

En esta guía sobre XPath frente a CSS Selector, aprenderá:
- Qué son las expresiones XPath, cómo funcionan y sus ventajas e inconvenientes.
- Qué son los selectores CSS, cómo funcionan y sus pros y contras.
- Cómo se comparan las expresiones XPath y los selectores CSS en cuanto a rendimiento, simplicidad y casos de uso.
¡Es hora de profundizar!
XPath: análisis completo
Comencemos esta guía comparativa entre XPath y los selectores CSS profundizando en el primer elemento de la comparación, XPath.
Definición
XPath, abreviatura de XML Path Language, es un lenguaje de consulta para navegar y consultar el DOM. En concreto, proporciona una forma potente de localizar y extraer información de documentos XML/HTML.
XPath tiene una sintaxis similar a la de un sistema de archivos, que se basa en expresiones para localizar nodos en el árbol XML/HTML. Una expresión XPath define la ruta a elementos y atributos específicos dentro de la estructura jerárquica del documento.
Sintaxis
A continuación se muestra un desglose de los componentes clave de la sintaxis de XPath:
/: Para comenzar a seleccionar nodos desde el nodo raíz.//: Para seleccionar nodos en el documento desde el nodo actual que coincidan con la selección, independientemente de su ubicación..:Para seleccionar el nodo actual...: Para seleccionar el padre del nodo actual.@: Para seleccionar atributos de nodos.element: Para seleccionar nodos basados en una etiqueta específica (por ejemplo,div).[condición]: Para seleccionar nodos basados en una condición especificada (por ejemplo,[@type="submit"]).función(): Para aplicar una función XPath específica a la expresión (por ejemplo,text()devuelve el contenido de texto del nodo seleccionado).
Algunos ejemplos para comprender mejor la sintaxis de XPath son:
//a: Selecciona todos los elementos<a>del documento.//ul/li: Selecciona todos los elementos<li>que son hijos de elementos<ul>.//ul/..: Selecciona todos los nodos padres de los elementos<ul>.//ul/li[@category='fiction']: Selecciona todos los elementos<il>bajo las etiquetas<ul>con un atributode categoríaigual a«fiction».//title[@lang='en']: Selecciona todos los elementos<title>con un atributolangigual a«en»en cualquier parte del documento.- //title/text(): Recupera el contenido de texto de todos los elementos
<title>del documento. //div[contains(@class, 'post')]/following-sibling::div[1]: Selecciona el primer elemento<div>que sea hermano de cada elemento<div>que contenga la clase«post».
Tenga en cuenta que las expresiones XPath también admiten operadores booleanos y aritméticos para combinar múltiples funciones y condiciones.
Ventajas
- Gran versatilidad: permite navegar tanto por estructuras XML como HTML, lo que permite seleccionar con precisión elementos, atributos y nodos de texto. También admite el recorrido hacia adelante y hacia atrás del DOM, así como la selección de nodos padres y hermanos.
- Numerosas funciones y operadores: incluye un amplio conjunto de funciones integradas (por ejemplo,
contains(),concat(),count(), etc.) y operadores (por ejemplo,+,or,and, etc.) para manipular y comparar datos dentro de documentos XML/HTML. - Compatibilidad con rutas absolutas y relativas: las expresiones XPath describen la ruta a los nodos deseados desde la raíz del documento (rutas absolutas) o desde un elemento específico (rutas relativas).
- Compatibilidad con la selección de nodos de texto: permite la selección directa de nodos de texto, lo que abre la puerta a la extracción de contenido textual de documentos XML/HTML sin necesidad de Parseo o análisis adicional.
- Independencia de la plataforma: no está vinculado a un lenguaje de programación o plataforma específicos, sino que es compatible con una amplia gama de entornos, bibliotecas, navegadores y sistemas operativos.
Contras
- Sintaxis compleja y larga: la sintaxis de XPath puede resultar difícil, especialmente para los principiantes. Escribir la ruta a un nodo específico profundamente anidado en el DOM puede dar lugar a una expresión larga que puede implicar algunas funciones y operadores. Esto puede hacer que las expresiones XPath sean propensas a errores y difíciles de depurar.
- Soporte y popularidad limitados: No todas las bibliotecas de parseo HTML son compatibles con XPath. Esto se debe a que los selectores CSS son mucho más populares entre los desarrolladores web, y las bibliotecas tienden a centrarse en ellos. Además, la mayoría de las bibliotecas basadas en XPath, como HtmlAgilityPack, siguen dependiendo de XPath 1.0, lanzado en 1999. La versión actual es XPath 3.1, lanzada en 2017. Lee nuestra guía sobre HtmlAgilityPack para convertirte en un experto en Scraping web con C#.
Consejos y trucos
Chrome te permite probar y recuperar expresiones XPath directamente en el navegador.
Supongamos que te interesa seleccionar un elemento específico en una página web. Visítala en Chrome, haz clic con el botón derecho del ratón en el nodo que te interesa y selecciona «Inspeccionar:».
Haz clic con el botón derecho del ratón en el elemento DOM específico y selecciona «Copiar > Copiar XPath» para obtener una expresión XPath para él. En el ejemplo anterior, obtendrás:
//*[@id="site-content"]/section[1]/div/div/div[1]/div[4]/a[1]
Nota: Esto es útil para hacerse una idea de cómo construir una estrategia de selección XPath eficaz. Al mismo tiempo, las expresiones XPath generadas automáticamente tienden a ser demasiado largas y orientadas a la implementación. Por lo tanto, no se puede confiar en ellas en la producción.
Ahora, quieres probar una expresión XPath en la página. En Chrome, hay dos formas de hacerlo.
En primer lugar, pegue la expresión XPath en la barra de búsqueda de la sección «Elementos» de DevTools, que puede activar con CTRL/Comando + F:
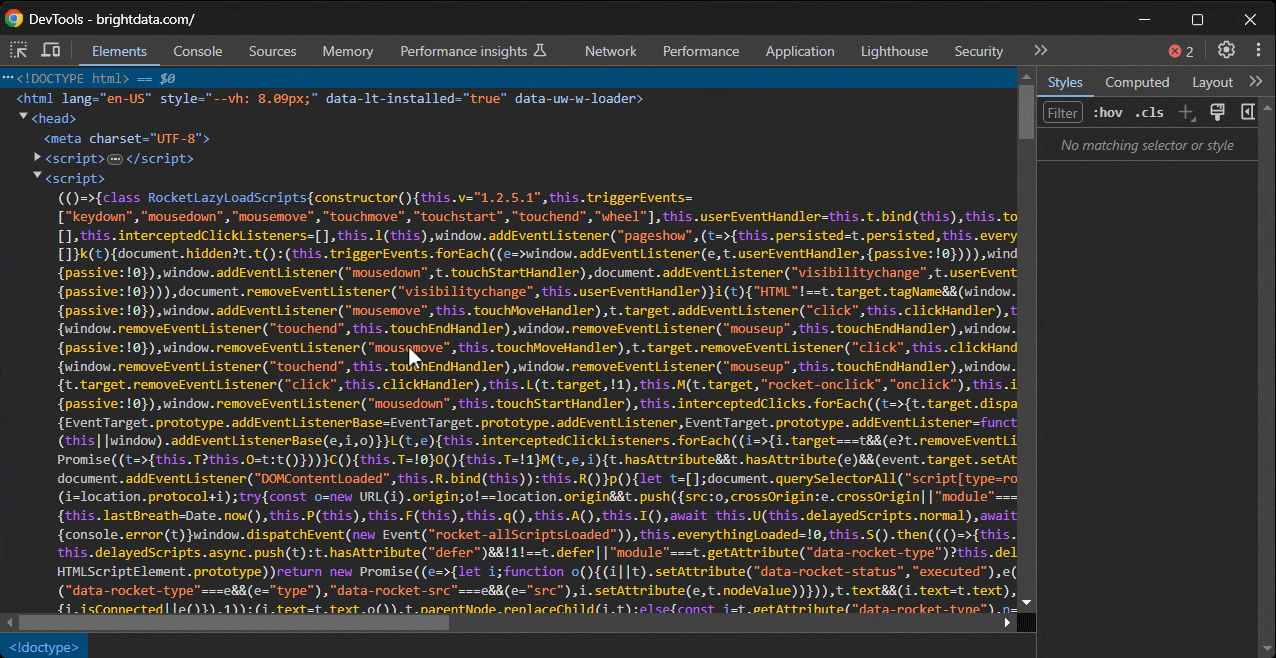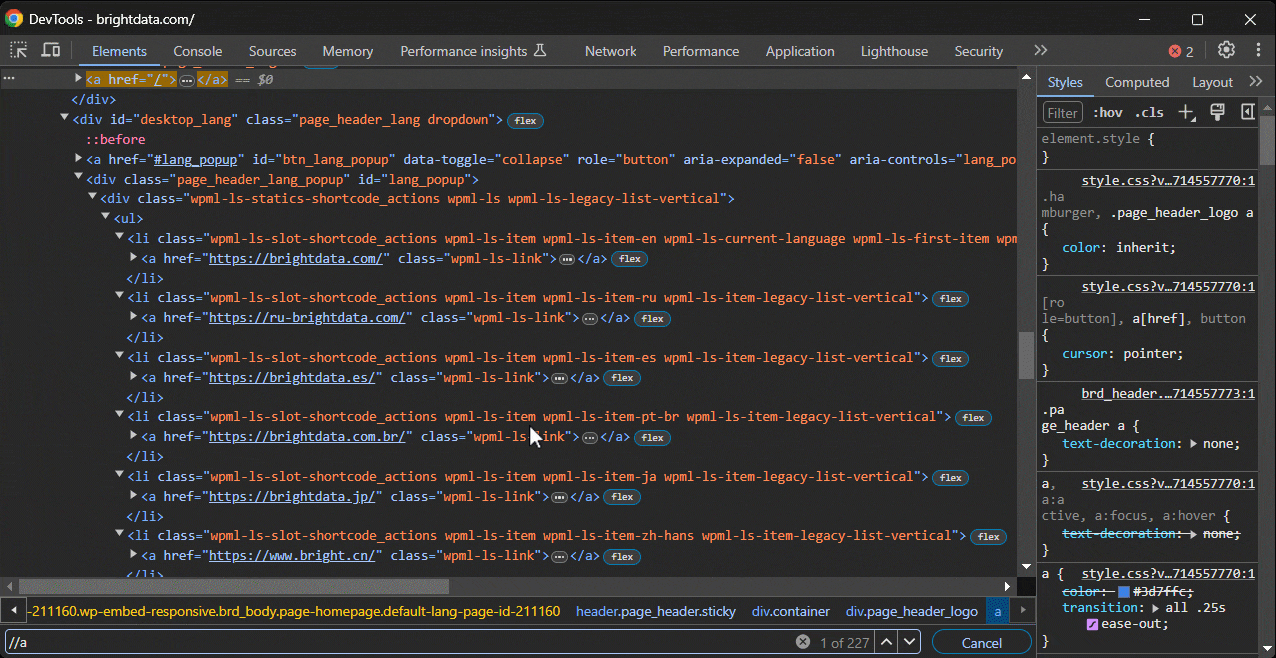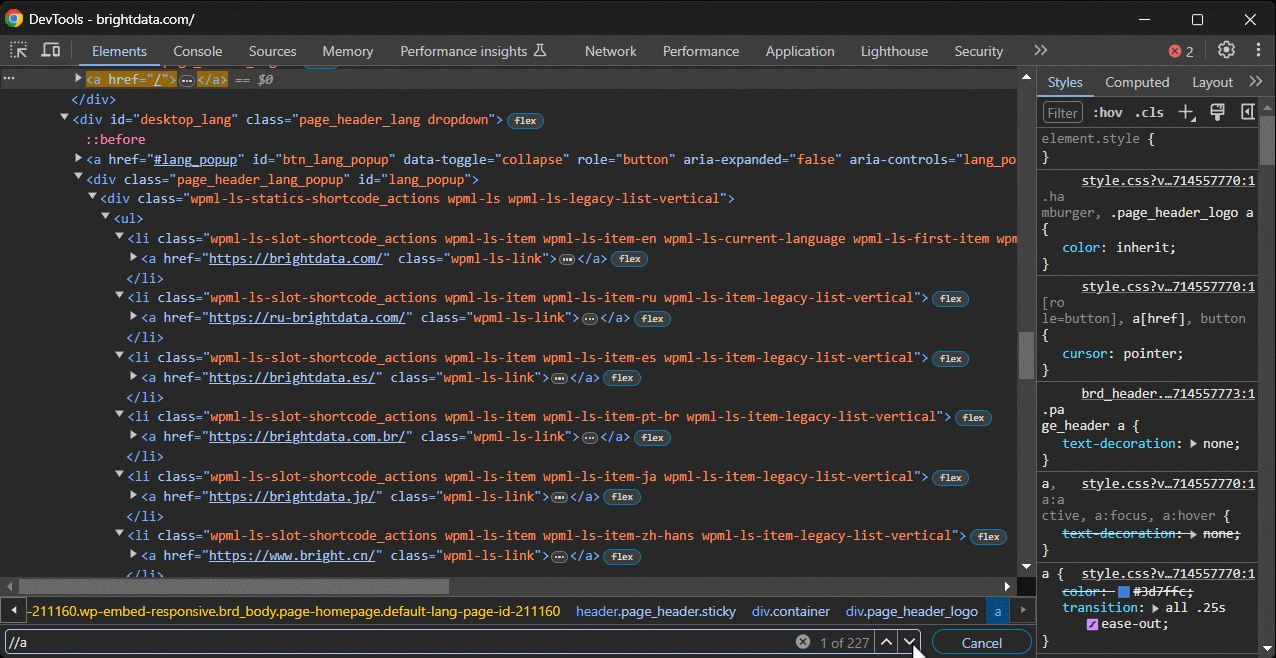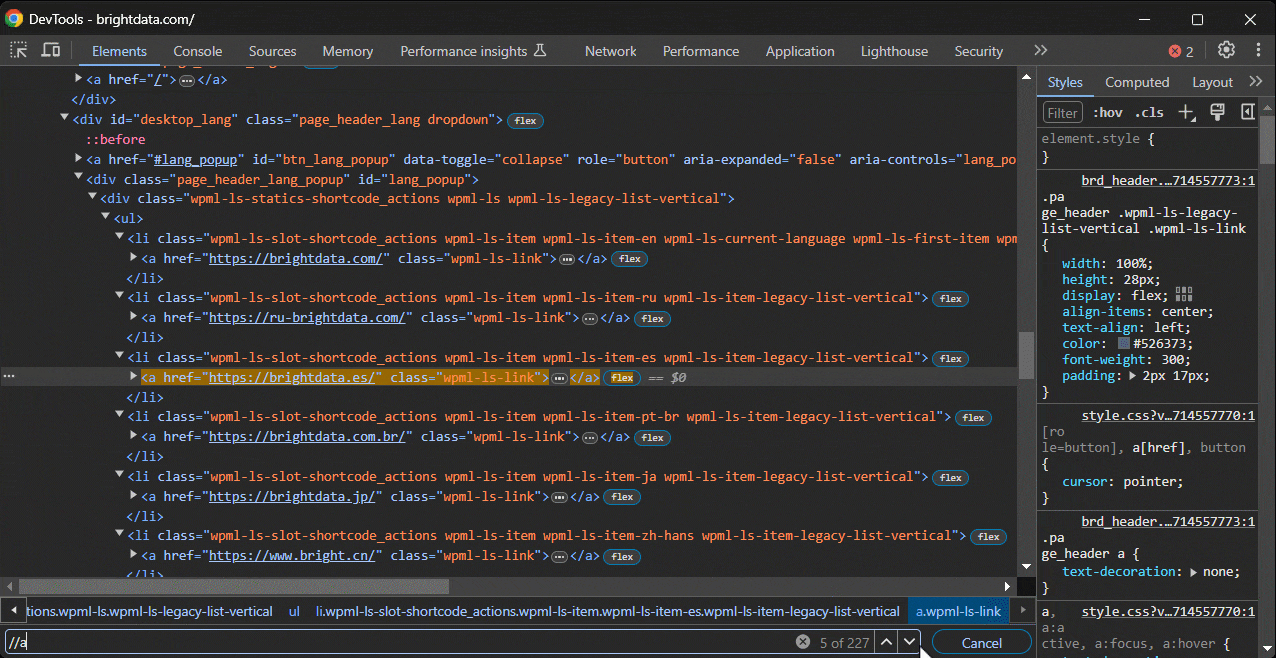
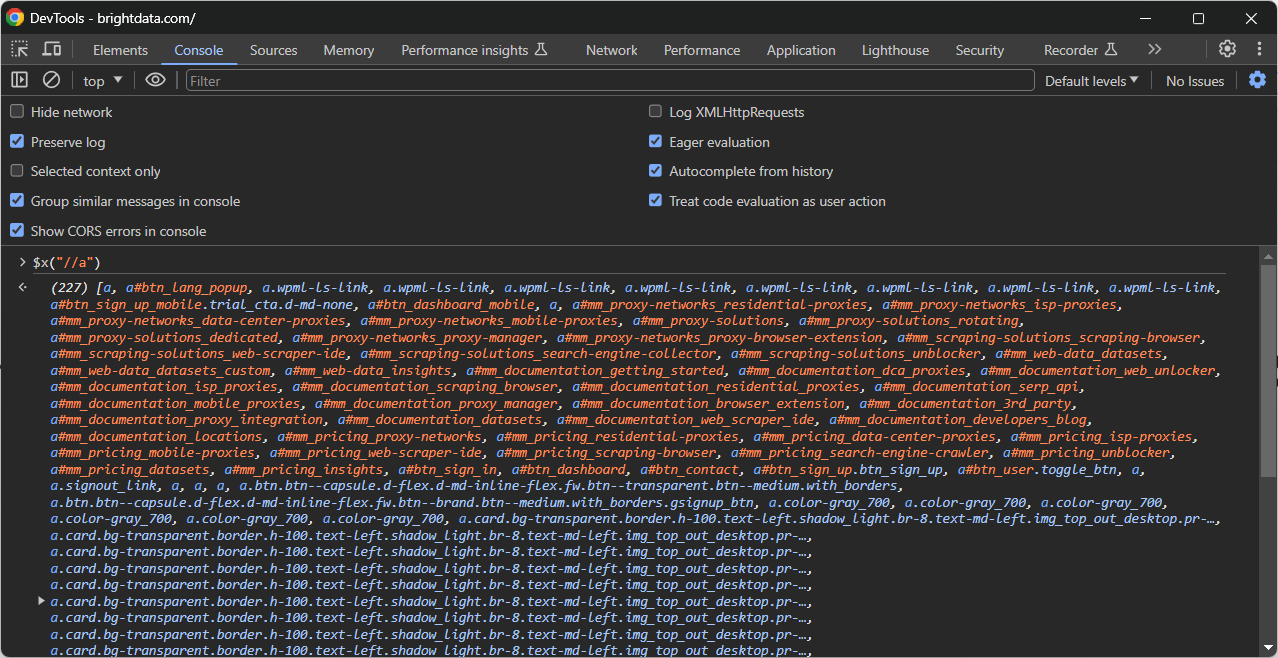
Segundo, llámela en la consola con la función especial $x():
Selectores CSS: revisión en profundidad
Continúa con este artículo sobre XPath frente a selectores CSS explorando el segundo elemento de la comparación, los selectores CSS.
Definición
Los selectores CSS te permiten seleccionar elementos HTML dentro de una página web. Forman parte de CSS y se utilizan para seleccionar elementos HTML en páginas web. Del mismo modo, las herramientas de navegador sin interfaz y las bibliotecas de Parseo de HTML los admiten como una forma de seleccionar nodos en el DOM.
Un selector CSS puede seleccionar elementos individuales o grupos de elementos en función de su ID, clase, atributos y posición en el árbol del documento. Si bien los selectores CSS desempeñan un papel crucial en la aplicación de estilos y formatos a las páginas web, también son una gran herramienta cuando se trata de Scraping web.
Sintaxis
La mejor manera de explicar la sintaxis de los selectores CSS es mostrarla a través de algunos ejemplos:
- Selector de elementos: para seleccionar elementos en función de su nombre de etiqueta. Por ejemplo,
pselecciona todos los elementos<p>del DOM. - Selector de clase: para seleccionar elementos con un atributo de clase específico. Por ejemplo,
.highlightselecciona todos los elementos con el atributo HTMLclass="highlight <otras_clases>". - Selector de ID: para seleccionar un elemento específico dado su atributo ID. Por ejemplo,
#navbarselecciona el elemento conid="navbar". - Selector de atributos: para seleccionar elementos en función de sus atributos. Por ejemplo,
input[type="text"]selecciona todos los elementos<input>con el atributotype="text". - Selector descendiente: para seleccionar elementos que son descendientes de otro elemento. Por ejemplo,
div aselecciona todos los elementos<a>que son descendientes de elementos<div>. - Selector de hijos: para seleccionar elementos que son hijos directos de otro elemento. Por ejemplo,
ul > liselecciona todos los elementos<li>que son hijos directos de elementos<ul>. - Selector de hermanos adyacentes: para seleccionar un elemento que está inmediatamente precedido por un elemento hermano específico. Por ejemplo,
h2 + pselecciona el elemento<p>inmediatamente después de un elemento<h2>.
Ten en cuenta que los diferentes navegadores ofrecen diferentes implementaciones del estándar CSS. Consulta sitios como caniuse.com para obtener información sobre la compatibilidad de un operador o sintaxis CSS específico.
Ventajas
- Excelente rendimiento: la mayoría de los navegadores tienen un motor selector CSS dedicado que garantiza un alto rendimiento. Este motor se utiliza principalmente para aplicar estilos, pero también puede resultar útil cuando se utilizan selectores CSS en una página a través de una herramienta de automatización del navegador.
- Fácil de aprender: la curva de aprendizaje para dominar los selectores CSS es bastante suave, incluso para principiantes, gracias a su sintaxis intuitiva.
- Sintaxis fácil y conocida: tienen una sintaxis concisa que no implica operadores o funciones complejos. Además, la mayoría de los desarrolladores web saben cómo utilizarlos, lo que les permite utilizarlos en más aspectos que el estilo.
- Gran facilidad de mantenimiento: los selectores CSS están diseñados para ser fáciles de leer y actualizar, lo que simplifica el mantenimiento del código.
- Compatibilidad general: los navegadores web modernos y las mejores herramientas de Scraping web los admiten. Esto garantiza una selección de nodos coherente en diferentes plataformas, dispositivos y casos de uso sin necesidad de soluciones alternativas específicas para cada entorno.
Contras
- No admiten funciones y operadores avanzados: a diferencia de XPath, los selectores CSS son bastante sencillos y no tienen muchas funciones ni operadores. Por ejemplo, no se pueden utilizar para seleccionar nodos de texto o extraer datos del DOM.
- No admiten el recorrido ascendente del árbol DOM: solo pueden buscar elementos en el DOM a partir del nodo raíz y moviéndose hacia abajo.
Consejos y trucos
Al igual que en el caso de XPath, Chrome puede probar y generar selectores CSS directamente en una página.
Supongamos que le interesa escribir un selector CSS para seleccionar un nodo específico. Visite la página de destino en Chrome, haga clic con el botón derecho del ratón en el elemento que le interesa y seleccione «Inspeccionar»:
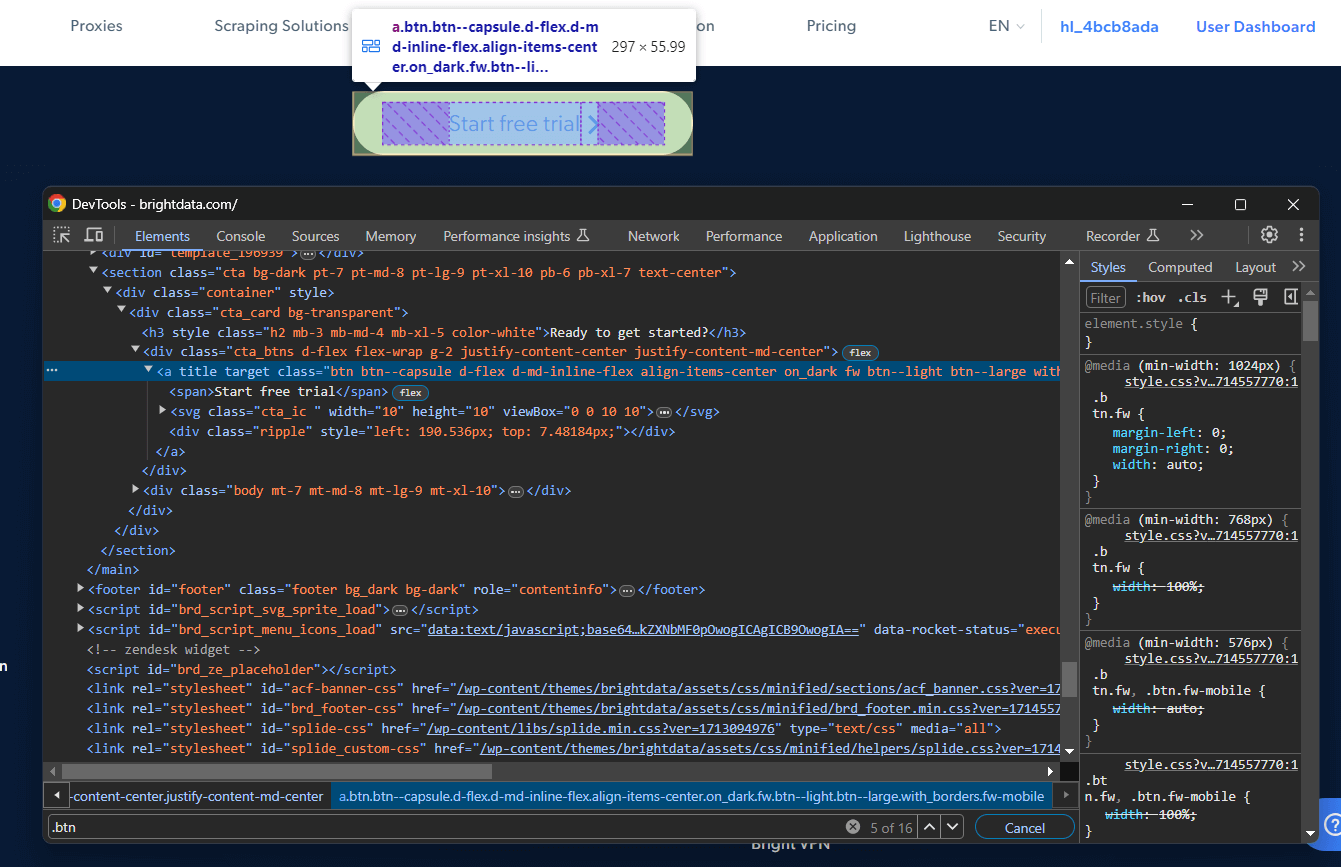
Haga clic con el botón derecho del ratón en el elemento DOM específico y seleccione «Copiar > Copiar selector» para obtener un selector CSS completo para él. En el ejemplo anterior, obtendrá:
#site-content > section.cta.bg-dark.pt-7.pt-md-8.pt-lg-9.pt-xl-10.pb-6.pb-xl-7.text-center > div > div > div.cta_btns.d-flex.flex-wrap.g-2.justify-content-center.justify-content-md-center > a
Como puede ver, es demasiado largo y específico de la implementación. Aunque es útil para hacerse una idea, no utilice los selectores CSS generados con esta función en producción.
Supongamos que necesita probar un selector CSS en una página web. En Chrome, hay varias formas de hacerlo.
El primer método consiste en pegar el selector CSS en la barra de búsqueda, como se muestra a continuación, que se puede activar con el atajo CTRL/Comando + F :
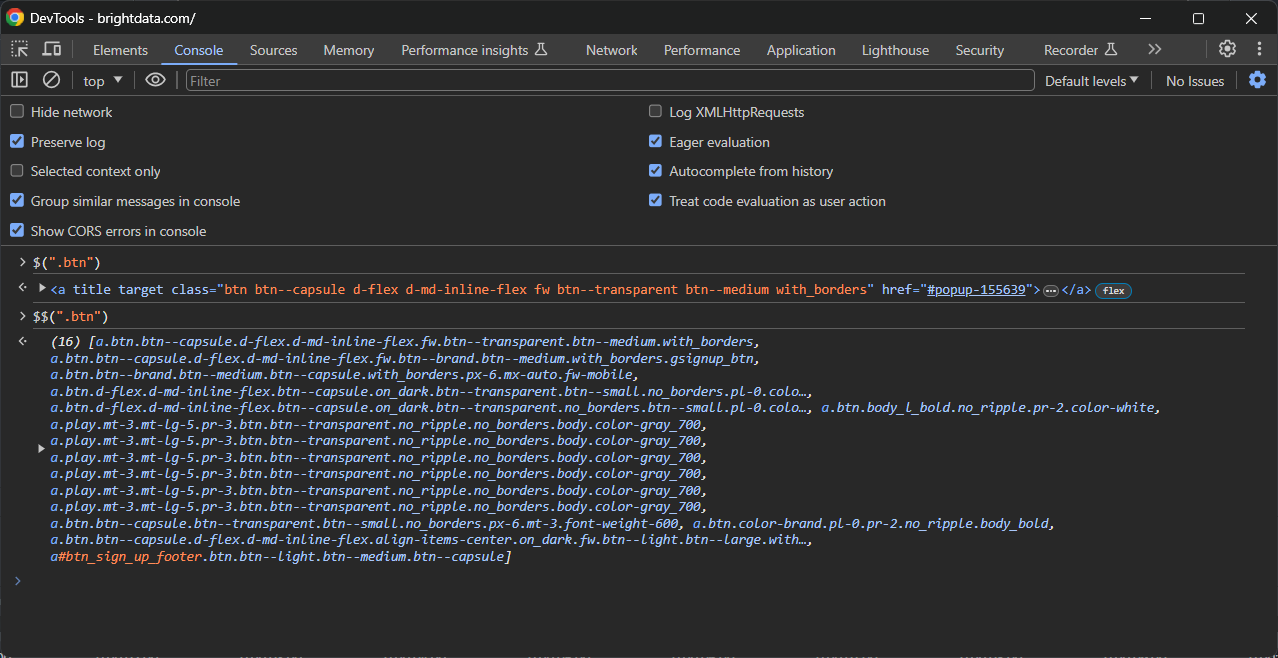
El segundo consiste en probarlos en la consola utilizando estas funciones especiales:
$(): Para seleccionar un único elemento con el selector CSS especificado.- $$(): Para seleccionar todos los elementos coincidentes.
Úsalas como en el siguiente ejemplo:
De forma equivalente, puede utilizar las funciones JavaScript querySelector() y querySelectorAll():
XPath frente a selector CSS: comparación directa
Ahora que ya sabe qué son los selectores XPath y CSS, está listo para profundizar en el análisis de XPath frente a CSS Selector.
Para una comparación directa de un vistazo, consulte la tabla resumen siguiente:
| Aspecto | XPath | Selektores CSS |
| Estándar W3C | Sí | Sí |
| Última especificación | XPath 3.1 (2017) | CSS Nivel 4 (en constante actualización) |
| Compatibilidad | La mayoría de los navegadores de scraping y herramientas de scraping siguen siendo compatibles con XPath 1.0 | La mayoría de los navegadores de scraping y herramientas de scraping lo admiten en su última especificación |
| Sintaxis | Compleja y prolija | Sencilla y concisa. |
| Funciones y operadores | Muchas | Pocas |
| Selección de nodos de texto | Compatible | No compatible |
| Rendimiento en el navegador | Medio/Lento | Rápido |
| Compatibilidad con bibliotecas | Normalmente compatible con bibliotecas de parseo de XML | Normalmente compatible con la mayoría de bibliotecas de parseo HTML |
Simplicidad
La sintaxis de XPath suele parecer mucho más compleja en comparación con los selectores CSS. Su sintaxis se asemeja a un lenguaje de consulta basado en rutas, lo que implica una curva de aprendizaje pronunciada para los desarrolladores que no están familiarizados con él. Sin embargo, XPath ofrece un control preciso sobre la selección y el recorrido de los elementos.
Los selectores CSS son generalmente más sencillos e intuitivos a la hora de seleccionar elementos DOM. Utilizan patrones familiares, como nombres de etiquetas, clases e ID, lo que los hace fáciles de entender y utilizar incluso para los principiantes. Los selectores CSS se utilizan ampliamente en el desarrollo web, lo que hace que su sintaxis sea bastante familiar.
Velocidad
Como muestra una prueba de rendimiento, las expresiones XPath aplicadas a los árboles DOM en un navegador tienden a ser más lentas que los selectores CSS. La razón es que los motores XPath suelen tener que realizar operaciones de recorrido más complejas que los motores de selectores CSS. Además, la mayoría de los navegadores modernos tienen motores de selectores CSS altamente optimizados, lo que permite una selección eficiente de los elementos HTML. En cuanto a las bibliotecas de parseo HTML, las diferencias de rendimiento dependen de la implementación subyacente.
Casos de uso
XPath es ideal para consultar y navegar por documentos XML utilizando XSLT o para la extracción de datos sencilla. Sus capacidades avanzadas pueden resultar útiles en determinados escenarios de scraping, como cuando se apuntan a nodos padres. Los selectores CSS se utilizan principalmente para dar estilo a documentos HTML y seleccionar nodos en scripts modernos de Scraping web.
Conclusión
¿XPath o selectores CSS? En esta guía sobre XPath y selectores CSS, ha aprendido que ambos son métodos eficaces para seleccionar elementos DOM. XPath se centra más en los documentos XML y ofrece funciones avanzadas, mientras que los selectores CSS funcionan muy bien en páginas HTML y son más sencillos.
Al utilizar expresiones XPath y selectores CSS en el Scraping web, el verdadero problema es que las tecnologías antibots bloquean el acceso. Independientemente de la estrategia de selección de nodos que adopte, estos sistemas pueden detectar y bloquear su script de scraping automatizado. Afortunadamente, Bright Data le ofrece varias soluciones de primera categoría:
- API de Scraper web: API fáciles de usar para el acceso programático a datos web estructurados de docenas de dominios populares.
- Navegador de scraping: un navegador controlable basado en la nube que ofrece capacidades de renderización de JavaScript y, al mismo tiempo, gestiona CAPTCHAs, huellas digitales del navegador, reintentos automatizados y mucho más. Se integra con las bibliotecas de navegadores de automatización más populares, como Playwright y Puppeteer.
- Web Unlocker: una API de desbloqueo que puede devolver sin problemas el HTML sin procesar de cualquier página, eludiendo cualquier medida anti-scraping.
¿No quieres ocuparte del Scraping web, pero sigues interesado en los datos online? ¡Explora nuestros conjuntos de datos listos para usar!





