

Tableau es una herramienta líder para la visualización de datos, pero tiene una limitación importante. No puede extraer de forma fiable datos en tiempo real de sitios web por sí sola. El antiguo Web Data Connector (WDC v2), que antes resolvía este problema, quedó obsoleto en 2023. Su última versión compatible (Tableau 2022.4) ha llegado al final de su vida útil, dejando a los analistas sin una solución compatible.
Esta guía compara seis métodos para el Scraping web y la conexión de datos en tiempo real a Tableau. También incluye un tutorial paso a paso para crear un flujo de trabajo de API a Tableau utilizando la API Web Scraper de Bright Data.
En resumen
Tableau no puede extraer datos de sitios web de forma nativa, y su Web Data Connector (WDC v2) quedó obsoleto en 2023. Se necesita un canal de datos externo.
- WDC v2 ha quedado obsoleto; WDC v3 solo permite la extracción y es complejo de implementar
- Google Sheets, Excel y TabPy tienen limitaciones críticas a gran escala
- Los scripts de Python de creación propia funcionan inicialmente, pero requieren un mantenimiento constante
- Una API de extracción gestionada gestiona los Proxies, los CAPTCHA y el parseo de datos automáticamente
Siga el tutorial paso a paso de esta guía para crear un canal de datos operativo de Amazon → Bright Data → Tableau.
Por qué Tableau necesita un canal de datos externo
La pila de datos moderna requiere datos web en tiempo real: precios de la competencia, métricas de redes sociales, ofertas de empleo, anuncios inmobiliarios y feeds financieros. Tableau no fue diseñado para recopilarlos.
Los principales retos son:
- Los sitios web cambian constantemente: los diseños varían, las medidas anti-bot evolucionan y los requisitos de renderización de JavaScript aumentan
- La escala es fundamental: supervisar 10 000 SKU de la competencia a diario requiere lógica de reintentos, limitación de velocidad y gestión de errores que un script de una sola página no necesita
- El cumplimiento normativo es obligatorio: el RGPD, la CCPA y los términos de las plataformas exigen prácticas cuidadosas de recopilación de datos
- La infraestructura es costosa: la rotación de proxies, la Resolución de CAPTCHA, la lógica de reintentos y la gestión de IP son retos de ingeniería constantes
Los siguientes métodos cubren esa brecha.
Seis métodos para el Scraping web y la conexión de datos en tiempo real a Tableau
Cada método equilibra la escala, el mantenimiento y la fiabilidad de forma diferente. Se enumeran de menos viable a más listo para producción.
Método 1: Tableau Web Data Connector v2 (obsoleto)
Qué era: WDC v2 permitía crear conectores basados en JavaScript que extraían datos de API web directamente a Tableau.
Por qué ya no funciona: Obsoleto en Tableau 2023.1. Los conectores WDC v2 no son compatibles con ninguna de las versiones actuales de Tableau, y es posible que Tableau los elimine por completo en una futura versión. Es necesaria la migración a WDC v3, pero la v3 tiene una arquitectura fundamentalmente diferente.
Limitación crítica: Se ha finalizado el soporte. Si todavía utiliza conectores WDC v2, migre ahora, ya que podrían dejar de funcionar en cualquier actualización futura de Tableau.
Método 2: Google Sheets como capa intermedia
Cómo funciona: extrae los datos a Google Sheets (mediante Apps Script, IMPORTXML, IMPORTDATA o herramientas de terceros) y, a continuación, conecta Tableau a Sheets como fuente de datos en tiempo real.
Por qué utilizarlo: Es gratuito, no requiere programación y Tableau se conecta a Google Sheets a través de su conector de Google Drive.
Limitaciones importantes:
- Google Sheets tiene un límite de 10 millones de celdas; los Conjuntos de datos grandes alcanzan este límite rápidamente
- Las fórmulas
IMPORTXMLeIMPORTHTMLfallan constantemente debido a cambios en la estructura de los sitios web - La periodicidad de actualización no es fiable. Google limita la ejecución de fórmulas de forma impredecible
- No hay renderización de JavaScript, por lo que las aplicaciones modernas de página única (SPA) devuelven datos vacíos (para estas se requiere un Navegador de scraping )
- Los límites de frecuencia de la API de Google Sheets provocan fallos de sincronización durante las actualizaciones programadas
Conclusión: funciona para prototipos pequeños. Deja de funcionar a cualquier escala mayor. Buena opción para paneles de control personales que registran menos de 10 000 filas de datos que rara vez cambian.
Método 3: Excel + OneDrive / SharePoint
Cómo funciona: Utilice la función Power Query de Excel o «Obtener datos de la web» para extraer datos de URL y guardarlos en OneDrive. A continuación, conecte Tableau al archivo de Excel alojado en la nube.
Limitaciones críticas:
- Se requiere una actualización manual: Power Query no se actualiza automáticamente en segundo plano de forma fiable
- No admite renderizado de JavaScript, por lo que no puede gestionar React, Angular ni ningún sitio basado en SPA
- Parseo limitado. Las estructuras HTML complejas suelen interrumpir la importación
- Los conflictos de sincronización de OneDrive provocan problemas de integridad de los datos
- La ausencia de rotación de proxies implica bloqueos de IP ante cualquier volumen significativo de scraping
Conclusión: Vale para un único informe de una página web estática. No es un canal de datos.
Método 4: TabPy (Python + extensiones de Tableau)
Cómo funciona: TabPy es el servidor Python oficial de Tableau. Ejecuta scripts de Python dentro de los campos calculados de Tableau utilizando funciones como SCRIPT_REAL y SCRIPT_STR. En teoría, la lógica de Scraping web se ejecuta directamente dentro de Tableau a través de TabPy.
Por qué utilizarlo: Python cuenta con amplias bibliotecas de scraping, y TabPy es compatible oficialmente con Tableau.
Limitaciones críticas:
- Requiere un servidor TabPy en ejecución: infraestructura adicional que mantener
- El scraping dentro de los campos calculados de Tableau es un antipatrón. Es lento, poco fiable y bloquea la visualización del dashboard
- La ausencia de rotación de proxies implica que la IP de tu servidor TabPy será bloqueada inmediatamente en objetivos de alto volumen
- No resolución de CAPTCHA, no tiene lógica de reintentos ni renderización de JavaScript
- Los campos calculados tienen límites de tiempo de ejecución, por lo que las tareas de scraping complejas agotan el tiempo de espera
- La depuración es extremadamente difícil porque los errores se muestran como mensajes de error poco claros de Tableau
En resumen: TabPy es ideal para ejecutar modelos de aprendizaje automático y cálculos estadísticos dentro de Tableau. No es adecuado para el Scraping web.
Método 5: Scripts de Python personalizados (requests, Scrapy, Selenium)
Cómo funciona: Escribe scripts de Python personalizados utilizando bibliotecas como requests, BeautifulSoup, Scrapy o Selenium. Ejecútalos según una programación (como cron o Airflow), genera archivos CSV/JSON y conecta Tableau a esos archivos.
Por qué utilizarlo: Máxima flexibilidad. Usted controla todo.
Limitaciones críticas:
- Gran carga de mantenimiento: los sitios web cambian de diseño, añaden medidas contra los bots y modifican las estructuras HTML. Su Scraper falla sin previo aviso y el panel muestra datos desactualizados.
- Bloqueo de IP a gran escala: sin una red de Proxy, los sitios de destino bloquean tu servidor en cuestión de horas
- Sin resolución de CAPTCHA: Cloudflare, reCAPTCHA y hCaptcha bloquean su Scraper sin una solución integrada (servicios como Web Unlocker se encargan de esto automáticamente)
- Costes de infraestructura: necesitas servidores, suscripciones a Proxy, supervisión y alertas
- Riesgo de incumplimiento normativo: sin la infraestructura adecuada, puedes infringir el RGPD, la CCPA o los términos de las plataformas
- No es escalable: extraer datos de 100 URL es diferente a hacerlo con 100 000. La arquitectura que funciona para una cantidad falla por completo con la otra.
Conclusión: el «hazlo tú mismo» es viable al principio, pero no es fiable a largo plazo. La mayoría de los equipos empiezan así, y muchos tienen éxito al principio. Pero el esfuerzo de mantenimiento aumenta con el tiempo.
Funciona bien el primer mes, pero al cabo de varios meses se dedica más tiempo a arreglar selectores defectuosos y bloqueos de IP que a crear paneles de control. Si se extraen datos de uno o dos sitios web con un volumen reducido, es posible que los scripts DIY sean todo lo que se necesita.
Método 6: API Web Scraper de Bright Data (recomendado)
Cómo funciona: La API Web Scraper de BrightData se encarga de toda la capa de recopilación de datos: rotación de proxies, Resolución de CAPTCHA, renderización de JavaScript, elusión de sistemas anti-bot y salida de datos estructurados. Se activa una tarea de recopilación a través de la API, se reciben datos limpios en formato JSON/CSV y se cargan en Tableau.
Ventajas:
| Capacidad | Bright Data | Scripts DIY |
|---|---|---|
| Red de proxies | Más de 150 millones de direcciones IP en 195 países | Compra las tuyas propias (caras) |
| Scrapers ya preparados | Más de 120 para las principales plataformas | Crea uno desde cero |
| Resolución de CAPTCHA | Automático | No incluido |
| Renderización de JavaScript | Integrado | Requiere Selenium/Playwright |
| Evitar el bloqueo de bots | Automático | Requiere actualizaciones manuales constantes |
| Tiempo de actividad | 99,99 % | Depende de tu infraestructura |
| Cumplimiento normativo | RGPD, CCPA, ISO 27001 | Tu responsabilidad |
| Mantenimiento | Mínimo: Bright Data se encarga de las actualizaciones del Scraper | Constante |
| Escala | Millones de páginas al día | Limitado por tus servidores |
| Precios | Desde 1,50 $ por cada 1000 registros | Variable (servidores + Proxies + mantenimiento) |
Conclusión: tú te centras en los paneles de Tableau; Bright Data se encarga de la infraestructura de recopilación de datos.
Contras: Bright Data es un servicio de terceros de pago. Dependes de su infraestructura y su modelo de precios. Para el scraping ocasional de uno o dos sitios con un volumen reducido, un script DIY (Método 5) cuesta menos y te ofrece un control total.
¿Qué método de conexión de datos de Tableau deberías elegir?
Esta tabla compara los seis métodos en función de las capacidades más importantes para los procesos de producción.
| Método | Renderización JS | Rotación de proxies | Resolución de CAPTCHA | Actualización automática | Escalado | Mantenimiento | Estado |
|---|---|---|---|---|---|---|---|
| WDC v2 | No | No | No | Sí | Bajo | N/A | Obsoleto |
| Hojas de cálculo de Google | No | No | No | Poco fiable | Muy baja | Bajo | Límites de celda |
| Excel + OneDrive | No | No | No | Manual | Muy bajo | Medio | Proceso manual |
| TabPy | Manual/Hazlo tú mismo | No | No | Sí | Bajo | Alto | Bloqueos de IP |
| Python para principiantes | A través de Selenium | Hazlo tú mismo | No | A través de cron | Medio | Muy alto | Interrupciones a gran escala |
| API de Bright Data | Sí | Sí (más de 150 millones de direcciones IP) | Sí | Sí | Alta | Mínimo | Listo para producción |
Tutorial: conectar una API de Scraping web a Tableau
Este tutorial crea un flujo de trabajo real: precios de productos de Amazon → API de Bright Data → CSV → panel de Tableau utilizando la API de Amazon Scraper. Abarca el caso de uso «Monitoreo de precios de la competencia», la razón más común por la que los equipos conectan datos web a Tableau.
Arquitectura
El proceso sigue este flujo:
┌─────────────────┐ ┌──────────────────────┐ ┌─────────────┐ ┌─────────────┐
│ Su script │────▶│ Bright Data Scraper │────▶ │ CSV/JSON │────▶│ Tableau │
│ (Python/cron) │ │ API │ │ Salida │ │ Panel de control │
└─────────────────┘ └──────────────────────┘ └─────────────┘ └─────────────┘
│ │ │
Activar con Gestiona Proxies, Visualiza precios,
palabras clave/URLs CAPTCHAs, renderización valoraciones, tendenciasRequisitos previos
Necesitarás tener instalado o disponible lo siguiente antes de empezar:
- Python 3.8+
- Una cuenta de Bright Data (prueba gratuita disponible, no se requiere tarjeta de crédito)
- Tu token de API del panel de control de Bright Data (instrucciones en el paso 0)
- Tableau Desktop (prueba gratuita de 14 días), Tableau Cloud o Tableau Public (gratuito, los paneles son públicos)
Una vez que tengas estas herramientas listas, empieza por generar tu token de API de Bright Data.
Paso 0: Obtén tu token de API de Bright Data
Sigue estos pasos para generar tu token de API:
- Regístrate o inicia sesión en brightdata.com/cp
- Vaya a Configuración de la cuenta → Usuarios y claves API
- Selecciona «Añadir clave API» (arriba a la derecha de la sección de claves API)
- Establece los permisos y la fecha de caducidad, y luego selecciona Guardar
- Copia el token
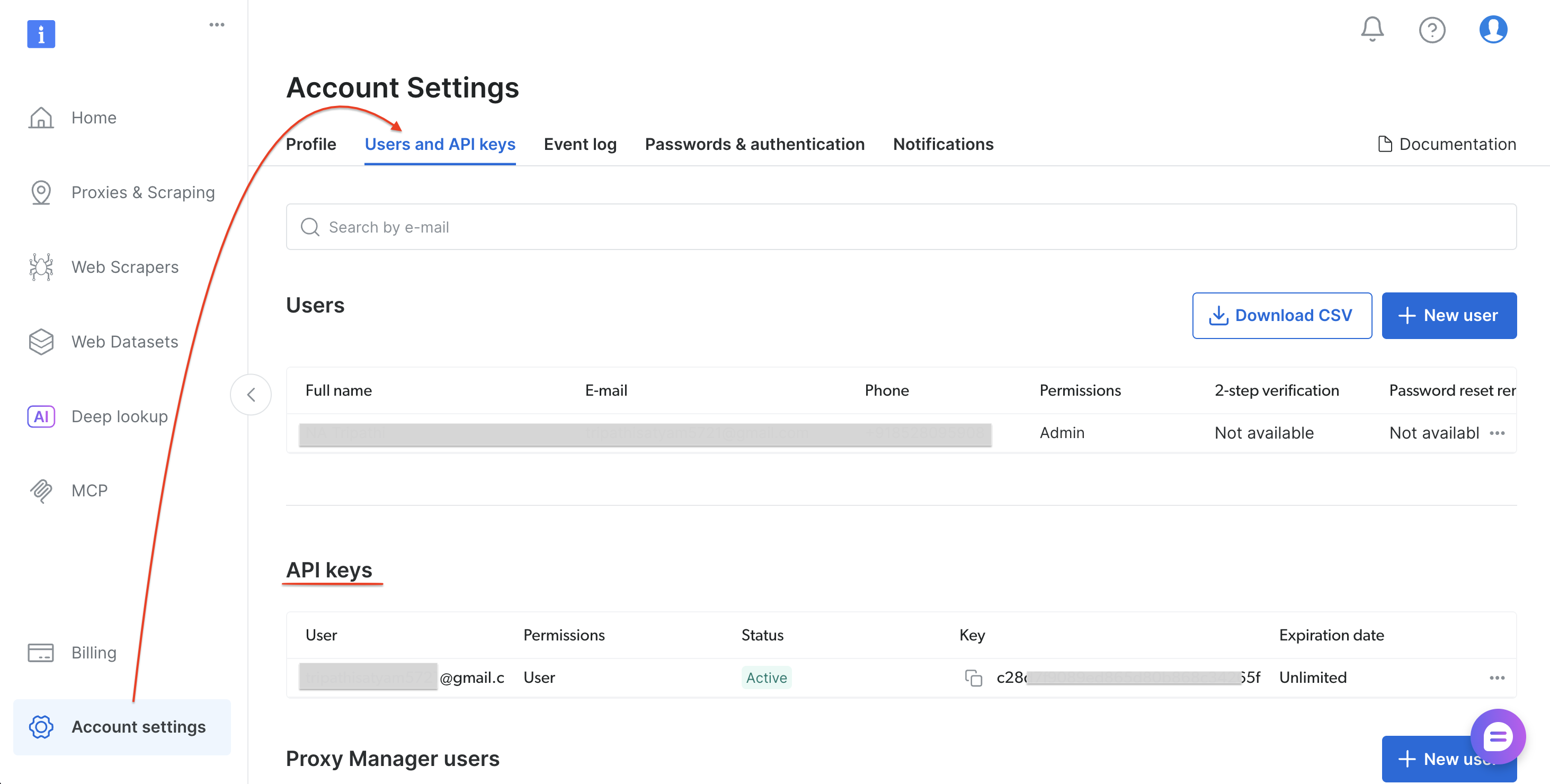
Una vez guardado el token de API, instala las dependencias de Python.
Paso 1: Instalar las dependencias
Instala los paquetes de Python necesarios:
pip install requests pandasUna vez instalados requests y pandas, crea el script del pipeline.
Paso 2: El script del pipeline
Crea un archivo llamado bright_data_to_tableau.py:
"""
Pipeline de Bright Data → Tableau
Extrae datos de productos de Amazon a través de la API Web Scraper de Bright Data
y genera un archivo CSV listo para Tableau.
Uso:
1. Reemplaza YOUR_API_TOKEN por tu token de API de Bright Data
2. Ejecuta: python bright_data_to_tableau.py
3. Abre el archivo CSV resultante en Tableau Desktop
"""
import requests
import time
import json
import sys
import pandas as pd
from datetime import datetime
# ─── Configuración ───────────────────────────────────────────────────────────
API_TOKEN = "YOUR_API_TOKEN" # Sustitúyelo por tu token de API de Bright Data
DATASET_ID = "gd_lwdb4vjm1ehb499uxs" # Búsqueda de productos de Amazon (por palabra clave)
OUTPUT_CSV = "amazon_products_tableau.csv"
POLL_INTERVAL = 10 # segundos entre comprobaciones de estado
POLL_TIMEOUT = 300 # tiempo máximo de espera en segundos
# ─── Puntos finales de la API ───────────────────────────────────────────────────────────
TRIGGER_URL = (
f"https://api.brightdata.com/conjuntos_de_datos/v3/trigger"
f"?dataset_id={DATASET_ID}&include_errors=true"
)
SNAPSHOT_URL = "https://api.brightdata.com/conjuntos_de_datos/v3/snapshot"
HEADERS = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
def trigger_collection(keyword: str) -> str:
"""Activa una tarea de recopilación de datos en Bright Data."""
payload = [{
"keyword": keyword,
"url": "https://www.amazon.com",
"pages_to_search": 1
}]
print(f"[1/3] Activando la recopilación para la palabra clave: '{keyword}'...")
response = requests.post(TRIGGER_URL, headers=HEADERS, data=json.dumps(payload))
if response.status_code != 200:
print(f" ERROR {response.status_code}: {response.text}")
sys.exit(1)
result = response.json()
snapshot_id = result.get("snapshot_id")
print(f" ID de instantánea: {snapshot_id}")
return snapshot_id
def poll_snapshot(snapshot_id: str) -> list:
"""Interroga el punto final de la instantánea hasta que los datos estén listos."""
url = f"{SNAPSHOT_URL}/{snapshot_id}?format=json"
elapsed = 0
print(f"[2/3] Esperando resultados...")
while elapsed < POLL_TIMEOUT:
response = requests.get(url, headers=HEADERS)
if response.status_code == 200:
data = response.json()
print(f" ¡Listo! Se han recibido {len(data)} registros.")
return data
elif response.status_code == 202:
print(f" Procesando... ({elapsed}s / {POLL_TIMEOUT}s)")
time.sleep(POLL_INTERVAL)
elapsed += POLL_INTERVAL
else:
print(f" ERROR {response.status_code}: {response.text}")
sys.exit(1)
print(f" TIEMPO DE ESPERA AGOTADO: Instantánea no lista tras {POLL_TIMEOUT}s.")
print(f" Intente aumentar POLL_TIMEOUT o consulte el panel de control de Bright Data.")
sys.exit(1)
def to_tableau_csv(data: list, output_path: str) -> pd.DataFrame:
"""Transforma los datos sin procesar de la API en un CSV limpio y optimizado para Tableau."""
df = pd.DataFrame(data)
# Asigna nombres de campos de la API → nombres compatibles con Tableau
column_mapping = {
"title": "Nombre del producto",
"seller_name": "Vendedor",
"brand": "Marca",
"initial_price": "Precio original",
"final_price": "Precio actual",
"currency": "Moneda",
"rating": "Valoración",
"reviews_count": "Número de reseñas",
"availability": "Disponibilidad",
"url": "URL del producto",
"asin": "ASIN",
"categories": "Categorías",
"delivery": "Información de entrega",
}
# Conservar solo las columnas presentes en los datos
disponibles = {k: v para k, v en column_mapping.items() si k está en df.columns}
df = df.rename(columns=disponibles)
df = df[list(disponibles.values())]
# Añadir metadatos para el filtrado y seguimiento de Tableau
df["Scrape Date"] = datetime.now().strftime("%Y-%m-%d")
df["Scrape Timestamp"] = datetime.now().isoformat()
df["Data Source"] = "Bright Data API"
df.to_csv(output_path, index=False)
print(f"[3/3] Filas guardadas {len(df)} → {output_path}")
return df
def print_summary(df: pd.DataFrame):
"""Imprime un resumen de los datos extraídos."""
print(f"n{'─'*50}")
print(f" Resumen")
print(f"{'─'*50}")
print(f" Total de productos : {len(df)}")
if "Precio actual" in df.columns:
precios = pd.to_numeric(df["Precio actual"], errors="coerce")
print(f" Rango de precios : ${prices.min():.2f} – ${prices.max():.2f}")
print(f" Precio medio : ${prices.mean():.2f}")
if "Brand" in df.columns:
print(f" Marcas únicas : {df['Brand'].nunique()}")
if "Rating" in df.columns:
ratings = pd.to_numeric(df["Rating"], errors="coerce")
print(f" Valoración media : {ratings.mean():.1f} / 5.0")
print(f"{'─'*50}n")
def run_pipeline(keyword: str):
"""Ejecutar el pipeline completo: Trigger → Poll → CSV → Summary."""
print(f"n{'='*50}")
print(f" Bright Data → Tableau Pipeline")
print(f" Palabra clave: '{keyword}'")
print(f"{'='*50}n")
snapshot_id = trigger_collection(keyword)
data = poll_snapshot(snapshot_id)
df = to_tableau_csv(data, OUTPUT_CSV)
print_summary(df)
return df
if __name__ == "__main__":
# Palabra clave predeterminada: cámbiala o pásala como argumento de la CLI
keyword = sys.argv[1] if len(sys.argv) > 1 else "auriculares inalámbricos"
run_pipeline(keyword)Paso 3: Ejecutar el script
Ejecuta el script del pipeline:
python bright_data_to_tableau.pySalida esperada:
==================================================
Bright Data → Pipeline de Tableau
Palabra clave: «auriculares inalámbricos»
==================================================
[1/3] Activando la recopilación para la palabra clave: «auriculares inalámbricos»...
ID de instantánea: sd_mmlan9p51yycmmkd7d
[2/3] Esperando resultados...
Procesando... (0 s / 300 s)
¡Listo! Se han recibido 43 registros.
[3/3] Se han guardado 43 filas → amazon_products_tableau.csv
──────────────────────────────────────────────────
Resumen
──────────────────────────────────────────────────
Total de productos: 43
Rango de precios: 0,00 $ – 169,95 $
Precio medio: 45,98 $
Marcas únicas: 4
Valoración media: 4,4 / 5,0
──────────────────────────────────────────────────El archivo CSV está listo. Ábrelo en Tableau para empezar a crear paneles.
Paso 4: Conéctese a Tableau
Cargue el CSV en Tableau y compruebe los tipos de datos:
- Abre Tableau Desktop, Tableau Cloud o Tableau Public
- Conéctese al CSV: en Desktop, seleccione Conectar → Archivo de texto. En Cloud, seleccione Nuevo → Libro de trabajo → pestaña Archivos y cargue el archivo
- Comprueba que
«Precio actual»y«Valoración»se detectan como «Número», no como «Cadena» - Seleccione la Hoja 1 para comenzar a crear
Vistas recomendadas del dashboard:
- Distribución de precios: histograma del
«Precio actual» para identificar el posicionamiento en el mercado - Análisis de la caída de precios: gráfico de barras en paralelo del
precio originalfrente alprecio actualpara identificar descuentos - Valoración frente a precio: gráfico de dispersión para encontrar productos de alto valor
- Comparación de marcas: gráfico de barras que agrupa los productos por
marcapara comparar precios y valoraciones
Paso 5: Automatizar la actualización
Para mantener tu panel actualizado, programa el script con cron (Linux/Mac) o el Programador de tareas (Windows):
# Ejecutar cada 6 horas — crontab -e
0 */6 * * * cd /path/to/project && python bright_data_to_tableau.pyActualización de Tableau para mostrar los nuevos datos:
- Tableau Desktop. Una vez que la tarea cron haya actualizado el CSV, pulsa F5 (Windows) o Comando+R (Mac) para recargar. También puedes seleccionar la fuente de datos en el menú Datos y elegir Actualizar. Tableau Desktop no actualiza automáticamente las fuentes basadas en archivos por sí solo, por lo que tendrás que actualizar manualmente o volver a abrir el libro de trabajo.
- Tableau Server. Desde Tableau Desktop, publique a través de Servidor → Publicar libro de trabajo. En el cuadro de diálogo de publicación, establezca una Programación de actualización del extracto (por ejemplo, cada 6 horas para que coincida con su tarea cron). Tableau Server actualizará automáticamente el extracto según esa programación.
- Tableau Cloud. Los archivos CSV cargados desde el navegador no se pueden actualizar automáticamente. Para automatizar las actualizaciones, instale Tableau Bridge en el equipo que ejecute su tarea cron. Bridge conecta su CSV local con Tableau Cloud y admite actualizaciones programadas de extractos. Sin Bridge, vuelva a cargar el CSV manualmente después de cada ejecución del pipeline.
- Tableau Public. No admite actualizaciones programadas para fuentes basadas en archivos. En el caso de los pipelines basados en CSV, deberá volver a publicar el libro cada vez que se actualicen los datos.
Paso 6: Utilice cualquier Scraper (búsqueda de ID de Conjuntos de datos)
El tutorial utiliza el conjunto de datos Amazon Products Search (gd_lwdb4vjm1ehb499uxs). Para extraer datos de un sitio web diferente, cambia el ID del conjunto de datos. A continuación te indicamos cómo encontrarlo:
- Inicie sesión en el panel de control de Bright Data
- Selecciona «Web Scrapers» en la barra lateral para abrir la biblioteca de Scrapers web
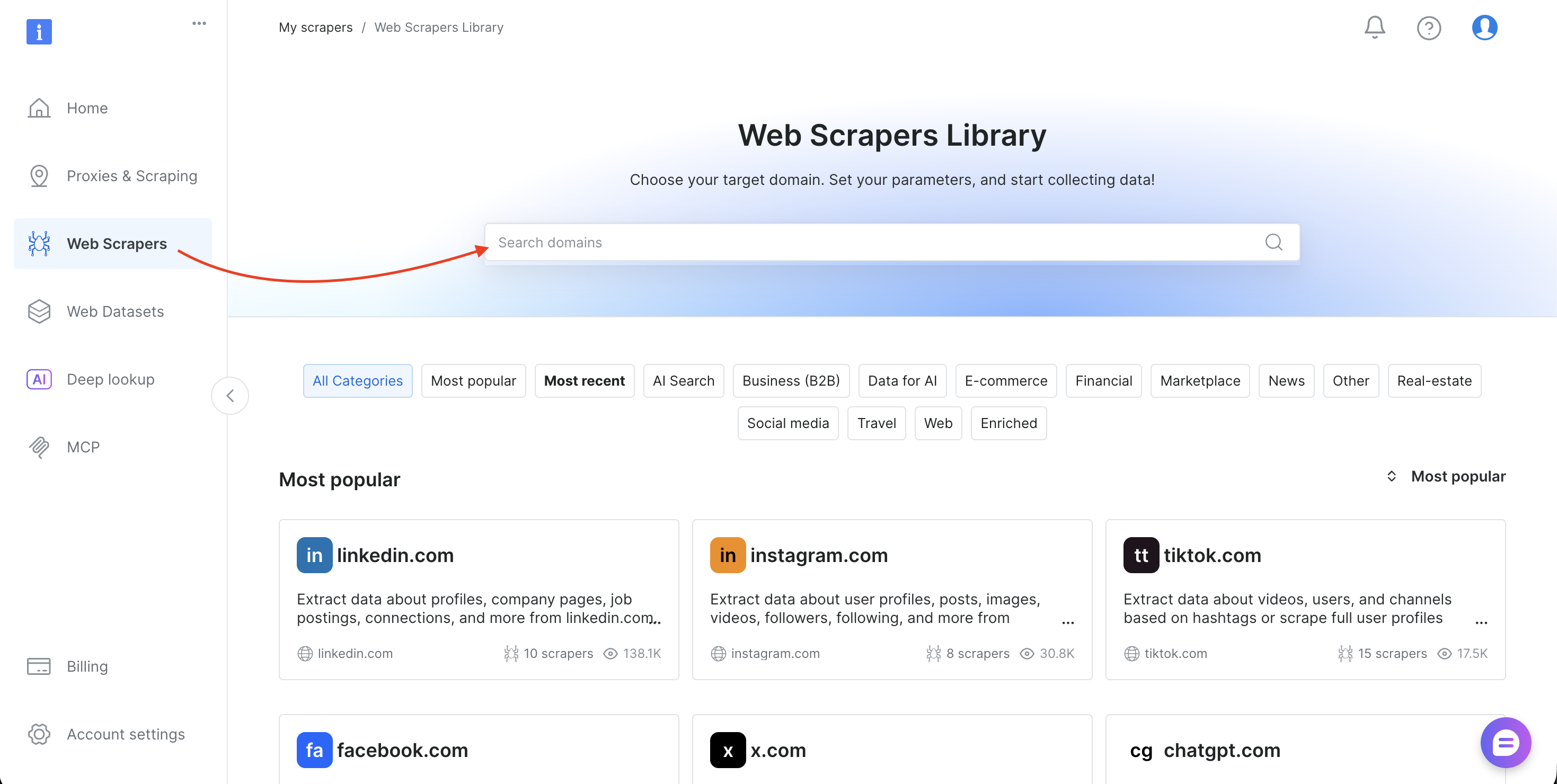
- Busca el dominio de destino (como amazon.com, zillow.com o linkedin.com) y selecciónalo
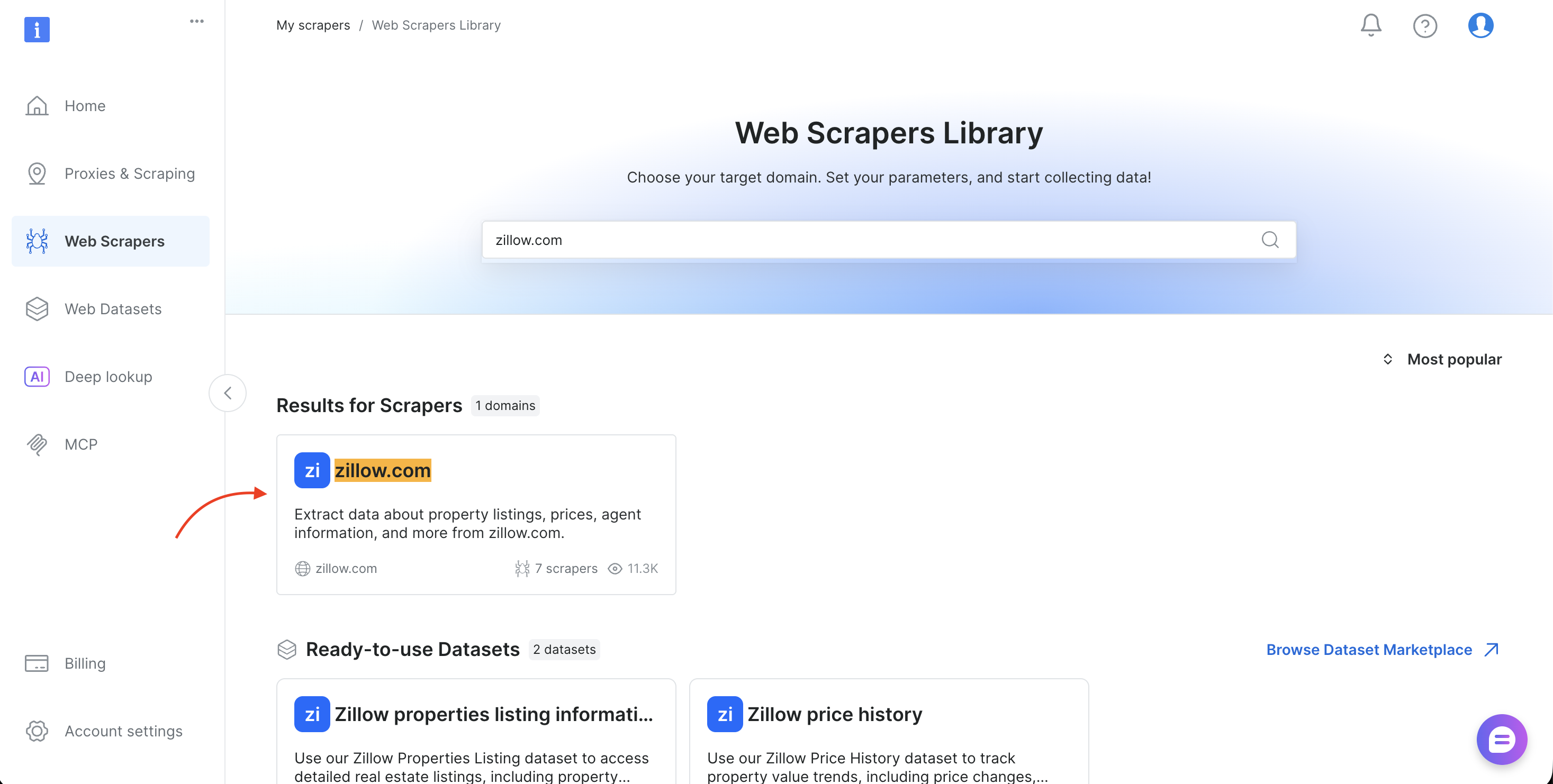
- Elige el método de recopilación (Recopilar por URL o Descubrir por palabra clave)
- Copia el
dataset_idde la barra de direcciones del navegador (por ejemplo,brightdata.com/cp/Scrapers/gd_lfqkr8wm13ixtbd8f5) o del panel de ejemplos de código
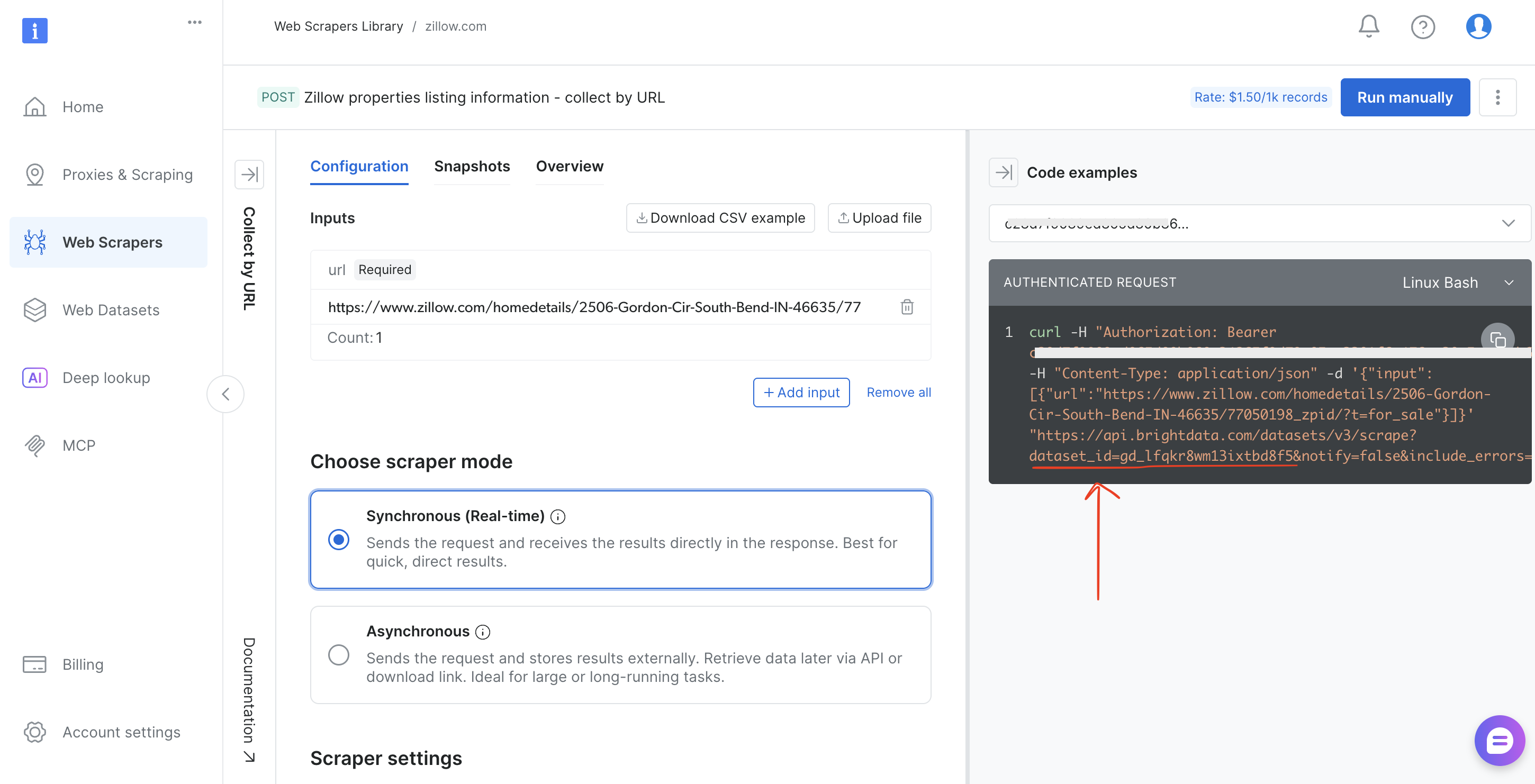
Sustituye DATASET_ID en el script, ajusta la carga útil, y el mismo proceso funciona para cualquiera de los más de 120 Scrapers de Bright Data.
Resultados reales: aspecto de los datos extraídos
La siguiente captura de pantalla muestra la salida CSV sin procesar del proceso, exactamente lo que la API de Bright Data devolvió para la palabra clave «auriculares inalámbricos»:
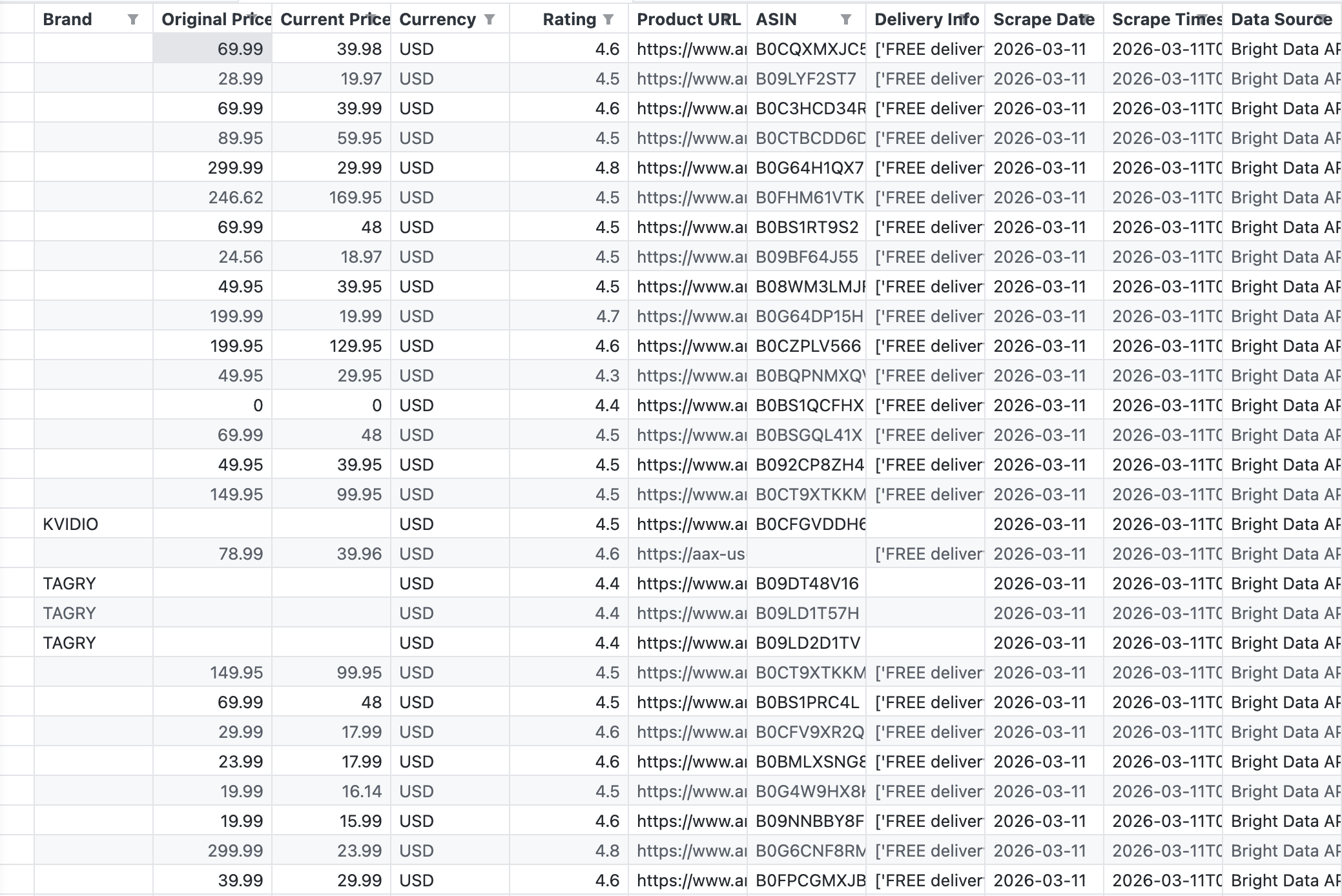
La API devolvió 43 registros con campos que incluyen Marca, Precio original, Precio actual, Valoración, ASIN, URL del producto e Información de entrega.
La API devolvió 43 productos en una sola llamada. Los datos están estructurados y listos para Tableau. Sin parseo de HTML, sin selectores rotos, sin retos CAPTCHA. Para obtener más detalles sobre las opciones de scraping de Amazon, consulta Cómo extraer datos de productos de Amazon.
Visualización de los datos: del CSV a los insights
Estas cuatro visualizaciones muestran lo que produce el proceso. Cada vista se ha creado a partir del mismo CSV que generó el script:
Distribución de precios entre productos
Este gráfico clasifica 31 productos (aquellos con nombres analizables a partir de sus URL de Amazon) por precio actual, de menor a mayor:
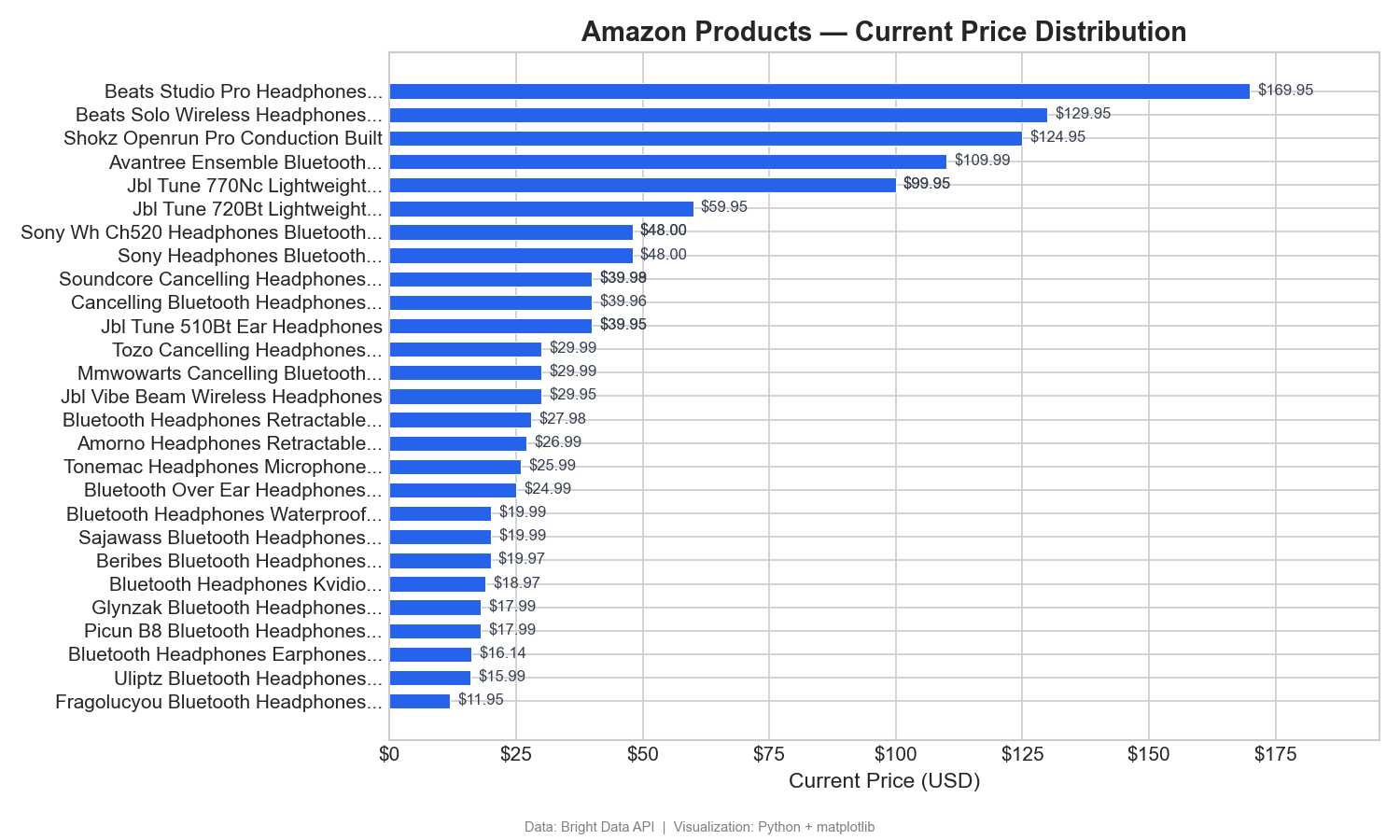
Este gráfico de barras horizontales muestra claramente el rango de precios: Beats domina el segmento premium (125–170 $), mientras que la mayoría de los auriculares inalámbricos se agrupan en el rango de 12–60 $. En Tableau, se crearía esto como un gráfico de barras ordenado con «Precio actual» en las columnas y «Nombre del producto » en las filas.
Bajas de precio: precio original frente a precio actual
Este gráfico de barras agrupadas compara los precios de catálogo y los precios actuales de los 10 productos con mayor descuento:
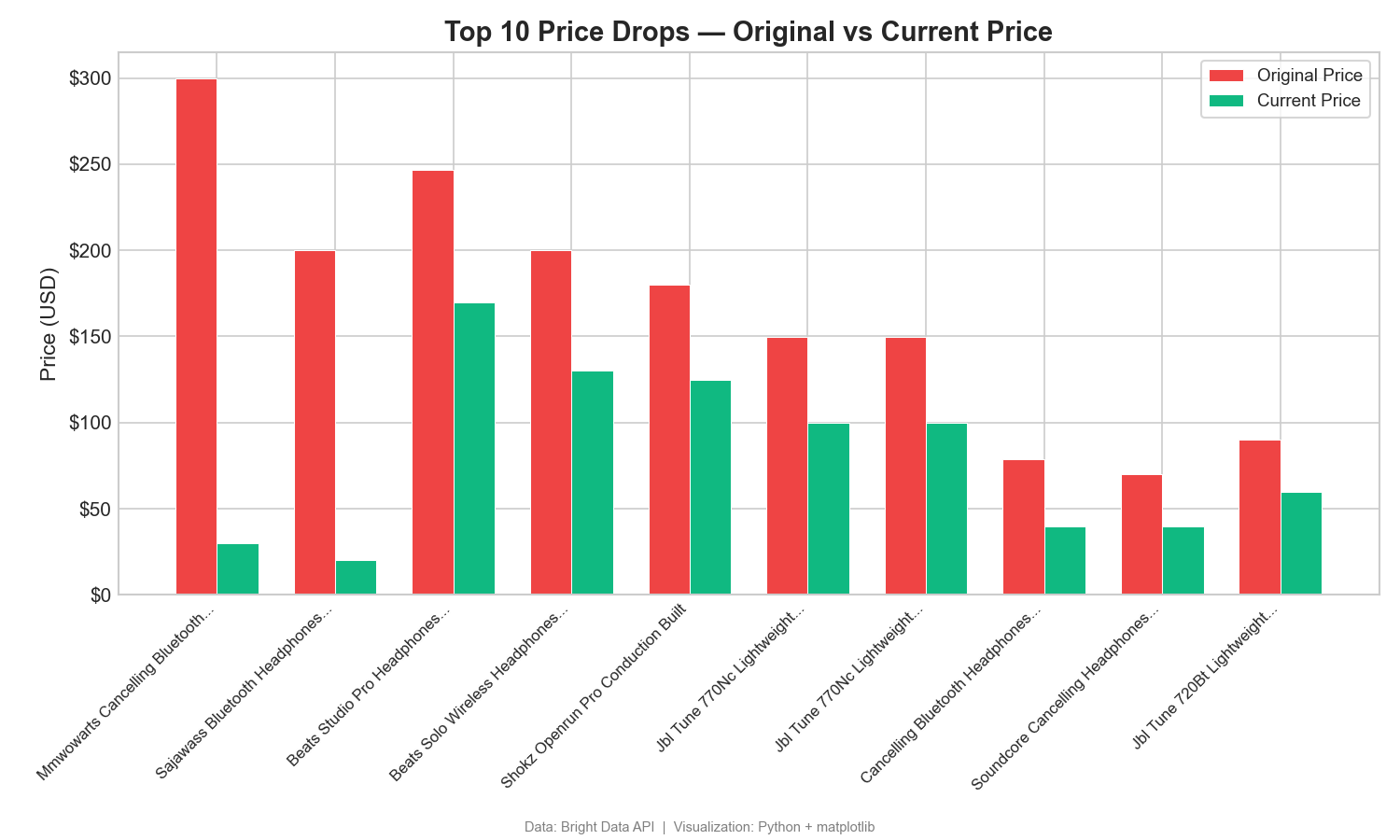
La diferencia entre el precio original y el actual muestra grandes descuentos. Un producto presenta una bajada de 270 $ respecto a su precio original de catálogo (299,99 $ → 29,99 $). Diferencias como esta reflejan estrategias promocionales y de precios. En Tableau, utilice un gráfico de barras en paralelo con los nombres de las medidas en el color.
Valoración frente a precio: búsqueda de valor
Este gráfico de dispersión representa las valoraciones de los clientes en función del precio para identificar productos de alto valor:
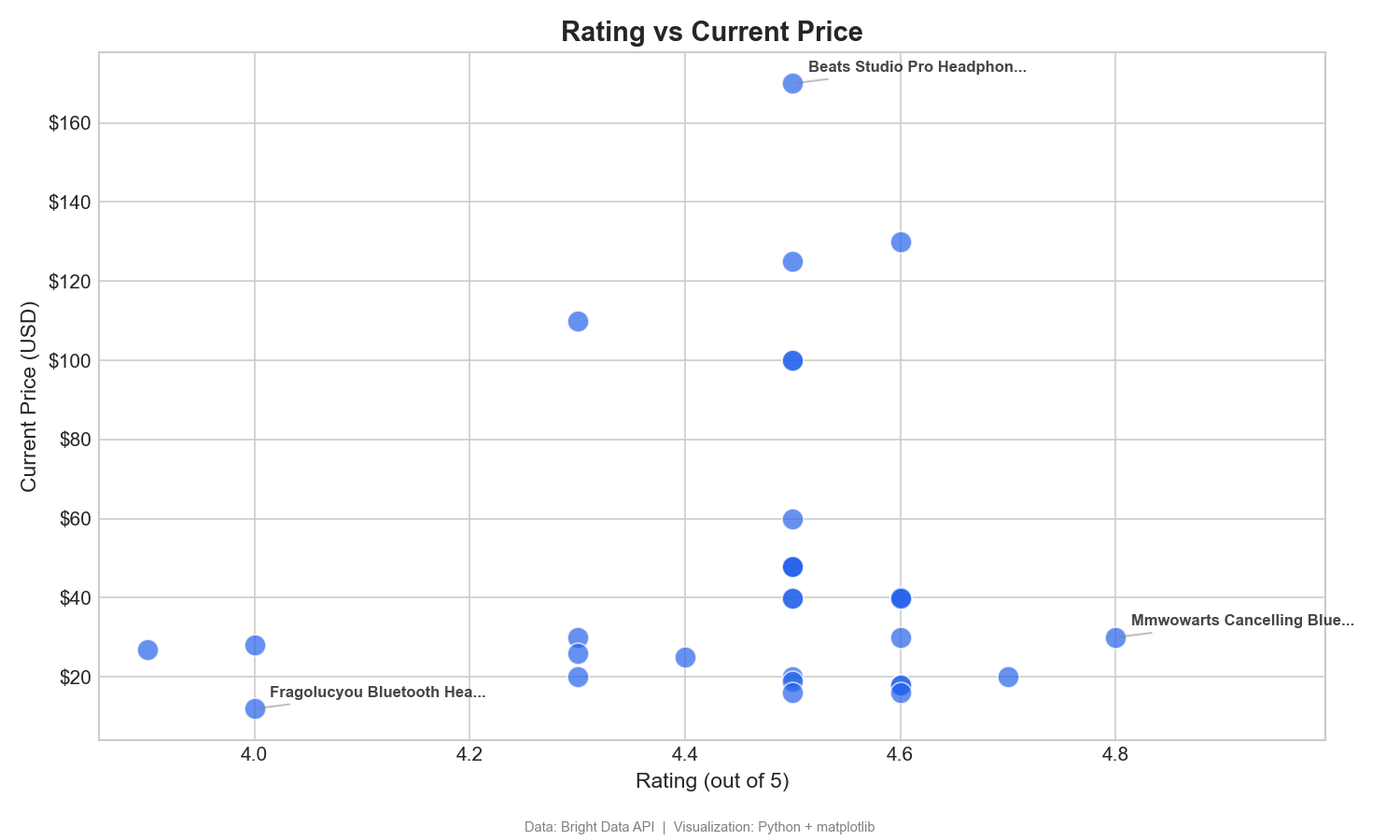
Este gráfico de dispersión ayuda a identificar productos de alto valor, aquellos con valoraciones altas y precios bajos (cuadrante inferior derecho). Los auriculares MMWOWARTS a 29,99 $ con una valoración de 4,8 son un claro ejemplo. En Tableau, arrastre «Valoración» a «Columnas», «Precio actual» a «Filas» y «Nombre del producto » a «Detalle».
Segmentación del mercado por rango de precios
Este gráfico de anillo desglosa los productos por rango de precios:
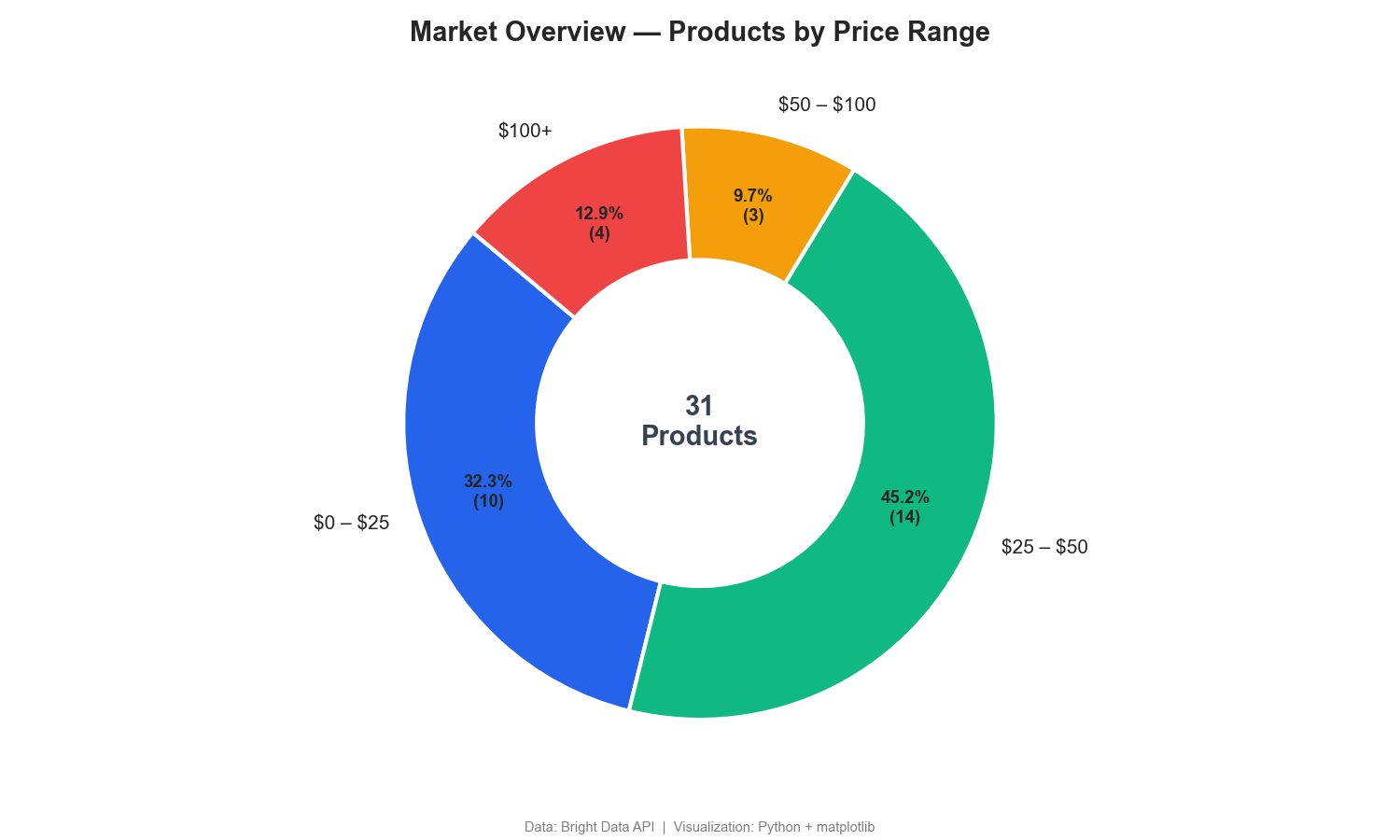
El gráfico de anillo muestra que el 77 % de los auriculares inalámbricos se venden por menos de 50 $, mientras que solo el 13 % se encuentra en el segmento premium de más de 100 $. Los paneles de control de Monitoreo de precios de la competencia suelen incluir una segmentación similar.
Bonus: canalización inmobiliaria con Zillow
El mismo patrón de canalización funciona con cualquiera de los más de 120 Scrapers de Bright Data. El siguiente ejemplo utiliza la API del Scraper de Zillow (repositorio de GitHub). Actualice dos variables en bright_data_to_tableau.py y el resto de la canalización se ejecutará sin cambios:
# Reemplaza el ID del conjunto de datos de Amazon por el ID del conjunto de datos de Zillow
DATASET_ID = "gd_lfqkr8wm13ixtbd8f5" # Propiedades de ZillowA continuación, actualice la carga útil en trigger_collection() para utilizar una URL de ubicación en lugar de una palabra clave:
payload = [{
"url": "https://www.zillow.com/new-york-ny/"
}]Ejecute el script de la misma manera. La lógica de sondeo y exportación a CSV funciona sin cambios.
Los campos de Zillow incluyen: dirección de la propiedad, precio, dormitorios, baños, superficie, tamaño del terreno, año de construcción, tipo de propiedad, estado del anuncio y Zestimate.
Ideas para el panel de Tableau:
- Mapa de calor del precio por metro cuadrado por código postal
- Análisis de la diferencia entre el precio de venta y el Zestimate
- Distribución de tipos de vivienda por ciudad o código postal
- Gráfico de dispersión de año de construcción frente a precio para oportunidades de renovación
La ventaja clave: aprendes el patrón una vez y luego lo aplicas a cualquier fuente de datos. Amazon, Zillow, ofertas de empleo de LinkedIn: todos utilizan la misma infraestructura de Bright Data para enviar datos a los paneles de Tableau.
Los 6 principales casos de uso de datos web en tiempo real en Tableau
Estas son las razones más comunes por las que los equipos crean canalizaciones de datos web en Tableau.
1. Monitoreo de precios de la competencia
Realice un seguimiento de los precios de la competencia en Amazon, Walmart, Target o cualquier plataforma de comercio electrónico. Cree paneles de Tableau que muestren las variaciones diarias de precios, las tendencias históricas y el posicionamiento de precios en su mercado. Configure alertas cuando los competidores bajen por debajo de su precio mínimo.
Supervise miles de SKU en múltiples mercados con los más de 120 Scrapers listos para usar de Bright Data. No se necesitan Scrapers personalizados.
Vistas de Tableau: gráficos de cascada de precios, tendencias de series temporales por SKU, mapas de calor de precios de la competencia.
2. Seguimiento de la marca en redes sociales
Extrae menciones, métricas de interacción, recuentos de seguidores y datos de comentarios de Instagram, Twitter/X, TikTok y LinkedIn. Crea paneles que hagan un seguimiento de la visibilidad de la marca en todas las plataformas y midan el rendimiento de las campañas a lo largo del tiempo. El Navegador de scraping gestiona plataformas sociales con gran cantidad de JavaScript que las solicitudes HTTP estándar no pueden renderizar.
Vistas de Tableau: tendencias de la tasa de interacción, volumen de menciones a lo largo del tiempo, gráficos de barras comparativos entre plataformas.
3. Análisis del mercado laboral
Agrega ofertas de empleo de Indeed, Glassdoor, LinkedIn (repositorio de GitHub) y bolsas de empleo especializadas. Analiza las tendencias de contratación, los salarios de referencia, las habilidades requeridas y los cambios en la demanda en distintos sectores y zonas geográficas. Los equipos de RR. HH. y los reclutadores utilizan estos paneles para comparar remuneraciones e identificar cambios en el mercado de talento antes que la competencia.
Vistas de Tableau: mapas de burbujas geográficas de puestos vacantes, histogramas de distribución salarial, mapas de árbol de demanda de habilidades.
4. Paneles de control inmobiliarios
Supervisa los anuncios inmobiliarios, los cambios de precios, los niveles de inventario y las tendencias de los barrios a partir de Zillow, Realtor.com, Redfin y Airbnb. Los inversores y analistas inmobiliarios crean mapas de calor geográficos en Tableau para identificar mercados infravalorados y realizar un seguimiento de las tendencias de rentabilidad de los alquileres en diferentes ciudades.
Vistas de Tableau: mapas de calor por código postal, diagramas de dispersión de precio por metro cuadrado, series temporales del volumen de anuncios.
5. Fuentes de datos financieros
Recopile cotizaciones bursátiles, informes de resultados, calificaciones de analistas, datos sobre operaciones con información privilegiada y noticias financieras de Yahoo Finance, Bloomberg y otras plataformas financieras. Los analistas cuantitativos y los gestores de carteras crean paneles financieros con actualización automática de datos para realizar un seguimiento del rendimiento de la cartera y de las señales del mercado.
Vistas de Tableau: gráficos de precios de tipo candlestick, gráficos de barras de sorpresas en los resultados, paneles de control de rotación sectorial.
6. Supervisión de la cadena de suministro
Realice un seguimiento de la disponibilidad de productos, las estimaciones de envío, los niveles de inventario de los vendedores y los precios en los mercados globales. Los equipos de operaciones crean paneles de Tableau que detectan interrupciones en el suministro, como agotamientos repentinos de existencias o picos en los tiempos de entrega, antes de que afecten al resto de la cadena de suministro.
Vistas de Tableau: matrices de estado de disponibilidad, líneas de tendencia de plazos de entrega, cuadros de mando de riesgo de proveedores.
Cada uno de estos casos de uso sigue la misma arquitectura: API de Bright Data → Datos estructurados → Panel de Tableau. Lo único que cambia es el ID del Conjunto de datos y las visualizaciones de Tableau que se crean.
Cómo funciona el proceso de la API de Bright Data
El script del tutorial se encarga de la activación y la consulta. Esto es lo que ocurre a lo largo de todo el proceso, desde la llamada a la API hasta el panel de Tableau.
Flujo de datos paso a paso
- Activación. Tu script de Python envía una solicitud POST al punto final
/triggerde Bright Data. Incluye una palabra clave (para el descubrimiento) o una lista de URL (para la recopilación selectiva). La API devuelve unsnapshot_idinmediatamente. - Recopilación. La infraestructura de Bright Data enruta las solicitudes a través de más de 150 millones de Proxies residenciales. Gestiona automáticamente los retos CAPTCHA, ejecuta JavaScript cuando es necesario y vuelve a intentar las solicitudes fallidas.
- Parseo. Bright Data realiza el parseo del HTML sin procesar y lo convierte en campos de datos estructurados. En el caso de los productos de Amazon, esto puede incluir el título, el precio, la valoración, las reseñas, la información del vendedor y la disponibilidad, aunque los campos exactos devueltos dependen de los Conjuntos de datos y del tipo de búsqueda.
- Instantánea. Una vez completadas la recopilación y el parseo, Bright Data almacena los datos como una instantánea. Su script consulta el punto final
/snapshothasta que el estado cambia de202 (en procesamiento)a200 (listo). - Entrega. Se recupera la instantánea en formato JSON o CSV. Como alternativa, se puede configurar la entrega a Amazon S3, Google Cloud Storage, Azure Blob, Snowflake, SFTP o webhook. La entrega automática resulta útil para los flujos de trabajo de producción que almacenan datos en un almacén.
- Transformación. Su script (o una herramienta como pandas) renombra columnas, filtra campos y formatea los datos para que Tableau pueda leerlos. Aquí es donde añade columnas de metadatos como la fecha de extracción y la fuente de datos.
- Visualización. Tableau lee el archivo de salida (o se conecta a una base de datos si ha cargado los datos allí) y representa su dashboard con los datos más recientes.
Ampliación del proceso
Para uso en producción, tenga en cuenta estas mejoras:
- Múltiples palabras clave. Recorra una lista de palabras clave o categorías de productos en su script para crear Conjuntos de datos completos.
- Almacenamiento en base de datos. En lugar de CSV, escribe en PostgreSQL o MySQL. Tableau se conecta de forma nativa a ambas, y los datos históricos se acumulan con el tiempo para el análisis de tendencias.
- Orquestación. Utilice Apache Airflow, Prefect o una tarea cron para programar ejecuciones con la frecuencia que requiera su negocio (cada hora, cada día, cada semana).
- Entrega mediante webhooks. Evite por completo el sondeo configurando Bright Data para que envíe los resultados a su servidor mediante POST cuando estén listos.
Lista de verificación de producción
Antes de implementar el proceso en un calendario de producción, resuelve estas cuestiones operativas:
- Gestión de errores. Envuelve las llamadas a la API en bloques try/except con lógica de reintento. Registra los fallos en un archivo o servicio de monitorización para detectar a tiempo los datos obsoletos.
- Deduplicación de datos. Añade una clave única (como el ASIN + la fecha de rastreo) y deduplica los datos antes de cargarlos en Tableau. Las filas duplicadas distorsionan las agregaciones.
- Validación del esquema. Verifique que la respuesta de la API contenga los campos esperados antes de escribir en CSV. Los cambios en el sitio web pueden alterar la estructura de los datos sin previo aviso.
- Supervisión y alertas. Configura alertas (correo electrónico, Slack o PagerDuty) para ejecuciones fallidas, Conjuntos de datos vacíos o caídas inesperadas en el recuento de filas.
- Copias de seguridad de datos. Archiva cada instantánea CSV con una marca de tiempo. Si un rastreo defectuoso daña tu archivo de trabajo, vuelve a la versión anterior.
Por qué elegir Bright Data para los flujos de trabajo de Tableau
Para los flujos de trabajo de Tableau en producción, estos factores son importantes:
- Entrega flexible. Obtenga resultados en formato JSON, CSV o NDJSON a través de API, webhook, Amazon S3, Google Cloud, Azure o SFTP. Cargue los datos en su almacén de datos de Tableau.
- Personalizado o listo para usar. Utilice Serverless Functions para crear scrapers personalizados, Scraper Studio para crear scrapers generados y basados en IA, o utilice Conjuntos de datos listos para usar para acceder al instante sin necesidad de escribir código.
- Rentable. Paga 1,50 $ por cada 1000 registros en el modelo de pago por uso, con descuentos por volumen de hasta 0,75 $/1000 en los niveles superiores.
Crea tu canalización de datos web en tiempo real
La brecha entre los datos disponibles y los datos necesarios sigue creciendo, especialmente cuando esos datos se encuentran en la web abierta sin API ni conector.
WDC v2 está obsoleto y ya no recibe soporte. Google Sheets alcanza los límites de celdas. Excel requiere trabajo manual. TabPy carece de rotación de proxies. Los scripts DIY fallan a gran escala.
La API Scraper de Bright Data proporciona la capa de infraestructura de la que carecen estos enfoques. La API incluye más de 120 Scrapers listos para usar, más de 150 millones de Proxies en 195 países, Resolución de CAPTCHA y salida de datos estructurados en formatos que Tableau admite de forma nativa. Los precios comienzan en 1,50 $ por cada 1000 registros, con un tiempo de actividad del 99,99 % y pleno cumplimiento GDPR, CCPA e ISO 27001.
En lugar de crear una infraestructura de recopilación de datos, céntrate en crear paneles de control.
Preguntas frecuentes
¿Se ha dejado de utilizar Tableau WDC?
Sí. El Web Data Connector v2 de Tableau quedó oficialmente obsoleto en la versión 2023.1. Tableau 2022.4, la última versión compatible con WDC v2, ha llegado al final de su vida útil. Los conectores WDC v2 no son compatibles con ninguna de las versiones actuales de Tableau y podrían eliminarse en cualquier actualización futura.
¿Qué ha sustituido a Tableau WDC?
Tableau lanzó WDC v3, pero solo permite extraer datos y no es compatible con Tableau Bridge. Para datos web en tiempo real, una canalización de API de scraping (Bright Data → CSV/JSON → Tableau) es una alternativa práctica. El tutorial de esta guía muestra cómo crear esa canalización.
¿Puede Tableau conectarse directamente a una API de Scraping web?
No de forma nativa. Tableau se conecta a bases de datos, archivos y servicios en la nube específicos. Para utilizar una API de scraping, se necesita un script ligero en Python o Node.js que llame a la API y reciba los datos. A continuación, el script genera un formato que Tableau puede leer: CSV, JSON o una inserción en una base de datos.
¿Cómo mantengo actualizados los datos de mi panel de Tableau?
Programe su script de recopilación de datos utilizando cron (Linux/Mac), el Programador de tareas (Windows) o un orquestador de flujos de trabajo como Apache Airflow. El script extrae los datos más recientes de la API de Bright Data y sobrescribe el archivo CSV. Tableau carga los datos actualizados en su siguiente ciclo de actualización.
¿Cuánto cuesta cargar datos web en Tableau?
La API Web Scraper de Bright Data tiene un precio inicial de 1,50 $ por cada 1000 registros en el modelo de pago por uso, con descuentos por volumen de hasta 0,75 $ por cada 1000 registros. Para un panel de control típico de monitorización de la competencia que realiza un seguimiento de 5000 productos al día, eso supone aproximadamente 7,50 $ al día o unos 225 $ al mes.
¿Qué formatos de datos genera Bright Data para Tableau?
Bright Data entrega los datos en formato JSON, CSV o NDJSON a través de la API. Para Tableau, el CSV es la opción más directa. Tableau lo lee de forma nativa sin necesidad de transformación. Como alternativa, configura la entrega automática a Amazon S3, Google Cloud Storage, Azure Blob, Snowflake, SFTP o webhook para los flujos de trabajo de producción.
¿Puedo usar Bright Data con Tableau Public?
Sí. Bright Data genera archivos CSV estándar que Tableau Public lee de forma nativa. La limitación está en el lado de Tableau Public: no admite actualizaciones programadas para fuentes basadas en archivos. Es necesario volver a ejecutar el script de recopilación de datos y volver a publicar el libro de trabajo cada vez que se actualicen los datos.





