
En este tutorial, verá:
- Qué es opencode, qué características ofrece y por qué no debe confundirse con Crush.
- Cómo ampliarlo con capacidades de interacción web y extracción de datos puede hacerlo aún más ingenioso.
- Cómo conectar opencode al servidor MCP de Bright Data en la CLI para crear un potente agente de codificación de IA.
¡Vamos a sumergirnos!
¿Qué es opencode?
opencode es un agente de codificación de IA de código abierto creado para el terminal. En particular, funciona como:
- Una TUI(Terminal User Interface) en tu CLI.
- Una integración IDE en Visual Studio Code, Cursor, etc.
- Una extensión de GitHub.
Más en detalle, opencode te permite:
- Configurar una interfaz de terminal responsiva y tematizable.
- Cargar el LSP(Language Server Protocols) correcto para tu LLM.
- Ejecutar múltiples agentes en paralelo en el mismo proyecto.
- Compartir enlaces a cualquier sesión para referencia o depuración.
- Iniciar sesión con Anthropic para utilizar tu cuenta Claude Pro o Max, así como integrarte con otros más de 75 proveedores de LLM a través de Models.dev (incluyendo modelos locales).
Como puedes ver, la CLI es agnóstica a LLM. Está desarrollada principalmente en Go y TypeScript y ya ha acumulado más de 20k estrellas en GitHub, un testimonio de su popularidad en la comunidad.
Nota: Esta tecnología no debe confundirse con Crush, un proyecto diferente cuyo nombre original era “opencode”. Obtenga más información sobre la disputa por el nombre en X. Si busca Crush en su lugar, consulte nuestra guía sobre la integración de Crush con el MCP Web de Bright Data.
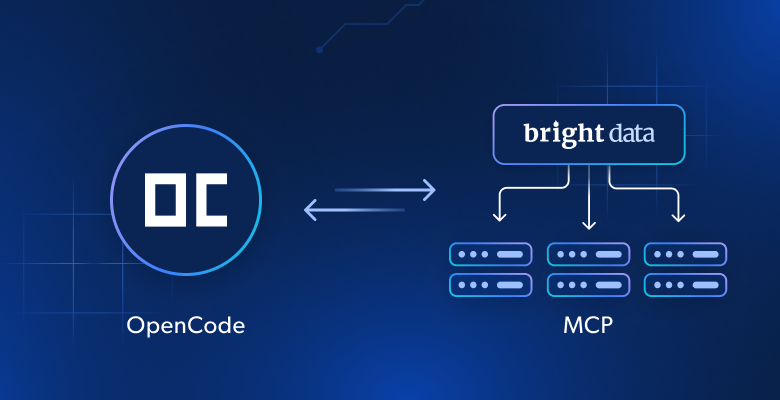
Por qué es importante integrar el MCP Web de Bright Data en la TUI de opencode
No importa qué LLM termine configurando en opencode, todos comparten la misma limitación: su conocimiento es estático. Los datos con los que se formaron representan una instantánea en el tiempo, que rápidamente queda desfasada. Esto es especialmente cierto en campos tan cambiantes como el desarrollo de software.
Ahora, imagina darle a tu asistente de opencode CLI la capacidad de:
- Obtener nuevos tutoriales y documentación.
- Consultar guías en vivo mientras escribe código.
- Navegar por sitios web dinámicos con la misma facilidad con la que navega por sus archivos locales.
Éstas son precisamente las capacidades que desbloquea conectándolo al MCP Web de Bright Data.
El MCP Web de Bright Data proporciona acceso a más de 60 herramientas preparadas para la IA y diseñadas para la interacción web y la recopilación de datos en tiempo real, todas ellas impulsadas por la infraestructura de IA de Bright Data.
Las dos herramientas más utilizadas(incluso disponibles en el nivel gratuito) en el MCP Web de Bright Data son:
| Herramienta | Descripción |
|---|---|
scrape_as_markdown |
Raspe el contenido de una sola página web con opciones de extracción avanzadas, devolviendo los datos resultantes en Markdown. Puede evitar la detección de bots y CAPTCHA. |
search_engine |
Extrae resultados de búsqueda de Google, Bing o Yandex. Devuelve los datos SERP en formato JSON o Markdown. |
Además de estas dos, hay más de 55 herramientas especializadas para interactuar con páginas web (por ejemplo, scraping_browser_click) y recopilar datos estructurados de múltiples dominios, como LinkedIn, Amazon, Yahoo Finance, TikTok y otros. ool recupera información estructurada de perfil de una página pública de LinkedIn cuando se le da la URL de un profesional.
¡Es hora de comprobar cómo funciona Web MCP dentro de opencode!
Cómo conectar opencode al Web MCP de Bright Data
Aprenda cómo instalar y configurar opencode localmente e integrarlo con el servidor Web MCP de Bright Data. El resultado será un agente de codificación extendido con acceso a más de 60 herramientas web. Este agente CLI se utilizará en una tarea de ejemplo para:
- Raspar una página de producto de LinkedIn sobre la marcha para recopilar datos de perfil del mundo real.
- Almacenar los datos localmente en un archivo JSON.
- Crear un script Node.js para cargar y procesar los datos.
Sigue estos pasos
Nota: Esta sección del tutorial se centra en el uso de opencode a través de la CLI. Sin embargo, puedes utilizar una configuración similar para integrarlo directamente en tu IDE, como se menciona en la documentación.
Requisitos previos
Antes de empezar, comprueba que tienes lo siguiente:
- Un entorno macOS o Linux (los usuarios de Windows deben utilizar el WSL).
- Una suscripción a Claude Pro o Max o una cuenta de Anthropic con algunos fondos y una clave API (en este tutorial, usaremos una clave API de Anthropic, pero puedes configurar cualquier otro LLM soportado).
- Node.js instalado localmente (recomendamos la última versión LTS).
- Una cuenta de Bright Data con una clave API preparada.
No se preocupe por la configuración de Bright Data por ahora, ya que se le guiará a través de los siguientes pasos.
A continuación, le ofrecemos algunos conocimientos previos opcionales pero útiles:
- Comprensión general del funcionamiento de MCP.
- Familiaridad con el Web MCP de Bright Data y sus herramientas.
Paso #1: Instalar opencode
Instale opencode en su sistema basado en Unix utilizando el siguiente comando:
curl -fsSL https://opencode.ai/install | bashEsto descargará el instalador de https://opencode.ai/install y lo ejecutará para configurar opencode en su máquina. Explore las otras opciones de instalación posibles.
Verifique que opencode funciona con:
opencodeSi se encuentra con un error de “ejecutable no encontrado” o “comando no reconocido”, reinicie su máquina e inténtelo de nuevo.
Si todo funciona como se espera, debería ver algo como esto:

Ahora opencode está listo para usarse.
Paso #2: Configurar el LLM
opencode puede conectarse a muchos LLMs, pero los modelos recomendados son los de Anthropic. Asegúrate de que tienes una suscripción Claude Max o Pro, o una cuenta de Anthropic con algunos fondos y una clave API.
Los siguientes pasos le mostrarán cómo conectar opencode a su cuenta de Anthropic a través de la clave API, pero cualquier otra integración LLM soportada también funcionará.
Cierra tu ventana de opencode con el comando /exit, y luego inicia la autenticación con un proveedor LLM usando:
opencode auth login Se le pedirá que seleccione un proveedor de modelos de IA:

Elija “Anthropic” pulsando Intro y, a continuación, seleccione la opción “Introducir manualmente la clave API”:

Pegue su clave API de Anthropic y pulse Intro:

La configuración de LLM ha finalizado. Reinicie opencode, ejecute el comando /models y podrá seleccionar un modelo de Anthropic. Por ejemplo, elija “Claude Opus 4.1”:
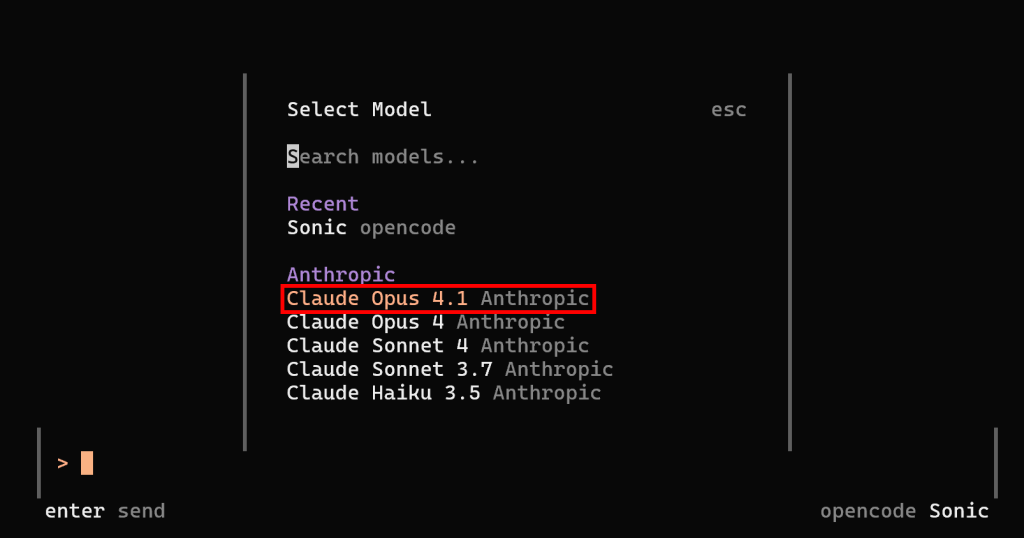
Pulse Intro, y ahora debería ver:

Observe cómo opencode funciona ahora utilizando el modelo antrópico Claude Opus 4.1 configurado. ¡Bien hecho!
Paso #3: Inicialice su proyecto opencode
Vaya al directorio de su proyecto usando el comando cd e inicie opencode allí:
cd <ruta_a_su_carpeta_de_proyecto>
opencodeEjecute el comando /init para inicializar un proyecto opencode. El resultado debería ser similar a éste:

Específicamente, el comando /init creará un archivo AGENTS.md. Similar a CLAUDE.md o a las reglas de Cursor, proporciona instrucciones personalizadas a opencode. Estas instrucciones se incluyen en el contexto del LLM para personalizar su comportamiento para su proyecto específico.
Abre el archivo AGENTS.md en tu IDE (por ejemplo, Visual Studio Code), y deberías verlo:

Personalízalo de acuerdo a tus necesidades para instruir al agente de codificación AI sobre cómo operar dentro del directorio de tu proyecto.
Sugerencia: El archivo AGENTS.md debe confirmarse en el repositorio Git de la carpeta del proyecto.
Paso #4: Probar el MCP Web de Bright Data
Antes de intentar integrar su agente opencode con el servidor Web MCP de Bright Data, es importante entender cómo funciona este servidor y si su máquina puede ejecutarlo.
Si aún no lo ha hecho, empiece por crear una cuenta Bright Data. Si ya tiene una, simplemente inicie sesión. Para una configuración rápida, eche un vistazo a la página “MCP” de su cuenta:

Si no, siga las instrucciones siguientes.
Ahora, genere su clave API de Bright Data. Asegúrese de guardarla en un lugar seguro, ya que la necesitará pronto. En este caso, supondremos que utiliza una clave API con permisos de administrador, ya que facilita la integración.
En la terminal, instala el Web MCP globalmente a través del paquete @brightdata/mcp:
npm install -g @brightdata/mcpComprueba que el servidor MCP local funciona con este comando Bash:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpSustituya el marcador de posición <YOUR_BRIGHT_DATA_API> por el token real de la API de Bright Data. El comando establece la variable de entorno API_TOKEN necesaria y, a continuación, ejecuta el MCP web a través del paquete @brightdata/mcp.
En caso de éxito, debería ver registros similares a este:

En el primer lanzamiento, el paquete configura automáticamente dos zonas predeterminadas en su cuenta de Bright Data:
mcp_unlocker: Una zona para Web Unlocker.mcp_browser: Una zona para Browser API.
Estas dos zonas son necesarias para que el MCP Web active todas las herramientas que expone.
Para confirmar que se han creado las dos zonas anteriores, inicie sesión en su cuenta de Bright Data. En el panel de control, vaya a la página“Proxies & Scraping Infrastructure“. Allí, debería ver las dos zonas en la tabla:

Nota: Si su token de API no tiene permisos de administrador, es posible que estas zonas no se creen automáticamente. En ese caso, puede configurarlas manualmente en el panel de control y especificar sus nombres mediante variables de entorno, como se explica en la página de GitHub del paquete.
Por defecto, el servidor MCP sólo expone las herramientas search_engine y scrape_as_markdown(¡que pueden utilizarse gratuitamente!).
Para desbloquear funciones avanzadas como la automatización del navegador y la recuperación de feeds de datos estructurados, debes activar el modo Pro. Para ello, establezca la variable de entorno PRO_MODE=true antes de iniciar el servidor MCP:
API_TOKEN="<TU_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpImportante: Una vez activado el modo Pro, tendrá acceso a las más de 60 herramientas. Por otro lado, el modo Pro no está incluido en el nivel gratuito y conllevará cargos adicionales.
Perfecto. Acaba de verificar que el servidor Web MCP funciona en su máquina. Detenga el proceso del servidor, ya que ahora configurará opencode para que lo inicie por usted y se conecte a él.
Paso #5: Integrar el Web MCP en opencode
opencode soporta la integración MCP a través de la entradamcp en el archivo de configuración. Tenga en cuenta que hay dos enfoques de configuración soportados:
- Globalmente: A través del archivo en
~/.config/opencode/opencode.json. La configuración global es útil para ajustes como temas, proveedores o combinaciones de teclas. - Por proyecto: A través de un archivo local
opencode.json en el directorio de su proyecto.
Supongamos que desea configurar la integración MCP localmente. Comience por añadir un archivo opencode.j son dentro de su directorio de trabajo.
A continuación, abra el archivo y asegúrese de que contiene las siguientes líneas:
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"brightData": {
"tipo": "local",
"enabled": true
"comando": [
"npx",
"-y",
"@brightdata/mcp"
],
"entorno": {
"API_TOKEN": "<SU_CLAVE_API_BRIGHT_DATA>",
"PRO_MODE": "true"
}
}
}
}Sustituya <YOUR_BRIGHT_DATA_API_KEY> por la clave de API de Bright Data que generó y probó anteriormente.
En esta configuración:
- El objeto
mcpindica a opencode cómo iniciar servidores MCP externos. - La entrada
brightDataespecifica el comando(npx) y las variables de entorno necesarias para iniciar el MCP Web.(PRO_MODEes opcional, pero al activarlo se desbloquea todo el conjunto de herramientas disponibles).
En otras palabras, la configuración opencode.json anterior indica a la CLI que ejecute el mismo comando npx con las variables de entorno definidas anteriormente. Esto le da a opencode la capacidad de iniciar y conectarse al servidor Bright Data Web MCP.
En el momento de escribir esto, no hay ningún comando dedicado para comprobar las conexiones del servidor MCP o herramientas disponibles. Por lo tanto, ¡pasemos directamente a las pruebas!
Paso 6: Ejecute una tarea en opencode
Para comprobar las capacidades web de su agente de codificación opencode mejorado, ejecute un prompt como el siguiente:
Scrapea "https://it.linkedin.com/in/antonello-zanini" y almacena los datos resultantes en un archivo local "profile.json". A continuación, configura un script Node.js básico que lea el archivo JSON y devuelva su contenido.Esto representa un caso de uso del mundo real, ya que recoge datos reales y luego los utiliza en un script Node.js.
Inicia opencode, escribe el prompt, y presiona Enter para ejecutarlo. Deberías ver un comportamiento similar a este:

El GIF se ha acelerado, pero esto es lo que ocurre paso a paso:
- El modelo Claude Opus define un plan.
- El primer paso del plan es recuperar los datos de LinkedIn. Para ello, el LLM selecciona la herramienta MCP adecuada
(web_data_linkedin_person_profile, referenciada comoBrightdata_web_data_linkedin_person_profileen la CLI) con los argumentos correctos extraídos del prompt(https://it.linkedin.com/in/antonello-zanini). - El LLM recopila los datos de destino mediante la herramienta de raspado de LinkedIn y actualiza el plan.
- Los datos se almacenan en un archivo
profile.jsonlocal. - Se crea un script Node.js (llamado
readProfile.js) para leer los datos deprofile.jsone imprimirlos. - Se muestra un resumen de los pasos ejecutados, con instrucciones para ejecutar el script Node.js producido.
En este ejemplo, la salida final producida por la tarea tiene este aspecto:

Al final de la interacción, su directorio de trabajo debe contener estos archivos:
├── AGENTS.md
├── opencode.json
├── profile.json # <-- creado por la CLI
└── readProfile.js # <-- creado por la CLI¡¡¡Maravilloso!!! Comprobemos ahora si los archivos generados contienen los datos y la lógica previstos.
Paso #7: Explorar y probar la salida
Abra el directorio del proyecto en Visual Studio Code y comience inspeccionando el archivo profile.json:

Importante: Los datos de profile. json son datos reales de LinkedIn recopilados por Bright Data LinkedIn Scraper a través de la herramienta MCP dedicada web_data_linkedin_person_profile. No se trata de contenido alucinado o inventado generado por el modelo Claude.
Los datos de LinkedIn se recuperaron correctamente, como puedes comprobar inspeccionando la página pública del perfil de LinkedIn mencionada en el mensaje:

Nota: El scraping de LinkedIn es notoriamente difícil debido a sus sofisticadas protecciones anti-bot. Un LLM normal no puede realizar esta tarea de forma fiable, lo que demuestra lo potente que se ha vuelto su agente de codificación gracias a la integración de Bright Data Web MCP.
A continuación, eche un vistazo al archivo readProfile.js:
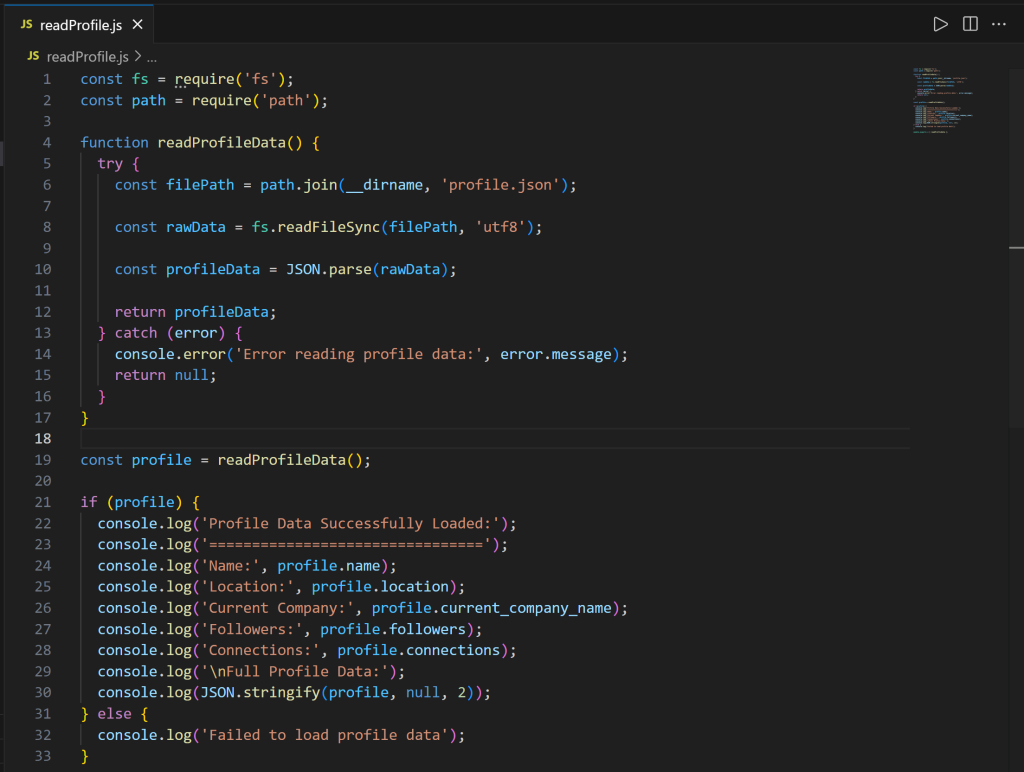
Observe que el código define una función readProfileData() para leer los datos del perfil de LinkedIn desde profile.json. A continuación, se llama a esta función para imprimir los datos del perfil con todos los detalles.
Prueba el script con:
node readProfile.jsLa salida debería ser:

Observa cómo el script producido imprime los datos raspados de LinkedIn según lo previsto.
Misión cumplida. Pruebe diferentes indicaciones y pruebe flujos de trabajo de datos avanzados basados en LLM directamente en la CLI.
Conclusión
En este artículo, ha visto cómo conectar opencode con el Web MCP de Bright Data(¡que ahora ofrece un nivel gratuito!). El resultado es un agente de codificación de IA rico en herramientas capaz de extraer datos de la web e interactuar con ellos.
Para construir agentes de IA más complejos, explore toda la gama de servicios y productos disponibles en la infraestructura de IA de Bright Data. Estas soluciones soportan una amplia variedad de escenarios de agentes, incluyendo varias integraciones CLI.
Regístrese gratis en Bright Data y empiece a experimentar con nuestras herramientas web preparadas para la IA.




