
En esta entrada del blog, verá:
- Qué es Ctush y por qué es una aplicación CLI tan querida para la asistencia de codificación de IA.
- Cómo ampliarlo con la interacción web y la extracción de datos lo hace mucho más eficaz.
- Cómo conectar Crush CLI con el servidor Bright Data Web MCP para crear un agente de codificación de IA mejorado.
¡Vamos a sumergirnos!
¿Qué es Crush?
Crush es un agente de codificación de IA de código abierto para su terminal. En concreto, Crush CLI es una aplicación CLI basada en Go que aporta asistencia de IA directamente a su entorno de terminal. Ofrece una TUI(Terminal User Interface) para interactuar con varios LLMs para ayudar con la codificación, depuración y otras tareas de desarrollo.
En concreto, esto es lo que hace especial a Crush
- Multiplataforma: Funciona en los principales terminales de macOS, Linux, Windows (PowerShell y WSL), FreeBSD, OpenBSD y NetBSD.
- Compatible con varios modelos: Elija entre una amplia gama de LLM, integre los suyos propios a través de API compatibles con OpenAI o Anthropic, o conéctese a modelos locales.
- Experiencia basada en sesiones: Mantenga múltiples sesiones de trabajo y contextos por proyecto.
- Gran flexibilidad: Posibilidad de cambiar entre LLMs a mitad de sesión conservando el contexto.
- Preparado para LSP: Crush soporta LSP(Language Server Protocols) para un contexto e inteligencia adicionales, como un IDE moderno.
- Extensible: Soporta la integración a través de funcionalidades de terceros vía MCPs(HTTP, stdio, y SSE).
El proyecto ya ha alcanzado más de 10k estrellas en GitHub y es mantenido activamente por una vibrante comunidad de desarrolladores, con más de 35 colaboradores.
Superando la Brecha de Conocimiento LLM en Crush CLI con el Web MCP
Un reto común para todos los LLM es tener un límite de conocimientos. El LLM que se configura en Crush CLI no es diferente. Dado que estos modelos se entrenan en un conjunto de datos fijo, su conocimiento es una instantánea estática del pasado. Esto significa que no conocen los acontecimientos o desarrollos recientes.
Este es un inconveniente importante en el vertiginoso mundo de la tecnología. Sin una base de conocimientos actualizada, un LLM podría sugerir bibliotecas obsoletas, prácticas de programación anticuadas o simplemente desconocer nuevas funciones y herramientas.
¿Y si tu asistente de programación Crush AI pudiera hacer algo más que recordar información antigua? Imagina que fuera capaz de buscar en Internet la documentación, los artículos y las guías más recientes, y utilizar esos datos en tiempo real para proporcionar una asistencia mejor y más precisa.
Puede conseguirlo conectando Crush a una solución que proporcione a los LLM el poder del acceso web y la recuperación de datos. Eso es precisamente lo que obtiene con el servidor Web MCP de Bright Data. Este servidor de código abierto(¡ahora con un nivel gratuito!) le equipa con más de 60 herramientas preparadas para la IA para la interacción web y la recopilación de datos.
Integración de Bright Data Web MCP
A continuación se muestran dos de las principales herramientas que puede encontrar en ese servidor MCP:
search_engine: Se conecta a SERP API para realizar búsquedas en Google, Bing o Yandex y devolver los datos de la página de resultados del motor de búsqueda en formato HTML o Markdown.scrape_as_markdown: Utiliza Web Unlocker para scrapear el contenido de una única página web. Soporta opciones avanzadas de extracción, eludiendo sistemas de detección de bots y resolviendo CAPTCHAs por ti.
Además, existen más de 55 herramientas especializadas para interactuar con páginas web (como scraping_browser_click) y recopilar datos estructurados de una gran variedad de dominios, como Amazon, LinkedIn y TikTok. Por ejemplo, la herramienta web_data_amazon_product puede extraer información detallada y estructurada de productos directamente de Amazon utilizando la URL de un producto.
Dadas estas herramientas, he aquí algunas formas de aprovechar Bright Data Web MCP con Crush:
- Recupere información actualizada para sus proyectos, como precios de acciones de Yahoo Finance o detalles de productos de sitios de comercio electrónico. Almacene esos datos en archivos locales para realizar análisis, pruebas, simulaciones, etc.
- Deje que la IA busque la documentación más reciente de una biblioteca o marco de trabajo que esté utilizando, asegurándose de que el código que sugiere está actualizado y no obsoleto.
- Recopile enlaces contextuales e integre esos recursos en archivos Markdown, documentación u otros resultados, todo ello sin salir del editor de código.
Prepárese para ver cómo el Web MCP puede mejorar su agente CLI de Crush.
Cómo conectar Crush al Web MCP de Bright Data
En este tutorial guiado, aprenderá cómo instalar y configurar Crush localmente e integrarlo con el MCP Web de Bright Data. El resultado será un agente de codificación de IA mejorado capaz de:
- Scrapear una página de producto de Amazon sobre la marcha.
- Almacenar los datos en un archivo JSON local.
- Crear un script Node.js para cargar y procesar esos datos.
Sigue las instrucciones a continuación.
Requisitos previos
Antes de empezar, asegúrate de tener lo siguiente:
- Node.js instalado localmente (se recomienda la última versión LTS).
- Una clave API de uno de los proveedores LLM compatibles (en esta guía, utilizaremos Google Gemini).
- Una cuenta de Bright Data con una clave de API preparada (no se preocupe, se le guiará para crear una si aún no la tiene).
Además, los conocimientos previos son opcionales pero útiles:
- Comprensión general del funcionamiento de MCP.
- Cierta familiaridad con el servidor MCP de Bright Data Web y sus herramientas.
- Conocimiento del funcionamiento de los agentes de codificación CLI y cómo pueden interactuar con su sistema de archivos.
Paso #1: Instalar y configurar Crush
Instale Crush CLI globalmente en su sistema a través del paquete npm @charmland/crush:
npm install -g @charmland/crushSi no quieres instalar el CLI vía npm, descubre las otras opciones de instalación.
Ahora puedes lanzar Crush con:
crushLo que deberías ver es la pantalla de selección de LLM de abajo:
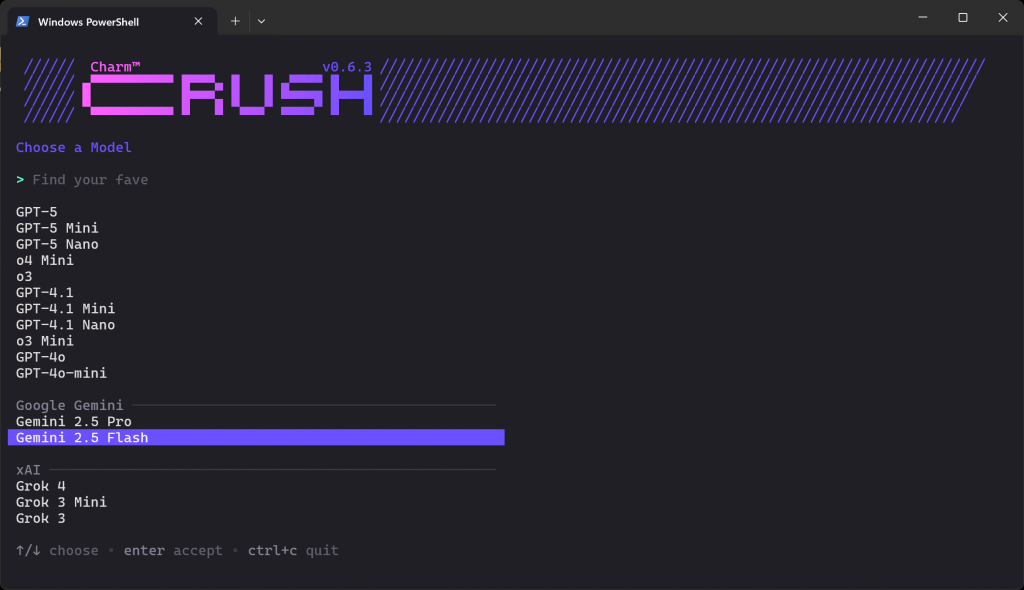
Hay docenas de proveedores y cientos de modelos para elegir. Usa las flechas para navegar hasta que encuentres el modelo que quieres del proveedor donde tienes una clave API. En este ejemplo, seleccionaremos “Gemini 2.5 Flash” (que es esencialmente de uso gratuito a través de API).
A continuación, se le pedirá que introduzca su clave API. Pégala y pulsa Intro:
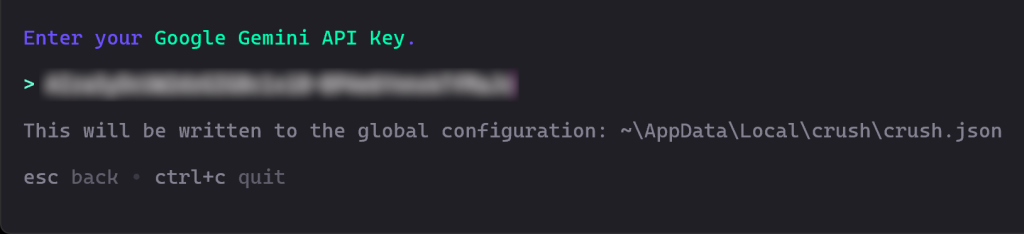
En este caso, pega tu clave API de Google Gemini, que puedes obtener gratuitamente de Google Studio AI.
Crush validará tu clave API para confirmar que funciona.
Una vez completada la validación, deberías ver algo como esto:
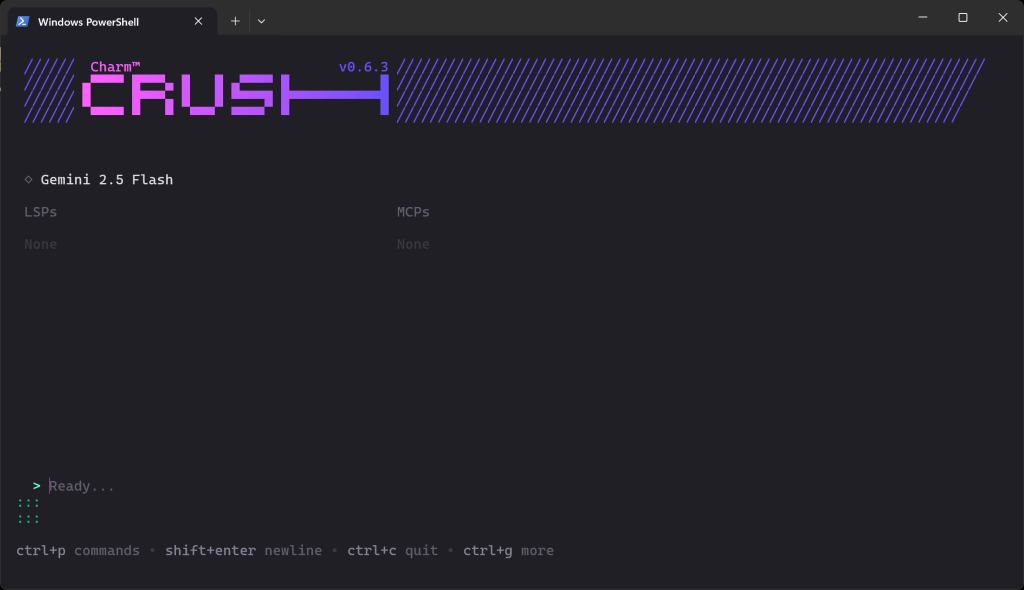
En la sección “Listo…”, ahora puedes escribir tu solicitud.
Nota: Si ejecutas el CLI de Crush de nuevo, no se te pedirá que configures una conexión LLM por segunda vez. Esto es porque tu clave LLM configurada es automáticamente guardada en la configuración global $HOME/.config/crush/crush.json (o en Windows, %USERPROFILE%AppDataLocalcrushcrush.json)
Abra el archivo de configuración global crush.json en Visual Studio Code (o su IDE favorito) para inspeccionarlo:
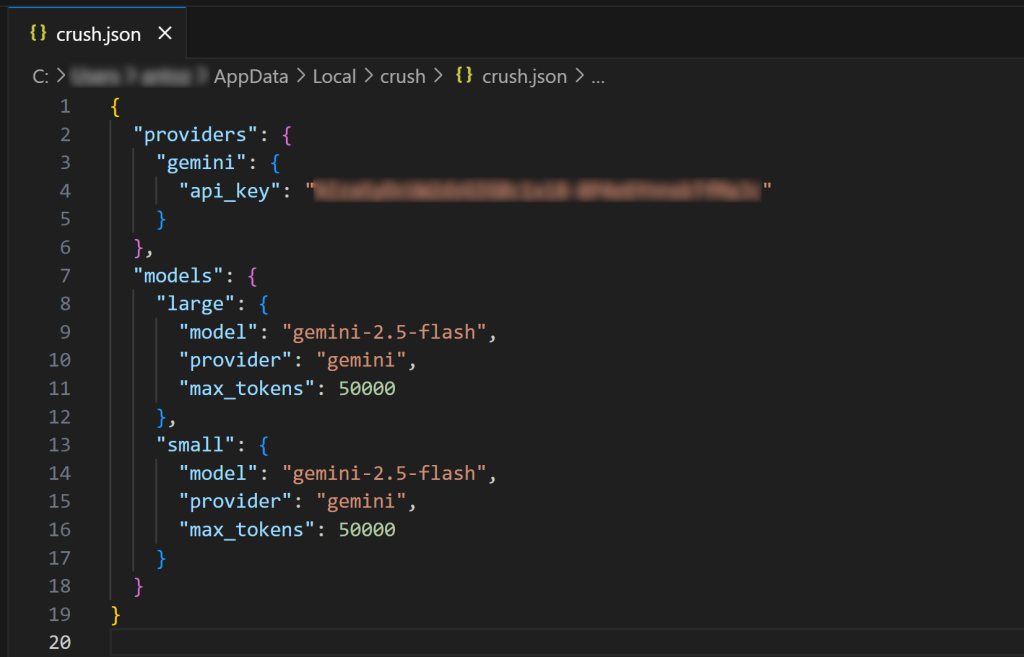
Como puede ver, el archivo crush. json contiene su clave API junto con la configuración para el modelo elegido. Esto fue rellenado por la CLI de Crush cuando seleccionaste un LLM. También puedes editar este archivo para configurar otros modelos de IA(incluso modelos locales).
De forma similar, puedes crear archivos locales crush.json o .crush.json dentro del directorio de tu proyecto para anular la configuración global. Para más detalles, consulta la documentación oficial.
¡Increíble! La CLI de Crush ya está instalada y funcionando en su sistema.
Paso #2: Pruebe el Web MCP de Bright Data
Si aún no tiene una, cree una cuenta Bright Data. De lo contrario, inicie sesión en su cuenta existente.
A continuación, siga las instrucciones oficiales para generar su clave API de Bright Data. Guárdela en un lugar seguro, ya que la necesitará pronto. Para simplificar, supondremos que utiliza una clave API con permisos de administrador.
Instale el Web MCP globalmente utilizando el paquete @brightdata/mcp con:
npm install -g @brightdata/mcpA continuación, verifica que el servidor funciona con este comando Bash:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpO, de forma equivalente, en Windows PowerShell:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpSustituya el marcador de posición <YOUR_BRIGHT_DATA_API> por el token real de la API de Bright Data que generó anteriormente. Los comandos anteriores establecen la variable de entorno API_TOKEN necesaria y activan el servidor MCP a través del paquete npm @brightdata/mcp.
Si todo funciona correctamente, debería ver registros como este:

En el primer lanzamiento, el servidor MCP crea automáticamente dos zonas en su cuenta de Bright Data:
mcp_unlocker: Una zona para Web Unlocker.mcp_browser: Una zona para Browser API.
Estas zonas son necesarias para utilizar todas las herramientas del servidor MCP.
Para confirmar que se han creado, inicie sesión en su panel de Bright Data y vaya a la página “Proxies & Scraping Infrastructure“. Debería ver las dos zonas en la lista:
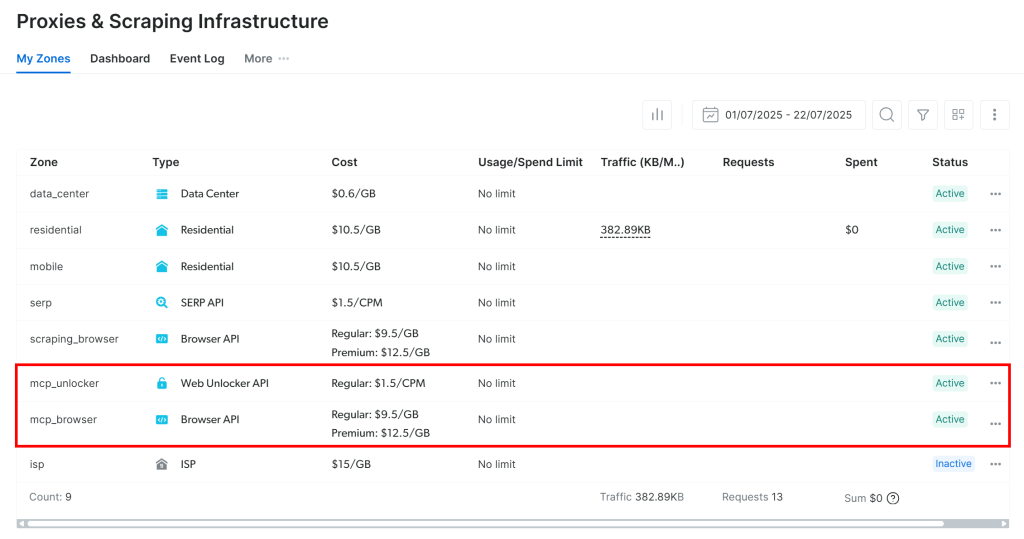
Nota: Si su token de API no tiene permisos de administrador, es posible que estas zonas no se hayan creado para usted. En ese caso, puede configurarlas manualmente y especificar sus nombres utilizando variables de entorno, como se ilustra en la documentación oficial.
Recuerde: Por defecto, el servidor MCP sólo expone las herramientas search_engine y scrape_as_markdown.
Para desbloquear las herramientas avanzadas para la automatización del navegador y los feeds de datos estructurados, es necesario activar el modo Pro. Para ello, establezca la variable de entorno PRO_MODE=true antes de iniciar el servidor MCP:
API_TOKEN="<TU_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpO, en Windows
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpImportante: Con el modo Pro, tendrá acceso a las más de 60 herramientas. Sin embargo, las herramientas adicionales del modo Pro no están incluidas en el nivel gratuito, por lo que incurrirá en gastos.
Descubra más sobre el servidor Web MCP de Bright Data en la documentación oficial.
Perfecto. Ha comprobado que el servidor Web MCP se ejecuta correctamente en su equipo. Detenga el servidor, ya que el siguiente paso será configurar Crush para que lo inicie y se conecte a él al arrancar.
Paso #3: Configurar el Web MCP en Crush
Crush soporta la integración MCP a través de la entrada mcp en el archivo de configuración local o global crush.json.
En este ejemplo, supongamos que desea configurar el MCP Web de Bright Data globalmente en su entorno CLI de Crush. Para ello, abra el archivo de configuración global:
- En Linux/macOS:
$HOME/.config/crush/crush.json. - En Windows:
%USERPROFILE%AppDataLocalcrushcrush.json.
Asegúrese de que contiene lo siguiente
"mcp": {
"brightData": {
"tipo": "stdio",
"command": "npx",
"args": [
"-y",
"@brightdata/mcp"
],
"env": {
"API_TOKEN": "<SU_CLAVE_API_BRIGHT_DATA>",
"PRO_MODE": "true"
}
}
}En esta configuración:
- La entrada
mcple dice a Crush como lanzar servidores MCP externos. - La entrada
brightDatadefine el comando y las variables de entorno necesarias para ejecutar el MCP Web. (Recuerde: EstablecerPRO_MODEes opcional pero recomendado. Además, sustituya<YOUR_BRIGHT_DATA_API_KEY>por su clave API de Bright Data).
En otras palabras, esta configuración añade un servidor MCP personalizado llamado brightData. Crush utiliza las variables de entorno que estableció en el archivo e inicia el servidor a través del comando npx especificado (que corresponde al comando mostrado en el paso anterior). En términos más simples, Crush ahora puede iniciar un proceso MCP Web local y conectarse a él al inicio.
¡Fantástico! Es hora de probar la integración MCP dentro del CLI de Crush.
Paso #4: Verificar la conexión MCP
Cierre todas las instancias de Crush en ejecución y láncelo de nuevo:
crush Si la conexión MCP funciona como se espera, debería ver la entrada brightData listada en la sección “MCPs”:
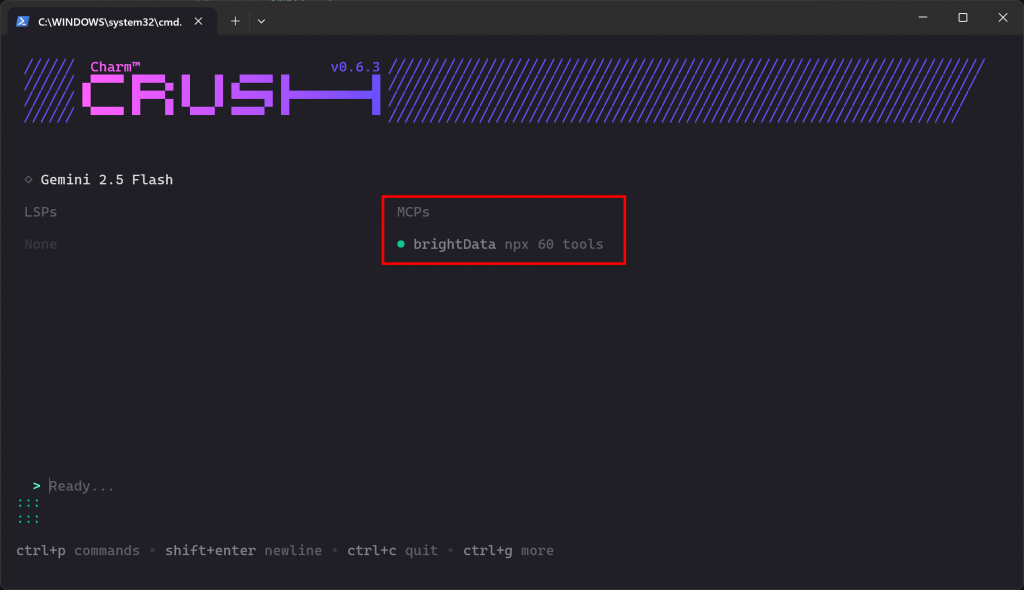
La CLI indica que hay 60 herramientas disponibles. Esto se debe a que lo hemos configurado para que se ejecute en modo Pro. De lo contrario, sólo tendría acceso a 2 herramientas(scrape_as_markdown y search_engine). Bien hecho.
Paso #5: Ejecutar una tarea en Crush
Para verificar las nuevas capacidades en tu configuración de Crush CLI, intenta ejecutar un prompt como este:
Scrapea datos de "https://www.amazon.com/Microfiber-Cleaning-Cloth-Performance-Washes/dp/B08BRJHJF9/", guárdalos en un archivo local "product.json", y define un script Node.js "script.js" para cargar el archivo e imprimir su contenido en la terminal.Este es un gran caso de prueba porque pide la recuperación de datos de productos frescos, lo que debería lograrse utilizando las herramientas expuestas por el Web MCP de Bright Data. Además, demuestra un flujo de trabajo realista que podría utilizar al simular o configurar un proyecto de análisis de datos.
Pegue el mensaje en Crush y pulse Intro para ejecutarlo. Debería ver algo como esto:
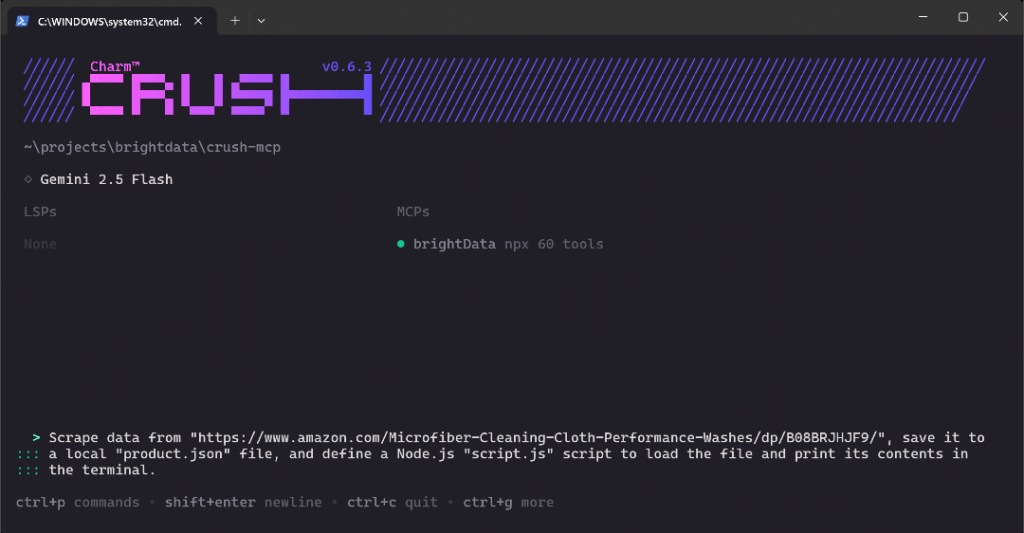
El GIF anterior se ha acelerado, pero esto es lo que sucede paso a paso:
- Crush identifica la herramienta
web_data_amazon_product(referenciada comomcp_brightData_web_data_amazon_productpor la CLI) como la correcta para la tarea y le pide permiso para ejecutarla. - Una vez aprobada, la tarea de scraping se ejecuta a través de la integración MCP.
- Los datos de producto JSON resultantes se muestran en el terminal.
- Crush pregunta si puede guardar estos datos en un archivo local llamado
product.json. - Tras la aprobación, se crea el archivo y se rellena con los datos raspados.
- A continuación, Crush CLI genera la lógica JavaScript para
script.js, que carga e imprime el contenido JSON. - Una vez aprobado, se crea el archivo
script.js. - Se le pedirá permiso para ejecutar el script Node.js.
- Una vez concedido el permiso, se ejecuta
script.js y se imprimen los datos del producto en el terminal.
Observe que la CLI solicitó ejecutar el script Node.js producido, aunque usted no lo solicitó explícitamente. Este comportamiento fue intencional, ya que hace que las pruebas (y por lo tanto la fijación en caso de errores) más fácil y añade valor al flujo de trabajo.
Al final, tu directorio de trabajo debería contener estos dos archivos:
├── prodcut.json
└── script.jsAbre product. json en VS Code, y deberías ver:
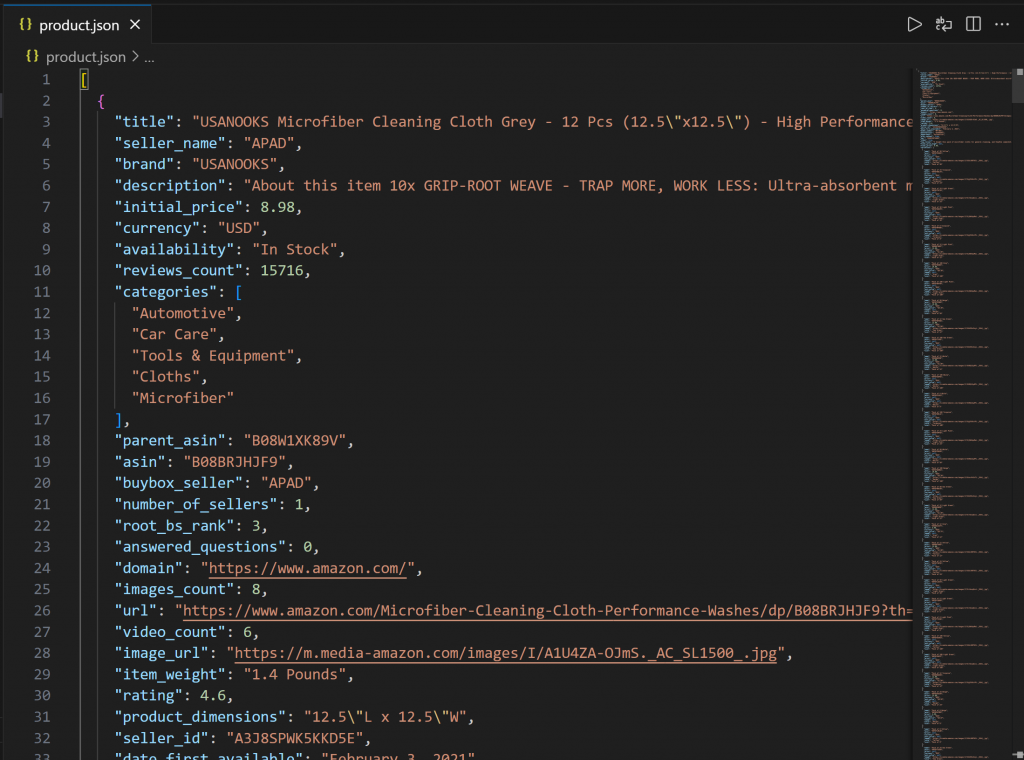
Este archivo contiene datos de productos reales raspados de Amazon a través de Web MCP de Bright Data.
Ahora, abra script.js:
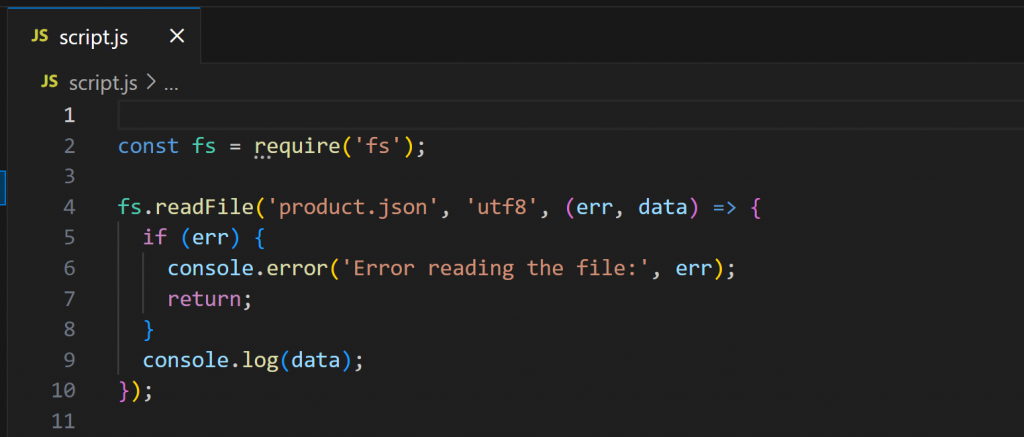
Este script utiliza Node.js para cargar y mostrar el contenido de product.json. Ejecútelo con
node script.jsEl resultado debería ser:
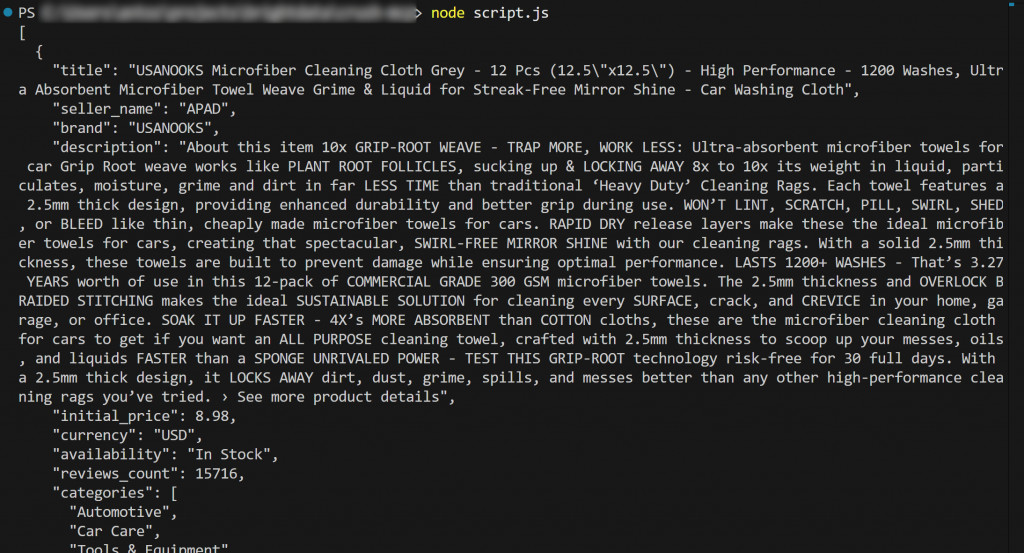
¡Et voilà! El flujo de trabajo ha tenido éxito.
En detalle, el contenido cargado desde product.json e impreso en el terminal coincide con los datos reales que puedes encontrar en la página original del producto de Amazon.
Importante: product. json contiene datos scrapeados auténticos, no contenido alucinado o inventado producido por la IA. Es fundamental señalar esto porque el scraping de Amazon es notoriamente difícil debido a sus avanzadas protecciones anti-bot (por ejemplo, debido al CAPTCHA de Amazon). Por lo tanto, ¡un LLM normal por sí solo no podría lograr este objetivo!
Este ejemplo muestra la verdadera potencia de combinar Crush con el servidor MCP de Bright Data. Ahora pruebe a experimentar con nuevas solicitudes y explore flujos de trabajo de datos más avanzados basados en LLM directamente en la CLI.
Conclusión
En este tutorial, ha visto cómo conectar Crush con el MCP Web de Bright Data(¡que ahora ofrece un nivel gratuito!). El resultado es un potente agente de codificación CLI capaz de acceder e interactuar con la web. Esta integración es posible gracias al soporte incorporado de Crush CLI para servidores MCP.
La tarea de ejemplo en esta guía fue intencionalmente simple. Sin embargo, no olvide que con esta integración puede abordar casos de uso mucho más complejos. Después de todo, las herramientas MCP de Bright Data Web admiten una amplia variedad de escenarios de agentes.
Para crear agentes más avanzados, explore toda la gama de servicios disponibles en la infraestructura de IA de Bright Data.
Regístrese para obtener una cuenta gratuita de Bright Data y empiece a experimentar con herramientas web preparadas para IA hoy mismo.




