

Python es, con diferencia, el lenguaje de Scraping web dominante en todo el mundo. No siempre fue así. A finales de la década de 1990 y principios de la de 2000, el Scraping web se realizaba casi en su totalidad en Perl y PHP.
Hoy vamos a enfrentar a Python con uno de esos titanes del desarrollo web del pasado, PHP. Repasaremos algunas diferencias entre ambos lenguajes y veremos cuál ofrece la mejor experiencia de Scraping web.
Requisitos previos
Si decides seguirnos, necesitarás tener instalados Python y PHP. Haz clic en los enlaces de descarga correspondientes y sigue las instrucciones para tu sistema operativo específico.
- Python
- PHP
Puedes comprobar la instalación de cada uno con los siguientes comandos.
Python
python --version
Debería ver un resultado como este.
Python 3.10.12
PHP
php --version
Aquí está el resultado.
PHP 8.3.14 (cli) (compilado: 25 de noviembre de 2024, 18:07:16) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.3.14, Copyright (c) Zend Technologies
con Zend OPcache v8.3.14, Copyright (c), por Zend Technologies
Sería útil tener un conocimiento básico de ambos lenguajes, pero no es un requisito. De hecho, ¡nunca había escrito nada en PHP hasta ahora!
Comparación entre Python y PHP para el Scraping web
Antes de crear nuestro proyecto, debemos examinar cada uno de estos lenguajes con un poco más de detalle.
- Sintaxis: Python tiene una sintaxis más legible y ampliamente adoptada, especialmente en la comunidad de datos.
- Biblioteca estándar: ambos lenguajes ofrecen bibliotecas estándar muy completas.
- Marcos de scraping: Python tiene una selección mucho más amplia de marcos de scraping.
- Rendimiento: PHP tiende a ofrecer velocidades más rápidas porque fue creado para ejecutarse en la web.
- Mantenimiento: Python tiende a ser más fácil de mantener debido a su sintaxis clara y al fuerte apoyo de la comunidad.
| Característica | Python | PHP |
|---|---|---|
| Facilidad de uso | Apto para principiantes y fácil de aprender | Más difícil para los desarrolladores noveles |
| Biblioteca estándar | Amplia y repleta de funciones | Rica y llena de funciones |
| Herramientas de scraping | Muchas herramientas de scraping de terceros | Ecosistema mucho más reducido |
| Compatibilidad con datos | Diseñado pensando en el procesamiento de datos | Bibliotecas y herramientas básicas disponibles |
| Comunidad | Grandes comunidades y soporte | Comunidades más pequeñas con soporte limitado |
| Mantenimiento | Fácil de mantener, uso generalizado | Difícil, es complicado encontrar programadores |
¿Qué rastrear?
Dado que se trata solo de una demostración y queremos un sitio que sea coherente para la evaluación comparativa, vamos a utilizar quotes.toscrape.com. Este sitio nos ofrece contenido coherente y no bloquea los Scrapers. Es perfecto para casos de prueba.
En la imagen siguiente, puede ver uno de los elementos de cita de la página. Es un div con la clase quote. Primero tendremos que encontrar todos estos elementos.
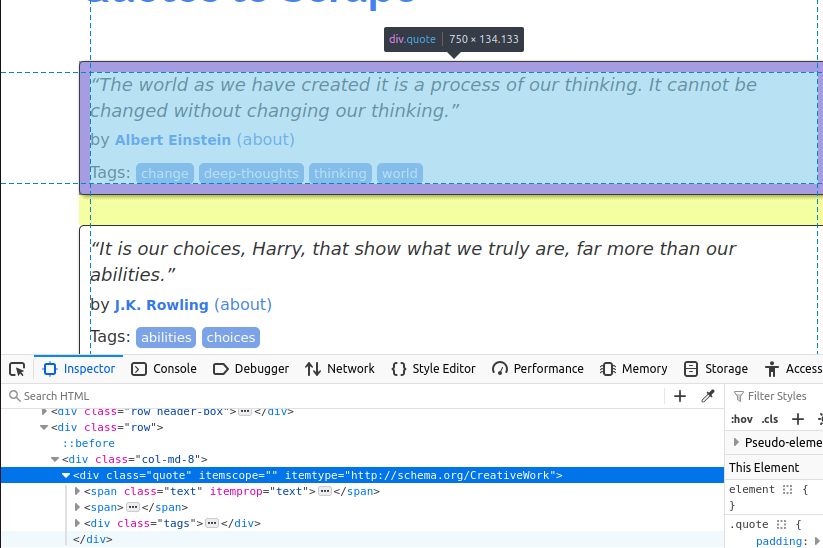
Una vez que hayamos encontrado todas las tarjetas de citas en la página, tendremos que extraer los elementos individuales de cada una.
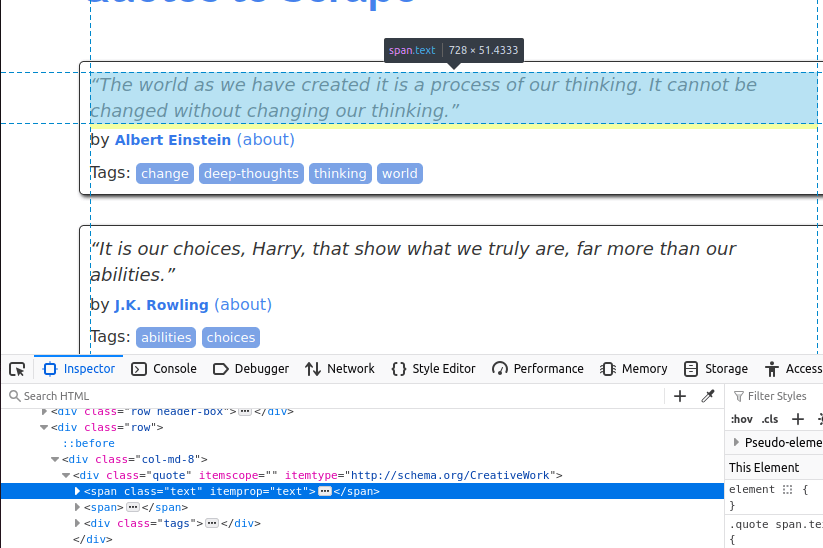
El texto viene incrustado en un elemento span con la clase text.
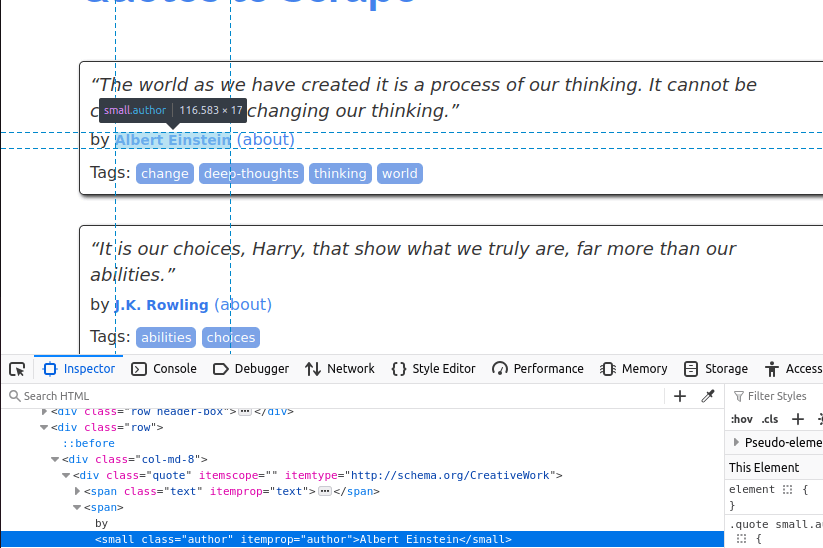
Ahora, tenemos que obtener el autor. Este se encuentra dentro de un pequeño elemento con la clase author.
Por último, extraeremos las etiquetas. Estas se encuentran dentro de elementos con la clase tag.

Ahora que sabemos qué datos queremos, estamos listos para empezar.
Primeros pasos
Ahora es el momento de configurarlo todo. Necesitaremos un par de dependencias con Python y PHP.
Python
Para Python, necesitamos instalar Requests y BeautifulSoup.
Podemos instalarlos ambos con pip.
pip install requests
pip install beautifulsoup4
PHP
Aparentemente, todas estas dependencias deberían venir preinstaladas con PHP. Sin embargo, cuando fui a utilizarlas, no era así.
sudo apt install php-curl
sudo apt install php-xml
Con nuestras dependencias instaladas, ya estamos listos para empezar a programar.
Extracción de datos
Empecé escribiendo el siguiente Scraper en Python. El código siguiente realiza una serie de solicitudes a quotes.toscrape.com. Extrae el texto, el nombre y el autor de cada cita. Una vez que ha terminado de obtener todas las citas, las escribimos en un archivo JSON. No dudes en copiarlo y pegarlo en tu propio archivo Python.
Python
import requests
from bs4 import BeautifulSoup
import json
page_number = 1
output_json = []
while page_number <= 5:
response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")
soup = BeautifulSoup(response.text, "html.parser")
divs = soup.select("div[class='quote']")
for div in divs:
tags = []
quote_text = div.select_one("span[class='text']").text
author = div.select_one("small[class='author']").text
tag_holders = div.select("a[class='tag']")
for tag_holder in tag_holders:
tags.append(tag_holder.text)
quote_dict = {
"author": author,
"quote": quote_text.strip(),
"tags": tags
}
output_json.append(quote_dict)
page_number+=1
with open("quotes.json", "w") as file:
json.dump(output_json, file, indent=4)
print("Scraping complete. Quotes saved to quotes.json.")
- En primer lugar, establecemos las variables para
page_numberyoutput_json. while page_number <= 5le dice al Scraper que continúe su trabajo hasta que hayamos rastreado 5 páginas.response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")envía una solicitud a la página en la que nos encontramos.- Encontramos todos nuestros elementos
divobjetivo condivs = soup.select("div[class='quote']"). - Iteramos a través de los
divsy extraemos sus datos:quote_text:div.select_one("span[class='text']").textauthor:div.select_one("small[class='author']").texttags: Encontramos todos los elementostag_holdery luego extraemos su texto individualmente.
- Una vez que hemos terminado con todo esto, guardamos la matriz
output_jsonen un archivo eimprimimos ()un mensaje en la terminal.
Aquí hay capturas de pantalla de algunas de nuestras ejecuciones. Hicimos más ejecuciones que estas, pero en aras de la brevedad, usaremos una muestra de 3 ejecuciones aquí.
La ejecución 1 tardó 11,642 segundos.

La ejecución 2 tardó 11,413.

La ejecución 3 tardó 10,258.

Nuestro tiempo de ejecución medio con Python es de 11,104 segundos.
PHP
Después de escribir el código Python, le pedí a ChatGPT que lo reescribiera en PHP. Al principio, el código no funcionaba, pero tras algunos pequeños ajustes, quedó listo para usar.
<?php
$pageNumber = 1;
$outputJson = [];
while ($pageNumber <= 5) {
$url = "https://quotes.toscrape.com/page/$pageNumber";
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$response = curl_exec($ch);
curl_close($ch);
if ($response === false) {
echo "Error al obtener la página $pageNumbern";
break;
}
$dom = new DOMDocument();
@$dom->loadHTML($response);
$xpath = new DOMXPath($dom);
$quoteDivs = $xpath->query("//div[@class='quote']");
foreach ($quoteDivs as $div) {
$quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";
$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";
$tagElements = $xpath->query(".//a[@class='tag']", $div);
$tags = [];
foreach ($tagElements as $tagElement) {
$tags[] = $tagElement->textContent;
}
$outputJson[] = [
"author" => trim($author),
"quote" => trim($quoteText),
"tags" => $tags
];
}
$pageNumber++;
}
$jsonData = json_encode($outputJson, JSON_PRETTY_PRINT | JSON_UNESCAPED_UNICODE);
file_put_contents("quotes.json", $jsonData);
echo "Raspado completado. Citas guardadas en quotes.json.n";
- Al igual que en el código Python, comenzamos con las variables
pageNumberyoutputJson. - Utilizamos un bucle
whilepara mantener el tiempo de ejecución del rastreo real:while ($pageNumber <= 5). $ch = curl_init($url);configura nuestra solicitud HTTP. Utilizamoscurl_setopt()para seguir las redirecciones.$response = curl_exec($ch);ejecuta la solicitud HTTP.$dom = new DOMDocument();configura un nuevo objetoDOMpara que lo utilicemos. Esto es similar a cuando utilizamosBeautifulSoup()anteriormente.- Obtenemos nuestros
divsutilizando su Xpath en lugar de su selector CSS:$quoteDivs = $xpath->query("//div[@class='quote']"); $quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";nos da el texto de cada cita.$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";nos da el autor.- Obtenemos nuestras
etiquetasbuscando de nuevo todos los elementos de etiqueta y iterándolos con un bucle para extraer su texto. - Por último, cuando todo está listo, guardamos nuestra salida en un archivo json e imprimimos un mensaje en la pantalla.
Estos son los resultados de nuestra ejecución con PHP.
La ejecución 1 tardó 11,351 segundos.

La ejecución 2 tardó 9,846.

La ejecución 3 tardó 9,795 segundos.

Nuestro promedio con PHP fue de 10,33 segundos.
Tras realizar más pruebas, PHP siguió ofreciendo resultados más rápidos… ¡A veces tan rápidos como 7 segundos!
Considere utilizar Bright Data
Si las secciones anteriores te han resultado interesantes, ¡escribe Scrapers web! Cuando te dedicas a extraer datos, cosas como las que ves arriba son el tipo de código que escribirás todo el tiempo.
Ofrecemos una variedad de productos que pueden hacer que tus scrapers sean más robustos.El Navegador de scrapingte ofrece un navegador remoto con integración de Proxy y renderización JavaScript incorporadas. Si solo quieres proxies y Resolución de CAPTCHA sin navegador, utilizaWeb Unlocker.
Los Scrapers no son para todo el mundo.
Si solo quieres obtener tus datos y seguir con tu día, echa un vistazo a nuestros Conjuntos de datos.Nosotros nos encargamos del scraping para que tú no tengas que hacerlo.Echa un vistazo a nuestrosConjuntos de datos listos para usar. Nuestros Conjuntos de datos más populares son LinkedIn, Amazon, Crunchbase, Zillow y Glassdoor. Puedes ver datos de muestra de forma gratuita y descargar informes en formato CSV o JSON.
Conclusión
Con una velocidad media de 11,104 segundos en Python y 10,33 segundos en PHP, nuestro scraper PHP fue consistentemente más rápido que el scraper Python. Parte de esto podría deberse a la latencia relacionada con el servidor, pero en pruebas posteriores, PHP siguió superando a Python en casi todas las ejecuciones.
Aunque sin duda supera a Python en la categoría de velocidad, no ocurre lo mismo con la sintaxis. Hoy en día, no muchos desarrolladores se sienten cómodos con la sintaxis utilizada en lenguajes como PHP o Perl. Son los lenguajes de scripting de antaño. Además, es posible que su equipo no se sienta cómodo con PHP. Se necesita un tipo especial de programador para escribir este tipo de código todo el tiempo y mantener las aplicaciones heredadas en funcionamiento.
Lleve sus operaciones de scraping al siguiente nivel con Bright Data. ¡Regístrese ahora y comience su prueba gratuita!





