
Las herramientas de automatización del navegador se han convertido en esenciales para los desarrolladores que crean raspadores web, bots o agentes de IA que necesitan interactuar con sitios web. Aunque herramientas de código abierto como Puppeteer y Playwright son ampliamente utilizadas, el navegador de agentes de Bright Data aporta un enfoque diferente, creado para flujos de trabajo sigilosos, escalables y nativos de IA.
En esta guía aprenderás:
- En qué se diferencia Agent Browser de Puppeteer y Playwright en cuanto a sigilo y huellas digitales.
- Las funciones integradas que ofrece Bright Data, como la rotación de proxy y la gestión automatizada de sesiones.
- Escenarios en los que cada herramienta destaca o se queda corta.
- Las limitaciones tanto del navegador de agentes como de los marcos tradicionales, y cuándo elegir uno sobre el otro.
¿Por qué comparar el navegador de agentes, el titiritero y el dramaturgo?
La automatización del navegador se ha convertido en una solución imprescindible para los desarrolladores que crean scrapers, bots y agentes de IA. Ya se trate de recopilar datos de páginas web dinámicas, realizar inicios de sesión automáticos o ejecutar tareas repetitivas a escala, los frameworks de navegador son ahora una parte fundamental de los flujos de trabajo de desarrollo modernos.
Entre las herramientas más populares en este ámbito se encuentran Puppeteer y Playwright, bibliotecas de código abierto basadas en Node.js que ofrecen una API de alto nivel para controlar navegadores completos o sin navegador. Puppeteer, mantenida por el equipo de Chrome, es conocida por su estrecha integración con Chromium y Playwright, desarrollada por Microsoft, se basa en esa base al soportar múltiples navegadores (Chromium, Firefox y WebKit) y permitir funciones más avanzadas como contextos multipágina y esperas integradas. Estas herramientas se han adoptado ampliamente por su flexibilidad y control, especialmente en la creación de flujos de trabajo personalizados.
Sin embargo, a medida que los sitios web incorporan mecanismos de detección de bots cada vez más agresivos, muchos desarrolladores se encuentran pasando más tiempo lidiando con retos como la toma de huellas dactilares, la resolución de CAPTCHA y la rotación de proxy que escribiendo lógica de negocio. Aquí es donde entra en juego nuestro Navegador de Agentes.
Construido específicamente para agentes de IA y flujos de trabajo de automatización, el Navegador de Agentes abstrae gran parte del trabajo de bajo nivel que los usuarios de Puppeteer y Playwright tienen que gestionar manualmente. Se trata de un entorno de navegador completo diseñado para imitar a los usuarios reales, con ocultación, gestión de proxy, persistencia de sesión y gestión de CAPTCHA. Forma parte de la infraestructura más amplia de Bright Data para recopilar datos web a escala, y está diseñado para ayudar a los desarrolladores a centrarse en sus objetivos de automatización en lugar de en la fontanería necesaria para pasar desapercibidos.
Diferencias clave: Sigilo y huella digital
Uno de los mayores retos actuales en la automatización de navegadores es evitar la detección. Los sitios web utilizan cada vez más sofisticados sistemas de detección de bots que controlan todo, desde la falta de coincidencia de las huellas dactilares del navegador hasta los patrones de movimiento del ratón, etc. Aquí es donde herramientas como Puppeteer y Playwright empiezan a mostrar sus límites.
Fuera de la caja, Puppeteer y Playwright no vienen con características de sigilo o anti-detección. Los desarrolladores a menudo tienen que parchear manualmente herramientas como puppeteer-extra-plugin-stealth, rotar proxies o modificar cabeceras y huellas digitales para pasar desapercibidos. Incluso así, las tasas de detección pueden seguir siendo altas, especialmente en sitios con protección avanzada contra bots.
Agent Browser, por su parte, fue diseñado con el sigilo como característica de primera clase. Ejecuta sesiones de navegador headful basadas en la nube que imitan el comportamiento real de los usuarios, con huellas dactilares similares a las humanas, patrones naturales de desplazamiento e interacción y control inteligente de encabezados. Cada sesión se inicia con características realistas del navegador que se alinean con la ubicación, el tipo de dispositivo y la versión del navegador que se está emulando.
Esto es lo que hace nada más sacarlo de la caja:
- Falsificación de huellas dactilares: Agent Browser crea huellas dactilares de navegador que se asemejan a los entornos de usuario reales (a diferencia de las firmas headless predeterminadas).
- Solución de CAPTCHA: Resuelve automáticamente los desafíos cuando aparece un CAPTCHA, lo que reduce las interrupciones en los flujos automatizados.
- Rotación de proxy: Rota las direcciones IP y reintenta las peticiones automáticamente si se detecta un bloqueo.
- Seguimiento de cookies y sesiones: Mantiene el estado de la sesión y las cookies persistentes, reduciendo la detección por peticiones repetidas.
Estas funciones son especialmente importantes cuando se escanean sitios web con diseños dinámicos, puertas de acceso o contenidos personalizados. Por ejemplo, una tienda de comercio electrónico que muestre precios o disponibilidad específicos de una región. En este tipo de plataformas, incluso pequeñas incoherencias en el comportamiento del navegador pueden provocar bloqueos o respuestas vacías. Con Agent Browser, los desarrolladores no necesitan configurar manualmente plugins de ocultación o rotar proxies, todo se gestiona en segundo plano.
Esta estrecha integración con nuestra infraestructura de proxy también significa que los desarrolladores pueden acceder a contenidos de geolocalizaciones específicas, ajustar las cabeceras de los remitentes y mantener sesiones de larga duración, lo que lo convierte en una opción sólida para los flujos de trabajo de agentes de varios pasos.
Gestión de sesiones y autenticación
El manejo de sesiones es mayormente manual con Puppeteer y Playwright; los desarrolladores deben capturar y reutilizar cookies o almacenamiento local, escribir lógica para la persistencia de login, autenticación, y manejar tokens o protección CSRF. Esto aumenta la complejidad, especialmente a escala.
Agent Browser automatiza la persistencia y rotación de sesiones. Las cookies y el almacenamiento local se gestionan automáticamente en la nube, por lo que el estado de la sesión se mantiene en todas las páginas y pestañas sin lógica personalizada. Si se bloquea una sesión, se inicia una nueva con una IP y una huella digital nuevas. No se necesita código de reintento ni de gestión de CAPTCHA.
Esta automatización reduce las prohibiciones de IP, minimiza los fallos de sesión y permite a los desarrolladores centrarse en tareas de automatización en lugar de en la gestión de sesiones. También se integra con la red de proxy de Bright Data para un control de identidad coherente.
Facilidad de uso y experiencia del desarrollador
Uno de los factores clave que los desarrolladores tienen en cuenta a la hora de elegir una herramienta de automatización de navegadores es la rapidez con la que pueden pasar de la configuración a la primera ejecución satisfactoria. Con Puppeteer y Playwright, empezar es muy sencillo si ya has trabajado con navegadores headless. Instalar las librerias, lanzar una instancia del navegador, y navegar por una pagina toma solo unas pocas lineas de codigo. Pero en el momento en que necesites añadir soporte proxy, gestión de CAPTCHA, huellas digitales o persistencia de sesión, las cosas se vuelven más complejas. A menudo tendrás que instalar plugins adicionales, configurar bibliotecas de proxy, gestionar manualmente las cookies y solucionar problemas de detección.
Agent Browser está diseñado para reducir esa complejidad. La integración se puede hacer a través de la API o MCP sin necesidad de configuración por sitio. No hay necesidad de mantener su propia infraestructura de navegador; No hay necesidad de parchear plugins sigilosos o rotar IPs manualmente, todo se maneja automáticamente en segundo plano.
Los desarrolladores pueden elegir entre una experiencia headful o headless, con control programático sobre la sesión de principio a fin. Para aquellos que prefieren flujos de trabajo basados en código, Agent Browser es compatible con Playwright, Puppeteer y Selenium. Los ejemplos de código a continuación le ayudarán a conectarlo a su pila ya existente con la mínima fricción.
JavaScript:
const pw = require('playwright');
const SBR_CDP = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222';
async function main() {
console.log('Connecting to Scraping Browser...');
// Scraping browswer here...
const browser = await pw.chromium.connectOverCDP(SBR_CDP);
try {
const page = await browser.newPage();
console.log('Connected! Navigating to <https://example.com>...');
await page.goto('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html);
} finally {
await browser.close();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
const puppeteer = require('puppeteer-core');
const SBR_WS_ENDPOINT = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222';
async function main() {
console.log('Connecting to Scraping Browser...');
const browser = await puppeteer.connect({
// Scraping browswer here...
browserWSEndpoint: SBR_WS_ENDPOINT,
});
try {
const page = await browser.newPage();
console.log('Connected! Navigating to <https://example.com>...');
await page.goto('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html)
} finally {
await browser.close();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
const { Builder, Browser } = require('selenium-webdriver');
const SBR_WEBDRIVER = '<https://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9515>';
async function main() {
console.log('Connecting to Scraping Browser...');
const driver = await new Builder()
.forBrowser(Browser.CHROME)
// Scraping browswer here...
.usingServer(SBR_WEBDRIVER)
.build();
try {
console.log('Connected! Navigating to <https://example.com>...');
await driver.get('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await driver.getPageSource();
console.log(html);
} finally {
driver.quit();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
Python:
import asyncio
from playwright.async_api import async_playwright
SBR_WS_CDP = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222'
async def run(pw):
print('Connecting to Scraping Browser...')
# Scraping browswer here...
browser = await pw.chromium.connect_over_cdp(SBR_WS_CDP)
try:
page = await browser.new_page()
print('Connected! Navigating to <https://example.com>...')
await page.goto('<https://example.com>')
print('Navigated! Scraping page content...')
html = await page.content()
print(html)
finally:
await browser.close()
async def main():
async with async_playwright() as playwright:
await run(playwright)
if __name__ == '__main__':
asyncio.run(main())
const puppeteer = require('puppeteer-core');
const SBR_WS_ENDPOINT = 'wss://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9222';
async function main() {
console.log('Connecting to Scraping Browser...');
const browser = await puppeteer.connect({
# Scraping browswer here...
browserWSEndpoint: SBR_WS_ENDPOINT,
});
try {
const page = await browser.newPage();
console.log('Connected! Navigating to <https://example.com>...');
await page.goto('<https://example.com>');
console.log('Navigated! Scraping page content...');
const html = await page.content();
console.log(html)
} finally {
await browser.close();
}
}
main().catch(err => {
console.error(err.stack || err);
process.exit(1);
});
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
SBR_WEBDRIVER = '<https://brd-customer-CUSTOMER_ID-zone-ZONE_NAME:[email protected]:9515>'
def main():
print('Connecting to Scraping Browser...')
# Scraping browswer here...
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, 'goog', 'chrome')
with Remote(sbr_connection, options=ChromeOptions()) as driver:
print('Connected! Navigating to <https://example.com>...')
driver.get('<https://example.com>')
print('Navigated! Scraping page content...')
html = driver.page_source
print(html)
if __name__ == '__main__':
main()
El objetivo es sencillo: eliminar la configuración repetitiva para que los desarrolladores puedan centrarse en lo que debe hacer su automatización, no en cómo mantenerla en funcionamiento de forma fiable.
Bajo el capó: funciones integradas con datos brillantes
Lo que diferencia al Navegador de Agentes es lo que ya se incluye cuando se inicia la sesión.
- La rotación de proxy se gestiona automáticamente. Cada sesión está respaldada por nuestra amplia red de proxy, que incluye más de 150 millones de IP residenciales en 195 países.
- Las huellas dactilares de los navegadores se asemejan a las humanas por su diseño, evitando los signos reveladores sin cabeza y emulando entornos reales (hasta el dispositivo, el sistema operativo y la versión del navegador).
- Laresolución de CAPTCHA está incorporada, no se requieren servicios externos, no se cuelgan sesiones fallidas debido a desafíos visuales.
- La persistencia de la sesión es consistente. Se conservan las pestañas, las cookies y el almacenamiento local, lo que es fundamental para tareas como el scraping autenticado o los flujos de trabajo basados en pasos.
- El control de referencias y cabeceras permite simular visitas procedentes de fuentes conocidas o de confianza, lo que resulta útil en situaciones en las que las cabeceras HTTP afectan a la entrega de la página.
Todo ello está integrado en un entorno estandarizado basado en la nube, por lo que se obtiene un rendimiento constante independientemente de dónde y cuándo se ejecute la sesión. Es escalable, accesible mediante API y está estrechamente integrado con el canal de datos más amplio, por lo que el resultado está inmediatamente listo para la IA, estructurado o sin procesar, en tiempo real o por lotes.
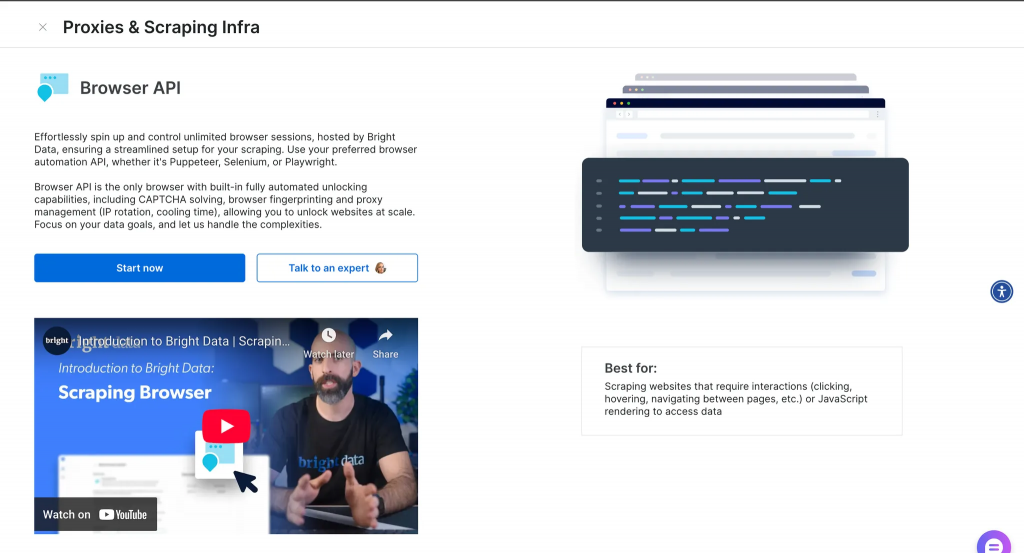
A continuación encontrará un resumen de lo que obtendrá en su panel de control tras crear una cuenta.

Tras hacer clic en más información, obtendrá más datos, como se ve a continuación.
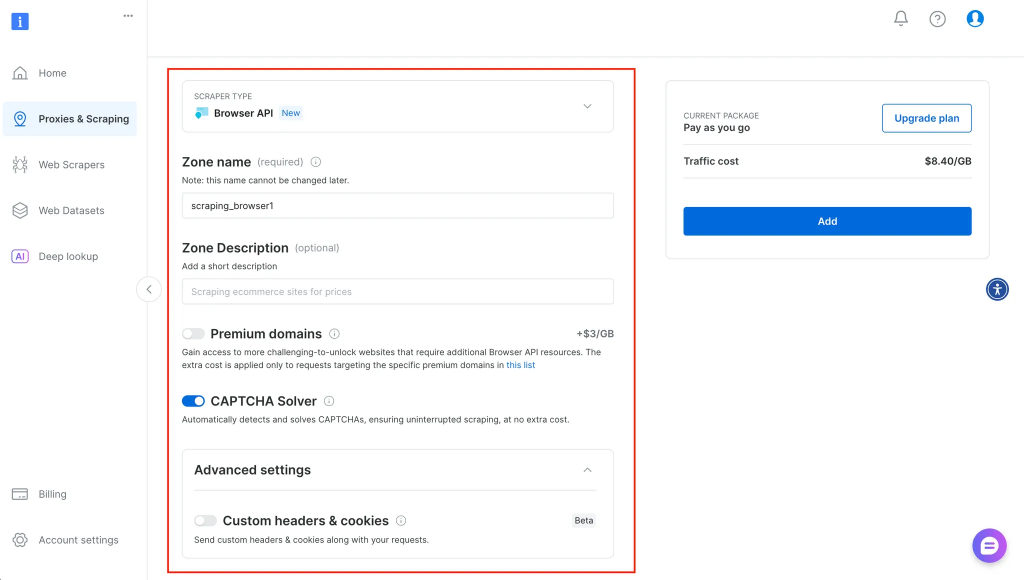
Después de hacer clic en Inicio, se le redirigirá a un lugar donde podrá introducir más información sobre su servicio y configurarlo en consecuencia, como se muestra a continuación:
Elegir la herramienta adecuada: Cuándo tiene sentido cada una
Cada herramienta tiene su lugar, y saber cuándo utilizar una en lugar de otra puede ahorrar tiempo y frustración.
Utilice el Navegador de Agentes si:
- Necesita manejar mecanismos anti-bot avanzados sin construir capas de ocultación personalizadas.
- Sus flujos de trabajo implican tareas de varios pasos que requieren la persistencia de la sesión (por ejemplo, inicios de sesión, envío de formularios).
- Desea lanzar y escalar cientos o miles de sesiones de navegación a través de diferentes geolocalizaciones.
- Prefieres centrarte en lo que hace el agente, no en cómo gestionar su infraestructura.
Quédate con Titiritero o Dramaturgo si:
- Su tarea es a pequeña escala, rápida y local, como un script que extrae algunos titulares o automatiza las pruebas en CI.
- Desea un control total sobre el entorno del navegador y no necesita un desbloqueo incorporado.
- Estás operando en un entorno offline o seguro en el que no es posible utilizar un navegador remoto.
En algunos casos, lo mejor es un enfoque híbrido. Por ejemplo, puede ejecutar los scripts de Playwright localmente pero utilizar proxies de Bright Data para gestionar la rotación de IP y la geolocalización. O utilizar el MCP Web para objetivos de alto riesgo y marcos de código abierto para el scraping de baja fricción.
Limitaciones y consideraciones
Ninguna herramienta es perfecta y cada una tiene sus ventajas y desventajas.
La naturaleza basada en la nube de Agent Browser significa que no está diseñado para el uso fuera de línea o entornos donde la localización de datos es crítica. Para los equipos que trabajan en sectores regulados o con redes restringidas, puede seguir siendo preferible ejecutar los navegadores localmente.
Puppeteer y Playwright, aunque flexibles, requieren un mantenimiento constante a medida que los sitios web evolucionan. Las nuevas técnicas de detección de bots o los cambios de diseño suelen romper los scripts existentes, especialmente cuando los plugins de ocultación se quedan obsoletos. Y a medida que aumenta la escala, el mantenimiento de la infraestructura del navegador, la rotación de IP y la prevención de bloqueos pueden convertirse en una preocupación a tiempo completo.
También hay que tener en cuenta que Agent Browser está diseñado para sitios web públicos y tareas de automatización alineadas con el scraping ético. No está pensado para saltarse los muros de acceso sin permiso ni para el scraping de contenidos detrás de muros de pago.
Conclusión y próximos pasos
La elección entre Agent Browser, Puppeteer y Playwright se reduce a lo que exige su flujo de trabajo. Si necesita sigilo, escala y simplicidad, Agent Browser ofrece automatización sin complicaciones. Si estás construyendo algo rápido y local con control total, Puppeteer y Playwright son opciones sólidas. En cualquier caso, comprender en qué se diferencian, especialmente en lo que respecta a la gestión de sesiones, las huellas digitales y la infraestructura, puede ayudarle a evitar pérdidas de tiempo y flujos rotos.
Puedes explorar el Navegador de Agentes o conectarlo a tu pila de automatización existente usando Playwright, Puppeteer, o incluso MCP. Para más información, echa un vistazo a nuestra guía sobre web scraping con ChatGPT o la creación de agentes con MCP.





