

En este tutorial aprenderás
- Cómo podría funcionar un asistente de búsqueda de empleo de LinkedIn potenciado por IA.
- Cómo construirlo integrando los datos de empleo de LinkedIn de Bright Data con un flujo de trabajo potenciado por OpenAI.
- Cómo mejorar y ampliar este flujo de trabajo para convertirlo en un asistente de búsqueda de empleo robusto.
Puedes ver los archivos finales del proyecto aquí.
¡Vamos a sumergirnos!
Explicación del flujo de trabajo del asistente de IA para la búsqueda de empleo de LinkedIn
En primer lugar, no se puede crear un asistente de IA para la búsqueda de empleo en LinkedIn sin tener acceso a los datos de las ofertas de empleo de LinkedIn. Aquí es donde Bright Data entra en juego.
Gracias a LinkedIn Jobs Scraper, puedes recuperar datos de ofertas de empleo públicas de LinkedIn a través de web scraping. La experiencia que se obtiene es idéntica a la de buscar en el portal de empleo de LinkedIn. Pero en lugar de una página web, recibirás los datos estructurados de las ofertas de empleo directamente en formato JSON o CSV.
A partir de esos datos, puedes pedirle a una IA que puntúe cada empleo en función de tus habilidades y del puesto que buscas. A grandes rasgos, eso es lo que hace por ti el Asistente de IA para empleos de LinkedIn.
Pasos técnicos
Los pasos necesarios para implementar el flujo de trabajo de LinkedIn job AI son:
- Cargar los argumentos CLI: Analiza los argumentos de la línea de comandos para obtener los parámetros de ejecución. Esto permite una ejecución flexible y una fácil personalización sin cambiar el código.
- Cargar las variables de entorno: Cargar las claves de API de OpenAI y Bright Data desde las variables de entorno. Son necesarias para conectarse a las integraciones de terceros que impulsan este flujo de trabajo de IA.
- Cargar el archivo de configuración: Lea un archivo de configuración JSON que contenga los parámetros de búsqueda de empleo, los detalles del perfil del candidato y la descripción del empleo deseado. Esa información de configuración guía la recuperación de empleos y la puntuación de la IA.
- Extraer los empleos de LinkedIn: Obtén ofertas de empleo filtradas según la configuración de la API de LinkedIn Jobs Scraper.
- Puntúa las ofertas mediante IA: Envía cada lote de ofertas a OpenAI. La IA los puntúa de
0a100en función de tu perfil y del puesto deseado. También añade un breve comentario explicando cada puntuación para ayudarte a entender la calidad de la coincidencia. - Amplía los empleos con puntuaciones y comentarios de la IA: ****Merge las puntuaciones y comentarios generados por la IA en las ofertas de empleo originales, enriqueciendo cada registro de empleo con estos nuevos campos generados por la IA.
- Exporte los datos de las ofertas puntuadas: Exporte los datos de las ofertas enriquecidas a un archivo CSV para su posterior análisis y procesamiento.
- Imprima lasofertas más votadas: Muestra las mejores coincidencias directamente en la consola con los detalles principales, proporcionando una visión inmediata de las oportunidades más relevantes.
Vea cómo implementar este flujo de trabajo de IA en Python.
Cómo utilizar OpenAI y Bright Data para crear un flujo de trabajo de IA para la búsqueda de empleo en LinkedIn
En este tutorial, aprenderás a crear un flujo de trabajo de IA para ayudarte a encontrar trabajo en LinkedIn. Los datos de empleo de LinkedIn provendrán de Bright Data, mientras que las capacidades de IA serán proporcionadas por OpenAI. Ten en cuenta que también puedes utilizar cualquier otro LLM.
Al final de esta sección, tendrás un flujo de trabajo completo de IA en Python que podrás ejecutar desde la línea de comandos. Identificará los mejores puestos de trabajo de LinkedIn, ahorrándote tiempo y esfuerzo en la agotadora y agotadora tarea de la búsqueda de empleo.
¡Vamos a construir un asistente de IA para la búsqueda de empleo en LinkedIn!
Requisitos previos
Para seguir este tutorial, asegúrate de tener lo siguiente:
- Python 3.8 o superior instalado localmente (recomendamos utilizar la última versión).
- Una clave API de Bright Data.
- Una clave API de OpenAI.
Si aún no dispone de una clave API de Bright Data, cree una cuenta de Bright Data y siga la guía oficial de configuración. Del mismo modo, siga las instrucciones oficiales de OpenAI para obtener su clave de API de OpenAI.
Paso #0: Configurar su Proyecto Python
Abre un terminal y crea un nuevo directorio para tu asistente de IA para la búsqueda de empleo en LinkedIn:
mkdir linkedin-job-hunting-ai-assistant/La carpeta linkedin-job-hunting-ai-assistant contendrá todo el código Python para tu flujo de trabajo de IA.
A continuación, navega hasta el directorio del proyecto e inicializa un entorno virtual dentro de él:
cd linkedin-job-hunting-ai-assistant/
python -m venv venvAhora, abre el proyecto en tu IDE de Python favorito.. Recomendamos Visual Studio Code con la extensión Python o PyCharm Community Edition.
Dentro de la carpeta del proyecto, crea un nuevo archivo llamado assistant.py. Tu estructura de directorios debería ser la siguiente
linkedin-job-hunting-ai-assistant/
├── venv/
└── assistant.pyActiva el entorno virtual en tu terminal. En Linux o macOS, ejecute:
source venv/bin/activateDe forma equivalente, en Windows, ejecuta este comando:
venv/Scripts/activateEn los siguientes pasos, se le guiará a través de la instalación de los paquetes de Python necesarios. Si prefieres instalarlos todos ahora, en el entorno virtual activado, ejecuta
pip install python-dotenv requests openai pydanticEn concreto, las librerías necesarias son:
python-dotenv: Carga variables de entorno desde un archivo.env, facilitando la gestión de claves API de forma segura.pydantic: Ayuda a validar y parsear el archivo de configuración en objetos Python estructurados.requests: Gestiona peticiones HTTP para llamar a APIs como Bright Data y recuperar datos.openai: Proporciona el cliente OpenAI para interactuar con los modelos de lenguaje de OpenAI para la puntuación de trabajos de IA.
Nota: Estamos instalando la biblioteca openai aquí porque este tutorial se basa en OpenAI como proveedor de modelos de lenguaje. Si planeas utilizar un proveedor de LLM diferente, asegúrate de instalar el SDK o las dependencias correspondientes.
¡Ya está todo listo! Su entorno de desarrollo Python ya está listo para construir un flujo de trabajo de IA utilizando OpenAI y Bright Data.
Paso 1: Cargar los argumentos CLI
El script de IA para la búsqueda de empleo en LinkedIn requiere algunos argumentos. Para mantenerlo reutilizable y personalizable sin cambiar el código, debes leerlos a través de la CLI.
En detalle, necesitarás los siguientes argumentos CLI:
--config_file: La ruta al archivo de configuración JSON que contiene los parámetros de búsqueda de empleo, los detalles del perfil del candidato y la descripción del empleo deseado. Por defecto esconfig.json.--batch_size: El número de trabajos que se enviarán a la IA para su puntuación cada vez. El valor predeterminado es5.--jobs_number: El número máximo de entradas de trabajos que debe devolver Bright Data LinkedIn Jobs Scraper. El valor predeterminado es20.--output_csv: nombre del archivo CSV de salida que contiene los datos de empleo enriquecidos con puntuaciones y comentarios de la IA. El valor predeterminado esjobs_scored.csv.
Lea estos argumentos desde la interfaz de línea de comandos mediante la siguiente función:
def parse_cli_args():
# Analiza los argumentos de la línea de comandos para las opciones de configuración y tiempo de ejecución
parser = argparse.ArgumentParser(description="LinkedIn Job Hunting Assistant")
parser.add_argument("--config_file", type=str, default="config.json", help="Ruta al archivo JSON de configuración")
parser.add_argument("--jobs_number", type=int, default=20, help="Limitar el número de trabajos devueltos por la API de Bright Data Scraper")
parser.add_argument("--batch_size", type=int, default=5, help="Número de trabajos a puntuar en cada lote")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="Nombre del archivo CSV de salida")
return parser.parse_args()No olvides importar argparse de la biblioteca estándar de Python:
import argparse¡Genial! Ahora tienes acceso a los argumentos desde la CLI.
Paso #2: Cargar las variables de entorno
Configure su script para leer los secretos de las variables de entorno. Para simplificar la carga de variables de entorno, utilice el paquete python-dotenv. Con tu entorno virtual activado, instálalo ejecutando
pip install python-dotenvA continuación, en tu archivo assistant.py, importa la librería y llama a load_dotenv() para cargar tus variables de entorno:
from dotenv import load_dotenv
cargar_dotenv()Ahora tu asistente puede leer variables de un fichero .env local. Por lo tanto, añade un archivo . env a la raíz del directorio de tu proyecto:
linkedin-job-hunting-ai-assistant/
├── venv/
├── .env # <-----------
└── assistant.pyAbra el archivo .env y añádale las envs OPENAI_API_KEY y BRIGHT_DATA_API_KEY:
OPENAI_API_KEY="<TU_OPENAI_API_KEY>"
BRIGHT_DATA_API_KEY="<SU_BRIGHT_DATA_API_KEY>"Sustituya el marcador de posición <YOUR_OPENAI_API_KEY> por su clave de API OpenAI real. Del mismo modo, sustituya el marcador de posición <YOUR_BRIGHT_DATA_API_KEY> por su clave de API de Bright Data.
A continuación, añada esta función a su script para cargar esas dos variables de entorno:
def load_env_vars():
# Leer las claves de API necesarias del entorno y verificar su presencia
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
if not openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")
si falta:
raise EnvironmentError(
f "Faltan variables de entorno necesarias: {', '.join(missing)}"
"Por favor, configúrelas en su .env o entorno".
)
return openai_api_key, brightdata_api_keyAñade la importación necesaria de la biblioteca estándar de Python:
import os¡Maravilloso! Ahora ha cargado de forma segura los secretos de integración de terceros utilizando variables de entorno.
Paso 3: Cargar el archivo de configuración
Ahora, necesita una forma programática de decirle a su asistente qué trabajos le interesan. Para que sus resultados sean precisos, el asistente también debe conocer su experiencia laboral y el tipo de empleo que busca.
Para evitar la codificación de esta información directamente en el código, tiene sentido leerla de un archivo de configuración JSON. En concreto, este archivo debe contener
Ubicación: La ubicación geográfica en la que desea buscar empleo. Esto define el área principal donde se recopilarán los listados de empleos.palabra clave: palabras o frases específicas relacionadas con el puesto o la función que busca, como “desarrollador de Python”. Utilice comillas para que la búsqueda sea exacta.país: Un código de país de dos letras (por ejemplo,USpara Estados Unidos,FRpara Francia) para limitar la búsqueda de empleo a un país específico.intervalo_de_tiempo: El periodo de tiempo en el que se publicaron las ofertas de empleo, para filtrar las ofertas recientes o relevantes (por ejemplo,la semana pasada,el mes pasado, etc.).job_type: El tipo de empleo por el que filtrar, comoTiempo completo,Tiempo parcial, etc.nivel_experiencia: El nivel requerido de experiencia profesional, comoEntry level,Associate, etc.remoto: Filtra los empleos en función del modo de ubicación del trabajo (por ejemplo,Remoto,PresencialoHíbrido).empresa: Centra la búsqueda en ofertas de empleo de una empresa o empleador específico.búsqueda_selectiva: Cuando está activada, excluye los listados de empleos cuyos títulos no contienen las palabras clave especificadas para producir resultados más específicos.jobs_to_not_include: Una lista de ID de empleos específicos para excluir de los resultados de búsqueda, útil para eliminar duplicados o anuncios no deseados.radio_ubicación: Define hasta qué punto alrededor de la ubicación especificada debe extenderse la búsqueda, incluyendo las áreas cercanas.profile_summary: Resumen de tu perfil profesional. Esta información es utilizada por la IA para evaluar la adecuación de cada empleo a su perfil.resumen_empleo_deseado: breve descripción del tipo de empleo que buscas, que ayuda a la IA a puntuar las ofertas de empleo en función de su adecuación.
Corresponden exactamente a los argumentos requeridos por la API de Bright Data LinkedIn job listings “discover by keyword” (que forma parte de su solución LinkedIn Jobs Scraper):
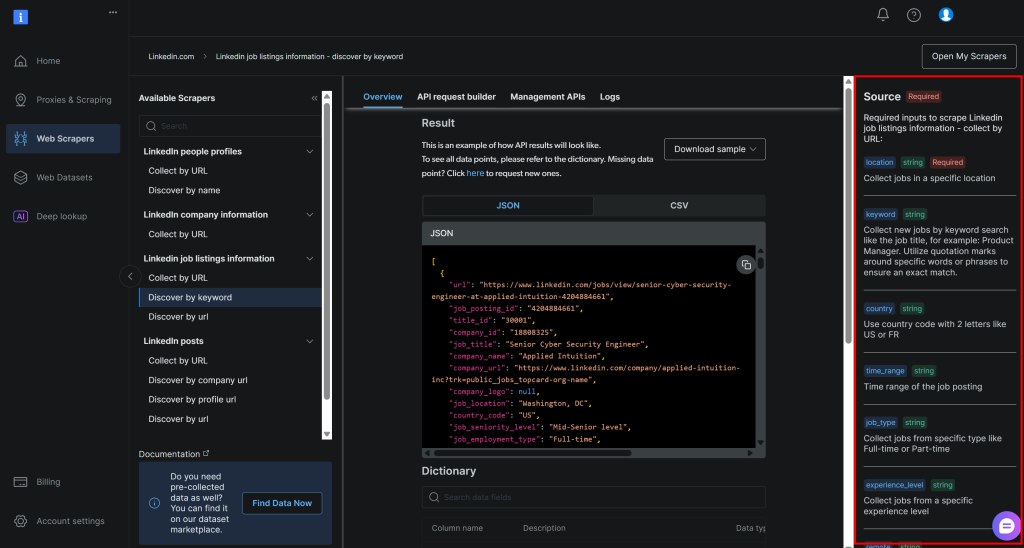
Para obtener más información sobre estos campos y los valores que pueden asumir, consulte la documentación oficial.
Los dos últimos campos(profile_summary y desired_job_summary) describen quién eres profesionalmente y qué estás buscando. Estos campos se pasarán a la IA para puntuar cada oferta de empleo devuelta por Bright Data.
Para facilitar el manejo del archivo de configuración en el código, es una buena idea mapearlo a un modelo Pydantic. En primer lugar, instale Pydantic en su entorno virtual:
pip install pydanticDespués, define el modelo Pydantic mapeando el fichero de configuración JSON como se muestra a continuación:
clase JobSearchConfig(BaseModel):
location: str
palabra clave: Opcional[str] = None
país: Opcional[str] = Ninguno
intervalo_de_tiempo: Opcional[str] = None
tipo_trabajo: Opcional[str] = None
nivel_experiencia: Opcional[str] = None
remoto: Opcional[str] = None
empresa: Opcional[str] = None
selective_search: Opcional[bool] = Campo(por defecto=False)
jobs_to_not_include: Optional[List[str]] = Field(por defecto_factory=list)
location_radius: Opcional[str] = None
# Campos adicionales
profile_summary: str # Resumen del perfil del candidato para la puntuación de IA
desired_job_summary: str # Descripción del trabajo deseado para la puntuación de IAObserve que sólo se requieren los dos primeros y últimos campos de configuración.
A continuación, cree una función para leer las configuraciones JSON de la ruta del archivo --config_file. Deserialízala en una instancia JobSearchConfig:
def cargar_y_validar_config(nombre_archivo: str) -> JobSearchConfig:
# Cargar fichero de configuración JSON
try:
with open(nombre_archivo, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f "Archivo de configuración '{nombredearchivo}' no encontrado.")
try:
# Deserializar los datos JSON de entrada a una instancia JobSearchConfig
config = JobSearchConfig(**datos)
except ValidationError as e:
raise ValueError(f "Config deserialization error:n{e}")
return configEsta vez, necesitarás estas importaciones
from pydantic import BaseModel, Field, ValidationError
from typing import Optional, List
importar json¡Fantástico! Ahora tu fichero de configuración está correctamente leído y deserializado.
Paso 4: Extraer las ofertas de empleo de LinkedIn
Es hora de utilizar la configuración que ha cargado anteriormente para llamar a la API de Bright Data LinkedIn Jobs Scraper.
Si no está familiarizado con el funcionamiento de las API de Web Scraper de Bright Data, le recomendamos que consulte primero la documentación.
En resumen, las API de Web Scraper proporcionan puntos finales de API que le permiten recuperar datos públicos de dominios específicos. Entre bastidores, Bright Data inicializa y ejecuta una tarea de raspado preparada en sus servidores. Estas API gestionan la rotación de IP, CAPTCHA y otras medidas para recopilar datos públicos de páginas web de forma eficaz y ética. Una vez finalizada la tarea, los datos recopilados se analizan en un formato estructurado y se ponen a su disposición en forma de instantánea.
Así pues, el flujo de trabajo general es
- Activar la llamada a la API para iniciar una tarea de web scraping.
- Comprobar periódicamente si la instantánea que contiene los datos raspados está lista.
- Recuperar los datos de la instantánea una vez que estén disponibles.
Puede implementar la lógica anterior con unas pocas líneas de código:
def trigger_and_poll_linkedin_jobs(config: JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Activa la búsqueda de empleo en LinkedIn de Bright Data
url = "https://api.brightdata.com/datasets/v3/trigger"
cabeceras = {
"Authorization": f "Bearer {brightdata_api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l", # Bright Data "Linkedin job listings information - discover by keyword" dataset ID
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": str(jobs_number),
}
# Preparar la carga útil para Bright Data API en función de la configuración del usuario
datos = [{
"location": config.location
"keyword": config.keyword o "",
"country": config.country o "",
"time_range": config.time_range o "",
"job_type": config.job_type o "",
"experience_level": config.experience_level o "",
"remoto": config.remoto o "",
"empresa": config.empresa o "",
"selective_search": config.selective_search,
"jobs_to_not_include": config.jobs_to_not_include o "",
"location_radius": config.location_radius o "",
}]
response = requests.post(url, headers=cabeceras, params=parámetros, json=datos)
if response.status_code != 200:
raise RuntimeError(f "Fallo en la solicitud de activación: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("No snapshot_id returned from Bright Data trigger.")
print(f "¡Búsqueda de empleo en LinkedIn activada! ID de instantánea: {snapshot_id}")
# Sondee el punto final de la instantánea hasta que los datos estén listos o se agote el tiempo de espera
snapshot_url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f "Bearer {brightdata_api_key}"}
print(f "Sondeo de instantánea para ID: {snapshot_id}")
while True
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# Instantánea lista: devuelve los datos JSON de las ofertas de empleo
print("La instantánea está lista")
return snap_resp.json()
elif snap_resp.status_code == 202:
# Instantánea aún no lista: esperar y reintentar
print(f "La instantánea aún no está lista. Reintento en {polling_timeout} segundos...")
time.sleep(polling_timeout)
si no:
raise RuntimeError(f "Error en el sondeo de instantáneas: {snap_resp.status_code} - {snap_resp.text}")Esta función activa LinkedIn Jobs Scraper de Bright Data utilizando los parámetros de búsqueda del archivo de configuración, asegurándose de que sólo obtiene los listados que coinciden con sus criterios. A continuación, sondea hasta que la instantánea de datos está lista y, una vez disponible, devuelve los anuncios de empleo en formato JSON. Tenga en cuenta que la autenticación se gestiona utilizando la clave de la API de Bright Data cargada anteriormente desde sus variables de entorno.
La instantánea recuperada con LinkedIn Jobs Scraper contendrá ofertas de empleo en formato JSON, como se muestra a continuación:
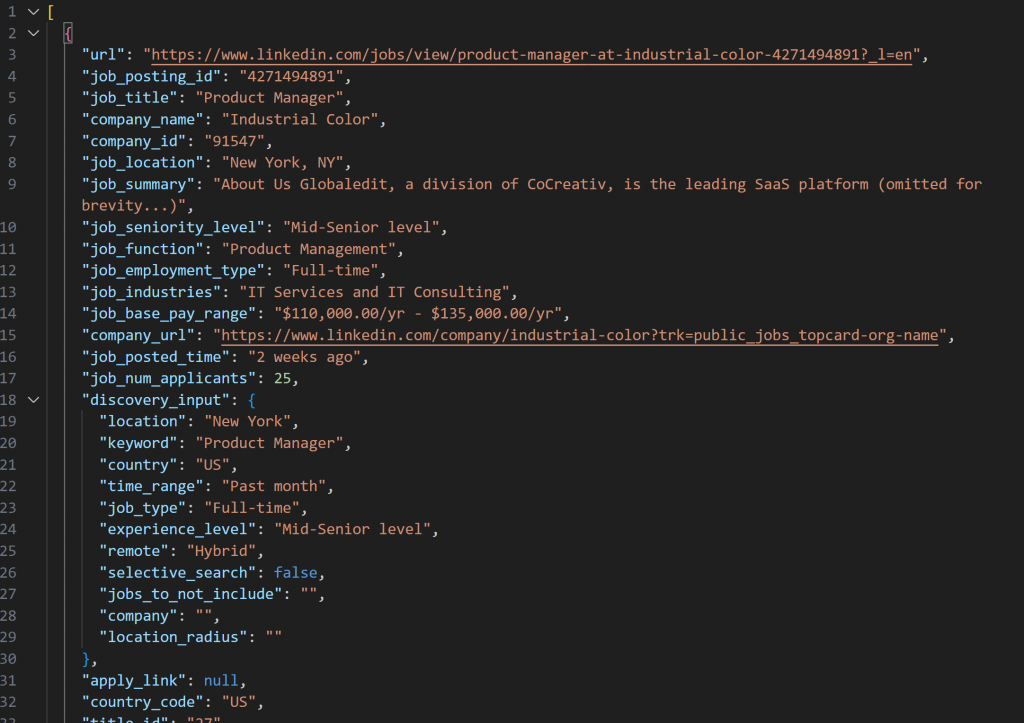
Nota: La instantánea JSON producida contiene exactamente hasta --jobs_number empleos. En este caso, contiene 20 empleos.
Para que la función anterior funcione, necesitas instalar requests:
pip install requestsPara más información sobre cómo funciona, consulta nuestra guía avanzada sobre Python HTTP Requests.
A continuación, no olvides importarla junto con time desde la Librería Estándar de Python:
import requests
importar tiempo¡Estupendo! Acabas de integrarte con Bright Data para recopilar datos frescos y específicos de las ofertas de empleo de LinkedIn.
Paso 5: Puntúa los empleos mediante IA
Ahora, es el momento de pedir a un LLM (como los modelos de OpenAI) que evalúe cada anuncio de empleo raspado.
El objetivo es asignar una puntuación de 0 a 100 junto con un breve comentario, en función de la adecuación del puesto de trabajo:
- Tu experiencia laboral
(profile_summary) - Su puesto deseado
(resumen_empleo_deseado)
Para reducir los viajes de ida y vuelta de la API y acelerar las cosas, tiene sentido procesar los trabajos por lotes. En concreto, evaluará un número --tamaño_lote_de trabajos a la vez.
Comience por instalar el paquete openai:
pip install openaiA continuación, importar OpenAI e inicializar el cliente:
from openai import OpenAI
# ...
# Inicializar el cliente OpenAI
cliente = OpenAI()Ten en cuenta que no necesitas pasar manualmente tu clave API al constructor de OpenAI. La librería la lee automáticamente de la variable de entorno OPENAI_API_KEY, que ya has configurado.
Procede a crear la función de puntuación de trabajos basada en IA:
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# Construye el prompt para que la IA puntúe los empleos coincidentes en base al perfil del candidato
prompt = f"""
"Eres un experto en selección de personal. Dado el siguiente perfil de candidato:n"
"{profile_summary}nn"
"Descripción del puesto de trabajo deseado:n{desired_job_summary}n"
"Puntúe cada oferta de empleo con precisión de 0 a 100 en función de lo bien que se ajuste al perfil y al empleo deseado.n"
"Para cada oferta de empleo, añada un breve comentario (máximo 50 palabras) que explique la puntuación y la calidad de la coincidencia.n"
"Devuelve un array de objetos con las claves 'job_posting_id', 'score', y 'comment'.nn"
"Jobs:n{json.dumps(jobs_batch)}n"
"""
mensajes = [
{"rol": "sistema", "contenido": "Eres un útil asistente de puntuación de trabajos",}
{"rol": "usuario", "contenido": prompt},
]
# Utiliza la API de OpenAI para analizar la respuesta estructurada en el modelo JobScoresResponse
response = client.responses.parse(
model="gpt-5-mini",
input=mensajes,
text_format=Respuesta JobScores,
)
# Devuelve la lista de trabajos puntuados
return response.output_parsed.scoresEsto utiliza el nuevo modelo gpt-5-mini para que OpenAI puntúe cada publicación de trabajo de 0 a 100, junto con un breve comentario explicativo.
Para asegurarse de que la respuesta se devuelve siempre en el formato exacto que necesita, se llama al método parse(). Ese método impone un modelo de salida estructurado, definido aquí con los siguientes modelos Pydantic:
clase JobScore(BaseModel):
job_posting_id: str
puntuación: int = Field(..., ge=0, le=100)
comentario: str
clase JobScoresResponse(BaseModel):
puntuaciones: List[PuntuaciónTrabajo]Básicamente, la IA devolverá datos JSON estructurados como los siguientes:
{
"puntuaciones": [
{
"job_posting_id": "4271494891",
"score": 80,
"comment": "Strong SaaS product fit with end-to-end ownership, APIs, and cross-functional work-aligns with your startup PM and customer-first experience. Role targets 2-4 yrs, so it's slightly junior for your 7 years."
},
// omitido por brevedad...
{
"job_posting_id": "4273328527",
"score": 65,
"comment": "Rol de producto con fuerte énfasis en datos / técnico; las responsabilidades ágiles y multifuncionales se alinean, pero prefiere la experiencia de dominio cuantitativo / técnico (finanzas / modelado estadístico) que puede ser un ajuste más débil."
}
]
}A continuación, el método parse( ) convertirá la respuesta JSON en una instancia JobScoresResponse. A continuación, podrá acceder mediante programación tanto a las puntuaciones como a los comentarios en su código.
Nota: Si prefieres utilizar un proveedor de LLM diferente, asegúrate de ajustar el código anterior para que funcione con el proveedor que hayas elegido.
Ya está. La evaluación de trabajos con IA está completa.
Paso #6: Expandir los Trabajos con Acores AI y Comentarios
Echa un vistazo a la salida JSON sin procesar devuelta por la IA mostrada anteriormente. Puedes ver que cada puntuación de empleo contiene un campo job_posting_id. Corresponde al ID que LinkedIn utiliza para identificar las ofertas de empleo.
Dado que estos ID también aparecen en los datos de instantáneas producidos por Bright Data LinkedIn Jobs Scraper, puede utilizarlos para:
- Encontrar los objetos de publicación de empleo originales a partir de la matriz de empleos raspados.
- Enriquecer ese objeto de publicación de empleo añadiendo la puntuación y el comentario generados por la IA.
Consíguelo con la siguiente función:
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# Dónde almacenar los datos enriquecidos
extended_jobs = []
# Combinar los trabajos originales con las puntuaciones AI y los comentarios
for puntuación_obj in todas_puntuaciones:
matched_job = None
para job en jobs
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
break
si trabajo_comparado:
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = puntuación_obj.comment
extended_jobs.append(trabajo_con_puntuación)
# Ordenar los trabajos extendidos por puntuación de IA (primero la más alta)
extended_jobs.sort(key=lambda j: j["ai_score"], reverse=True)
return trabajos_extendidosComo puedes ver, un par de bucles for son suficientes para abordar la tarea. Antes de devolver los datos enriquecidos, ordene la lista en orden descendente por ai_score. De este modo, los trabajos que mejor coinciden aparecen en la parte superior, por lo que son fáciles de encontrar.
¡Genial! Tu asistente de búsqueda de empleo de LinkedIn ya está casi listo para funcionar.
Paso 7: Exporta los datos de los empleos puntuados
Utiliza el paquete csv integrado de Python para exportar los datos de los empleos extraídos y enriquecidos a un archivo CSV.
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# Obtener dinámicamente los nombres de campo del primer elemento de la matriz
nombres_campo = list(trabajos_extendidos[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# Escribir los datos del trabajo ampliado con las puntuaciones AI en CSV
writer = csv.DictWriter(csvfile, fieldnames=nombresdecampo)
writer.writeheader()
para trabajo en trabajos_extendidos:
writer.writerow(job)
print(f "Exportados {len(trabajos_extendidos)} trabajos a {salida_csv}") Se llamará a la función anterior sustituyendo output_csv por el argumento CLI --output_csv.
No olvide importar csv:
import csv¡Perfecto! El asistente de IA para la búsqueda de empleo de LinkedIn ahora exporta los datos enriquecidos con IA a un archivo CSV de salida.
Paso #8: Imprime los Top Job Matches
Para obtener información inmediata en el terminal sin abrir el archivo CSV de salida, escribe una función para imprimir los detalles clave de las 3 mejores ofertas de empleo:
def print_top_jobs(extended_jobs: List[dict], top: int = 3):
print(f"n*** Top {top} job matches ***")
para trabajo en trabajos_extendidos[:3]:
print(f "URL: {empleo.get('url', 'N/A')}")
print(f "Título: {empleo.get('titulo_empleo', 'N/A')}")
print(f "Puntuación AI: {job.get('ai_score')}")
print(f "Comentario AI: {job.get('ai_comment', 'N/A')}")
print("-" * 40)Paso 9: Juntar todo
Combina todas las funciones de los pasos anteriores en la lógica principal del asistente de búsqueda de empleo de LinkedIn:
# Obtener parámetros de ejecución de la CLI
args = parse_cli_args()
probar:
# Cargar claves API del entorno
_, brightdata_api_key = load_env_vars()
# Cargar archivo de configuración de búsqueda de trabajo
config = load_and_validate_config(args.config_file)
# Obtener trabajos
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f "¡{len(jobs_data)} trabajos encontrados!")
except Exception as e:
print(f"[Error] {e}")
devolver
all_scores = []
# Procesa los trabajos por lotes para evitar sobrecargar la API y manejar grandes conjuntos de datos
for i in range(0, len(datos_trabajos), args.tamaño_lote):
batch = datos_trabajos[i : i + tamaño_lote].
print(f "Calificando lote {i // args.tamaño_lote + 1} con {len(lote)} trabajos...")
puntuaciones = puntuar_trabajos_lote(lote, config.resumen_perfil, config.resumen_trabajos_deseados)
all_scores.extend(puntuaciones)
time.sleep(1) # Para evitar que se activen los límites de velocidad de la API
# Combinar las puntuaciones en los trabajos extraídos
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# Guardar los resultados en CSV
export_extended_jobs(extended_jobs, args.output_csv)
# Imprimir las mejores coincidencias de trabajos con información clave para una revisión rápida
print_top_jobs(trabajos_extendidos)¡Increíble! Sólo queda revisar el código completo del asistente y verificar que funciona como se espera.
Paso #10: Código completo y primera ejecución
Su archivo final assistant.py debería contener:
# pip install python-dotenv requests openai pydantic
import argparse
from dotenv import carga_dotenv
import os
from pydantic import ModeloBase, Campo, ErrorValidación
from typing import Opcional, Lista
import json
import requests
import tiempo
from openai import OpenAI
import csv
# Cargar variables de entorno del archivo .env
load_dotenv()
# Modelos Pydantic que soportan el proyecto
clase JobSearchConfig(BaseModel):
# Fuente: https://docs.brightdata.com/api-reference/web-scraper-api/social-media-apis/linkedin#discover-by-keyword
ubicación: str
palabra clave: Opcional[str] = None
país: Opcional[str] = Ninguno
intervalo_de_tiempo: Opcional[str] = None
tipo_trabajo: Opcional[str] = None
nivel_experiencia: Opcional[str] = None
remoto: Opcional[str] = None
empresa: Opcional[str] = None
selective_search: Opcional[bool] = Campo(por defecto=False)
jobs_to_not_include: Optional[List[str]] = Field(por defecto_factory=list)
location_radius: Opcional[str] = None
# Campos adicionales
profile_summary: str # Resumen del perfil del candidato para la puntuación de IA
desired_job_summary: str # Descripción del empleo deseado para la puntuación de IA
clase JobScore(BaseModel):
job_posting_id: str
puntuación: int = Field(..., ge=0, le=100)
comentario: str
clase JobScoresResponse(BaseModel):
puntuaciones: List[PuntuaciónTrabajo]
def parse_cli_args():
# Analiza los argumentos de la línea de comandos para las opciones de configuración y ejecución
parser = argparse.ArgumentParser(description="LinkedIn Job Hunting Assistant")
parser.add_argument("--config_file", type=str, default="config.json", help="Ruta al archivo JSON de configuración")
parser.add_argument("--jobs_number", type=int, default=20, help="Limitar el número de trabajos devueltos por la API de Bright Data Scraper")
parser.add_argument("--batch_size", type=int, default=5, help="Número de trabajos a puntuar en cada lote")
parser.add_argument("--output_csv", type=str, default="jobs_scored.csv", help="Nombre del archivo CSV de salida")
return parser.parse_args()
def load_env_vars():
# Leer las claves API necesarias del entorno y verificar su presencia
openai_api_key = os.getenv("OPENAI_API_KEY")
brightdata_api_key = os.getenv("BRIGHT_DATA_API_KEY")
missing = []
if not openai_api_key:
missing.append("OPENAI_API_KEY")
if not brightdata_api_key:
missing.append("BRIGHT_DATA_API_KEY")
si falta:
raise EnvironmentError(
f "Faltan variables de entorno necesarias: {', '.join(missing)}"
"Por favor, configúrelas en su .env o entorno".
)
return openai_api_key, brightdata_api_key
def load_and_validate_config(filename: str) -> JobSearchConfig:
# Cargar archivo de configuración JSON
try:
with open(nombrearchivo, "r", encoding="utf-8") as f:
data = json.load(f)
except FileNotFoundError:
raise FileNotFoundError(f "Archivo de configuración '{nombredearchivo}' no encontrado.")
try:
# Deserielizar los datos JSON de entrada a una instancia JobSearchConfig
config = JobSearchConfig(**datos)
except ValidationError as e:
raise ValueError(f "Config deserialization error:n{e}")
return config
def trigger_and_poll_linkedin_jobs(config: JobSearchConfig, brightdata_api_key: str, jobs_number: int, polling_timeout=10):
# Activa la búsqueda de empleo en LinkedIn de Bright Data
url = "https://api.brightdata.com/datasets/v3/trigger"
cabeceras = {
"Authorization": f "Bearer {brightdata_api_key}",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l", # Bright Data "Linkedin job listings information - discover by keyword" dataset ID
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": str(jobs_number),
}
# Preparar la carga útil para Bright Data API en función de la configuración del usuario
datos = [{
"location": config.location
"keyword": config.keyword o "",
"country": config.country o "",
"time_range": config.time_range o "",
"job_type": config.job_type o "",
"experience_level": config.experience_level o "",
"remoto": config.remoto o "",
"empresa": config.empresa o "",
"selective_search": config.selective_search,
"jobs_to_not_include": config.jobs_to_not_include o "",
"location_radius": config.location_radius o "",
}]
response = requests.post(url, headers=cabeceras, params=parámetros, json=datos)
if response.status_code != 200:
raise RuntimeError(f "Fallo en la solicitud de activación: {response.status_code} - {response.text}")
snapshot_id = response.json().get("snapshot_id")
if not snapshot_id:
raise RuntimeError("No snapshot_id returned from Bright Data trigger.")
print(f "¡Búsqueda de empleo en LinkedIn activada! ID de instantánea: {snapshot_id}")
# Sondee el punto final de la instantánea hasta que los datos estén listos o se agote el tiempo de espera
snapshot_url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f "Bearer {brightdata_api_key}"}
print(f "Sondeo de instantánea para ID: {snapshot_id}")
while True
snap_resp = requests.get(snapshot_url, headers=headers)
if snap_resp.status_code == 200:
# Instantánea lista: devuelve los datos JSON de las ofertas de empleo
print("La instantánea está lista")
return snap_resp.json()
elif snap_resp.status_code == 202:
# Instantánea aún no lista: esperar y reintentar
print(f "La instantánea aún no está lista. Reintento en {polling_timeout} segundos...")
time.sleep(polling_timeout)
si no:
raise RuntimeError(f "Falló el sondeo de la instantánea: {snap_resp.status_code} - {snap_resp.text}")
# Inicializar el cliente OpenAI
cliente = OpenAI()
def score_jobs_batch(jobs_batch: List[dict], profile_summary: str, desired_job_summary: str) -> List[JobScore]:
# Construye la solicitud para que la IA puntúe las ofertas de empleo en función del perfil del candidato
prompt = f"""
"Eres un experto en selección de personal. Dado el siguiente perfil de candidato:n"
"{profile_summary}nn"
"Descripción del puesto de trabajo deseado:n{desired_job_summary}n"
"Puntúe cada oferta de empleo con precisión de 0 a 100 en función de lo bien que se ajuste al perfil y al empleo deseado.n"
"Para cada oferta de empleo, añada un breve comentario (máximo 50 palabras) que explique la puntuación y la calidad de la coincidencia.n"
"Devuelve un array de objetos con las claves 'job_posting_id', 'score', y 'comment'.nn"
"Jobs:n{json.dumps(jobs_batch)}n"
"""
mensajes = [
{"rol": "sistema", "contenido": "Eres un útil asistente de puntuación de trabajos",}
{"rol": "usuario", "contenido": prompt},
]
# Utiliza la API de OpenAI para analizar la respuesta estructurada en el modelo JobScoresResponse
response = client.responses.parse(
model="gpt-5-mini",
input=mensajes,
text_format=Respuesta JobScores,
)
# Devuelve la lista de trabajos puntuados
return response.output_parsed.scores
def extend_jobs_with_scores(jobs: List[dict], all_scores: List[JobScore]) -> List[dict]:
# Dónde almacenar los datos enriquecidos
extended_jobs = []
# Combinar los trabajos originales con las puntuaciones AI y los comentarios
for puntuación_obj in todas_puntuaciones:
matched_job = None
para job en jobs
if job.get("job_posting_id") == score_obj.job_posting_id:
matched_job = job
break
si trabajo_comparado:
job_with_score = dict(matched_job)
job_with_score["ai_score"] = score_obj.score
job_with_score["ai_comment"] = puntuación_obj.comment
extended_jobs.append(trabajo_con_puntuación)
# Ordenar los trabajos extendidos por puntuación de IA (primero la más alta)
extended_jobs.sort(key=lambda j: j["puntuación_ai"], reverse=True)
return trabajos_extendidos
def export_extended_jobs(extended_jobs: List[dict], output_csv: str):
# Obtener dinámicamente los nombres de campo del primer elemento de la matriz
nombres_campo = list(trabajos_extendidos[0].keys())
with open(output_csv, mode="w", newline="", encoding="utf-8") as csvfile:
# Escribir los datos del trabajo ampliado con las puntuaciones AI en CSV
writer = csv.DictWriter(csvfile, fieldnames=nombresdecampo)
writer.writeheader()
para trabajo en trabajos_extendidos:
writer.writerow(job)
print(f "Exportados {len(trabajos_extendidos)} trabajos a {salida_csv}")
def print_top_jobs(extended_jobs: Lista[dict], top: int = 3):
print(f"n*** Top {top} job matches ***")
para trabajo en trabajos_extendidos[:3]:
print(f "URL: {empleo.get('url', 'N/A')}")
print(f "Título: {empleo.get('titulo_empleo', 'N/A')}")
print(f "Puntuación AI: {job.get('ai_score')}")
print(f "Comentario AI: {job.get('ai_comment', 'N/A')}")
print("-" * 40)
def main():
# Obtener parámetros de ejecución desde CLI
args = parse_cli_args()
try:
# Cargar claves API del entorno
_, brightdata_api_key = load_env_vars()
# Cargar archivo de configuración de búsqueda de trabajo
config = load_and_validate_config(args.config_file)
# Obtener trabajos
jobs_data = trigger_and_poll_linkedin_jobs(config, brightdata_api_key, args.jobs_number)
print(f "¡{len(jobs_data)} trabajos encontrados!")
except Exception as e:
print(f"[Error] {e}")
devolver
all_scores = []
# Procesar los trabajos por lotes para evitar sobrecargar la API y manejar grandes conjuntos de datos
for i in range(0, len(datos_trabajos), args.tamaño_lote):
batch = datos_trabajos[i : i + tamaño_lote].
print(f "Calificando lote {i // args.tamaño_lote + 1} con {len(lote)} trabajos...")
puntuaciones = puntuar_trabajos_lote(lote, config.resumen_perfil, config.resumen_trabajo_deseado)
all_scores.extend(puntuaciones)
time.sleep(1) # Para evitar que se activen los límites de velocidad de la API
# Combinar las puntuaciones en los trabajos extraídos
extended_jobs = extend_jobs_with_scores(jobs_data, all_scores)
# Guardar los resultados en CSV
export_extended_jobs(extended_jobs, args.output_csv)
# Imprimir las mejores coincidencias de trabajos con información clave para una revisión rápida
print_top_jobs(extended_jobs)
if __name__ == "__main__":
main()Supongamos que eres un jefe de producto con 7 años de experiencia que busca un puesto de trabajo híbrido en Nueva York. Configura tu archivo config.json como sigue:
{
"location": "Nueva York",
"keyword": "Product Manager",
"country": "US",
"time_range": "Past month",
"job_type": "Full-time": "Tiempo completo",
"experience_level": "Mid-Senior level",
"remote": "Hybrid",
"profile_summary": "Product manager con experiencia de 7 años en startups tecnológicas, especializado en metodologías ágiles y liderazgo de equipos interfuncionales",
"desired_job_summary": "Buscando un papel de gerente de producto a tiempo completo centrado en productos SaaS y desarrollo centrado en el cliente".
}A continuación, puedes ejecutar el asistente de búsqueda de empleo de LinkedIn con:
python assistant.pyOpcional: Para una ejecución personalizada, escribe algo como
python assistant.py --config_file=config.json --batch_size=10 --jobs_number=40 --output_csv=results.csvEste comando ejecuta el asistente utilizando el archivo config.json especificado. Procesa trabajos en lotes de 10, recupera hasta 40 listados de trabajos de Bright Data y guarda los resultados enriquecidos con puntuaciones de IA y comentarios en results.csv.
Ahora, si ejecuta el asistente con los argumentos de CLI predeterminados, debería ver algo como esto en el terminal:
Búsqueda de empleo en LinkedIn activada. ID de instantánea: s_me6x0s3qldm9zz0wv
Instantánea de sondeo para ID: s_me6x0s3qldm9zz0wv
La instantánea aún no está lista. Reintentando en 10 segundos...
# Omitido por brevedad...
Instantánea aún no lista. Reintentando en 10 segundos...
Instantánea lista
¡20 trabajos encontrados!
Calificando lote 1 con 5 trabajos...
Calificando lote 2 con 5 trabajos...
Calificando lote 3 con 5 trabajos...
Calificando lote 4 con 5 trabajos...
Exportados 20 trabajos a jobs.csvEntonces, la salida con los 3 mejores trabajos será algo como:
*** Top 3 job matches ***
URL: https://www.linkedin.com/jobs/view/product-manager-growth-at-yext-4267903356?_l=en
Puesto: Director de Producto, Crecimiento
Puntuación AI: 92
Comentario AI: Excelente ajuste: PM de crecimiento centrado en SaaS con objetivos centrados en el cliente, crecimiento impulsado por el producto, experimentación y colaboración interfuncional: coincidencia directa con la experiencia del candidato y el puesto deseado.
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-industrial-color-4271494891?_l=en
Puesto: Director de Producto
Puntuación AI: 90
Comentario AI: Fuerte coincidencia: Producto SaaS, API/integraciones, liderazgo ágil y multidisciplinar. El único desajuste menor es el objetivo de 2-4 años indicado (tú tienes 7), lo que probablemente te hace sobrecualificado pero muy aplicable.
----------------------------------------
URL: https://www.linkedin.com/jobs/view/product-manager-at-resourceful-talent-group-4277945862?_l=en
Puesto: Jefe de Producto
Puntuación AI: 88
Comentario de AI: Un puesto muy similar en SaaS/integraciones con prácticas ágiles e iteración orientada al cliente. La lista del reclutador apunta a 2-4 años, pero tus 7 años de experiencia como PM en startups y tu liderazgo interfuncional encajan bien.
----------------------------------------Abre el archivo jobs_scored.csv generado. En las columnas principales, verás:
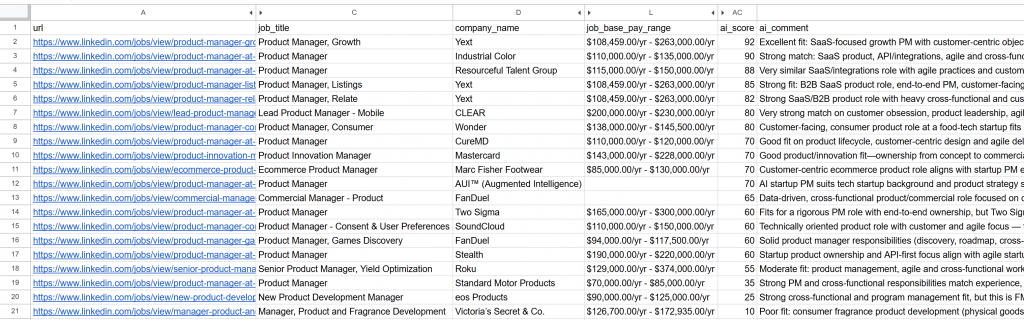
Observa cómo cada trabajo ha sido puntuado y comentado por la IA. Esto te ayudará a centrarte sólo en los puestos en los que tienes posibilidades reales de éxito.
¡Et voilà! Gracias a este flujo de trabajo de búsqueda de empleo en LinkedIn potenciado por la IA, encontrar tu próximo trabajo nunca ha sido tan fácil.
Pasos siguientes
El asistente de búsqueda de empleo de LinkedIn construido aquí funciona como un chat, pero hay algunas mejoras que vale la pena explorar:
- Evita evaluar los mismos empleos repetidamente: Para evaluar diferentes ofertas cada vez que ejecutes el script, establece la matriz
jobs_to_not_includeen tu archivoconfig.json. Debe contener losjob_posting_idsde los trabajos que el asistente ya ha analizado. Por ejemplo, para excluir los trabajos raspados actuales, la configuración podría ser la siguiente:
{
"ubicación": "Nueva York",
"keyword": "Gestor de productos",
"country": "US",
"time_range": "Past month",
"job_type": "Full-time": "Tiempo completo",
"experience_level": "Mid-Senior level",
"remote": "Hybrid",
"jobs_to_not_include": ["4267903356", "4271494891", "4277945862", "4267906118", "4255405781", "4267537560", "4245709356", "4265355147", "4277751182", "4256914967", "4281336197", "4232207277", "4273328527", "4277435772", "4253823512", "4279286518", "4224506933", "4250788498", "4256023955", "4252894407"], // <--- NOTA: Los ID de los empleos que deben excluirse.
"profile_summary": "Product manager con experiencia de 7 años en startups tecnológicas, especializado en metodologías ágiles y liderazgo de equipos interfuncionales",
"desired_job_summary": "Buscando un papel de gerente de producto a tiempo completo centrado en productos SaaS y desarrollo centrado en el cliente".
}- Automatice las ejecuciones periódicas de secuencias de comandos: Programe el script para que se ejecute periódicamente (por ejemplo, a diario) con herramientas como Cron. En este caso, recuerde establecer el argumento
time_rangeadecuado (por ejemplo, “Pasadas 24 horas”) y actualizar la listajobs_to_not_includepara excluir las ofertas que ya haya evaluado. Esto te ayudará a centrarte en las nuevas ofertas. - Utilice un modelo de juez de IA específico: En lugar de un modelo GPT-5 general, considere la posibilidad de utilizar un modelo de IA especializado y perfeccionado para la concordancia y puntuación de empleos. Este sencillo cambio puede mejorar enormemente la precisión y relevancia de las evaluaciones de puestos.
Conclusión
En este artículo, ha aprendido a aprovechar las capacidades de raspado de empleos de LinkedIn de Bright Data para crear un asistente de búsqueda de empleo potenciado por IA.
El flujo de trabajo de IA construido aquí es perfecto para cualquiera que busque un nuevo trabajo y quiera maximizar sus posibilidades centrándose sólo en las mejores oportunidades. Le ayuda a ahorrar tiempo y energía solicitando puestos de trabajo que realmente coinciden con sus objetivos profesionales y tienen una mayor probabilidad de contratación.
Para crear flujos de trabajo más avanzados, explore toda la gama de soluciones para obtener, validar y transformar datos web en tiempo real en la infraestructura de Bright Data AI.
Cree una cuenta gratuita en Bright Data y empiece a experimentar con nuestras herramientas de datos preparadas para la IA.
Preguntas frecuentes
El ejemplo anterior utiliza LinkedIn como fuente de datos, pero puede ampliar fácilmente el script para que funcione con Indeed o cualquier otra fuente de ofertas de empleo disponible a través de Bright Data. Para obtener más información sobre la integración con Indeed, consulte Indeed Jobs Scraper.
Este flujo de trabajo de IA se basa en OpenAI por su amplia adopción y popularidad. Sin embargo, puede adaptar fácilmente el flujo de trabajo para que funcione con otros proveedores de LLM como Gemini, Anthropic, Cohere o cualquier modelo de lenguaje de gran tamaño disponible en la API.
Los datos devueltos por LinkedIn Jobs Scraper son de tan alta calidad y están tan bien estructurados que puede procesarlos para su puntuación utilizando directamente un LLM. Por ello, no necesita necesariamente la complejidad de un agente autónomo con capacidades de razonamiento y toma de decisiones.
Aún así, si desea crear un agente de IA para la búsqueda de empleo en LinkedIn más avanzado, podría considerar la siguiente arquitectura multiagente:
Agente de búsqueda de empleo: Un agente de IA integrado con la infraestructura de Bright Data (a través de herramientas o MCP) que llama a la API de LinkedIn Jobs Scraper para obtener y actualizar continuamente las ofertas de empleo.
Agente de puntuación de empleos: Un agente especializado en evaluar y puntuar empleos en función del perfil y las preferencias del candidato mediante un LLM.
Agente orquestador: Un agente de alto nivel que coordina a los otros dos agentes, desencadenando repetidamente ciclos de recuperación y puntuación de datos hasta obtener el número deseado de ofertas de empleo relevantes y de alta puntuación.
Incluso podrías programar al agente para que se postulara automáticamente a esas ofertas de empleo por ti. Si estás pensando en crear un sistema de búsqueda de empleo en LinkedIn, te recomendamos que utilices una plataforma multiagente como CrewAI.




