
El scraping web desempeña un papel importante en la recopilación de datos a gran escala, sobre todo cuando es esencial tomar decisiones rápidas y con conocimiento de causa.
En este tutorial aprenderás:
- Qué es Midscene.js y cómo funciona,
- Las limitaciones del uso de Midscene.js,
- Cómo ayuda Bright Data a superar esos retos
- Cómo integrar Midscene.js con Bright Data para un raspado web eficaz
Sumerjámonos.
¿Qué es Midscene.js?
Midscene.js es una herramienta de código abierto que permite automatizar las interacciones del navegador utilizando un inglés sencillo. En lugar de escribir scripts complejos, puedes simplemente escribir comandos como “Haz clic en el botón de inicio de sesión” o “Escribe en el campo de correo electrónico”. A continuación, Midscene convierte esas instrucciones en pasos de automatización mediante agentes de IA.
También es compatible con herramientas modernas de automatización del navegador, como Puppeteer y Playwright, lo que la hace especialmente útil para tareas como pruebas, automatización de la interfaz de usuario y raspado de sitios web dinámicos.
En detalle, las principales características que ofrece son:
- Control en lenguaje natural: Automatiza tareas con instrucciones claras en inglés en lugar de código.
- Integración de IA con servidor MCP: Conecta con modelos de IA a través de un servidor MCP para ayudar a generar scripts de automatización.
- Compatibilidad integrada con Puppeteer y Playwright: Actúa como una capa de alto nivel sobre los frameworks más populares, facilitando la gestión y ampliación de sus flujos de trabajo.
- Automatización multiplataforma: Soporta tanto web (a través de Puppeteer/Playwright) como Android (a través de su SDK JavaScript).
- Experiencia sin código: Ofrece herramientas como Midscene Chrome Extension para que puedas crear automatizaciones sin escribir ninguna línea de código.
- Diseño sencillo de la API: Proporciona una API limpia y bien documentada para interactuar con los elementos de la página y extraer contenido de manera eficiente.
Limitaciones del uso de Midscene para la automatización del navegador web
Midscene utiliza modelos de IA como GPT-4o o Qwen para automatizar los navegadores mediante comandos de lenguaje natural. Funciona con herramientas como Puppeteer y Playwright, pero tiene limitaciones clave.
La precisión de Midscene depende de la claridad de las instrucciones y de la estructura subyacente de la página. Las instrucciones vagas como “pulsa el botón” pueden fallar si hay varios botones similares. La IA se basa en capturas de pantalla y diseños visuales, por lo que pequeños cambios estructurales o la falta de etiquetas pueden provocar errores o clics erróneos. Las instrucciones que funcionan en una página web pueden no funcionar en otra con una apariencia similar.
Para minimizar los errores, escriba instrucciones claras y específicas que coincidan con la estructura de la página. Pruebe siempre las instrucciones con la extensión de Chrome Midscene antes de integrarlas en scripts de automatización.
Otra limitación clave es el elevado consumo de recursos. Cada paso de automatización con Midscene envía una captura de pantalla y un mensaje al modelo de IA, utilizando muchos tokens, especialmente en páginas dinámicas o con muchos datos. Esto puede limitar la velocidad de la API de IA y aumentar los costes de uso a medida que aumenta el número de pasos automatizados.
Midscene tampoco puede interactuar con elementos protegidos del navegador, como CAPTCHAs, iframes de origen cruzado o contenidos detrás de muros de autenticación. Por lo tanto, no es posible rastrear contenidos seguros o cerrados. Midscene es más eficaz en sitios estáticos o moderadamente dinámicos con contenidos accesibles y estructurados.
Por qué Bright Data es una solución más eficaz
Bright Data es una potente plataforma de recopilación de datos que le ayuda a construir, ejecutar y escalar sus operaciones de web scraping. Ofrece una potente infraestructura de proxy, herramientas de automatización y conjuntos de datos para empresas y desarrolladores, lo que le permite acceder, extraer e interactuar con cualquier sitio web público.
- Maneja sitios web dinámicos y con mucho JavaScript Bright Data ofrece varias herramientas, como SERP API, Crawl API, Browser API y Unlocker API, que le permiten acceder, extraer datos e interactuar con sitios web complejos que cargan contenido de forma dinámica. Estas herramientas proporcionan diversos instrumentos que permiten recuperar datos de cualquier plataforma, por lo que resultan ideales para plataformas de comercio electrónico, viajes e inmobiliarias.
- Infraestructura pro xy eficaz Bright Data ofrece una infraestructura proxy potente y flexible a través de sus cuatro redes principales: Residencial, Centro de Datos, ISP y Móvil. Estas redes proporcionan acceso a millones de direcciones IP en todo el mundo, lo que permite a los usuarios recopilar datos web de forma fiable y minimizar los bloqueos.
- Admite contenidos multimedia Bright Data permite extraer diversos tipos de contenidos, como vídeos, imágenes, audio y texto, de fuentes de acceso público. Su infraestructura está diseñada para gestionar la recopilación de contenidos multimedia a gran escala y dar soporte a casos de uso avanzados, como el entrenamiento de modelos de visión por ordenador, la creación de herramientas de reconocimiento de voz y la alimentación de sistemas de procesamiento de lenguaje natural.
- Proporciona conjuntos de datoslistos para usar Bright Data proporciona conjuntos de datos listos para usar que están totalmente estructurados, son de alta calidad y están listos para usar. Estos conjuntos de datos abarcan diversos ámbitos, como el comercio electrónico, las ofertas de empleo, el sector inmobiliario y las redes sociales, por lo que son adecuados para diferentes sectores y casos de uso.
Cómo integrar Midscene.js con Bright Data
En esta sección del tutorial, aprenderá cómo raspar datos de sitios web utilizando Midscene y la API de navegador de Bright Data y cómo combinar ambas herramientas para obtener mejores funcionalidades de raspado web.
Para demostrarlo, haremos scraping de una página web estática que muestra una lista de tarjetas de contacto de empleados. Empezaremos usando Midscene y Bright Data individualmente, y luego integraremos ambos usando Puppeteer para mostrar cómo pueden trabajar juntos.
Requisitos previos
Para seguir este tutorial, asegúrate de tener lo siguiente:
- Una cuenta de Bright Data.
- un editor de código, como Visual Studio Code, Cursor, etc.
- Una clave de API de OpenAI compatible con el modelo GPT-4o.
- Conocimientos básicos del lenguaje de programación JavaScript.
Si aún no tiene una cuenta de Bright Data, no se preocupe. Le explicaremos cómo crearla en los pasos siguientes.
Paso nº 1: Configuración del proyecto
Abra su terminal y ejecute el siguiente comando para crear una nueva carpeta para sus scripts de automatización:
mkdir automation-scripts
cd automation-scripts
Añada un archivo package.json en la carpeta recién creada utilizando el siguiente fragmento de código:
npm init -y
Cambiar el valor del tipo package.json de commonjs a module.
{
"type": "module"
}
A continuación, instala los paquetes necesarios para habilitar la ejecución de TypeScript y acceder a la funcionalidad de Midscene.js:
npm install tsx @midscene/web --save
A continuación, instale los paquetes Puppeteer y Dotenv.
npm install puppeteer dotenv
Puppeteer es una libreria Node.js que proporciona una API de alto nivel para controlar los navegadores Chrome o Chromium. Dotenv te permite almacenar de forma segura tus claves API.
Ahora, todos los paquetes necesarios han sido instalados. Podemos empezar a escribir los scripts de automatización.
Paso 2: Automatizar el Web Scraping con Midscene.js
Antes de continuar, crea un archivo .env dentro de la carpeta automation-scripts y copia la clave de la API de OpenAI en el archivo como variable de entorno.
OPENAI_API_KEY=<your_openai_key>
Midscene utiliza el modelo GPT-4o de OpenAI para llevar a cabo las tareas de automatización en función de las órdenes del usuario.
A continuación, cree un archivo dentro de la carpeta.
cd automation-scripts
touch midscene.ts
Importe Puppeteer, Midscene Puppeteer Agent, y la configuración dotenv en el archivo:
import puppeteer from "puppeteer";
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import "dotenv/config";
Añade el siguiente fragmento de código al archivo midscene.ts:
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 initialize puppeteer
const browser = await puppeteer.launch({
headless: false,
});
//👇🏻 set the page config
const page = await browser.newPage();
await page.setViewport({
width: 1280,
height: 800,
deviceScaleFactor: 1,
});
/*
----------
👉🏻 Write automation scripts here 👈🏼
-----------
*/
})()
);
El fragmento de código inicializa Puppeteer dentro de una Expresión de Función Inmediatamente Invocada (IIFE) asíncrona. Esta estructura le permite utilizar await en el nivel superior sin envolver la lógica en múltiples llamadas a funciones.
A continuación, añada los siguientes fragmentos de código dentro del IIFE:
//👇🏻 Navigates to the web page
await page.goto(
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>"
);
// 👇🏻 init Midscene agent
const agent = new PuppeteerAgent(page as any);
//👇🏻 gives the AI model a query
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
//👇🏻 Waits for 5secs
await sleep(5000);
// 👀 log the results
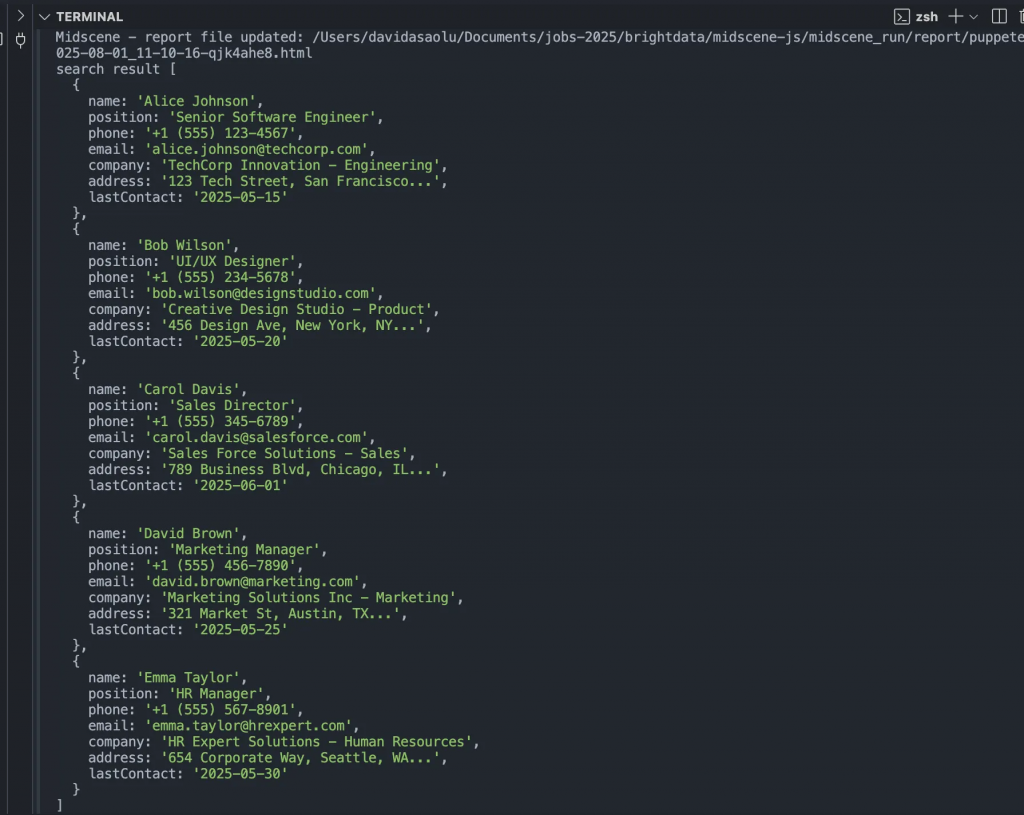
console.log("search result", items);
El fragmento de código anterior va a la dirección de la página web, inicializa el agente Puppeteer, recupera todos los datos de contacto de la página web y registra el resultado.
Paso 3: Automatizar el Web Scraping con Bright Data Browser API
Cree un archivo brightdata.ts dentro de la carpeta automation-scripts.
cd automation-scripts
touch brightdata.ts
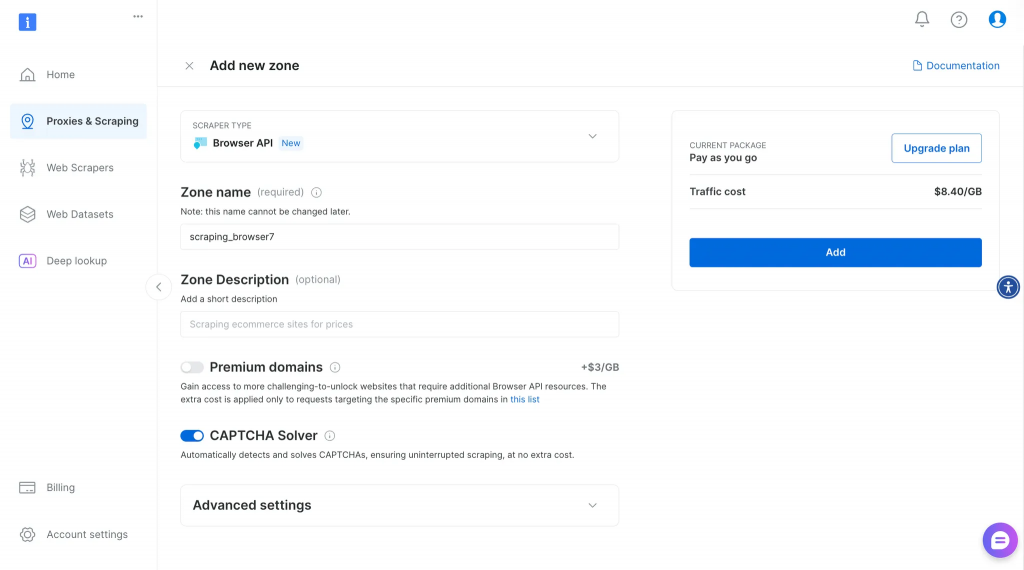
Vaya a la página de inicio de Bright Data y cree una cuenta.
Seleccione Browser API en su panel de control y, a continuación, introduzca el nombre y la descripción de la zona para crear una nueva API de navegador.
A continuación, copie sus credenciales de Puppeteer y guárdelas en el archivo brightdata.ts como se muestra a continuación:
const BROWSER_WS = "wss://brd-customer-******";
Modifique el archivo brightdata.ts como se muestra a continuación:
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
run(URL);
async function run(url: string) {
try {
/*
---------------------------
👉🏻 Web automation workflow 👈🏼
---------------------------
*/
//👇🏻 close the browser
await browser.close();
} catch (err) {
console.error("Error fetching data");
}
}
El fragmento de código declara una variable para la URL de la página web y la credencial API del navegador de Bright Data y, a continuación, declara una función que acepta la URL como parámetro.
Añada el siguiente fragmento de código dentro del marcador de posición del flujo de trabajo de automatización web:
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to webpage
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("Navigated! Waiting for popup...");
El siguiente fragmento de código conecta Puppeteer a Bright Data Browser utilizando su API WebSocket endpoint. Una vez establecida la conexión, abre una nueva página del navegador y navega a la URL pasada en la función run().
Por último, recupere los datos en la página web utilizando selectores CSS con el siguiente fragmento de código:
//👇🏻 Get contact details using CSS attribute
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // Skip if any required element is missing
}
const contact = {
name:
(nameEl as HTMLElement)?.dataset.name ||
(nameEl as HTMLElement)?.innerText.trim() ||
null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("Contacts grid found! Extracting data...", contacts);
El fragmento de código anterior recorre cada tarjeta de contacto de la página web y extrae detalles clave como el nombre, el cargo, el número de teléfono, la dirección de correo electrónico, la empresa, la dirección y la fecha del último contacto.
Aquí está el script de automatización completo:
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS ="wss://brd-customer-*******";
run(URL);
async function run(url: string) {
try {
//👇🏻 connect to Bright data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to webpage
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("Navigated! Waiting for popup...");
//👇🏻 Get contact details using CSS attribute
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // Skip if any required element is missing
}
const contact = {
name: (nameEl as HTMLElement)?.dataset.name || (nameEl as HTMLElement)?.innerText.trim() || null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("Contacts grid found! Extracting data...", contacts);
//👇🏻 close the browser
await browser.close();
} catch (err) {
console.error("Error fetching data");
}
}
Paso 4: Scripts de automatización de IA con Midscene y Bright Data
Bright Data soporta la automatización web con agentes de IA a través de la integración con Midscene. Dado que ambas herramientas soportan Puppeteer, combinarlas te permite escribir flujos de trabajo de automatización sencillos potenciados por IA. Cree un archivo combine.ts y copie el siguiente fragmento de código en el archivo:
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
/*
---------------------------
👉🏻 Web automation workflow 👈🏼
---------------------------
*/
//👇🏻 close the browser
await browser.close();
})()
);
El fragmento de código anterior crea una IIFE asíncrona (expresión de función invocada inmediatamente) e incluye una función de suspensión que permite añadir retardos dentro del script de automatización de IA.
A continuación, añada el siguiente fragmento de código al marcador de posición del flujo de trabajo de automatización web:
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
//👇🏻 declares page
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to website
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 init Midscene agent
const agent = new PuppeteerAgent(page as any);
// 👇🏻 get contact details using AI agent
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
//👇🏻 delays for 5secs
await sleep(5000);
//👇🏻 logs the result
console.log("search result", items);
El fragmento de código inicializa Puppeteer y su agente para navegar a la página web, obtener todos los datos de contacto y registrar los resultados en la consola. Esto muestra cómo se puede integrar el agente Puppeteer AI con Bright Data Browser API para confiar en los comandos claros que proporciona Midscene.
Paso 5: Ponerlo todo en orden
En la sección anterior, aprendió a integrar Midscene con Bright Data Browser API. A continuación se muestra el script de automatización completo:
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-*****";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to Booking.com
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 init Midscene agent
const agent = new PuppeteerAgent(page as any);
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
await sleep(5000);
console.log("search result", items);
await browser.close();
})()
);
Ejecute el siguiente fragmento de código en su terminal para ejecutar el script:
npx tsx combine.ts
El fragmento de código anterior ejecuta el script de automatización y registra los datos de contacto en la consola.
[
{
name: 'Alice Johnson',
jobTitle: 'Senior Software Engineer',
phone: '+1 (555) 123-4567',
email: '[email protected]',
company: 'TechCorp Innovation - Engineering',
address: '123 Tech Street, San Francisco...',
lastContact: 'Last contact: 2026-05-15'
},
{
name: 'Bob Wilson',
jobTitle: 'UI/UX Designer',
phone: '+1 (555) 234-5678',
email: '[email protected]',
company: 'Creative Design Studio - Product',
address: '456 Design Ave, New York, NY...',
lastContact: 'Last contact: 2026-05-20'
},
{
name: 'Carol Davis',
jobTitle: 'Sales Director',
phone: '+1 (555) 345-6789',
email: '[email protected]',
company: 'Sales Force Solutions - Sales',
address: '789 Business Blvd, Chicago, IL...',
lastContact: 'Last contact: 2026-06-01'
},
{
name: 'David Brown',
jobTitle: 'Marketing Manager',
phone: '+1 (555) 456-7890',
email: '[email protected]',
company: 'Marketing Solutions Inc - Marketing',
address: '321 Market St, Austin, TX...',
lastContact: 'Last contact: 2026-05-25'
},
{
name: 'Emma Taylor',
jobTitle: 'HR Manager',
phone: '+1 (555) 567-8901',
email: '[email protected]',
company: 'HR Expert Solutions - Human Resources',
address: '654 Corporate Way, Seattle, WA...',
lastContact: 'Last contact: 2026-05-30'
}
]
Paso nº 6: Próximos pasos
Este tutorial muestra las posibilidades que ofrece la integración de Midscene con la API de Bright Data Browser. Puede partir de esta base para automatizar flujos de trabajo más complejos.
Combinando ambas herramientas, puede realizar tareas de automatización del navegador eficientes y escalables, como:
- Extracción de datos estructurados de sitios web dinámicos o con mucho JavaScript
- Automatización del envío de formularios para pruebas o recopilación de datos
- Navegar por sitios web e interactuar con elementos mediante instrucciones en lenguaje natural
- Ejecución de trabajos de extracción de datos a gran escala con gestión de proxy y manejo de CAPTCHA
Conclusión
Hasta ahora, ha aprendido a automatizar los procesos de raspado web mediante Midscene y la API Bright Data Browser, y a utilizar ambas herramientas para raspar sitios web a través de agentes de IA.
Midscene depende en gran medida de los modelos de IA para la automatización del navegador, y su uso con Bright Data Scraping Browser supone una reducción de las líneas de código con funciones eficaces de raspado web. La API de navegador es solo un ejemplo de cómo las herramientas y servicios de Bright Data pueden potenciar la automatización avanzada basada en IA.
Regístrese ahora para explorar todos los productos.





