

En esta guía, verá:
- Qué es la puesta a punto.
- Cómo afinar GPT-4o con una API web scraper a través de n8n.
- Una comparación entre enfoques de ajuste fino.
- Por qué los datos de alta calidad son el núcleo de cualquier proceso de ajuste.
Sumerjámonos.
¿Qué es el ajuste fino?
El ajuste fino, también conocido como ajuste fino supervisado (SFT, por sus siglas en inglés), es un procedimiento para mejorar el conocimiento o la capacidad específica de un LLM preentrenado. En el contexto de los LLM, el preentrenamiento se refiere al entrenamiento de un modelo de IA desde cero.
El ajuste fino es importante porque los modelos imitan los datos de entrenamiento. Esto significa que cuando se prueba un LLM después del entrenamiento, su salida seguirá de alguna manera los datos de entrenamiento. Como los LLM son modelos generalistas, si se quiere que adquieran conocimientos específicos, hay que ajustarlos a datos específicos.
Si quiere saber más sobre la SFT, lea nuestra guía sobre el ajuste fino supervisado en los LLM.
Cómo ajustar GPT-4o con la integración n8n de Bright Data
Como cubrimos en un tutorial reciente, ahora ya sabe cómo ajustar Llama 4 utilizando la nube con datos raspados mediante las API de Web Scraper. En esta sección guiada, conseguirá el mismo resultado ajustando GPT-4o mediante n8n, una popular plataforma de automatización de flujos de trabajo.
En detalle, nos referiremos a la misma página web de destino, que es la página de productos de oficina más vendidos de Amazon:
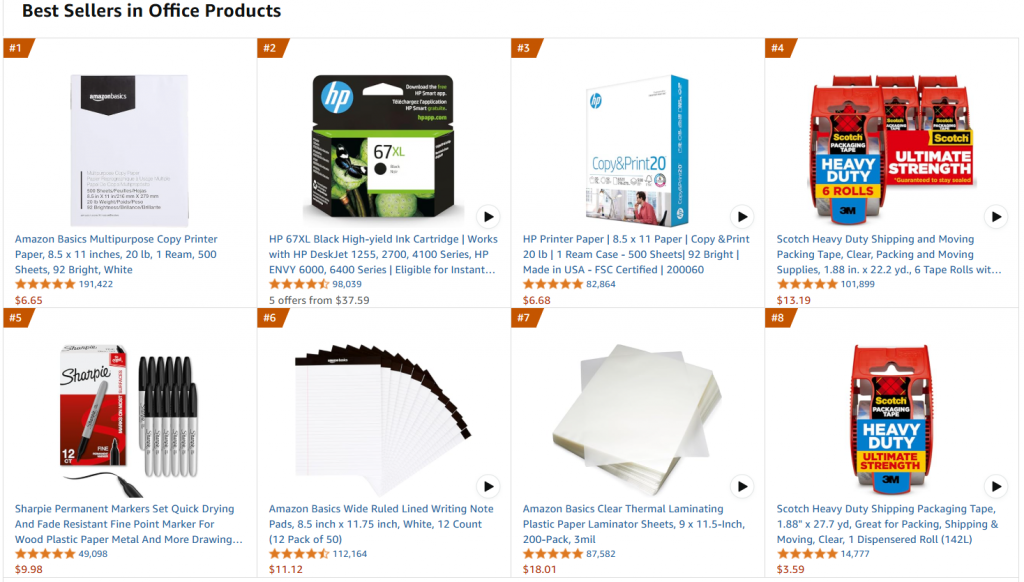
El objetivo de este proyecto es perfeccionar GPT-4o-mini para crear descripciones de productos de tipo ofimático, dadas algunas características como entrada en un prompt.
Siga los pasos que se indican a continuación para aprender a ajustar GPT-4o-mini mediante n8n con un conjunto de datos de entrenamiento extraídos de las soluciones de Bright Data.
Requisitos
Para reproducir este proceso de ajuste, necesitas lo siguiente:
- Un token activo de la API de Bright Data.
- Una cuenta n8n activa.
- Un token de la API de OpenAI.
Perfecto. Ya está listo para empezar a ajustar GPT-4o.
Paso 1: Crear un nuevo flujo de trabajo n8n e instalar el nodo de datos Bright
Después de iniciar sesión en n8n, el panel de control tiene el aspecto de la siguiente imagen:
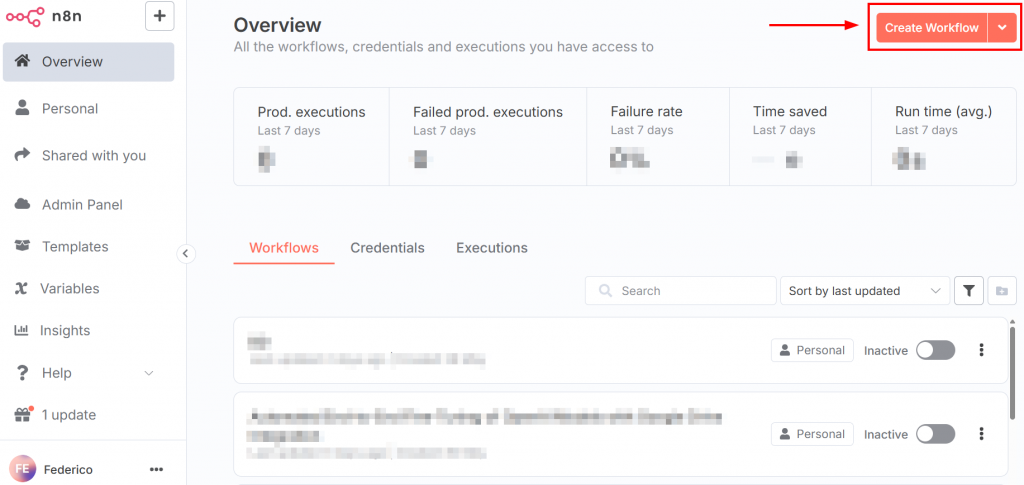
Para crear un nuevo flujo de trabajo, haga clic en el botón “Crear flujo de trabajo”. A continuación, haga clic en “Abrir panel de nodos”:
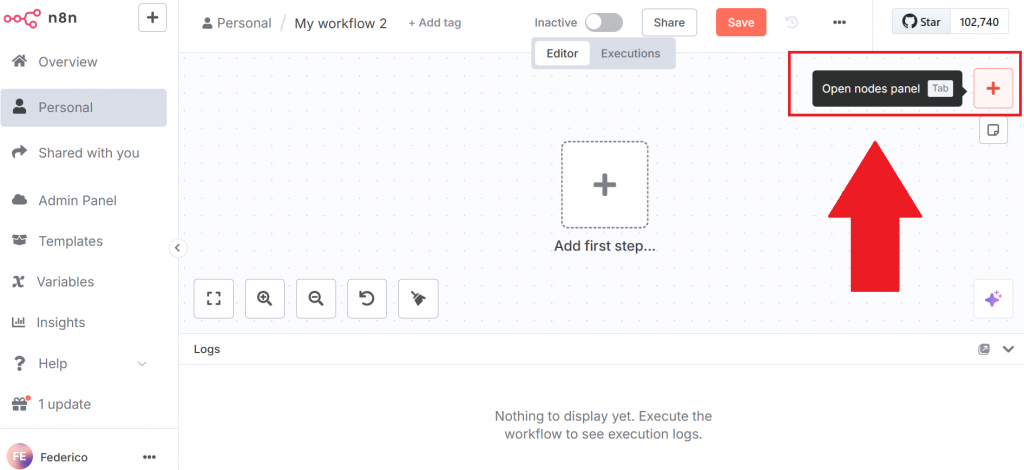
En el panel de nodos, busque el nodo de Bright Data. En n8n, un “nodo” es un bloque de construcción de un flujo de trabajo automatizado, que representa un paso o una acción distinta en la cadena de procesamiento de datos.
Haga clic en el nodo Bright Data n8n para instalarlo:

Para más información, consulte la página de documentación oficial sobre cómo configurar Bright Data en n8n.
Muy bien. Has inicializado tu primer flujo de trabajo n8n.
Paso 2: Configurar el nodo de Bright Data y extraer los datos
Haga clic en “Añadir primer paso” en la interfaz de usuario y seleccione “Activar manualmente”:
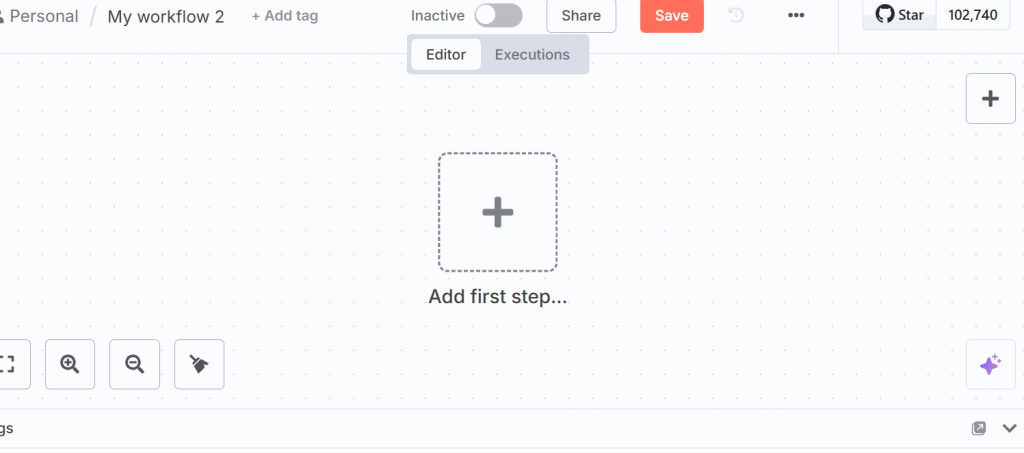
Este nodo le permite activar manualmente todo el flujo de trabajo.
Haga clic en el signo “+” situado a la derecha del nodo de activación manual y busque Bright Data. En la sección “acciones del raspador web”, haga clic en “raspar datos de forma sincrónica por URL”:
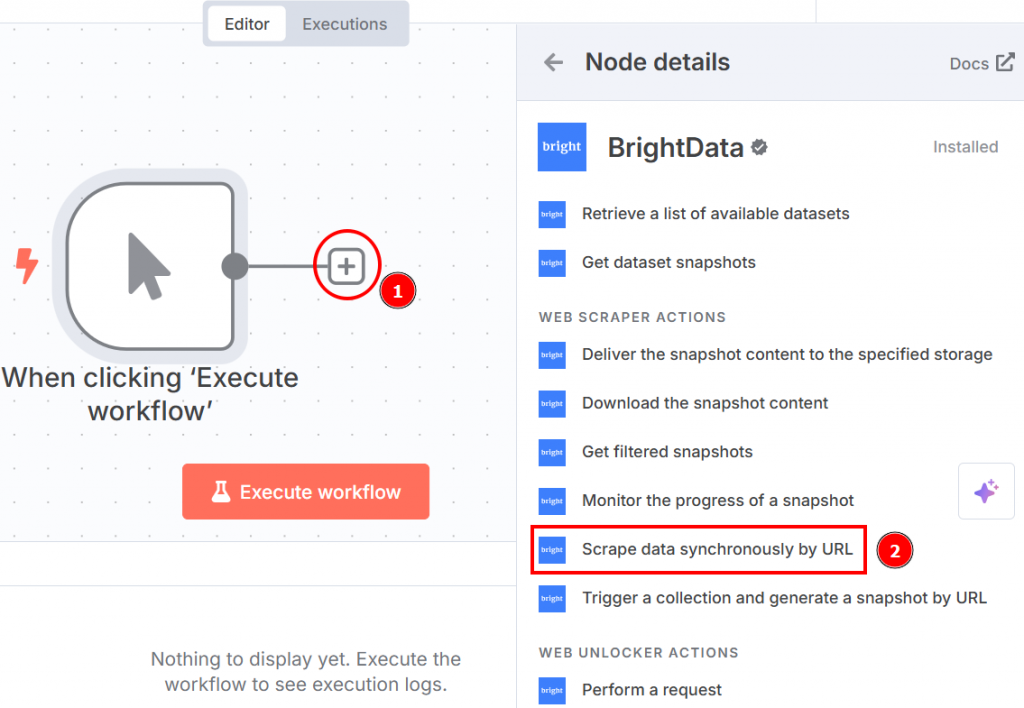
A continuación se muestra cómo aparece la configuración del nodo al hacer clic en él:

Configúralos de la siguiente manera:
- “Credencial para conectarse”: Haga clic en ella y añada su token de API de Bright Data. Las credenciales se guardarán.
- “Operación”: Seleccione la opción “Scrape por URL”. Esto le permite pasar una lista de URL que la API de Web Scraper utilizará como páginas de destino para extraer los datos.
- “Conjunto de datos”: Elija la opción “Productos más vendidos de Amazon”. Eso está optimizado para extraer los datos de los productos más vendidos de Amazon.
- “URLs”: Ve a la página de productos de oficina más vendidos de Amazon para copiar y pegar una lista de al menos 10 URLs. Necesitas al menos 10 URLs porque el nodo OpenAI Chat necesita al menos 10. Si pasas menos de 10, el nodo OpenAI devolverá un error mientras afina el LLM de destino.
- “Formato”: Selecciona el formato de datos “JSON”, ya que Web Scraper API admite varios formatos de salida.
A continuación se muestra cómo se ve su flujo de trabajo hasta ahora:

Si pulsa el botón “Ejecutar flujo de trabajo”, los datos raspados estarán disponibles dentro del nodo de Bright Data en la sección de salida:
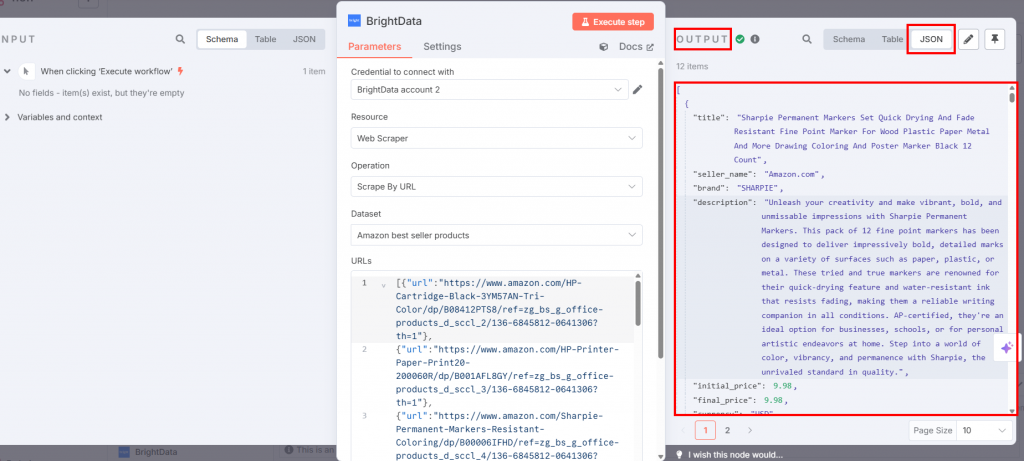
¡Fantástico! Ha obtenido los datos específicos que necesitaba con la API Web Scraper de Bright Data sin siquiera escribir una línea de código.
Paso 3: Configurar el nodo de código
Conecte el nodo Code del nodo Bright Data y seleccione JavaScript en la casilla “Idioma”:

En el campo “JavaScript”, pegue el siguiente código:
// get all incoming items
const allInputItems = $input.all();
let jsonlString = "";
// define the training prompt
const systemMessage = "You are an expert marketing assistant specializing in writing compelling and informative product descriptions.";
// loop through each item retrieved from the input
for (const item of allInputItems) {
const product = item.json;
// validate if the product data exists and is an object
if (!product || typeof product !== 'object') {
console.warn('Skipping an item because product data is missing or not an object:', item);
continue;
}
// extract product data
const title = product.title || "N/A";
const brand = product.brand || "N/A";
let featuresString = "Not specified";
if (product.features && Array.isArray(product.features) && product.features.length > 0) {
featuresString = product.features.slice(0, 5).join(', ');
}
// create a snippet of the original product description for training
const originalDescSnippet = (product.description || "No original description available.").substring(0, 250) + "...";
// create prompt with specific details about the product
const userPrompt = `Generate a product description for the following item. Title: ${title}. Brand: ${brand}. Key Features: ${featuresString}. Original Description Snippet: ${originalDescSnippet}.`;
// create template for the kind of description the AI should generate
let idealDescription = `Discover the ${title} from ${brand}, a top-choice for discerning customers. `;
idealDescription += `Key highlights include: ${featuresString}. `;
if (product.rating) {
idealDescription += `Boasting an impressive customer rating of ${product.rating} out of 5 stars! `;
}
idealDescription += `This product, originally described as "${originalDescSnippet}", is perfect for anyone seeking quality and reliability. `;
idealDescription += `Don't miss out on the ${product.availability === "In Stock" ? "readily available" : "upcoming"} ${title} – enhance your collection today!`;
// create a training example object in the format expected by OpenAI
const trainingExample = {
messages: [
{ role: "system", content: systemMessage },
{ role: "user", content: userPrompt },
{ role: "assistant", content: idealDescription }
]
};
jsonlString += JSON.stringify(trainingExample) + "n";
}
// remove any leading or trailing whitespace
const fileContentString = jsonlString.trim();
// check if any product data was actually processed
if (fileContentString.length === 0) {
console.warn("No product data was processed, outputting empty file content.");
return [{
json: { error: "No products processed", fileNameToUse: "data.jsonl" },
binary: {}
}];
}
// convert the final JSONL string into a Buffer (raw binary data)
const buffer = Buffer.from(fileContentString, 'utf-8');
// define the filename that will be used when this data is sent to OpenAI
const actualFileNameForOpenAI = "data.jsonl";
// define the MIME type for the file
const mimeType = 'application/jsonl';
// prepare the binary data for output
const binaryData = await this.helpers.prepareBinaryData(buffer, actualFileNameForOpenAI, mimeType);
// return the processed data
return [{
json: {
processedFileName: actualFileNameForOpenAI
},
binary: {
// the "Input Data Field Name" in the OpenAI node
"data.jsonl": binaryData
}
}];La entrada de este nodo es el archivo JSON que contiene los datos raspados de Bright Data. Sin embargo, el nodo OpenAI necesita un archivo JSONL. Este código JavaScript transforma el JSON en un JSONL de la siguiente manera:
- Recupera todos los datos procedentes del nodo anterior con el método
$input.all(). - Itera y procesa los productos. En concreto, para cada elemento de producto, itera:
- Extrae detalles del producto como
título,marca,características,descripción,valoraciónydisponibilidad. Incluye valores de reserva si faltan determinados datos. - Construye un
userPromptformateando estos detalles en una petición para que el LLM genere la descripción del producto. - Genera una
idealDescriptionutilizando una plantilla que incorpora los atributos del producto. Esto sirve como la respuesta deseada del “asistente” en los datos de entrenamiento. - Combina un mensaje del sistema,
la userPrompty laidealDescriptionen un único objetotrainingExample, formateado para la formación LLM conversacional. - Serializa este
trainingExampleen una cadena JSON y la añade a una cadena creciente, con cada objeto JSON en una nueva línea (formato JSONL).
- Extrae detalles del producto como
- Después de procesar todos los elementos, convierte la cadena JSONL acumulada en un
Bufferde datos binarios. - Devuelve el archivo llamado
data.jsonl.
Si hace clic en “Ejecutar paso” en el nodo Código, el JSONL estará disponible en la sección de salida:
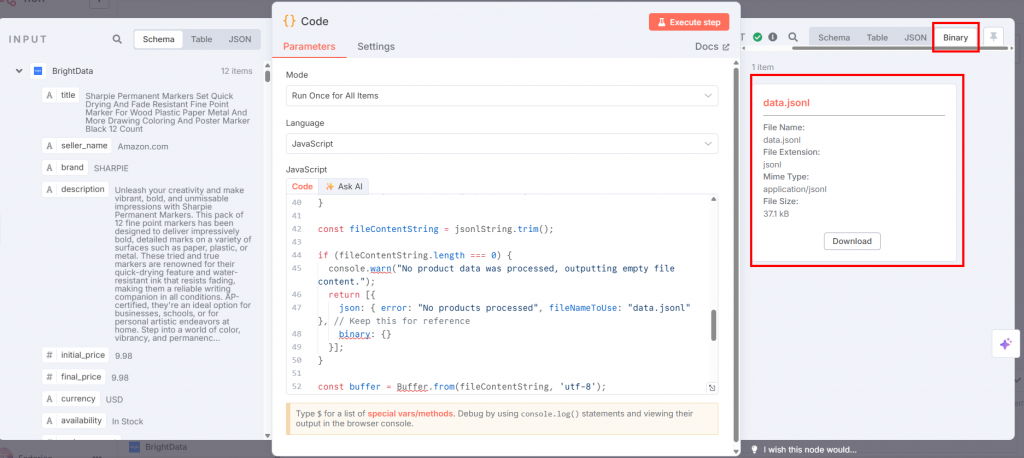
A continuación se muestra cómo se ve su flujo de trabajo hasta ahora:
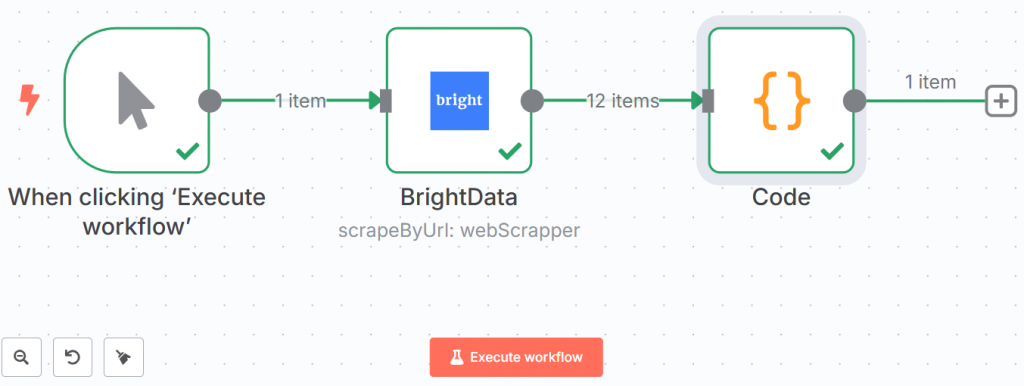
Las líneas verdes y las marcas demuestran que cada paso se ha completado con éxito.
¡Hurra! Ha recuperado los datos utilizando Bright Data y los ha guardado en formato JSONL. Ahora está listo para introducirlos en el LLM.
Paso 4: Introducir los datos de ajuste en el nodo de chat de OpenAI
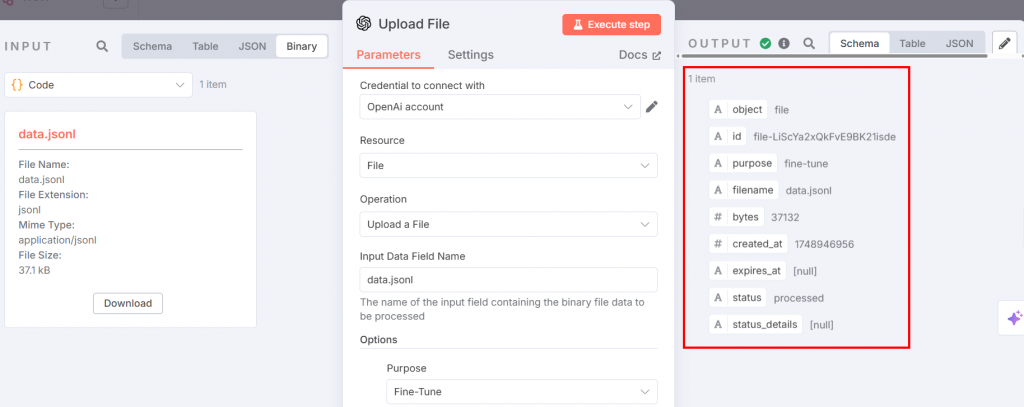
El archivo JSONL de ajuste fino está listo para ser subido a la plataforma OpenAI para el ajuste fino. Para ello, añada un nodo OpenAI. Elija la opción “Cargar un archivo” en la sección “Acciones de archivo”:

A continuación se indican los ajustes que debe configurar:

El nodo anterior proporciona la entrada para el proceso de ajuste fino. Ajuste los parámetros de la siguiente manera:
- “Credencial para conectarse”: Añade tu token de la API de OpenAI. Una vez que lo configures, se guardarán las credenciales.
- “Recurso”: Elija “Archivo”. Esto se debe a que subirá un archivo JSONL a la plataforma.
- “Operación”: Seleccione “Cargar un archivo”.
- “Nombre del campo de datos de entrada”: El nombre del archivo de ajuste fino es
data.jsonl. - En la sección “Opciones”, añade “Propósito” y elige “Afinar”.
Después de ejecutar el paso, la salida tendrá el siguiente aspecto:
Ahora, tu flujo de trabajo tendrá este aspecto:
¡Increíble! Lo has preparado todo para el proceso de puesta a punto. Es hora de pasar por el proceso real.
Paso 5: Afinar el LLM
Para realizar el ajuste fino real, conecta un nodo HTTP Request al de OpenAI:

Los ajustes deben ser los siguientes:
- El “Método” debe ser “POST”, ya que está cargando el archivo de datos de entrenamiento.
- El campo “URL” debe ser
https://api.openai.com/v1/fine_tuning/jobsendpoint. Esta es la URL estándar para trabajos de ajuste fino en la plataforma OpenAI. - En el campo “Autenticación”, elige “Tipo de credencial predefinido” para que utilice tu token de la API de OpenAI.
- Para el “Tipo de credencial”, seleccione “OpenAi” para que el nodo se conecte a OpenAI.
- En la casilla “OpenAI”, elige el nombre de tu cuenta OpenAI.
- El conmutador “Enviar cuerpo” debe estar activado. Seleccione “JSON” y “Usar JSON” respectivamente para los campos “Tipo de contenido del cuerpo” y “Especificar cuerpo”.
El campo JSON debe contener lo siguiente:
{
"training_file": "{{ $json.id }}",
"model": "gpt-4o-mini-2024-07-18"
} Este JSON:
- Especifica el nombre de los datos de entrenamiento con
$json.id. - Define el modelo que se utilizará para el ajuste fino. En este caso, se utilizará GPT-4o-mini según la versión publicada el 2024-07-18.
A continuación se muestra la salida que recibirá:
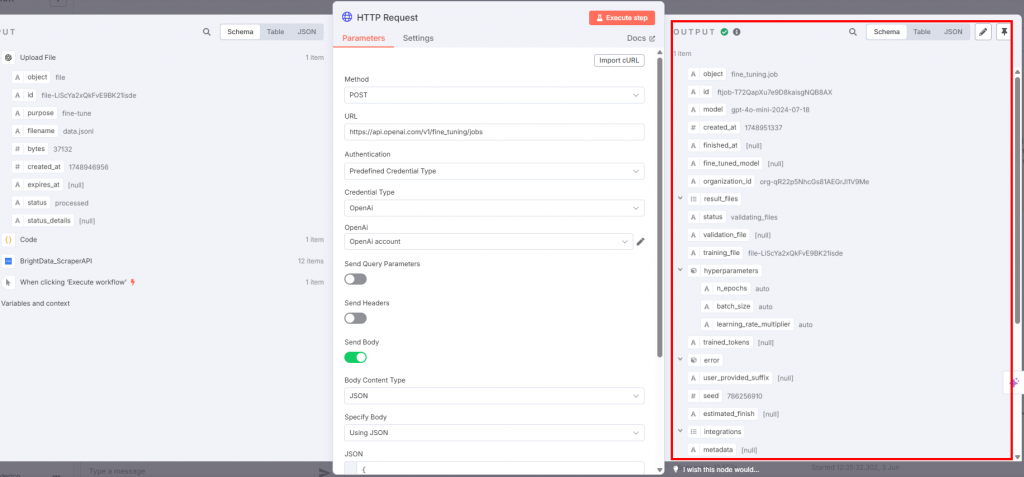
Cuando se activa el nodo HTTP Request, comienza el proceso de ajuste fino. Puedes ver sus avances en la sección de ajuste fino de la plataforma OpenAI. Cuando el proceso de ajuste fino se completa con éxito, OpenAI te proporciona el modelo ajustado que utilizarás en el Paso #7:

El flujo de trabajo del n8n debería tener ahora el siguiente aspecto:

¡Enhorabuena! Ha entrenado su primer modelo GPT utilizando datos recuperados con la API Scraper de Bright Data a través de n8n.
Este es el nodo final de la primera mitad de todo el flujo de trabajo.
Paso #6: Añadir el Nodo Chat
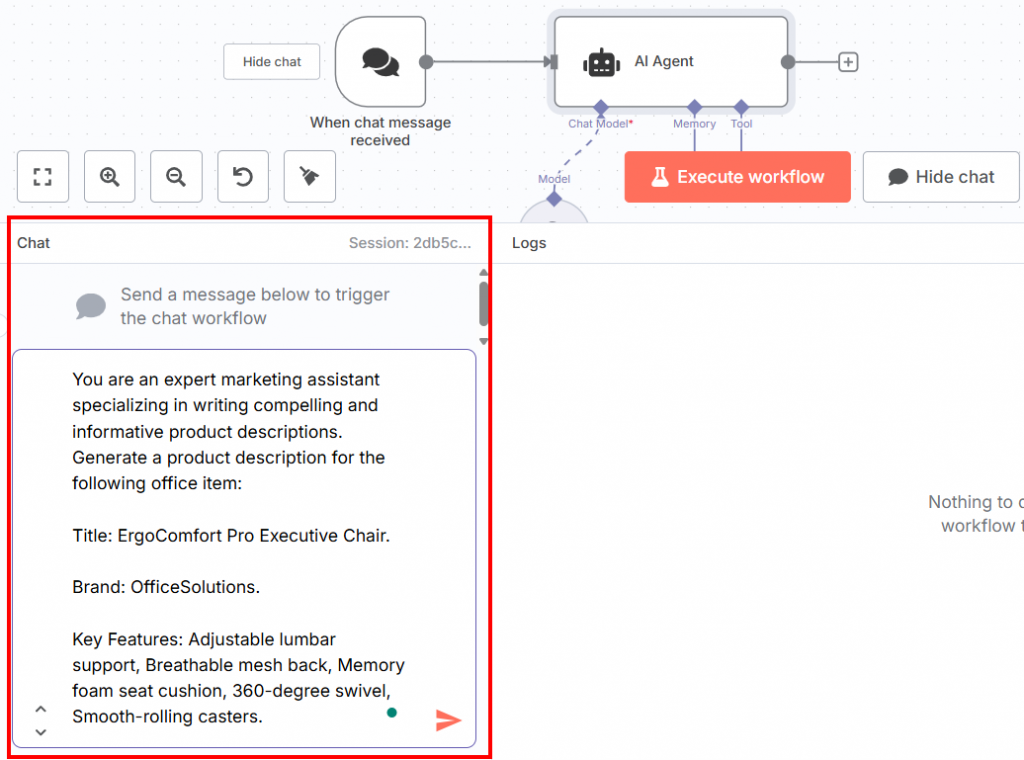
La segunda mitad de todo el flujo de trabajo debe comenzar con un nodo Chat Trigger. En él se insertará el aviso para probar el LLM ajustado:

A continuación se muestra el mensaje que puede insertar en el chat:
You are an expert marketing assistant specializing in writing compelling and informative product descriptions. Generate a product description for the following office item:
Title: ErgoComfort Pro Executive Chair.
Brand: OfficeSolutions.
Key Features: Adjustable lumbar support, Breathable mesh back, Memory foam seat cushion, 360-degree swivel, Smooth-rolling casters.Como puede ver, este aviso:
- Informa de la misma frase sobre cómo ser un asistente de marketing experto utilizada en la fase de formación.
- Pide que se genere una descripción del producto dada la información sobre el artículo de oficina necesario definida por:
- El título.
- La marca.
- Principales características del producto de oficina.
Es importante que la estructura de la indicación sea así. Esto se debe a que el modelo, en esta fase, imita los datos de entrenamiento. Por lo tanto, hay que darle una instrucción y unos datos similares a los que se utilizaron en la fase de entrenamiento. Entonces, el LLM afinado escribirá la descripción del producto basándose en esos factores.
Puede insertar el aviso en la sección de chat de la parte inferior de la interfaz de usuario:
Este es su flujo de trabajo actual n8n:
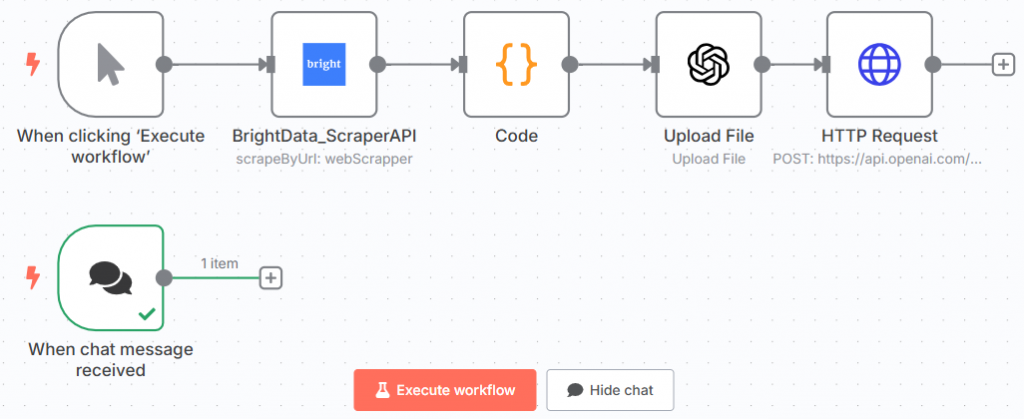
¡Fantástico! Has definido el indicador para probar el modelo afinado.
Paso 7: Añadir el agente de IA y los nodos de chat de OpenAI
Ahora tienes que conectar un nodo de Agente AI a Chat Trigger:

Los ajustes deben ser:
- “Agente”: Elija “Agente conversacional”. Esto te permite modificar lo que quieras usando el nodo “Chat Trigger”, como haces con cualquier otro agente conversacional.
- Establezca el “Origen de la solicitud (mensaje de usuario)” como “Nodo desencadenante de chat conectado” para que pueda ingerir la solicitud directamente desde el chat.
Conecta un nodo OpenAI Chat Model al del Agente AI a través de su opción de conexión “Chat Model”:

La siguiente imagen muestra la configuración del nodo OpenAI Chat Model:

Configure el nodo como se indica a continuación:
- “Credenciales para conectarse”: Selecciona tus credenciales de OpenAI guardadas.
- “Modelo”: Pega el modelo de salida de ajuste fino de la sección de ajuste fino de la plataforma OpenAI.
Vuelva al nodo del Agente AI y haga clic en el botón “Ejecutar paso”. Verá la descripción resultante del producto:
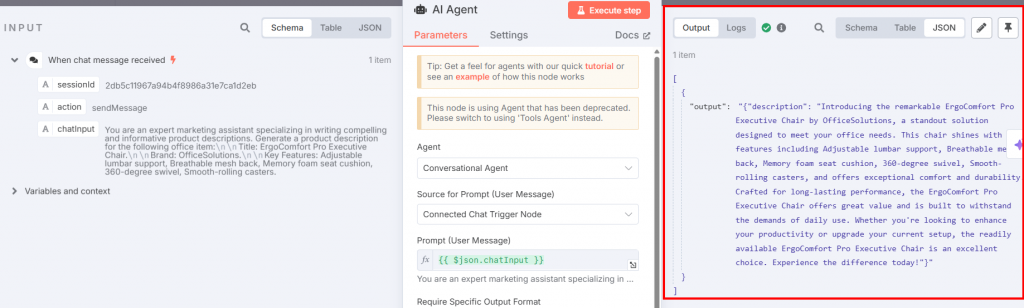
A continuación se muestra la descripción resultante en texto sin formato:
Introducing the remarkable ErgoComfort Pro Executive Chair by OfficeSolutions, a standout solution designed to meet your office needs. This chair shines with key features including Adjustable lumbar support, Breathable mesh back, Memory foam seat cushion, 360-degree swivel, Smooth-rolling casters, and offers exceptional comfort and durability. Crafted for long-lasting performance, the ErgoComfort Pro Executive Chair offers great value and is built to withstand the demands of daily use. Whether you're looking to enhance your productivity or upgrade your current setup, the readily available ErgoComfort Pro Executive Chair is an excellent choice. Experience the difference today!Como puede ver, la descripción aprovecha el nombre del título del objeto (“Silla ejecutiva ErgoComfort Pro”), su marca (“OfficeSolutions”) y todas sus características para generar la descripción del producto. En concreto, la descripción no se limita a enumerar los datos de entrada, sino que los aprovecha para crear una descripción atractiva. Las últimas frases son la clave:
- “Fabricada para un rendimiento duradero, la Silla Ejecutiva ErgoComfort Pro ofrece un gran valor y está construida para soportar las exigencias del uso diario.”
- “Si busca mejorar su productividad o actualizar su configuración actual, la Silla Ejecutiva ErgoComfort Pro es una excelente elección. Experimente la diferencia hoy mismo”.
¡Et voilà! Ha probado su modelo GPT-4o-mini, que ha generado una descripción del producto para responder a la pregunta dada (definida en el paso 6).
Paso 8: Póngalo todo junto
El flujo de trabajo final de la puesta a punto del GTP-4o n8n tiene ahora el siguiente aspecto:

Ahora que el flujo de trabajo está completamente configurado, si hace clic en “Ejecutar flujo de trabajo”, se ejecutará de nuevo desde el principio. Sin embargo, tenga en cuenta que los resultados se guardan en cada paso. Esto significa que si quiere probar diferentes avisos para probar el modelo ajustado, sólo tiene que escribirlos en el nodo Chat Trigger y ejecutar ese nodo y el nodo AI agent.
Comparación de enfoques de ajuste: Infraestructura en nube frente a automatización del flujo de trabajo
Esta guía se ha elaborado por dos motivos:
- Enseñarle a ajustar un LLM utilizando una herramienta de automatización del flujo de trabajo como n8n
- Comparando esta forma de afinar los LLM con la utilizada en nuestro artículo “Afinar Llama 4 con datos web frescos para obtener mejores resultados“
Es hora de comparar los dos enfoques.
Comparación de los métodos de ajuste fino
El enfoque que seguimos en nuestro artículo anterior para poner a punto Llama 4 requiere:
- El uso de una infraestructura en la nube, que lleva tiempo configurar e incurre en costes.
- Escribir código para recuperar los datos utilizando las API de raspado de Bright Data.
- Preparando Cara de Abrazo.
- La necesidad de desarrollar un cuaderno con el código Python para la puesta a punto, lo que requiere tiempo y conocimientos técnicos.
No se pueden calcular las capacidades técnicas necesarias. Sin embargo, sí se puede calcular el tiempo necesario para montar toda la infraestructura y el dinero gastado:
- Tiempo: aproximadamente una jornada laboral completa.
- Dinero: 25 dólares. Después de gastar $25 por el servicio en la nube, el consumo será por hora. Al mismo tiempo, es necesario pagar 25 dólares antes de empezar. Por lo tanto, ese es el precio mínimo para utilizar la nube.
El enfoque que ha aprendido en esta guía requiere:
- n8n, que es de uso gratuito y no requiere grandes conocimientos técnicos.
- Un token de la API OpenAI para acceder a GPT-4o u otros modelos.
- Conocimientos básicos de codificación, en concreto para escribir un fragmento de JavaScript para el nodo Código.
En este caso, las habilidades técnicas son mucho menores. El fragmento de código JavaScript puede ser creado fácilmente por cualquier LLM, si usted no puede escribirlo por su cuenta. Aparte de eso, no es necesario escribir ningún otro fragmento de código en todo el flujo de trabajo.
En este caso, puedes estimar el tiempo necesario para montar la infraestructura y el dinero necesario de la siguiente manera:
- Duración: aproximadamente media jornada laboral.
- Dinero: 10 $ por un token de API de OpenAI. Incluso en este caso, pagarás por cada solicitud de API. Aún así, puedes empezar con sólo 10 dólares. Una licencia de n8n cuesta actualmente 25 $/mes para el plan básico, o completamente gratis si eliges usar la versión autoalojada. Así que, para empezar, necesitas unos 10 dólares.
¿Qué enfoque elegir?
| Aspecto | Enfoque de infraestructura en nube | Automatización del flujo de trabajo |
|---|---|---|
| Competencias técnicas | Alta (requiere conocimientos de Python, la nube y codificación de recuperación de datos) | Bajo (JavaScript básico) |
| Tiempo de preparación | Aproximadamente una jornada laboral completa | Alrededor de media jornada laboral |
| Coste inicial | ~25$ mínimo por servicio en la nube + honorarios por hora | ~$10 por el token de la API OpenAI + $24/mes por la licencia n8n o autoalojamiento gratuito |
| Flexibilidad | Alta (adecuada para personalización avanzada y diversos casos de uso) | Moderado (bueno para automatizar flujos de trabajo y personalización de bajo código) |
| Lo mejor para | Equipos con altos conocimientos técnicos que necesitan una infraestructura potente y flexible | Equipos que buscan una configuración rápida o con conocimientos limitados de codificación |
| Ventajas adicionales | Control total del entorno y el proceso de ajuste | Plantillas prediseñadas, baja barrera de entrada, integración con otros flujos de trabajo |
Los dos enfoques requieren una inversión inicial similar, tanto de tiempo como de dinero. Entonces, ¿cómo elegir entre uno y otro? He aquí algunas pautas:
- n8n: Elija n8n -o cualquier herramienta similar de automatización de flujos de trabajo- para ajustar los LLM si necesita automatizar otros flujos de trabajo y si su equipo no tiene grandes conocimientos técnicos. Este enfoque de bajo código le ayudará a automatizar cualquier otro flujo de trabajo. Requiere escribir código sólo si necesita personalización. También proporciona plantillas preconstruidas que puede utilizar de forma gratuita, lo que reduce la barrera de entrada al uso de la herramienta.
- Servicios en la nube: Elige un servicio en la nube para afinar los LLM si lo necesitas para múltiples propósitos y cuentas con un equipo altamente cualificado. La configuración del entorno en la nube y el desarrollo del cuaderno de ajuste requieren conocimientos técnicos avanzados.
El corazón del proceso de ajuste: Datos de alta calidad
Independientemente del enfoque que elija, Bright Data sigue siendo el intermediario clave en ambos. La razón es sencilla: ¡los datos de alta calidad son la base del proceso de ajuste!
Bright Data le cubre con una infraestructura de IA para datos, ofreciendo una gama de servicios y soluciones para apoyar sus aplicaciones de IA:
- Servidor MCP: Un servidor MCP Node.js de código abierto que expone más de 20 herramientas para la recuperación de datos en agentes de IA.
- APIs de Web Scraper: API preconfiguradas para extraer datos estructurados de más de 100 dominios importantes.
- Desbloqueador Web: Una API todo en uno que maneja el desbloqueo de sitios en sitios con protecciones anti-bot.
- API SERP: Una API especializada que desbloquea los resultados de los motores de búsqueda y extrae datos completos de las SERP.
- Modelos básicos: Acceda a conjuntos de datos compatibles a escala web para potenciar el preentrenamiento, la evaluación y el ajuste de LLM.
- Proveedores de datos: Conéctese con proveedores de confianza para obtener conjuntos de datos de alta calidad preparados para la IA a escala.
- Paquetes de datos: Obtenga conjuntos de datos curados y listos para usar: estructurados, enriquecidos y anotados.
Aunque esta guía le ha enseñado a ajustar GPT-4o-mini raspando los datos mediante las API de Web Scraper, puede optar por un enfoque diferente utilizando uno de nuestros servicios.
Conclusión
En este artículo, ha aprendido a ajustar GPT-4o-mini con datos extraídos de Amazon utilizando n8n para automatizar todo el flujo de trabajo. Usted ha pasado por todo el proceso, que consta de dos ramas:
- Realiza el ajuste fino después de raspar los datos.
- Prueba el modelo ajustado insertando el aviso a través de un disparador de chat.
También has pasado por la comparación de este enfoque, que utiliza una herramienta de automatización del flujo de trabajo, con respecto a otro que utiliza un servicio en la nube.
Independientemente del enfoque que mejor se adapte a sus necesidades y a su equipo, recuerde que los datos de alta calidad siguen siendo el núcleo del proceso. En este sentido, Bright Data le ofrece varios servicios de datos para IA.
Cree una cuenta gratuita en Bright Data y pruebe nuestra infraestructura de datos preparada para la IA.





