

En este artículo, aprenderás paso a paso cómo extraer datos deGoogle Scholarcon Python. Antes de sumergirnos en los pasos de extracción, repasaremos los requisitos previos y cómo configurar nuestro entorno. ¡Empecemos!
Alternativa al rastreo manual de Google Scholar
Extraer datos manualmente de Google Scholar puede ser complicado y llevar mucho tiempo. Como alternativa, considera utilizar los Conjuntos de datos de Bright Data:
- Mercado de conjuntos de datos: accede a datos recopilados previamente y listos para su uso inmediato.
- Conjuntos de datos personalizados: solicite o cree conjuntos de datos adaptados a sus necesidades específicas.
El uso de los servicios de Bright Data le ahorra tiempo y le garantiza información precisa y actualizada sin las complejidades del scraping manual. ¡Ahora, continuemos!
Requisitos
Antes de comenzar este tutorial, debe instalar los siguientes elementos:
- La última versión dePython
- Un editor de código de su elección, comoVisual Studio Code
Además, antes de comenzar cualquier proyecto de scraping, debes asegurarte de que tus scripts cumplan con el archivorobots.txtdel sitio web para no extraer información de áreas restringidas. El código utilizado en este artículo tiene fines exclusivamente educativos y debe utilizarse de forma responsable.
Configurar un entorno virtual Python
Antes de configurar su entorno virtual Python, navegue hasta la ubicación deseada para el proyecto y cree una nueva carpeta llamada google_scholar_scraper:
mkdir google_scholar_scraper
cd google_scholar_scraper
Una vez que haya creado la carpeta google_scholar_scraper, cree un entorno virtual para el proyecto con el siguiente comando:
python -m venv google_scholar_env
Para activar su entorno virtual, utilice el siguiente comando en Linux/Mac:
source google_scholar_env/bin/activate
Sin embargo, si utilizas Windows, utiliza lo siguiente:
.google_scholar_envScriptsactivate
Instala los paquetes necesarios
Una vez activadovenv, debe instalarBeautiful Soupypandas:
pip install beautifulsoup4 pandas
Beautiful Soup ayuda a realizar el parseo de las estructuras HTML de las páginas de Google Scholar y a extraer elementos de datos específicos, como artículos, títulos y autores. pandas organiza los datos que extraes en un formato estructurado y los almacena como un archivo CSV.
Además de Beautiful Soup y pandas, también debe configurarSelenium. Los sitios web como Google Scholar suelen implementar medidas para bloquear las solicitudes automatizadas y evitar la sobrecarga. Selenium le ayuda a eludir estas restricciones automatizando las acciones del navegador e imitando el comportamiento del usuario.
Utilice el siguiente comando para instalar Selenium:
pip install selenium
Asegúrate de que estás utilizando la última versión de Selenium (4.6.0 en el momento de escribir este artículo) para no tener que descargarChromeDriver.
Crea un script de Python para acceder a Google Scholar
Una vez que haya activado su entorno y haya descargado las bibliotecas necesarias, es el momento de empezar a extraer datos de Google Scholar.
Cree un nuevo archivo Python llamado gscholar_scraper.py en el directorio google_scholar_scraper y, a continuación, importe las bibliotecas necesarias:
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
A continuación, vas a configurarSelenium WebDriverpara controlar el navegador Chrome en modo sin interfaz gráfica (es decir, sin interfaz gráfica de usuario), ya que esto te ayuda a extraer datos sin abrir una ventana del navegador. Añade la siguiente función al script para inicializar Selenium WebDriver:
def init_selenium_driver():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
return driver
Una vez que hayas inicializado WebDriver, debes añadir otra función al script que envíe la consulta de búsqueda a Google Scholar utilizando Selenium WebDriver:
def fetch_search_results(driver, query):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}"
driver.get(base_url + params)
driver.implicitly_wait(10) # Espera hasta 10 segundos a que se cargue la página
# Devuelve el código fuente de la página (contenido HTML)
return driver.page_source
En este código, driver.get(base_url + params) le indica a Selenium WebDriver que navegue a la URL construida. El código también configura WebDriver para que espere hasta diez segundos a que se carguen todos los elementos de la página antes de realizar Parseo.
Parseo el contenido HTML
Una vez que tengas el contenido HTML de la página de resultados de búsqueda, necesitarás una función para Parseo y extraer la información necesaria.
Para obtener los selectores CSS y los elementos adecuados para los artículos, es necesario inspeccionar manualmente la página de Google Scholar. Utilice las herramientas de desarrollo de su navegador y busque clases o ID únicas para los elementos de autor, título y fragmento (por ejemplo, gs_rt para el título, como se muestra en la siguiente imagen):
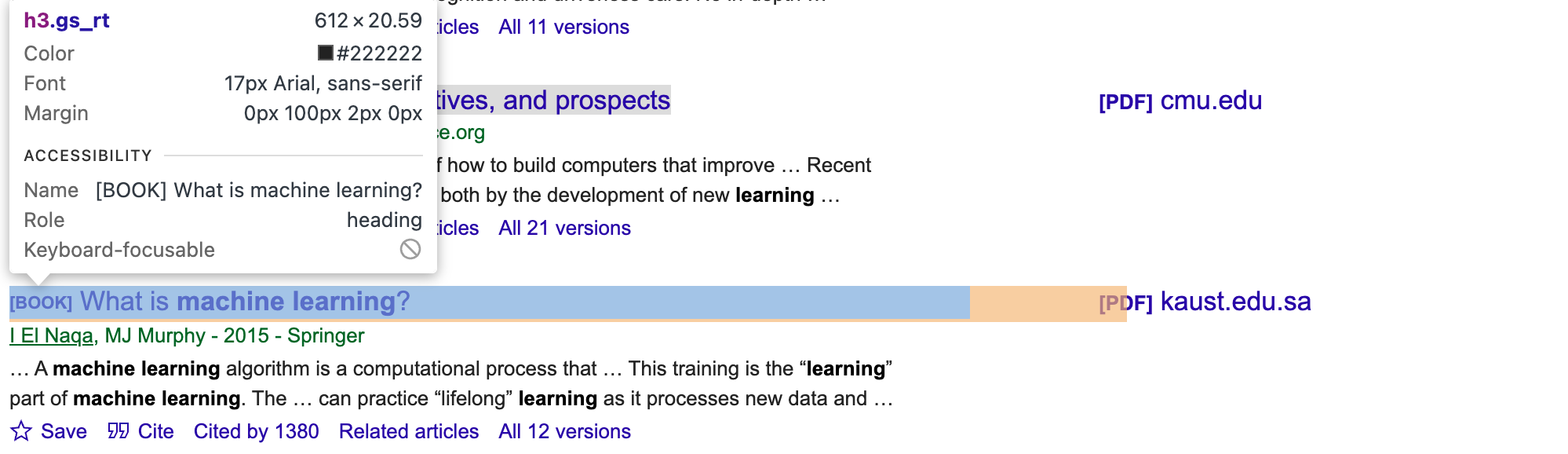
A continuación, actualice el script:
def parse_results(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
for item in soup.select('.gs_ri'):
title = item.select_one('.gs_rt').text
authors = item.select_one('.gs_a').text
snippet = item.select_one('.gs_rs').text
articles.append({'title': title, 'authors': authors, 'snippet': snippet})
return articles
Esta función utiliza BeautifulSoup para navegar por la estructura HTML; localizar elementos que contienen información sobre los artículos; extraer los títulos, autores y fragmentos de cada artículo; y, a continuación, combinarlos en una lista de diccionarios.
Observará que el script actualizado contiene .select(.gs_ri), que es el selector CSS que coincide con cada elemento de los resultados de búsqueda en la página de Google Scholar. A continuación, el código extrae el título, los autores y el fragmento (breve descripción) de cada resultado utilizando selectores más específicos (.gs_rt, .gs_a y .gs_rs).
Ejecuta el script
Para probar el script del scraper, añade el siguiente código _main_ para ejecutar una búsqueda de «machine learning»:
if __name__ == "__main__":
search_query = "machine learning"
# Inicializar Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
La función fetch_search_results extrae el contenido HTML de la página de resultados de búsqueda. A continuación, parse_results extrae los datos del contenido HTML.
El script completo tiene este aspecto:
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def init_selenium_driver():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
return driver
def fetch_search_results(driver, query):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}"
# Utiliza Selenium WebDriver para recuperar la página.
driver.get(base_url + params)
# Esperar a que se cargue la página
driver.implicitly_wait(10) # Esperar hasta 10 segundos a que se cargue la página
# Devuelve el código fuente de la página (contenido HTML)
return driver.page_source
def parse_results(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
for item in soup.select('.gs_ri'):
title = item.select_one('.gs_rt').text
authors = item.select_one('.gs_a').text
snippet = item.select_one('.gs_rs').text
articles.append({'title': title, 'authors': authors, 'snippet': snippet})
return articles
if __name__ == "__main__":
search_query = "machine learning"
# Inicializar Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
Ejecute python gscholar_scraper.py para ejecutar el script. El resultado debería ser similar a este:
% python3 scrape_gscholar.py
título autores fragmento
0 [PDF][PDF] Algoritmos de aprendizaje automático: una revisión B Mahesh - Revista Internacional de Ciencia y... ... Aquí hay un resumen rápido de algunos de los más comunes...
1 [LIBRO][B] Aprendizaje automático E Alpaydin - 2021 - books.google.com El MIT presenta una concisa introducción al aprendizaje automático...
2 Aprendizaje automático: tendencias, perspectivas y pr... MI Jordan, TM Mitchell - Science, 2015 - scien... … El aprendizaje automático aborda la cuestión de h...
3 [LIBRO][B] ¿Qué es el aprendizaje automático? I El Naqa, MJ Murphy - 2015 - Springer … Un algoritmo de aprendizaje automático es un cálculo...
4 [LIBRO][B] Aprendizaje automático
Convierta la consulta de búsqueda en un parámetro
Actualmente, la consulta de búsqueda está codificada de forma rígida. Para que el script sea más flexible, es necesario pasarla como parámetro, de modo que se pueda cambiar fácilmente el término de búsqueda sin modificar el script.
Comience importando sys para acceder a los argumentos de la línea de comandos pasados al script:
import sys
A continuación, actualice el script del bloque __main__ para utilizar la consulta como parámetro:
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Uso: python gscholar_scraper.py '<search_query>'")
sys.exit(1)
search_query = sys.argv[1]
# Inicializar Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
Ejecute el siguiente comando junto con una consulta de búsqueda específica:
python gscholar_scraper.py <search_query>
En este punto, puede ejecutar todo tipo de consultas de búsqueda a través de la terminal (por ejemplo, «inteligencia artificial», «modelado basado en agentes» o «aprendizaje afectivo»).
Habilitar la paginación
Normalmente, Google Scholar solo muestra unos pocos resultados de búsqueda por página (unos diez), lo que puede no ser suficiente. Para obtener más resultados, es necesario explorar varias páginas de búsqueda, lo que significa modificar el script para solicitar y analizar páginas adicionales.
Puede modificar la función fetch_search_results para incluir un parámetro de inicio que controle el número de páginas que se van a recuperar. El sistema de paginación de Google Scholar incrementa este parámetro en diez por cada página posterior.
Si revisa la primera página de un enlace típico de Google Scholar, como https://scholar.google.ca/scholar?start=10&q=machine+learning&hl=en&as_sdt=0,5, el parámetro start de la URL determina qué conjunto de resultados se muestra. Por ejemplo, start=0 recupera la primera página, start=10 recupera la segunda página, start=20 recupera la tercera página, y así sucesivamente.
Actualicemos el script para gestionar esto:
def fetch_search_results(driver, query, start=0):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}&start={start}"
# Utiliza Selenium WebDriver para recuperar la página.
driver.get(base_url + params)
# Esperar a que se cargue la página
driver.implicitly_wait(10) # Esperar hasta 10 segundos a que se cargue la página
# Devolver el código fuente de la página (contenido HTML)
return driver.page_source
A continuación, debes crear una función para gestionar el rastreo de varias páginas:
def scrape_multiple_pages(driver, query, num_pages):
all_articles = []
for i in range(num_pages):
start = i * 10 # cada página contiene 10 resultados
html_content = fetch_search_results(driver, query, start=start)
articles = parse_results(html_content)
all_articles.extend(articles)
return all_articles
Esta función itera sobre el número de páginas especificado (num_pages), realiza el Parseo del contenido HTML de cada página y recopila todos los artículos en una sola lista.
No olvides actualizar el script principal para utilizar la nueva función:
if __name__ == "__main__":
if len(sys.argv) < 2 or len(sys.argv) > 3:
print("Uso: python gscholar_scraper.py '<search_query>' [<num_pages>]")
sys.exit(1)
search_query = sys.argv[1]
num_pages = int(sys.argv[2]) if len(sys.argv) == 3 else 1
# Inicializar Selenium WebDriver
driver = init_selenium_driver()
try:
all_articles = scrape_multiple_pages(driver, search_query, num_pages)
df = pd.DataFrame(all_articles)
df.to_csv('results.csv', index=False)
finally:
driver.quit()
Este script también incluye una línea (df.to_csv('results.csv', index=False)) para almacenar todos los datos agregados y no solo mostrarlos en la terminal.
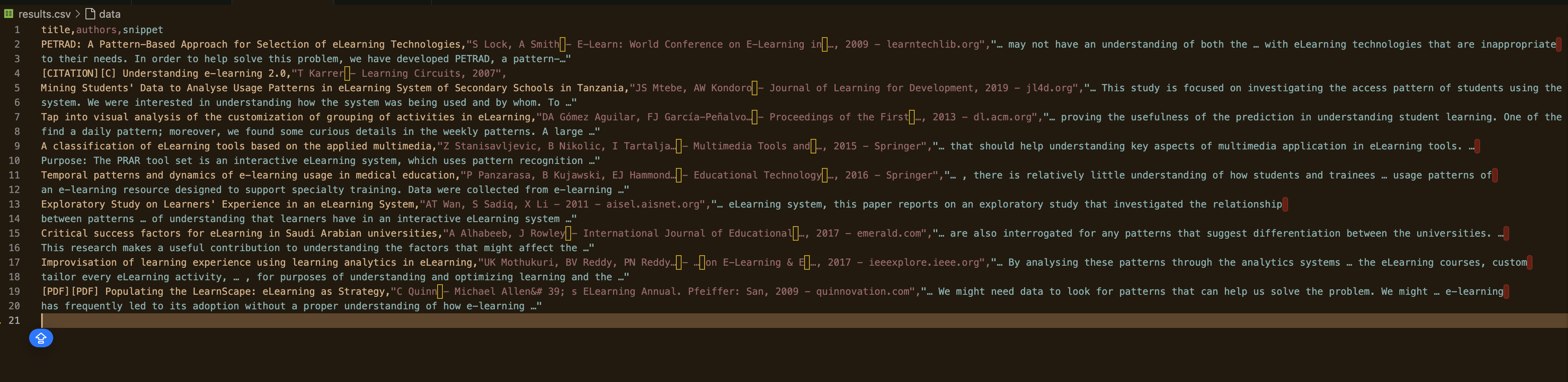
Ahora, ejecute el script y especifique el número de páginas que desea extraer:
python gscholar_scraper.py "understanding elearning patterns" 2
El resultado debería ser similar a este:
Cómo evitar el bloqueo de IP
La mayoría de los sitios web cuentan con medidas antibots que detectan patrones de solicitudes automatizadas para evitar el rastreo. Si un sitio web detecta una actividad inusual, es posible que su IP sea bloqueada.
Por ejemplo, al crear este script, hubo un momento en el que la respuesta devuelta era solo datos vacíos:
DataFrame vacío
Columnas: []
Índice: []
Cuando esto ocurre, es posible que tu IP ya haya sido bloqueada. En este caso, debes encontrar una forma de evitar que tu IP sea marcada. A continuación se indican algunas técnicas que te ayudarán a evitar el bloqueo de IP.
Utilice Proxy
Los servicios de Proxy te ayudan a distribuir las solicitudes entre varias direcciones IP, por lo que hay menos posibilidades de que se bloqueen. Por ejemplo, cuando reenvías una solicitud a través de un Proxy, el servidor Proxy enruta las solicitudes directamente al sitio web. De esta manera, el sitio web solo ve tu solicitud desde la dirección IP del Proxy en lugar de la tuya. Si quieres aprender a implementar un Proxy en tu proyecto, consulta este artículo.
Rote las IP
Otra técnica para evitar los bloqueos de IP es configurar tu script para que rote las direcciones IP después de un determinado número de solicitudes. Puedes hacerlo manualmente outilizar un servicio proxy que rote automáticamente las IP por ti. Esto dificulta que el sitio web detecte y bloquee tu IP, ya que las solicitudes parecen provenir de diferentes usuarios.
Incorporar redes privadas virtuales
Una red privada virtual (VPN) enmascara tu dirección IP al enrutar tu tráfico de Internet a través de un servidor ubicado en otro lugar. Puedes configurar una VPN con servidores en diferentes países para simular tráfico de varias regiones. También oculta tu dirección IP real y dificulta que los sitios web rastreen y bloqueen tus actividades basándose en la IP.
Conclusión
En este artículo, hemos explorado cómo extraer datos de Google Scholar utilizando Python. Hemos configurado un entorno virtual, instalado paquetes esenciales como Beautiful Soup, pandas y Selenium, y escrito scripts para obtener y analizar los resultados de la búsqueda. También hemos implementado la paginación para extraer varias páginas y hemos discutido técnicas para evitar el bloqueo de IP, como el uso de Proxy, la rotación de IP y la incorporación de VPN.
Aunque el rastreo manual puede tener éxito, a menudo conlleva retos como el bloqueo de IP y la necesidad de un mantenimiento continuo de los scripts. Para simplificar y mejorar sus esfuerzos de recopilación de datos, considere la posibilidad de aprovechar las soluciones de Bright Data. Nuestra red de proxies residenciales ofrece un alto nivel de anonimato y fiabilidad, lo que garantiza que sus tareas de rastreo se ejecuten sin interrupciones. Además, nuestras API de Scraping web gestionan automáticamente la rotación de IP y la resolución de CAPTCHA, lo que le ahorra tiempo y esfuerzo. Si desea datos listos para usar, explore nuestra amplia gama de conjuntos de datos adaptados a diversas necesidades.
Lleve su recopilación de datos al siguiente nivel:regístrese hoymismo para obtener una prueba gratuita de Bright Data y experimente soluciones de scraping eficientes y fiables para sus proyectos.





