

En este tutorial, aprenderemos a extraer ofertas de empleo de JOBKOREA, un moderno portal de empleo.
Trataremos los siguientes temas:
- Extracción manual con Python mediante la extracción de datos Next.js incrustados
- Scraping web con Bright Data Web MCP para una solución más estable y escalable
- Extracción sin código utilizando AI Scraper Studio de Bright Data
Cada técnica se implementa utilizando el código del proyecto proporcionado en este repositorio, pasando de un rastreo de bajo nivel a una extracción totalmente autónoma y basada en IA.
Requisitos
Antes de comenzar este tutorial, asegúrese de tener lo siguiente:
- Python 3.9+
- Conocimientos básicos de Python y JSON
- Una cuenta de Bright Data con acceso a MCP
- Claude Desktop instalado (utilizado como agente de IA para el enfoque sin código)
Configuración del proyecto
Clonar el repositorio del proyecto e instalar las dependencias:
python -m venv venv
source venv/bin/activate # macOS / Linux
venvScriptsactivate # Windows
pip install -r requirements.txtEstructura del proyecto
El repositorio está organizado de manera que cada técnica de scraping sea fácil de seguir:
jobkorea_scraper/
│
├── manual_scraper.py # Rastreo manual con Python
├── mcp_scraper.py # Rastreo con Bright Data Web MCP
├── parsers/
│ └── jobkorea.py # Lógica de parseo compartida
├── schemas.py # Esquema de datos de empleo
├── requirements.txt
├── README.mdCada script se puede ejecutar de forma independiente, dependiendo del método que desee explorar.
Técnica 1: Rastreo manual con Python
Comenzaremos con el enfoque más básico: scraping de JOBKOREA utilizando Python sin formato, sin navegador, MCP ni agente de IA.
Esta técnica es útil para comprender cómo JOBKOREA entrega sus datos y para crear rápidamente un prototipo de scraper antes de pasar a soluciones más robustas.
Obtención de la página
Abra manual_scraper.py.
El rascador comienza enviando una solicitud HTTP estándar utilizando requests. Para evitar ser bloqueados inmediatamente, incluimos encabezados similares a los de un navegador.
headers = {
"User-Agent": "Mozilla/5.0 (...)",
"Accept": "text/html,application/xhtml+xml,*/*",
"Accept-Language": "en-US,en;q=0.9,ko;q=0.8",
"Referer": "https://www.jobkorea.co.kr/"
}El objetivo es simplemente hacer que la solicitud parezca tráfico web normal. A continuación, recuperamos la página y forzamos la codificación UTF-8 para evitar problemas con el texto coreano:
response = requests.get(url, headers=headers, timeout=20)
response.raise_for_status()
response.encoding = "utf-8"
html = response.textPara la depuración, el HTML sin procesar se guarda localmente:
with open("debug.html", "w", encoding="utf-8") as f:
f.write(html)Este archivo es extremadamente útil cuando el sitio cambia y el Parseo deja de funcionar repentinamente.
Parseo de la respuesta
Una vez descargado el HTML, se pasa a una función de parseo compartida:
jobs = parse_job_list(html)Esta función se encuentra en parsers/jobkorea.py y contiene toda la lógica específica de JOBKOREA.
Intento de parseo tradicional de HTML
Dentro de parse_job_list, primero intentamos extraer las listas de empleos utilizando BeautifulSoup, como si JOBKOREA fuera un sitio tradicional renderizado por el servidor.
soup = BeautifulSoup(html, "html.parser")
job_lists = soup.find_all("div", class_="list-default")Si no se encuentran anuncios, se prueba un selector secundario:
job_lists = soup.find_all("ul", class_="clear")Cuando esto funciona, el rastreador extrae campos como:
- Título del puesto
- Nombre de la empresa
- Ubicación
- Fecha de publicación
- Enlace al puesto
Sin embargo, este enfoque solo funciona cuando JOBKOREA expone elementos HTML significativos, lo que no siempre es el caso.
Solución alternativa: extracción de datos de hidratación de Next.js
Si no se encuentran empleos mediante el parseo HTML, el rastreador cambia a una estrategia alternativa que se centra en los datos de hidratación de Next.js incrustados.
nextjs_jobs = parse_nextjs_data(html)Esta función escanea la página en busca de cadenas JSON inyectadas durante el renderizado del lado del cliente. Una versión simplificada de la lógica de coincidencia se ve así:
pattern = r'\"id\":\"(?P<id>d+)\",\"title\":\"(?P<title>.*?)\",\"postingCompanyName\":\"(?P<company>.*?)\"'A partir de estos datos, reconstruimos las URL de las ofertas de empleo:
link = f"https://www.jobkorea.co.kr/Recruit/GI_Read/{job_id}"Esta alternativa permite que el rastreador funcione sin necesidad de ejecutar un navegador.
Guardar los resultados
Cada oferta de empleo se valida utilizando un esquema compartido y se escribe en el disco:
with open("jobs.json", "w", encoding="utf-8") as f:
json.dump(
[job.model_dump() for job in jobs],
f,
ensure_ascii=False,
indent=2
)Ejecute el Scraper de esta manera:
python manual_scraper.py "https://www.jobkorea.co.kr/Search/?stext=python"Ahora debería tener un archivo jobs.json que contiene los listados extraídos.
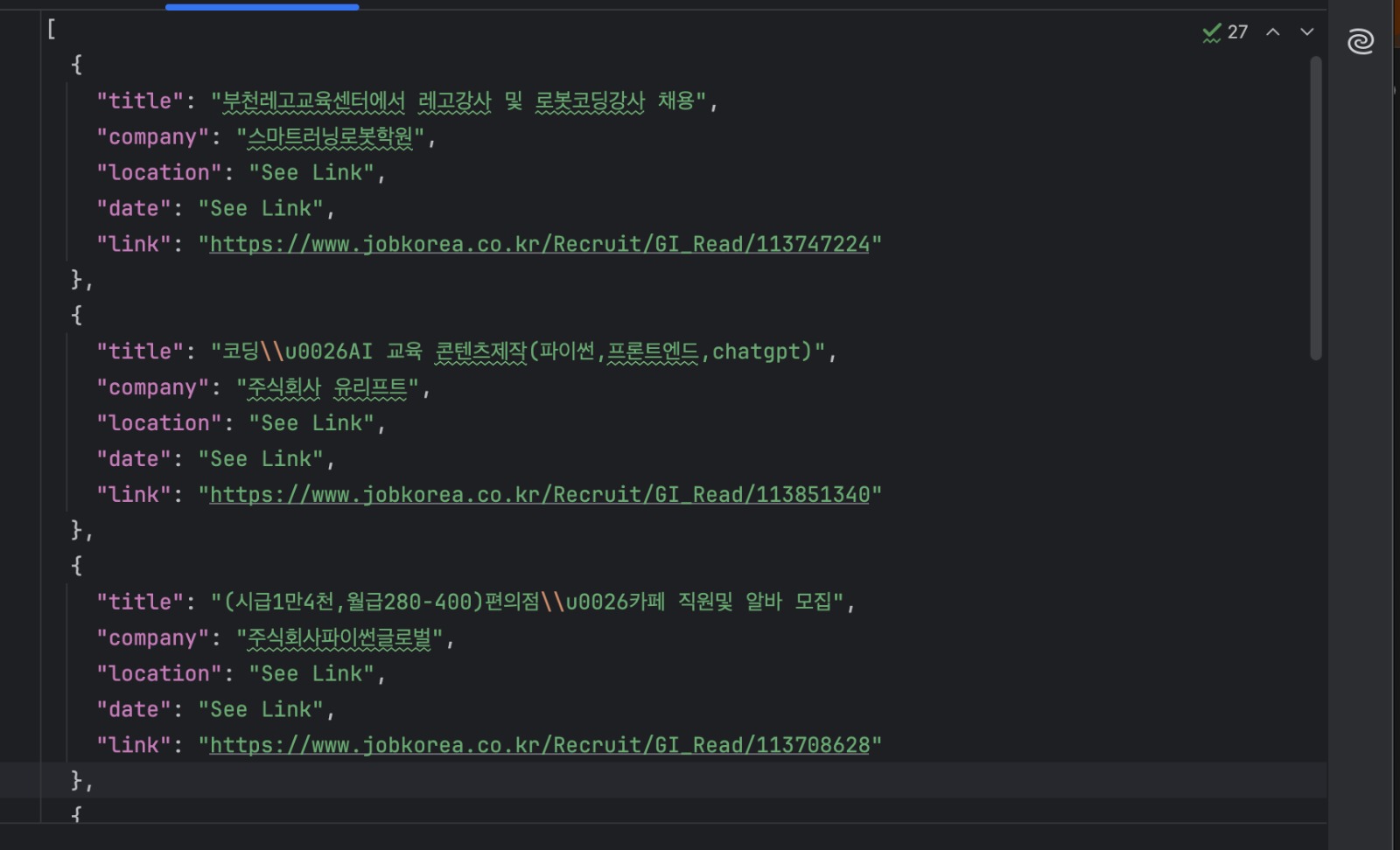
Cuándo es ideal este enfoque
El rastreo manual es útil cuando se está explorando cómo funciona un sitio o se está creando un prototipo rápido. Es rápido, sencillo y no depende de servicios externos.
Sin embargo, este enfoque está estrechamente vinculado a la estructura actual de la página de JOBKOREA. Dado que depende de diseños HTML específicos y patrones de hidratación incrustados, puede fallar cuando el sitio cambia.
Para un rastreo más estable y duradero, es mejor confiar en herramientas que se encarguen del renderizado y los cambios del sitio web, que es precisamente lo que haremos a continuación utilizando Bright Data Web MCP.
Técnica 2: Scraping web con Bright Data Web MCP
En la sección anterior, extrajimos datos de JOBKOREA descargando manualmente el HTML y extrayendo los datos incrustados. Aunque ese enfoque funciona, está estrechamente vinculado a la estructura actual del sitio.
En esta técnica, utilizamos Bright Data Web MCP para gestionar la obtención y el renderizado de la página. A continuación, nos centramos únicamente en convertir el contenido devuelto en datos de empleo estructurados.
Este enfoque se implementa en mcp_scraper.py.
Obtener su clave/token API de Bright Data
- Inicie sesión en el panel de control de Bright Data
- Abra Configuración en la barra lateral izquierda
- Vaya a Usuarios y claves API
- Copie su clave API
Más adelante en este tutorial, las capturas de pantalla mostrarán exactamente dónde se encuentra esta página y dónde aparece el token.
Cree un archivo .env en la raíz del proyecto y añada:
BRIGHT_DATA_API_TOKEN=tu_token_aquíEl script carga el token en tiempo de ejecución y se detiene antes de tiempo si falta.
Requisitos para MCP
Bright Data Web MCP se inicia localmente utilizando npx, así que asegúrate de tener:
- Node.js instalado
- npx disponible en su PATH
El servidor MCP se inicia desde Python utilizando:
server_params = StdioServerParameters( command="npx", args=["-y", "@brightdata/mcp"], env={"API_TOKEN": BRIGHT_DATA_API_TOKEN, **os.environ} )Ejecutar el rastreador MCP
Ejecute el script con una URL de búsqueda de JOBKOREA:
python mcp_scraper.py "https://www.jobkorea.co.kr/Search/?stext=python"El script abre una sesión MCP e inicializa la conexión:
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()Una vez conectado, el scraper está listo para recuperar contenido.
Obtención de la página con MCP
En este proyecto, el scraper utiliza la herramienta MCP scrape_as_markdown:
result = await session.call_tool(
"scrape_as_markdown",
arguments={"url": url}
)El contenido devuelto se recopila y se guarda localmente:
with open("scraped_data.md", "w", encoding="utf-8") as f:
f.write(content_text)Esto le proporciona una instantánea legible de lo que ha devuelto MCP, lo cual es útil para la depuración y el Parseo.
Parseo de trabajos desde Markdown
El Markdown devuelto por MCP se convierte entonces en datos de trabajo estructurados.
La lógica de Parseo busca enlaces de Markdown:
link_pattern = re.compile(r"[(.*?)]((.*?))")Las ofertas de empleo se identifican mediante URL que contienen:
if "Recruit/GI_Read" in url:Una vez encontrado el enlace del puesto de trabajo, se utilizan las líneas circundantes para extraer el nombre de la empresa, la ubicación y la fecha de publicación.
Por último, los resultados se escriben en el disco:
with open("jobs_mcp.json", "w", encoding="utf-8") as f:
json.dump(
[job.model_dump() for job in jobs],
f,
ensure_ascii=False,
indent=2
)Archivos de salida
Una vez finalizado el script, debería tener:
scraped_data.md
El marcado sin procesar devuelto por Bright Data Web MCP
jobs_mcp.json
Las listas de trabajos parseadas en formato JSON estructurado
Cuándo es ideal este enfoque
El uso de Bright Data Web MCP directamente desde Python es una buena opción cuando se desea un rastreador que sea fiable y repetible.
Dado que MCP se encarga del renderizado, la conexión a la red y las defensas básicas del sitio, este enfoque es mucho menos sensible a los cambios de diseño que el rastreo manual. Al mismo tiempo, mantener la lógica en Python facilita la automatización, la programación y la integración en canales de datos más grandes.
Esta técnica funciona bien cuando se necesitan resultados consistentes a lo largo del tiempo o cuando se extraen múltiples páginas de búsqueda o palabras clave. También proporciona una clara vía de actualización desde el rastreo manual sin necesidad de cambiar completamente a un flujo de trabajo impulsado por la IA.
A continuación, pasaremos a la tercera técnica, en la que utilizamos Claude Desktop como agente de IA conectado a Bright Data Web MCP para extraer datos de JOBKOREA sin escribir ningún código de extracción.
Técnica 3: Código de rastreo generado por IA utilizando Bright Data IDE
En esta última técnica, generamos código de rastreo utilizando el rastreador asistido por IA de Bright Data dentro del IDE de Scraping web.
No es necesario escribir manualmente la lógica de rastreo desde cero. Basta con describir lo que se desea y el IDE ayuda a generar y perfeccionar el Scraper.
Abrir el IDE del Scraper
Desde el panel de control de Bright Data:
Abre Datos en la barra lateral izquierda
- Haga clic en Mis scrapers

- Seleccione Nuevo en la esquina superior derecha
- Seleccione Desarrolle su propio rascador web

Esto abre el entorno de desarrollo integrado (IDE) de JavaScript
Introduce tu URL de destino «https://www.jobkorea.co.kr/Search/» y haz clic en «Generar código».
El IDE procesará su solicitud y generará una plantilla de código lista para usar. Recibirá una notificación por correo electrónico cuando esté lista. A continuación, podrá editar o ejecutar el código según sea necesario.
Comparación de las tres técnicas de rastreo
Cada técnica de este proyecto resuelve el mismo problema, pero se adapta a un flujo de trabajo diferente. La siguiente tabla destaca las diferencias prácticas.
| Técnica | Esfuerzo de configuración | Fiabilidad | Automatización | Dónde se ejecuta | Mejor caso de uso |
|---|---|---|---|---|---|
| Rastreo manual con Python | Bajo | Bajo a medio | Limitado | Máquina local | Aprendizaje, experimentos rápidos |
| Bright Data MCP (Python) | Medio | Alto | Alto | Local + Bright Data | Rastreo de producción, trabajos programados |
| Scraper generado por IA (Bright Data IDE) | Bajo | Alto | Alto | Plataforma Bright Data | Configuración rápida, scrapers gestionados reutilizables |
Conclusión
En este tutorial, hemos tratado tres formas diferentes de extraer datos de JOBKOREA: extracción manual con Python, un flujo de trabajo más estable basado en Bright Data Web MCP y el uso de AI Scraper Studio de Bright Data para un enfoque sin código.
Cada técnica se basa en la anterior. El scraping manual ayuda a comprender cómo funciona el sitio, el scraping basado en MCP proporciona fiabilidad y automatización, y el enfoque del agente IA ofrece la vía más rápida para obtener datos estructurados con una configuración mínima.
Si está extrayendo datos de sitios web modernos renderizados por el cliente, como JOBKOREA, y necesita una alternativa más fiable a los selectores frágiles y la automatización del navegador, Bright Data Web MCP proporciona una base sólida que funciona tanto con scripts tradicionales como con flujos de trabajo impulsados por IA.





