
En este artículo aprenderás:
- Cómo crear un agente de IA listo para la producción que conserve las conversaciones en bases de datos
- Cómo implementar la extracción inteligente de datos y el seguimiento de entidades
- Cómo crear un manejo de errores robusto con recuperación automática
- Cómo mejorar su agente con datos web en tiempo real de Bright Data
¡Empecemos!
El reto de las conversaciones de IA sin estado
Los agentes de IA actuales suelen funcionar como sistemas sin estado. Tratan cada conversación como un evento independiente. Esta falta de contexto histórico hace que los usuarios repitan la información. Como resultado, se producen ineficiencias operativas y frustración por parte de los usuarios. Además, las empresas pierden la oportunidad de utilizar datos a largo plazo para la personalización o la mejora del servicio.
La IA con datos persistentes resuelve este problema registrando todas las interacciones en una base de datos estructurada. Al mantener un registro continuo, estos sistemas pueden recordar el contexto histórico, realizar un seguimiento de entidades específicas a lo largo del tiempo y utilizar patrones de interacción pasados para proporcionar una experiencia de usuario coherente y personalizada.
Lo que estamos construyendo: sistema de agente de IA conectado a una base de datos
Crearemos un agente de IA listo para la producción que procese mensajes utilizando LangChain y GPT-4. Guarda cada conversación en PostgreSQL. Extrae entidades e información en tiempo real. Mantiene un historial completo de conversaciones entre sesiones. Gestiona los errores con sistemas de reintento automático. Ofrece supervisión con registro.
El sistema se encargará de:
- Esquema de base de datos con relaciones e índices adecuados
- Agente LangChain con herramientas de base de datos personalizadas
- Persistencia automática de conversaciones y extracción de entidades
- Proceso de fondo para la recopilación de datos
- Gestión de errores con gestión de transacciones
- Interfaz de consulta para recuperar datos históricos
- Integración de RAG con Bright Data para inteligencia web
Requisitos previos
Configure su entorno de desarrollo con:
- Python 3.10 o superior. Requerido para funciones asíncronas modernas y sugerencias de tipos
- PostgreSQL 14+ o SQLite 3.35+. Base de datos para la persistencia de datos
- Clave API de OpenAI. Para acceder a GPT-4. Obténla en la plataforma OpenAI
- LangChain. Marco para crear agentes de IA. Consulte la documentación
- Entorno virtual Python. Mantiene las dependencias aisladas. Consulte la documentación
de venv
Configuración del entorno
Cree el directorio de su proyecto e instale las dependencias:
mkdir database-agent
cd database-agent
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venv\Scripts\activate
pip install langchain langchain-openai sqlalchemy psycopg2-binary python-dotenv pydanticCree un nuevo archivo llamado agent.py y añada las siguientes importaciones:
import os
import json
import logging
import time
from datetime import datetime, timedelta
from typing import List, Dict, Any, Optional
from queue import Queue
from threading import Thread
# Importaciones de SQLAlchemy
from sqlalchemy import create_engine, Column, Integer, String, Text, DateTime, Float, JSON, ForeignKey, text
from sqlalchemy.orm import sessionmaker, relationship, Session, declarative_base
from sqlalchemy.pool import QueuePool
from sqlalchemy.exc import SQLAlchemyError
# Importaciones de LangChain
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.tools import Tool
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.schema import HumanMessage, AIMessage, SystemMessage
# Importaciones RAG
from langchain_community.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
import requests
# Configuración del entorno
from dotenv import load_dotenv
load_dotenv()
# Configurar el registro
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)Crea un archivo .env con tus credenciales:
# Configuración de la base de datos
DATABASE_URL="postgresql://username:password@localhost:5432/agent_db"
# O para SQLite: DATABASE_URL="sqlite:///./agent_data.db"
# Claves API
OPENAI_API_KEY="your-openai-api-key"
# Opcional: Bright Data (para el paso 7)
BRIGHT_DATA_API_KEY="tu-clave-api-bright-data"
# Configuración de la aplicación
AGENT_MODEL="gpt-4-turbo-preview"
CONNECTION_POOL_SIZE=5
MAX_RETRIES=3Necesitas:
- URL de la base de datos: cadena de conexión para PostgreSQL o SQLite
- Clave API de OpenAI: para la inteligencia del agente a través de GPT-4
- Clave de la API de Bright Data: opcional, para datos web en tiempo real en el paso 7
Creación de su agente de IA conectado a la base de datos
Paso 1: Diseñar el esquema de la base de datos
Diseñe tablas para usuarios, conversaciones, mensajes y entidades extraídas. El esquema utiliza claves externas y relaciones para mantener la integridad de los datos.
Base = declarative_base()
class User(Base):
"""Tabla de perfiles de usuario: almacena la información y las preferencias del usuario."""
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
user_id = Column(String(255), unique=True, nullable=False, index=True)
name = Column(String(255))
email = Column(String(255))
preferences = Column(JSON, default={})
created_at = Column(DateTime, default=datetime.utcnow)
last_active = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
# Relaciones
conversaciones = relationship("Conversación", back_populates="usuario", cascade="todo, eliminar huérfanos")
def __repr__(self):
return f"<Usuario(user_id='{self.user_id}', nombre='{self.name}')>"
class Conversation(Base):
"""Tabla de sesiones de conversación: realiza un seguimiento de las sesiones de conversación individuales."""
__tablename__ = 'conversations'
id = Column(Integer, primary_key=True)
conversation_id = Column(String(255), unique=True, nullable=False, index=True)
user_id = Column(Integer, ForeignKey('users.id'), nullable=False)
title = Column(String(500))
summary = Column(Text)
status = Column(String(50), default='active') # active, archived, deleted
meta_data = Column(JSON, default={})
created_at = Column(DateTime, default=datetime.utcnow)
updated_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
# Relaciones
usuario = relación("Usuario", back_populates="conversaciones")
mensajes = relación("Mensaje", back_populates="conversación", cascade="todo, eliminar huérfanos")
entidades = relación("Entidad", back_populates="conversación", cascade="todo, eliminar huérfanos")
def __repr__(self):
return f"<Conversation(id='{self.conversation_id}', user='{self.user_id}')>"
class Message(Base):
"""Tabla de mensajes individuales: almacena cada mensaje de una conversación."""
__tablename__ = 'messages'
id = Column(Integer, primary_key=True)
conversation_id = Column(Integer, ForeignKey('conversations.id'), nullable=False, index=True)
role = Column(String(50), nullable=False) # usuario, asistente, sistema
content = Column(Text, nullable=False)
tokens = Column(Integer)
model = Column(String(100))
meta_data = Column(JSON, default={})
created_at = Column(DateTime, default=datetime.utcnow)
# Relaciones
conversation = relationship("Conversation", back_populates="messages")
def __repr__(self):
return f"<Message(role='{self.role}', conversation='{self.conversation_id}')>"
class Entity(Base):
"""Tabla de entidades extraídas: almacena entidades con nombre extraídas de conversaciones."""
__tablename__ = 'entities'
id = Column(Integer, primary_key=True)
conversation_id = Column(Integer, ForeignKey('conversations.id'), nullable=False, index=True)
entity_type = Column(String(100), nullable=False, index=True) # persona, organización, ubicación, etc.
entity_value = Column(String(500), nullable=False)
context = Column(Text)
confidence = Column(Float, default=0.0)
meta_data = Column(JSON, default={})
extracted_at = Column(DateTime, default=datetime.utcnow)
# Relaciones
conversation = relationship("Conversation", back_populates="entities")
def __repr__(self):
return f"<Entity(type='{self.entity_type}', value='{self.entity_value}')>"
class AgentLog(Base):
"""Tabla de registros de operaciones del agente: almacena registros operativos para su supervisión."""
__tablename__ = 'agent_logs'
id = Column(Integer, primary_key=True)
conversation_id = Column(String(255), index=True)
level = Column(String(50), nullable=False) # INFO, WARNING, ERROR
operation = Column(String(255), nullable=False)
message = Column(Text, nullable=False)
error_details = Column(JSON)
execution_time = Column(Float) # en segundos
created_at = Column(DateTime, default=datetime.utcnow)
def __repr__(self):
return f"<AgentLog(level='{self.level}', operation='{self.operation}')>"El esquema define cinco tablas principales. El usuario almacena perfiles con preferencias JSON para datos flexibles. La conversación realiza un seguimiento de las sesiones con seguimiento de estado. El mensaje contiene intercambios individuales con indicadores de rol para mensajes de usuario frente a mensajes de asistente. La entidad captura información extraída con puntuaciones de confianza. AgentLog proporciona seguimiento de operaciones para la supervisión. Las claves externas mantienen la integridad referencial. Los índices en campos consultados con frecuencia optimizan el rendimiento. La configuración cascade="all, delete-orphan" limpia los registros relacionados cuando se eliminan los registros principales.
Paso 2: Configuración de la capa de conexión de la base de datos
Configure el administrador de conexiones de la base de datos con SQLAlchemy. El administrador se encarga del agrupamiento de conexiones, las comprobaciones de estado y la lógica de reintentos automáticos para garantizar la fiabilidad.
class DatabaseManager:
"""
Gestiona las conexiones y operaciones de la base de datos.
Características:
- Agrupación de conexiones para un uso eficiente de los recursos
- Comprobaciones de estado para verificar la conectividad de la base de datos
- Creación automática de tablas
"""
def __init__(self, database_url: str, pool_size: int = 5, max_retries: int = 3):
"""
Inicializa el gestor de bases de datos.
Argumentos:
database_url: Cadena de conexión a la base de datos (por ejemplo, 'sqlite:///./agent_data.db')
pool_size: Número de conexiones que se mantendrán en el grupo
max_retries: Número máximo de intentos de reintento para operaciones fallidas
"""
self.database_url = database_url
self.max_retries = max_retries
# Crear motor con agrupación de conexiones
self.engine = create_engine(
database_url,
poolclass=QueuePool,
pool_size=pool_size,
max_overflow=10,
pool_pre_ping=True, # Verificar conexiones antes de usar
echo=False # Establecer en True para la depuración de SQL
)
# Crear fábrica de sesiones
self.SessionLocal = sessionmaker(
bind=self.engine,
autocommit=False,
autoflush=False
)
logger.info(f"✓ Motor de base de datos creado con {pool_size} grupo de conexiones")
def initialize_database(self):
"""Crear todas las tablas de la base de datos."""
try:
Base.metadata.create_all(bind=self.engine)
logger.info("✓ Tablas de la base de datos creadas correctamente")
except Exception as e:
logger.error(f"❌ Error al crear las tablas de la base de datos: {e}")
raise
def get_session(self) -> Session:
"""Obtener una nueva sesión de base de datos para realizar operaciones."""
return self.SessionLocal()
def health_check(self) -> bool:
"""
Comprobar la conectividad de la base de datos.
Devuelve:
bool: True si la base de datos está en buen estado, False en caso contrario.
"""
try:
with self.engine.connect() as conn:
conn.execute(text("SELECT 1"))
logger.info("✓ Comprobación del estado de la base de datos superada")
return True
except Exception as e:
logger.error(f"❌ Fallo en la comprobación del estado de la base de datos: {e}")
return FalseEl DatabaseManager establece conexiones utilizando el agrupamiento de conexiones de SQLAlchemy. Al establecer pool_size=5 se mantienen cinco conexiones persistentes para mayor eficiencia. La opción pool_pre_ping valida las conexiones antes de su uso. Esto evita errores de conexión obsoletos. El mecanismo de reintento intenta las operaciones fallidas hasta tres veces con retroceso exponencial. Gestiona problemas de red transitorios.
Paso 3: Creación del núcleo del agente LangChain
Cree el agente de IA utilizando LangChain con herramientas personalizadas que interactúan con la base de datos. El agente utiliza llamadas a funciones para guardar información y recuperar el historial de conversaciones.
class DataPersistentAgent:
"""
Agente de IA con capacidades de persistencia de base de datos.
Este agente:
- Recuerda las conversaciones entre sesiones.
- Guarda y recupera información del usuario.
- Extrae y almacena entidades importantes.
- Proporciona respuestas personalizadas basadas en el historial.
"""
def __init__(
self,
db_manager: DatabaseManager,
model_name: str = "gpt-4-turbo-preview",
temperature: float = 0.7
):
"""
Inicializa el agente con persistencia de datos.
Argumentos:
db_manager: Instancia del gestor de la base de datos.
model_name: Modelo LLM que se va a utilizar (por defecto: gpt-4-turbo-preview).
temperature: Temperatura del modelo para la generación de respuestas.
"""
self.db_manager = db_manager
self.model_name = model_name
# Inicializar LLM
self.llm = ChatOpenAI(
model=model_name,
temperature=temperature,
openai_api_key=os.getenv("OPENAI_API_KEY")
)
# Crear herramientas para el agente
self.tools = self._create_agent_tools()
# Crear indicaciones para el agente
self.prompt = self._create_agent_prompt()
# Inicializar memoria
self.memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# Crear agente
self.agent = create_openai_functions_agent(
llm=self.llm,
tools=self.tools,
prompt=self.prompt
)
# Crear ejecutor de agente
self.agent_executor = AgentExecutor(
agent=self.agent,
tools=self.tools,
memory=self.memory,
verbose=True,
handle_parsing_errors=True,
max_iterations=5
)
logger.info(f"✓ Agente persistente de datos inicializado con {model_name}")
def _create_agent_tools(self) -> List[Tool]:
"""Crear herramientas personalizadas para operaciones de base de datos."""
def save_user_info(user_data: str) -> str:
"""Guardar la información del usuario en la base de datos."""
try:
data = json.loads(user_data)
session = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=data['user_id']).first()
if not user:
user = User(**data)
session.add(user)
else:
for key, value in data.items():
setattr(user, key, value)
sesión.commit()
sesión.close()
return f"✓ Información del usuario guardada correctamente"
except Exception as e:
logger.error(f"Error al guardar la información del usuario: {e}")
return f"❌ Error al guardar la información del usuario: {str(e)}"
def recuperar_historial_usuario(id_usuario: str) -> str:
"""Recuperar el historial de conversaciones del usuario."""
try:
sesión = self.db_manager.get_session()
usuario = sesión.query(User).filter_by(user_id=id_usuario).first()
if not usuario:
return "No se ha encontrado ningún usuario"
conversations = session.query(Conversation).filter_by(user_id=user.id).order_by(Conversation.created_at.desc()).limit(5).all()
history = []
for conv in conversations:
messages = session.query(Message).filter_by(conversation_id=conv.id).all()
historial.append({
'conversation_id': conv.conversation_id,
'created_at': conv.created_at.isoformat(),
'message_count': len(mensajes),
'summary': conv.summary
})
sesión.close()
return json.dumps(historial, indent=2)
except Exception as e:
logger.error(f"Failed to retrieve history: {e}")
return f"❌ Error retrieving history: {str(e)}"
def extract_entities(text: str) -> str:
"""Extract entities from text and save to database."""
try:
entities = []
# Extracción simple de palabras clave (reemplazar con NER adecuado)
keywords = ['importante', 'clave', 'crítico']
for keyword in keywords:
if keyword in text.lower():
entities.append({
'entity_type': 'keyword',
'entity_value': keyword,
'confidence': 0.8
})
return json.dumps(entities, indent=2)
except Exception as e:
logger.error(f"Failed to extract entities: {e}")
return f"❌ Error extracting entities: {str(e)}"
tools = [
Tool(
name="SaveUserInfo",
func=save_user_info,
description="Guardar la información del usuario en la base de datos. La entrada debe ser una cadena JSON con los datos del usuario."
),
Tool(
name="RetrieveUserHistory",
func=retrieve_user_history,
description="Recupera el historial de conversaciones de un usuario de la base de datos. La entrada debe ser el user_id."
),
Tool(
name="ExtractEntities",
func=extract_entities,
description="Extraer entidades importantes del texto y guardarlas en la base de datos. La entrada debe ser el texto a analizar."
)
]
return tools
def _create_agent_prompt(self) -> ChatPromptTemplate:
"""Crear plantilla de solicitud de agente."""
system_message = """Eres un asistente de IA útil con la capacidad de recordar y aprender de las conversaciones.
Tienes acceso a las siguientes herramientas:
- SaveUserInfo: guarda la información del usuario para recordarla en futuras conversaciones.
- RetrieveUserHistory: busca conversaciones anteriores con un usuario.
- ExtractEntities: extrae y guarda información importante de las conversaciones.
Utiliza estas herramientas para proporcionar respuestas personalizadas y contextuales. Comprueba siempre si tienes conversaciones anteriores con un usuario antes de responder.
Sé proactivo a la hora de guardar información importante para futuras conversaciones."""
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
return prompt
def chat(self, user_id: str, message: str, conversation_id: Optional[str] = None) -> Dict[str, Any]:
"""
Procesa un mensaje de chat y lo guarda en la base de datos.
Este método gestiona:
1. Crear o recuperar conversaciones.
2. Guardar mensajes de usuario en la base de datos.
3. Generar respuestas de agente.
4. Guardar respuestas de agente en la base de datos.
5. Registrar operaciones para supervisión.
Argumentos:
user_id: identificador único del usuario.
message: texto del mensaje del usuario.
conversation_id: ID de conversación opcional para continuar una conversación existente.
Devuelve:
dict: Contiene conversation_id, response y execution_time
"""
start_time = datetime.utcnow()
try:
# Obtener o crear conversación
session = self.db_manager.get_session()
if conversation_id:
conversation = session.query(Conversation).filter_by(conversation_id=conversation_id).first()
else:
# Crear nueva conversación
user = session.query(User).filter_by(user_id=user_id).first()
if not user:
user = User(user_id=user_id, name=user_id)
session.add(user)
session.commit()
conversation = Conversation(
conversation_id=f"conv_{user_id}_{datetime.utcnow().timestamp()}",
user_id=user.id,
title=message[:100]
)
session.add(conversation)
session.commit()
# Guardar mensaje del usuario
user_message = Message(
conversation_id=conversation.id,
role="user",
content=message,
model=self.model_name
)
session.add(user_message)
session.commit()
# Obtener la respuesta del agente
response = self.agent_executor.invoke({
"input": f"[ID de usuario: {user_id}] {message}"
})
# Guardar mensaje del asistente
mensaje_asistente = Mensaje(
id_conversación=conversación.id,
rol="asistente",
contenido=respuesta['salida'],
modelo=self.nombre_modelo
)
sesión.añadir(mensaje_asistente)
sesión.confirmar()
# Registrar operación
execution_time = (datetime.utcnow() - start_time).total_seconds()
log_entry = AgentLog(
conversation_id=conversation.conversation_id,
level="INFO",
operation="chat",
message="Chat procesado correctamente",
execution_time=execution_time
)
session.add(log_entry)
session.commit()
# Extraer conversation_id antes de cerrar la sesión
conversation_id_result = conversation.conversation_id
session.close()
logger.info(f"✓ Chat procesado para el usuario {user_id} en {execution_time:.2f}s")
return {
'conversation_id': conversation_id_result,
'response': response['output'],
'execution_time': execution_time
}
except Exception as e:
logger.error(f"❌ Error al procesar el chat: {e}")
# Registrar error
sesión = self.db_manager.get_session()
error_log = AgentLog(
conversation_id=conversation_id o "desconocido",
nivel="ERROR",
operación="chat",
mensaje=str(e),
detalles_error={'exception_type': tipo(e).__name__}
)
session.add(error_log)
session.commit()
session.close()
raiseEl DataPersistentAgent envuelve la función de LangChain que llama al agente con herramientas de base de datos. La herramienta SaveUserInfo conserva los datos del usuario creando o actualizando registros de usuario. La herramienta RetrieveHistory consulta conversaciones pasadas para proporcionar contexto. El sistema indica al agente que sea proactivo a la hora de guardar información y comprobar el historial. El ConversationBufferMemory mantiene el contexto a corto plazo dentro de las sesiones. El almacenamiento en la base de datos proporciona persistencia a largo plazo entre sesiones.
Paso 3.5: Creación del módulo de recopilación de datos
Cree herramientas para extraer y estructurar datos de las conversaciones. El recopilador genera resúmenes, extrae preferencias e identifica entidades utilizando el LLM.
class DataCollector:
"""
Recopila y estructura datos de las conversaciones de los agentes.
Este módulo:
- Genera resúmenes de conversaciones.
- Extrae las preferencias de los usuarios del historial de conversaciones.
- Identifica y guarda entidades con nombre.
"""
def __init__(self, db_manager: DatabaseManager, llm: ChatOpenAI):
"""
Inicializa el recopilador de datos.
Argumentos:
db_manager: Instancia del gestor de bases de datos
llm: Modelo de lenguaje para el análisis de texto
"""
self.db_manager = db_manager
self.llm = llm
logger.info("✓ Recopilador de datos inicializado")
def extract_conversation_summary(self, conversation_id: str) -> str:
"""
Genera y guarda el resumen de la conversación utilizando LLM.
Argumentos:
conversation_id: ID de la conversación que se va a resumir
Devuelve:
str: Texto del resumen generado
"""
try:
session = self.db_manager.get_session()
conversation = session.query(Conversation).filter_by(conversation_id=conversation_id).first()
if not conversation:
return "Conversación no encontrada"
messages = session.query(Message).filter_by(conversation_id=conversation.id).all()
# Crear texto de conversación
conv_text = "n".join([
f"{msg.role}: {msg.content}" for msg in messages
])
# Generar resumen utilizando LLM
summary_prompt = f"""Resuma la siguiente conversación en 2-3 frases, captando los temas principales y los resultados:
{conv_text}
Resumen:"""
summary_response = self.llm.invoke([HumanMessage(content=summary_prompt)])
summary = summary_response.content
# Actualizar conversación con resumen
conversation.summary = summary
session.commit()
session.close()
logger.info(f"✓ Resumen generado para la conversación {conversation_id}")
return summary
except Exception as e:
logger.error(f"Error al generar el resumen: {e}")
return ""
def extract_user_preferences(self, user_id: str) -> Dict[str, Any]:
"""
Extraer y guardar las preferencias del usuario del historial de conversaciones.
Argumentos:
user_id: ID del usuario que se va a analizar.
Devuelve:
dict: Preferencias extraídas.
"""
try:
session = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=user_id).first()
if not user:
return {}
# Obtener conversaciones recientes
conversations = session.query(Conversation).filter_by(user_id=user.id).order_by(Conversation.created_at.desc()).limit(10).all()
all_messages = []
for conv in conversations:
messages = session.query(Message).filter_by(conversation_id=conv.id).all()
all_messages.extend([msg.content for msg in messages if msg.role == "user"])
if not all_messages:
return {}
# Analizar las preferencias utilizando LLM
analysis_prompt = f"""Analiza los siguientes mensajes de un usuario y extrae sus preferencias, intereses y estilo de comunicación.
Mensajes:
{chr(10).join(all_messages[:20])}
Devuelve un objeto JSON con la siguiente estructura:
{{
"interests": ["interest1", "interest2"],
"communication_style": "description",
"preferred_topics": ["topic1", "topic2"],
"language_preference": "language"
}}"""
response = self.llm.invoke([HumanMessage(content=analysis_prompt)])
try:
# Extraer JSON de la respuesta
content = response.content
if '```json' in content:
content = content.split('```json')[1].split('```')[0].strip()
elif '```' in content:
content = content.split('```')[1].split('```')[0].strip()
preferences = json.loads(content)
# Actualizar preferencias del usuario
user.preferences = preferences
session.commit()
logger.info(f"✓ Preferencias extraídas para el usuario {user_id}")
return preferences
except json.JSONDecodeError:
logger.warning("Error al analizar las preferencias JSON")
return {}
finally:
session.close()
except Exception as e:
logger.error(f"Failed to extract preferences: {e}")
return {}
def extract_entities_with_llm(self, conversation_id: str) -> List[Dict[str, Any]]:
"""
Extraer entidades nombradas utilizando LLM.
Argumentos:
conversation_id: ID de la conversación que se va a analizar.
Devuelve:
list: Lista de entidades extraídas.
"""
try:
session = self.db_manager.get_session()
conversation = session.query(Conversation).filter_by(conversation_id=conversation_id).first()
if not conversation:
return []
messages = session.query(Message).filter_by(conversation_id=conversation.id).all()
conv_text = "n".join([msg.content for msg in messages])
# Extraer entidades utilizando LLM
entity_prompt = f"""Extraer entidades nombradas de la siguiente conversación. Identificar:
- Personas (PERSON)
- Organizaciones (ORG)
- Ubicaciones (LOC)
- Fechas (DATE)
- Productos (PRODUCT)
- Tecnologías (TECH)
Conversación:
{conv_text}
Devuelve una matriz JSON de entidades con el formato:
[
{{"type": "PERSON", "value": "John Doe", "context": "mencionado como jefe de equipo"}},
{{"type": "ORG", "value": "Acme Corp", "context": "empresa cliente"}}
]"""
response = self.llm.invoke([HumanMessage(content=entity_prompt)])
try:
content = response.content
if '```json' in content:
content = content.split('```json')[1].split('```')[0].strip()
elif '```' in content:
content = content.split('```')[1].split('```')[0].strip()
entities_data = json.loads(content)
# Guardar entidades en la base de datos
saved_entities = []
for entity_data in entities_data:
entity = Entity(
conversation_id=conversation.id,
entity_type=entity_data['type'],
entity_value=entity_data['value'],
context=entity_data.get('context', ''),
confidence=0.9 # La extracción LLM tiene una alta confianza
)
session.add(entity)
saved_entities.append(entity_data)
session.commit()
session.close()
logger.info(f"✓ Extracted {len(saved_entities)} entities from conversation {conversation_id}")
return saved_entities
except json.JSONDecodeError:
logger.warning("Failed to parse entities JSON")
return []
except Exception as e:
logger.error(f"Failed to extract entities: {e}")
return []El DataCollector utiliza el LLM para analizar conversaciones. El método extract_conversation_summary crea resúmenes concisos de las conversaciones. El método extract_user_preferences analiza patrones de mensajes para identificar los intereses y estilos de comunicación de los usuarios. El método extract_entities_with_llm utiliza indicaciones estructuradas para extraer entidades nombradas, como personas, organizaciones y tecnologías. Todos los datos extraídos se guardan en la base de datos para futuras consultas.
Paso 4: Creación del canal de procesamiento de datos inteligentes
Implemente el procesamiento en segundo plano para gestionar la recopilación de datos sin bloquear al agente. El canal utiliza subprocesos de trabajo y colas para procesar resúmenes y entidades.
class DataProcessingPipeline:
"""
Pipeline de procesamiento de datos asíncrono.
Este pipeline:
- Procesa conversaciones en segundo plano.
- Genera resúmenes.
- Extrae entidades sin bloquear el flujo principal.
- Actualiza las preferencias del usuario periódicamente.
"""
def __init__(self, db_manager: DatabaseManager, collector: DataCollector, batch_size: int = 10):
"""
Inicializa el canal de procesamiento.
Argumentos:
db_manager: Instancia del gestor de bases de datos
collector: Recopilador de datos para operaciones de procesamiento
batch_size: Número de elementos que se procesarán en cada lote
"""
self.db_manager = db_manager
self.collector = collector
self.batch_size = batch_size
# Colas de procesamiento
self.summary_queue = Queue()
self.entity_queue = Queue()
self.preference_queue = Queue()
# Subprocesos de trabajo
self.workers = []
self.running = False
logger.info("✓ Canalización de procesamiento de datos inicializada")
def start(self):
"""Iniciar trabajadores de procesamiento en segundo plano."""
self.running = True
# Crear subprocesos de trabajo
summary_worker = Thread(target=self._process_summaries, daemon=True)
entity_worker = Thread(target=self._process_entities, daemon=True)
preference_worker = Thread(target=self._process_preferences, daemon=True)
summary_worker.start()
entity_worker.start()
preference_worker.start()
self.workers = [summary_worker, entity_worker, preference_worker]
logger.info("✓ Se han iniciado 3 trabajadores de procesamiento en segundo plano")
def stop(self):
"""Detener los trabajadores de procesamiento en segundo plano."""
self.running = False
for worker in self.workers:
worker.join(timeout=5)
logger.info("✓ Se han detenido los trabajadores de procesamiento en segundo plano")
def queue_conversation_for_processing(self, conversation_id: str, user_id: str):
"""
Añadir conversación a las colas de procesamiento.
Argumentos:
conversation_id: ID de la conversación a procesar.
user_id: ID del usuario para la extracción de preferencias.
"""
self.summary_queue.put(conversation_id)
self.entity_queue.put(conversation_id)
self.preference_queue.put(user_id)
logger.info(f"✓ Conversación {conversation_id} en cola para procesamiento")
def _process_summaries(self):
"""Trabajador para procesar resúmenes de conversaciones."""
while self.running:
try:
if not self.summary_queue.empty():
conversation_id = self.summary_queue.get()
self.collector.extract_conversation_summary(conversation_id)
self.summary_queue.task_done()
else:
time.sleep(1)
except Exception as e:
logger.error(f"Error en el trabajador de resúmenes: {e}")
def _process_entities(self):
"""Trabajador para procesar la extracción de entidades."""
while self.running:
try:
if not self.entity_queue.empty():
conversation_id = self.entity_queue.get()
self.collector.extract_entities_with_llm(conversation_id)
self.entity_queue.task_done()
else:
time.sleep(1)
except Exception as e:
logger.error(f"Error en el trabajador de entidades: {e}")
def _process_preferences(self):
"""Trabajador para procesar las preferencias del usuario."""
while self.running:
try:
if not self.preference_queue.empty():
user_id = self.preference_queue.get()
self.collector.extract_user_preferences(user_id)
self.preference_queue.task_done()
else:
time.sleep(1)
except Exception as e:
logger.error(f"Error en el trabajador de preferencias: {e}")
def get_queue_status(self) -> Dict[str, int]:
"""
Obtener los tamaños actuales de la cola.
Devuelve:
dict: Tamaños de las colas para cada tipo de procesamiento.
"""
return {
'summary_queue': self.summary_queue.qsize(),
'entity_queue': self.entity_queue.qsize(),
'preference_queue': self.preference_queue.qsize()
}ProcessingPipeline desacopla la recopilación de datos del procesamiento de mensajes. Cuando se completa una conversación, se añade a las colas en lugar de procesarse inmediatamente. Hilos de trabajo independientes extraen elementos de estas colas y los procesan en segundo plano. Esto evita que la recopilación de datos bloquee las respuestas de los agentes. La configuración daemon=True garantiza que los trabajadores terminen cuando se cierre el programa principal. La supervisión del estado de la cola ayuda a realizar un seguimiento de los retrasos en el procesamiento.
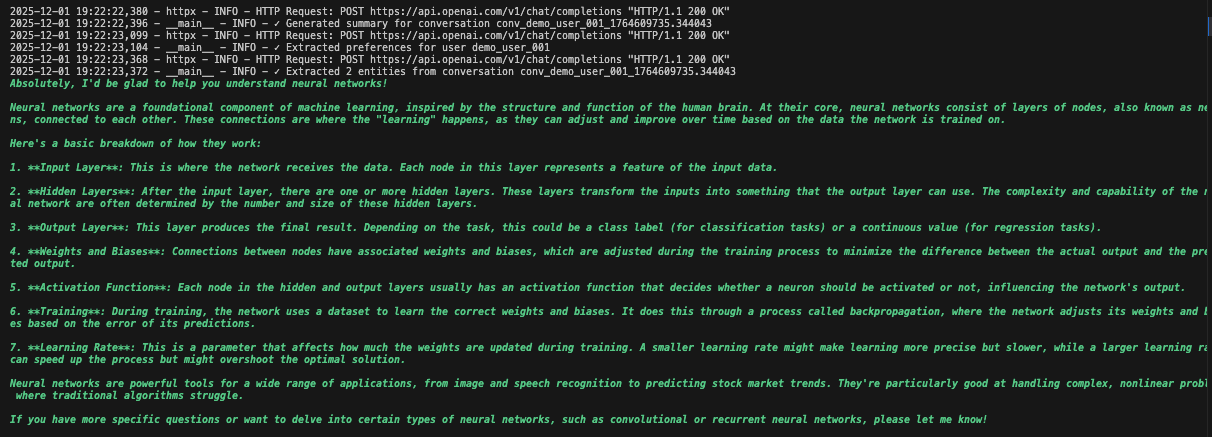
Paso 5: Añadir supervisión y registro en tiempo real
Cree un sistema de supervisión para realizar un seguimiento del rendimiento de los agentes, detectar errores y generar informes. El monitor analiza los registros para proporcionar información operativa.
class AgentMonitor:
"""
Supervisión en tiempo real y recopilación de métricas.
Este módulo:
- Realiza un seguimiento de las métricas de rendimiento.
- Supervisa el estado del sistema.
- Genera informes analíticos.
"""
def __init__(self, db_manager: DatabaseManager):
"""
Inicializar el monitor del agente.
Argumentos:
db_manager: Instancia del gestor de la base de datos
"""
self.db_manager = db_manager
logger.info("✓ Monitor del agente inicializado")
def get_performance_metrics(self, hours: int = 24) -> Dict[str, Any]:
"""
Obtiene métricas de rendimiento para el periodo de tiempo especificado.
Argumentos:
hours: Número de horas que se van a revisar
Devuelve:
dict: Métricas de rendimiento, incluyendo recuentos de operaciones y tasas de error
"""
try:
session = self.db_manager.get_session()
cutoff_time = datetime.utcnow() - timedelta(hours=hours)
# Consultar registros
logs = session.query(AgentLog).filter(
AgentLog.created_at >= cutoff_time
).all()
# Calcular métricas
total_operations = len(logs)
error_count = len([log for log in logs if log.level == "ERROR"])
avg_execution_time = sum([log.execution_time or 0 for log in logs]) / max(total_operations, 1)
# Obtener recuentos de conversaciones
conversations = session.query(Conversation).filter(
Conversation.created_at >= cutoff_time
).count()
messages = session.query(Message).join(Conversation).filter(
Message.created_at >= cutoff_time
).count()
session.close()
métricas = {
'tiempo_horas': horas,
'total_operaciones': total_operaciones,
'recuento_errores': recuento_errores,
'tasa_errores': recuento_errores / max(total_operaciones, 1),
'avg_execution_time': avg_execution_time,
'conversations_created': conversations,
'messages_processed': messages
}
logger.info(f"✓ Métricas de rendimiento generadas para las últimas {hours} horas")
return metrics
except Exception as e:
logger.error(f"Error al obtener las métricas de rendimiento: {e}")
return {}
def health_check(self) -> Dict[str, Any]:
"""
Realizar comprobación de estado.
Devuelve:
dict: Estado de salud, incluyendo conectividad de la base de datos y tasas de error.
"""
try:
# Comprobar conectividad de la base de datos
db_healthy = self.db_manager.health_check()
# Comprobar la tasa de errores reciente
metrics = self.get_performance_metrics(hours=1)
recent_errors = metrics.get('error_count', 0)
# Determinar el estado general
is_healthy = db_healthy and recent_errors < 10
health_status = {
'status': 'healthy' if is_healthy else 'degraded',
'database_connected': db_healthy,
'recent_errors': recent_errors,
'timestamp': datetime.utcnow().isoformat()
}
logger.info(f"✓ Comprobación de estado: {health_status['status']}")
return health_status
except Exception as e:
logger.error(f"Health check failed: {e}")
return {
'status': 'unhealthy',
'error': str(e),
'timestamp': datetime.utcnow().isoformat()
}AgentMonitor proporciona observabilidad en las operaciones del sistema. Realiza un seguimiento de métricas como el total de operaciones, las tasas de error y los tiempos medios de ejecución mediante consultas a la tabla AgentLog. El método get_metrics calcula estadísticas en ventanas de tiempo configurables. El método get_error_report recupera información detallada sobre los errores para su depuración. Esta supervisión permite la detección proactiva de problemas. Las altas tasas de error activan una investigación antes de que los usuarios se vean afectados.
Paso 6: Creación de la interfaz de consulta
Cree capacidades de consulta para recuperar y analizar los datos almacenados. La interfaz proporciona métodos para buscar conversaciones, realizar un seguimiento de entidades y generar análisis.
class DataQueryInterface:
"""
Interfaz para consultar los datos almacenados del agente.
Este módulo proporciona métodos para:
- Consultar análisis de usuarios.
- Recuperar el historial de conversaciones.
- Buscar información específica.
"""
def __init__(self, db_manager: DatabaseManager):
"""
Inicializar la interfaz de consulta.
Argumentos:
db_manager: Instancia del gestor de bases de datos
"""
self.db_manager = db_manager
logger.info("✓ Interfaz de consulta inicializada")
def get_user_analytics(self, user_id: str) -> Dict[str, Any]:
"""
Obtener análisis para un usuario específico.
Argumentos:
user_id: ID del usuario que se va a analizar
Devuelve:
dict: Análisis del usuario, incluyendo recuentos de conversaciones y preferencias
"""
try:
session = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=user_id).first()
if not user:
return {}
# Obtener el recuento de conversaciones
conversation_count = session.query(Conversation).filter_by(user_id=user.id).count()
# Obtener el recuento de mensajes
message_count = session.query(Message).join(Conversation).filter(
Conversation.user_id == user.id
).count()
# Obtener el recuento de entidades
entity_count = session.query(Entity).join(Conversation).filter(
Conversation.user_id == user.id
).count()
# Obtener el intervalo de tiempo
first_conversation = session.query(Conversation).filter_by(
user_id=user.id
).order_by(Conversation.created_at).first()
last_conversation = session.query(Conversation).filter_by(
user_id=user.id
).order_by(Conversation.created_at.desc()).first()
session.close()
analytics = {
'user_id': user_id,
'name': user.name,
'conversation_count': conversation_count,
'message_count': message_count,
'entity_count': entity_count,
'preferences': user.preferences,
'first_interaction': first_conversation.created_at.isoformat() if first_conversation else None,
'last_interaction': last_conversation.created_at.isoformat() if last_conversation else None,
'avg_messages_per_conversation': message_count / max(conversation_count, 1)
}
logger.info(f"✓ Análisis generado para el usuario {user_id}")
return analytics
except Exception as e:
logger.error(f"Error al obtener el análisis del usuario: {e}")
return {}QueryInterface proporciona métodos para acceder a los datos almacenados. El método get_user_conversations recupera el historial completo de conversaciones con la inclusión opcional de mensajes. El método search_conversations realiza una búsqueda de texto completo en el contenido de los mensajes utilizando el operador ILIKE de SQL. El método get_entity_mentions encuentra todas las conversaciones en las que se mencionan entidades específicas. El método get_user_analytics genera estadísticas sobre la actividad del usuario. Estas consultas permiten crear paneles de control, generar informes y crear experiencias personalizadas.
Paso 7: Creación de un RAG con datos web en tiempo real de Bright Data
Mejora tu agente conectado a la base de datos con las capacidades RAG de la inteligencia web en tiempo real de Bright Data. Esta integración combina tu historial de conversaciones con datos web actualizados para obtener mejores respuestas.
class BrightDataRAGEnhancer:
"""
Mejora el agente de datos persistentes con la inteligencia web de Bright Data.
Este módulo:
- Obtiene datos web en tiempo real de Bright Data.
- Ingesta datos web en el almacén vectorial para RAG.
- Mejora el agente con conocimientos aumentados por la web.
"""
def __init__(self, api_key: str, db_manager: DatabaseManager):
"""
Inicializa el potenciador RAG con Bright Data.
Argumentos:
api_key: clave API de Bright Data
db_manager: instancia del gestor de bases de datos
"""
self.api_key = api_key
self.db_manager = db_manager
self.base_url = "https://api.brightdata.com"
# Inicializar el almacén de vectores para RAG
self.embeddings = OpenAIEmbeddings()
self.vector_store = Chroma(
embedding_function=self.embeddings,
persist_directory="./chroma_db"
)
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
logger.info("✓ Bright Data RAG enhancer initialized")
def fetch_dataset_data(
self,
dataset_id: str,
filters: Optional[Dict[str, Any]] = None,
limit: int = 1000
) -> List[Dict[str, Any]]:
"""
Recupera datos de Bright Data Dataset Marketplace.
Argumentos:
dataset_id: ID del conjunto de datos que se va a recuperar.
filters: Filtros opcionales para los datos.
limit: Número máximo de registros que se van a recuperar.
Devuelve:
list: Registros del conjunto de datos recuperados.
"""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
endpoint = f"{self.base_url}/Conjuntos de datos/v3/snapshot/{dataset_id}"
params = {
"format": "json",
"limit": limit
}
if filters:
params["filter"] = json.dumps(filters)
try:
response = requests.get(endpoint, headers=headers, params=params)
response.raise_for_status()
data = response.json()
logger.info(f"✓ Retrieved {len(data)} records from Bright Data dataset {dataset_id}")
return data
except Exception as e:
logger.error(f"Error al recuperar el conjunto de datos de Bright Data: {e}")
return []
def ingest_web_data_to_rag(
self,
dataset_records: List[Dict[str, Any]],
text_fields: List[str],
metadata_fields: Optional[List[str]] = None
) -> int:
"""
Ingesta datos web en el almacén vectorial RAG.
Argumentos:
dataset_records: Registros de Bright Data.
text_fields: Campos que se utilizarán como contenido de texto.
metadata_fields: Campos que se incluirán en los metadatos.
Devuelve:
int: Número de fragmentos de documentos importados
"""
try:
documents = []
for record in dataset_records:
# Combinar campos de texto
text_content = " ".join([
str(record.get(field, ""))
for field in text_fields
if record.get(field)
])
if not text_content.strip():
continue
# Crear metadatos
metadata = {
"source": "bright_data",
"record_id": record.get("id", "unknown"),
"timestamp": datetime.utcnow().isoformat()
}
if metadata_fields:
for field in metadata_fields:
if field in record:
metadata[field] = record[field]
# Dividir el texto en fragmentos
chunks = self.text_splitter.split_text(text_content)
for chunk in chunks:
documents.append({
"content": chunk,
"metadata": metadata
})
# Añadir al almacén vectorial
if documents:
texts = [doc["content"] for doc in documents]
metadatas = [doc["metadata"] for doc in documents]
self.vector_store.add_texts(
texts=texts,
metadatas=metadatas
)
logger.info(f"✓ Ingested {len(documents)} document chunks into RAG")
return len(documents)
except Exception as e:
logger.error(f"Error al introducir datos web en RAG: {e}")
return 0
def create_rag_enhanced_agent(
self,
base_agent: DataPersistentAgent
) -> DataPersistentAgent:
"""
Mejora el agente existente con capacidades RAG.
Argumentos:
base_agent: Agente base para mejorar
Devuelve:
DataPersistentAgent: Agente mejorado con la herramienta RAG
"""
def rag_search(query: str) -> str:
"""Busca tanto en el historial de conversaciones como en los datos web."""
intentar:
# Recuperar del historial de conversaciones
sesión = self.db_manager.get_session()
mensajes = sesión.query(Mensaje).filtrar(
Mensaje.contenido.ilike(f'%{query}%')
).ordenar_por(Mensaje.creado_en.desc()).limitar(5).todo()
results = []
for msg in messages:
results.append({
'content': msg.content,
'source': 'conversation_history',
'relevance': 0.8
})
session.close()
# Recuperar del almacén vectorial (datos web)
try:
vector_results = self.vector_store.similarity_search_with_score(query, k=5)
for doc, score in vector_results:
results.append({
'content': doc.page_content,
'source': 'web_data',
'relevance': 1 - score
})
except Exception as e:
logger.error(f"Error al recuperar del almacén vectorial: {e}")
if not results:
return "No se ha encontrado información relevante."
# Formato del contexto
context_text = "nn".join([
f"[{item['source']}] {item['content'][:200]}..."
para item en results[:5]
])
return f"Contexto recuperado:n{context_text}"
excepto Exception como e:
logger.error(f"Error en la búsqueda RAG: {e}")
return f"Error al realizar la búsqueda: {str(e)}"
# Añadir herramienta RAG al agente
rag_tool = Tool(
name="SearchKnowledgeBase",
func=rag_search,
description="Busca información relevante tanto en el historial de conversaciones como en datos web en tiempo real. La entrada debe ser una consulta de búsqueda."
)
base_agent.tools.append(rag_tool)
# Recrear el agente con nuevas herramientas
base_agent.agent = create_openai_functions_agent(
llm=base_agent.llm,
tools=base_agent.tools,
prompt=base_agent.prompt
)
base_agent.agent_executor = AgentExecutor(
agent=base_agent.agent,
tools=base_agent.tools,
memory=base_agent.memory,
verbose=True,
handle_parsing_errors=True,
max_iterations=5
)
logger.info("✓ Agente mejorado con capacidades RAG")
return base_agentBrightDataEnhancer integra datos web en tiempo real en su agente. El método fetch_dataset recupera datos estructurados del mercado de Bright Data. El método ingest_to_rag procesa y divide estos datos. Los almacena en una base de datos vectorial Chroma para la búsqueda semántica. El método retrieve_context realiza una recuperación híbrida. Combina el historial de la base de datos con la búsqueda de similitud vectorial. El método create_rag_tool empaqueta esta funcionalidad como una herramienta LangChain que utiliza el agente. El método enhance_agent añade esta capacidad RAG a su agente existente. Permite al agente responder a preguntas utilizando tanto el historial de conversaciones internas como datos externos recientes.
Ejecución de su sistema completo de agente con datos persistentes
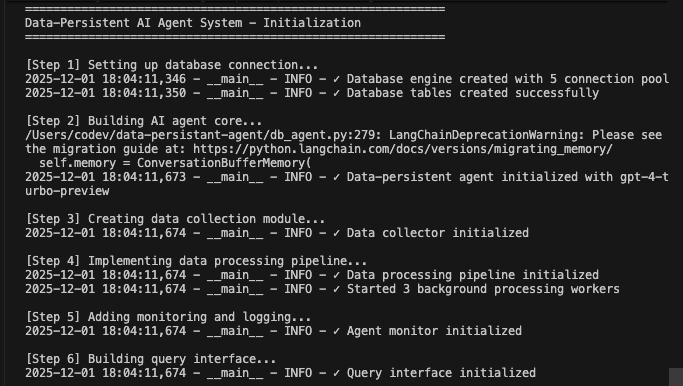
Reúna todos los componentes para crear un sistema funcional.
def main():
"""Flujo de ejecución principal que muestra todos los componentes trabajando juntos."""
print("=" * 60)
print("Sistema de agente de IA con datos persistentes - Inicialización")
print("=" * 60)
# Paso 1: Inicializar la base de datos
print("n[Paso 1] Configurando la conexión a la base de datos...")
db_manager = DatabaseManager(
database_url=os.getenv("DATABASE_URL"),
pool_size=5,
max_retries=3
)
db_manager.initialize_database()
# Paso 2: Inicializar el agente central
print("n[Paso 2] Creando el núcleo del agente de IA...")
agent = DataPersistentAgent(
db_manager=db_manager,
model_name=os.getenv("AGENT_MODEL", "gpt-4-turbo-preview")
)
# Paso 3: Inicializar el recopilador de datos
print("n[Paso 3] Creando el módulo de recopilación de datos...")
collector = DataCollector(db_manager, agent.llm)
# Paso 4: Inicializar el canal de procesamiento
print("n[Paso 4] Implementando el canal de procesamiento de datos...")
pipeline = DataProcessingPipeline(db_manager, collector)
pipeline.start()
# Paso 5: Inicializar la supervisión.
print("n[Paso 5] Añadiendo supervisión y registro...")
monitor = AgentMonitor(db_manager)
# Paso 6: Inicializar la interfaz de consulta.
print("n[Paso 6] Creando interfaz de consulta...")
query_interface = DataQueryInterface(db_manager)
# Paso 7: Mejora opcional de Bright Data RAG
print("n[Paso 7] Mejora de RAG (opcional)...")
bright_data_key = os.getenv("BRIGHT_DATA_API_KEY")
if bright_data_key and bright_data_key != "your-bright-data-api-key":
print("Obteniendo datos web en tiempo real de Bright Data...")
enhancer = BrightDataRAGEnhancer(bright_data_key, db_manager)
# Ejemplo: Obtener e ingestar datos web
web_data = enhancer.fetch_dataset_data(
dataset_id="example_dataset_id",
limit=100
)
if web_data:
enhancer.ingest_web_data_to_rag(
dataset_records=web_data,
text_fields=["title", "content", "description"],
metadata_fields=["url", "published_date"]
)
# Mejorar el agente con RAG
agent = enhancer.create_rag_enhanced_agent(agent)
print("✓ Agente mejorado con las capacidades RAG de Bright Data")
else:
print("⚠️ No se ha encontrado la clave API de Bright Data: se omite la integración de datos web")
print("n" + "=" * 60)
print("Conversaciones de demostración")
print("=" * 60)
# Interacciones de usuario de demostración
test_user = "demo_user_001"
# Primera conversación
print("n📝 Conversación 1:")
response1 = agent.chat(
user_id=test_user,
message="¡Hola! Me interesa aprender sobre el aprendizaje automático."
)
print(f"Agente: {response1['response']}n")
# Cola para procesamiento
pipeline.queue_conversation_for_processing(
response1['conversation_id'],
test_user
)
# Segunda conversación
print("📝 Conversación 2:")
respuesta2 = agente.chat(
user_id=usuario_de_prueba,
mensaje="¿Me ayudas a entender las redes neuronales?",
conversation_id=respuesta1['conversation_id']
)
print(f"Agente: {respuesta2['respuesta']}n")
# Esperar al procesamiento en segundo plano
print("⏳ Procesando datos en segundo plano...")
time.sleep(5)
print("n" + "=" * 60)
print("Análisis y supervisión")
print("=" * 60)
# Obtener métricas de rendimiento
metrics = monitor.get_performance_metrics(hours=1)
print(f"n📊 Métricas de rendimiento:")
print(f" - Total de operaciones: {metrics.get('total_operations', 0)}")
print(f" - Tasa de error: {metrics.get('error_rate', 0):.2%}")
print(f" - Tiempo medio de ejecución: {metrics.get('avg_execution_time', 0):.2f}s")
print(f" - Conversaciones creadas: {metrics.get('conversations_created', 0)}")
print(f" - Mensajes procesados: {metrics.get('messages_processed', 0)}")
# Obtener análisis de usuario
analytics = query_interface.get_user_analytics(test_user)
print(f"n👤 Análisis de usuario:")
print(f" - Recuento de conversaciones: {analytics.get('conversation_count', 0)}")
print(f" - Recuento de mensajes: {analytics.get('message_count', 0)}")
print(f" - Recuento de entidades: {analytics.get('entity_count', 0)}")
print(f" - Promedio de mensajes/conversación: {analytics.get('avg_messages_per_conversation', 0):.1f}")
# Comprobación de estado
health = monitor.health_check()
print(f"n🏥 Estado del sistema: {health['status']}")
# Estado de la cola
queue_status = pipeline.get_queue_status()
print(f"n📋 Colas de procesamiento:")
print(f" - Cola de resumen: {queue_status['summary_queue']}")
print(f" - Cola de entidades: {queue_status['entity_queue']}")
print(f" - Cola de preferencias: {queue_status['preference_queue']}")
# Detener canalización
pipeline.stop()
print("n" + "=" * 60)
print("Sistema de agente de datos persistentes: completado")
print("=" * 60)
print("n✓ Todos los datos se han guardado en la base de datos")
print("✓ Procesamiento en segundo plano completado")
print("✓ Sistema listo para su uso en producción")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("nn⚠️ Apagando correctamente...")
except Exception as e:
logger.error(f"Error del sistema: {e}")
import traceback
traceback.print_exc()Ejecute su sistema de agente conectado a la base de datos:
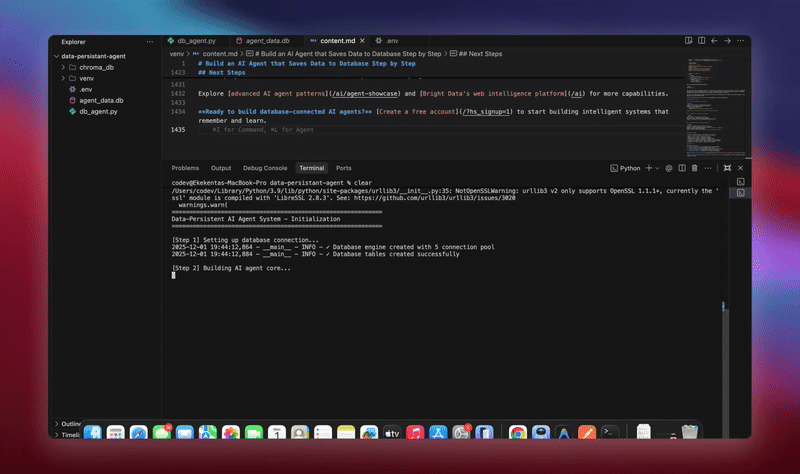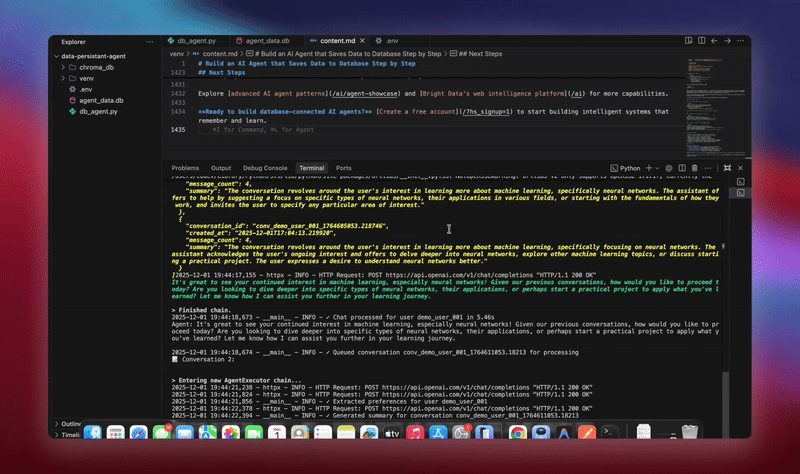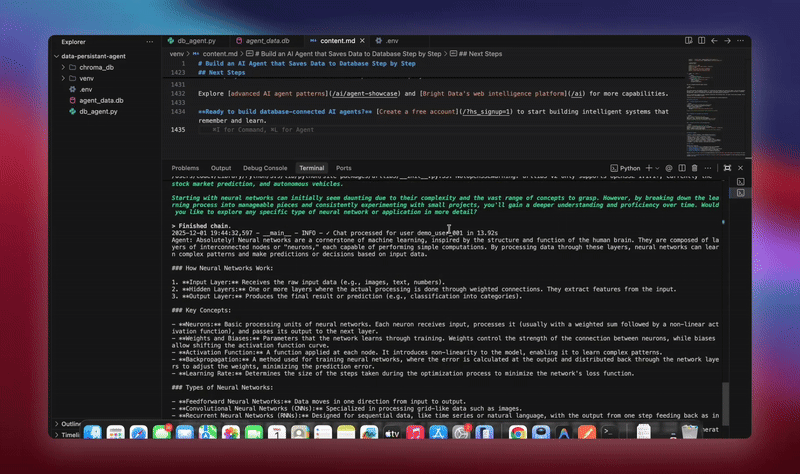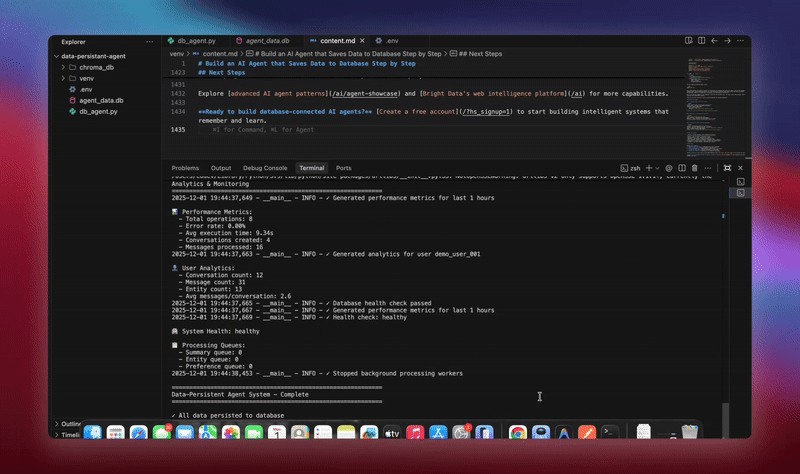
python agent.pyEl sistema ejecuta el flujo de trabajo completo. Inicializa la base de datos y crea todas las tablas. Configura el agente LangChain con herramientas de base de datos. Inicia los trabajadores en segundo plano para el procesamiento. Procesa conversaciones de demostración y las guarda en la base de datos. Extrae entidades y genera resúmenes en segundo plano. Muestra análisis y métricas en tiempo real.
Verá registros detallados a medida que cada componente se inicializa y procesa los datos. El agente almacena todos los mensajes. Extrae información. Mantiene el contexto completo de la conversación.
Casos de uso prácticos
1. Atención al cliente con historial completo
# El agente recupera interacciones pasadas
support_agent = DataPersistentAgent(db_manager)
response = support_agent.chat(
user_id="customer_123",
message="Sigo teniendo ese problema de conexión")
# El agente ve conversaciones anteriores sobre problemas de conexión2. Asistente personal de IA con aprendizaje
# El agente aprende las preferencias con el tiempo
query_interface = QueryInterface(db_manager)
analytics = query_interface.get_user_analytics("user_456")
# Muestra patrones de interacción, preferencias y temas comunes3. Asistente de investigación con base de conocimientos
# Combina el historial de conversaciones con datos web
enhancer = BrightDataEnhancer(api_key, db_manager)
enhancer.ingest_to_rag(research_data, ["title", "abstract", "content"])
agent = enhancer.enhance_agent(agent)
# El agente consulta tanto discusiones pasadas como las últimas investigacionesResumen de ventajas
| Característica | Sin base de datos | Con base de datos Persistencia |
|---|---|---|
| Memoria | Se pierde al reiniciar | Almacenamiento permanente |
| Personalización | Ninguna | Basada en el historial completo |
| Análisis | No es posible | Datos completos de interacción |
| Recuperación de errores | Intervención manual | Reintento automático y registro |
| Escalabilidad | Instancia única | Múltiples instancias con estado compartido |
| Información | Pérdida tras la sesión | Extraída y rastreada |
Conclusión
Ahora dispone de un sistema de agente de IA listo para producción que conserva las conversaciones en bases de datos. El sistema almacena todas las interacciones, extrae entidades e información, mantiene el historial completo de conversaciones y proporciona supervisión con recuperación automática de errores.
Mejórelo añadiendo autenticación de usuario para un acceso seguro, creando paneles para visualizar los análisis, implementando incrustaciones para la búsqueda semántica, creando puntos finales de API para la integración o implementándolo con Docker para obtener escalabilidad. El diseño modular permite una fácil personalización según sus necesidades específicas.
Explore los patrones avanzados de agentes de IA y la plataforma de inteligencia web de Bright Data para obtener más capacidades.
Cree una cuenta gratuita para empezar a construir sistemas inteligentes que recuerdan y aprenden.





