Al final de este tutorial, comprenderás:
- Por qué PyTorch es una excelente opción para crear un flujo de trabajo de aprendizaje automático multimodal.
- La necesidad de una fuente fiable de datos de confianza procedentes de Conjuntos de datos que contengan varios millones de registros, como los que proporciona Bright Data.
- Cómo aprovechar los Conjuntos de datos de Bright Data en PyTorch para ajustar un modelo de aprendizaje automático para la clasificación de imágenes de productos en un proceso multimodal.
¡Empecemos!
Por qué utilizar PyTorch para el aprendizaje automático multimodal
Los datos solo son tan valiosos como los conocimientos que permiten obtener. Para las empresas, aprovechar los datos con el enfoque adecuado puede impulsar decisiones más inteligentes, perfeccionar estrategias y mejorar resultados como la retención de clientes y el rendimiento del marketing.
El aprendizaje automático moderno permite procesar no solo datos estructurados, como valoraciones o cifras de ventas, sino también datos no estructurados, como imágenes, texto e incluso vídeo. Esto abre la puerta a conocimientos multimodales. Por ejemplo, combinar imágenes de reseñas con texto puede proporcionar una comprensión más rica de lo que impulsa la participación de los clientes.
Este artículo se basa en PyTorch, un marco de aprendizaje automático de Python ampliamente utilizado para crear y entrenar redes neuronales profundas. La biblioteca admite una larga lista de tareas, entre las que se incluyen la clasificación de imágenes, el procesamiento del lenguaje natural y flujos de trabajo combinados en los que se analizan conjuntamente varios tipos de datos.
Algunas aplicaciones comunes de PyTorch son:
- Evaluación de la calidad de las imágenes de los productos: determinar automáticamente si las imágenes son visualmente atractivas y susceptibles de atraer a los clientes.
- Análisis de la opinión de los clientes: extraer información de las reseñas textuales para comprender las opiniones y la satisfacción de los usuarios.
- Creación de sistemas de recomendación: combinar características de texto e imágenes para generar sugerencias de productos más precisas y personalizadas.
- Modelado predictivo con datos multimodales: utilizar conjuntamente información visual y textual para pronosticar tendencias, ventas o comportamiento de los clientes.
Cómo obtener datos multimodales de alta calidad para su empresa
Independientemente del tipo de aplicación de aprendizaje automático o IA que esté desarrollando, debe recordar que estos sistemas solo son tan eficaces como los datos con los que se entrenan.
En las aplicaciones multimodales, la obtención de datos puede resultar especialmente difícil, ya que requiere recopilar información tanto en formato textual como visual. Aquí es donde entran en juego los proveedores de datos de confianza, como Bright Data.
Bright Data ofrece un conjunto de soluciones preparadas para la IA y el aprendizaje automático para empresas de todos los tamaños, desde startups hasta grandes empresas:
- API de Web Scraper: proporciona acceso programático a datos estructurados de cientos de sitios web populares, lo que permite la recopilación automatizada de datos web actualizados a gran escala.
- Mercado de conjuntos de datos: ofrece conjuntos de datos multimodales listos para usar con miles de millones de entradas, incluyendo imágenes, texto y campos estructurados.
- Servicios de adquisición de datos gestionados: soluciones totalmente gestionadas y de nivel empresarial que permiten a los equipos adquirir y mantener datos sin necesidad de crear o mantener canales de extracción.
- Servicios de anotación de datos: soluciones de anotación escalables y personalizables para tareas de PLN, visión artificial y reconocimiento de voz.
Estas soluciones permiten a los investigadores, las pymes y las grandes empresas recopilar e integrar de forma eficiente datos web públicos. Esto se puede aprovechar para impulsar flujos de trabajo de aprendizaje automático multimodal, entrenar modelos sofisticados de IA, desarrollar agentes inteligentes y crear sistemas de análisis e inteligencia empresarial.
Cómo crear un canal de análisis de aprendizaje automático multimodal utilizando PyTorch con un conjunto de datos de Bright Data
En esta sección guiada, aprenderá a entrenar un modelo de aprendizaje automático con el conjunto de datos«Productos de Amazon»de Bright Data, que contiene datos tanto textuales como de imágenes.
Supondremos que vende productos en línea y comprende la importancia de mostrarlos con imágenes adecuadas. El objetivo es utilizar PyTorch para entrenar un modelo de aprendizaje automático con imágenes de productos de comercio electrónico junto con su información de valoración. Este modelo se encargará de evaluar automáticamente si una imagen de producto es «buena» o «mala».
Gracias a este flujo de trabajo de aprendizaje automático multimodal, su empresa puede evaluar de forma programática la probabilidad de que las imágenes de sus productos atraigan a los clientes y fomenten su participación.
Nota: Esto es solo un ejemplo. Al utilizar PyTorch junto con los Conjuntos de datos y las fuentes de datos de Bright Data, podría cubrir muchos otros casos de uso y escenarios.
¡Siga las instrucciones que se indican a continuación!
Requisitos
Para seguir esta sección, asegúrese de tener:
- Python 3.9 o superior instalado localmente.
- Una cuenta de Bright Data.
Además, estar familiarizado con el modelo ResNet-18 y cómo funciona el ajuste fino será útil para comprender completamente la lógica de clasificación de imágenes multimodal de PyTorch.
Paso n.º 1: Crear un proyecto JupyterLab
Cuando se trabaja con datos multimodales, es útil visualizar los Conjuntos de datos. Por este motivo, JupyterLab es una excelente opción como entorno de desarrollo. Una vez desarrollado el flujo de trabajo, el código se puede convertir fácilmente en un proceso de aprendizaje automático listo para su producción.
Comience creando una carpeta de proyecto dedicada y navegue hasta ella:
mkdir pytorch-brightdata-product-image-analysis
cd pytorch-brightdata-product-image-analysisA continuación, inicialice un entorno virtual dentro de ella:
python -m venv .venvEn macOS/Linux, active el entorno virtual con:
source .venv/bin/activateO, en Windows, ejecute:
.venvScriptsactivateCon el entorno virtual activo, instale JupyterLab a través del paquete jupyterlab:
pip install jupyterlabInicie JupyterLab con:
jupyter labLa interfaz de JupyterLab se abrirá en http://localhost:8888/lab/ en su navegador. Cree un nuevo cuaderno haciendo clic en el botón «Python 3 (ipykernel)» en la sección «Notebook»:
Verá un archivo Untitled.ipynb:
Asigne un nombre a su nuevo cuaderno, como «Bright Data + PyTorch», y guárdelo.
¡Listo! Ahora tiene un entorno Python completamente configurado, listo para desarrollar flujos de trabajo de aprendizaje automático multimodal a través de PyTorch.
Paso n.º 2: Instalar e importar las dependencias necesarias
En su cuaderno, añada una nueva celda de código con el siguiente comando pip
!pip install pillow tqdm requests scikit-learn torch torchvision pandasEjecute este bloque para instalar todas las bibliotecas necesarias:
pillow: para cargar y procesar imágenes.tqdm: para mostrar barras de progreso para bucles, lo que resulta útil para realizar un seguimiento de la carga de datos y el entrenamiento.requests: Para descargar imágenes desde URL mediante solicitudes HTTP.scikit-learn: proporciona herramientas comotrain_test_splitpara dividir Conjuntos de datos.torch: La biblioteca principal de PyTorch para crear y entrenar modelos de aprendizaje automático.torchvision: proporciona Conjuntos de datos, modelos preentrenados y transformaciones de imágenes.pandas: maneja datos estructurados como archivos CSV y facilita la manipulación de datos.
En otra celda de código, importe todos los módulos necesarios:
import os
import io
import json
import requests
from PIL import Image, ImageStat
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
from tqdm import tqdm
from PIL import Image¡Genial! Con estas dos celdas, tu cuaderno está totalmente listo para manejar Conjuntos de datos multimodales de Bright Data y realizar el procesamiento de imágenes y texto utilizando PyTorch.
Paso n.º 3: Descargar el conjunto de datos de Bright Data
Ahora que tu cuaderno está configurado para el desarrollo con PyTorch, es el momento de obtener el componente más importante de este flujo de trabajo: ¡los datos de entrada!
Para este tutorial, utilizaremos el conjunto de datos«Productos de Amazon», uno de los muchos Conjuntos de datos de comercio electrónico disponibles en Bright Data. En el momento de escribir este artículo, ese conjunto de datos contiene más de 311 millones de entradas, cada una con 87 campos de datos. Para cada producto, esos campos enumeran las URL de las imágenes, la valoración de las reseñas, el ASIN del producto y mucha más información.
Nota: Puede recopilar datos estructurados actualizados de plataformas como Amazon, eBay, Walmart y muchas otras utilizando el Scraper de comercio electrónico de Bright Data.
Para empezar, si aún no tiene una cuenta de Bright Data, cree una. De lo contrario, inicie sesión y vaya a la página«Mercadodeconjuntos de datos»de su cuenta:
Seleccione el conjunto de datos «Amazon products» entre los «Most popular»:
Llegará a la página de los Conjuntos de datos:
Aquí puede filtrar las entradas manualmente o utilizar filtros basados en IA para crear subconjuntos adaptados a sus necesidades. Tenga en cuenta que esos filtros también se pueden aplicar mediante programación a través de la API de filtros, que le permite crear instantáneas de Conjuntos de datos basadas en criterios específicos.
Para este tutorial, solo necesitamos un pequeño conjunto de datos de muestra para demostrar un flujo de trabajo de ML multimodal, por lo que el conjunto de datos de muestra gratuito es suficiente. Para un flujo de trabajo listo para la producción o la empresa, debe descargar un conjunto de datos completo creado en función de sus necesidades específicas.
Para descargar el conjunto de datos de muestra, abra el menú desplegable «Muestra de conjunto de datos» y seleccione «Descargar como CSV»: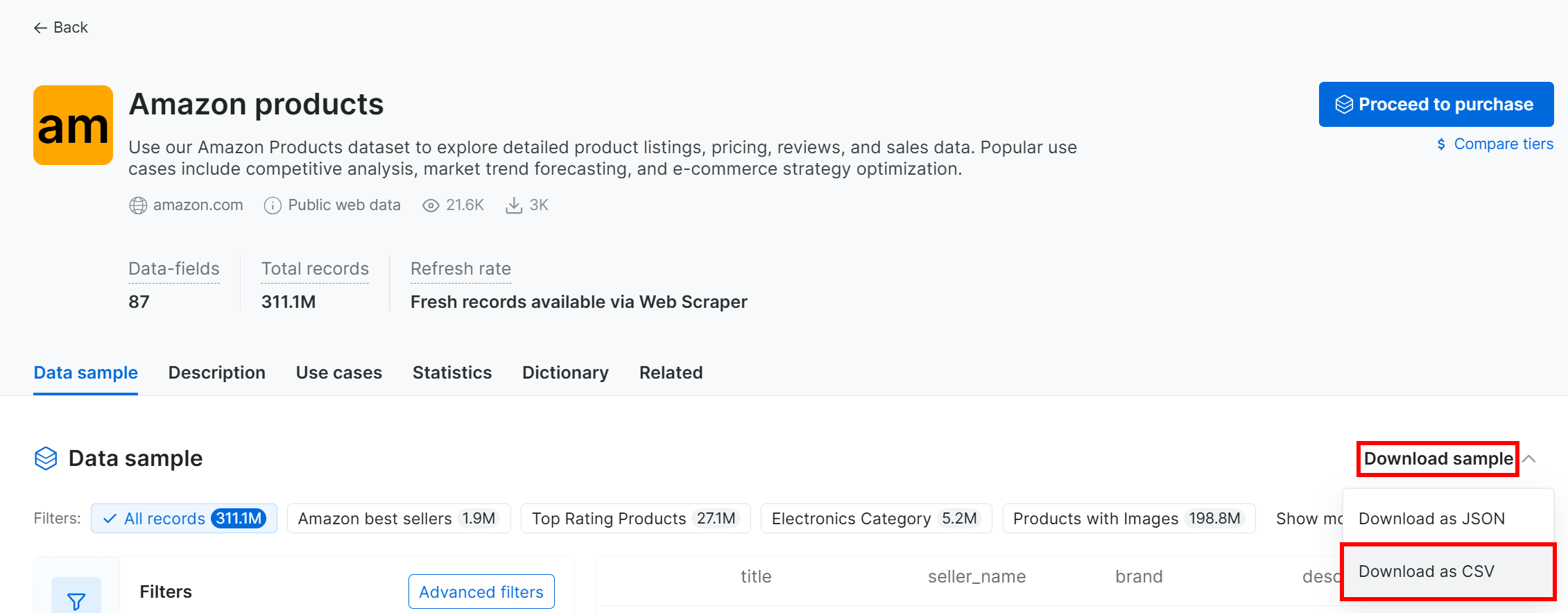
Recibirá un archivo llamado Amazon products.csv, que contiene 1000 productos (~7,3 MB). Cámbiele el nombre a amazon_products.csv y colóquelo en la carpeta de su proyecto: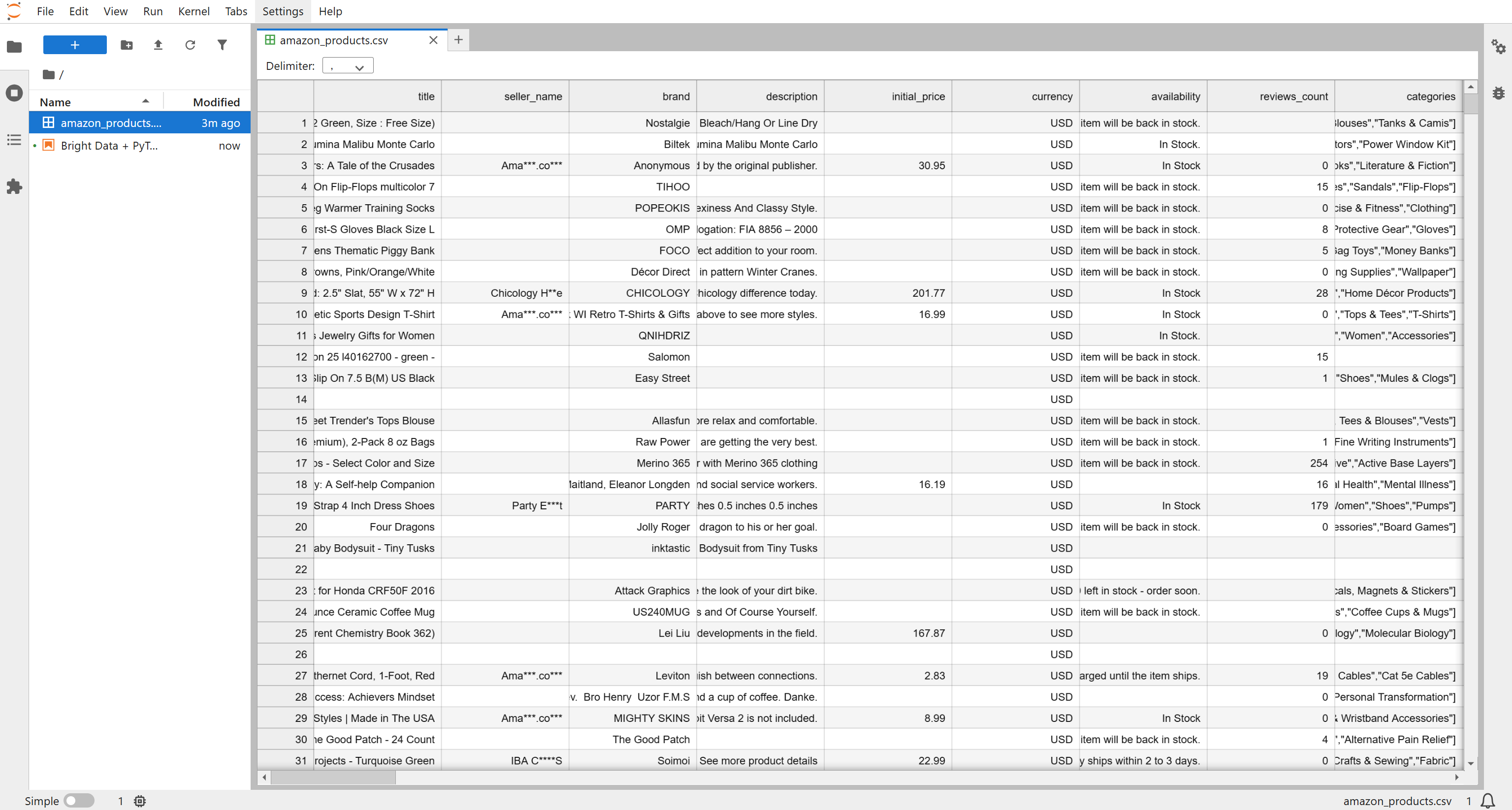
De los 87 campos disponibles, los relevantes para este flujo de trabajo multimodal son:
asin: el identificador único del producto en Amazon.image_url: la URL de la imagen principal del producto.images: una matriz en formato JSON que contiene URL de imágenes adicionales del producto.rating: la valoración media de las opiniones de los clientes, en una escala del 1 al 5.
Estos campos le permiten combinar datos visuales (imágenes) con datos numéricos estructurados (valoraciones) en un flujo de trabajo multimodal de PyTorch ML. ¡Fantástico! Ahora ya tiene el conjunto de datos de entrada.
Paso n.º 4: definir la lógica para descargar y etiquetar las imágenes de los productos
De vuelta en el cuaderno, inicialice la lógica central añadiendo las funciones para la descarga y el etiquetado de imágenes. Estas dos funciones constituyen los pilares para implementar el proceso de clasificación de imágenes de ML, que requiere los siguientes pasos:
- Recopilar datos de productos, incluyendo
image_url, matrizde imágenes,calificaciónyasin, del conjunto de datos «Productos de Amazon» de Bright Data. - Extraiga y deduplique las URL de las imágenes para cada entrada de producto.
- Descargar las imágenes de todas las URL y almacenarlas localmente.
- Etiquetar las imágenes, combinando heurística visual (fondo blanco, resolución) y valoraciones de reseñas.
- Preparar un conjunto de datos PyTorch utilizando las imágenes etiquetadas, adecuado para entrenar un modelo CNN (red neuronal convolucional).
- Ajustar una CNN para predecir la calidad de la imagen («BUENA» frente a «MALLA») utilizando el conjunto de datos etiquetado.
- Evaluar el modelo en un conjunto de prueba.
- Utiliza el modelo para evaluar automáticamente las imágenes de nuevos productos.
En una nueva celda de código de su cuaderno, escriba las funciones para descargar y etiquetar imágenes de productos:
def download_image(url):
# Enviar una solicitud GET a la URL de la imagen.
response = requests.get(url)
# Leer el contenido de la respuesta en un objeto BytesIO.
image_bytes = io.BytesIO(response.content)
# Abrir la imagen con PIL y convertirla al modo RGB.
image = Image.open(image_bytes).convert("RGB")
return image
def label_image(image, rating):
# Obtener la anchura y la altura de la imagen.
w, h = image.size
# Recortar los 10 píxeles superiores para analizar el brillo del borde.
border = image.crop((0, 0, w, 10))
# Calcular las estadísticas (media) del borde.
stat = ImageStat.Stat(border)
# Brillo medio en los canales RGB.
brightness = sum(stat.mean) / 3
# Determinar si la imagen tiene un fondo blanco.
is_white_bg = brightness > 240
# Determinar si la imagen es de baja resolución (lado más pequeño < 400 píxeles).
is_low_res = min(image.size) < 400
# Etiqueta heurística: 1 = buena si tiene fondo blanco y no es de baja resolución; 0 = mala en los demás casos.
heuristic_label = 1 si (is_white_bg y no is_low_res) en caso contrario 0
# Si la calificación falta o es cero, basarse solo en la heurística
si la calificación es None o la calificación == 0:
devolver heuristic_label
# Normalizar la calificación al rango 0-1
r = calificación / 5
# Aplicar supervisión débil para ajustar la etiqueta en función de las calificaciones extremas
if heuristic_label == 1 and r < 0.5: # calificación muy baja → marcar como mala
return 0
if heuristic_label == 0 and r > 0.9: # calificación excelente → marcar como buena
return 1
# De lo contrario, mantener la etiqueta heurística
return heuristic_labelLa función download_image() simplemente descarga una imagen de una URL determinada y la devuelve como una instancia de PIL Image. En cambio, la función label_image() implementa una evaluación multimodal de las imágenes de los productos, combinando señales visuales y datos textuales/numéricos, como las valoraciones de los clientes.
label_image() primero aplica heurística, comprobando si hay un fondo blanco y una resolución suficiente, para asignar una etiqueta inicial de «buena» o «mala». A continuación, si hay una calificación disponible, la función ajusta la etiqueta de la siguiente manera:
- Las valoraciones muy bajas anulan una imagen visualmente buena.
- Las valoraciones excelentes rescatan una imagen de aspecto deficiente.
Esta lógica tiene sentido porque, aunque una imagen parezca buena, una valoración baja indica que no es beneficiosa. Por el contrario, una valoración excelente puede destacar una imagen exitosa a pesar de que las imágenes sean malas. Por lo tanto, se tiene en cuenta tanto la información visual como la numérica a la hora de asignar la etiqueta final.
¡Genial! Es hora de importar los Conjuntos de datos y preparar las entradas de sus productos para aplicar estas dos funciones a todas las imágenes.
Paso n.º 5: Cargar el conjunto de datos y prepararse para descargar todas las imágenes
Si inspecciona el archivo amazon_products.csv, verá que las imágenes de los productos se almacenan en dos campos de datos:
image_url: URL de la imagen principal del producto.images: una cadena con formato JSON que contiene una matriz con todas las imágenes adicionales del producto.
En un nuevo bloque de código, carga el CSV y recupera todas las imágenes de cada producto utilizando una función auxiliar:
def extract_image_list(row):
image_urls = []
# Comprueba si hay una única imagen principal image_url y añádela si existe y no está vacía.
if isinstance(row.get("image_url"), str) and row["image_url"].strip():
image_urls.append(row["image_url"].strip())
# Comprueba el campo «images», que puede ser una cadena JSON o una lista Python.
images_field = row.get("images")
if isinstance(images_field, str):
# Decodifica la cadena JSON en una lista Python.
decoded = json.loads(images_field)
if isinstance(decoded, list):
# Añade todas las imágenes de la lista a image_urls
image_urls.extend(decoded)
# Desduplica las URL convirtiéndolas en un conjunto y, a continuación, volviéndolas a convertir en una lista
return list(set(image_urls))
# Carga el CSV de productos de Amazon en un DataFrame
df = pd.read_csv("amazon_products.csv")
# Eliminar las filas que no contienen los campos obligatorios
df = df.dropna(subset=["asin", "image_url", "images", "rating"])
# Aplicar la función extract_image_list a cada fila para generar una lista de todas las URL de imágenes únicas
df["all_image_urls"] = df.apply(extract_image_list, axis=1)El conjunto de datos importado ahora tiene una nueva columna llamada all_image_urls. Esta almacena una lista deduplicada de todas sus URL de imágenes, combinando la imagen principal y cualquier imagen adicional. En el siguiente paso, accederás a ese campo para descargar y procesar todas las imágenes de cada producto.
Paso n.º 6: descargar y etiquetar todas las imágenes
En una celda, implemente la lógica para descargar todas las imágenes de los productos en una carpeta local images/ y etiquetarlas:
# Crear la carpeta «images» si aún no existe.
os.makedirs("images", exist_ok=True)
# Inicializar una lista para almacenar los metadatos de cada imagen descargada y etiquetada.
records = []
# Iterar sobre cada fila de productos en el DataFrame con una barra de progreso.
for idx, row in tqdm(df.iterrows(), total=len(df)):
# Acceder a los campos de datos del producto requeridos.
url_list = row["all_image_urls"]
rating = float(row["rating"])
asin = row.get("asin")
# Iterar sobre cada URL de imagen de este producto para descargarla y etiquetarla.
for i, url in enumerate(url_list):
# Descargar la imagen
image = download_image(url)
if image is None:
continue
# Construir un nombre de archivo utilizando ASIN y el índice de la imagen
filename = f"{asin}_{i}.jpg"
path = os.path.join("images", filename)
# Guardar la imagen descargada en el disco
image.save(path)
# Etiqueta la imagen utilizando la información multimodal
etiqueta = etiquetar_imagen(imagen, calificación)
# Almacena los metadatos relevantes para esta imagen
registros.append({
"asin": asin,
"ruta_imagen": ruta,
"url_imagen": url,
"etiqueta": etiqueta
})
# Convierte la lista de registros en un DataFrame y expórtala a un archivo CSV
labeled_df = pd.DataFrame(records)
labeled_df.to_csv("labeled_images.csv", index=False)Al ejecutar este bloque de código en tu cuaderno, se iniciará el proceso de descarga. Se descargarán más de 2500 imágenes, así que ten paciencia durante unos minutos.
Una vez completado, la salida en la celda de código debería mostrar una barra de progreso al 100 %:
Ahora, la carpeta images/ en el directorio de su proyecto contendrá todas las imágenes de productos descargadas del conjunto de datos:
Además, se creará localmente el archivo labeled_images.csv, que contendrá la información de etiquetado de cada imagen:
¡Genial! Ahora dispone de todas las imágenes locales y la información de etiquetado necesarias para entrenar el modelo de aprendizaje automático en un proceso multimodal.
Paso n.º 7: Prepare los Conjuntos de datos de entrenamiento y prueba
Añada un nuevo bloque para leer la información de etiquetado de las imágenes del archivo labeled_images.csv y utilícela para producir conjuntos de datos de entrenamiento y prueba que utilizará para el ajuste fino del modelo de aprendizaje automático:
# Defina una clase de conjunto de datos PyTorch personalizada para las imágenes de los productos.
class ProductImageDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
def __len__(self):
# Devuelve el número total de muestras del conjunto de datos.
return len(self.df)
def __getitem__(self, idx):
# Obtenga la ruta de la imagen y la etiqueta para un índice dado
path, label = self.df.iloc[idx]["image_path"], self.df.iloc[idx]["label"]
# Cargue la imagen y conviértala a RGB
image = Image.open(path).convert("RGB")
# Aplicar transformaciones si se proporcionan (por ejemplo, cambio de tamaño, conversión de tensor)
if self.transform:
image = self.transform(image)
# Devolver el tensor de imagen y la etiqueta como un tensor torch
return image, torch.tensor(label, dtype=torch.long)
# Cargar el CSV de imágenes etiquetadas
labeled_df = pd.read_csv("labeled_images.csv")
# Dividir el conjunto de datos en conjuntos de entrenamiento y prueba, manteniendo equilibrada la distribución de etiquetas
train_df, test_df = train_test_split(
labeled_df,
test_size=0.2,
stratify=labeled_df["label"]
)
# Definir transformaciones para cambiar el tamaño de las imágenes a 224x224 y convertirlas a tensores
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# Inicializar los objetos del conjunto de datos
train_ds = ProductImageDataset(train_df, transform)
test_ds = ProductImageDataset(test_df, transform)
# Envuelve los Conjuntos de datos en DataLoaders para procesarlos por lotes y mezclarlos
train_dl = DataLoader(train_ds, batch_size=32, shuffle=True)
test_dl = DataLoader(test_ds, batch_size=32)Este fragmento prepara las imágenes de productos etiquetadas para entrenar una CNN de PyTorch. Para ello, define un conjunto de datos personalizado y aplica estas transformaciones de imagen:
transforms.Resize((224, 224)): Cambia el tamaño de las imágenes a224×224. Esto es importante porque las imágenes del conjunto de datos tienen diferentes resoluciones y relaciones de aspecto, mientras que las CNN esperan que todas las entradas tengan el mismo tamaño fijo.transforms.ToTensor(): Los modelos PyTorch operan con tensores en lugar de imágenes PIL sin procesar. Esto convierte cada imagen en un tensor normalizado de forma(C, H, W)(canales, altura, anchura), lo que la hace compatible con la CNN.
En conjunto, las transformaciones estandarizan todas las imágenes en términos de tamaño y formato, lo que permite al modelo centrarse en el aprendizaje de patrones visuales en lugar de gestionar entradas inconsistentes. A continuación, el conjunto de datos se divide en conjuntos de entrenamiento y prueba, conservando las distribuciones de etiquetas, y se envuelve en objetos DataLoader para generar lotes de datos de imágenes y etiquetas.
En general, este paso garantiza que la CNN reciba datos con el formato adecuado, sentando las bases para un entrenamiento eficaz de aprendizaje automático multimodal. ¡Genial!
Paso n.º 8: Entrenar el modelo de aprendizaje automático multimodal
Con los conjuntos de datos de entrenamiento y prueba listos, ajuste una CNN en PyTorch para la clasificación de imágenes con este código:
# Seleccionar el dispositivo para el entrenamiento (GPU si está disponible, de lo contrario CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
# Cargar un modelo ResNet-18 preentrenado desde torchvision
model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)
# Reemplazar la capa final totalmente conectada para generar 2 clases (GOOD/BAD)
model.fc = nn.Linear(model.fc.in_features, 2)
# Mover el modelo al dispositivo seleccionado
model = model.to(device)
# Definir la función de pérdida para la clasificación
criterion = nn.CrossEntropyLoss()
# Definir el optimizador con una tasa de aprendizaje pequeña
opt = torch.optim.Adam(model.parameters(), lr=1e-4)
# Bucle de entrenamiento durante 3 épocas
for epoch in range(3):
model.train()
total_loss = 0
# Iterar sobre lotes de imágenes y etiquetas
for images, labels in tqdm(train_dl, desc=f"Epoch {epoch+1}"):
images, labels = images.to(device), labels.to(device)
opt.zero_grad()
out = model(images)
loss = criterion(out, labels)
loss.backward()
opt.step()
total_loss += loss.item()
# Imprimir la pérdida media para la época
print(f"Época {epoch+1}: Pérdida media={total_loss/len(train_dl):.4f}")La celda anterior ajusta con precisión una CNN ResNet-18 preentrenada, una red neuronal convolucional de 18 capas de profundidad que se emplea principalmente para clasificar imágenes en diversas categorías.
En este caso, el modelo de aprendizaje automático clasificará las imágenes de los productos como buenas o malas. El uso de los pesos de ImageNet acelera la convergencia y aprovecha las características ya aprendidas de millones de imágenes naturales. A continuación, se sustituye la capa final totalmente conectada para generar dos clases («BUENA» y «MALA», según lo previsto).
En el bucle, la instancia CrossEntropyLoss mide el error de clasificación, mientras que el optimizador Adam actualiza las ponderaciones del modelo. Cada época itera sobre lotes, realizando un paso hacia adelante, calculando la pérdida, la retropropagación y las actualizaciones de ponderación.
Ejecute el bloque de código y obtendrá un resultado como este: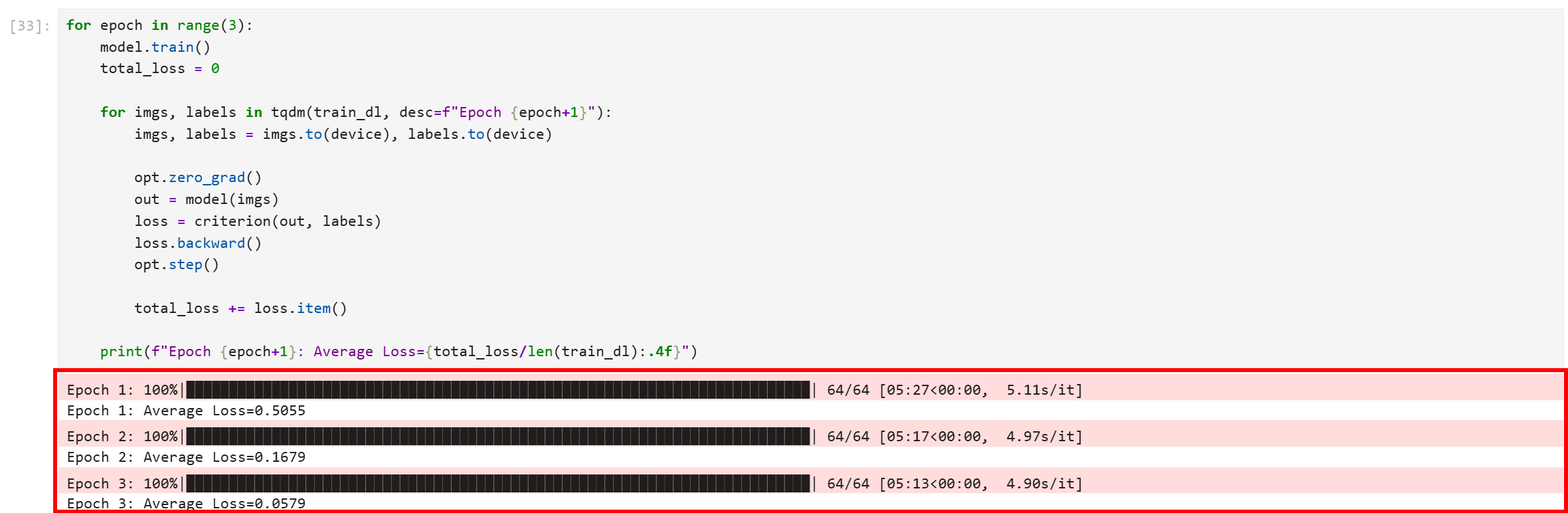
Tenga en cuenta que las tres épocas se completaron con éxito. La pérdida media final es de 0,0579, lo que es bastante bajo e indica que el modelo ha convergido bien y ha aprendido a distinguir entre las imágenes de entrenamiento con alta confianza.
¡Ya está! Acaba de ajustar una CNN para la distinción de la calidad de las imágenes de comercio electrónico.
Paso n.º 9: Evaluar el rendimiento del modelo
Para verificar el rendimiento del modelo, ejecuta un paso de evaluación:
# Cargar la versión de evaluación del modelo.
model.eval()
# Para realizar un seguimiento de las imágenes procesadas.
correct = 0
total = 0
# Evaluar el modelo con respecto al conjunto de datos de entrenamiento.
with torch.no_grad():
for images, labels in test_dl:
images, labels = images.to(device), labels.to(device)
out = model(images)
prediction = out.argmax(dim=1)
correct += (prediction == labels).sum().item()
total += len(labels)
# Mostrar los resultados
print("Precisión de la prueba:", correct / total)Esto mide la capacidad del modelo ajustado para generalizar datos que nunca ha visto antes (el conjunto de datos de prueba). En concreto, realiza la evaluación del modelo mediante inferencia.
La celda de código primero cambia el modelo al modo de evaluación y desactiva el seguimiento del gradiente para optimizar la velocidad y garantizar un comportamiento coherente. A continuación, el bucle itera a través del conjunto de datos de prueba, comparando las predicciones del modelo con las etiquetas reales. Por último, calcula la precisión total, proporcionando una métrica clara de la capacidad del modelo para generalizar más allá del conjunto de entrenamiento.
El resultado debería ser algo así:

Una puntuación de precisión de prueba de 0,924XXX significa que su modelo ResNet-18 ajustado clasificó correctamente más del 92,4 % de las imágenes de productos de sus conjuntos de datos de prueba no vistos como «BUENO» o «MALO».
Esto puede considerarse un resultado excelente para la clasificación binaria en datos del mundo real, como las imágenes de productos de comercio electrónico. Sugiere claramente que el modelo ha aprendido con éxito la diferencia entre las características de buena y mala calidad de imagen y no se limita a memorizar los datos de entrenamiento.
¡Bien hecho! Ahora apliquemos el modelo ajustado a un par de imágenes nuevas para ver si funciona como se espera.
Paso n.º 10: Utilizar el modelo de aprendizaje automático para predecir la calidad de la imagen
Para validar realmente si el modelo ajustado funciona como se espera, debe probar su rendimiento con imágenes con las que nunca se ha encontrado. Dado que el modelo está entrenado para funcionar con cualquier imagen de producto de comercio electrónico, puede probarlo con imágenes de plataformas como eBay, Walmart, Alibaba o sus propias bases de datos internas de productos.
En esta demostración, probaremos el modelo con las dos imágenes de productos siguientes, procedentes de eBay:
Para ello, añada el siguiente código en un bloque dedicado:
def predict_image_quality(img: Image.Image) -> str:
# Establecer el modelo en modo de evaluación.
model.eval()
# Aplicar transformaciones y añadir una dimensión por lotes.
x = transform(img).unsqueeze(0).to(device)
with torch.no_grad():
# Paso hacia adelante, obtener el índice de clase predicho y extraerlo como un escalar
prediction = model(x).argmax().item()
# Devolver la cadena de resultado
return "GOOD" if prediction == 1 else "BAD"
# Imágenes de prueba
image_urls = ["https://i.ebayimg.com/images/g/N5kAAOSwTlplqFTa/s-l500.webp", "https://i.ebayimg.com/images/g/yUsAAOSweMJd67Jd/s-l1600.webp"]
# Recorrer las URL de las imágenes, descargar, predecir y mostrar
for image_url in image_urls:
# Descargar el contenido de la imagen mediante una solicitud HTTP
response = requests.get(image_url)
image = Image.open(io.BytesIO(response.content)).convert("RGB")
# Llamar a la función de predicción.
quality = predict_image_quality(image)
# Mostrar la imagen en el cuaderno junto con los resultados del modelo.
display(image)
print(image_url, "→", quality)Al ejecutar la celda, observará las siguientes clasificaciones:
Tenga en cuenta que el modelo clasificó la imagen como «MAL». Este es un resultado correcto, ya que la imagen es visiblemente de baja calidad, borrosa y el fondo carece de contraste nítido, lo que no permite resaltar adecuadamente el producto.
En cambio, en la segunda imagen, produce:
Esta vez, la clasificación es «BUENA», lo cual es un resultado convincente teniendo en cuenta que la imagen es visualmente atractiva, nítida y bien iluminada. Además, muestra claramente el producto.
¡Et voilà! Gracias a los ricos Conjuntos de datos de Bright Data, ha recuperado datos de productos de comercio electrónico (en este caso, de Amazon). A continuación, ha aplicado PyTorch para ajustar una CNN para el reconocimiento de imágenes siguiendo un enfoque de análisis de datos ML multimodal.
Conclusión
En esta entrada del blog, has visto cómo implementar un sistema de aprendizaje automático multimodal. Hemos utilizado conjuntos de datos de productos que contienen cientos de millones de productos de Amazon y sus imágenes correspondientes.
Al introducir esos datos en un flujo de trabajo de PyTorch dentro de un cuaderno de Python, has ajustado con éxito una CNN (red neuronal convolucional) para clasificar las imágenes de productos de comercio electrónico como buenas o malas.
Este proyecto responde directamente a las necesidades de las pequeñas y medianas empresas o de las grandes empresas que buscan formas de evaluar rápidamente la calidad de las imágenes para la representación de productos, especialmente con fines de comercio electrónico.
Todo esto no sería posible sin los servicios de datos empresariales de Bright Data, que te ayudan a recopilar datos de más de 100 dominios, incluidos Amazon, Walmart, LinkedIn, Zillow, Airbnb, Yahoo Finance y muchos otros.
¡Regístrese hoy mismo en Bright Data para probar nuestras soluciones de datos de forma gratuita!