

¿Por qué extraer datos de productos de Zalando?
Zalando es una de las plataformas minoristas de ropa online más populares de Europa. Con más de 50 millones de usuarios activos, es el sitio de comercio electrónico de moda líder en Europa. Ofrece una amplia gama de productos, incluyendo calzado, ropa y accesorios, tanto de marcas consolidadas como de diseñadores emergentes.
Las tres razones principales para extraer datos de productos de Zalando son:
- Estudio de mercado: obtenga información valiosa sobre las tendencias actuales de la moda. Esta información ayuda a las empresas a tomar decisiones informadas, mantener su competitividad y adaptar su oferta para satisfacer eficazmente las demandas de los clientes.
- Monitoreo de precios: realice un seguimiento de las fluctuaciones de precios para aprovechar las grandes ofertas y estudiar el mercado.
- Popularidad de las marcas: céntrese en los productos populares de Zalando para ver qué marcas son actualmente más populares entre los clientes y estudiar su estrategia.
En resumen, el scraping de Zalando abre un mundo de posibilidades y es ideal tanto para las empresas como para los usuarios.
Bibliotecas y herramientas para el scraping de Zalando
Para saber cuál de las muchas herramientas de scraping disponibles es la mejor para hacer scraping en Zalando, ábrela en tu navegador. Inspecciona el DOM y compáralo con el código fuente sin procesar. Notarás que la estructura del DOM es ligeramente diferente del documento HTML producido por el servidor. Esto significa que el sitio se basa en JavaScript para la renderización. Para hacer scraping en un sitio de contenido dinámico, necesitas una herramienta que pueda ejecutar JavaScript, como Selenium.
Ahora es el turno del lenguaje de programación. Cuando se trata de Scraping web, el más popular es Python. Su sintaxis sencilla y su rico ecosistema de bibliotecas lo hacen perfecto para nuestros objetivos. Así que, usemos Python
Antes de empezar, echa un vistazo a estas dos guías:
- Scraping web con Python: guía paso a paso
- Extracción de sitios web dinámicos con Python
Selenium renderiza los sitios en un navegador web controlable al que puedes dar instrucciones para realizar operaciones específicas. Al utilizarlo en Python, podrás crear un eficaz Scraper de Zalando. ¡Es hora de ver cómo!
Rastrear datos de productos de Zalando con Selenium
Sigue este tutorial paso a paso y aprende a crear un Scraper de Zalando en Python.
Paso 1: Configurar un proyecto Python
Antes de lanzarte al Scraping web, asegúrate de que cumples los siguientes requisitos previos:
- Python 3+ instalado en tu equipo: descarga el instalador, haz doble clic en él y sigue el asistente de instalación.
- Un IDE de Python de su elección: PyCharm Community Edition o Visual Studio Code con la extensión Python serán suficientes.
¡Ahora ya tienes todo lo necesario para configurar un proyecto Python y escribir código!
Inicie el terminal y ejecute los siguientes comandos para:
- Crear una carpeta zalando-scraper.
- Entrar en ella.
- Inicializarla con un entorno virtual Python.
mkdir zalando-scraper
cd zalando-scraper
python -m venv envEn Linux o macOS, ejecute el siguiente comando para activar el entorno:
./env/bin/activateEnWindows, ejecuta:envScriptsactivate.ps1
A continuación, crea un archivo scraper.py en la carpeta del proyecto y añádele la siguiente línea:
print("Hello, World!")Este es el script de Python más sencillo que se puede escribir. Por ahora, solo imprime «¡Hola, mundo!», pero pronto contendrá la lógica de scraping de Zalando.
Ejecútelo para comprobar que funciona con:
python Scraper.pyDebería imprimir este mensaje en la terminal:
¡Hola, mundo!Ahora que estás seguro de que el script funciona como esperabas, abre la carpeta del proyecto en tu IDE de Python.
¡Genial! Prepárate para escribir las primeras líneas de tu Scraper.
Paso 2: Instala las bibliotecas de scraping
Como se mencionó anteriormente, Selenium es la herramienta elegida para crear un Scraper de Zalando. En el entorno virtual Python activado, ejecuta el siguiente comando para añadirlo a las dependencias del proyecto:
pip install seleniumEl proceso de instalación puede tardar un poco, así que ten paciencia.
Ten en cuenta que este tutorial hace referencia a Selenium 4.13.x, que incluye la función de detección automática de controladores. Si tienes una versión anterior de Selenium en tu equipo, actualízala con:
pip install selenium -UElimine todo el contenido de scraper.py e inicialice un Scraper Selenium con:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# configura una instancia controlable de Chrome
service = Service()
options = webdriver.ChromeOptions()
# tus opciones de navegador...
driver = webdriver.Chrome(
service=service,
options=options
)
# maximizar la ventana para evitar la representación responsiva
driver.maximize_window()
# lógica de scraping...
# cerrar el navegador y liberar sus recursos
driver.quit()El script anterior importa Selenium y lo utiliza para instanciar un objeto WebDriver. Esto le permite controlar mediante programación una instancia del navegador Chrome.
De forma predeterminada, se abrirá la ventana del navegador y podrá supervisar las acciones realizadas en la página. Esto resulta útil en el desarrollo.
Para abrir Chrome en modo sin interfaz gráfica de usuario, configura las opciones como se indica a continuación:
options.add_argument('--headless=new')
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
options.add_argument(f'user-agent={user_agent}')Ten en cuenta que la opción adicional user-agent es necesaria, ya que Zalando bloquea las solicitudes de navegadores sin interfaz gráfica que no incluyan ese encabezado. Esta configuración es más habitual en entornos de producción.
¡Genial! Es hora de crear tu Scraper web Zalando Python.
Paso 3: Abre la página de destino
En esta guía, verás cómo extraer datos detallados de un producto de calzado de Zalando Reino Unido. Si te centras en un tipo de producto diferente, tendrás que realizar pequeños cambios en el script que vas a crear. El motivo es que cada producto puede tener estructuras de página específicas con información diferente.
En el momento de escribir este artículo, así es como se ve la página de destino:
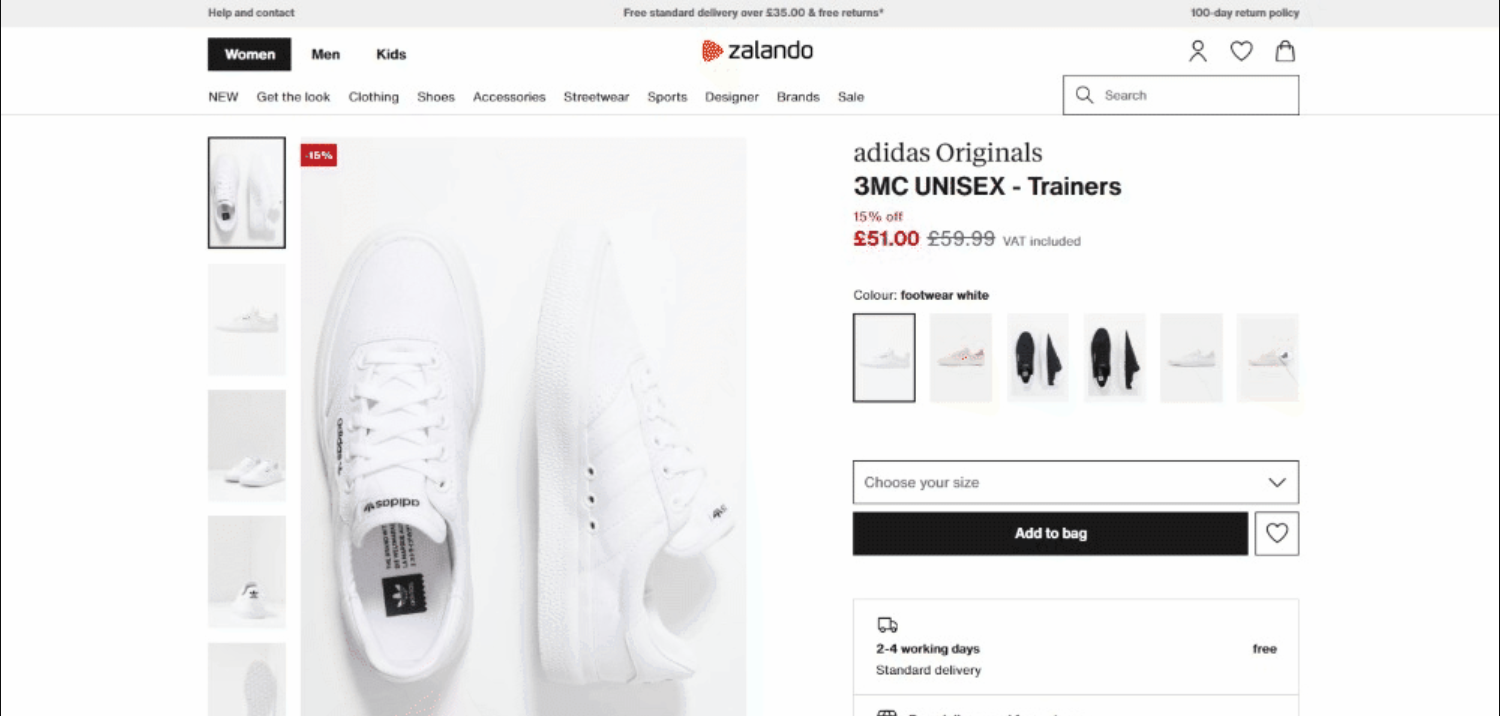
En detalle, esta es la URL de la página de destino:
Conéctese a la página de destino en Selenium con:
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')get() indica al navegador que visite la página especificada por la URL pasada como parámetro.
Este es el script de scraping de Zalando hasta ahora:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service()
# configurar la instancia de Chrome
options = webdriver.ChromeOptions()
# tus opciones de navegador...
driver = webdriver.Chrome(
service=service,
options=options
)
# maximizar la ventana para evitar la representación responsiva
driver.maximize_window()
# visitar la página de destino en el navegador controlado
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')
# lógica de scraping...
# cerrar el navegador y liberar sus recursos
driver.quit()Ejecuta la aplicación. Se abrirá la ventana siguiente durante menos de un segundo antes de cerrarse:
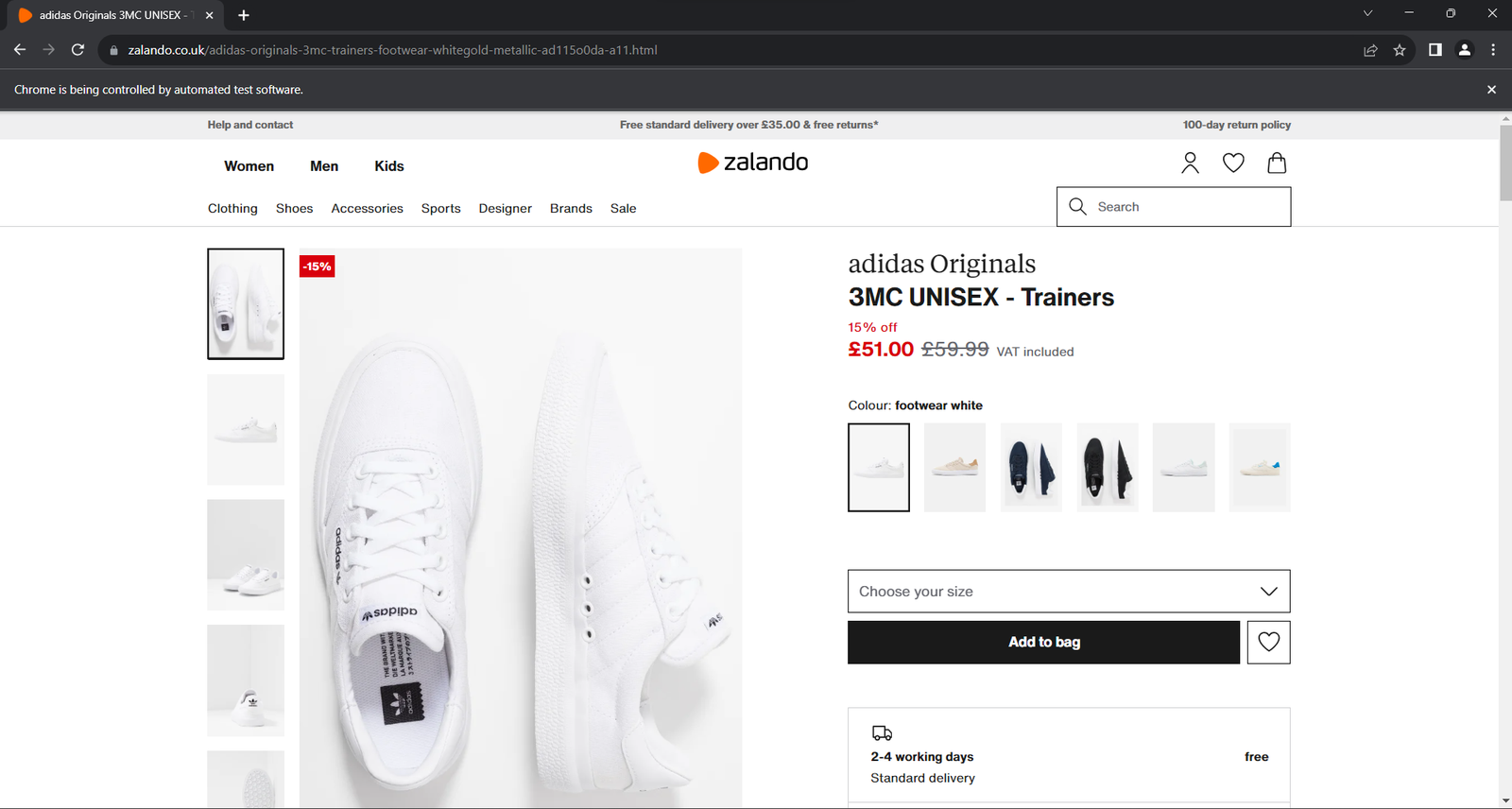
El aviso «Chrome está siendo controlado por software automatizado» garantiza que Selenium funciona según lo esperado.
Paso 4: Familiarízate con la estructura de la página
Para escribir una lógica de scraping eficaz, es necesario dedicar algo de tiempo a estudiar la estructura DOM de la página de destino. Esto le ayudará a comprender cómo seleccionar elementos HTML y extraer datos de ellos.
Abra su navegador en modo incógnito y visite la página del producto Zalando elegido. Haga clic con el botón derecho del ratón y seleccione la opción «Inspeccionar» para abrir las herramientas de desarrollo de su navegador:
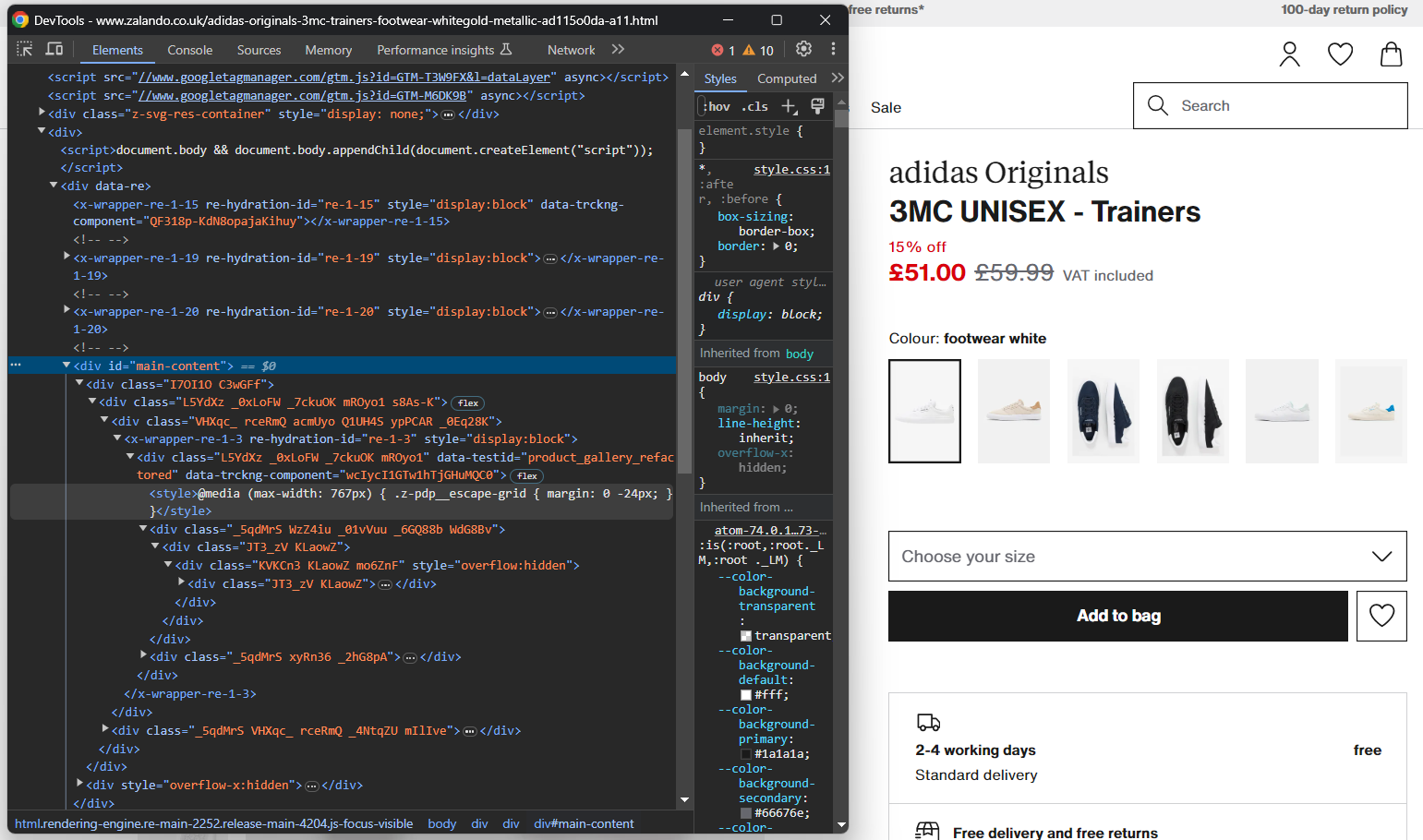
Aquí, seguramente notarás que la mayoría de las clases CSS parecen generarse aleatoriamente en el momento de la compilación. En otras palabras, no debes basar tu estrategia de selección en ellas, ya que cambiarán en cada implementación. Al mismo tiempo, algunos elementos tienen atributos HTML poco comunes, como data-testid. Eso te ayudará a definir selectores eficaces.
Interactúa con la página para estudiar cómo cambia el DOM después de hacer clic en elementos específicos, como los acordeones. Te darás cuenta de que algunos datos se añaden dinámicamente al DOM en función de las acciones del usuario.
Sigue inspeccionando la página de destino y familiarízate con su estructura HTML hasta que te sientas preparado para continuar.
Paso 5: Empieza a extraer los datos del producto
En primer lugar, inicialice una estructura de datos donde realizar un seguimiento de los datos extraídos. Un diccionario Python será perfecto:
product = {}¡Comienza a seleccionar elementos de la página y extrae datos de ellos!
Inspeccione el elemento HTML que contiene la marca del calzado:
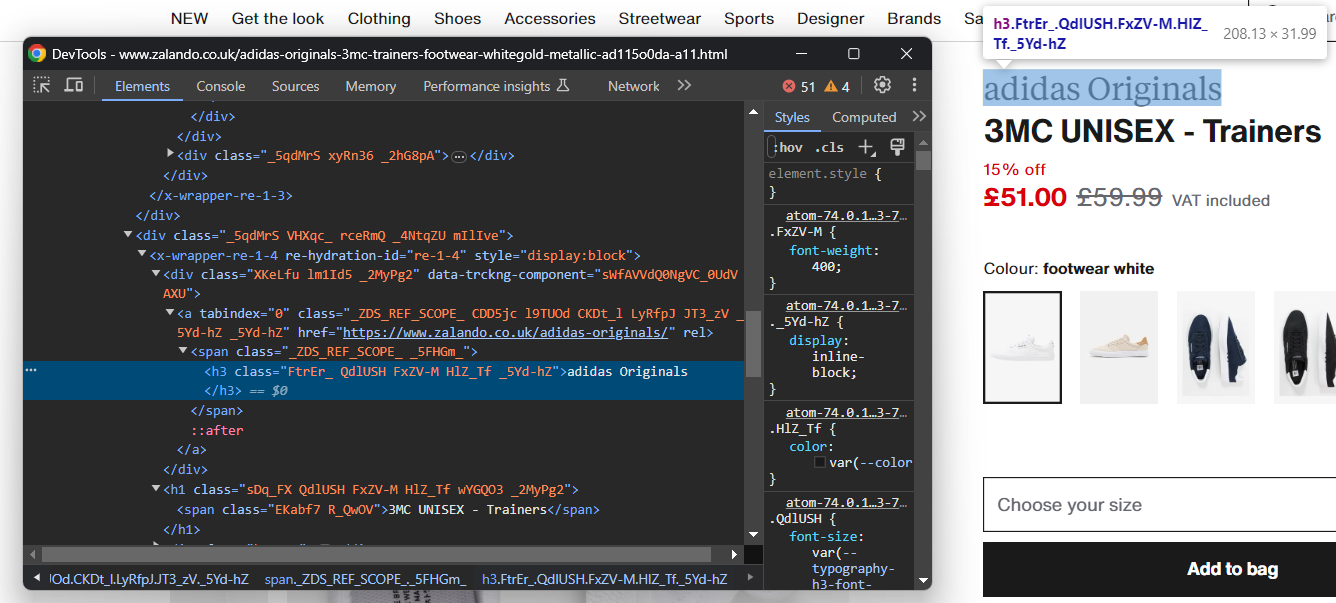
Tenga en cuenta que la marca es un <h3> y el nombre del producto un <h1>. Extraiga estos datos con:
brand_element = driver.find_element(By.CSS_SELECTOR, 'h3')
brand = brand_element.text
name_element = driver.find_element(By.CSS_SELECTOR, 'h1')
name = name_element.textfind_element() es un método de Selenium que devuelve el primer elemento que coincide con la estrategia de selección pasada como parámetro. En concreto, By.CSS_SELECTOR indica al controlador que utilice una estrategia de selector CSS. Selenium también admite:
- By.TAG_NAME: para buscar elementos basándose en su etiqueta HTML.
- By.XPATH: para buscar elementos a través de una expresión XPath.
Del mismo modo, también existe find_elements(), que devuelve la lista de todos los nodos que coinciden con la consulta de selección.
Recuerda importar By con:
from selenium.webdriver.common.by import ByDado un elemento HTML, puede acceder a su contenido de texto con el atributo text. Cuando sea necesario, utilice el método replace() de Python para limpiar las cadenas de texto.
Extraer información sobre precios es un poco más complicado. Como puede ver en la imagen siguiente, no hay una forma fácil de seleccionar estos elementos:
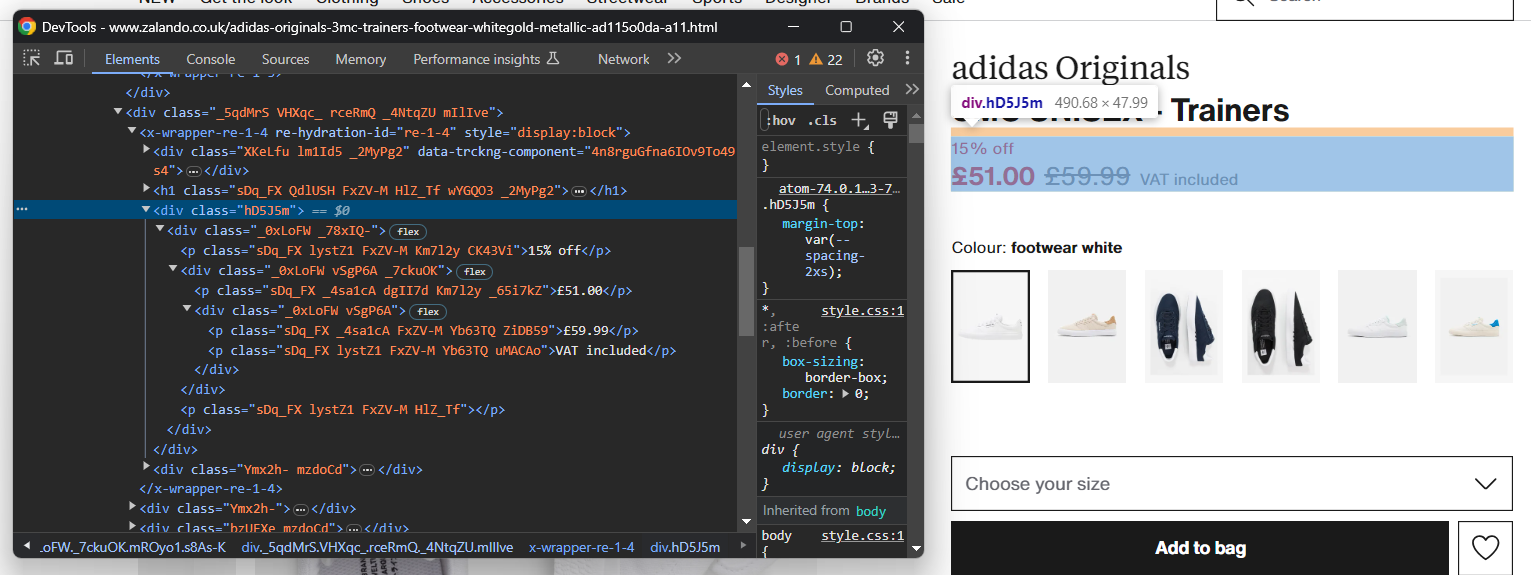
Lo que puede hacer es:
- Acceder al precio <div> como el primer elemento hermano del elemento <h1> name.
- Obtener todos los nodos <p> que hay dentro.
Para ello, utilice:
price_elements = name_element
.find_element(By.XPATH, 'following-sibling::*[1]')
.find_elements(By.TAG_NAME, "p")Ten en cuenta que Selenium no proporciona un método de utilidad para acceder a los hermanos de un nodo. Por eso debes utilizar la expresión Xpath following-sibling::* en su lugar.
A continuación, puede obtener los datos del precio del producto con:
descuento = Ninguno
precio = Ninguno
precio_original = Ninguno
si len(elementos_de_precio) >= 3:
descuento = elementos_de_precio[0].texto.reemplazar(' off', '')
precio = elementos_de_precio[1].texto
precio_original = elementos_de_precio[2].textoAhora céntrate en la galería de imágenes del producto:
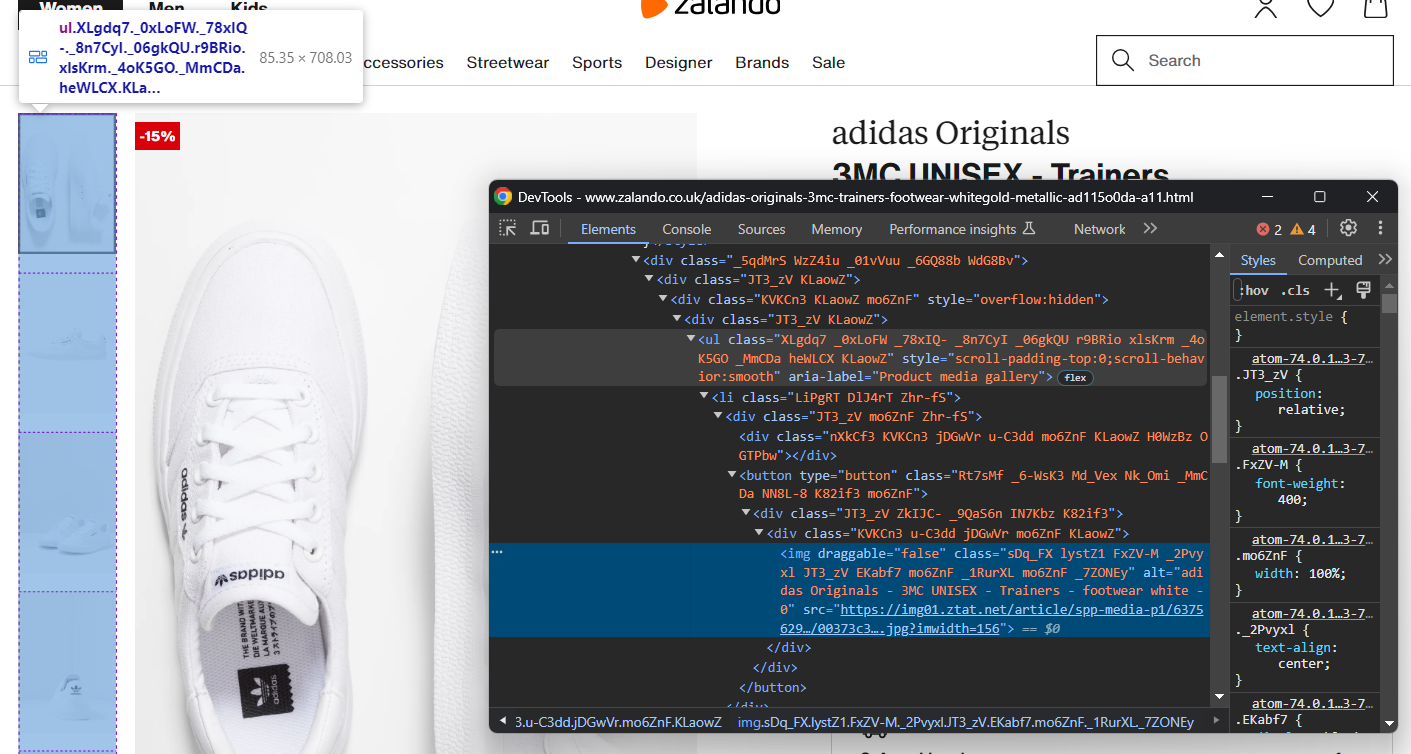
Esta contiene varias imágenes, así que inicialice una matriz para almacenarlas todas:
imágenes = []Una vez más, seleccionar el <img> no es fácil, pero puedes lograrlo apuntando a los elementos <li> dentro del <ul> «Galería multimedia del producto»:
image_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Product media gallery"] li')for image_element in image_elements:
image = image_element.find_element(By.TAG_NAME, 'img').get_attribute('src')
images.append(image)Del mismo modo, puede recopilar las opciones de color de los zapatos:
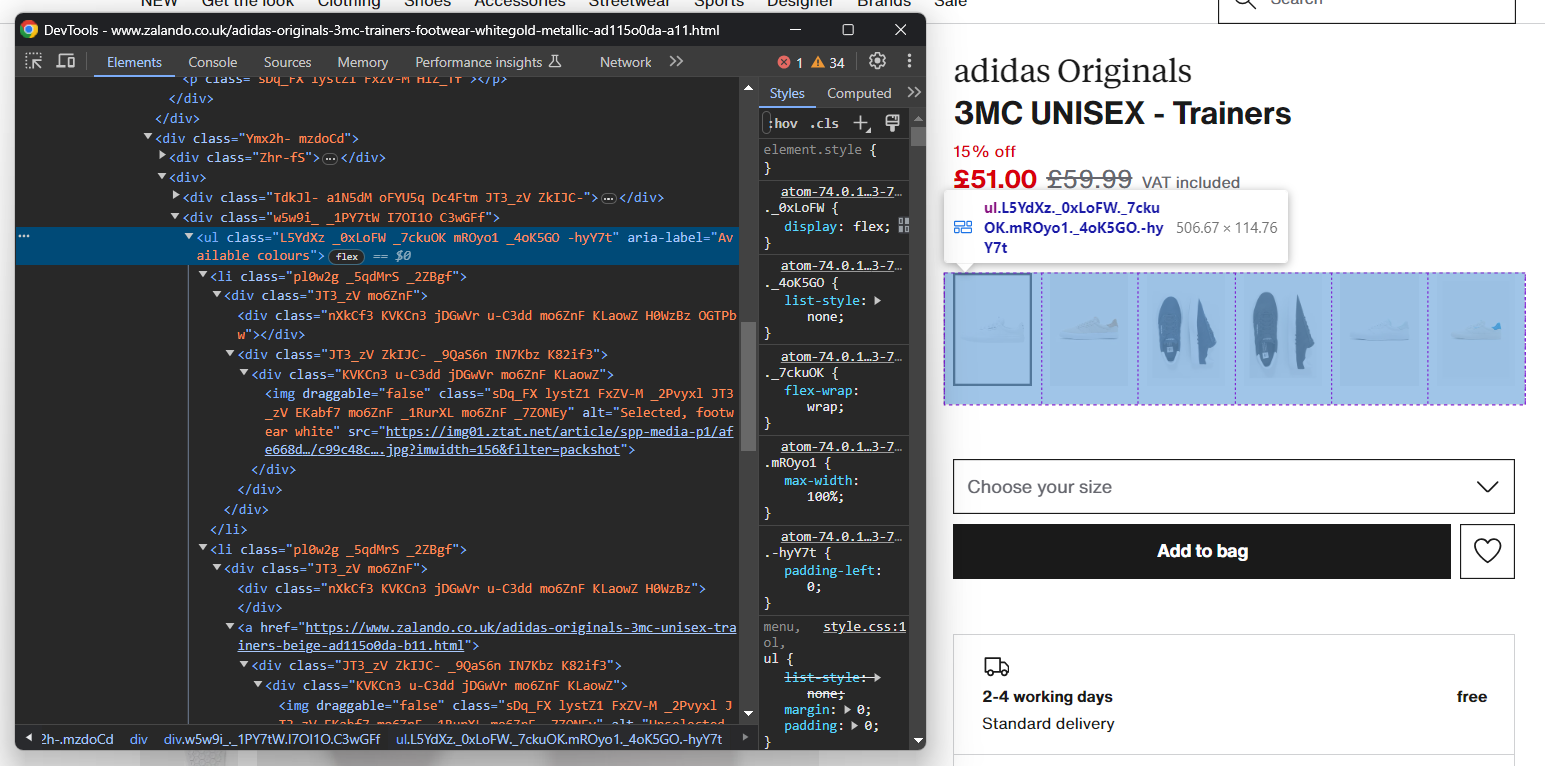
Al igual que antes, cada elemento de color es <li>. En detalle, cada sección de color tiene:
- Un enlace opcional.
- Una imagen.
- Un nombre, almacenado en el atributo alt del elemento de imagen.
Extrae todos los colores con:
colors = []
color_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Colores disponibles"] li')
for color_element in color_elements:
# inicializar un nuevo objeto de color
color = {
'color': None,
'image': None,
'link': None
}
# comprueba si el enlace de color está presente y extrae su URL
link_elements = color_element.find_elements(By.TAG_NAME, 'a')
if len(link_elements) > 0:
color['link'] = link_elements[0].get_attribute('href')
# comprueba si la imagen del color está presente y extrae sus datos
image_elements = color_element.find_elements(By.TAG_NAME, 'img')
if len(image_elements) > 0:
color['image'] = image_elements[0].get_attribute('src')
color['color'] = image_elements[0].get_attribute('alt')
.replace('Selected, ', '')
.replace('Unselected, ','')
.strip()
colors.append(color)¡Perfecto! Acabas de implementar una lógica de scraping, pero aún quedan más datos por recuperar.
Paso 6: Extraer los datos de los detalles del producto
Los detalles del producto se almacenan en tarjetas situadas debajo del elemento de selección de color:
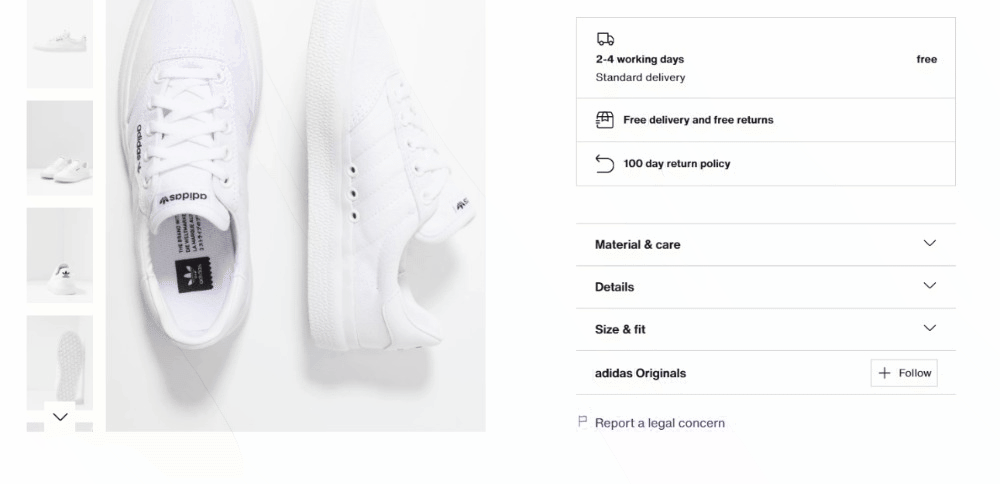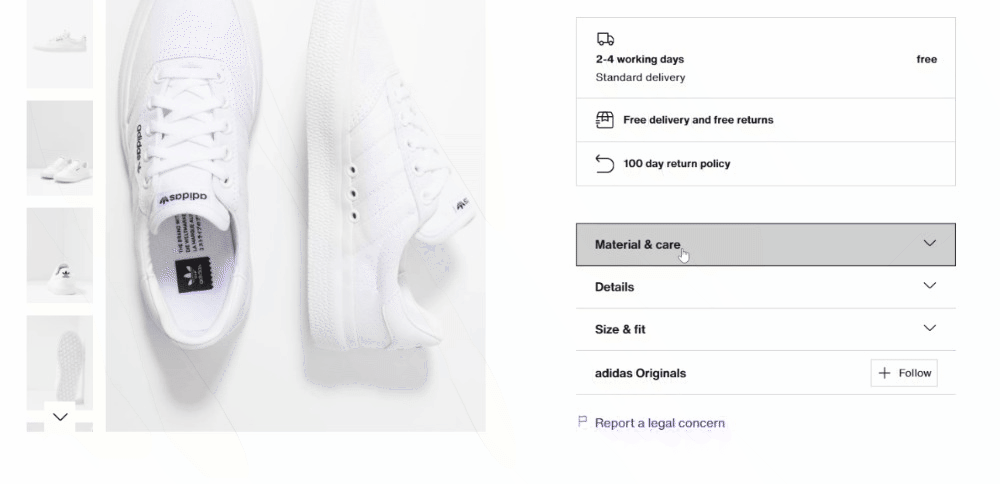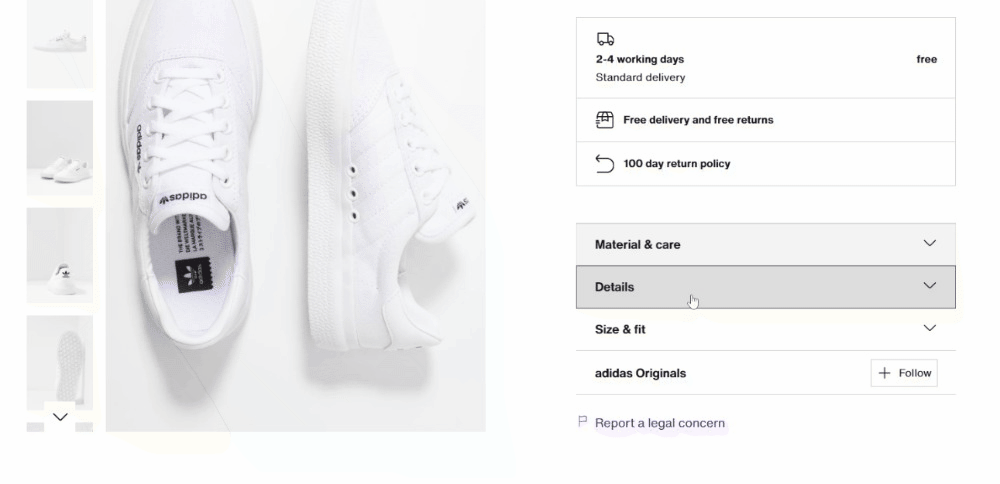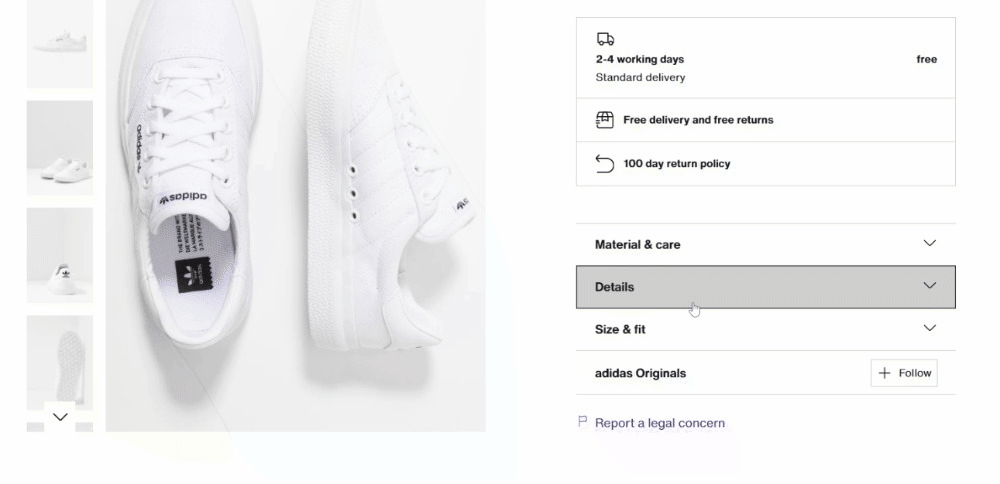
En primer lugar, céntrate en la información de entrega:
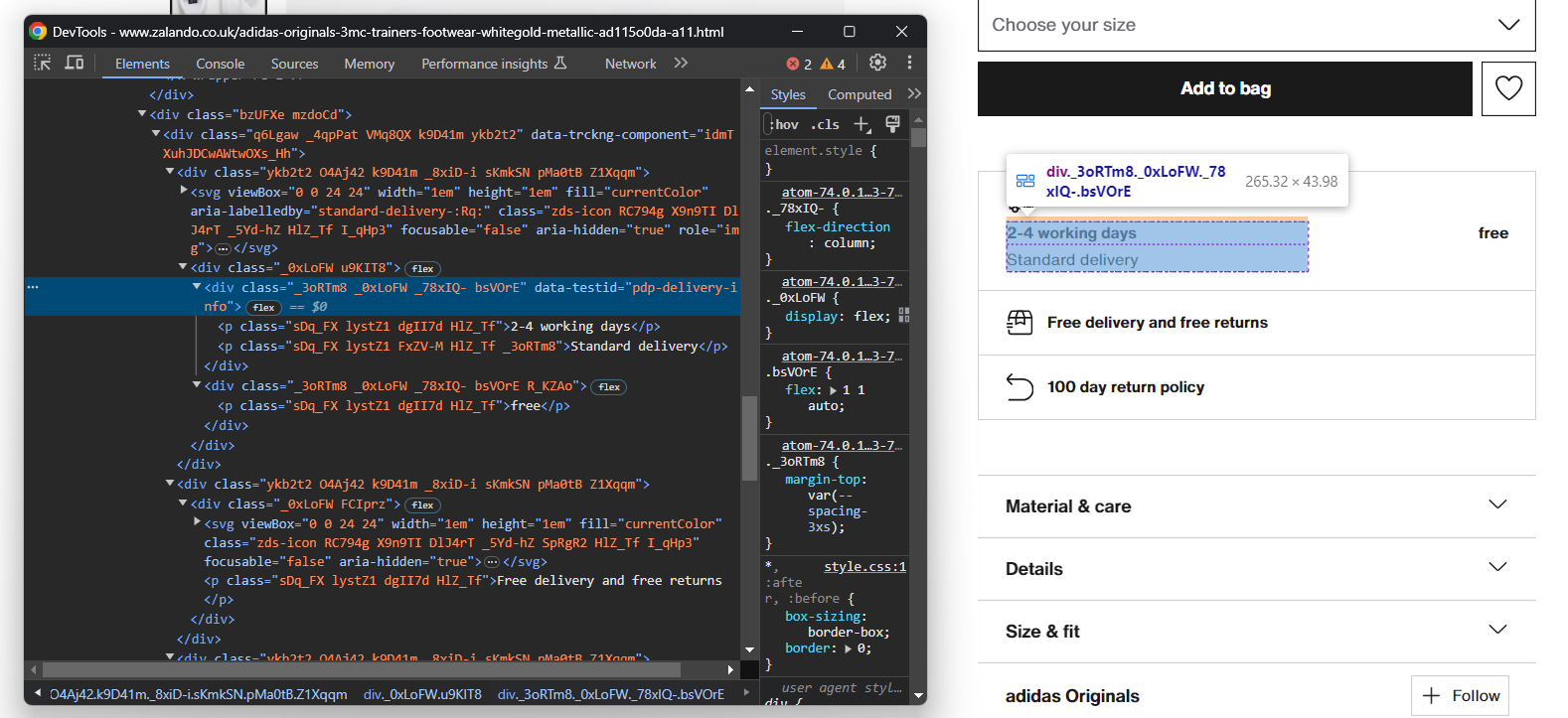
Consiste en tres campos de datos, así que inicializa un diccionario de entrega como se muestra a continuación:
delivery = {
'time': None,
'type': None,
'cost': None,
}Una vez más, no hay un selector fácil para seleccionar esos tres elementos. Lo que puede hacer es:
- Seleccionar el nodo cuyo atributo data-testid sea «pdp-delivery-info».
- Vaya a su elemento padre.
- Obtenga todos los elementos <p> descendientes.
Implementa esta lógica y extrae los datos de entrega con:
delivery_elements = driver
.find_element(By.CSS_SELECTOR, '[data-testid="pdp-delivery-info"]')
.find_element(By.XPATH, 'parent::*[1]')
.find_elements(By.TAG_NAME, 'p')
if len(delivery_elements) == 3:
delivery['time'] = delivery_elements[0].text
delivery['type'] = delivery_elements[1].text
delivery['cost'] = delivery_elements[2].textDado que Selenium no ofrece una forma de acceder al padre de un nodo, es necesario utilizar la expresión Xpath parent::*.
A continuación, centra tu atención en los acordeones de detalles del producto:
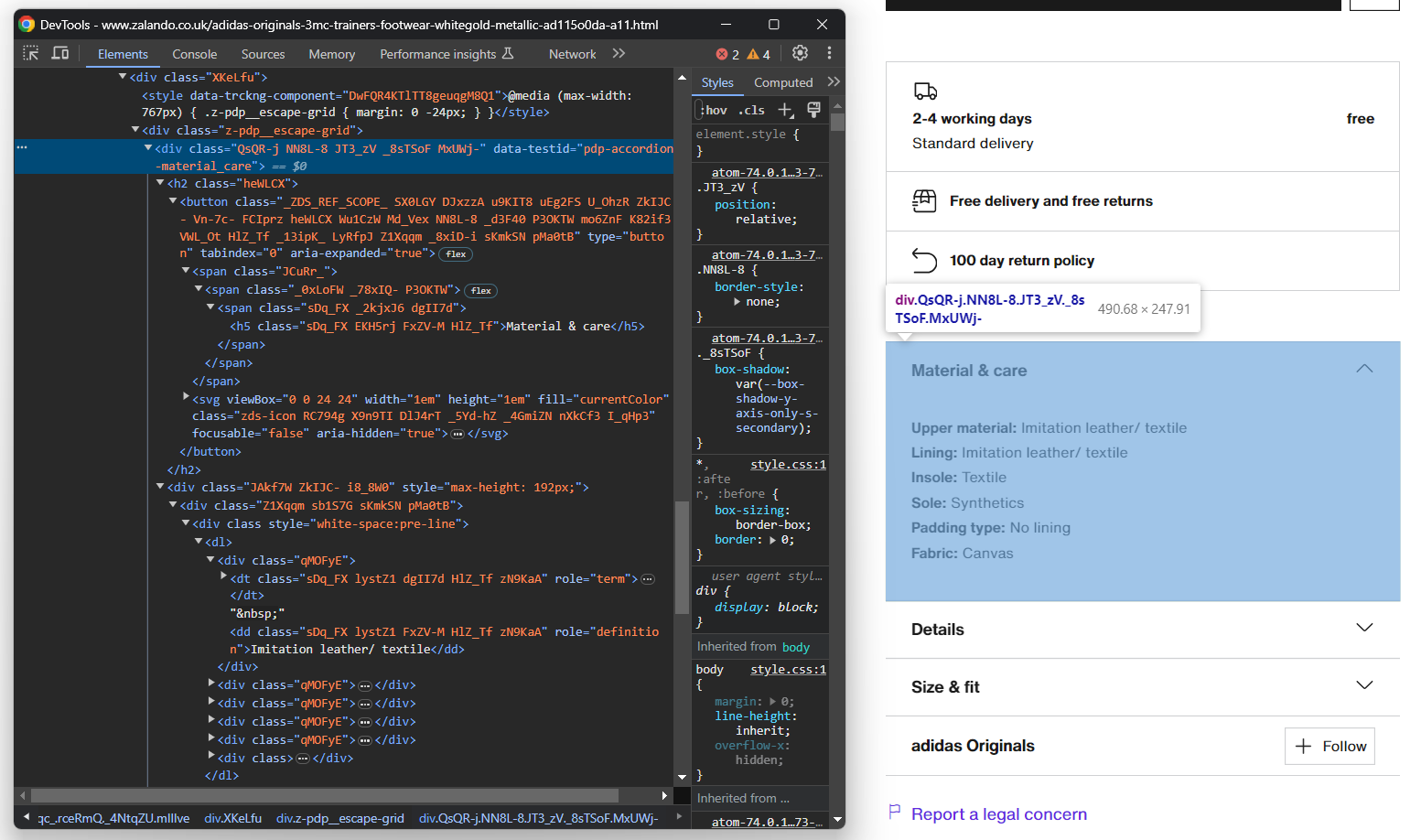
Esta vez, puede obtener todos los elementos del acordeón seleccionando los nodos cuyo atributo data-testid comience por «pdp-accordion-». Para ello, utilice el siguiente selector CSS:
[data-testid^="pdp-accordion-"]Esa sección contiene varios campos, por lo que debe crear un diccionario para realizar un seguimiento:
info = {}A continuación, aplique el selector CSS mencionado anteriormente para seleccionar los acordeones de detalles del producto:
info_elements = driver.find_elements(By.CSS_SELECTOR, '[data-testid^="pdp-accordion-"]')[:2]El elemento «Talla y ajuste» no contiene datos relevantes, por lo que puede ignorarlo. [:2] reducirá la lista a los dos primeros elementos, tal y como se desea.
Esos elementos HTML son dinámicos y su contenido se añade al DOM solo cuando se abren. Por lo tanto, es necesario simular la interacción del clic con el método click():
for info_element in info_elements:
info_element.click()
// lógica de scraping...
A continuación, rellene el objeto de información mediante programación con:
info_section_name = info_element.find_element(By.CSS_SELECTOR, 'h5').text
info[info_section_name] = {}
for dt_element in info_element.find_elements(By.CSS_SELECTOR, 'dt'):
info_section_detail_name = dt_element.text.replace(':', '')
info[info_section_name][info_section_detail_name] = dt_element.find_element(By.XPATH, 'following-sibling::dd').textLa lógica anterior extrae dinámicamente la información de los acordeones y la organiza por nombre.
Para comprender mejor cómo funciona ese código, intente imprimir info. Verá lo siguiente:
{'Material y cuidado': {'Material superior': 'Imitacione de piel/textil', 'Forro': 'Imitacione de piel/textil', 'Plantilla': 'Textil', 'Suela': 'Sintética', 'Tipo de acolchado': 'Sin forro', 'Tejido': 'Lona'}, «Detalles»: {«Punta del zapato»: «Redonda», «Tipo de tacón»: «Plano», «Cierre»: «Cordones», «Cierre del zapato»: «Cordones», «Patrón»: «Liso», «Número de artículo»: «AD115O0DA-A11»}}¡Fantástico! ¡Detalles del producto Zalando recopilados!
Paso 7: Rellenar el objeto del producto
Solo queda rellenar el diccionario del producto con los datos extraídos:
# asignar los datos extraídos al diccionario
product['brand'] = brand
product['name'] = name
product['price'] = price
product['original_price'] = original_price
product['discount'] = discount
product['images'] = images
product['colors'] = colors
product['delivery'] = delivery
product['info'] = infoTambién puede añadir una instrucción de registro para verificar que el Scraper de Zalando funciona según lo esperado:
print(job)
Ejecuta el script:
python Scraper.pyEsto producirá un resultado similar al siguiente:
{'brand': 'adidas Originals', 'name': '3MC UNISEX - Trainers', 'price': '£51.00', 'original_price': '£59.99', 'discount': '15%', ... }¡Et voilà! Acabas de aprender a extraer datos de productos de Zalando.
Paso 8: Exportar los datos extraídos a JSON
En este momento, los datos extraídos se almacenan en un diccionario de Python. Exporta los datos a JSON para que sean más fáciles de compartir y leer:
with open('product.json', 'w', encoding='utf-8') as file:
json.dump(product, file, indent=4, ensure_ascii=False)El fragmento anterior crea un archivo de salida product.json con open() y lo rellena con datos JSON a través de json.dump(). Echa un vistazo a nuestra guía para obtener más información sobre cómo realizar el parseo y la serialización de datos a JSON en Python.
Recuerda añadir la importación json:
import jsonEste paquete proviene de la biblioteca estándar de Python, por lo que ni siquiera es necesario instalarlo manualmente.
¡Increíble! Has partido de datos de productos sin procesar contenidos en una página web y ahora tienes datos JSON semiestructurados. Ya estás listo para ver el Scraper completo de Zalando.
Paso 8: Ponlo todo junto
Aquí está el código completo del archivo scraper.py:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
service = Service()
# configurar la instancia de Chrome
options = webdriver.ChromeOptions()
# tus opciones de navegador...
driver = webdriver.Chrome(
service=service,
options=options)
# maximizar la ventana para evitar la representación responsiva
driver.maximize_window()
# visitar la página de destino en el navegador controlado
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')
# instanciar el objeto que contendrá los datos extraídos
product = {}
# lógica de extracción
brand_element = driver.find_element(By.CSS_SELECTOR, 'h3')
brand = brand_element.text
name_element = driver.find_element(By.CSS_SELECTOR, 'h1')
name = name_element.text
price_elements = name_element
.find_element(By.XPATH, 'following-sibling::*[1]')
.find_elements(By.TAG_NAME, "p")
discount = None
price = None
original_price = None
if len(price_elements) >= 3:
descuento = price_elements[0].text.replace(' off', '')
precio = price_elements[1].text
precio_original = price_elements[2].text
imágenes = []
elementos_imagen = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Galería multimedia del producto"] li')
para elemento_imagen en elementos_imagen:
imagen = elemento_imagen.find_element(By.TAG_NAME, 'img').get_attribute('src')
imágenes.append(imagen)
colores = []
color_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Colores disponibles"] li')
for color_element in color_elements:
color = {
'color': None,
'image': None,
'link': None
}
link_elements = color_element.find_elements(By.TAG_NAME, 'a')
if len(link_elements) > 0:
color['link'] = link_elements[0].get_attribute('href')
image_elements = color_element.find_elements(By.TAG_NAME, 'img')
if len(image_elements) > 0:
color['image'] = image_elements[0].get_attribute('src')
color['color'] = image_elements[0].get_attribute('alt')
.replace('Selected, ', '')
.replace('Unselected, ','')
.strip()
colors.append(color)
delivery = {
'time': None,
'type': None,
'cost': None,
}
delivery_elements = driver
.find_element(By.CSS_SELECTOR, '[data-testid="pdp-delivery-info"]')
.find_element(By.XPATH, 'parent::*[1]')
.find_elements(By.TAG_NAME, 'p')
if len(delivery_elements) == 3:
delivery['time'] = delivery_elements[0].text
delivery['type'] = delivery_elements[1].text
delivery['cost'] = delivery_elements[2].text
info = {}
info_elements = driver.find_elements(By.CSS_SELECTOR, '[data-testid^="pdp-accordion-"]')[:2]
for info_element in info_elements:
info_element.click()
info_section_name = info_element.find_element(By.CSS_SELECTOR, 'h5').text
info[info_section_name] = {}
for dt_element in info_element.find_elements(By.CSS_SELECTOR, 'dt'):
info_section_detail_name = dt_element.text.replace(':', '')
info[info_section_name][info_section_detail_name] = dt_element.find_element(By.XPATH, 'following-sibling::dd').text
# cerrar el navegador y liberar sus recursos
driver.quit()
# asignar los datos extraídos al diccionario
product['brand'] = brand
product['name'] = name
product['price'] = price
product['original_price'] = original_price
product['discount'] = discount
product['images'] = images
product['colors'] = colors
product['delivery'] = delivery
product['info'] = info
print(product)
# exportar los datos extraídos a un archivo JSON
with open('product.json', 'w', encoding='utf-8') as file:
json.dump(product, file, indent=4, ensure_ascii=False)Con poco más de 100 líneas de código, acabas de crear un Scraper de Zalando con todas las funciones para recuperar datos detallados de los productos.
Ejecútalo con:
python Scraper.pyEspera unos segundos a que se complete el script.
Al final del proceso de rastreo, aparecerá un archivo product.json en la carpeta raíz de tu proyecto. Ábrelo y verás:
{
"brand": "adidas Originals",
"name": "3MC UNISEX - Trainers",
"price": "£51.00",
"original_price": "£59.99",
"discount": "15%",
"images": [
"https://img01.ztat.net/article/spp-media-p1/637562911a7e36c28ce77c9db69b4cef/00373c35a7f94b4b84a4e070879289a2.jpg?imwidth=156",
// omitido por brevedad...
«https://img01.ztat.net/article/spp-media-p1/7d4856f0e4803b759145755d10e8e6b6/521545d1286c478695901d26fcd9ed3a.jpg?imwidth=156»
],
"colors": [
{
"color": "footwear white",
"image": "https://img01.ztat.net/article/spp-media-p1/afe668d0109a3de0a5175a1b966bf0c9/c99c48c977ff429f8748f961446f79f5.jpg?imwidth=156&filter=packshot",
"link": null
},
// omitido por brevedad...
{
"color": "blanco",
"imagen": "https://img01.ztat.net/article/spp-media-p1/87e6a1f18ce44e3cbd14da8f10f52dfd/bb1c3a8c409544a085c977d6b4bef937.jpg?imwidth=156&filter=packshot",
"link": "https://www.zalando.co.uk/adidas-originals-3mc-unisex-trainers-white-ad115o0da-a16.html"
}
],
"delivery": {
"time": "2-4 días laborables",
"tipo": "Entrega estándar",
"coste": "gratis"
},
"información": {
"Material y cuidados": {
"Material exterior": "Imitacione de cuero/textil",
"Forro": "Imitacione de cuero/textil",
«Plantilla»: «Tejido»,
«Suela»: «Sintética»,
«Tipo de acolchado»: «Sin forro»,
«Tejido»: «Lona»
},
«Detalles»: {
«Punta del zapato»: «Redonda»,
«Tipo de tacón»: «Plano»,
«Cierre»: «Cordones»,
«Cierre del zapato»: «Cordones»,
«Patrón»: «Liso»,
«Número de artículo»: «AD115O0DA-A11»
}
}
}¡Enhorabuena! ¡Acabas de aprender a extraer datos de Zalando en Python!
Conclusión
En este tutorial, has comprendido por qué Zalando es un sitio de comercio electrónico ideal para extraer datos y cómo hacerlo. Aquí has visto cómo crear un Scraper de Zalando que recupera automáticamente los datos de una página de producto.
Como se muestra aquí, extraer datos de Zalando no es una tarea fácil por al menos tres razones:
- El sitio implementa algunas medidas anti-scraping que podrían bloquear tu script.
- Las páginas web contienen clases CSS aleatorias.
- Cada página de producto tiene una estructura específica y puede contener información diferente.
Para evitar el primer problema y olvidarte de los bloqueos, ¡prueba nuestra nueva solución! El Navegador de scraping es un navegador controlable que gestiona automáticamente los CAPTCHA, las huellas digitales, los reintentos automáticos y mucho más por ti. Sin embargo, seguirás teniendo que escribir código y mantenerlo. Resuelve los dos problemas restantes con una solución lista para usar: ¡echa un vistazo a nuestro Scraper de Zalando!
Nota: esta guía ha sido probada exhaustivamente por nuestro equipo en el momento de su redacción, pero dado que los sitios web actualizan con frecuencia su código y estructura, es posible que algunos pasos ya no funcionen como se esperaba.




