

En esta entrada del blog sobre scraping web gestionado frente a basado en API, verá:
- Una descripción general de los servicios de Scraping web gestionados y las soluciones de Scraping web basadas en API.
- Qué es el Scraping web gestionado, cómo funciona, sus principales casos de uso y cuándo es la mejor opción.
- Qué son las API de Scraping web, cómo funcionan, sus principales casos de uso y cuándo alcanzan su máximo valor.
- Una comparación final para ayudarle a decidir qué enfoque se adapta mejor a sus necesidades de recopilación de datos web.
¡Empecemos!
Introducción a los servicios gestionados de scraping web y las API de scraping web
El scraping web gestionado y el scraping web basado en API son dos de los enfoques más comunes para recopilar datos web. En ambos casos, los principales retos del scraping web (por ejemplo, las huellas digitales del navegador, la representación de JavaScript, las huellas digitales TLS, los límites de velocidad, los CAPTCHA y otros obstáculos similares) se externalizan a un proveedor externo.
Con los servicios gestionados, todo el proceso de scraping se externaliza por completo. El proveedor trabaja con usted para comprender sus necesidades y le proporciona los datos necesarios, a menudo enriquecidos con información y análisis personalizados. En esencia, se trata de una solución integral y llave en mano.
Por otro lado, el scraping web basado en API implica la creación de scripts personalizados, agentes de IA o canalizaciones que se conectan a las API de scraping. Estos puntos finales recopilan datos web estructurados de dominios conocidos, al tiempo que se encargan de eludir los sistemas antiscraping, la escalabilidad y la infraestructura. Sin embargo, usted sigue siendo responsable de la integración, el almacenamiento de datos y otros aspectos técnicos.
En ambos enfoques, es fundamental elegir un proveedor fiable. Bright Data es un proveedor líder de soluciones de Scraping web que cubre ambos enfoques:
- Adquisición de datos gestionada: acceda a datos e información sin esfuerzo de desarrollo o mantenimiento a través de un servicio totalmente gestionado y de nivel empresarial.
- API de scraping web: un amplio conjunto de puntos finales de scraping para más de 120 plataformas populares. Admiten rotación automática de proxies, evasión de antibots, renderización de JavaScript y mucho más.
Lo que distingue a Bright Data es su infraestructura preparada para empresas, que da soporte a más de 20 000 empresas en todo el mundo con un tiempo de actividad y una tasa de éxito del 99,99 %, asistencia de expertos 24/7, datos conformes y de origen ético, y acceso a más de 150 millones de IP de usuarios reales en 195 países, una de las redes de Proxy más grandes del mundo.
Scraping web gestionado: una inmersión profunda
Comencemos este artículo sobre el scraping gestionado frente al basado en API centrándonos en los servicios de adquisición de datos web gestionados y entendiendo para qué son más adecuados.
Qué es
El scraping web gestionado es un servicio de recopilación de datos integral en el que un proveedor se encarga de todo por usted.
Esto incluye la búsqueda de páginas web, eludir los sistemas antibots, Parseo de los datos de las páginas identificadas, validar y limpiar los resultados, escalar la infraestructura y entregar datos estructurados, fiables y conformes que satisfagan sus necesidades.
En lugar de crear y mantener bots de scraping y gestionar toda la infraestructura, usted simplemente describe sus deseos al proveedor. A cambio, el proveedor le entrega conjuntos de datos, paneles de control o información listos para usar que satisfacen sus necesidades.
El objetivo del Scraping web gestionado es ahorrar tiempo, reducir el esfuerzo de ingeniería y disminuir los costes operativos, al tiempo que se le sigue proporcionando acceso a los datos que desea.
Cómo funciona
Cuando se opta por una solución gestionada de adquisición de datos web, todo el proceso de datos se gestiona por usted. Desde la configuración inicial hasta la entrega final, el proveedor se encarga de todos los pasos necesarios para proporcionarle los datos que desea en el formato o presentación deseados.
El proceso suele incluir las siguientes etapas:
- Inicio del proyecto: Empieza seleccionando un servicio de recopilación de datos gestionado. A continuación, trabaja en estrecha colaboración con los expertos del proveedor para definir las fuentes de datos, los campos necesarios, la información y los KPI que se ajustan a sus objetivos empresariales.
- Recopilación de datos: el proveedor de scraping gestionado dirige todo el proceso de recopilación de datos. Su equipo crea, automatiza y escala la solución de extracción en función de sus requisitos y la ejecuta de forma continua, mientras que su gestor de proyectos supervisa la ejecución.
Ahora tiene acceso a los datos que solicitó. Sin embargo, con los mejores proveedores, el proceso no se detiene ahí e incluye dos pasos adicionales:
- Validación y enriquecimiento de datos: el proveedor refina los datos mediante la deduplicación automatizada, las referencias cruzadas y la supervisión continua de la calidad. El objetivo es proporcionar datos precisos, coherentes, enriquecidos y de alta calidad.
- Informes y conocimientos: una vez recopilados y pulidos los datos, el proveedor también puede ofrecer información a través de paneles de control, seguimiento en tiempo real y orientación de expertos para respaldar mejores decisiones empresariales.
Como puede ver, este enfoque realmente abarca todo el proceso. Garantiza que todo el proceso de recuperación, procesamiento y finalización de los datos se gestione íntegramente por usted, desde los datos brutos hasta el conocimiento útil.
Requisitos
Los servicios gestionados de scraping web no requieren prácticamente ningún conocimiento técnico por su parte. El motivo es que todo el proceso de scraping de datos se externaliza. Por lo tanto, no necesita conocimientos técnicos para crear scrapers, gestionar Proxy o administrar la infraestructura subyacente.
El requisito principal es tener una comprensión clara de sus necesidades de datos, incluyendo aspectos como las fuentes de destino, los campos de datos, el número de registros y la frecuencia de actualización. Obviamente, también necesita la capacidad de comprender y aprovechar los resultados entregados.
Casos de uso
El scraping web gestionado puede ser útil para prácticamente todos los sectores. Los proveedores pueden incluso agregar datos de múltiples fuentes a la vez, como combinar información de varias plataformas de comercio electrónico con datos de redes sociales para realizar análisis de opiniones.
Ideal para
Optar por el Scraping web gestionado es ideal cuando se carece de las habilidades, la infraestructura o la capacidad para manejar un proyecto de recopilación de datos.
La razón es que crear un canal de datos fiable alimentado por el scraping web no es nada fácil. Debe elegir las herramientas de scraping web adecuadas, integrar proxies e implementar soluciones de bypass antirrastreo para que sus scripts sean eficaces en situaciones reales.
Además, hay que supervisar los sitios web para detectar cambios estructurales, comprobar que el software personalizado funciona de forma coherente y gestionar la escalabilidad de la infraestructura. Y estos son solo algunos de los aspectos que intervienen en la creación y gestión de un proceso de Scraping web listo para la producción…
Todo ello conlleva una importante inversión de tiempo y dinero en personal, servidores y soluciones de terceros. Al adoptar un servicio gestionado en lugar de crear uno interno, se eliminan esas necesidades. Esto se traduce en un flujo de trabajo más optimizado que puede suponer un ahorro considerable, especialmente si su equipo tiene poca o ninguna experiencia previa en Scraping web.
Por ejemplo, considere el retorno de la inversión estimado al elegir los servicios de Scraping web gestionados de Bright Data en lugar de implementar y gestionar el proceso usted mismo: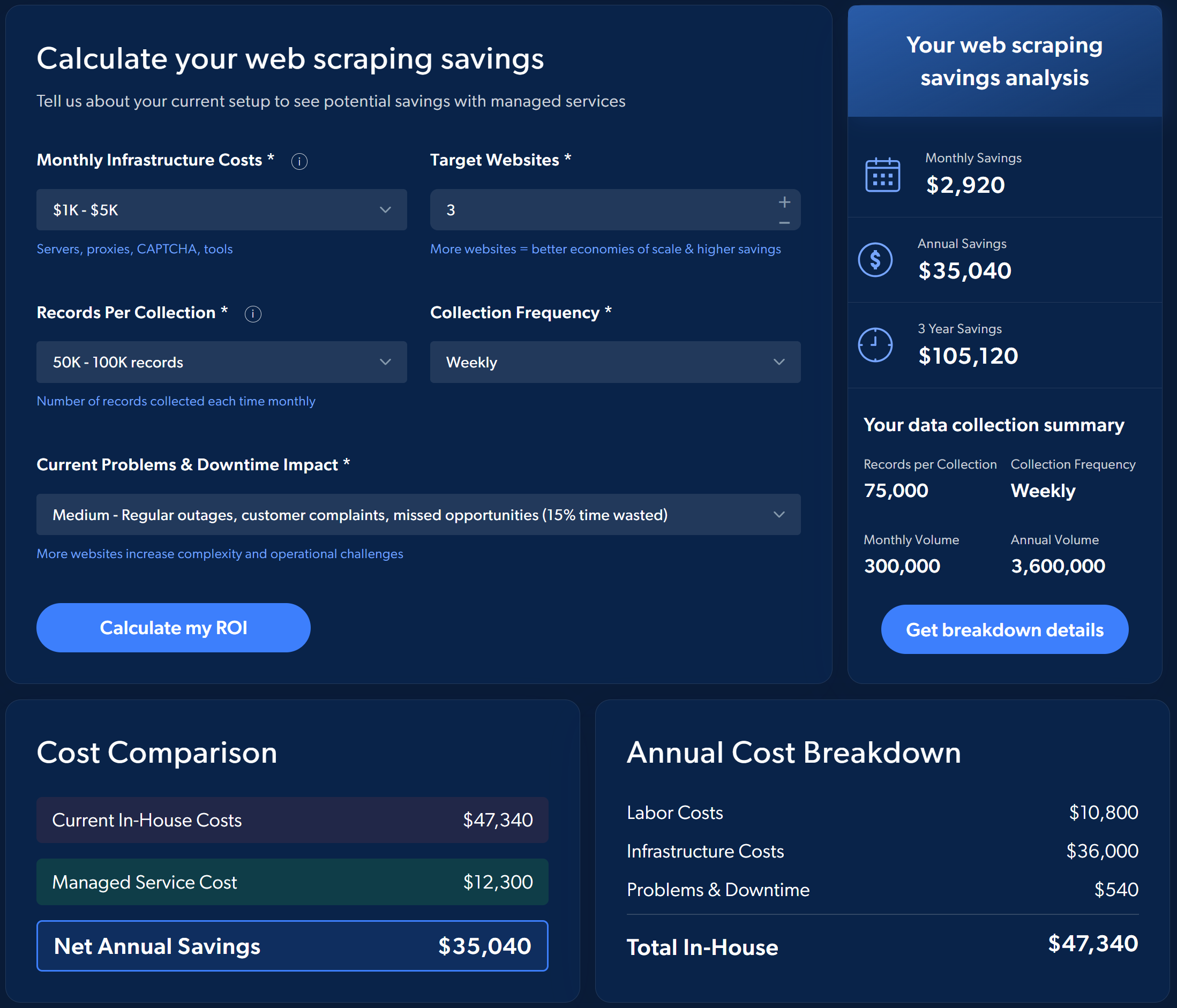
Para hacerse una idea del ahorro potencial, realice una sencilla simulación directamente en la página del servicio de recopilación de datos gestionado de Bright Data.
En resumen, los servicios gestionados son ideales para las empresas que desean datos fiables, actualizados, escalables y validados sin invertir en un equipo dedicado.
Scraping web basado en API: un análisis en profundidad
Continúe con esta entrada del blog sobre el scraping web gestionado frente al basado en API explorando la recopilación de datos web a través de API de scraping, que cubre toda la información esencial que necesita saber.
Qué es
El scraping web basado en API consiste en conectarse directamente a una solución API de scraping para recopilar datos web. Estas API se pueden clasificar en tres tipos:
- API de sitios oficiales: proporcionan acceso a un conjunto predefinido de datos directamente desde el sitio web.
- API desbloqueadoras web generales: puntos finales que eluden las protecciones antibots de cualquier página web.
- API específicas de scraping web: extraen datos de dominios concretos y devuelven datos estructurados con un esquema determinado.
Aquí nos centraremos en los dos últimos tipos de API de Scraping web. La razón es que las API de sitios oficiales suelen ser caras, tienen límites de velocidad estrictos y ofrecen poco control, ya que el sitio puede dejar de exponer datos en cualquier momento. Para obtener más detalles, consulte nuestra guía sobre scraping web frente a API.
Cómo funciona
El scraping web basado en API es un buen término medio entre los enfoques totalmente internos y totalmente externalizados.
La idea es crear scripts sencillos que se conecten a estas API, que se encargan de todo el trabajo pesado, incluyendo la obtención de páginas, el tratamiento de la representación de JavaScript, la elusión de las protecciones antirraspado e incluso, potencialmente, la devolución de datos ya estructurados.
Lo primero es encontrar el proveedor de API de scraping web adecuado a sus necesidades. Si hay disponibles API de scraping que proporcionan los datos que desea, debe utilizarlas directamente. De lo contrario, puede optar por una API de desbloqueo web que proporcione el HTML desbloqueado de las páginas web de interés.
Cuando se utilizan API de scraping, solo es necesario crear scripts sencillos que llamen a la API, gestionen los errores con lógica de reintento en caso de fallos ocasionales y almacenen los datos recuperados en una base de datos, en archivos locales, en la nube o utilizando el método de almacenamiento que prefiera.
Si elige una API Web Unlocker, tendrá que implementar una lógica de Parseo de datos personalizada, ya sea utilizando selectores CSS/expresiones XPath o inteligencia artificial. Una vez extraídos los datos del HTML desbloqueado, deben almacenarse como se ha mencionado anteriormente.
Por último, los datos deben validarse, limpiarse, procesarse y analizarse para extraer información.
Requisitos
Aunque el scraping web basado en API es mucho más sencillo que crear un rastreador web desde cero, sigue requiriendo cierta configuración técnica.
Se necesitan conocimientos básicos de programación para escribir scripts que llamen programáticamente a las API en el lenguaje de programación preferido. También se debe saber cómo abordar la autenticación, gestionar las solicitudes HTTP paralelas y tratar los errores comunes.
Nota: Los principales proveedores suelen ofrecer soluciones sin código, lo que le permite utilizar API de scraping web sin escribir ningún código ni necesitar conocimientos técnicos.
Para guardar los datos recopilados, también debe estar familiarizado con las opciones de almacenamiento de datos. Además, debe tener conocimientos de gestión de datos para evitar duplicados y garantizar actualizaciones periódicas con un control de versiones adecuado.
Si utiliza una API de desbloqueo web en lugar de una API de Scraping web dedicada, necesitará conocimientos adicionales para Parseo HTML y estructurar los datos según sus necesidades. Por último, se necesitan conocimientos relacionados con los datos para prepararlos para su procesamiento, visualización y análisis.
Casos de uso
Las API de scraping web admiten una larga lista de casos de uso, tales como:
- Comercio electrónico: recopilar información sobre productos, precios, reseñas y datos de vendedores de sitios como Amazon, eBay y Walmart.
- Finanzas: acceder a datos bursátiles, informes financieros y tendencias del mercado desde plataformas como Yahoo Finance o Nasdaq.
- Mercado laboral: recopilar ofertas de empleo y datos de empresas de LinkedIn, Indeed y otros.
- Viajes: realizar un seguimiento de vuelos, disponibilidad de hoteles y precios de Expedia, Booking.com y sitios similares.
- B2B: obtener datos de empresas de fuentes como Crunchbase o ZoomInfo.
- Redes sociales: supervise las publicaciones, las tendencias y la interacción de X, Instagram y TikTok.
- Motores de búsqueda: realice búsquedas programáticas en motores de búsqueda como Google, Bing, Yandex y otros utilizando API especializadas de SERP y búsqueda web.
Con una API de desbloqueo web, puede acceder a datos estructurados de prácticamente cualquier sitio web, incluso de aquellos que no cuentan con una API de scraping dedicada.
Ideal para
El scraping basado en API es más adecuado para situaciones en las que se necesitan datos web consistentes y estructurados sin externalizar totalmente el proceso. Ofrece un equilibrio entre el desarrollo interno y los servicios gestionados, lo que le permite mantener el control sobre la recopilación de datos mientras que la API se encarga de los principales retos.
Scraping web gestionado frente a scraping web basado en API: comparación directa
Ahora que ya conoce las dos metodologías para obtener datos web, es el momento de compararlas en una sección dedicada al scraping web gestionado frente al basado en API.
Cómo elegir el enfoque de scraping adecuado
Compare el scraping web gestionado con el scraping web basado en API en la tabla resumen siguiente:
| Scraping web gestionado | Scraping web basado en API | |
|---|---|---|
| Descripción | Usted describe sus requisitos al proveedor, que extrae y entrega los datos de las fuentes seleccionadas. | Usted se conecta a las API para recuperar datos web. La API se encarga de la obtención de páginas, el bypass anti-bot, la integración de Proxy, etc. |
| Para quién | Empresas que necesitan una solución sin intervención y que no cuentan con personal ni infraestructura propios. | Equipos con ingenieros internos o recursos técnicos que desean controlar la recopilación de datos y externalizar el trabajo pesado. |
| Configuración y mantenimiento | Totalmente gestionado de principio a fin por el proveedor. No requiere ninguna configuración técnica por su parte. | Requiere conocimientos básicos de programación y configuración de scripts, gestión de errores y almacenamiento. |
| Gestión antibots | Totalmente gestionado por el proveedor. | Totalmente gestionado por el proveedor. |
| Infraestructura | Totalmente gestionada por el proveedor. | Gestionada por el proveedor de API, pero la implementación e integración de sus scripts es su responsabilidad. |
| Entrega | Los datos se entregan en el formato y la forma que desees. | Los datos son devueltos por la API de scraping en formato HTML, JSON o Markdown. |
| Limpieza de datos y control de calidad | El proveedor se encarga de la validación automatizada, la deduplicación, el enriquecimiento y los controles de calidad continuos. | Usted es responsable de la validación, limpieza y procesamiento adicionales. |
| Información y paneles de control | El proveedor puede proporcionar paneles de control, informes, análisis e información útil personalizados. | No incluido. |
| Consultoría y estrategia | Se incluyen recomendaciones y orientación de expertos para optimizar la recopilación y el uso de datos. | No incluido. |
| Asistencia | Equipo de asistencia dedicado, incluido un asistente de datos para la resolución de problemas y la gestión de proyectos. | Limitado a la documentación de la API y la asistencia técnica básica. |
Scraping web gestionado
👍 Ventajas:
- Acceso a datos estructurados, paneles de control o información listos para usar.
- Servicio integral que abarca la recopilación, validación, enriquecimiento y entrega de datos, sin necesidad de conocimientos técnicos.
- Reduce los costes operativos y el esfuerzo de ingeniería.
- Aplicable a prácticamente cualquier caso de uso, sector o escenario.
- Asistencia y recomendaciones de un equipo de expertos en múltiples áreas.
👎 Contras:
- Menor control sobre el proceso de scraping.
- Dependencia total de un proveedor externo específico.
Scraping web basado en API
👍 Ventajas:
- Fácil integración en los sistemas existentes.
- Alta velocidad y concurrencia, admite muchas solicitudes simultáneas.
- No hay que preocuparse por bloqueos o restricciones antibots.
- No requiere gestión ni mantenimiento de infraestructura.
- Muy adecuado para crear herramientas de scraping personalizadas para agentes de IA o flujos de trabajo automatizados.
👎 Contras:
- Requiere conocimientos técnicos.
- Usted es responsable de validar, limpiar y estructurar los datos.
Comentario final
Tanto los servicios web gestionados como las API de scraping web tienen como objetivo proporcionar datos web, pero abordan el problema de forma diferente.
Las API de scraping web son puntos finales para la recuperación simplificada de datos, lo que permite a los desarrolladores integrarlas directamente en scripts, pipelines o incluso agentes de IA y flujos de trabajo. Son ideales cuando se necesitan puntos de datos específicos, como precios de productos, reseñas o resultados de búsqueda, sin tener que gestionar la infraestructura subyacente. Sin embargo, siguen requiriendo cierta configuración y conocimientos técnicos.
Por el contrario, los servicios gestionados de adquisición de Scraping web se encargan de todo el ciclo de vida de los datos, desde la extracción hasta la validación, el enriquecimiento y la entrega, sin necesidad de ingeniería o mantenimiento internos.
En particular, la solución de adquisición de datos gestionada de Bright Data ejemplifica ese enfoque. Proporciona canalizaciones de nivel empresarial, controles de calidad automatizados, cumplimiento de las leyes de privacidad y paneles de control para obtener información en tiempo real. Solo tiene que definir sus objetivos y KPI, y Bright Data se encarga de escalar, supervisar y entregar datos estructurados listos para usar que le ayudarán a maximizar el retorno de la inversión.
En conclusión, piénselo de esta manera: las API le proporcionan las herramientas; los servicios gestionados le entregan el producto terminado.
Conclusión
En esta guía, ha examinado los matices de los dos enfoques más populares para el Scraping web: los servicios gestionados y las soluciones basadas en API.
Ha aprendido que el Scraping web gestionado es ideal cuando se desea una experiencia totalmente automática. No solo le proporciona los datos, sino también conjuntos de datos validados e información interesante. Todo ello sin tener que lidiar con la complejidad técnica. Por el contrario, las API de Scraping web ofrecen mayor flexibilidad y control, pero pueden requerir experiencia en programación.
Sea cual sea el enfoque que elija, Bright Data le ofrece lo que necesita. Ofrece API de scraping web líderes en el sector, como la API Unlocker y las API Scraper específicas para cada dominio, así como servicios de adquisición de datos gestionados de nivel empresarial.
¡Regístrate gratis en Bright Data y explora nuestras soluciones de Scraping web hoy mismo!




