

Cuando se realiza el Scraping web, el parseo HTML es fundamental, independientemente de las herramientas que se utilicen.El Scraping web con Java no es una excepción a esta regla. En Python, utilizamos herramientas comoRequestsyBeautifulSoup. Con Java, podemos enviar nuestras solicitudes HTTP y realizar el parseo de nuestro HTML utilizandojsoup. Para este tutorial, utilizaremosBooks to Scrape.
Introducción
En este tutorial, vamos a utilizar Maven para la gestión de dependencias. Si aún no lo tienes, puedes instalar Mavenaquí.
Una vez que hayas instalado Maven, debes crear un nuevo proyecto Java. El siguiente comando crea un nuevo proyecto, jsoup-scraper.
mvn archetype:generate -DgroupId=com.example -DartifactId=jsoup-scraper -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
A continuación, deberá añadir las dependencias pertinentes. Reemplace el código depom.xmlpor el código siguiente. Es similar a la gestión de dependencias enRustcon Cargo.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<ARTIFACTID>jsoup-scraper</ARTIFACTID>
<PACKAGING>jar</PACKAGING>
<VERSION>1.0-SNAPSHOT</VERSION>
<NAME>jsoup-scraper</NAME>
<URL>http://maven.apache.org</URL>
<DEPENDENCIES>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<versión>1.16.1</versión>
</dependencia>
</dependencias>
<propiedades>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
</propiedades>
</proyecto>
Pega el siguiente código en App.java. No es mucho, pero es el Scraper básico a partir del cual construiremos.
package com.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
String url = "https://books.toscrape.com";
int pageCount = 1;
while (pageCount <= 1) {
try {
System.out.println("---------------------PÁGINA "+pageCount+"--------------------------");
//conectarse a un sitio web y obtener su HTML
Document doc = Jsoup.connect(url).get();
//imprimir el título
System.out.println("Título de la página: " + doc.title());
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("Total de páginas extraídas: "+(pageCount-1));
}
}
Jsoup.connect("https://books.toscrape.com").get(): esta línea recupera la página y devuelve un objetoDocumentque podemos manipular.doc.title()devuelve el título del documento HTML, en este caso:Todos los productos | Libros para extraer - Sandbox.
Uso de métodos DOM con Jsoup
jsoup contiene una variedad de métodos para encontrar elementos en el DOM (Modelo de objetos de documento). Podemos utilizar cualquiera de los siguientes para encontrar fácilmente elementos de la página.
getElementById(): Busca un elemento utilizando suid.getElementsByClass(): Busca todos los elementos utilizando su clase CSS.getElementsByTag(): Busca todos los elementos utilizando su etiqueta HTML.getElementsByAttribute(): Encuentra todos los elementos que contienen un determinado atributo.
getElementById
En nuestro sitio de destino, la barra lateral contiene un div con un id de promotions_left. Puedes verlo en la imagen de abajo.
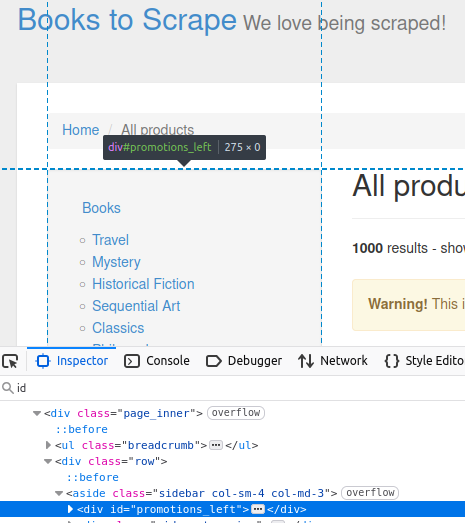
//obtener por Id
Element sidebar = doc.getElementById("promotions_left");
System.out.println("Sidebar: " + sidebar);
Este código muestra el elemento HTML que se ve en la página de inspección.
Sidebar: <div id="promotions_left">
</div>
getElementsByTag
getElementsByTag() nos permite encontrar todos los elementos de la página con una etiqueta determinada. Veamos los libros de esta página.
Cada libro contiene una etiqueta de artículo única.
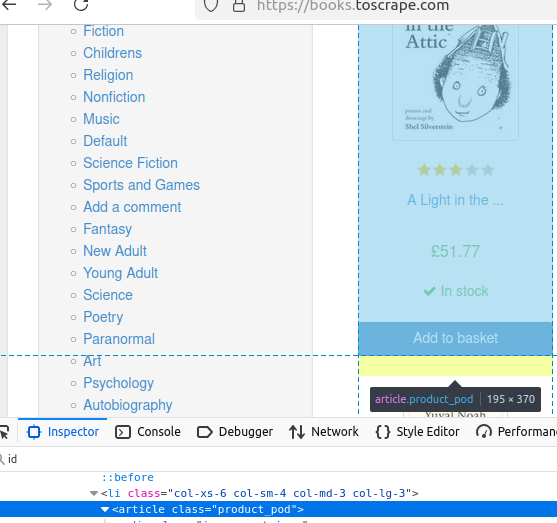
El código siguiente no imprimirá nada, pero devolverá una matriz de libros. Estos libros proporcionarán la base para el resto de nuestros datos.
//obtener por etiqueta
Elements books = doc.getElementsByTag("article");
getElementsByClass
Veamos el precio de un libro. Como se puede ver resaltado, su clase es price_color.
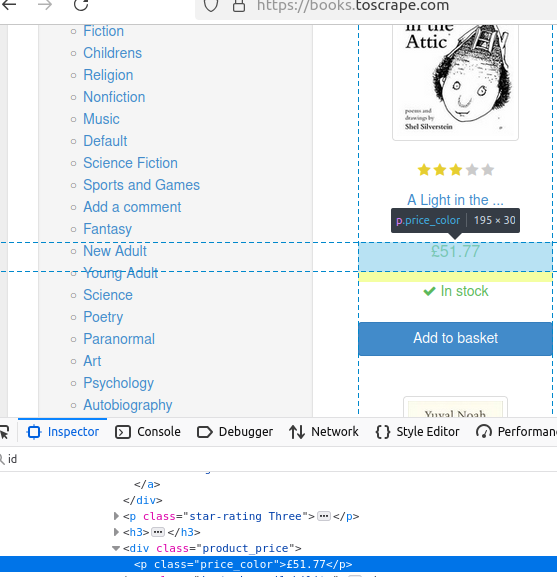
En este fragmento, encontramos todos los elementos de la clase price_color. A continuación, imprimimos el texto del primero utilizando .first().text().
System.out.println("Precio: " + book.getElementsByClass("price_color").first().text());
getElementsByAttribute
Como ya sabrás, todos los elementos a requieren un atributo href. En el código siguiente, utilizamos getElementsByAttribute("href") para encontrar todos los elementos con un href. Utilizamos .first().attr("href") para devolver su href.
//obtener por atributo
Elements hrefs = book.getElementsByAttribute("href");
System.out.println("Enlace: https://books.toscrape.com/" + hrefs.first().attr("href"));
Técnicas avanzadas
Selektores CSS
Cuando queremos utilizar varios criterios para buscar elementos, podemos pasar selectores CSSal métodoselect(). Este método devuelve una matriz de todos los objetos que coinciden con el selector. A continuación, utilizamosli[class='next']para buscar todos los elementoslicon la clasenext.
Elementos nextPage = doc.select("li[class='next']");
Gestión de la paginación
Para gestionar nuestra paginación, utilizamos nextPage.first() para llamar a getElementsByAttribute("href").attr("href") en el primer elemento devuelto por la matriz y extraer su href. Curiosamente, después de la página 2, la palabra «catálogo» se elimina de los enlaces, por lo que, si no está presente en el href, la volvemos a añadir. A continuación, combinamos este enlace con nuestra URL base y lo utilizamos para obtener el enlace a la página siguiente.
if (!nextPage.isEmpty()) {
String nextUrl = nextPage.first().getElementsByAttribute("href").attr("href");
if (!nextUrl.contains("catalogue")) {
nextUrl = "catalogue/"+nextUrl;
}
url = "https://books.toscrape.com/" + nextUrl;
pageCount++;
}
Poniendo todo junto
Este es nuestro código final. Si desea extraer más de una página, simplemente cambie el 1 en while (pageCount <= 1) por el objetivo deseado. Si desea extraer 4 páginas, utilice while (pageCount <= 4).
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
String url = "https://books.toscrape.com";
int pageCount = 1;
while (pageCount <= 1) {
try {
System.out.println("---------------------PÁGINA "+pageCount+"--------------------------");
//conectarse a un sitio web y obtener su HTML
Document doc = Jsoup.connect(url).get();
//imprimir el título
System.out.println("Título de la página: " + doc.title());
//obtener por Id
Element sidebar = doc.getElementById("promotions_left");
System.out.println("Barra lateral: " + barra lateral);
//obtener por etiqueta
Elements libros = doc.getElementsByTag("artículo");
for (Element libro : libros) {
System.out.println("------Libro------");
System.out.println("Título: " + book.getElementsByTag("img").first().attr("alt"));
System.out.println("Precio: " + book.getElementsByClass("price_color").first().text());
System.out.println("Disponibilidad: " + book.getElementsByClass("instock availability").first().text());
//obtener por atributo
Elements hrefs = book.getElementsByAttribute("href");
System.out.println("Enlace: https://books.toscrape.com/" + hrefs.first().attr("href"));
}
//buscar el siguiente botón utilizando su selector CSS
Elements nextPage = doc.select("li[class='next']");
if (!nextPage.isEmpty()) {
String nextUrl = nextPage.first().getElementsByAttribute("href").attr("href");
if (!nextUrl.contains("catalogue")) {
nextUrl = "catalogue/"+nextUrl;
}
url = "https://books.toscrape.com/" + nextUrl;
pageCount++;
}
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("Total de páginas recopiladas: "+(pageCount-1));
}
}
Antes de ejecutar el código, recuerde compilarlo.
mvn package
A continuación, ejecútelo con el siguiente comando.
mvn exec:java -Dexec.mainClass="com.example.App"
Aquí está el resultado de la primera página.
---------------------PÁGINA 1--------------------------
Título de la página: Todos los productos | Libros para rastrear - Sandbox
Barra lateral: <div id="promotions_left">
</div>
------Libro------
Título: Una luz en el ático
Precio: 51,77 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
------Libro------
Título: Tipping the Velvet
Precio: 53,74 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html
------Libro------
Título: Soumission
Precio: 50,10 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/soumission_998/index.html
------Libro------
Título: Sharp Objects (Objetos cortantes)
Precio: 47,82 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/sharp-objects_997/index.html
------Libro------
Título: Sapiens: Una breve historia de la humanidad
Precio: 54,23 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html
------Libro------
Título: The Requiem Red
Precio: 22,65 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/the-requiem-red_995/index.html
------Libro------
Título: The Dirty Little Secrets of Getting Your Dream Job
Precio: 33,34 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html
------Libro------
Título: The Coming Woman: Una novela basada en la vida de la famosa feminista Victoria Woodhull
Precio: 17,93 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html
------Libro------
Título: The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics (Los chicos del barco: nueve estadounidenses y su épica búsqueda del oro en los Juegos Olímpicos de Berlín de 1936)
Precio: 22,60 £
Disponibilidad: En stock.
Enlace: https://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html
------Libro------
Título: The Black Maria (La María Negra)
Precio: 52,15 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/the-black-maria_991/index.html
------Libro------
Título: Starving Hearts (Trilogía del comercio triangular, n.º 1)
Precio: 13,99 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html
------Libro------
Título: Shakespeare's Sonnets (Sonetos de Shakespeare)
Precio: 20,66 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html
------Libro------
Título: Set Me Free (Libérame)
Precio: 17,46 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/set-me-free_988/index.html
------Libro------
Título: Scott Pilgrim's Precious Little Life (La preciosa vida de Scott Pilgrim) (Scott Pilgrim n.º 1)
Precio: 52,29 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html
------Libro------
Título: Rip it Up and Start Again (Rompe y empieza de nuevo)
Precio: 35,02 £
Disponibilidad: En stock.
Enlace: https://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html
------Libro------
Título: Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991
Precio: 57,25 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html
------Libro------
Título: Olio
Precio: 23,88 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/olio_984/index.html
------Libro------
Título: Mesaerion: Las mejores historias de ciencia ficción 1800-1849
Precio: 37,59 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html
------Libro------
Título: Libertarianismo para principiantes
Precio: 51,33 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html
------Libro------
Título: It's Only the Himalayas (Solo es el Himalaya)
Precio: 45,17 £
Disponibilidad: En stock
Enlace: https://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html
Total de páginas recopiladas: 1
Conclusión
Ahora que ya sabes cómo extraer datos HTML con jsoup, puedes empezar a crear Scrapers web más avanzados. Ya sea que estés rastreando listados de productos, artículos de noticias o datos de investigación, manejar contenido dinámico y evitar bloqueos son retos clave.
Para ampliar tus esfuerzos de rastreo de manera eficiente, considera utilizar las herramientas de Bright Data:
- Proxies residenciales: evita las prohibiciones de IP y accede a contenido con restricciones geográficas.
- Navegador de scraping: renderiza sin esfuerzo sitios con mucho JavaScript.
- Conjuntos de datos listos para usar: olvídate del rastreo y obtén datos estructurados al instante.
Al combinar jsoup con la infraestructura adecuada, puede extraer datos a gran escala y minimizar los riesgos de detección. ¿Está listo para llevar el Scraping web al siguiente nivel? Regístrese ahora y comience su prueba gratuita.





