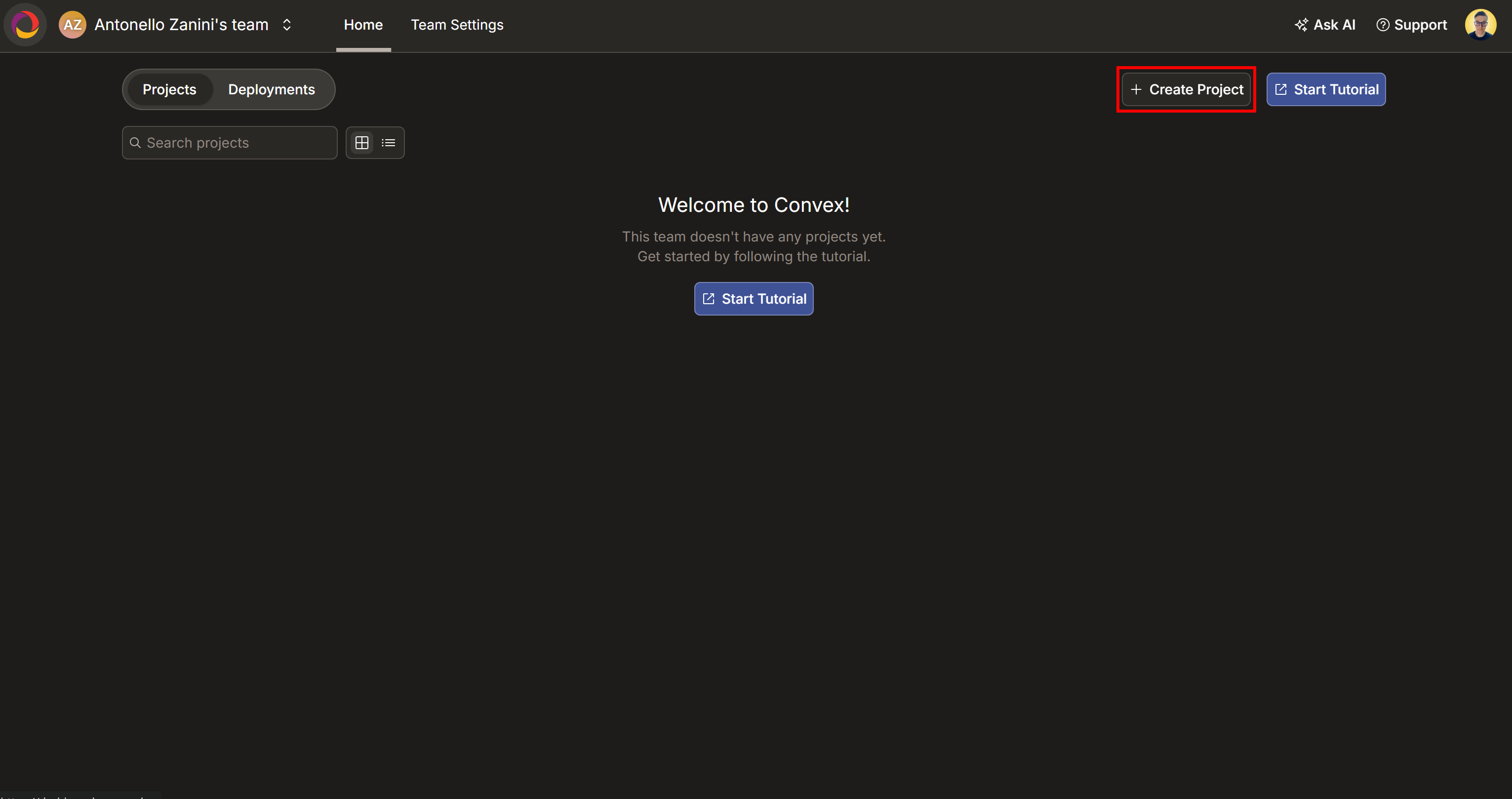
Aquí, pulsa el botón «Crear proyecto». Asigna a tu proyecto el nombre «Terminal de estudio de mercado con IA» (o cualquier nombre que prefieras) y, a continuación, haz clic en «Crear»: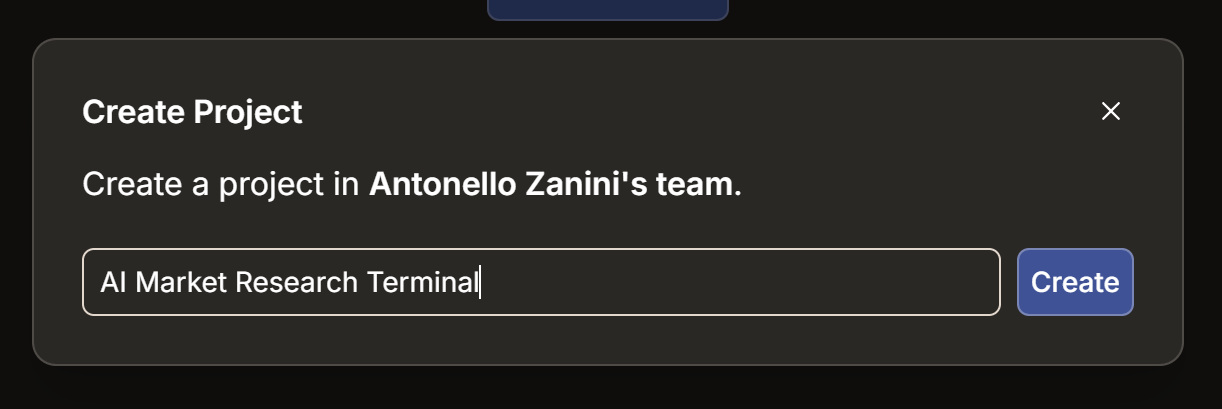
Espera a que el proyecto se inicialice y, a continuación, selecciona una región de implementación: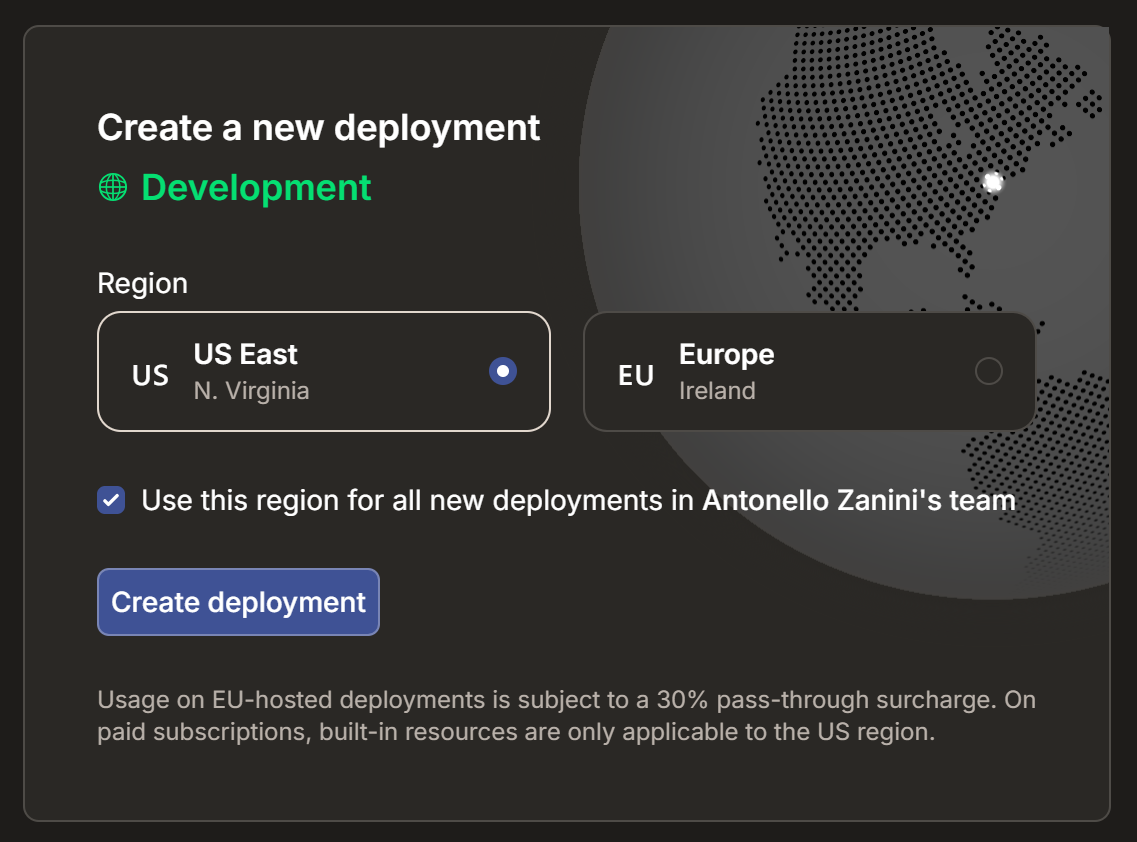
Confirma pulsando «Configurar implementación». Tras unos segundos, tu proyecto debería estar listo:
¡Genial! Ahora tienes todos los componentes necesarios para clonar y ejecutar el proyecto localmente.
Paso n.º 3: Configurar el proyecto
Empieza clonando el repositorio de demostración en una carpeta local llamada ai-market-research-terminal/:
git clone https://github.com/brightdata/market-terminal IA-market-research-terminalTu carpeta de proyecto ai-estudio-de-mercado-terminal/ debería contener ahora todos los archivos que figuran en el repositorio oficial.
Accede al directorio del proyecto:
cd ai-estudio-de-mercado-terminalA continuación, instala las dependencias del proyecto:
npm install¡Genial! Ahora puedes abrir el proyecto en tu IDE de JavaScript favorito, como Visual Studio Code. Explóralo y familiarízate con él para ver cómo funciona. Para obtener más información y conocer los detalles técnicos, lee el artículo detallado dedicado a este tema en DEV.
Paso n.º 4: Configurar la aplicación
La aplicación lee toda su configuración desde un archivo .env.local. El repositorio incluye un archivo de ejemplo llamado .env.local.example. Cópialo para crear tu propio archivo .env.local:
cp .env.local.example .env.local
A continuación, configura el conector Convex ejecutando el siguiente comando en la carpeta raíz de tu proyecto:
npx convex devSigue las instrucciones y conecta tu dispositivo a tu cuenta de Convex en el navegador. A continuación, selecciona el proyecto «IA Estudio de mercado» que creaste en el paso n.º 2. Convex actualizará automáticamente tu archivo .env.local con las variables de entorno necesarias. En este caso, añadirá:
CONVEX_DEPLOYMENT=dev:deafening-bloodhound-209
NEXT_PUBLIC_CONVEX_URL=https://deafening-bloodhound-209.convex.cloud
NEXT_PUBLIC_CONVEX_SITE_URL=https://deafening-bloodhound-209.convex.siteEstos valores permiten que su aplicación se conecte a su proyecto Convex.
De forma predeterminada, se añadirán dos nuevas tablas (sessionEnvts y session) a tu proyecto Convex: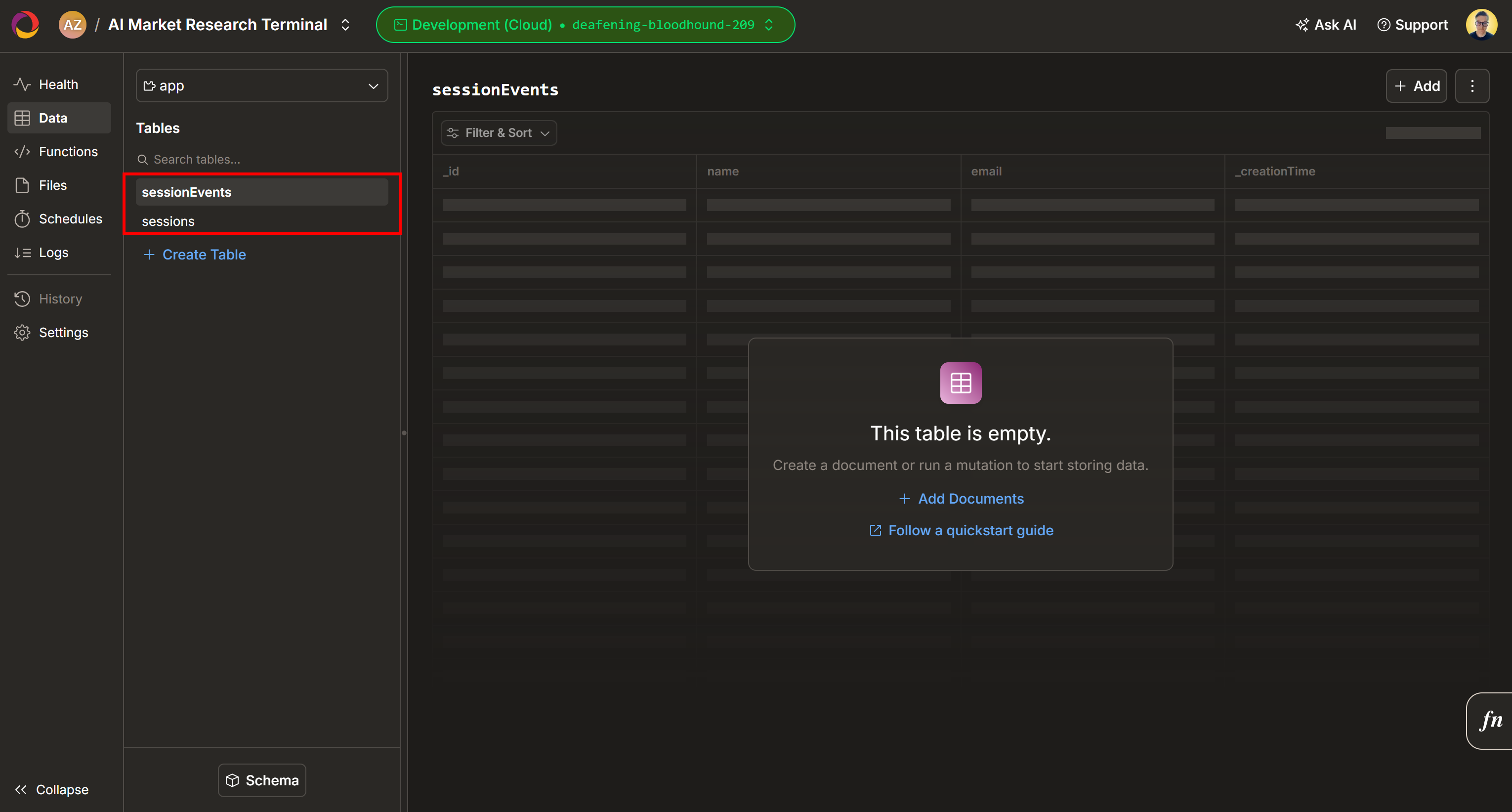
A continuación, rellene las variables de entorno restantes en .env.local:
BRIGHTDATA_API_TOKEN=<SU_CLAVE_API_BRIGHTDATA>
BRIGHTDATA_WEB_UNLOCKER_ZONE=<NOMBRE_DE_SU_API_WEB_UNLOCKER_BRIGHTDATA> # p. ej., «web_unlocker»
BRIGHTDATA_SERP_ZONE=<TU_NOMBRE_DE_API_DE_SERP_DE_BRIGHTDATA> # p. ej., «serp_api»
OPENROUTER_API_KEY=<TU_CLAVE_DE_API_DE_OPENROUTER>
OPENROUTER_MODEL=google/gemini-3-flash-previewSustituye los marcadores de posición por tu token de API de Bright Data, el nombre de la zona de Web Unlocker, el nombre de la zona de la API SERP y la clave de API de OpenRouter. Ten en cuenta que el LLM predeterminado es Gemini 3 Flash, pero puedes utilizar cualquier otro modelo compatible si lo prefieres.
¡Genial! Tu demo ya está totalmente configurada y lista para ejecutarse localmente.
Paso n.º 5: Ejecuta la aplicación localmente
Inicia la demo localmente con:
npm run devAbre http://localhost/market-terminal en tu navegador para acceder a la aplicación local IA Estudio de mercado Terminal. Deberías ver:
Prueba la aplicación introduciendo una consulta, por ejemplo:
¿Por qué ha bajado el BTC hoy?Pulsa el botón «Generar» y obtendrás un resultado como este: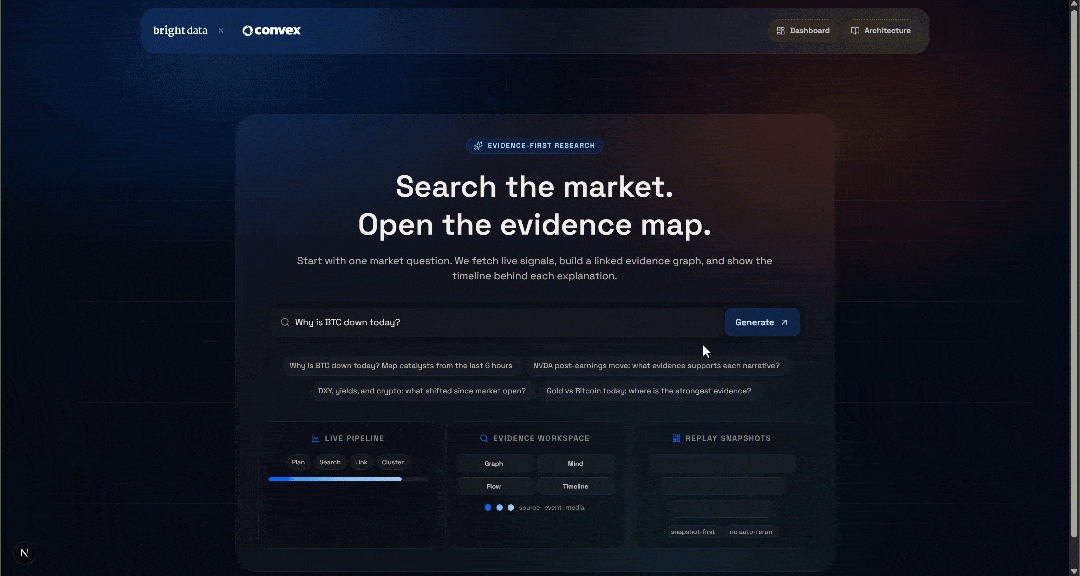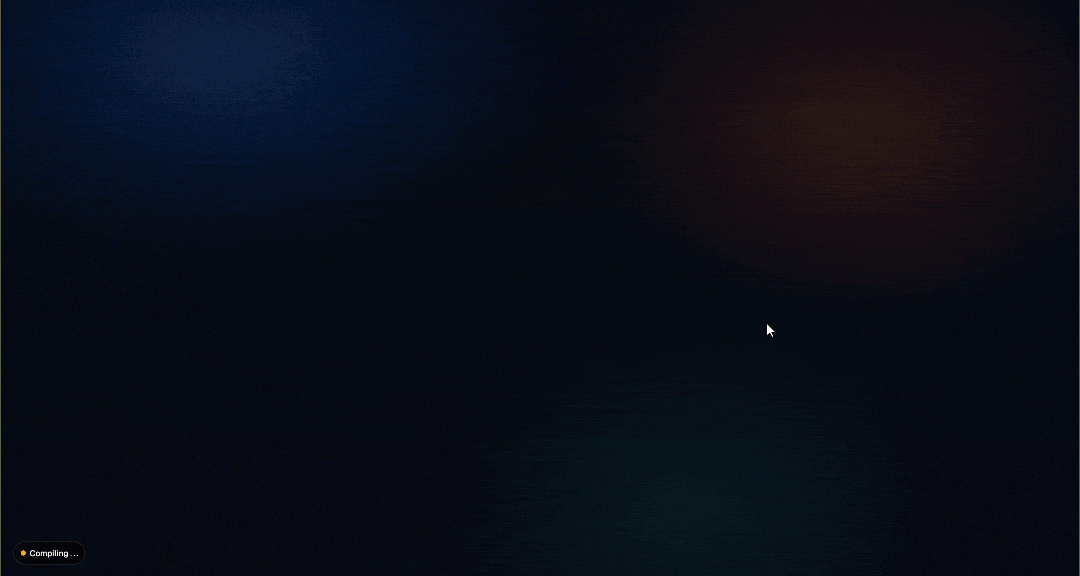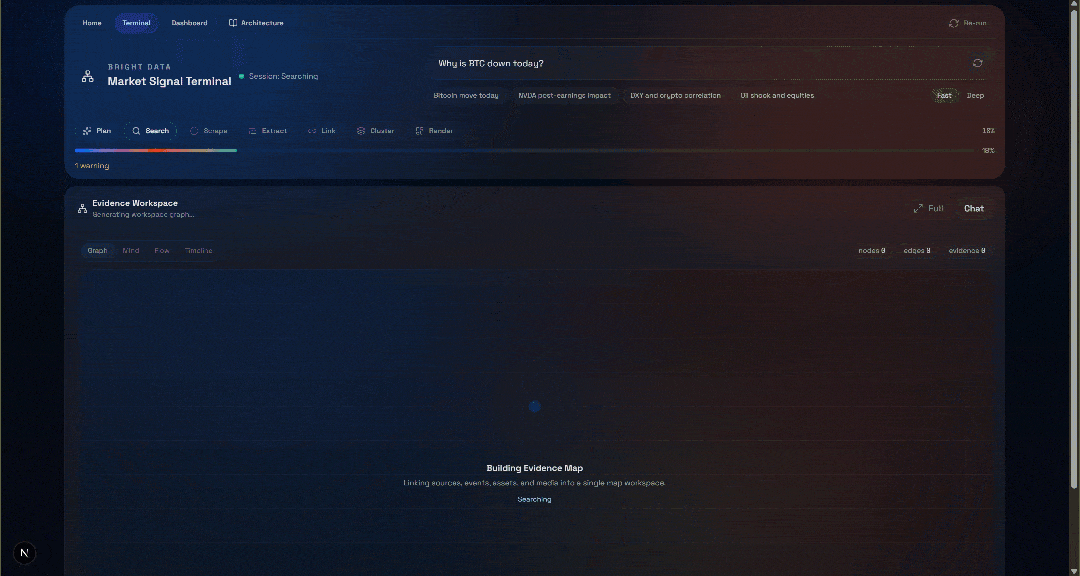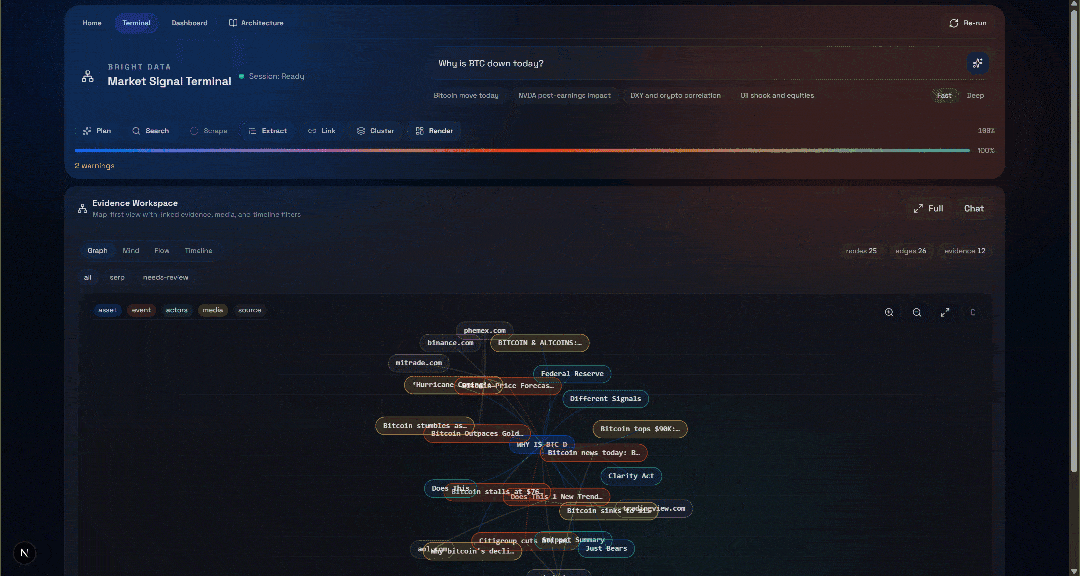
Ahora, echa un vistazo a la sección «Espacio de trabajo de evidencia». Esta vista contiene todos los datos recuperados en tiempo real mediante Scraping web, agregados, procesados y almacenados en Convex. Tu base de datos de Convex contendrá ahora los datos de esta ejecución: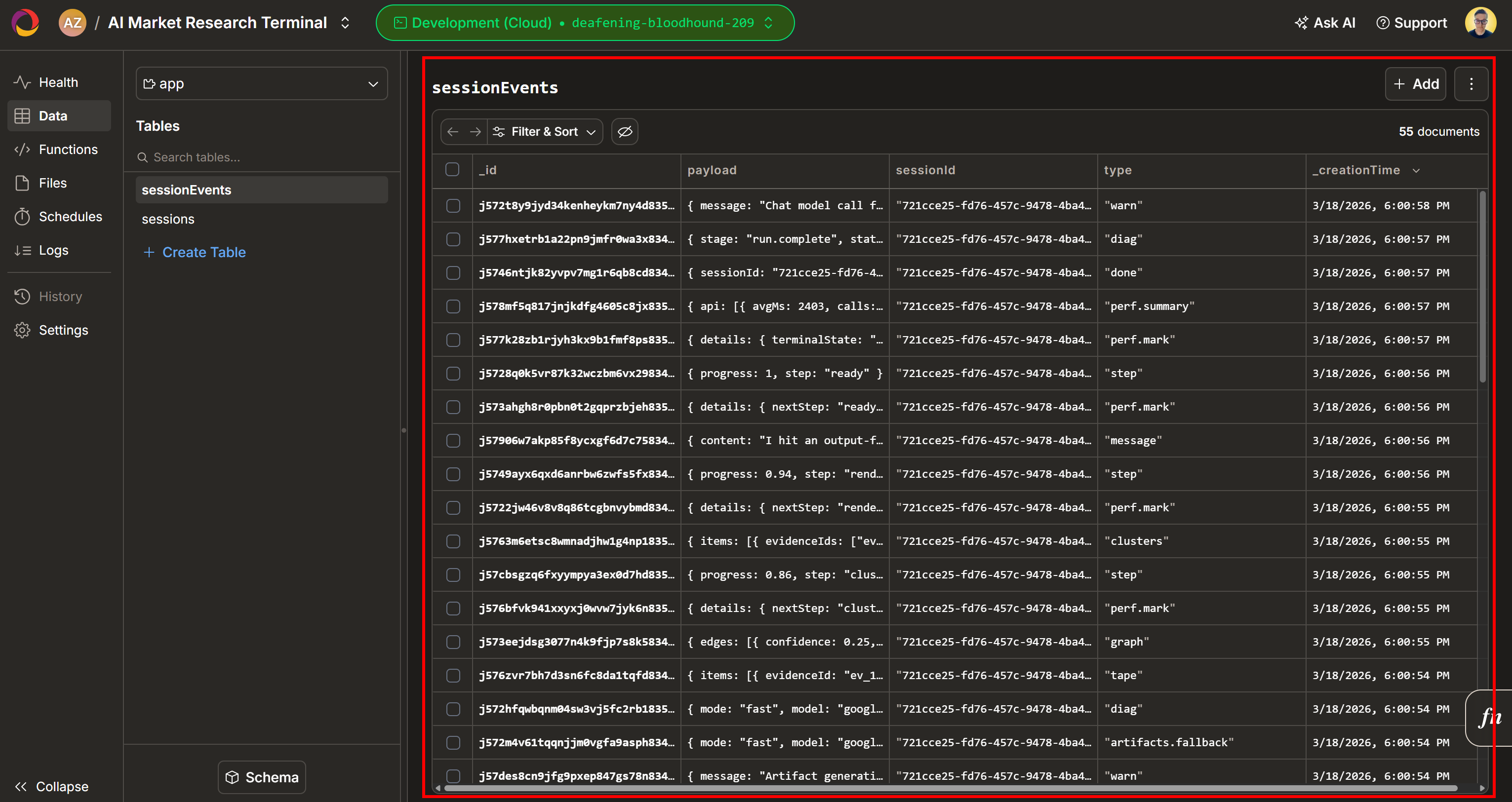
A continuación, explora las vistas «Graph», «Mind», «Flow» y «Timeline»: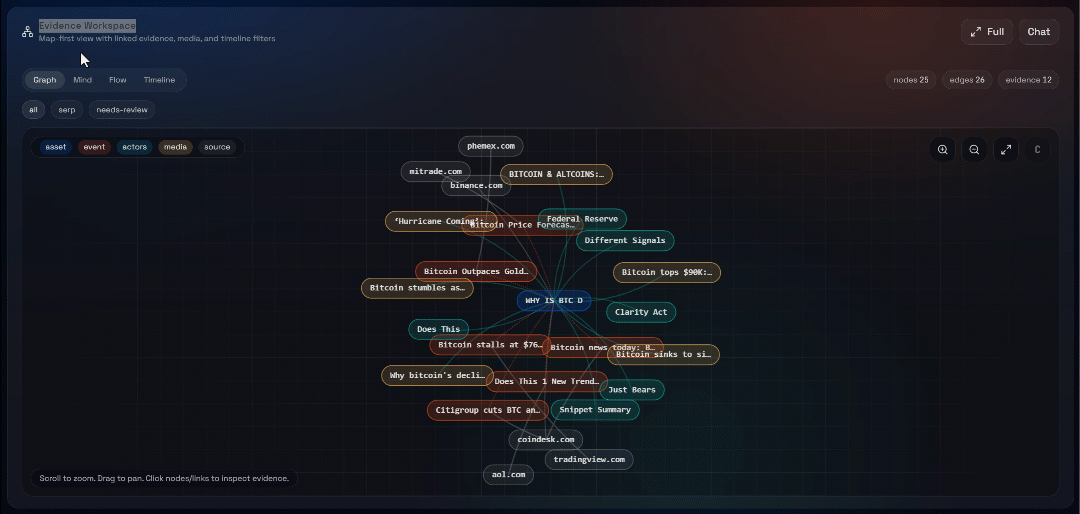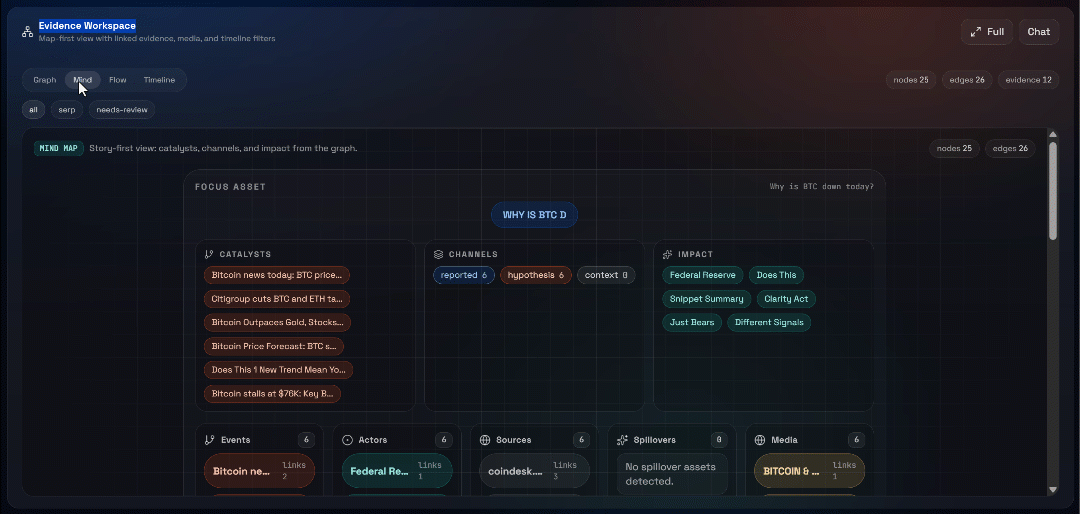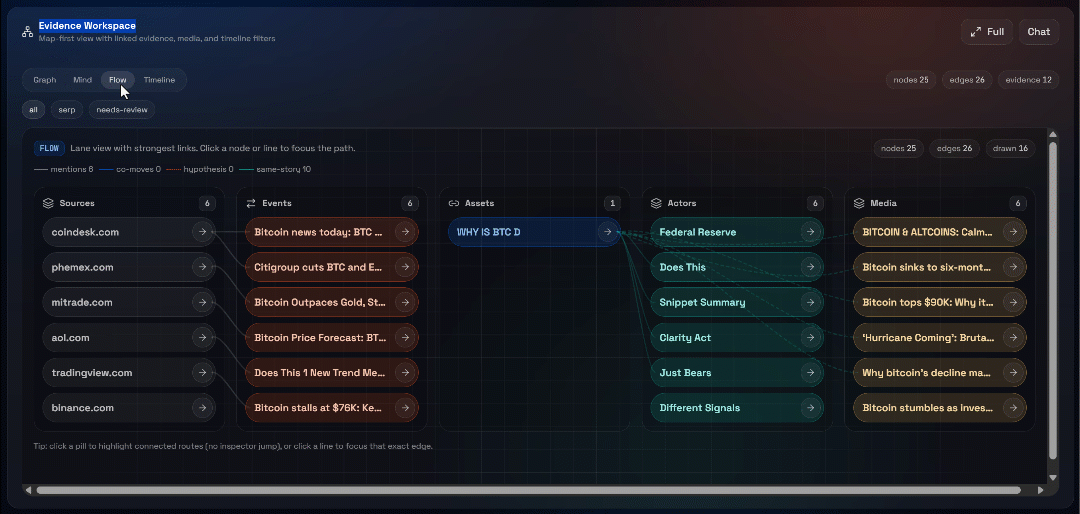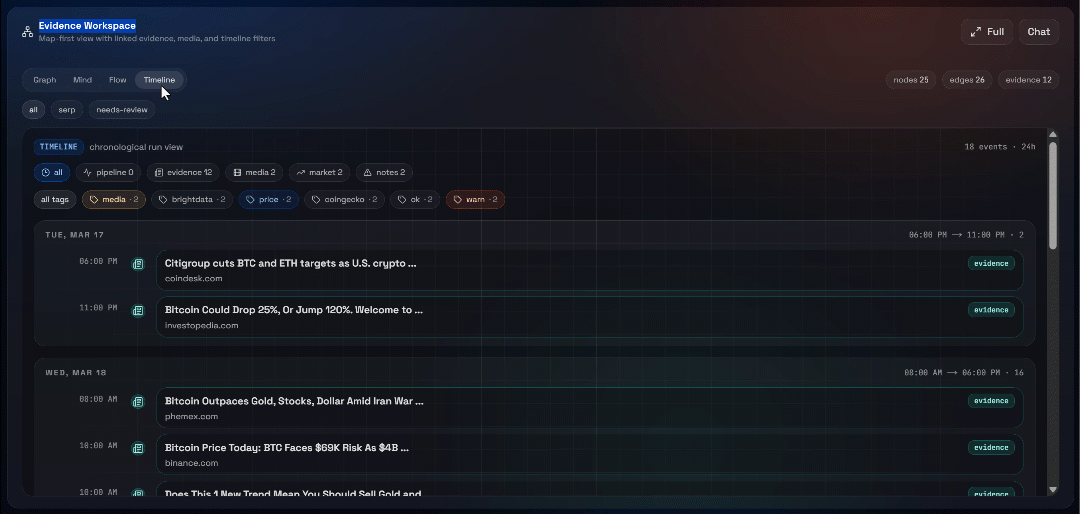
Aquí puedes ver las fuentes recuperadas, filtrarlas y explorar los datos más a fondo para obtener información más detallada.
¡Et voilà! Ahora dispone de una aplicación de terminal de estudio de mercado con IA totalmente funcional, impulsada por Bright Data y con Convex como base de datos backend. Se trata de una aplicación en vivo y reactiva que lleva datos web en tiempo real directamente a su espacio de trabajo.
Conclusión
En este artículo, has aprendido qué es Convex, cómo funciona y cómo ayuda a impulsar aplicaciones reactivas. Esta solución se vuelve aún más potente cuando se utiliza para almacenar datos recientes extraídos en directo de la web.
Bright Data permite el scraping web en tiempo real a través de una infraestructura de nivel empresarial. Esto sirve de base para una amplia gama de servicios de scraping web, lo que te permite recopilar datos de la web de forma rápida y fiable sin que te bloqueen.
¡Regístrate hoy mismo en Bright Data de forma gratuita y explora nuestras soluciones de recopilación de datos web en tiempo real!





