

Google Travel recopila datos de viajes de todo el web para todo tipo de categorías relacionadas con los viajes, como vuelos, paquetes vacacionales y habitaciones de hotel. Buscar hoteles es difícil, y una de las mayores molestias es tener que clasificar entre la maraña de anuncios patrocinados y habitaciones aleatorias que no se ajustan a tu búsqueda.
Si no te interesa el scraping, echa un vistazo a nuestros Conjuntos de datos de viajes prefabricados. Con los Conjuntos de datos, nosotros nos encargamos del scraping para que tú no tengas que hacerlo. Si estás listo para hacer scraping, ¡sigue leyendo!
Requisitos previos
Para extraer datos de viajes, necesitarás Python y Selenium, Requests o AIOHTTP. Con Selenium, extraeremos la información de los hoteles directamente de Google Travel. Con Requests y AIOHTTP, utilizaremos la API de Booking.com de Bright Data.
Si utiliza Selenium, debe asegurarse de tener instalado webdriver. Si no está familiarizado con Selenium, puede echar un vistazo a esta guía para familiarizarse rápidamente.
Instalar Selenium
pip install selenium
Instalar Requests
pip install requests
Instalar AIOHTTP
pip install aiohttp
Una vez que hayas instalado la herramienta que elijas, estarás listo para empezar.
Qué extraer de Google Travel
Si decides extraer datos de Google Travel manualmente, debes comprender mejor qué datos estamos tratando de extraer. Todos nuestros resultados de hoteles vienen incrustados en un elemento c-wiz personalizado de Google Travel.
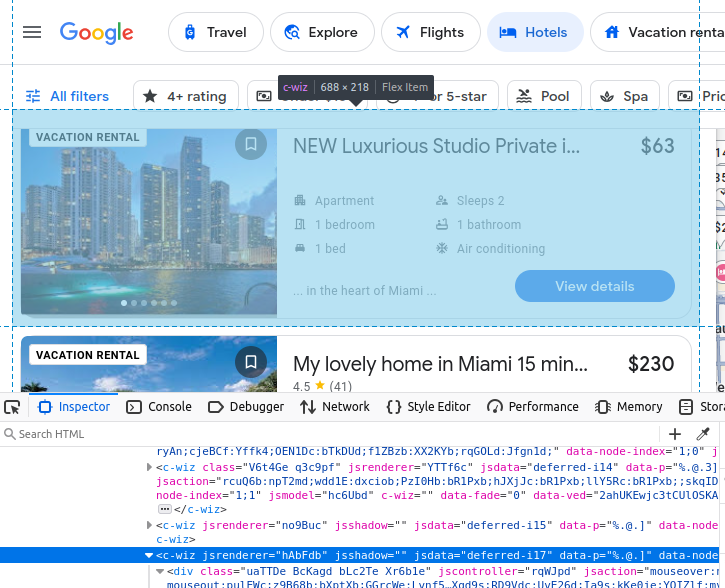
Sin embargo, hay muchos elementos c-wiz en la página. Cada una de nuestras tarjetas de hotel contiene un elemento a que desciende directamente de un div y de este elemento c-wiz. Podemos escribir un selector CSS para encontrar todas las etiquetas a que descienden de estos elementos: c-wiz > div > a.
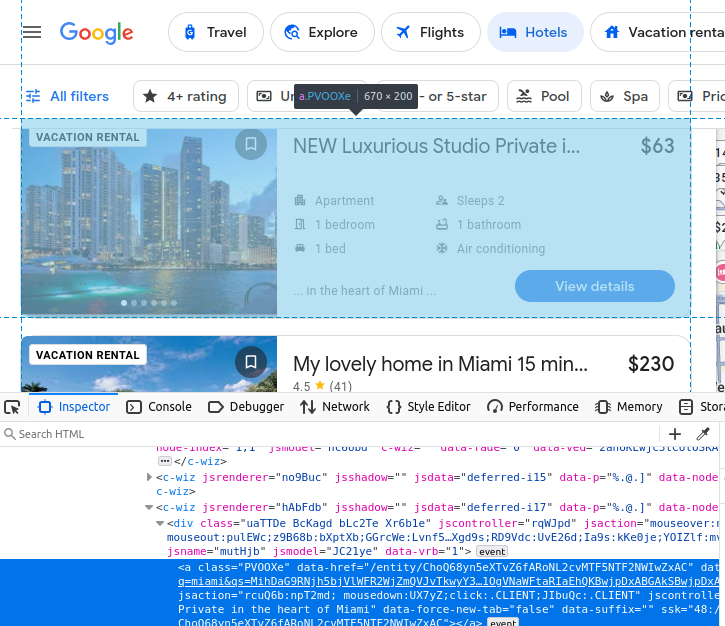
El nombre del anuncio viene incrustado en un h2.
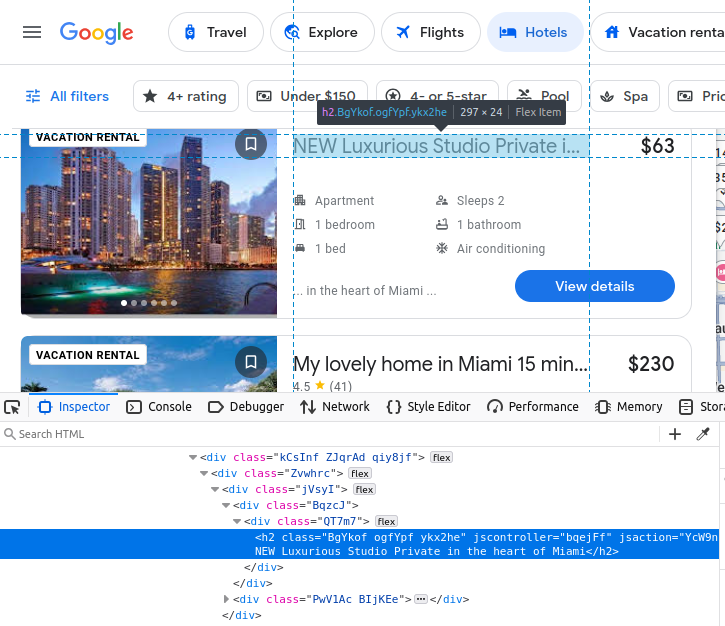
Nuestro precio viene incrustado en un span.
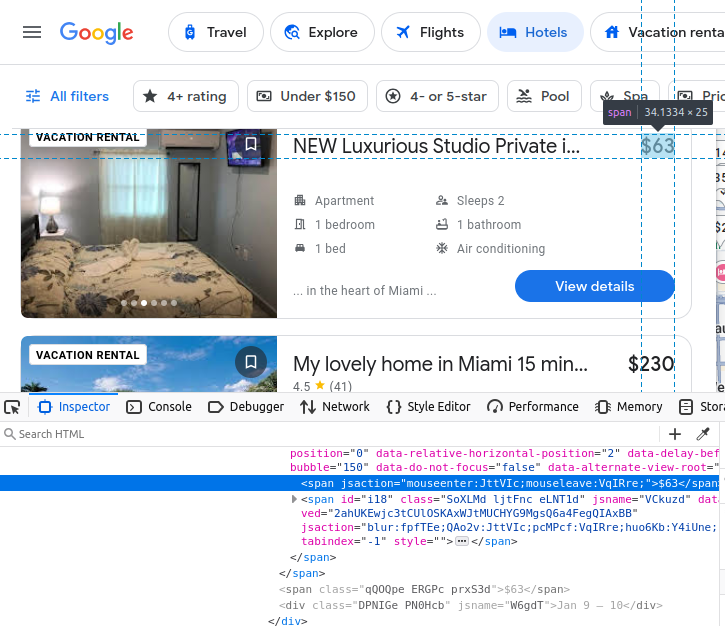
Nuestras comodidades están incrustadas en elementos li (lista).
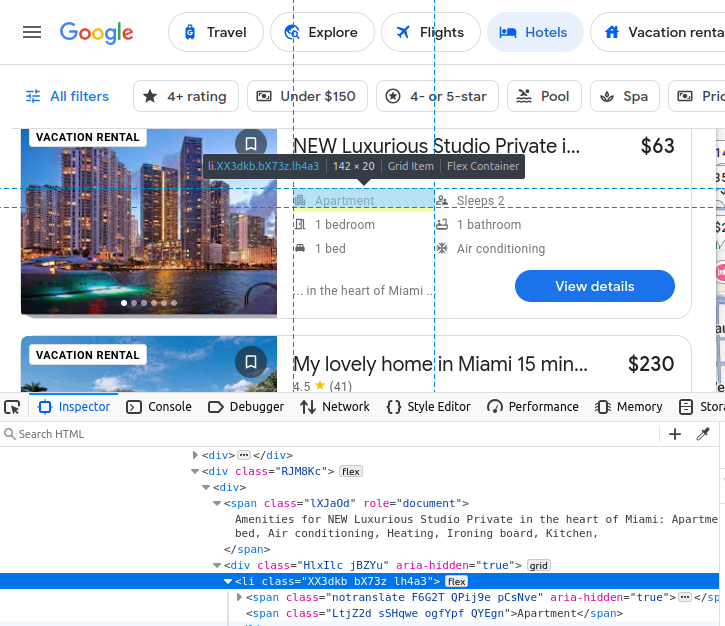
Después de encontrar nuestra ficha de hotel, podemos extraer todos los datos mencionados anteriormente.
Extraer los datos con Selenium
Extraer estos datos con Selenium es relativamente sencillo una vez que sabes qué buscar. Sin embargo, Google Travel carga nuestros resultados de forma dinámica, lo que hace que sea un proceso un poco delicado que se mantiene unido por esperas preconfiguradas, clics del ratón y ventanas personalizadas. Sin la ventana personalizada, los resultados no se cargarán correctamente.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import json
from time import sleep
OPTIONS = webdriver.ChromeOptions()
OPTIONS.add_argument("--headless")
OPTIONS.add_argument("--window-size=1920,1080")
def scrape_hotels(location, pages=5):
driver = webdriver.Chrome(options=OPTIONS)
actions = ActionChains(driver)
url = f"https://www.google.com/travel/search?q={location}"
driver.get(url)
done = False
found_hotels = []
page = 1
result_number = 1
while page <= pages:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(5)
hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")
print(f"-----------------PÁGINA {página}------------------")
imprimir("ELEMENTOS ENCONTRADOS: ", len(enlaces_hoteles))
para enlace_hotel en enlaces_hoteles:
tarjeta_hotel = enlace_hotel.find_element(By.XPATH, "..")
intentar:
info = {}
info["url"] = hotel_link.get_attribute("href")
info["rating"] = 0.0
info["price"] = "n/a"
info["name"] = hotel_card.find_element(By.CSS_SELECTOR, "h2").text
price_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span")
info["amenities"] = []
amenities_holders = hotel_card.find_elements(By.CSS_SELECTOR, "li")
for amenity in amenities_holders:
info["amenities"].append(amenity.text)
if "DEAL" in price_holder[0].text or "PRICE" in price_holder[0].text:
if price_holder[1].text[0] == "$":
info["price"] = price_holder[1].text
else:
info["price"] = price_holder[0].text
rating_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span[role='img']")
if rating_holder:
info["rating"] = float(rating_holder[0].get_attribute("aria-label").split(" ")[0])
info["result_number"] = result_number
if info not in found_hotels:
found_hotels.append(info)
result_number+=1
except:
continue
print("Total recopilado:", len(found_hotels))
next_button = driver.find_elements(By.XPATH, "//span[text()='Next']")
if next_button:
print("¡Botón siguiente encontrado!")
sleep(1)
actions.move_to_element(next_button[0]).click().perform()
page+=1
sleep(5)
else:
done = True
driver.quit()
with open("scraped-hotels.json", "w") as file:
json.dump(found_hotels, file, indent=4)
if __name__ == "__main__":
PAGES = 2
scrape_hotels("miami", pages=PAGES)
- Primero, creamos una instancia de
ChromeOptions. La utilizamos para añadir nuestros argumentos--headlessy--window-size=1920,1080.- Sin nuestro tamaño de ventana personalizado, los resultados no se cargan correctamente, por lo que terminamos recopilando los mismos resultados una y otra vez.
- Cuando iniciamos el navegador, utilizamos el argumento de palabra clave
options=OPTIONS. Esto inicia Chrome con nuestras opciones personalizadas. ActionChains(driver)nos proporciona una instanciade ActionChains. La utilizamos más adelante en nuestro script para mover el cursor al botónSiguientey hacer clic en él.- Utilizamos un bucle
whilepara contener nuestro tiempo de ejecución. Una vez que haya finalizado el rastreo, saldremos de este bucle. hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")nos da todos los enlaces de hoteles de la página. Encontramos sus elementos principales utilizando su xpath:hotel_card = hotel_link.find_element(By.XPATH, "..").- A continuación, revisamos y extraemos todos los datos individuales que hemos visto anteriormente:
- url:
hotel_link.get_attribute("href") - name:
hotel_card.find_element(By.CSS_SELECTOR, "h2").text - Al buscar el precio, a veces hay elementos adicionales en la tarjeta, como
DEALyGREAT PRICE. Para asegurarnos de que siempre obtenemos el precio correcto, extraemos los elementosspanen una matriz. Si la matriz contiene estas palabras, tomamos el segundo elemento (price_holder[1].text) en lugar del primero (price_holder[0].text). - También utilizamos el método
find_elements()cuando buscamos la valoración. Si no hay ninguna valoración, le damos un valor predeterminado den/a. hotel_card.find_elements(By.CSS_SELECTOR, "li")nos da nuestros titulares de servicios. Extraemos cada uno de ellos utilizando su atributode texto.
- url:
- Continuamos este bucle hasta que hayamos extraído todas las páginas deseadas. Una vez que tenemos nuestros datos, establecemos
doneenTruey salimos del bucle. - Cerramos el navegador de scraping y utilizamos
json.dump()para guardar todos los datos extraídos en un archivo JSON.
Al extraer hoteles de Google Travel, no encontramos ningún problema de bloqueo, pero todo es posible. Si se encuentra con algún problema, ofrecemos Proxies residenciales y un Navegador de scraping integrado con Proxy para ayudarle a superar cualquier obstáculo que se le presente.
Extraer estos resultados con Selenium es tedioso y delicado, pero totalmente factible.
Extraiga los datos con la API de viajes de Bright Data
A veces no quieres depender de un Scraper o pasar todo el día lidiando con selectores y localizadores. ¡No pasa nada! Ofrecemos varios tipos de datos de viajes. Incluso puedes extraer datos de hoteles utilizando nuestra API de Booking.com. Todo lo que tienes que hacer es realizar unas cuantas solicitudes HTTP. Nosotros nos encargamos del resto para que puedas seguir con tu día.
Solicitudes
El código siguiente te configura con la API de Booking.com. Solo tienes que introducir tu clave API, el lugar de viaje, la fecha de entrada y la fecha de salida. En primer lugar, realiza una solicitud a la API para generar los datos. A continuación, comprueba los datos cada 10 segundos hasta que nuestro informe está listo. Una vez que hemos recibido nuestros datos, los guardamos cómodamente en un archivo JSON.
import requests
import json
import time
def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/conjuntos_de_datos/v3/trigger"
#booking.com dataset
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
auth_token = api_key
#
headers = {
"Authorization": f"Bearer {auth_token}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
response = requests.post(endpoint, headers=headers, json=payload)
if response.status_code == 200:
print("Solicitud correcta. Respuesta:")
print(json.dumps(response.json(), indent=4))
return response.json()["snapshot_id"]
else:
print(f"Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file="snapshot-data.json"):
#crear la URL de la instantánea
snapshot_url = f"https://api.brightdata.com/conjuntos-de-datos/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Sondeando instantánea para ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("La instantánea está lista. Descargando...")
snapshot_data = response.json()
#escribe la instantánea en un nuevo archivo json
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Instantánea guardada en {output_file}")
break
elif response.status_code == 202:
print("La instantánea aún no está lista. Reintentando en 10 segundos...")
else:
print(f"Error: {response.status_code}")
print(response.text)
break
time.sleep(10)
if __name__ == "__main__":
API_KEY = "tu-clave-api-bright-data"
LOCATION = "Miami"
CHECK_IN = "2026-02-01T00:00:00.000Z"
CHECK_OUT = "2026-02-02T00:00:00.000Z"
DATES = {
"check_in": CHECK_IN,
"check_out": CHECK_OUT
}
snapshot_id = get_bookings(API_KEY, LOCATION, DATES)
poll_and_retrieve_snapshot(API_KEY, snapshot_id)
get_bookings()toma tuAPI_KEY,LOCATIONyDATES. A continuación, realiza una solicitud de datos y devuelve elsnapshot_id.- El
snapshot_ides muy importante. Lo necesitamos para recuperar la instantánea. - Una vez generado el
snapshot_id,poll_and_retrieve_snapshot()comprueba cada 10 segundos si los datos están listos. - Una vez que los datos están listos, utilizamos
json.dump()para guardarlos en un archivo JSON.
Cuando ejecute el código, debería ver algo similar a esto en su terminal.
Solicitud correcta. Respuesta:
{
"snapshot_id": "s_m5moyblm1wikx4ntot"
}
Solicitando instantánea para ID: s_m5moyblm1wikx4ntot...
La instantánea aún no está lista. Volviendo a intentarlo en 10 segundos...
La instantánea aún no está lista. Volviendo a intentarlo en 10 segundos...
La instantánea aún no está lista. Volviendo a intentarlo en 10 segundos...
La instantánea aún no está lista. Volviendo a intentarlo en 10 segundos...
La instantánea está lista. Descargando...
Instantánea guardada en snapshot-data.json
A continuación, obtendrá un archivo JSON lleno de objetos como este.
{
"input": {
"url": "https://www.booking.com",
"location": "Miami",
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z",
"adults": 2,
"rooms": 1
},
"url": "https://www.booking.com/hotel/us/ramada-plaze-by-wyndham-marco-polo-beach-resort.html?checkin=2025-02-01&checkout=2025-02-02&group_adults=2&no_rooms=1&group_children=",
"location": "Miami",
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z",
"adults": 2,
"children": null,
"rooms": 1,
"id": "55989",
«title»: «Ramada Plaza by Wyndham Marco Polo Beach Resort»,
«address»: «19201 Collins Avenue»,
«city»: «Sunny Isles Beach (Florida)»,
«review_score»: 6.2,
«review_count»: «1788»,
«imagen»: «https://cf.bstatic.com/xdata/images/hotel/square600/414501733.webp?k=4c14cb1ec5373f40ee83d901f2dc9611bb0df76490f3673f94dfaae8a39988d8&o=",
«precio_final»: 217,
«precio_original»: 217,
«moneda»: «USD»,
"tax_description": null,
"nb_livingrooms": 0,
"nb_kitchens": 0,
"nb_bedrooms": 0,
"nb_all_beds": 2,
"full_location": {
"description": "Esta es la distancia en línea recta en el mapa. La distancia real del trayecto puede variar.",
"main_distance": "11,4 millas del centro",
"display_location": "Miami Beach",
"beach_distance": "Frente al mar",
"nearby_beach_names": []
},
"no_prepayment": false,
"free_cancellation": true,
"property_sustainability": {
"is_sustainable": false,
"level_id": "L0",
"facilities": [
"436",
"490",
"492",
"496",
"506"
]
},
"timestamp": "2026-01-07T16:43:24.954Z"
},
AIOHTTP
Con AIOHTTP, podemos acelerar bastante este proceso. De hecho, podemos activar, sondear y descargar varios Conjuntos de datos simultáneamente. El código siguiente se basa en nuestros conceptos del ejemplo anterior de Requests, pero en su lugar utiliza el potente aiohttp.ClientSession() para realizar varias solicitudes de forma asíncrona.
import aiohttp
import asyncio
import json
async def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/conjuntos_de_datos/v3/trigger"
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
async with aiohttp.ClientSession(headers=headers) as session:
async with session.post(endpoint, json=payload) as response:
if response.status == 200:
response_data = await response.json()
print(f"Solicitud exitosa para la ubicación: {location}. Respuesta:")
print(json.dumps(response_data, indent=4))
return response_data["snapshot_id"]
else:
print(f"Error para la ubicación: {location}. Estado: {response.status}")
print(await response.text())
return None
async def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file):
snapshot_url = f"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Solicitando instantánea para ID: {snapshot_id}...")
async with aiohttp.ClientSession(headers=headers) as session:
while True:
async with session.get(snapshot_url) as response:
if response.status == 200:
print(f"La instantánea para {archivo_de_salida} está lista. Descargando...")
snapshot_data = await response.json()
# Guardar los datos de la instantánea en un archivo
with open(archivo_de_salida, "w", encoding="utf-8") as archivo:
json.dump(snapshot_data, archivo, indent=4)
print(f"Instantánea guardada en {archivo_de_salida}")
break
elif response.status == 202:
print(f"La instantánea para {archivo_de_salida} aún no está lista. Reintentando en 10 segundos...")
else:
print(f"Error al sondear la instantánea para {archivo_de_salida}. Estado: {response.status}")
print(await response.text())
break
await asyncio.sleep(10)
async def process_location(api_key, location, dates):
snapshot_id = await get_bookings(api_key, location, dates)
if snapshot_id:
output_file = f"snapshot-{location.replace(' ', '_').lower()}.json"
await poll_and_retrieve_snapshot(api_key, snapshot_id, output_file)
locations = ["Miami", "Key West"]
dates = {
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z"
}
# Procesar todas las ubicaciones en paralelo
tasks = [process_location(api_key, location, dates) for location in locations]
await asyncio.gather(*tasks)
if __name__ == "__main__":
asyncio.run(main())
- Tanto
get_bookings()comopoll_and_retrieve_snapshot()utilizan ahora nuestro objetoaiohttp.ClientSessionpara crear solicitudes asíncronas al servidor. process_location()se utiliza para procesar todos los datos de una ubicación.main()nos permite llamar aprocess_location()en todas las ubicaciones simultáneamente.
Con AIOHTTP, puede activar, sondear y descargar varios Conjuntos de datos al mismo tiempo. De esta manera, no es necesario esperar innecesariamente a que se complete un informe antes de generar el siguiente.
Eche un vistazo al resultado. Como puede ver, activamos ambos informes. A continuación, descargamos un informe mientras seguimos esperando el otro. A gran escala, esto le ahorrará una cantidad increíble de tiempo.
Solicitud exitosa para la ubicación: Miami. Respuesta:
{
"snapshot_id": "s_m5mtmtv62hwhlpyazw"
}
Solicitud exitosa para la ubicación: Cayo Hueso. Respuesta:
{
"snapshot_id": "s_m5mtmtv72gkkgxvdid"
}
Solicitando instantánea para ID: s_m5mtmtv62hwhlpyazw...
Solicitando instantánea para ID: s_m5mtmtv72gkkgxvdid...
La instantánea para snapshot-miami.json aún no está lista. Reintentando en 10 segundos...
La instantánea para snapshot-key_west.json aún no está lista. Reintentando en 10 segundos...
La instantánea para snapshot-key_west.json aún no está lista. Reintentando en 10 segundos...
La instantánea para snapshot-miami.json aún no está lista. Reintentando en 10 segundos...
La instantánea para snapshot-key_west.json aún no está lista. Reintentando en 10 segundos...
La instantánea para snapshot-miami.json aún no está lista. Volviendo a intentarlo en 10 segundos...
La instantánea para snapshot-miami.json está lista. Descargando...
La instantánea para snapshot-key_west.json aún no está lista. Volviendo a intentarlo en 10 segundos...
Instantánea guardada en snapshot-miami.json.
La instantánea para snapshot-key_west.json aún no está lista. Reintentando en 10 segundos...
La instantánea para snapshot-key_west.json aún no está lista. Reintentando en 10 segundos...
La instantánea para snapshot-key_west.json aún no está lista. Reintentando en 10 segundos...
La instantánea para snapshot-key_west.json está lista. Descargando...
Instantánea guardada en snapshot-key_west.json
Soluciones alternativas de Bright Data
Más allá de nuestras potentes API de Web Scraper, Bright Data ofrece conjuntos de datos listos para usar y adaptados a diversas necesidades. Entre nuestros conjuntos de datos de viajes más solicitados se encuentran:
- Conjuntos de datos de hoteles
- Conjuntos de datos de Expedia
- Conjuntos de datos de turismo
- Conjuntos de datos de Booking.com
- Conjuntos de datos de TripAdvisor
Con Bright Data, puede elegir entre conjuntos de datos personalizados totalmente gestionados o autogestionados, lo que le permite extraer datos de cualquier sitio web público y personalizarlos según sus especificaciones exactas.
Conclusión
Al scraping web, puedes encontrar un tesoro de información sobre hoteles en Google Travel. Tanto si prefieres el modelo DIY con Selenium como si solo quieres resultados rápidos y cómodos con la API de Booking.com, puedes recopilar estos datos para obtener información realmente valiosa. Tanto si quieres analizar precios históricos como si solo quieres buscar una habitación de forma eficiente, ¡acabas de añadir otra habilidad útil a tu conjunto de conocimientos tecnológicos!
Regístrese ahora para probar los productos de Bright Data de forma gratuita.






