

En este artículo, descubrirá:
- Qué productos ofrece Bright Data en Databricks.
- Cómo configurar una cuenta de Databricks y recuperar todas las credenciales necesarias para la recuperación y exploración programática de datos.
- Cómo consultar un conjunto de datos de Bright Data utilizando Databricks:
- API REST
- CLI
- Conector SQL
¡Empecemos!
Productos de datos de Bright Data en Databricks
Databricks es una plataforma de análisis abierta para crear, implementar, compartir y mantener soluciones de datos, análisis e IA a escala empresarial. En el sitio web se pueden encontrar productos de datos de múltiples proveedores, por lo que se considera uno de los mejores mercados de datos.
Bright Data se ha unido recientemente a Databricks como proveedor de productos de datos y ya ofrece más de 40 productos:
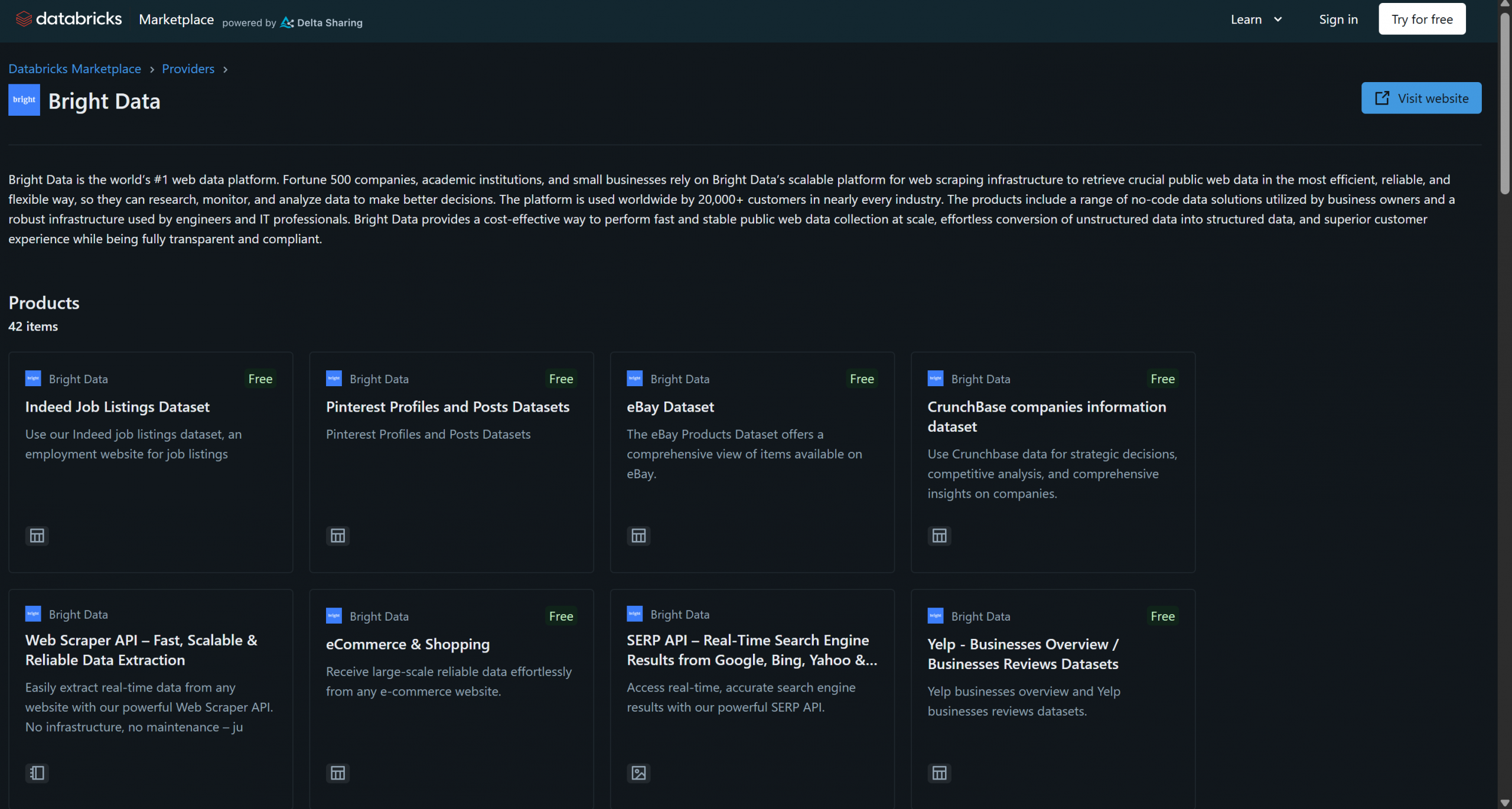
Estas soluciones incluyen conjuntos de datos B2B, conjuntos de datos de empresas, conjuntos de datos financieros, conjuntos de datos inmobiliarios y muchos otros. Además, también tiene acceso a soluciones más generales de recuperación de datos web y Scraping web a través de la infraestructura de Bright Data, como el Navegador de scraping y la API Web Scraper.
En este tutorial, aprenderá a consultar mediante programación los datos de uno de estos Conjuntos de datos de Bright Data utilizando la API de Databricks, la CLI y la biblioteca dedicada SQL Connector. ¡Empecemos!
Introducción a Databricks
Para consultar los Conjuntos de datos de Bright Data desde Databricks a través de la API o la CLI, primero debe configurar algunas cosas. Siga los pasos que se indican a continuación para configurar su cuenta de Databricks y obtener todas las credenciales necesarias para acceder e integrar los Conjuntos de datos de Bright Data.
Al final de esta sección, tendrá:
- Una cuenta de Databricks configurada
- Un token de acceso a Databricks
- Un ID de almacén de Databricks
- Una cadena de host de Databricks
- Acceso a uno o más Conjuntos de datos de Bright Data en su cuenta de Databricks
Requisitos
En primer lugar, asegúrese de que tiene una cuenta de Databricks (una cuenta gratuita es suficiente). Si no tiene una, cree una cuenta. De lo contrario, simplemente inicie sesión.
Configure su token de acceso a Databricks
Para autorizar el acceso a los recursos de Databricks, necesita un token de acceso. Siga las instrucciones que se indican a continuación para configurarlo.
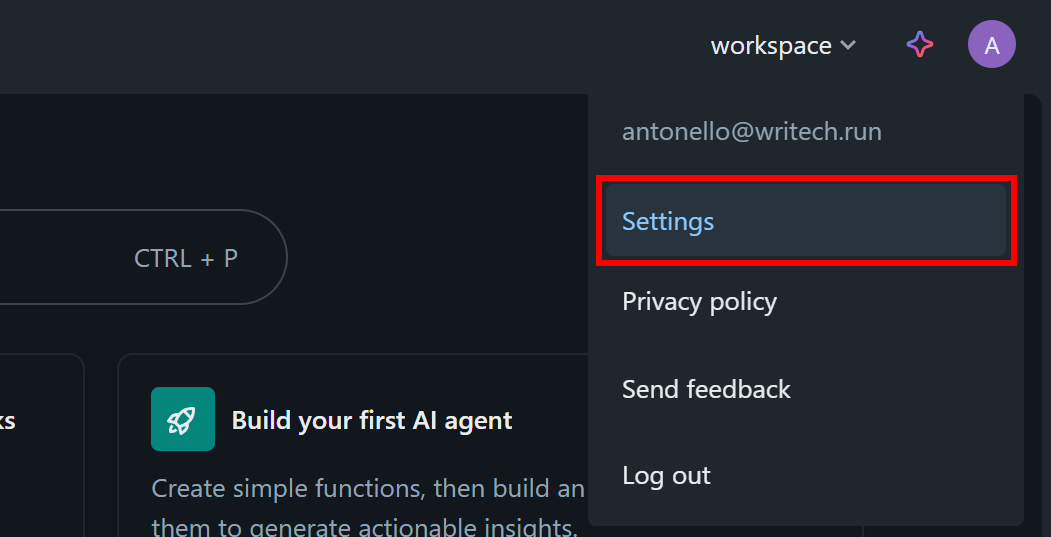
En su panel de control de Databricks, haga clic en su imagen de perfil y seleccione la opción «Configuración»:
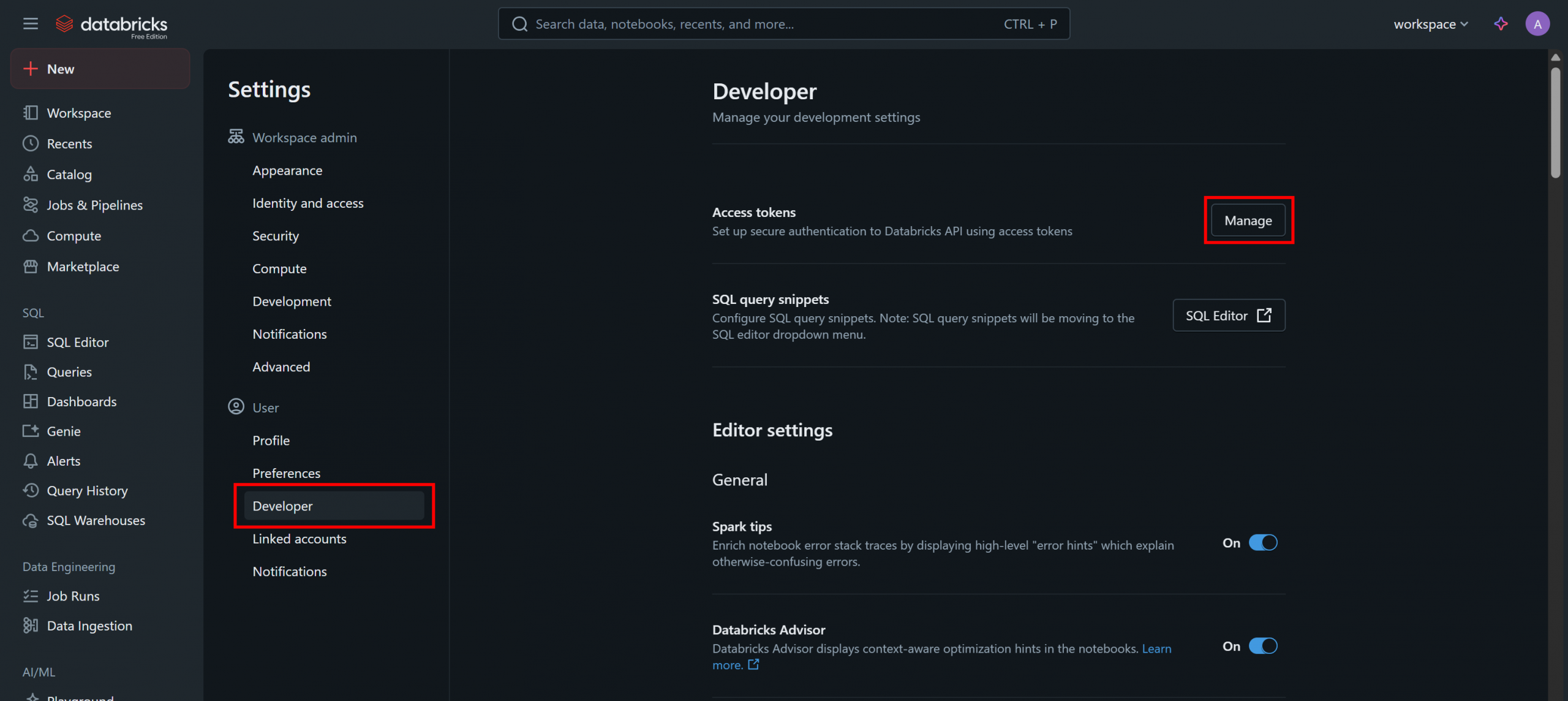
En la página «Configuración», seleccione la opción «Desarrollador» y, a continuación, haga clic en el botón «Administrar» de la sección «Tokens de acceso»:
En la página «Tokens de acceso», haga clic en «Generar nuevo token» y siga las instrucciones del modal:
Recibirá un token de acceso a la API de Databricks. Guárdelo en un lugar seguro, ya que lo necesitará pronto.
Recupera tu ID de almacén de Databricks
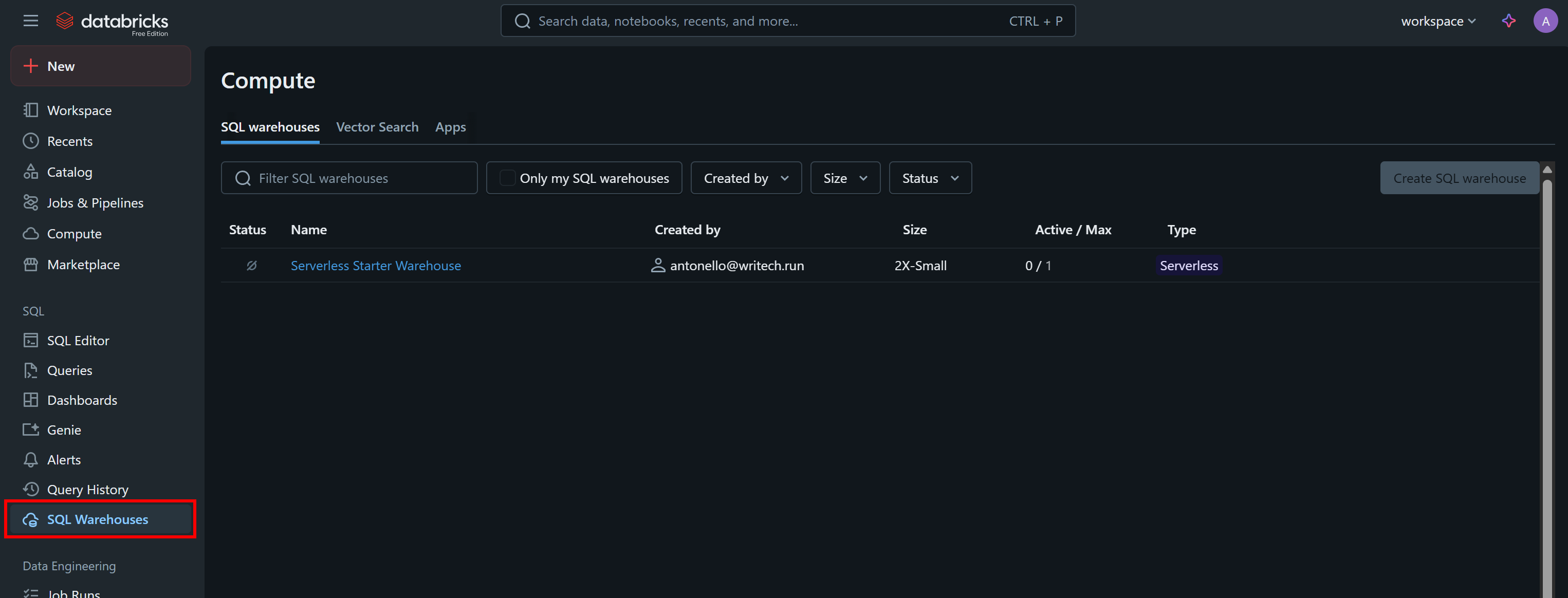
Otra información que necesita para llamar a la API mediante programación o consultar los Conjuntos de datos a través de la CLI es su ID de almacén de Databricks. Para recuperarlo, seleccione la opción «Almacenes SQL» en el menú:
Haga clic en el almacén disponible (en este ejemplo, «Almacén inicial sin servidor») y acceda a la pestaña «Descripción general»:
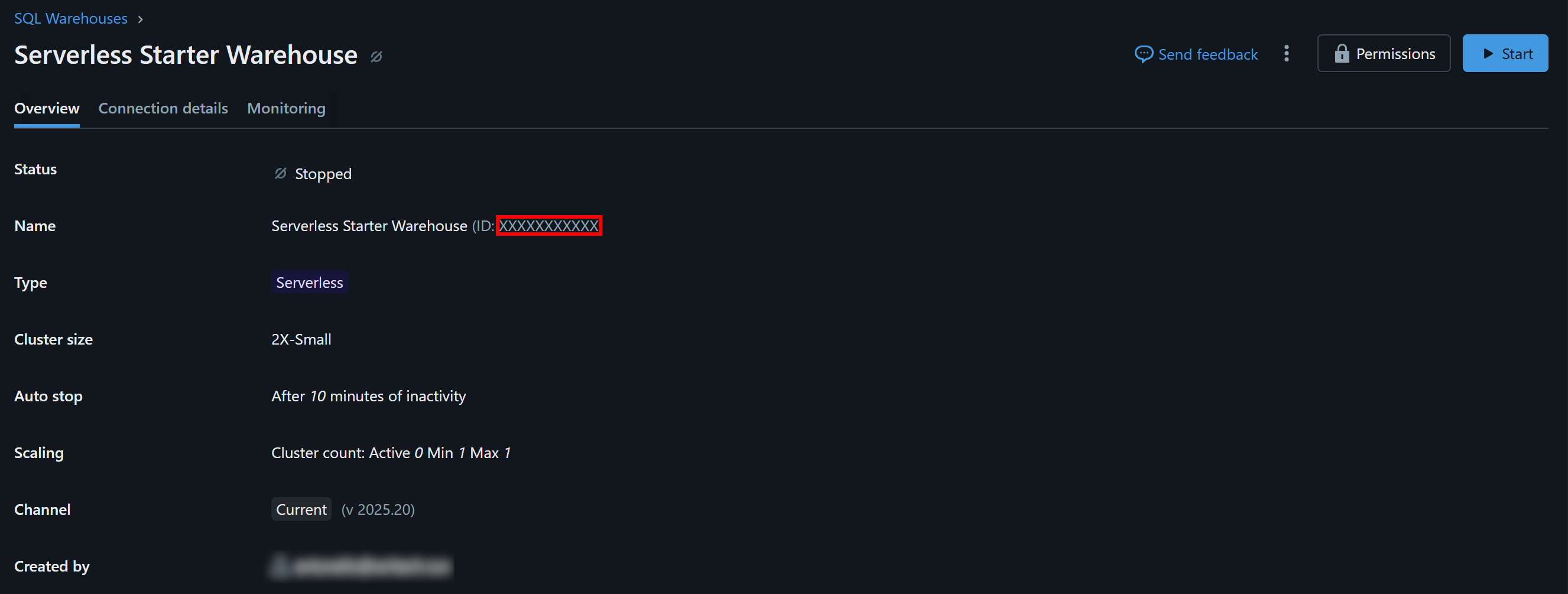
En la sección «Name» (Nombre), verá su ID de almacén de Databricks (entre paréntesis, después de ID:). Cópielo y guárdelo en un lugar seguro, ya que lo necesitará en breve.
Busque su host de Databricks
Para conectarse a cualquier recurso informático de Databricks, debe especificar su nombre de host de Databricks. Este corresponde a la URL base asociada a su cuenta de Databricks y tiene un formato similar al siguiente:
https://<cadena aleatoria>.cloud.databricks.comPuede encontrar esta información directamente copiándola de la URL de su panel de control de Databricks:

Obtenga acceso a los Conjuntos de datos de Bright Data
Ahora debe añadir uno o varios Conjuntos de datos de Bright Data a su cuenta de Databricks para poder consultarlos a través de la API, la CLI o el conector SQL.
Vaya a la página «Marketplace», haga clic en el botón de configuración de la izquierda y seleccione «Bright Data» como único proveedor que le interesa:
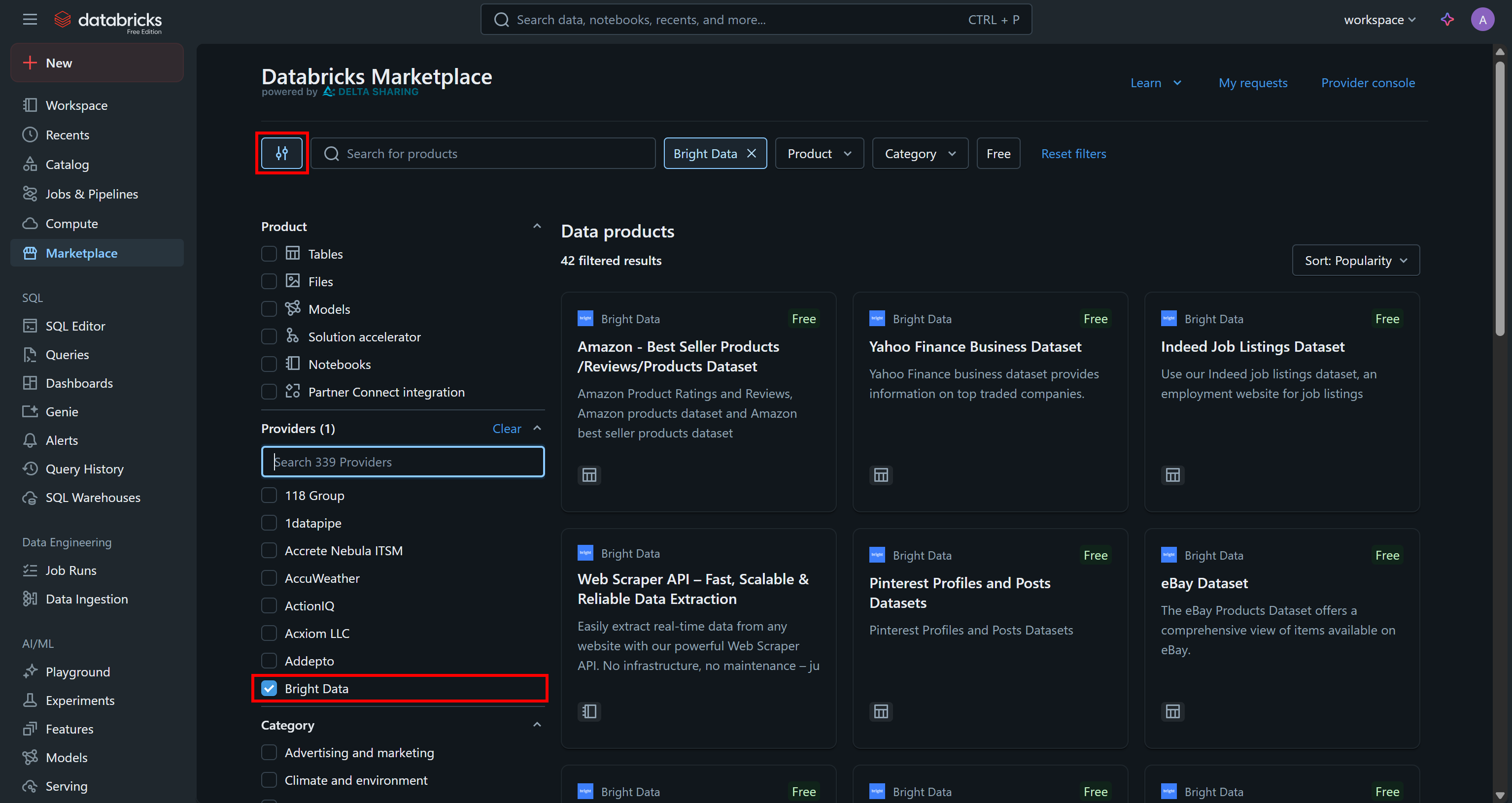
Esto filtrará los productos de datos disponibles para mostrar solo los proporcionados por Bright Data y accesibles a través de Databricks.
Para este ejemplo, supongamos que le interesa el«Conjunto de datos de información de propiedades de Zillow»:
Haga clic en la tarjeta del conjunto de datos y, en la página «Zillow Properties Information Dataset», pulse «Obtener acceso a instancias» para añadirlo a su cuenta de Databricks:
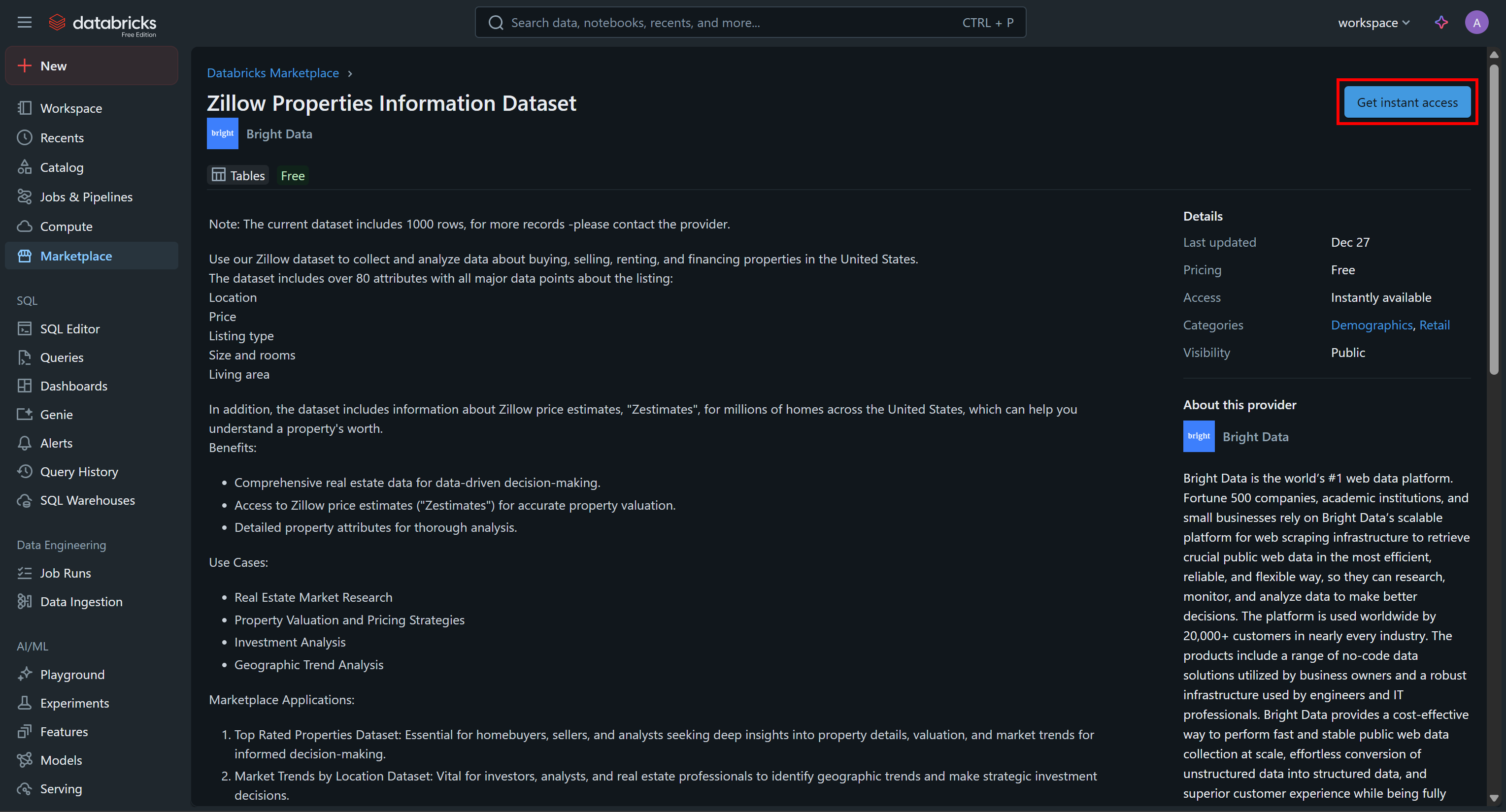
El conjunto de datos se añadirá a su cuenta y ahora podrá consultarlo a través de Databricks SQL. Si se pregunta de dónde proceden esos datos, la respuesta es de los Conjuntos de datos Zillow de Bright Data.
Compruébelo accediendo a la página «SQL Editor» y consulte los Conjuntos de datos utilizando una consulta SQL como esta:
SELECT * FROM bright_data_zillow_properties_information_dataset.conjuntos de datos.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;El resultado debería ser algo así:
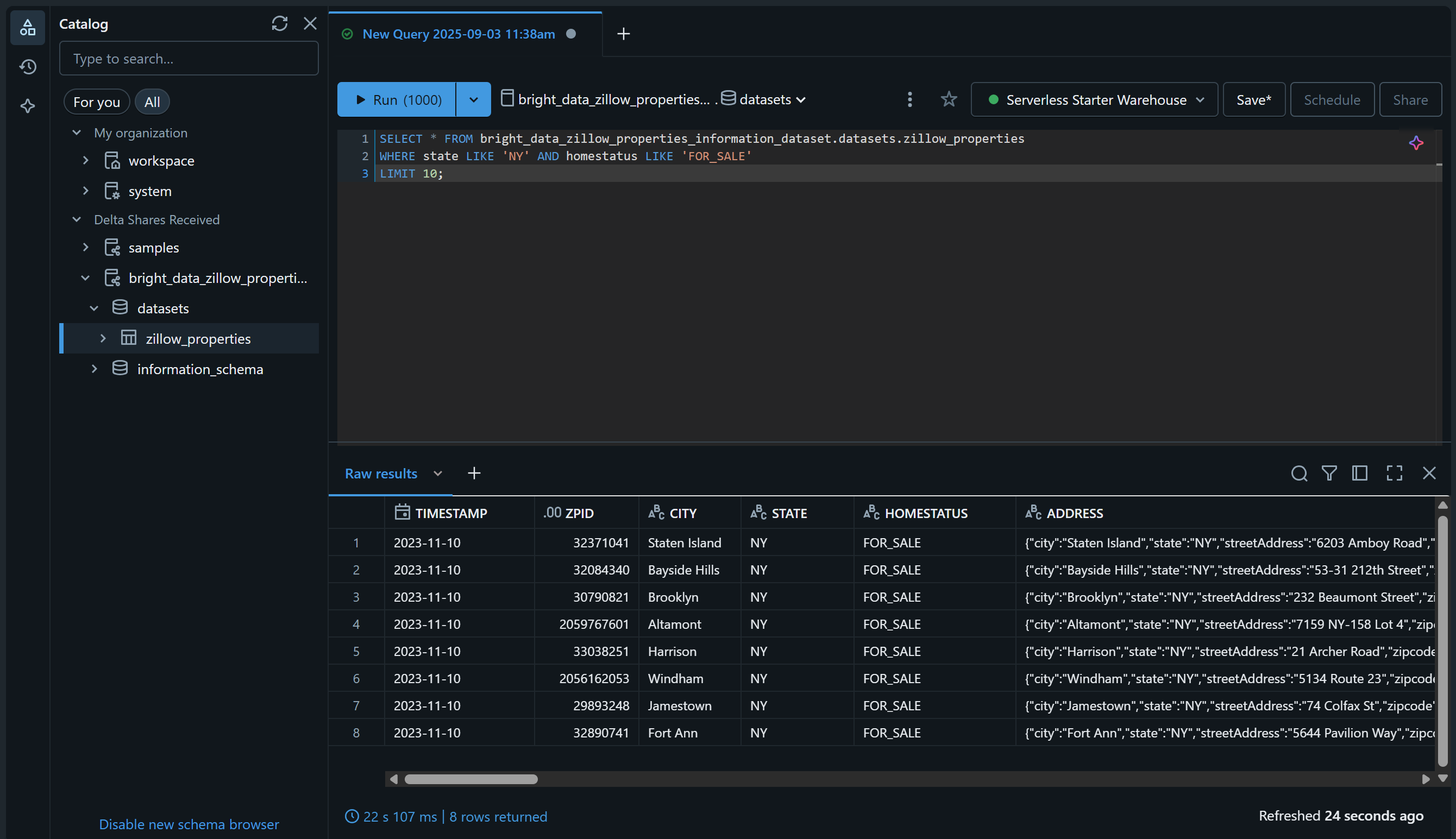
¡Genial! Ha añadido correctamente el conjunto de datos de Bright Data elegido y lo ha hecho consultable a través de Databricks. Puede seguir los mismos pasos para añadir otros Conjuntos de datos de Bright Data.
En las siguientes secciones, aprenderá a consultar este conjunto de datos:
- A través de la API REST de Databricks
- Con el conector SQL de Databricks para Python
- A través de la CLI de Databricks
Cómo consultar un conjunto de datos de Bright Data a través de la API REST de Databricks
Databricks expone algunas de sus características a través de una API REST, incluida la capacidad de consultar los Conjuntos de datos disponibles en su cuenta. Siga los pasos que se indican a continuación para ver cómo consultar mediante programación el «Conjunto de datos de información de propiedades de Zillow» proporcionado por Bright Data.
Nota: El código siguiente está escrito en Python, pero se puede adaptar fácilmente a otros lenguajes de programación o llamar directamente en Bash a través de cURL.
Paso n.º 1: Instalar las bibliotecas necesarias
Para ejecutar consultas SQL en almacenes remotos de Databricks, el punto final de la API REST que se debe utilizar es /api/2.0/sql/statements. Puede llamarlo a través de una solicitud POST utilizando cualquier cliente HTTP. En este ejemplo, utilizaremos la biblioteca Python Requests.
Instálela con:
pip install requestsA continuación, impórtela en su script con:
import requestsObtenga más información al respecto en nuestra guía dedicada a Python Requests.
Paso n.º 2: prepara tus credenciales y secretos de Databricks
Para llamar al punto final de la API REST de Databricks /api/2.0/sql/statements utilizando un cliente HTTP, debe especificar:
- Su token de acceso a Databricks: para la autenticación.
- Su host de Databricks: para crear la URL completa de la API.
- Su ID de almacén de Databricks: para consultar la tabla correcta en el almacén correcto.
Añada los secretos que ha recuperado anteriormente a su script de la siguiente manera:
databricks_access_token = "<SU_TOKEN_DE_ACCESO_A_DATABRICKS>"
databricks_warehouse_id = "<SU_ID_DE_ALMACÉN_DE_DATABRICKS>"
databricks_host = "<SU_HOST_DE_DATABRICKS>"Consejo: En producción, evite codificar estos secretos en su script. En su lugar, considere almacenar esas credenciales en variables de entorno y cargarlas utilizando python-dotenv para mayor seguridad.
Paso n.º 3: Llame a la API de ejecución de sentencias SQL
Realice una llamada HTTP POST al punto final /api/2.0/sql/statements con los encabezados y el cuerpo adecuados utilizando Requests:
# La consulta SQL parametrizada que se ejecutará en el conjunto de datos dado
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.conjuntos_de_datos.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# El parámetro para rellenar la consulta SQL
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# Realizar la solicitud POST y consultar los Conjuntos de datos
headers = {
"Authorization": f"Bearer {databricks_access_token}", # Para autenticarse en Databricks
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)Como puede ver, el fragmento anterior se basa en una instrucción SQL preparada. Tal y como se destaca en la documentación, Databricks recomienda encarecidamente utilizar consultas parametrizadas como práctica recomendada para sus instrucciones SQL.
En otras palabras, ejecutar el script anterior equivale a ejecutar la siguiente consulta en la tabla bright_data_zillow_properties_information_dataset.conjuntos de datos.zillow_properties, tal y como hicimos anteriormente:
SELECT * FROM bright_data_zillow_properties_information_dataset.conjuntos de datos.zillow_properties
WHERE state LIKE 'NY' AND homestatus LIKE 'FOR_SALE'
LIMIT 10;¡Fantástico! Solo queda gestionar los datos de salida
Paso n.º 4: Exportar los resultados de la consulta
Gestiona la respuesta y exporta los datos recuperados con esta lógica de Python:
if response.status_code == 200:
# Acceder a los datos JSON de salida
result = response.json()
# Exportar los datos recuperados a un archivo JSON
output_file = "zillow_properties.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=4)
print(f"¡Consulta realizada correctamente! Resultados guardados en '{output_file}'")
else:
print(f"Error {response.status_code}: {response.text}")Si la solicitud se realiza correctamente, el fragmento creará un archivo zillow_properties.json que contiene los resultados de la consulta.
Paso n.º 5: Combinar todo
El script final debe contener:
import requests
import json
# Tus credenciales de Databricks (sustitúyelas por los valores correctos)
databricks_access_token = "<TU_TOKEN_DE_ACCESO_A_DATABRICKS>"
databricks_warehouse_id = "<TU_ID_DE_ALMACÉN_DE_DATABRICKS>"
databricks_host = "<TU_HOST_DE_DATABRICKS>"
# La consulta SQL parametrizada que se ejecutará en el conjunto de datos dado
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.conjuntos_de_datos.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit;
"""
# El parámetro para rellenar la consulta SQL
parameters = [
{"name": "state", "value": "NY", "type": "STRING"},
{"name": "homestatus", "value": "FOR_SALE", "type": "STRING"},
{"name": "row_limit", "value": "10", "type": "INT"}
]
# Realizar la solicitud POST y consultar los Conjuntos de datos
headers = {
"Authorization": f"Bearer {databricks_access_token}", # Para autenticarse en Databricks
"Content-Type": "application/json"
}
payload = {
"statement": sql_query,
"warehouse_id": databricks_warehouse_id,
"parameters": parameters
}
response = requests.post(
f"{databricks_host}/api/2.0/sql/statements",
headers=headers,
data=json.dumps(payload)
)
# Gestionar la respuesta
if response.status_code == 200:
# Acceder a los datos JSON de salida
result = response.json()
# Exportar los datos recuperados a un archivo JSON
output_file = "zillow_properties.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=4)
print(f"¡Consulta realizada con éxito! Resultados guardados en '{output_file}'")
else:
print(f"Error {response.status_code}: {response.text}")Ejecútelo y debería generar un archivo zillow_properties.json en el directorio de su proyecto.
La salida contiene primero la estructura de columnas para ayudarte a comprender las columnas disponibles. A continuación, en el campo data_array, puedes ver los datos de la consulta resultante como una cadena JSON:
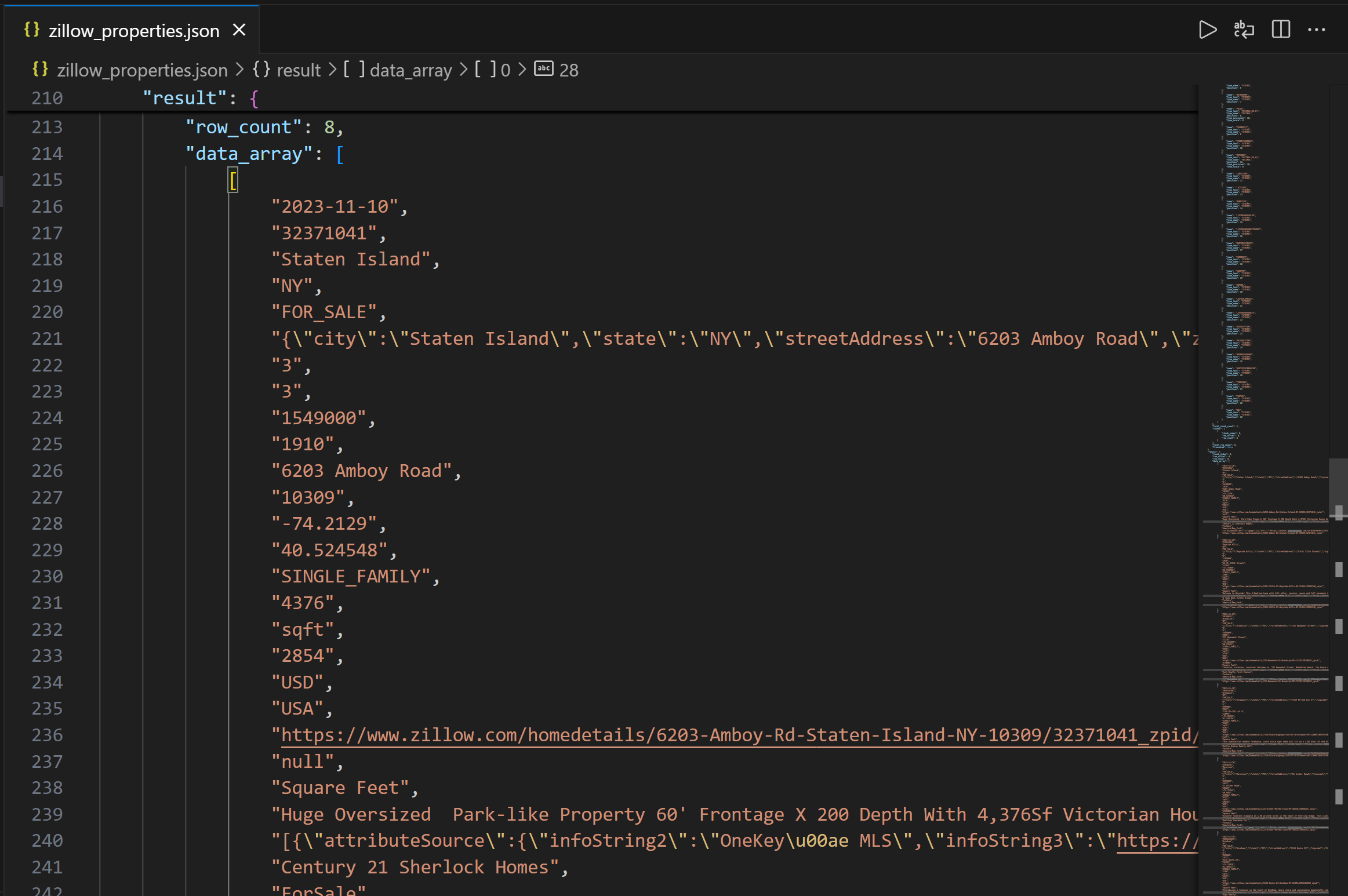
¡Misión cumplida! Acaba de recopilar datos de propiedades de Zillow proporcionados por Bright Data a través de la API REST de Databricks.
Cómo acceder a los Conjuntos de datos de Bright Data utilizando la CLI de Databricks
Databricks también le permite consultar datos en un almacén a través de la CLI de Databricks, que se basa en la API REST. ¡Aprenda a utilizarla!
Paso n.º 1: Instalar la CLI de Databricks
La CLI de Databricks es una herramienta de línea de comandos de código abierto que le permite interactuar con la plataforma Databricks directamente desde su terminal.
Para instalarla, siga la guía de instalación de su sistema operativo. Si todo está configurado correctamente, al ejecutar el comando databricks -v debería aparecer algo como esto:

¡Perfecto!
Paso n.º 2: definir un perfil de configuración para la autenticación
Utilice la CLI de Databricks para crear un perfil de configuración denominado DEFAULT que le autentique con su token de acceso personal de Databricks. Para ello, ejecute el siguiente comando:
databricks configure --profile DEFAULTA continuación, se le pedirá que proporcione:
- Su host de Databricks
- Su token de acceso de Databricks
Pegue ambos valores y pulse Intro para completar la configuración:

Ahora podrá autenticar los comandos de la API de la CLI especificando la opción --profile DEFAULT.
Paso n.º 3: Consultar su conjunto de datos
Utilice el siguiente comando CLI para ejecutar una consulta parametrizada a través del comando API post:
databricks API post "/api/2.0/sql/statements"
--profile DEFAULT
--json '{
"warehouse_id": "<YOUR_DATABRICKS_WAREHOUSE_ID>",
"statement": "SELECT * FROM bright_data_zillow_properties_information_dataset.Conjuntos de datos.zillow_properties WHERE state LIKE :state AND homestatus LIKE :homestatus LIMIT :row_limit",
"parameters": [
{ "name": "state", "value": "NY", "type": "STRING" },
{ "name": "homestatus", "value": "FOR_SALE", "type": "STRING" },
{ "name": "row_limit", "value": "10", "type": "INT" }
]
}'
> zillow_properties.jsonReemplace el marcador de posición <YOUR_DATABRICKS_WAREHOUSE_ID> con el ID real de su almacén de datos SQL de Databricks.
En segundo plano, esto hace lo mismo que hicimos antes en Python. Más concretamente, realiza una solicitud POST a la API REST SQL de Databricks. El resultado será un archivo zillow_properties.json que contiene los mismos datos que hemos visto antes:
Cómo consultar un conjunto de datos desde Bright Data a través del conector SQL de Databricks
El conector SQL de Databricks es una biblioteca de Python que le permite conectarse a clústeres y almacenes SQL de Databricks. En concreto, proporciona una API simplificada para conectarse a la infraestructura de Databricks y explorar sus datos.
En esta sección de la guía, aprenderá a utilizarlo para consultar el «Conjunto de datos de información de propiedades de Zillow» de Bright Data.
Paso n.º 1: Instalar el conector SQL de Databricks para Python
El conector SQL de Databricks está disponible a través de la biblioteca Python databricks-sql-connector. Instálelo con:
pip install databricks-sql-connectorA continuación, impórtelo en su script con:
from databricks import sqlPaso 2: Comience a utilizar el conector SQL de Databricks
El conector SQL de Databricks requiere credenciales diferentes a las de la API REST y la CLI. En concreto, necesita:
server_hostname: su nombre de host de Databricks (sin la partehttps://).http_path: una URL especial para conectarse a su almacén.access_token: su token de acceso a Databricks.
Puede encontrar los valores de autenticación necesarios, junto con un fragmento de código de inicio de muestra, en la pestaña «Detalles de conexión» de su almacén SQL:
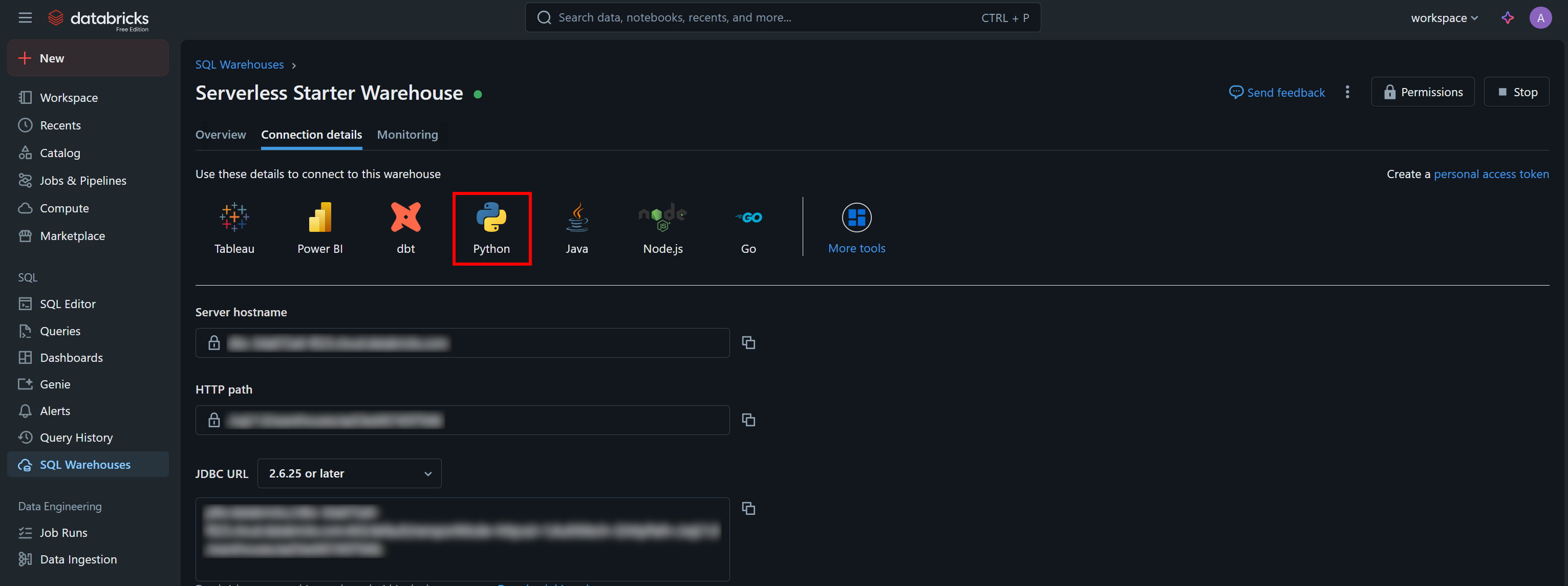
Pulse el botón «Python» y obtendrá:
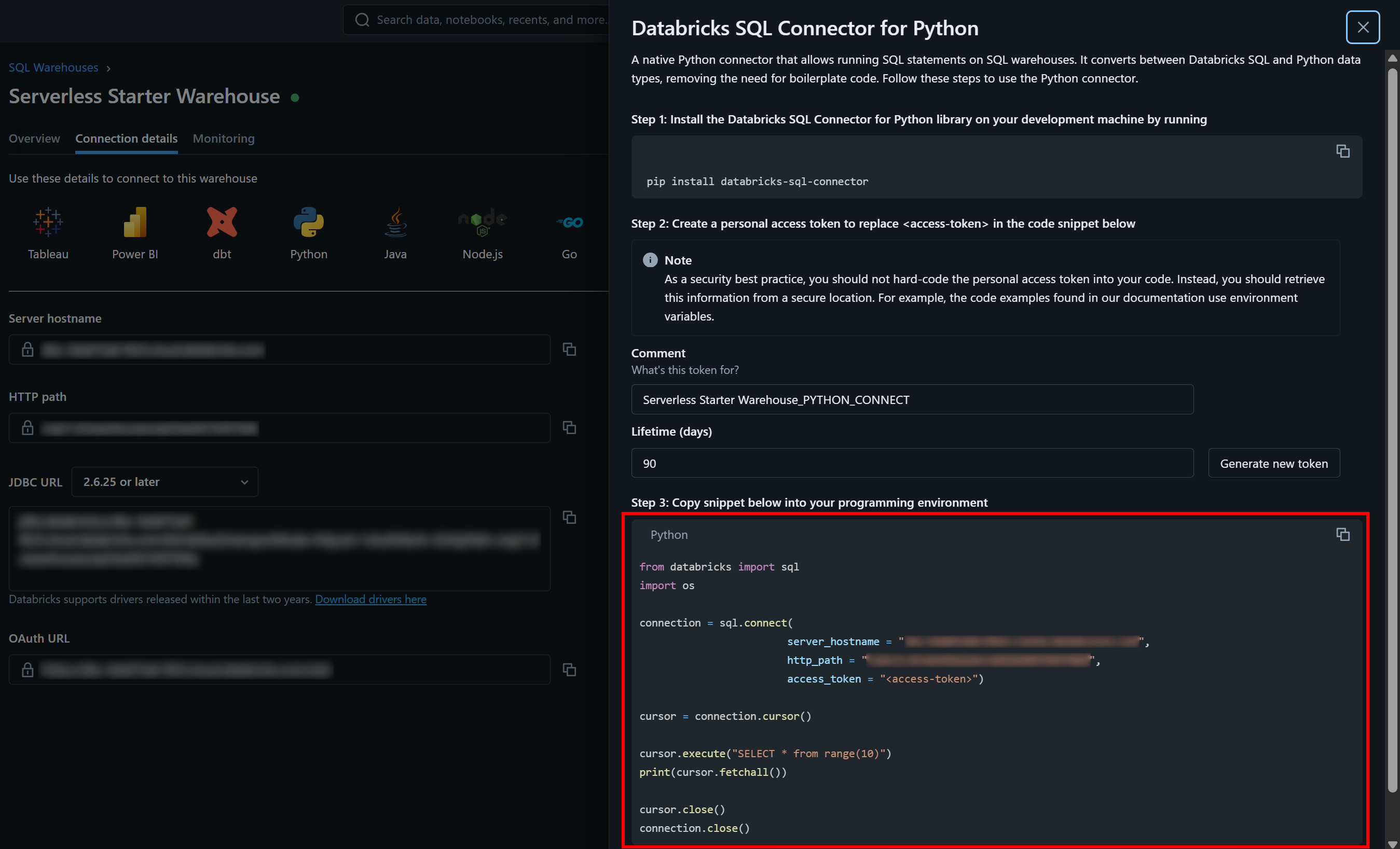
Estas son todas las instrucciones que necesita para empezar a utilizar el conector databricks-sql-connector.
Paso n.º 3: Ponlo todo junto
Adapte el código del fragmento de código de ejemplo de la sección «Conector SQL de Databricks para Python» a su almacén para ejecutar la consulta parametrizada que le interese. Debería obtener un script similar al siguiente:
from databricks import sql
# Conéctese a su almacén SQL en Databricks (sustituya las credenciales por sus valores)
connection = sql.connect(
server_hostname = "<YOUR_DATABRICKS_HOST>",
http_path = "<YOUR_DATABRICKS_WAREHOUST_HTTP_PATH>",
access_token = "<YOUR_DATABRICKS_ACCESS_TOKEN>"
)
# Ejecute la consulta SQL parametrizada y obtenga los resultados en un cursor
cursor = connection.cursor()
sql_query = """
SELECT *
FROM bright_data_zillow_properties_information_dataset.Conjuntos de datos.zillow_properties
WHERE state LIKE :state AND homestatus LIKE :homestatus
LIMIT :row_limit
"""
params = {
"state": "NY",
"homestatus": "FOR_SALE",
"row_limit": 10
}
# Ejecutar la consulta
cursor.execute(sql_query, params)
result = cursor.fetchall()
# Imprimir todos los resultados fila por fila
for row in result[:2]:
print(row)
# Cerrar el cursor y la conexión al almacén SQL
cursor.close()
connection.close()Ejecute el script y generará un resultado como este:
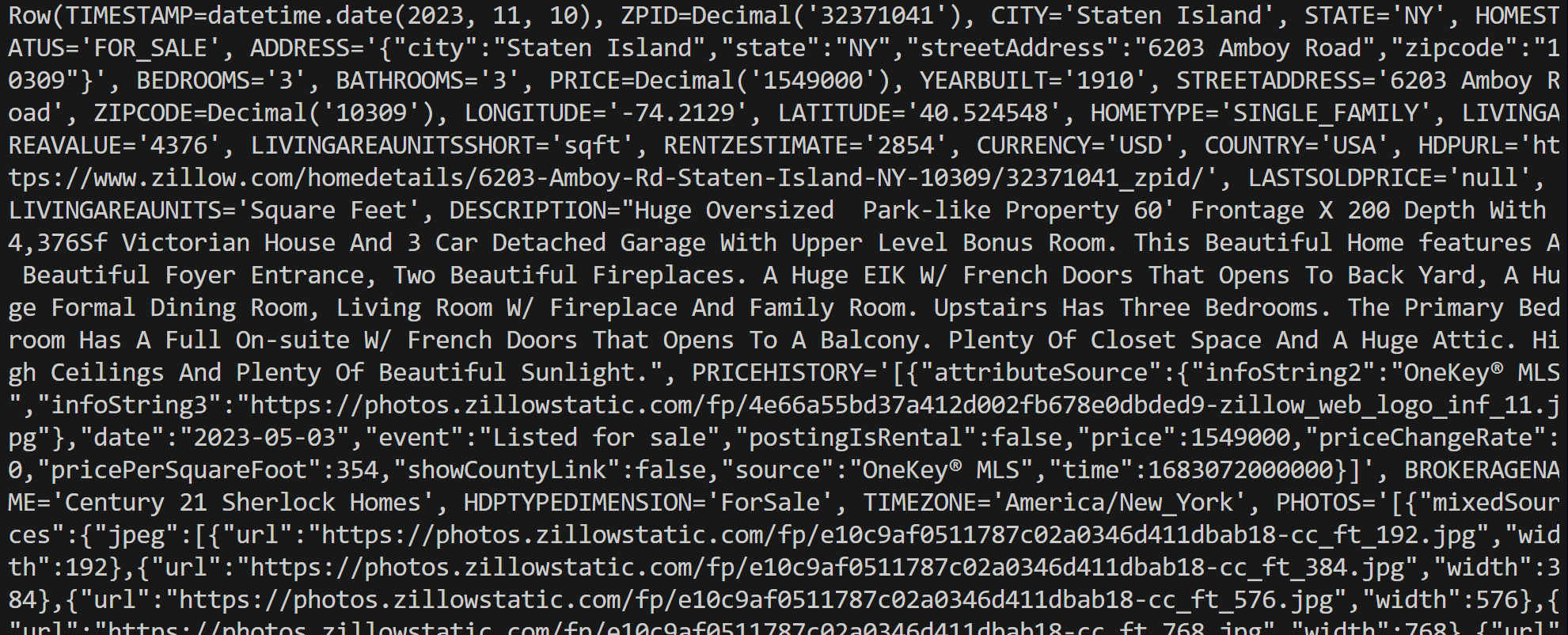
Tenga en cuenta que cada objeto de fila es una instancia Row, que representa un único registro de los resultados de la consulta. A continuación, puede procesar esos datos directamente en su script de Python.
Tenga en cuenta que puede convertir una instancia Row en un diccionario Python con el método asDict():
row_data = row.asDict()¡Et voilà! Ahora ya sabe cómo interactuar y consultar sus Conjuntos de datos de Bright Data en Databricks de múltiples maneras.
Conclusión
En este artículo, ha aprendido a consultar los Conjuntos de datos de Bright Data desde Databricks utilizando su API REST, CLI o biblioteca dedicada SQL Connector. Como se ha demostrado, Databricks ofrece múltiples formas de interactuar con los productos ofrecidos por sus proveedores de datos, entre los que ahora se incluye Bright Data.
Con más de 40 productos disponibles, puede explorar la gran riqueza de los Conjuntos de datos de Bright Data directamente en Databricks y acceder a sus datos de diversas formas.
¡Cree una cuenta gratuita en Bright Data y comience a experimentar con nuestras soluciones de datos hoy mismo!




