El scraping web se encuentra en un punto de inflexión, ya que los métodos tradicionales están siendo frustrados por sofisticadas defensas anti-bot, y los desarrolladores están constantemente parcheando scripts frágiles. Aunque siguen funcionando, sus limitaciones son evidentes, sobre todo si se comparan con las modernas infraestructuras de scraping nativas de IA que ofrecen resistencia y escalabilidad. Con un mercado de agentes de IA que crecerá de 7.840 millones de dólares a 52.620 millones en 2030, el futuro del acceso a los datos está en los sistemas inteligentes y autónomos.
Al combinar el marco de agente autónomo de CrewAI con la sólida infraestructura de Bright Data, obtendrá una pila de scraping que razona y supera las barreras anti-bot. En este tutorial, creará un agente de raspado impulsado por IA que proporciona datos fiables en tiempo real.
Los límites del scraping tradicional
El scraping tradicional es frágil: se basa en selectores CSS o XPath estáticos que se rompen con cualquier ajuste del front-end. Los principales retos son:
- Defensas anti-bot. CAPTCHAs, IP throttling y fingerprinting bloquean los rastreadores simples.
- Páginas con mucho JavaScript. React, Angular y Vue construyen el DOM en el navegador, por lo que las llamadas HTTP sin procesar se pierden la mayor parte del contenido.
- HTML desestructurado. El HTML incoherente y los datos en línea dispersos exigen un análisis sintáctico y un posprocesamiento intensivos antes de su uso.
- Cuellos de botella en el escalado. Orquestar proxies, reintentos y parches continuos se convierte en una carga operativa agotadora e interminable.
Cómo CrewAI y Bright Data agilizan el scraping
La construcción de un rascador autónomo se basa en dos pilares: un “cerebro” adaptable y un “cuerpo” resistente.
- CrewAI (El cerebro). Un tiempo de ejecución multiagente de código abierto que permite crear una “tripulación” de agentes capaces de planificar, razonar y coordinar trabajos de scraping de extremo a extremo.
- MCP de Bright Data (el cuerpo). Una pasarela de datos en directo que enruta cada solicitud a través de la pila Unlocker de Bright Data -rotación de IP, resolución de CAPTCHA y ejecución de navegadores sin cabeza- para que los LLM reciban HTML o JSON limpios de una sola vez. La implementación de Bright Data es la fuente líder del sector de datos fiables para agentes de IA.
Juntos, este combo de cerebro y cuerpo permite a sus agentes pensar, recuperar y adaptarse prácticamente en cualquier sitio.
¿Qué es CrewAI?
CrewAI es un marco de código abierto para orquestar agentes de IA cooperativos. El usuario define la función, el objetivo y las herramientas de cada agente y los agrupa en una tripulación para ejecutar flujos de trabajo de varios pasos.
Componentes básicos:
- Agente. Un trabajador dirigido por LLM con un papel, un objetivo y una historia de fondo opcional, que proporciona el contexto del dominio del modelo.
- Tarea. Un único trabajo bien definido para un agente, además de un resultado esperado que sirve como puerta de calidad.
- Herramienta. Cualquier llamada que el agente pueda invocar: una obtención HTTP, una consulta a la base de datos o el punto final MCP de Bright Data para el scraping.
- Tripulación. Conjunto de agentes y sus tareas que trabajan en pos de un objetivo.
- Proceso. El plan de ejecución -secuencial, paralelo o jerárquico- que controla el orden de las tareas, la delegación y los reintentos.
Es el reflejo de un verdadero equipo: los especialistas se ocupan de su parte, transmiten los resultados y escalan cuando es necesario.
¿Qué es el Protocolo de Contexto Modelo (MCP)?
MCP es un estándar abierto JSON-RPC 2.0 que permite a los agentes de IA llamar a herramientas y fuentes de datos externas a través de una interfaz única y estructurada. Es como un puerto USB-C para modelos: un enchufe para muchos dispositivos.
El servidor MCP de Bright Data convierte esa norma en práctica al conectar un agente directamente a la pila de raspado de Bright Data, lo que hace que el raspado web con MCP no sólo sea más potente, sino mucho más sencillo que las pilas tradicionales:
- Anulación de robots. Las solicitudes fluyen a través de Web Unlocker y un grupo de más de 150 millones de IP residenciales rotativas que abarcan 195 países.
- Compatibilidad con sitios dinámicos. Un navegador de raspado específico renderiza JavaScript para que los agentes vean el DOM completamente cargado.
- Resultados estructurados. Muchas herramientas devuelven JSON limpio, eliminando los analizadores personalizados.
El servidor publica más de 50 herramientas listas para usar, desde URL genéricas hasta raspadores específicos de sitios, para que su agente CrewAI pueda obtener precios de productos, datos de SERP o instantáneas de DOM con una sola llamada.
Crear su primer agente de AI Scraping
Construyamos un agente CrewAI que extraiga detalles de una página de producto de Amazon y los devuelva como JSON estructurado. Puedes redirigir fácilmente la misma pila a otro sitio modificando solo algunas líneas.
Requisitos previos
- Python 3.11 – Recomendado por estabilidad.
- Node.js + npm – Necesario para ejecutar el servidor MCP de Bright Data; descárguelo del sitio oficial.
- Entorno virtual Python – Mantiene las dependencias aisladas; consulte la documentación de
venv. - Cuenta de Bright Data: regístrese y cree un token de API (hay disponibles créditos de prueba gratuitos).
- Clave API de Google Gemini: cree una clave en Google AI Studio (haga clic en + Crear clave API). El nivel gratuito permite 15 solicitudes por minuto y 500 solicitudes por día. No se requiere perfil de facturación.
Arquitectura
Environment Setup → LLM Config → MCP Server Init →
Agent Definition → Task Definition → Crew Execution → JSON OutputPaso 1. Configuración del entorno e importaciones
mkdir crewai-bd-scraper && cd crewai-bd-scraper
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install "crewai-tools[mcp]" crewai mcp python-dotenv
from crewai import Agent, Task, Crew, Process
from crewai_tools import MCPServerAdapter
from mcp import StdioServerParameters
from crewai.llm import LLM
import os
from dotenv import load_dotenv
load_dotenv() # Load credentials from .envPaso 2. Configurar claves de API y zonas
Cree un archivo .env en la raíz de su proyecto:
BRIGHT_DATA_API_TOKEN="…"
WEB_UNLOCKER_ZONE="…"
BROWSER_ZONE="…"
GEMINI_API_KEY="…"Lo necesitas:
- Token de API. Generar un nuevo token de API.
- Zona Web Unlocker. Crear una nueva zona Web Unlocker. Si se omite, se crea una zona por defecto llamada
mcp_unlocker. - Zona API del navegador. Crear una nueva zona API de navegador. Sólo es necesaria para los destinos con mucho JavaScript. Copie la cadena de nombre de usuario que aparece en la pestaña Descripción general de la zona.
- Clave API de Google Gemini. Ya creada en Requisitos previos.
Paso 3. Configuración de LLM (Gemini) Configuración LLM (Gemini)
Configure el LLM (Gemini 1.5 Flash) para una salida determinista:
llm = LLM(
model="gemini/gemini-1.5-flash",
api_key=os.getenv("GEMINI_API_KEY"),
temperature=0.1,
)Paso 4. Configuración de Bright Data MCP
Configure el servidor MCP de Bright Data. Esto indica a CrewAI cómo iniciar el servidor y pasar las credenciales:
server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": os.getenv("WEB_UNLOCKER_ZONE"),
"BROWSER_ZONE": os.getenv("BROWSER_ZONE"),
},
)Esto lanza *npx @brightdata/mcp* como un subproceso y expone más de 50 herramientas (≈ 57 en el momento de escribir esto) a través del estándar MCP.
Paso 5. Definición de agentes y tareas Definición de agentes y tareas
Aquí definimos la persona del agente y la tarea específica que debe realizar. Las implantaciones eficaces de CrewAI siguen la regla 80/20: dedicar el 80% del esfuerzo al diseño de la tarea y el 20% a la definición del agente.
def build_scraper_agent(mcp_tools):
return Agent(
role="Senior E-commerce Data Extractor",
goal=(
"Return a JSON object with snake_case keys containing: title, current_price, "
"original_price, discount, rating, review_count, last_month_bought, "
"availability, product_id, image_url, brand, and key_features for the "
"target product page. Ensure strict schema validation."
),
backstory=(
"Veteran web-scraping engineer with years of experience reverse-"
"engineering Amazon, Walmart, and Shopify layouts. Skilled in "
"Bright Data MCP, proxy rotation, CAPTCHA avoidance, and strict "
"JSON-schema validation."
),
tools=mcp_tools,
llm=llm,
max_iter=3,
verbose=True,
)
def build_scraping_task(agent):
return Task(
description=(
"Extract product data from https://www.amazon.in/dp/B071Z8M4KX "
"and return it as structured JSON."
),
expected_output="""{
"title": "Product name",
"current_price": "$99.99",
"original_price": "$199.99",
"discount": "50%",
"last_month_bought": 150,
"rating": 4.5,
"review_count": 1000,
"availability": "In Stock",
"product_id": "ABC123",
"image_url": "https://example.in/image.jpg",
"brand": "BrandName",
"key_features": ["Feature 1", "Feature 2"],
}""",
agent=agent,
)Esto es lo que hace cada parámetro:
- rol – Título corto del trabajo, CrewAI inyecta en cada pregunta del sistema.
- meta – Objetivo norte-estrella; CrewAI lo compara después de cada bucle para decidir si se detiene.
- backstory – Contexto de dominio que guía el tono y reduce las alucinaciones.
- tools – Lista de objetos
BaseTool(por ejemplo, MCPsearch_engine,scrape_as_markdown). - llm – Modelo que CrewAI utiliza para cada ciclo pensar → planificar → actuar → responder.
- max_iter – Límite máximo de los bucles internos del agente (por defecto 20 en v0.30 +).
- verbose – Transmite todos los mensajes, pensamientos y llamadas a herramientas a stdout (útil para depuración).
- descripción – La instrucción orientada a la acción se inyecta cada turno.
- expected_output – Contrato formal de una respuesta válida (utilice JSON estricto, sin coma final).
- agent – Vincula esta tarea a una instancia de
agenteespecífica paraCrew.kickoff().
Paso 6. Reunión y ejecución de la tripulación
Esta parte ensambla el agente y la tarea en un Crew y ejecuta el flujo de trabajo.
def scrape_product_data():
"""Assembles and runs the scraping crew."""
with MCPServerAdapter(server_params) as mcp_tools:
scraper_agent = build_scraper_agent(mcp_tools)
scraping_task = build_scraping_task(scraper_agent)
crew = Crew(
agents=[scraper_agent],
tasks=[scraping_task],
process=Process.sequential,
verbose=True
)
return crew.kickoff()
if __name__ == "__main__":
try:
result = scrape_product_data()
print("n[SUCCESS] Scraping completed!")
print("Extracted product data:")
print(result)
except Exception as e:
print(f"n[ERROR] Scraping failed: {str(e)}")Paso 7. Funcionamiento del rascador
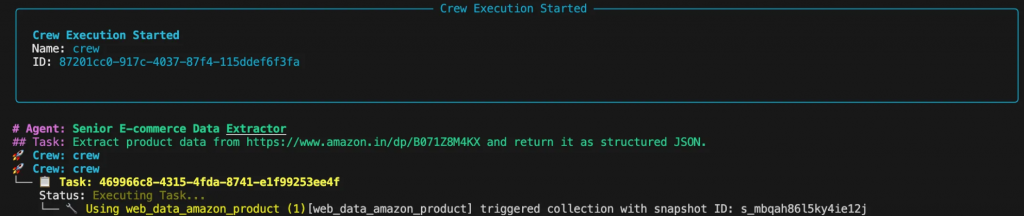
Ejecute el script desde su terminal. Verás el proceso de pensamiento del agente en la consola mientras planifica y ejecuta la tarea.
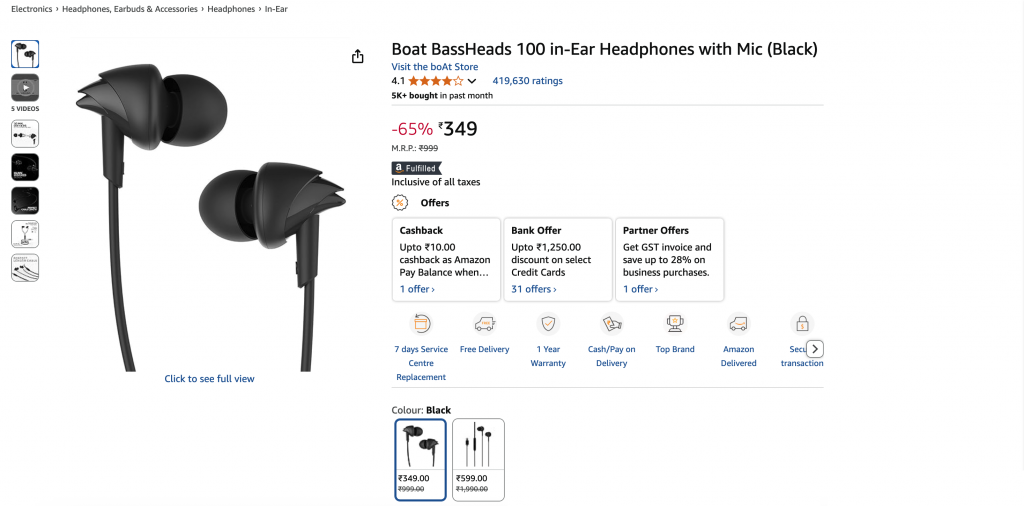
El resultado final será un objeto JSON limpio:
{
"title": "Boat BassHeads 100 in-Ear Headphones with Mic (Black)",
"current_price": "₹349",
"original_price": "₹999",
"discount": "-65%",
"rating": 4.1,
"review_count": 419630,
"last_month_bought": 5000,
"availability": "In stock",
"product_id": "B071Z8M4KX",
"image_url": "https://m.media-amazon.com/images/I/513ugd16C6L._SL1500_.jpg",
"brand": "boAt",
"key_features": [
"10mm dynamic driver",
"HD microphone",
"1.2 m cable",
"Comfortable fit",
"1 year warranty"
]
}Adaptación a otros objetivos
La verdadera fuerza de un diseño basado en agentes es su flexibilidad. ¿Quieres buscar publicaciones de LinkedIn en lugar de productos de Amazon? Basta con actualizar el papel, el objetivo y la historia del agente, además de la descripción de la tarea y el resultado esperado. Todo lo demás, incluido el código y la infraestructura subyacentes, permanece exactamente igual.
role = "Senior LinkedIn Post Extractor"
goal = (
"Return a JSON object containing: author_name, author_title, "
"author_profile_url, post_content, post_date, likes_count, "
"and comments_count"
)
backstory = (
"Seasoned social-data engineer specializing in LinkedIn data "
"extraction using Bright Data MCP. Produces clean, structured "
"JSON output."
)
description = (
"Extract post data from LinkedIn post (ID: orlenchner_agents-"
"brightdata-activity-7336402761892122625-h5Oa) and return "
"structured JSON."
)
expected_output = """{
"author_name": "Post author's full display name",
"author_title": "Author's job title/headline",
"author_profile_url": "Author's profile URL",
"post_content": "Complete post text with formatting",
"post_date": "ISO 8601 UTC timestamp",
"likes_count": "Number of post likes",
"comments_count": "Number of post comments",
}"""La salida será un objeto JSON limpio:
{
"author_name": "Or Lenchner",
"author_title": "CEO at Bright Data - Keeping public web data, public.",
"author_profile_url": "https://il.linkedin.com/in/orlenchner",
"post_content": "NEW PRODUCT! There’s a consensus that the future internet will be run by automated #Agents , automating the activity on behalf of “their” humans. AI solved the automation part (or at least shows strong indications), but the number one problem is ensuring smooth access to every website at scale without being blocked. browser.ai is the solution → Your Agent always gains access to any website with a simple prompt. Agents using Bright Data are already executing hundreds of millions of web actions daily on our browser infrastructure. #BrightData has long been the go-to for major LLM companies, providing the tools and scale they need to train and deploy such technologies. With browser.ai , we’re taking that foundation and tailoring it specifically for AI agents, optimizing our APIs, proxy networks, and serverless browsers to handle their unique demands. The web isn’t fully prepared for this shift yet, but we are. browser.ai immediate focus is to ensure *smooth* access to any website (DONE!), while phase two will be all about *fast* access (wip). https://browser.ai/",
"post_date": "2026-06-05T14:45:22.155Z",
"likes_count": 119,
"comments_count": 7
}Optimización de costes
El MCP de Bright Data se basa en el uso, por lo que cada solicitud adicional se añade a su factura. Algunas opciones de diseño mantienen los costes bajo control:
- Rastreo selectivo. Solicite solo los campos que necesita en lugar de rastrear páginas o conjuntos de datos enteros.
- Caché. Activa la caché a nivel de herramienta de CrewAI
(cache_function) para omitir llamadas cuando el contenido no haya cambiado, ahorrando tiempo y créditos. - Selección eficiente de herramientas. Utilice por defecto la zona Web Unlocker y cambie a una zona Browser API sólo cuando la renderización de JavaScript sea esencial.
- Establecer
max_iter. Da a cada agente un límite superior razonable para que no pueda hacer un bucle eterno en una página rota. (También puedes acelerar las peticiones conmax_rpm).
Siga estas prácticas y sus agentes CrewAI se mantendrán seguros, fiables y rentables, listos para cargas de trabajo de producción en Bright Data MCP.
El futuro
El ecosistema MCP sigue expandiéndose: La API Responses de OpenAI y el SDK Gemini de Google DeepMind ya hablan MCP de forma nativa, lo que garantiza la compatibilidad a largo plazo y la inversión continua.
CrewAI está desplegando agentes multimodales, depuración más rica y RBAC empresarial, mientras que el servidor MCP de Bright Data expone más de 60 herramientas preparadas y sigue creciendo.
Juntos, los marcos de agentes y el acceso estandarizado a los datos abren una nueva ola de inteligencia web para aplicaciones impulsadas por IA. Las guías sobre la conexión de MCP al SDK de agentes de OpenAI ponen de relieve lo esenciales que se han vuelto las canalizaciones de datos sólidas como una roca.
En última instancia, no se trata sólo de construir un rascador, sino de orquestar un flujo de trabajo de datos adaptable construido para la web del futuro.
¿Necesita más escala? Olvídese del mantenimiento de los rascadores y de la lucha contra los bloqueos: sólo tiene que solicitar datos estructurados:
- API de rastreo: extracción de sitios completos a gran escala.
- API de Web Scraper: más de 120 puntos finales específicos de dominio.
- API SERP: raspado de motores de búsqueda sin complicaciones.
- Mercado de conjuntos de datos: conjuntos de datos nuevos y validados bajo demanda.
¿Listo para crear aplicaciones de IA de última generación? Explore el paquete completo de productos de IA de Bright Data y descubra lo que el acceso web en directo y sin interrupciones puede hacer por sus agentes. Para profundizar más, consulte nuestras guías MCP para Qwen-Agent y Google ADK.