

En este artículo aprenderás:
- Qué es el Scraping web con Camoufox y cómo reduce la detección de bots basada en huellas digitales.
- Cómo configurar Camoufox con Proxies residenciales de Bright Data para una extracción de datos fiable.
- Dónde funciona bien Camoufox, dónde falla a gran escala y cuándo pasar al Navegador de scraping o al Web Unlocker de Bright Data para uso en producción.
¿Qué es Camoufox? Un vistazo a sus características principales

Camoufox es un navegador antidetección de código abierto basado en una versión modificada de Firefox. Está diseñado para la automatización del navegador y escenarios de Scraping web en los que los navegadores sin interfaz gráfica estándar se identifican y bloquean fácilmente.
Camoufox se centra en reducir la detección cambiando el comportamiento del navegador a nivel del motor, en lugar de basarse únicamente en trucos de JavaScript.
Características principales:
- Control de huellas digitales del navegador: Camoufox modifica los atributos de huellas digitales del navegador, como las propiedades del navegador, las interfaces gráficas, las capacidades multimedia y las señales de configuración regional. Estos cambios se aplican a nivel del navegador, lo que reduce las inconsistencias que suelen detectar los sistemas antibots.
- Parches de ocultación a nivel del motor: el navegador antidetección Camoufox elimina o altera los indicadores de automatización expuestos por las versiones predeterminadas del navegador. Esto incluye el manejo de propiedades que revelan marcos de automatización y evitar las firmas comunes de los navegadores sin interfaz gráfica sin inyectar scripts detectables en el contexto de la página.
- Aislamiento y variabilidad de las sesiones: cada sesión del navegador Camoufox está aislada, lo que permite utilizar diferentes perfiles de huellas digitales en cada ejecución. Esto ayuda a evitar la correlación entre sesiones cuando se extraen múltiples páginas o se reinicia el navegador.
Instalación y configuración
Instalar Camoufox: Camoufox se distribuye como un paquete Python y se envía con un navegador basado en Firefox fijado. Esto evita la deriva de la versión del navegador que aumenta la inestabilidad de las huellas digitales.
pip install -U camoufox[geoip]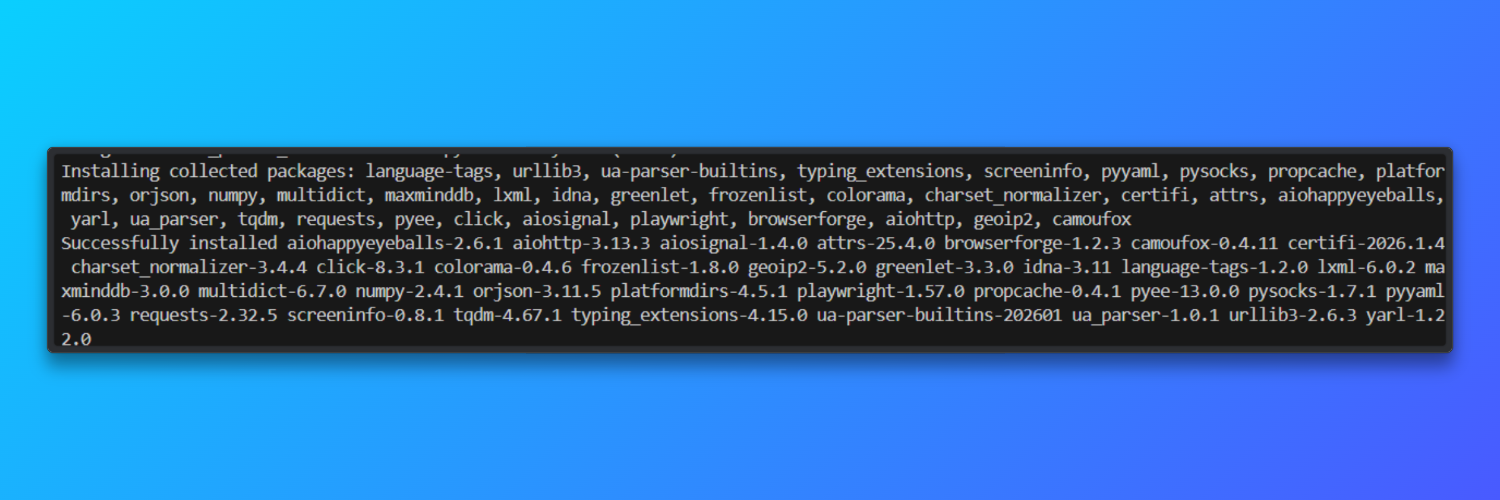
Descargar el navegador
camoufox fetch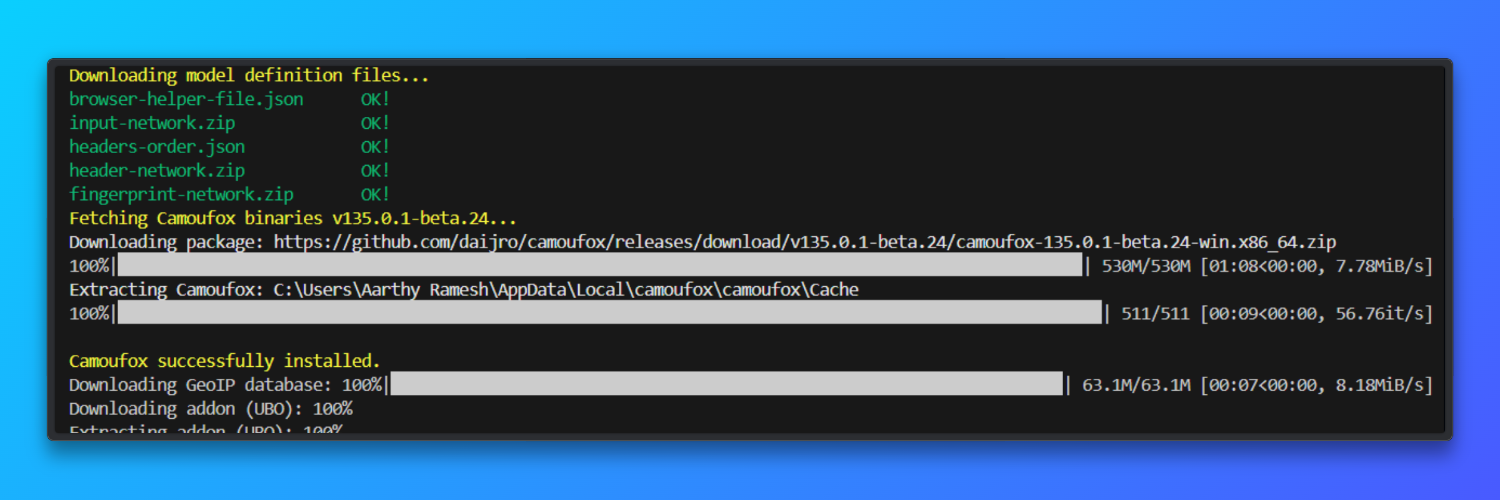
Requisitos de Python y del sistema operativo: Se requiere Python 3.9 o superior tanto en Windows como en macOS. Cada instancia de Camoufox consume aproximadamente 200 MB de memoria, lo que limita la concurrencia en sistemas con poca RAM.
Entorno virtual opcional (recomendado): el uso de un entorno virtual evita conflictos de dependencias que afectan al manejo de SSL, la representación de fuentes o las API gráficas. Esto se aplica tanto a Windows como a macOS.
python -m venv camoufox-envcamoufox-envScriptsactivate # Windowssource camoufox-env/bin/activate # macOSTutorial básico: Web scraping con Camoufox
En esta sección se muestra el flujo de trabajo mínimo necesario para utilizar Camoufox para el Scraping web. El código inicia un navegador Camoufox, abre una nueva página y carga una URL exactamente igual que un usuario real. Espera a que finalice toda la actividad de la red para garantizar que el contenido renderizado por JavaScript esté disponible.
Se captura una captura de pantalla completa para confirmar visualmente que la página se ha renderizado correctamente. Por último, se extrae el texto visible del cuerpo de la página para verificar que el rastreo funciona correctamente.
from camoufox.sync_api import Camoufox
with Camoufox(headless=True) as browser:
page = browser.new_page()
page.goto("<replace_with_a_link>")
page.wait_for_load_state("networkidle")
page.screenshot(path="page.png", full_page=True)
content = page.text_content("body")
print(content[:500])El script guarda una captura de pantalla llamada page.png en el directorio del proyecto que muestra la página web completamente renderizada. El terminal imprime la primera parte del texto visible de la página, lo que confirma que la extracción de contenido se ha realizado correctamente. Si la página se carga normalmente, no se producen errores.
Camoufox es muy adecuado para crear prototipos de flujos de trabajo de scraping basados en navegadores, ya que expone el comportamiento real de Firefox en lugar de abstraerlo.
Su huella digital nativa del navegador (a nivel de C++) alcanza alrededor de un 92 % de éxito cuando se combina con Proxies residenciales de alta calidad durante las primeras sesiones.
Como herramienta de código abierto, es especialmente valiosa para aprender cómo los sistemas antibots modernos evalúan las huellas digitales del navegador, las cookies y el estado de la sesión.
Configuración de los proxies de Bright Data con Camoufox
En esta sección se explica cómo configurar correctamente los Proxies residenciales de Bright Data con Camoufox para un Scraping web fiable y realista.
Por qué son importantes los proxies residenciales
Los Proxies residenciales enrutan las solicitudes a través de direcciones IP de consumidores reales en lugar de la infraestructura del centro de datos. Esto los hace significativamente más eficaces para las tareas de scraping web en las que los sitios web supervisan activamente los patrones de tráfico, la reputación de las IP o el origen de las solicitudes.
Muchos sitios web modernos implementan sistemas de mitigación de bots que bloquean rápidamente los rangos de IP de la nube o del centro de datos. Las IPs residenciales reducen este riesgo porque se asemejan al tráfico normal de los usuarios y son geográficamente coherentes con el comportamiento real de navegación. Esto es especialmente importante cuando se extrae contenido de plataformas con mucho contenido, páginas específicas de una región o sitios que aplican límites de velocidad y políticas de acceso.
Cuando se combinan con Camoufox, los Proxies residenciales ofrecen dos ventajas clave: huellas digitales de navegador realistas y autenticidad a nivel de IP. Esta combinación mejora las tasas de éxito de carga de páginas, reduce la frecuencia de CAPTCHA y permite que los scrapers funcionen durante más tiempo sin intervención manual. Para los procesos de scraping de nivel de producción, los Proxies residenciales son un componente fundamental de la infraestructura.
Configuración: Credenciales de Bright Data + Configuración automática de GeoIP
Inicie sesión en el panel de control de Bright Data y vaya a la sección Infraestructura de Proxy. Aquí es donde se crean y gestionan todas las zonas de Proxy.
Haga clic en el botón Crear Proxy para comenzar a configurar una nueva zona Proxy. Bright Data le guiará a través de un breve proceso de configuración.
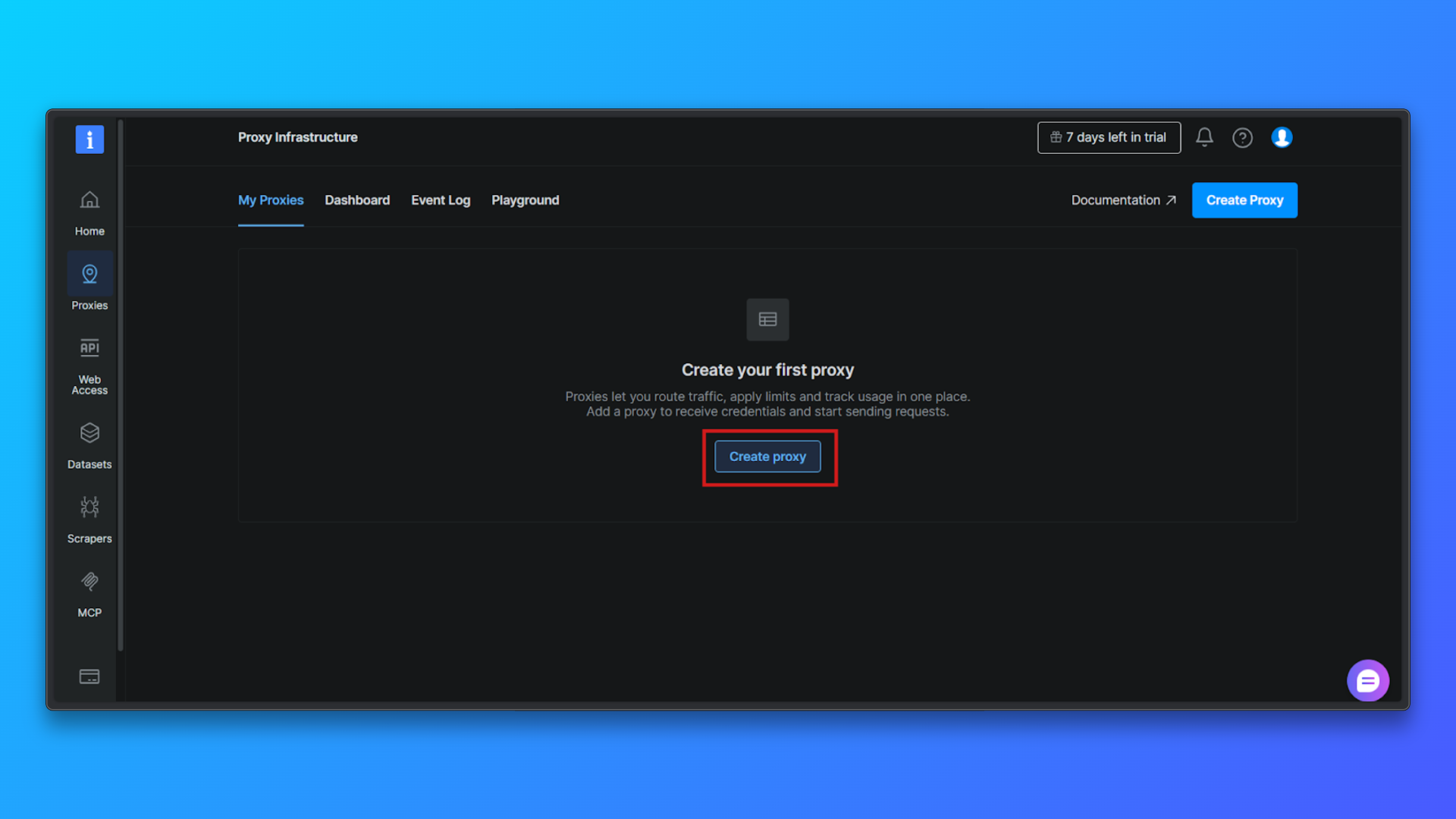
Elija Tipo de proxy → Residencial: en la lista de tipos de proxy, seleccione Residencial. Los Proxies residenciales dirigen el tráfico a través de IPs residenciales reales, lo que reduce significativamente la detección en comparación con los Proxies de centro de datos.
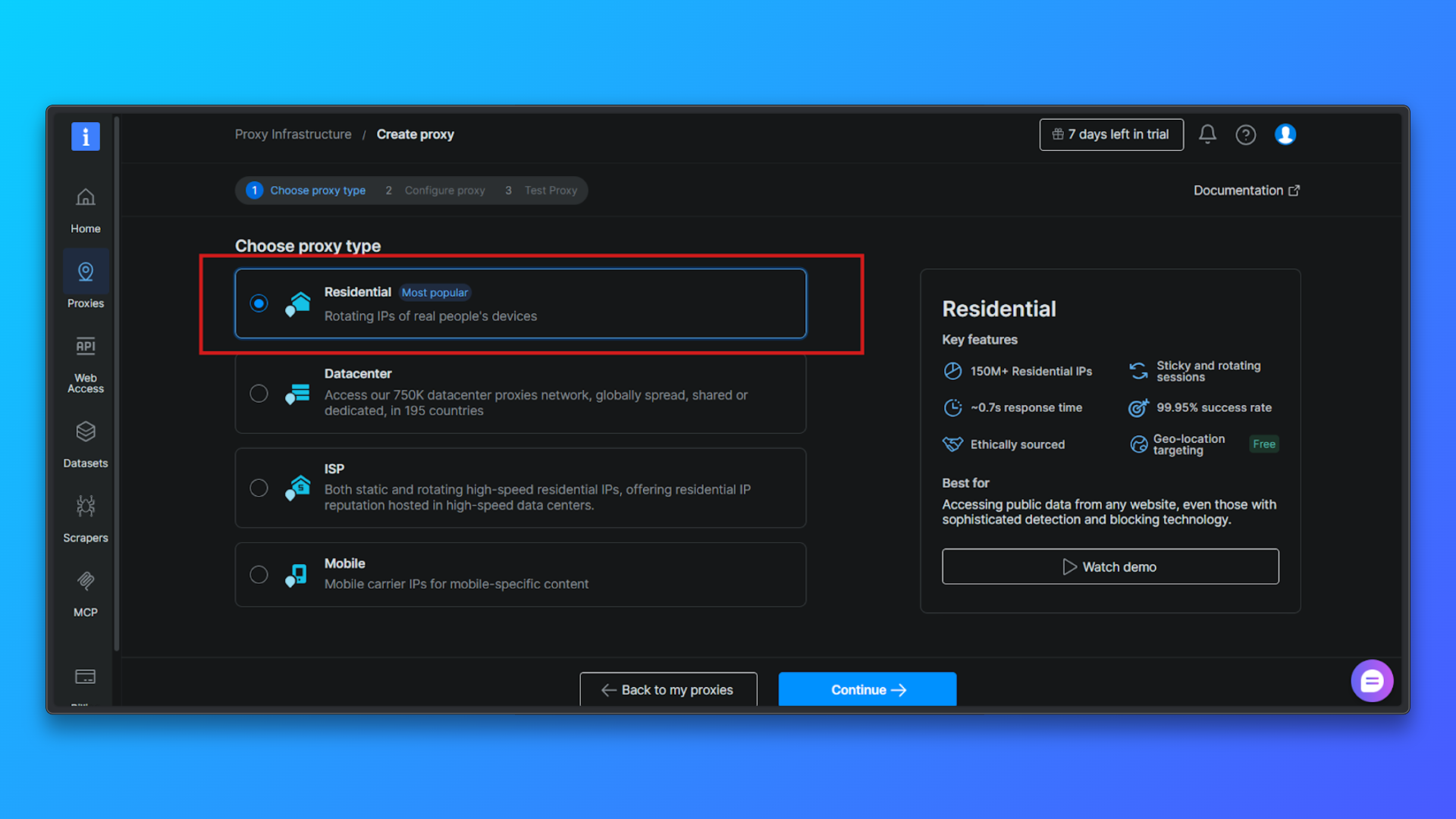
Configure el Proxy (opcional): puede configurar opcionalmente: orientación por país, comportamiento de la sesión, modo de acceso.
Para los principiantes, la configuración predeterminada es suficiente. Puede continuar sin cambiar las opciones avanzadas.
Haga clic en Continuar para crear la zona: confirme la configuración y complete la instalación. Bright Data creará una zona de Proxy residencial y le redirigirá a la página de resumen.
Revise las credenciales del Proxy en la pestaña Descripción general: En la pestaña Descripción general, verá:
- ID de cliente
- Nombre de la zona
- Nombre de usuario
- Contraseña
- Host y puerto del Proxy
- Modo de acceso
- Comando de terminal listo para usar
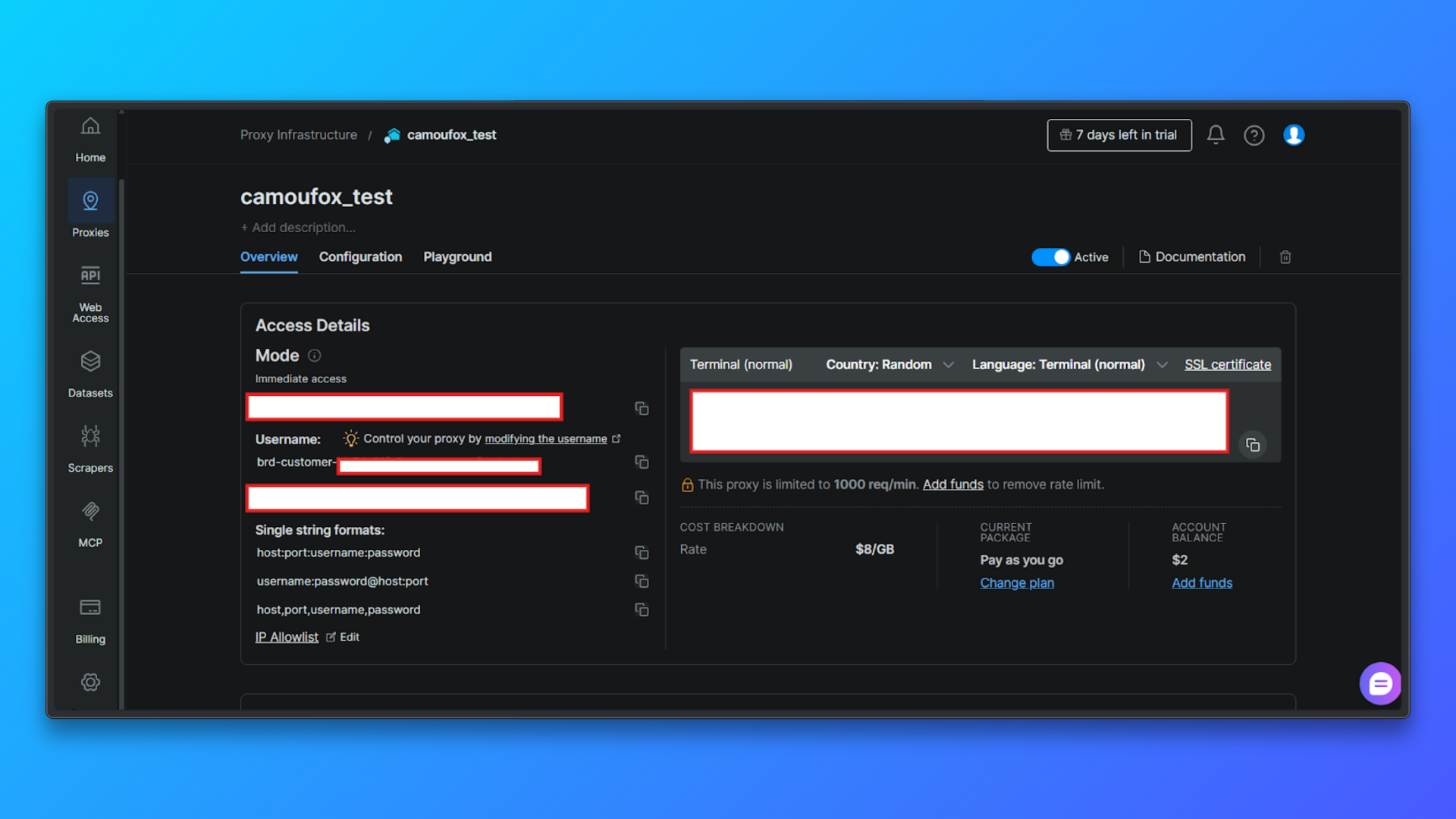
Estos valores se necesitarán más adelante al configurar los Proxies en el código.
Validar credenciales utilizando el comando de terminal: Copie el comando de terminal (curl) proporcionado en el panel de control y ejecútelo localmente.
Este comando envía una solicitud a través del Proxy al punto final de prueba de Bright Data y devuelve:
- Estado HTTP
- Respuesta del servidor
- Detalles de la IP asignada
- Información sobre el país, la ciudad y el ASN
Una respuesta satisfactoria confirma:
- Las credenciales del Proxy son válidas
- La autenticación funciona
- El enrutamiento de IPs residenciales está activo
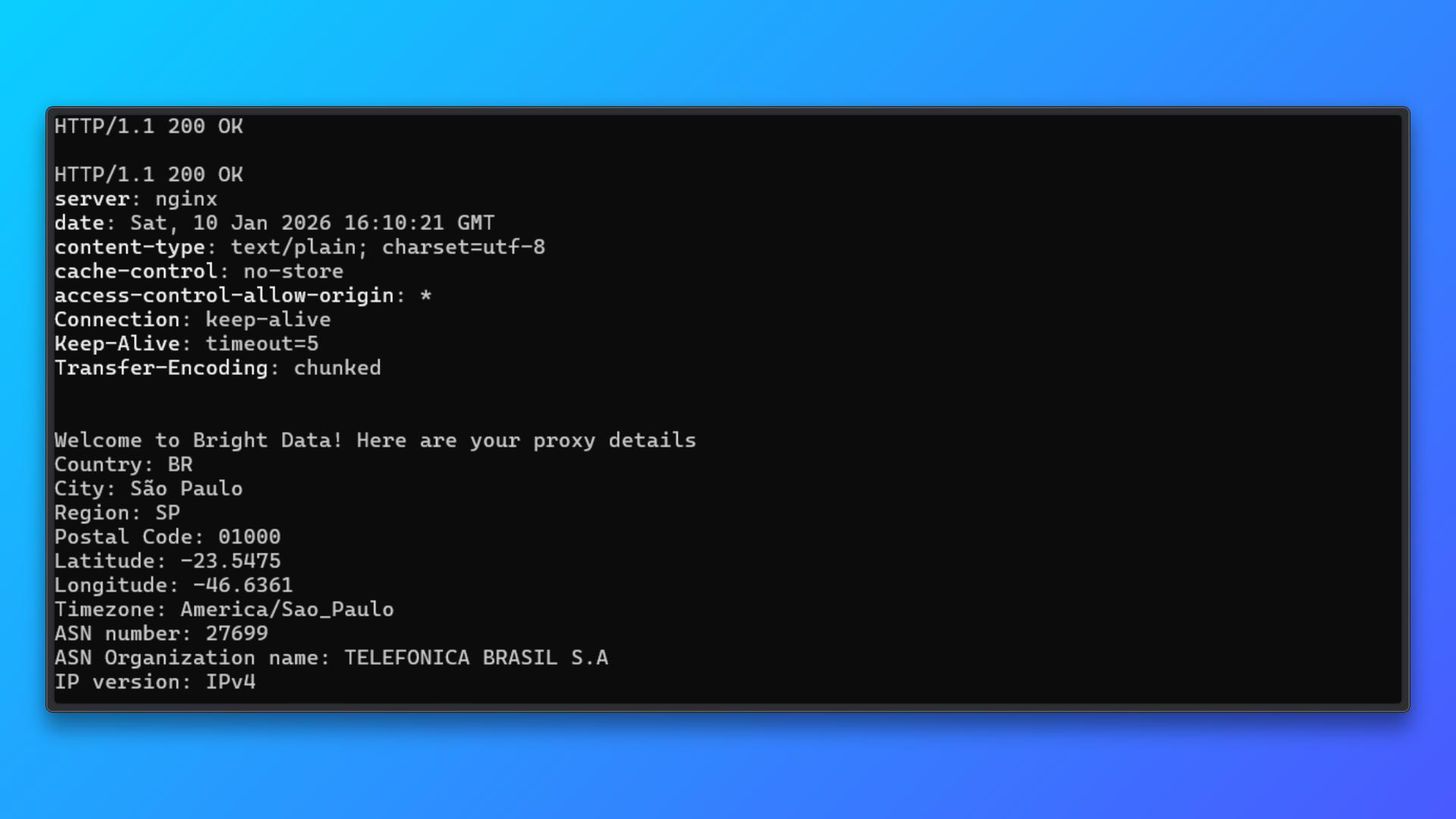
Este paso de validación aísla los problemas de configuración del Proxy antes de integrarlo en Camoufox o en cualquier código de scraping.
Bright Data permite el enrutamiento a nivel de país directamente a través del nombre de usuario. Esto significa que no es necesario gestionar las IP manualmente.
Camoufox puede alinear opcionalmente el comportamiento del navegador con la ubicación geográfica del Proxy utilizando geoip=True, lo que mejora la coherencia entre la ubicación de la IP y las señales del navegador.
Ejemplo de código: Camoufox + Bright Data
Ahora, configuremos los Proxies de Bright Data con Camoufox.
Paso 1: Importar Camoufox
from camoufox.sync_api import CamoufoxPaso 2: Definir la configuración del Proxy de Bright Data
Proxy = {
"server": "http://brd.superproxy.io:33335",
"username": "brd-customer-<CUSTOMER_ID>-Zona-<ZONE_NAME>-country-us",
"password": "<YOUR_PROXY_PASSWORD>",
}El servidorpermanece constante para Bright Data.- La selección del país se gestiona en el nombre de usuario.
- Las credenciales deben almacenarse de forma segura en variables de entorno para implementaciones reales.
Paso 3: Inicie Camoufox con el Proxy habilitado
con Camoufox(
Proxy=Proxy,
geoip=True,
headless=True,)
como navegador:
página = navegador.new_page(ignore_https_errors=True)
página.goto("https://example.com", wait_until="load")
print(página.title())Cuando el script se ejecuta correctamente, Camoufox inicia una instancia de Firefox sin interfaz gráfica de usuario enrutada a través del Proxy residencial de Bright Data. El navegador carga https://example.com e imprime el título de la página en la consola.
Salida
Estrategia de rotación de proxies
Bright Data gestiona la rotación de IP a nivel de red, pero el rastreo eficaz depende en gran medida de cómo se estructuran y reutilizan las sesiones a nivel del navegador. La rotación de proxies consiste en mantener un comportamiento de navegación realista en múltiples solicitudes.
Cuando se utilizan IPs residenciales de Bright Data, los flujos de trabajo de scraping suelen alcanzar alrededor del 92 % de cargas de página exitosas. Esto significa que la mayoría de las páginas se cargan completamente sin ser bloqueadas o interrumpidas. En comparación, las configuraciones de scraping similares que utilizan Proxies de centro de datos a menudo solo tienen éxito en alrededor del 50 % de los casos, especialmente en sitios web que utilizan huellas digitales, comprobaciones de reputación de IP o detección de comportamiento.
A continuación se presentan las estrategias de rotación más fiables para el Scraping web con Camoufox y Bright Data.
- Rotación basada en sesiones: en lugar de rotar la IP para cada solicitud, se reutiliza una única sesión del navegador para un número limitado de visitas a la página. Después de un umbral fijo, como visitar varias páginas o completar una tarea lógica, la sesión se cierra y se crea una nueva. Este enfoque refleja la forma en que los usuarios reales navegan por los sitios web y ayuda a mantener la coherencia en las cookies, los encabezados y los patrones de navegación. La rotación basada en sesiones logra un equilibrio entre el anonimato y el realismo, lo que la hace adecuada para la mayoría de las tareas de rastreo y scraping.
- Rotación basada en fallos: en esta estrategia, las sesiones solo se rotan cuando algo sale mal. Si una página no se carga, se agota el tiempo de espera o devuelve contenido inesperado, se descarta la sesión actual del navegador y se crea una nueva. Esto evita la rotación innecesaria durante las solicitudes exitosas, al tiempo que permite la recuperación de bloqueos o rutas de Proxy inestables. La rotación basada en fallos es especialmente útil para los rastreadores de larga duración en los que se espera una inestabilidad ocasional de la red.
- Enrutamiento específico por país: Bright Data permite el enrutamiento geográfico directamente a través del nombre de usuario del Proxy. Al incorporar un código de país en las credenciales de la sesión, las solicitudes se enrutan de forma coherente a través de direcciones IP de una región específica. Esto es útil para acceder a contenido bloqueado por región o para garantizar que las páginas localizadas devuelvan resultados correctos. Para obtener los mejores resultados, el comportamiento de geolocalización del navegador debe seguir alineado con el país del Proxy para evitar señales discordantes.
- Rastreo consciente de la velocidad: la rotación por sí sola no evita los bloqueos si las solicitudes se envían de forma demasiado agresiva. El rastreo consciente de la velocidad introduce pausas intencionadas entre las visitas a las páginas y evita los patrones de navegación rápidos. Incluso con IPs residenciales, el rastreo demasiado rápido puede parecer anormal. Los retrasos moderados, combinados con la reutilización de sesiones, producen patrones de tráfico que se asemejan mucho más al comportamiento real de los usuarios que la rotación agresiva y de alta frecuencia.
- Evite la rotación excesiva: la rotación de IP en cada solicitud rara vez es beneficiosa. La rotación excesiva puede crear patrones de tráfico poco naturales, aumentar la sobrecarga de la conexión y, en ocasiones, despertar sospechas en lugar de evitarlas. En la mayoría de los casos, la reutilización moderada de sesiones con una rotación controlada conduce a una mayor estabilidad y a mayores tasas de éxito a largo plazo.
Solución de problemas
- Errores SSL o HTTPS: pueden producirse errores como advertencias de certificados o emisores cuando el tráfico HTTPS se enruta a través de Proxies. Cree siempre páginas que ignoren los errores HTTPS para garantizar que la navegación se realice correctamente.
- Tiempo de espera de carga de la página: los Proxies residenciales pueden introducir una latencia adicional. Aumente el tiempo de espera de navegación y evite esperar a que se cargue toda la página si solo se necesita parte del contenido.
- Fallos en la autenticación del Proxy: compruebe que el nombre de usuario del Proxy sigue el formato requerido por Bright Data y que se están utilizando el puerto y la contraseña correctos. Asegúrese de que la zona del Proxy está activa en el panel de control.
- Ubicación o contenido lingüístico incorrectos: si las páginas devuelven contenido de una región inesperada, confirme que el enrutamiento por país está especificado correctamente en las credenciales del Proxy y que la alineación de la geolocalización está habilitada.
- CAPTCHAs frecuentes o bloqueos de acceso: esto suele indicar un comportamiento de scraping demasiado agresivo. Reduzca la frecuencia de las solicitudes, reutilice las sesiones de forma más eficaz y evite la carga paralela de páginas dentro de una misma instancia del navegador.
- Contenido de página inconsistente o parcial: algunas páginas cargan datos de forma dinámica. Utilice condiciones de espera adecuadas y compruebe que los elementos necesarios estén presentes antes de extraer el contenido.
- Fallos o desconexiones inesperadas del navegador: reinicie la sesión del navegador periódicamente y limite las sesiones de larga duración para evitar el agotamiento de los recursos durante los trabajos de scraping prolongados.
- Bright Data Web Unlocker: para los sitios en los que Cloudflare bloquea por completo la automatización del navegador, Bright Data’s Web Unlocker proporciona un bypass automático de Cloudflare sin necesidad de codificación, lo que elimina la necesidad de soluciones alternativas a nivel del navegador.
Proyecto de comercio electrónico en el mundo real: Scraping web con Camoufox (código completo)
Este proyecto muestra el scraping web basado en navegador con Camoufox en una página de categoría de comercio electrónico protegida por Cloudflare. El objetivo es extraer datos estructurados de productos en varias páginas, al tiempo que se gestionan los fallos de navegación y la paginación de forma controlada y repetible.
Este tipo de flujo de trabajo es común en el Monitoreo de precios, el análisis de catálogos y la Inteligencia competitiva.
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
import time
# Configuración del Proxy de Bright Data (enmascarado)
Proxy = {
"server": "http://brd.superproxy.io:33335",
"username": "brd-customer-<CUSTOMER_ID>-zona-<ZONA_NAME>-country-us",
"password": "<YOUR_PROXY_PASSWORD>",
}
results = []
with Camoufox(
Proxy=Proxy,
headless=True,
geoip=True,)
as browser:
# Crear una nueva página del navegador y permitir la interceptación HTTPS
page = browser.new_page(ignore_https_errors=True)
page.set_default_timeout(60000)
base_url = "https://books.toscrape.com/"
max_pages = 5
for page_number in range(1, max_pages + 1):
try:
print(f"Scraping page {page_number}")
# Navegar a la página
page.goto(
base_url,
wait_until="domcontentloaded"
)
# Localizar todas las fichas de productos
books = page.locator(".product_pod")
count = books.count()
if count == 0:
print("No se han encontrado productos, deteniendo el rastreo")
break
# Extraer datos de cada producto
for i in range(count):
book = books.nth(i)
title = book.locator("h3 a").get_attribute("title")
price = book.locator(".price_color").inner_text()
availability = book.locator(".availability").inner_text().strip()
results.append({
"title": title,
"price": price,
"availability": availability,
"page": page_number,
})
# Añadir un pequeño retraso para evitar patrones de solicitud agresivos
time.sleep(2)
except TimeoutError:
print(f"Tiempo de espera agotado en la página {page_number}, omitiendo")
continue
except Exception as e:
print(f"Error inesperado en la página {page_number}: {e}")
break
print(f"nSe han recopilado {len(results)} libros")
# Vista previa de algunos resultados
for item in results[:5]:
print(item)Camoufox lanza una instancia real del navegador Firefox, mientras que Bright Data proporciona IPs residenciales que se asemejan al tráfico real de los usuarios.
El script navega hasta el sitio web Books to Scrape, espera a que se cargue el DOM de la página y, a continuación, localiza cada ficha de producto en la página.
De cada lista de libros, extrae campos estructurados como el título, el precio y el estado de disponibilidad, y los almacena en una lista de Python para su posterior procesamiento.
El código también incluye mecanismos básicos de resiliencia necesarios para el scraping en el mundo real. Los tiempos de espera de navegación se gestionan con elegancia, los errores inesperados detienen el rastreo de forma segura y se añade un pequeño retraso entre las cargas de página para evitar patrones de tráfico agresivos.
Los errores de interceptación HTTPS se ignoran explícitamente, lo cual es necesario cuando se enruta el tráfico del navegador a través de Proxies que terminan las conexiones TLS.
Resultado:
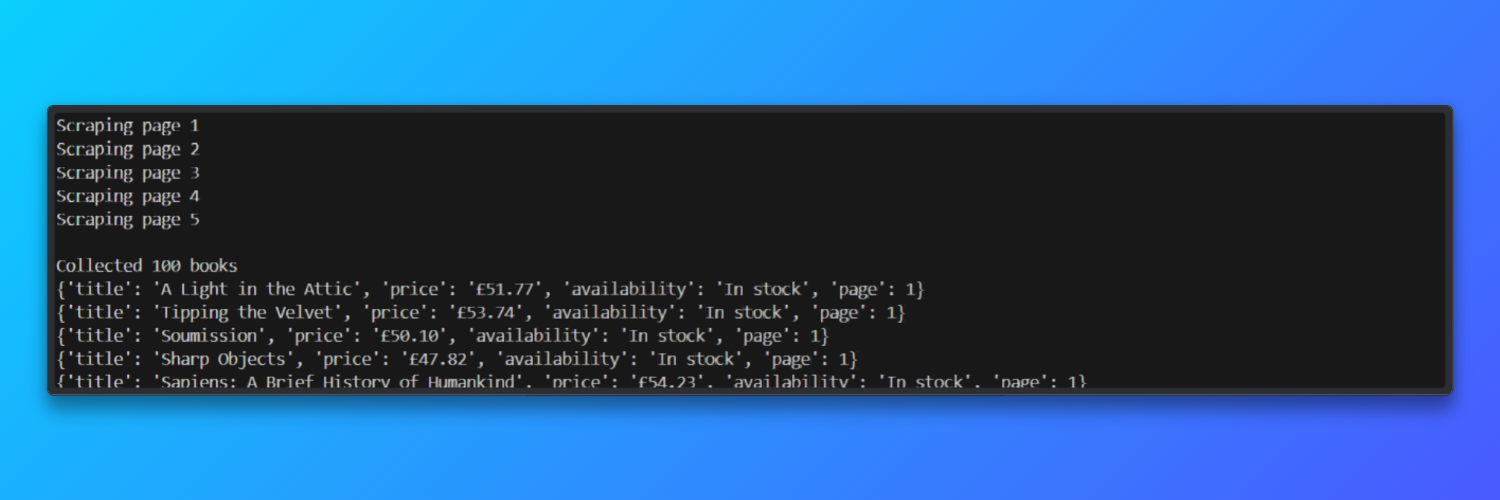
En las pruebas realizadas, el Scraper procesó cinco páginas paginadas en aproximadamente 45 segundos y alcanzó una tasa de éxito en la carga de páginas de alrededor del 92 % al utilizar Proxies residenciales de Bright Data.
Puntos de referencia de rendimiento y limitaciones
En esta sección se resumen el rendimiento medido, las limitaciones prácticas y las implicaciones de escalabilidad observadas al utilizar Camoufox con Proxies residenciales, y cómo esas limitaciones determinan el siguiente paso arquitectónico.
Puntos de referencia medidos (observados)
- Robustez de la huella digital: Camoufox obtiene una puntuación superior al 70 % en las pruebas de CreepJS, lo que indica una fuerte resistencia a las comprobaciones habituales de huellas digitales de los navegadores para una herramienta de código abierto.
- Huella de memoria: ~200 MB de RAM por instancia de navegador, lo que limita directamente el escalado horizontal en servidores típicos.
- Duración de la sesión: las cookies caducan cada 30-60 minutos, lo que requiere una actualización manual o el reinicio de la sesión para mantener el acceso.
- Tasa de éxito por deterioro temporal: ~92 % en la hora 1 → ~40 % en la hora 2 → ~10 % en la hora 3 a medida que las sesiones envejecen y los sistemas de detección se adaptan.
- Contraste de infraestructura: Bright Data proporciona más de 175 millones de direcciones IP, un tiempo de actividad del 99,95 % y 0 horas de mantenimiento por parte del usuario.
Limitaciones observadas a gran escala
A medida que el Scraping web con Camoufox se prolonga o se amplía, se hacen evidentes varias limitaciones:
- Caducidad de la sesión: las cookies suelen caducar en un plazo de 30 a 60 minutos, lo que requiere una actualización manual o el reinicio del navegador para mantener el acceso.
- Uso de memoria: cada instancia del navegador consume aproximadamente 200 MB de RAM, lo que limita la concurrencia en los servidores estándar.
- Límite de concurrencia: en un servidor de 8 GB, los límites prácticos son de unas 30 instancias de navegador simultáneas antes de que la estabilidad se vea afectada.
- Disminución de la fiabilidad con el tiempo: las tasas de éxito disminuyen notablemente a medida que las sesiones envejecen: ~92 % en la primera hora, ~40 % en la segunda hora y ~10 % en la tercera hora sin intervención.
- Sobrecarga operativa: para mantener resultados consistentes, normalmente se requieren entre 20 y 30 horas al mes de mantenimiento y ajuste activos.
Para los equipos que necesitan trabajos de larga duración o un tiempo de actividad predecible, estas limitaciones desplazan el foco de la lógica de scraping a la gestión de la infraestructura.
En esta etapa, las soluciones gestionadas se convierten en una alternativa práctica. La infraestructura de Bright Data ofrece más de 175 millones de IPs residenciales, un tiempo de actividad del 99,95 % y elimina la necesidad de gestionar manualmente las cookies y las sesiones.
En entornos de producción, esto suele traducirse en un éxito constante superior al 99 %, sin la degradación gradual que se observa en la automatización de navegadores autogestionada.
Cuando se incluyen el tiempo de mantenimiento y los costes de infraestructura, las configuraciones gestionadas suelen reducir el coste mensual total en comparación con los enfoques DIY. (1200 $/mes frente a 2850 $ DIY (incluido el mantenimiento)).
Camoufox vs Puppeteer vs Bright Data (tabla comparativa)
La siguiente tabla compara Camoufox con los Proxies residenciales de Bright Data, Puppeteer y el Navegador de scraping de Bright Data en función de los factores más importantes en proyectos de scraping reales.
| Característica | Camoufox + Proxies de Bright Data | Puppeteer | Bright Data Scraping Browser |
|---|---|---|---|
| Tasa de éxito | ~92 % de éxito con Proxies residenciales | ~15-30 % en sitios protegidos | Más del 99 % de éxito constante |
| Esfuerzo de configuración | Configuración media con ajuste de Proxy y huella digital | Configuración alta con parches y complementos | Configuración baja, listo para usar |
| Gestión de cookies | Actualización manual cada 30-60 minutos | Gestión totalmente manual | Gestión automática de cookies |
| Límite de escalabilidad | ~30 navegadores simultáneos por servidor | ~50 navegadores simultáneos | Escalabilidad ilimitada |
| Mantenimiento / Mes | 20-30 horas de mantenimiento continuo | 40-60 horas de mantenimiento | 0 horas necesarias |
| Coste (1 millón de solicitudes) | ~2850 $, incluido el uso de Proxy | ~2500 $ más tiempo de ingeniería | ~1200 $ de coste total |
Cuándo migrar a Bright Data
El navegador Camoufox, que evita los antibots, es una buena opción para crear flujos de trabajo de scraping en fases iniciales, pero no está diseñado para un uso productivo sostenido y de gran volumen.
A medida que los proyectos crecen, la caducidad de las cookies cada 30-60 minutos, la disminución de las tasas de éxito a largo plazo y la necesidad de reiniciar el navegador con frecuencia introducen una sobrecarga operativa.
El scraping web con Camoufox requiere una tasa de éxito constante superior al 99 %, una concurrencia superior a ~30 navegadores por servidor y un rendimiento predecible sin necesidad de ajustes continuos, por lo que migrar a Bright Data se convierte en el siguiente paso práctico.
Las soluciones de scraping gestionadas de Bright Data se encargan automáticamente de las huellas digitales del navegador, la persistencia de la sesión, los reintentos y el escalado, lo que elimina el mantenimiento manual y estabiliza los procesos de larga duración.
Conclusiones
Esta guía ha mostrado cómo funciona en la práctica el Scraping web con Camoufox, en qué aspectos destaca y cuáles son sus limitaciones. Camoufox, junto con los Proxies residenciales, es muy adecuado para la creación de prototipos, la experimentación y la comprensión de los sistemas modernos de detección de bots.
Para entornos de producción en los que la fiabilidad, la escala y la rentabilidad son importantes, una infraestructura de scraping gestionada como BrightData ofrece una vía operativa más clara.
Si su configuración de Camoufox Python ya es funcional pero requiere reinicios frecuentes, restablecimientos de sesión o ajustes de Proxy, el factor limitante es la infraestructura y no la lógica de scraping.
Explore los Proxies residenciales y el Navegador de scraping de Bright Data para reducir el esfuerzo de mantenimiento y lograr resultados estables y de calidad de producción a gran escala.
Además, el navegador de scraping de Bright Data actúa como una alternativa a Camoufox a escala de producción, ya que gestiona automáticamente las huellas digitales, la persistencia de las sesiones y los reintentos.
En general, se trata de una de las redes de Proxies orientadas al scraping más grandes, rápidas y fiables del mercado.
¡Regístrese ahora y comience su prueba gratuita de Proxy!






