

En esta guía aprenderás:
- Cómo identificar cuándo un sitio tiene una navegación compleja
- La mejor herramienta de scraping para manejar estos escenarios
- Cómo extraer patrones de navegación complejos comunes
¡Empecemos!
¿Cuándo tiene un sitio web una navegación compleja?
Un sitio con navegación compleja es unretocomún al que nos enfrentamos los desarrolladoresen el Scraping web. Pero, ¿qué significa exactamente «navegación compleja»? En el Scraping web, la navegación compleja se refiere a las estructuras de sitios web en las que no es fácil acceder al contenido o a las páginas.
Los casos de navegación compleja suelen implicar elementos dinámicos, carga de datos asíncrona o interacciones impulsadas por el usuario. Si bien estos aspectos pueden mejorar la experiencia del usuario, complican considerablemente los procesos de extracción de datos.
Ahora bien, la mejor manera de entender la navegación compleja es explorar algunos ejemplos:
- Navegación renderizada con JavaScript: sitios web que dependen de marcos de JavaScript (como React, Vue.js o Angular) para generar contenido directamente en el navegador.
- Contenido paginado: sitios con datos repartidos en varias páginas. Esto se vuelve más complejo cuando la paginación se carga numéricamente a través de AJAX, lo que dificulta el acceso a las páginas siguientes.
- Desplazamiento infinito: páginas que cargan contenido adicional de forma dinámica a medida que los usuarios se desplazan hacia abajo, algo habitual en las redes sociales y los sitios web de noticias.
- Menús multinivel: sitios con menús anidados que requieren varios clics o acciones de desplazamiento para revelar capas más profundas de navegación (por ejemplo, árboles de categorías de productos en grandes plataformas de comercio electrónico).
- Interfaces de mapas interactivos: sitios web que muestran información en mapas o gráficos, donde los puntos de datos se cargan dinámicamente a medida que los usuarios se desplazan o amplían la imagen.
- Pestañas o acordeones: páginas en las que el contenido se oculta bajo pestañas renderizadas dinámicamente o acordeones plegables cuyo contenido no está directamente incrustado en la página HTML devuelta por el servidor.
- Filtros dinámicos y opciones de clasificación: sitios con sistemas de filtrado complejos en los que la aplicación de múltiples filtros recarga la lista de elementos de forma dinámica, sin cambiar la estructura de la URL.
Las mejores herramientas de scraping para manejar sitios web con navegación compleja
Para extraer eficazmente un sitio con navegación compleja, debe comprender qué herramientas necesita utilizar. La tarea en sí misma es intrínsecamente difícil, y no utilizar las bibliotecas de scraping adecuadas solo la hará más difícil.
Lo que muchas de las interacciones complejas enumeradas anteriormente tienen en común es que:
- Requieren algún tipo de interacción por parte del usuario, o
- Se ejecutan en el lado del cliente dentro del navegador.
En otras palabras, estas tareas requieren la ejecución de JavaScript, algo que solo puede hacer un navegador. Esto significa que no se puede confiar en simplesanalizadores HTMLpara este tipo de páginas. En su lugar, se debe utilizar una herramienta de automatización del navegador como Selenium, Playwright o Puppeteer.
Estas soluciones le permiten indicar mediante programación a un navegador que realice acciones específicas en una página web, imitando el comportamiento del usuario. A menudo se denominannavegadores sin interfaz gráficaporque pueden renderizar el navegador sin una interfaz gráfica, lo que ahorra recursos del sistema.
Descubra lasmejores herramientas de navegador sin interfaz gráfica para el Scraping web.
Cómo extraer patrones de navegación complejos comunes
En esta sección del tutorial, utilizaremos Selenium en Python. Sin embargo, puede adaptar fácilmente la lógica a Playwright, Puppeteer o cualquier otra herramienta de automatización de navegadores. También daremos por sentado que ya está familiarizado con los conceptos básicos delScraping web con Selenium.
En concreto, trataremos cómo extraer los siguientes patrones de navegación complejos comunes:
- Paginación dinámica: sitios con datos paginados cargados dinámicamente a través de AJAX.
- Botón «Cargar más»: un ejemplo común de navegación basado en JavaScript.
- Desplazamiento infinito: una página que carga datos continuamente a medida que el usuario se desplaza hacia abajo.
¡Es hora de programar!
Paginación dinámica
La página de destino para este ejemplo es el entorno de pruebas«Películas ganadoras de un Óscar: AJAX y JavaScript»:
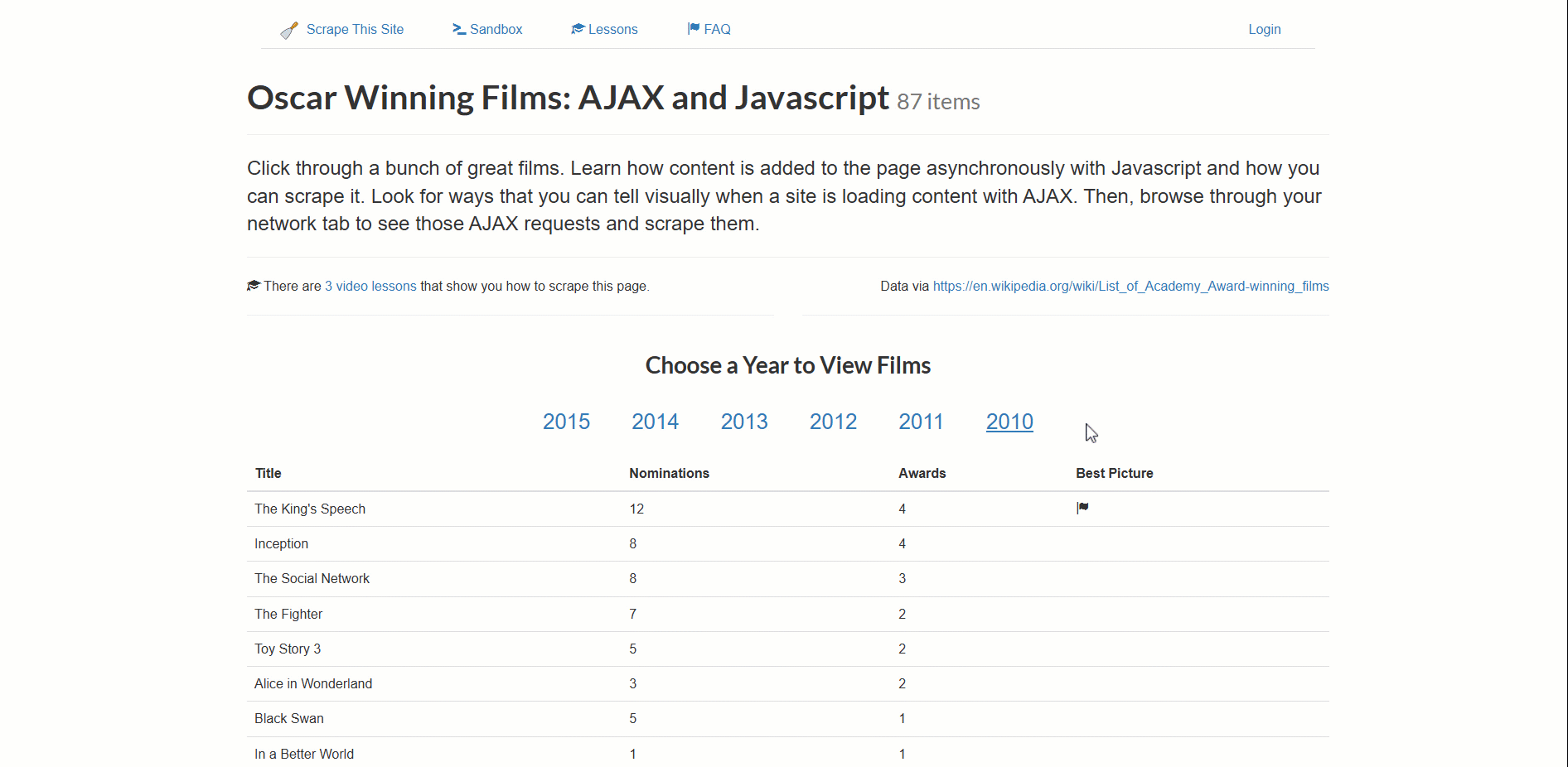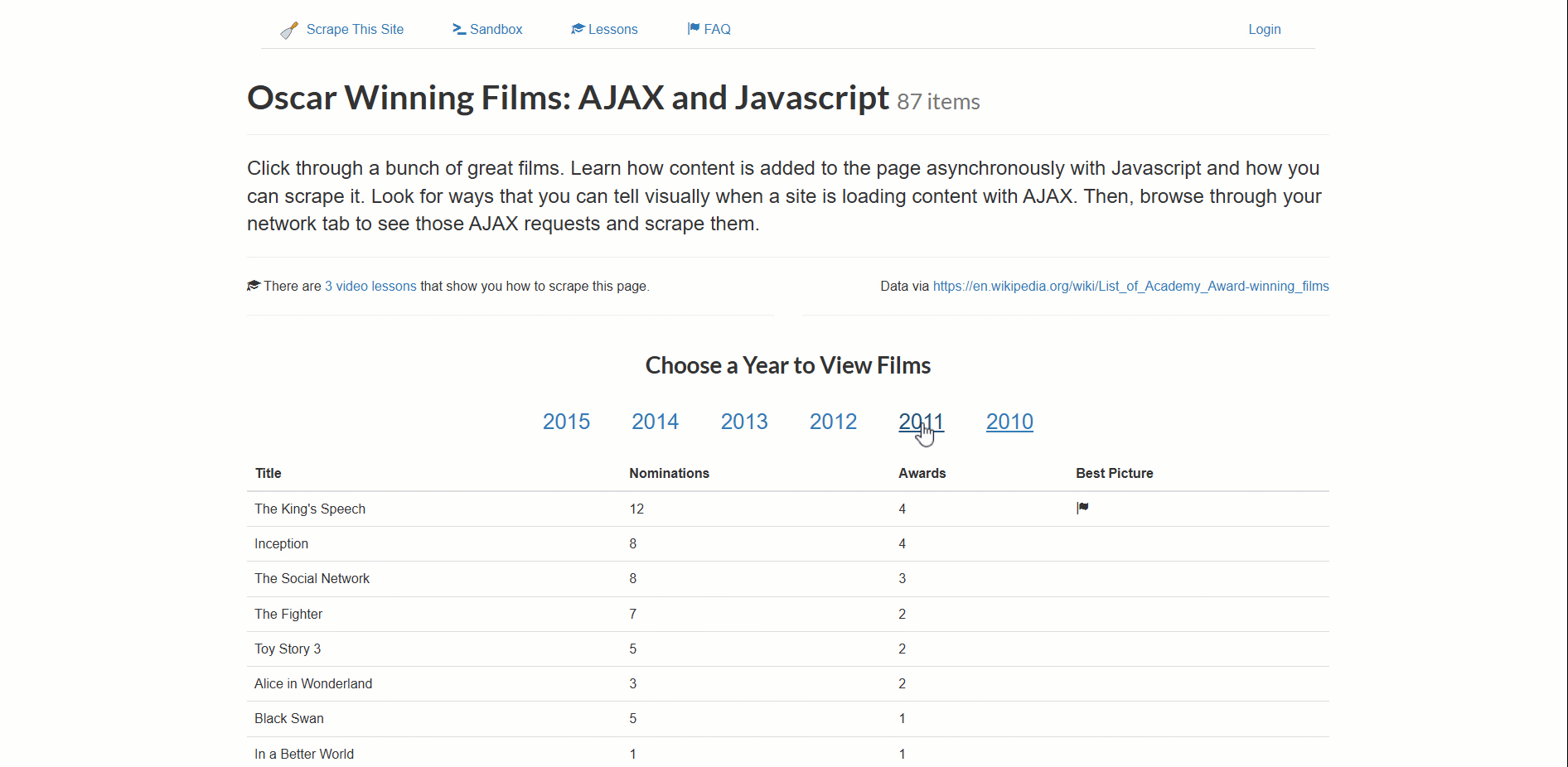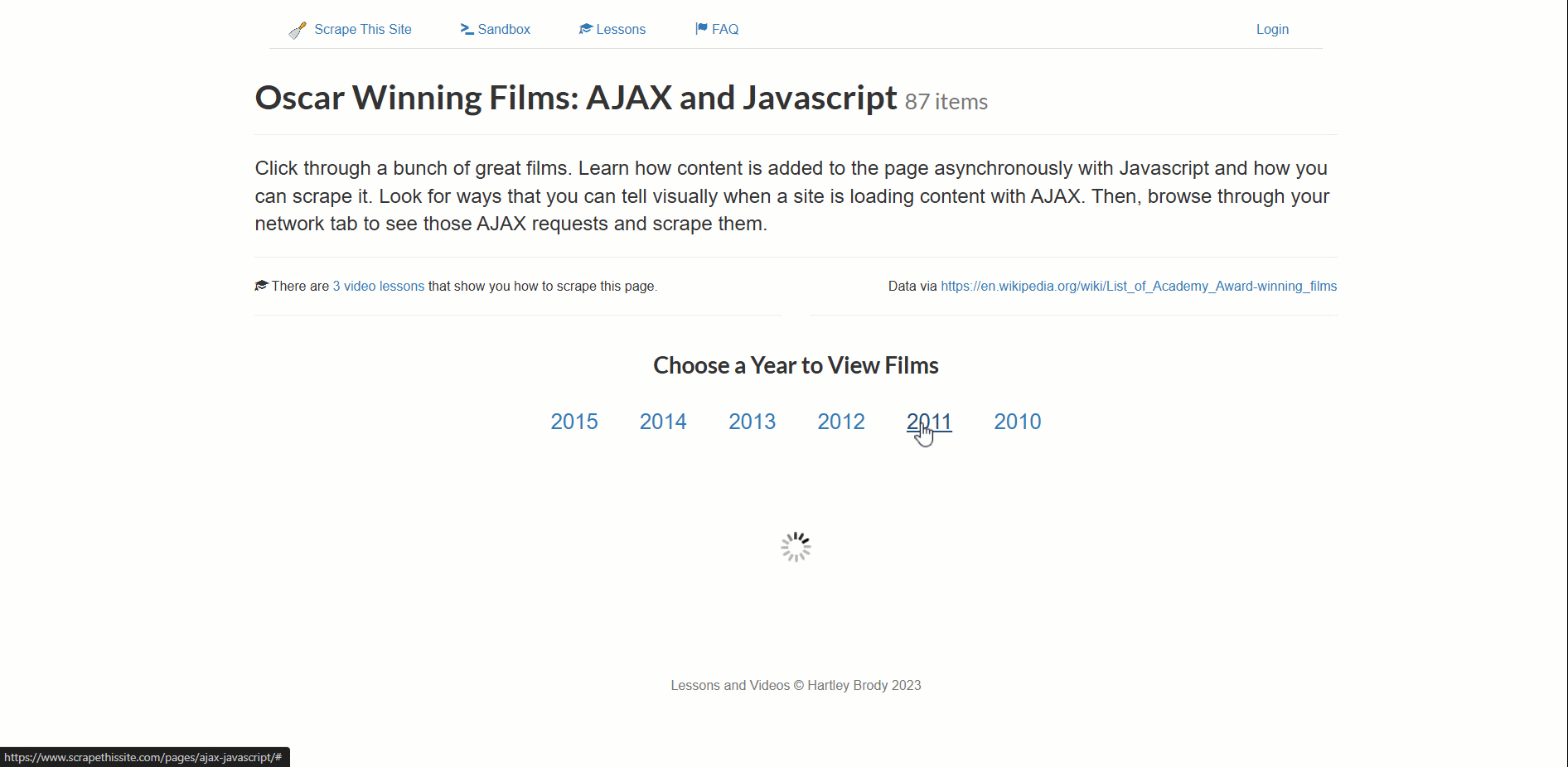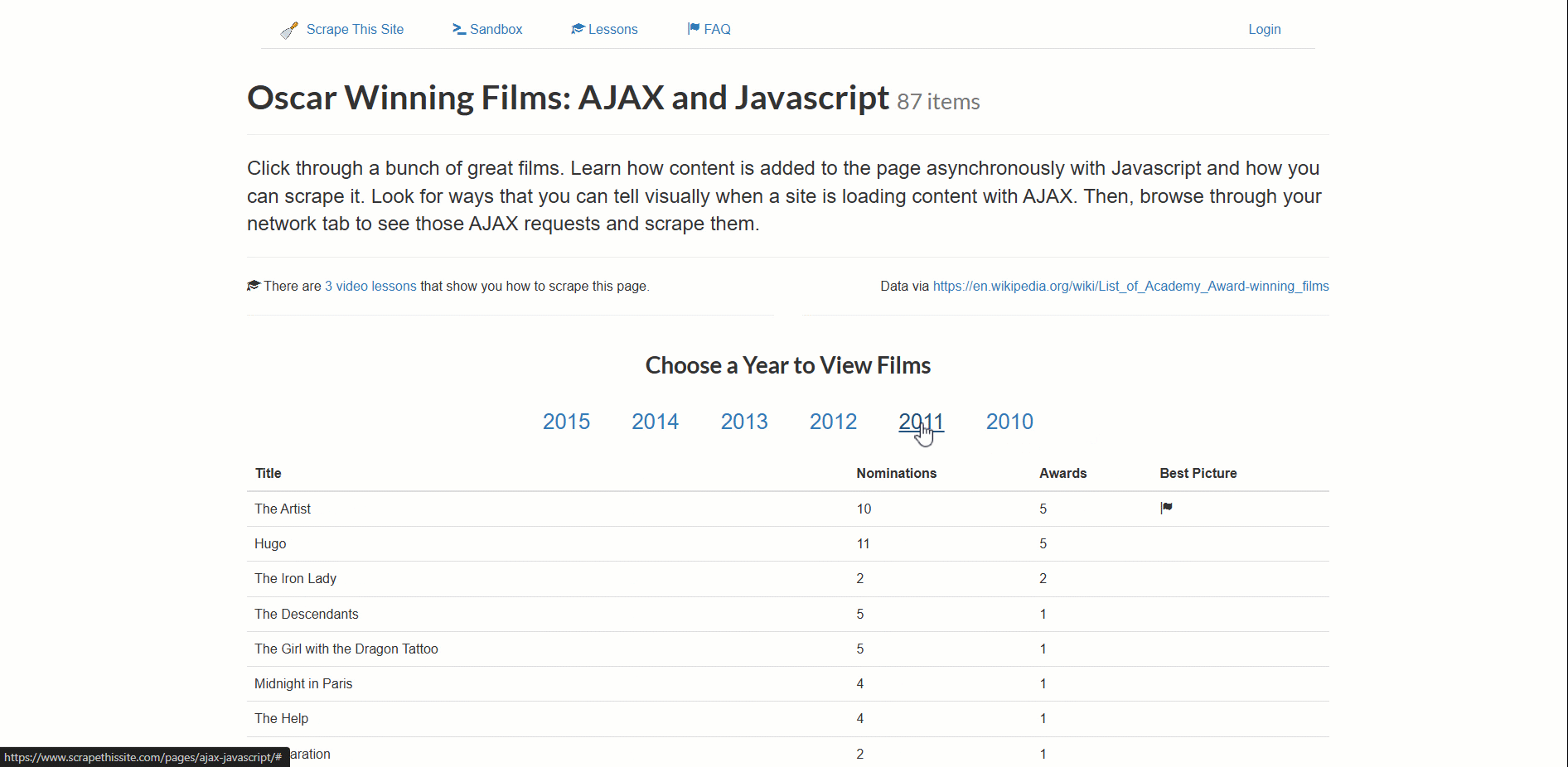
Este sitio carga dinámicamente datos de películas ganadoras de un Óscar, paginadas por año.
Para manejar una navegación tan compleja, el enfoque es el siguiente:
- Hacer clic en un nuevo año para activar la carga de datos (aparecerá un elemento de carga).
- Espere a que el elemento de carga desaparezca (los datos ya están completamente cargados).
- Asegúrese de que la tabla con los datos se ha renderizado correctamente en la página.
- Extraiga los datos una vez que estén disponibles.
A continuación se detalla cómo se puede implementar esa lógica utilizando Selenium en Python:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
# Configurar las opciones de Chrome para el modo sin interfaz gráfica
options = Options()
options.add_argument("--headless")
# Crear una instancia del controlador web de Chrome
driver = webdriver.Chrome(service=Service(), options=options)
# Conectarse a la página de destino
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/")
# Hacer clic en el botón de paginación «2012»
element = driver.find_element(By.ID, "2012")
element.click()
# Esperar hasta que el cargador ya no sea visible
WebDriverWait(driver, 10).until(
lambda d: d.find_element(By.CSS_SELECTOR, "#loading").get_attribute("style") == "display: none;")
# Los datos ya deberían estar cargados...
# Esperar a que la tabla aparezca en la página
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".table")))
# Dónde almacenar los datos extraídos
films = []
# Extraer datos de la tabla
table_body = driver.find_element(By.CSS_SELECTOR, "#table-body")
rows = table_body.find_elements(By.CSS_SELECTOR, ".film")
for row in rows:
title = row.find_element(By.CSS_SELECTOR, ".film-title").text
nominations = row.find_element(By.CSS_SELECTOR, ".film-nominations").text
awards = row.find_element(By.CSS_SELECTOR, ".film-awards").text
best_picture_icon = row.find_element(By.CSS_SELECTOR, ".film-best-picture").find_elements(By.TAG_NAME, "i")
best_picture = True if best_picture_icon else False
# Almacenar los datos extraídos
films.append({
"title": title,
"nominations": nominations,
"awards": awards,
"best_picture": best_picture
})
# Lógica de exportación de datos...
# Cerrar el controlador del navegador
driver.quit()
Este es el desglose del código anterior:
- El código configura una instancia de Chrome sin interfaz gráfica.
- El script abre la página de destino y hace clic en el botón de paginación «2012» para activar la carga de datos.
- Selenium espera a que desaparezca el cargador utilizando
WebDriverWait(). - Una vez que el cargador desaparece, el script espera a que aparezca la tabla.
- Una vez que los datos se han cargado por completo, el script extrae los títulos de las películas, las nominaciones, los premios y si la película ganó el Óscar a la mejor película. Almacena estos datos en una lista de diccionarios.
El resultado será:
[
{
"title": "Argo",
"nominations": "7",
"awards": "3",
"best_picture": true
},
// ...
{
"title": "Curfew",
"nominations": "1",
"awards": "1",
"best_picture": false
}
]
Tenga en cuenta que no siempre hay una única forma óptima de manejar este patrón de navegación. Es posible que se requieran otras opciones dependiendo del comportamiento de la página. Algunos ejemplos son:
- Utilizar
WebDriverWait()en combinación con condiciones esperadas para esperar a que aparezcan o desaparezcan elementos HTML específicos. - Supervisar el tráfico de las solicitudes AJAX para detectar cuándo se obtiene nuevo contenido. Esto puede implicar el uso del registro del navegador.
- Identificar la solicitud de API activada por la paginación y realizar solicitudes directas para recuperar los datos mediante programación (por ejemplo, utilizando labiblioteca
de solicitudes).
Botón «Cargar más»
Para representar escenarios de navegación complejos basados en JavaScript que implican la interacción del usuario, elegimos el ejemplo del botón «Cargar más». El concepto es sencillo: se muestra una lista de elementos y, al hacer clic en el botón, se cargan elementos adicionales.
En esta ocasión, el sitio de destino será la páginade ejemplo «Cargar más»del curso de scraping:
Para manejar este complejo patrón de navegación, siga estos pasos:
- Localice el botón «Cargar más» y haga clic en él.
- Espere a que los nuevos elementos se carguen en la página.
A continuación se muestra cómo se puede implementar con Selenium:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# Configurar las opciones de Chrome para el modo sin interfaz gráfica
options = Options()
options.add_argument("--headless")
# Crear una instancia del controlador web de Chrome
driver = webdriver.Chrome(options=options)
# Conectarse a la página de destino
driver.get("https://www.scrapingcourse.com/button-click")
# Recopilar el número inicial de productos
initial_product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Localizar el botón «Cargar más» y hacer clic en él
load_more_button = driver.find_element(By.CSS_SELECTOR, "#load-more-btn")
load_more_button.click()
# Esperar hasta que haya aumentado el número de productos en la página.
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > initial_product_count)
# Dónde almacenar los datos extraídos.
products = []
# Recopilar detalles del producto
product_elements = driver.find_elements(By.CSS_SELECTOR, ".product-item")
for product_element in product_elements:
# Extraer detalles del producto
name = product_element.find_element(By.CSS_SELECTOR, ".product-name").text
image = product_element.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
price = product_element.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# Almacenar los datos extraídos
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# Lógica de exportación de datos...
# Cerrar el controlador del navegador
driver.quit()
Para gestionar esta lógica de navegación, el script:
- Registra el número inicial de productos en la página
- Hace clic en el botón «Cargar más»
- Espera hasta que aumente el recuento de productos, confirmando que se han añadido nuevos artículos
Este enfoque es inteligente y genérico, ya que no requiere conocer el número exacto de elementos que se van a cargar. No obstante, hay que tener en cuenta que existen otros métodos para conseguir resultados similares.
Desplazamiento infinito
El desplazamiento infinito es una interacción común utilizada por muchos sitios web para mejorar la participación de los usuarios, especialmente en las redes sociales y las plataformas de comercio electrónico. En este caso, el objetivo será la misma página que antes, pero condesplazamiento infinito en lugar del botón «Cargar más»:
La mayoría de las herramientas de automatización de navegadores (incluido Selenium) no proporcionan un método directo para desplazarse hacia abajo o hacia arriba en una página. En su lugar, es necesario ejecutar un script de JavaScript en la página para realizar la operación de desplazamiento.
La idea es escribir un script JavaScript personalizado que se desplace hacia abajo:
- Un número determinado de veces, o
- Hasta que no haya más datos disponibles para cargar.
Nota: Cada desplazamiento carga nuevos datos, incrementando el número de elementos de la página.
Después, puede extraer el contenido recién cargado.
Así es como se puede gestionar el desplazamiento infinito en Selenium:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# Configurar las opciones de Chrome para el modo sin interfaz gráfica
options = Options()
# options.add_argument("--headless")
# Crear una instancia del controlador web de Chrome
driver = webdriver.Chrome(options=options)
# Conectarse a la página de destino con desplazamiento infinito
driver.get("https://www.scrapingcourse.com/infinite-scrolling")
# Altura actual de la página
scroll_height = driver.execute_script("return document.body.scrollHeight")
# Número de productos en la página
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Número máximo de desplazamientos
max_scrolls = 10
scroll_count = 1
# Limitar el número de desplazamientos a 10
while scroll_count < max_scrolls:
# Desplazarse hacia abajo
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Esperar hasta que haya aumentado el número de productos en la página
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > product_count)
# Actualizar el recuento de productos
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Obtener la nueva altura de la página
new_scroll_height = driver.execute_script("return document.body.scrollHeight")
# Si no se ha cargado ningún contenido nuevo
if new_scroll_height == scroll_height:
break
# Actualizar la altura de desplazamiento e incrementar el recuento de desplazamiento
scroll_height = new_scroll_height
scroll_count += 1
# Recopilar los detalles del producto tras el desplazamiento infinito
productos = []
elementos_del_producto = driver.find_elements(By.CSS_SELECTOR, ".product-item")
para elemento_del_producto en elementos_del_producto:
# Extraer los detalles del producto
nombre = elemento_del_producto.find_element(By.CSS_SELECTOR, ".product-name").text
imagen = elemento_del_producto.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
precio = elemento_del_producto.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# Almacenar los datos extraídos
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# Exportar a CSV/JSON...
# Cerrar el controlador del navegador
driver.quit()
Este script gestiona el desplazamiento infinito determinando primero la altura actual de la página y el número de productos. A continuación, limita las acciones de desplazamiento a un máximo de 10 iteraciones. En cada iteración:
- Se desplaza hasta la parte inferior
- Espera a que aumente el número de productos (lo que indica que se ha cargado nuevo contenido)
- Compara la altura de la página para detectar si hay más contenido disponible
Si la altura de la página permanece sin cambios después de un desplazamiento, el bucle se interrumpe, lo que indica que no hay más datos para cargar. Así es como se pueden abordar patrones complejos de desplazamiento infinito.
¡Genial! Ahora eres un experto en el rastreo de sitios web con navegación compleja.
Conclusión
En este artículo, has aprendido sobre los sitios que se basan en patrones de navegación complejos y cómo utilizar Selenium con Python para lidiar con ellos. Esto demuestra que el Scraping web puede ser un reto, pero puede resultar aún más difícil debido alas medidas antirrastreo.
Las empresas comprenden el valor de sus datos y los protegen a toda costa, por lo que muchos sitios implementan medidas para bloquear los scripts automatizados. Estas soluciones pueden bloquear tu IP después de demasiadas solicitudes, presentar CAPTCHAs e incluso cosas peores.
Las herramientas tradicionales de automatización de navegadores, como Selenium, no pueden eludir esas restricciones…
La solución es utilizar un navegador basado en la nube y dedicado al scraping, comoel Navegador de scraping. Se trata de un navegador que se integra con Playwright, Puppeteer, Selenium y otras herramientas, y que rota automáticamente las IP con cada solicitud. Puede gestionar las huellas digitales del navegador, los reintentos,la Resolución de CAPTCHA y mucho más. ¡Olvídate de los bloqueos cuando trabajes con sitios web complejos!




