

Perles uno de los lenguajes más populares y, gracias a su amplia colección de módulos, es una excelente opción para escribir Scrapers web.
En este artículo, trataremos lo siguiente:
- Cómo realizar Scraping web con Perl utilizando los siguientes métodos:
LWP::UserAgentyHTML::TreeBuilderWeb::ScraperMojo::UserAgentyMojo::DOMXML::LibXML
- Retos del scraping web con Perl
- Conclusión
Scraping web con Perl
Para seguir el artículo, asegúrate de tener instalada la última versión de Perl. El código de este artículo se ha probado con Perl 5.38.2. Este artículo también da por supuesto que sabes cómoinstalar módulos de Perl utilizandocpanm.
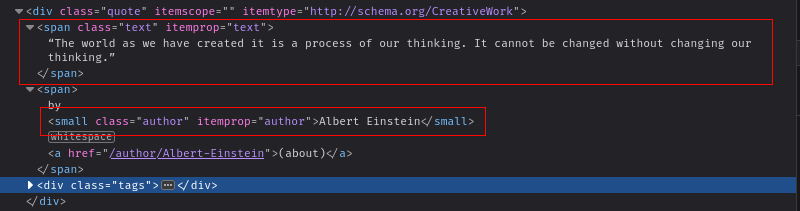
En este artículo, extraerá las citas delsitio web Quotes to Scrape. Antes de poder extraer datos del sitio web, debe comprender cómo está estructurado el HTML. Abra el sitio web en el navegador y presioneCTRL + Mayús + I(Windows) oComando + Mayús + C(Mac) para abrir el cuadro de diálogoInspeccionar elemento.
Al inspeccionar los elementos, verás que cada cita se almacena en undivcon la clasequote. Cada cita contiene unspancon la clasetexty unpequeñoelemento para almacenar el texto y el nombre del autor, respectivamente:
Uso de LWP::UserAgent y HTML::TreeBuilder
LWP::UserAgentforma parte deLWP, un grupo de módulos que interactúan con la web. El móduloLWP::UserAgentse puede utilizar para realizar una solicitud HTTP a una página web y devolver el contenido HTML. A continuación, puede utilizar el móduloHTML::TreeBuilderdeHTML::Treepara realizar el parseo del HTML y extraer información.
Para utilizar LWP::UserAgent y HTML::TreeBuilder, instale los módulos con los siguientes comandos:
cpanm Bundle::LWP
cpanm HTML::Tree
Cree un archivo llamado lwp-and-tree-builder.pl. Aquí es donde escribirá el código. A continuación, pegue las dos líneas siguientes en ese archivo:
use LWP::UserAgent;
use HTML::TreeBuilder;
Este código indica al intérprete de Perl que incluya los módulos LWP::UserAgent y HTML::TreeBuilder.
Defina una instancia de LWP::UserAgent y establezca el encabezado User-Agent en Quotes Scraper:
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
Defina la URL del sitio web de destino y cree una instancia de HTML::TreeBuilder:
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
Ahora puede realizar la solicitud HTTP:
my $request = $ua->get($url) or die "Se ha producido un error $!n";
Pega la siguiente instrucción if-else que comprueba si la solicitud se ha realizado correctamente o no:
if ($request->is_success) {
} else {
print "No se puede realizar el parseo del resultado. " . $request->status_line . "n";
}
Si la solicitud se ha realizado correctamente, puede comenzar a extraer datos.
Utilice el método parse de HTML::TreeBuilder para realizar el parseo de la respuesta HTML. Pegue el siguiente código dentro del bloque if:
$root->parse($request->content);
Ahora, utilice el método look_down para buscar los elementos div con la clase quote:
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
Itere sobre la matriz de citas, utilice look_down para encontrar el texto y el autor, y imprímalos:
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
El código completo tiene este aspecto:
use LWP::UserAgent;
use HTML::TreeBuilder;
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $ua->get($url) or die "Se ha producido un error $!n";
if ($request->is_success) {
$root->parse($request->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
} else {
print "No se puede realizar el parseo del resultado. " . $request->status_line . "n";
}
Ejecute este código con perl lwp-and-tree-builder.pl y debería ver el siguiente resultado:
«El mundo tal y como lo hemos creado es un proceso de nuestro pensamiento. No se puede cambiar sin cambiar nuestro pensamiento».: Albert Einstein
«Son nuestras elecciones, Harry, las que muestran lo que realmente somos, mucho más que nuestras habilidades».: J.K. Rowling
«Solo hay dos formas de vivir la vida. Una es como si nada fuera un milagro. La otra es como si todo fuera un milagro».: Albert Einstein
«La persona, ya sea caballero o dama, que no disfruta de una buena novela, debe ser intolerablemente estúpida»: Jane Austen.
«La imperfección es belleza, la locura es genio y es mejor ser absolutamente ridículo que absolutamente aburrido»: Marilyn Monroe.
«Intenta no convertirte en un hombre de éxito. Más bien, conviértete en un hombre de valor»: Albert Einstein.
«Es mejor ser odiado por lo que eres que ser amado por lo que no eres»: André Gide
«No he fracasado. Solo he encontrado 10 000 formas que no funcionan»: Thomas A. Edison
«Una mujer es como una bolsita de té: nunca sabes lo fuerte que es hasta que la sumerges en agua caliente»: Eleanor Roosevelt.
«Un día sin sol es como, ya sabes, la noche»: Steve Martin.
Uso de Web::Scraper
Web::Scraperes una biblioteca de Scraping web inspirada enScrAPI de Ruby. Proporciona un lenguaje específico de dominio (DSL) para extraer documentos HTML y XML. Consulte este artículo para obtener más información sobre el Scraping web con Ruby.
Para utilizar Web::Scraper, instala el módulo con cpanm Web::Scraper.
Crea un nuevo archivo llamado web-scraper.pl e incluye los siguientes módulos necesarios:
use URI;
use Web::Scraper;
use Encode;
A continuación, debe definir un bloque de Scraper utilizando el DSL del módulo. El DSL facilita la definición de un Scraper en solo unas pocas líneas. Comience definiendo un bloque de Scraper llamado $quotes:
my $quotes = Scraper {
};
El método Scraper define la lógica del Scraper, que se ejecuta cuando se llama al método scrape más adelante. Dentro del bloque Scraper, utiliza el método process para buscar elementos utilizando selectores CSS y ejecutar una función.
Comience por buscar todos los elementos div con la clase quote:
# Analizar todos los `div` con la clase `quote`
process 'div.quote', "quotes[]" => Scraper {
};
Este código busca todos los elementos div con la clase quote y los almacena en la matriz quotes. Para cada elemento, ejecuta el método Scraper, que se define de la siguiente manera:
# Y, en cada div, busca `span` con la clase `text`
process_first "span.text", text => 'TEXT';
# obtén `small` con la clase `author`
process_first "small", author => 'TEXT';
El método process_first encuentra el primer elemento que coincide con el selector CSS. Aquí, se busca el primer elemento span con la clase text y, a continuación, se extrae su texto y se almacena en la clave text. Para el nombre del autor, se busca el primer elemento small y se extrae el texto para almacenarlo en la clave author.
El bloque completo del Scraper tiene este aspecto:
my $quotes = Scraper {
# Analizar todos los `div` con clase `quote`
process 'div.quote', "quotes[]" => Scraper {
# Y, en cada div, buscar `span` con clase `text`
process_first "span.text", text => 'TEXT';
# obtener `small` con la clase `author`
process_first "small", author => 'TEXT';
};
};
Ahora, llama al método scrape y pasa la URL para iniciar el rastreo:
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
Por último, itera sobre la matriz de citas e imprime el resultado:
# iterar sobre la matriz
for my $quote (@{$res->{quotes}}) {
print Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}
El código completo tiene este aspecto:
use URI;
use Web::Scraper;
use Encode;
my $quotes = scraper {
# Analizar todos los `div` con la clase `quote`
process 'div.quote', "quotes[]" => scraper {
# Y, en cada div, buscar `span` con la clase `text`
process_first "span.text", text => 'TEXT';
# obtener `small` con clase `author`
process_first "small", author => 'TEXT';
};
};
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
# iterar sobre la matriz
for my $quote (@{$res->{quotes}}) {
print Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}
Ejecute el código anterior con perl web-scraper.pl y debería obtener el siguiente resultado:
«El mundo tal y como lo hemos creado es un proceso de nuestro pensamiento. No se puede cambiar sin cambiar nuestro pensamiento».: Albert Einstein
«Son nuestras elecciones, Harry, las que muestran lo que realmente somos, mucho más que nuestras habilidades».: J.K. Rowling
«Solo hay dos formas de vivir la vida. Una es como si nada fuera un milagro. La otra es como si todo fuera un milagro».: Albert Einstein
«La persona, ya sea caballero o dama, que no disfruta de una buena novela, debe ser intolerablemente estúpida»: Jane Austen.
«La imperfección es belleza, la locura es genio y es mejor ser absolutamente ridículo que absolutamente aburrido»: Marilyn Monroe.
«Intenta no convertirte en un hombre de éxito. Más bien, conviértete en un hombre de valor»: Albert Einstein.
«Es mejor ser odiado por lo que eres que ser amado por lo que no eres»: André Gide
«No he fracasado. Solo he encontrado 10 000 formas que no funcionan»: Thomas A. Edison
«Una mujer es como una bolsita de té: nunca sabes lo fuerte que es hasta que la sumerges en agua caliente»: Eleanor Roosevelt
«Un día sin sol es como, ya sabes, la noche»: Steve Martin
Uso de Mojo::UserAgent y Mojo::DOM
Mojo::UserAgentyMojo::DOMforman parte del marcoMojolicious, un marco web en tiempo real para Perl. En términos de funcionalidad, son similares aLWP::UserAgentyHTML::TreeBuilder.
Para utilizar Mojo::UserAgent y Mojo::DOM, instala los módulos con el siguiente comando:
cpanm Mojo::UserAgent
cpanm Mojo::DOM
Cree un nuevo archivo llamado mojo.pl e incluya los módulos Mojo::USeragent y Mojo::DOM:
use Mojo::UserAgent;
use Mojo::DOM;
Defina una instancia de Mojo::UserAgent y realice la solicitud HTTP:
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
De forma similar a LWP::UserAgent, utilice el siguiente bloque if-else para comprobar si la solicitud se ha realizado correctamente:
if ($res->is_success) {
} else {
print "No se puede realizar el parseo del resultado. " . $res->message . "n";
}
En el bloque if, inicializa una instancia de Mojo::DOM:
my $dom = Mojo::DOM->new($res->body);
Utilice el método find para buscar todos los elementos div con la clase quote:
my @quotes = $dom->find('div.quote')->each;
Iterar sobre la matriz de citas y extraer el texto y los nombres de los autores:
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}
El siguiente es el código completo:
use Mojo::UserAgent;
use Mojo::DOM;
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
if ($res->is_success) {
my $dom = Mojo::DOM->new($res->body);
my @quotes = $dom->find('div.quote')->each;
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}
} else {
print "No se puede realizar el parseo del resultado. " . $res->message . "n";
}
Ejecute este código con perl mojo.pl y debería obtener el siguiente resultado:
«El mundo tal y como lo hemos creado es un proceso de nuestro pensamiento. No se puede cambiar sin cambiar nuestra forma de pensar»: Albert Einstein.
«Son nuestras elecciones, Harry, las que muestran lo que realmente somos, mucho más que nuestras habilidades»: J. K. Rowling.
«Solo hay dos formas de vivir la vida. Una es como si nada fuera un milagro. La otra es como si todo fuera un milagro»: Albert Einstein.
«La persona, ya sea caballero o dama, que no disfruta de una buena novela, debe ser intolerablemente estúpida»: Jane Austen.
«La imperfección es belleza, la locura es genio y es mejor ser absolutamente ridículo que absolutamente aburrido»: Marilyn Monroe.
«Intenta no convertirte en un hombre de éxito. Más bien, conviértete en un hombre de valor»: Albert Einstein.
«Es mejor ser odiado por lo que eres que ser amado por lo que no eres»: André Gide
«No he fracasado. Solo he encontrado 10 000 formas que no funcionan»: Thomas A. Edison
«Una mujer es como una bolsita de té: nunca sabes lo fuerte que es hasta que la sumerges en agua caliente»: Eleanor Roosevelt.
«Un día sin sol es como, ya sabes, la noche»: Steve Martin.
Uso de XML::LibXML
El módulo PerlXML::LibXMLes un envoltorio de la bibliotecalibxml2. El móduloXML::LibXMLproporciona un potente analizador XHTML con capacidadesXPath.
Utiliza cpanm para instalar el módulo:
cpanm XML::LibXML
A continuación, crea un nuevo archivo llamado xml-libxml.pl. Al igual que con HTML::TreeBuilder, necesitas utilizar una biblioteca como LWP::UserAgent para realizar la solicitud HTTP al sitio web y obtener el contenido HTML, que pasas a XML::LibXML.
Pegue el siguiente código, que configura el módulo LWP:UserAgent y obtiene el contenido HTML de la página web:
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "Se ha producido un error $!n";
if ($request->is_success) {
} else {
print "No se puede realizar el Parseo del resultado. " . $request->status_line . "n";
}
Dentro del bloque if, comience realizando el parseo del documento HTML utilizando el método load_html:
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
La opción recover le indica al analizador que continúe analizando el HTML en caso de error, y la opción suppress_errors hace que el analizador no imprima los errores de parseo HTML en la consola. Dado que los documentos HTML no se validan tan estrictamente como los documentos XHTML, es probable que encuentres errores de parseo no fatales. Estas opciones mantienen el código en funcionamiento en caso de que se produzcan esos errores.
Una vez realizado el parseo del HTML, puede utilizar el método indnodes para buscar los elementos basándose en su expresión XPath:
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}
El código completo tiene este aspecto:
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "Se ha producido un error $!n";
if ($request->is_success) {
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}
} else {
print "No se puede realizar el parseo del resultado. " . $request->status_line . "n";
}
Ejecute el código con perl xml-libxml.pl y debería ver el siguiente resultado:
«El mundo tal y como lo hemos creado es un proceso de nuestro pensamiento. No se puede cambiar sin cambiar nuestra forma de pensar».: Albert Einstein
«Son nuestras elecciones, Harry, las que muestran lo que realmente somos, mucho más que nuestras habilidades».: J.K. Rowling
«Solo hay dos formas de vivir la vida. Una es como si nada fuera un milagro. La otra es como si todo fuera un milagro».: Albert Einstein
«La persona, ya sea caballero o dama, que no disfruta de una buena novela, debe ser intolerablemente estúpida»: Jane Austen.
«La imperfección es belleza, la locura es genio y es mejor ser absolutamente ridículo que absolutamente aburrido»: Marilyn Monroe.
«Intenta no convertirte en un hombre de éxito. Más bien conviértete en un hombre de valor»: Albert Einstein.
«Es mejor ser odiado por lo que eres que ser amado por lo que no eres»: André Gide
«No he fracasado. Solo he encontrado 10 000 formas que no funcionan»: Thomas A. Edison
«Una mujer es como una bolsita de té: nunca sabes lo fuerte que es hasta que la sumerges en agua caliente»: Eleanor Roosevelt.
«Un día sin sol es como, ya sabes, la noche»: Steve Martin.
Puedes encontrar todo el código de este tutorial en esterepositorio de GitHub.
Retos del Scraping web en Perl
Aunque Perl facilita el scraping web gracias a sus potentes módulos, los desarrolladores suelen encontrarse con algunos problemas comunes que pueden ralentizar o impedir por completo el Scraping web. A continuación se enumeran algunos de los retos a los que es probable que te enfrentes.
Manejo de la paginación
Los sitios web que manejan un gran volumen de datos no suelen enviar todos los datos de una sola vez. Por lo general, los datos se envían en varias páginas, y es necesario manejar la paginación para asegurarse de extraer todos los datos. Hay dos pasos para manejar la paginación:
- Compruebe si existen otras páginas. Por lo general, puede buscar un botón«Página siguiente»en la página, o puede intentar cargar la página siguiente y buscar un error.
- Si existen otras páginas, cargue la página siguiente y extraiga los datos.
En el caso de los sitios web estáticos, en los que cada página tiene su propia URL, puede ejecutar un bucle y cargar nuevas páginas incrementando el parámetro de número de página en la URL. O si utiliza un módulo comoWWW::Mechanize, simplemente puede seguir la URLde la página siguiente.
Aquí tienes el Scraper de citas modificado para gestionar la paginación utilizando WWW::Mechanize. Ten en cuenta el uso de follow_link:
use WWW::Mechanize ();
use HTML::TreeBuilder;
use open qw( :std :encoding(UTF-8) );
my $mech = WWW::Mechanize->new();
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $mech->get($url);
my $next_page = $mech->find_link(text_regex => qr/Next/);
while ($next_page) {
$root->parse($mech->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
$mech->follow_link(url => $next_page->url);
$next_page = $mech->find_link(text_regex => qr/Next/);
}
Para gestionar sitios web dinámicos que cargan la página siguiente utilizando JavaScript, consulte nuestra guía sobrecómo extraer datos de sitios web dinámicos con Python, o continúe leyendo.
Proxy rotativo
Los proxies son utilizados habitualmente por los scrapers web para proteger su privacidad y anonimato y para evadir las prohibiciones de direcciones IP. Módulos comoLWP::UserAgenttienen la opción de configurar proxies para el scraping. Sin embargo, el uso de un único servidor proxy sigue entrañando el riesgo de que la IP sea prohibida. Por eso se recomienda utilizar varios servidores proxy y rotarlos. A continuación se muestra un ejemplo muy sencillo de cómo hacerlo utilizandoLWP::UserAgent.
Comience por definir una matriz de Proxies. A continuación, elija uno al azar y configure el Proxy utilizando el método Proxy:
my @proxies = ( 'https://proxy1.com', 'https://proxy2.com', 'http://proxy3.com' );
my $index = rand @proxies;
my $proxy = $proxies[$index];
$ua->proxy(['http', 'https'], $proxy);
Ahora puede enviar una solicitud como de costumbre. Si la solicitud falla, es probable que el Proxy haya sido bloqueado, por lo que puede eliminar ese Proxy de la lista, elegir otro diferente y volver a intentarlo:
if(request->is_success) {
# Continúa con el rastreo
} else {
# Elimina el Proxy de la lista
splice(@proxies, $index, 1);
# Vuelve a intentarlo
}
Manejo de trampas honeypot
Las trampas honeypotson una técnica común empleada por los administradores web para atrapar bots y Scrapers. Por lo general, utilizan enlaces con la propiedadde visualizaciónestablecida ennone, lo que los hace invisibles para los usuarios humanos. Sin embargo, un bot puede detectarlos y seguir el enlace, lo que le lleva a una página web señuelo y le aleja del producto principal.
Para solucionar este problema, comprueba la propiedad de visualización de los enlaces antes de seguirlos. A continuación se muestra una forma de hacerlo utilizando HTML::TreeBuilder:
my @links = $root->look_down(
_tag => 'a',
);
foreach my $link (@qlinks) {
my $style = $link->attr('style');
if(defined $style && $style =~ /dislay: none/) {
# ¡Se ha detectado un honeypot!
} else {
# Se puede continuar con seguridad
}
}
Resolución de CAPTCHA
Los CAPTCHA ayudan a evitar el acceso no autorizado a un sitio web. Sin embargo, también pueden impedir que los Scrapers recopilen información de las páginas web.
Para combatir los CAPTCHAs, puede utilizar un servicio como Bright Data Web Unlocker, que realiza la resolución de CAPTCHA por usted.
A continuación se muestra un ejemplo del uso de Bright Data Web Unlocker para realizar una solicitud HTTP:
use LWP::UserAgent;
my $agent = LWP::UserAgent->new();
$agent->Proxy(['http', 'https'], "http://brd-customer-hl_6d74fc42-zona-residential_proxy4:[email protected]:22225");
print $agent->get('http://lumtest.com/myip.json')->content();
Cuando realizas una solicitud HTTP con Web Unlocker, este realiza la resolución de CAPTCHA, evita las medidas antibots y se encarga de la gestión del Proxy por ti.
Rastreo de sitios web dinámicos
Hasta ahora, todos los ejemplos que has aprendido aquí extraen datos de sitios web estáticos. Sin embargo, las aplicaciones de página única (SPA) y otros sitios web dinámicos necesitan técnicas más avanzadas.
Los sitios web dinámicos utilizan JavaScript para cargar el contenido de la página, lo que significa que necesitas herramientas de scraping que sean capaces de ejecutar JavaScript.Seleniumes una de esas herramientas que puede emular un navegador para ejecutar sitios web dinámicos. A continuación se muestra un pequeño fragmento de código de este módulo en acción:
use Selenium::Remote::Driver;
my $driver = Selenium::Remote::Driver->new;
$driver->get('http://example.com');
my $elem = $driver->find_element_by_id('foo');
print $elem->get_text();
$driver->quit();
Conclusión
Perl, gracias a su robusta colección de módulos, es un lenguaje excelente para el Scraping web. En este artículo, has aprendido a extraer datos de páginas web en Perl utilizando lo siguiente:
LWP::UserAgentyHTML::TreeBuilderWeb::ScraperMojo::UserAgentyMojo::DOMXML::LibXML
Sin embargo, como has visto, el scraping web se enfrenta a muchos retos en situaciones reales cuando los propietarios de sitios web están decididos a impedir que los Scrapers realicen scraping. Este artículo ha arrojado algo de luz sobre algunas situaciones comunes y cómo combatirlas. Sin embargo, intentar resolver esos retos por tu cuenta puede resultar tedioso y propenso a errores. Ahí es dondeBright Datapuede ayudar. Con los mejores servicios de Proxy, unNavegador de scraping,un Web Unlocker y la API de scraping web definitiva, Bright Data es una solución integral para realizar scraping web con facilidad. ¡Comience hoy mismo una prueba gratuita!





