

En esta guía, aprenderá:
- Qué es la gestión de riesgos de terceros (TPRM) y por qué falla la selección manual
- Cómo crear un agente de IA autónomo que investigue a los proveedores en busca de medios adversos
- Cómo integrar la API SERP y Web Unlocker de Bright Data para una recopilación de datos fiable y actualizada
- Cómo utilizar OpenHands SDK para la generación de scripts de agentes y OpenAI para el análisis de riesgos
- Cómo mejorar el agente con la API del navegador para escenarios complejos, como los registros judiciales
¡Empecemos!
El problema de la selección manual de proveedores
Los equipos de cumplimiento normativo de las empresas se enfrentan a una tarea imposible: supervisar a cientos de proveedores externos en busca de señales de riesgo en toda la web. Los enfoques tradicionales implican:
- Búsquedas manuales en Google de cada nombre de proveedor combinadas con palabras clave como «demanda», «quiebra» o «fraude».
- Encontrar muros de pago y CAPTCHAs al intentar acceder a artículos de noticias y registros judiciales
- Documentación inconsistente sin un proceso estandarizado para registrar los resultados.
- No hay un seguimiento continuo, la selección de proveedores se realiza una vez durante la incorporación y luego nunca más.
Este enfoque falla por tres razones fundamentales:
- Escala: un solo analista puede investigar a fondo entre 5 y 10 proveedores al día.
- Acceso: las fuentes protegidas, como los registros judiciales y los sitios web de noticias premium, bloquean el acceso automatizado.
- Continuidad: las evaluaciones puntuales pasan por alto los riesgos que surgen después de la incorporación
La solución: un agente TPRM autónomo
Un agente TPRM automatiza todo el flujo de trabajo de investigación de proveedores utilizando tres capas especializadas:
- Descubrimiento (API SERP): el agente busca en Google señales de alerta como demandas, medidas reguladoras y dificultades financieras.
- Acceso (Web Unlocker): cuando los resultados relevantes se encuentran detrás de muros de pago o CAPTCHAs, el agente sortea estas barreras para extraer el contenido completo.
- Acción (OpenAI + OpenHands SDK): el agente analiza el contenido para determinar la gravedad del riesgo utilizando OpenAI y, a continuación, utiliza OpenHands SDK para generar scripts de supervisión en Python que comprueban diariamente si hay nuevas noticias adversas en los medios de comunicación.
Este sistema transforma horas de investigación manual en minutos de análisis automatizado.
Requisitos previos
Antes de empezar, asegúrese de que dispone de:
- Python 3.12 o superior (requerido para OpenHands SDK)
- Una cuenta de Bright Data con acceso a la API (prueba gratuita disponible)
- Una clave API de OpenAI para el análisis de riesgos
- Una cuenta de OpenHands Cloud o su propia clave API LLM para la generación de scripts agenticos
- Conocimientos básicos de Python y API REST
Arquitectura del proyecto
El agente TPRM sigue un proceso de tres etapas:
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ DESCUBRIMIENTO │────▶│ ACCESO │────▶│ ACCIÓN │
│ (API SERP) │ │ (Web Unlocker) │ │ (OpenAI + SDK) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
Buscar en Google Eludir muros de pago Analizar riesgos
para señales de alerta y CAPTCHAs Generar scriptsCrear la siguiente estructura de proyecto:
tprm-agent/
├── src/
│ ├── __init__.py
│ ├── config.py # Configuración
│ ├── discovery.py # Integración de API SERP
│ ├── access.py # Integración de Web Unlocker
│ ├── actions.py # OpenAI + OpenHands SDK
│ ├── agent.py # Orquestación principal
│ └── browser.py # API del navegador (mejora)
├── api/
│ └── main.py # Puntos finales FastAPI
├── scripts/
│ └── generated/ # Scripts de supervisión generados automáticamente
├── .env
├── requirements.txt
└── README.md
Configuración del entorno
Cree un entorno virtual e instale las dependencias necesarias:
python -m venv venv
source venv/bin/activate # Windows: venvScriptsactivate
pip install requests fastapi uvicorn python-dotenv pydantic openai beautifulsoup4 playwright openhands-sdk openhands-tools
Cree un archivo .env para almacenar sus credenciales API:
# Token de API de Bright Data (para la API SERP)
BRIGHT_DATA_API_TOKEN=tu_token_api
# Zona SERP de Bright Data
BRIGHT_DATA_SERP_ZONE=tu_nombre_de_zona_serp
# Credenciales de Bright Data Web Unlocker
BRIGHT_DATA_CUSTOMER_ID=tu_id_de_cliente
BRIGHT_DATA_UNLOCKER_ZONE=tu_nombre_de_zona_unlocker
BRIGHT_DATA_UNLOCKER_PASSWORD=tu_contraseña_de_zona
# OpenAI (para análisis de riesgos)
OPENAI_API_KEY=tu_clave_api_openai
# OpenHands (para generación de scripts agenticos)
# Utiliza OpenHands Cloud: openhands/claude-sonnet-4-5-20260929
# O trae el tuyo propio: anthropic/claude-sonnet-4-5-20260929
LLM_API_KEY=tu_llm_api_key
LLM_MODEL=openhands/claude-sonnet-4-5-20260929Configuración de Bright Data
Paso 1: Crea tu cuenta de Bright Data
Regístrese en Bright Data y vaya al panel de control.
Paso 2: Configure la zona API SERP
- Vaya a Proxies e infraestructura de scraping
- Haga clic en «Añadir » y seleccione «API SERP».
- Asigna un nombre a tu zona (por ejemplo,
tprm_serp). - Copie el nombre de su zona y anote su token API en Configuración > Tokens API
La API SERP devuelve resultados de búsqueda estructurados de Google sin ser bloqueada. Añada brd_json=1 a su URL de búsqueda para obtener una salida JSON analizada.
Paso 3: Configurar la zona de Web Unlocker
- Haga clic en Añadir y seleccione Web Unlocker
- Asigne un número a su zona (por ejemplo,
tprm_unlocker). - Copie las credenciales de su zona (formato de nombre de usuario:
brd-customer-CUSTOMER_ID-zone-ZONE_NAME).
Web Unlocker gestiona automáticamente los CAPTCHA, las huellas digitales y la rotación de IP a través de un punto final Proxy.
Creación de la capa de descubrimiento (API SERP)
La capa de descubrimiento busca en Google medios adversos sobre proveedores utilizando la API SERP. Cree src/discovery.py:
import requests
from typing import Optional
from dataclasses import dataclass
from urllib.parse import quote_plus
from config import settings
@dataclass
class SearchResult:
title: str
url: str
snippet: str
source: str
class DiscoveryClient:
"""Busca medios adversos utilizando la API SERP de Bright Data (API directa)."""
RISK_CATEGORIES = {
"litigation": ["lawsuit", "litigation", "sued", "court case", "legal action"],
"financial": ["bankruptcy", "insolvency", "debt", "financial trouble", "default"],
"fraud": ["fraude", "estafa", "investigación", "acusación", "escándalo"],
"regulatory": ["violación", "multa", "penalización", "sanciones", "cumplimiento"],
«operational»: [«retirada», «problema de seguridad», «cadena de suministro», «interrupción»],
}
def __init__(self):
self.api_url = «https://api.brightdata.com/request»
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def _build_queries(self, vendor_name: str, categories: Optional[list] = None) -> list[str]:
"""Crear consultas de búsqueda para cada categoría de riesgo."""
categories = categories or list(self.RISK_CATEGORIES.keys())
queries = []
for category in categories:
keywords = self.RISK_CATEGORIES.get(category, [])
keyword_str = " OR ".join(keywords)
query = f'"{vendor_name}" ({keyword_str})'
queries.append(query)
return queries
def search(self, query: str) -> list[SearchResult]:
"""Ejecuta una única consulta de búsqueda utilizando la API SERP de Bright Data."""
try:
# Crear URL de búsqueda de Google con brd_json=1 para JSON analizado
encoded_query = quote_plus(query)
google_url = f"https://www.google.com/search?q={encoded_query}&hl=en&gl=us&brd_json=1"
payload = {
"zone": settings.BRIGHT_DATA_SERP_ZONE,
"url": google_url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=30,
)
response.raise_for_status()
data = response.json()
results = []
organic = data.get("organic", [])
for item in organic:
results.append(
SearchResult(
title=item.get("title", ""),
url=item.get("link", ""),
snippet=item.get("description", ""),
source=item.get("displayed_link", ""),
)
)
return results
except Exception as e:
print(f"Error de búsqueda: {e}")
return []
def discover_adverse_media(
self,
vendor_name: str,
categories: Optional[list] = None,
) -> dict[str, list[SearchResult]]:
"""Buscar medios adversos en todas las categorías de riesgo."""
queries = self._build_queries(vendor_name, categories)
category_names = categories or list(self.RISK_CATEGORIES.keys())
categorized_results = {}
for category, query in zip(category_names, queries):
print(f" Buscando: {category}...")
results = self.search(query)
categorized_results[category] = results
return categorized_results
def filter_relevant_results(
self, results: dict[str, list[SearchResult]], vendor_name: str
) -> dict[str, list[SearchResult]]:
"""Filtrar los resultados irrelevantes."""
filtered = {}
vendor_lower = vendor_name.lower()
for category, items in results.items():
relevant = []
for item in items:
if (
vendor_lower in item.title.lower()
or vendor_lower in item.snippet.lower()
):
relevant.append(item)
filtered[category] = relevant
return filtered
La API SERP devuelve JSON estructurado con resultados orgánicos, lo que facilita el parseo de títulos, URL y fragmentos para cada resultado de búsqueda.
Creación de la capa de acceso (Web Unlocker)
Cuando la capa de descubrimiento encuentra URL relevantes, la capa de acceso recupera el contenido completo utilizando la API Web Unlocker. Cree src/access.py:
import requests
from bs4 import BeautifulSoup
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class ExtractedContent:
url: str
title: str
text: str
publish_date: Optional[str]
author: Optional[str]
success: bool
error: Optional[str] = None
class AccessClient:
"""Accede al contenido protegido utilizando Bright Data Web Unlocker (basado en API)."""
def __init__(self):
self.api_url = "https://api.brightdata.com/request"
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def fetch_url(self, url: str) -> ExtractedContent:
"""Obtener y extraer contenido de una URL utilizando la API Web Unlocker."""
try:
payload = {
"zona": settings.BRIGHT_DATA_UNLOCKER_ZONA,
"url": url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=60,
)
response.raise_for_status()
# La API de Web Unlocker devuelve el HTML directamente.
html_content = response.text
content = self._extract_content(html_content, url)
return content
except requests.Timeout:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error="Request timed out",
)
except Exception as e:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error=str(e),
)
def _extract_content(self, html: str, url: str) -> ExtractedContent:
"""Extraer el contenido del artículo del HTML."""
soup = BeautifulSoup(html, "html.parser")
# Eliminar elementos no deseados
for element in soup(["script", "style", "nav", "footer", "header", "aside"]):
element.decompose()
# Extraer título
title = ""
if soup.title:
title = soup.title.string or ""
elif soup.find("h1"):
title = soup.find("h1").get_text(strip=True)
# Extraer contenido principal
article = soup.find("article") or soup.find("main") or soup.find("body")
text = article.get_text(separator="n", strip=True) if article else ""
# Limitar la longitud del texto
text = text[:10000] if len(text) > 10000 else text
# Intentar extraer la fecha de publicación
publish_date = None
date_meta = soup.find("meta", {"property": "article:published_time"})
if date_meta:
publish_date = date_meta.get("content")
# Intentar extraer el autor
autor = None
autor_meta = soup.find("meta", {"name": "author"})
si autor_meta:
autor = autor_meta.get("content")
return ExtractedContent(
url=url,
title=title,
text=text,
publish_date=publish_date,
author=author,
success=True,
)
def fetch_multiple(self, urls: list[str]) -> list[ExtractedContent]:
"""Fetch multiple URLs sequentially."""
results = []
for url in urls:
print(f" Obteniendo: {url[:60]}...")
content = self.fetch_url(url)
if not content.success:
print(f" Error: {content.error}")
results.append(content)
return results
Web Unlocker gestiona automáticamente los CAPTCHA, las huellas digitales del navegador y la rotación de IP. Simplemente enruta tus solicitudes a través del Proxy y se encarga del resto.
Creación de la capa de acción (OpenAI + OpenHands SDK)
La capa de acción utiliza OpenAI para analizar la gravedad del riesgo y OpenHands SDK para generar scripts de supervisión que utilizan la API de Bright Data Web Unlocker. OpenHands SDK proporciona capacidades de agente: el agente puede razonar, editar archivos y ejecutar comandos para crear scripts listos para la producción.
Cree src/actions.py:
import os
import json
from datetime import datetime, UTC
from dataclasses import dataclass, asdict
from openai import OpenAI
from pydantic import SecretStr
from openhands.sdk import LLM, Agent, Conversation, Tool
from openhands.tools.terminal import TerminalTool
from openhands.tools.file_editor import FileEditorTool
from config import settings
@dataclass
class RiskAssessment:
vendor_name: str
category: str
severity: str
summary: str
key_findings: list[str]
sources: list[str]
recommended_actions: list[str]
assessed_at: str
@dataclass
class MonitoringScript:
vendor_name: str
script_path: str
urls_monitored: list[str]
check_frequency: str
created_at: str
class ActionsClient:
"""Analizar los riesgos utilizando OpenAI y generar scripts de supervisión utilizando OpenHands SDK."""
def __init__(self):
# OpenAI para el análisis de riesgos
self.openai_client = OpenAI(api_key=settings.OPENAI_API_KEY)
# OpenHands para la generación de scripts agenticos
self.llm = LLM(
model=settings.LLM_MODEL,
api_key=SecretStr(settings.LLM_API_KEY),
)
self.workspace = os.path.join(os.getcwd(), "scripts", "generated")
os.makedirs(self.workspace, exist_ok=True)
def analyze_risk(
self,
vendor_name: str,
category: str,
content: list[dict],
) -> RiskAssessment:
"""Analizar el contenido extraído para determinar la gravedad del riesgo utilizando OpenAI."""
content_summary = "nn".join(
[f"Fuente: {c['url']}nTítulo: {c['title']}nContenido: {c['text'][:2000]}" for c in content]
)
prompt = f"""Analizar el siguiente contenido sobre «{vendor_name}» para la evaluación de riesgos de terceros.
Categoría: {category}
Contenido:
{content_summary}
Proporcionar una respuesta JSON con:
{{
"severity": "low|medium|high|critical",
"summary": "Resumen de 2-3 frases de los resultados",
"key_findings": ["resultado 1", "resultado 2", ...],
"recommended_actions": ["acción 1", "acción 2", ...]
}}
Tenga en cuenta lo siguiente:
- La gravedad debe basarse en el impacto potencial para el negocio.
- Crítico = se requiere una acción inmediata (fraude activo, declaración de quiebra).
- Alto = riesgo significativo que requiere investigación.
- Medio = preocupación notable que merece ser supervisada.
- Baja = problema menor o asunto histórico
"""
response = self.openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"},
)
response_text = response.choices[0].message.content
try:
result = json.loads(response_text)
except (json.JSONDecodeError, ValueError):
resultado = {
"severity": "medium",
"summary": "No se puede analizar la evaluación de riesgos",
"key_findings": [],
"recommended_actions": ["Se requiere revisión manual"],
}
return RiskAssessment(
vendor_name=vendor_name,
category=category,
severity=result.get("severity", "medium"),
summary=result.get("summary", ""),
key_findings=result.get("key_findings", []),
sources=[c["url"] for c in content],
recommended_actions=result.get("recommended_actions", []),
assessed_at=datetime.now(UTC).isoformat(),
)
def generate_monitoring_script(
self,
vendor_name: str,
urls: list[str],
check_keywords: list[str],
) -> MonitoringScript:
"""Generar un script de monitorización Python utilizando el agente OpenHands SDK."""
script_name = f"monitor_{vendor_name.lower().replace(' ', '_')}.py"
script_path = os.path.join(self.workspace, script_name)
prompt = f"""Crear un script de supervisión Python en {script_path} que:
1. Compruebe diariamente si hay contenido nuevo en estas URL: {urls[:5]}
2. Busque estas palabras clave: {check_keywords}
3. Envíe una alerta (imprimir en la consola) si se encuentra nuevo contenido relevante
4. Registre todas las comprobaciones en un archivo JSON llamado «monitoring_log.json»
El script DEBE utilizar la API Bright Data Web Unlocker para evitar los muros de pago y los CAPTCHA:
- Punto final de la API: https://api.brightdata.com/request
- Utiliza la variable de entorno BRIGHT_DATA_API_TOKEN para el token Bearer
- Utiliza la variable de entorno BRIGHT_DATA_UNLOCKER_ZONE para el nombre de la zona
- Realiza solicitudes POST con carga JSON: {{"zone": "zone_name", "url": "target_url", "format": "raw"}}
- Añada el encabezado: «Authorization»: «Bearer <token>»
- Añada el encabezado: «Content-Type»: «application/json»
El script debe:
- Cargar las credenciales de Bright Data desde las variables de entorno utilizando python-dotenv
- Utilizar la API Bright Data Web Unlocker para todas las solicitudes HTTP (NO solicitudes simples.get)
- Gestionar los errores correctamente con try/except
- Incluir una función main() que se pueda ejecutar directamente
- Admite la programación mediante cron
- Almacenar hash de contenido para detectar cambios
Escribir el script completo en {script_path}.
"""
# Crear agente OpenHands con herramientas de terminal y editor de archivos
agent = Agent(
llm=self.llm,
tools=[
Tool(name=TerminalTool.name),
Tool(name=FileEditorTool.name),
],
)
# Ejecutar el agente para generar el script
conversation = Conversation(agent=agent, workspace=self.workspace)
conversation.send_message(prompt)
conversation.run()
return MonitoringScript(
vendor_name=vendor_name,
script_path=script_path,
urls_monitored=urls[:5],
check_frequency="daily",
created_at=datetime.now(UTC).isoformat(),
)
def export_assessment(self, assessment: RiskAssessment, output_path: str) -> None:
"""Exportar la evaluación de riesgos a un archivo JSON."""
with open(output_path, "w") as f:
json.dump(asdict(assessment), f, indent=2)La ventaja clave de utilizar OpenHands SDK en lugar de la simple generación de código basada en comandos es que el agente puede iterar su trabajo, probar el script, corregir errores y perfeccionarlo hasta que funcione correctamente.
Orquestación de agentes
Ahora vamos a conectarlo todo. Cree src/agent.py:
from dataclasses import dataclass
from datetime import datetime, UTC
from typing import Optional
from discovery import DiscoveryClient, SearchResult
from access import AccessClient, ExtractedContent
from actions import ActionsClient, RiskAssessment, MonitoringScript
@dataclass
class InvestigationResult:
vendor_name: str
started_at: str
completed_at: str
total_sources_found: int
total_sources_accessed: int
risk_assessments: list[RiskAssessment]
monitoring_scripts: list[MonitoringScript]
errors: list[str]
clase TPRMAgent:
"""Agente autónomo para investigaciones de gestión de riesgos de terceros."""
def __init__(self):
self.discovery = DiscoveryClient()
self.access = AccessClient()
self.actions = ActionsClient()
def investigar(
self,
nombre_proveedor: str,
categorías: Optional[list[str]] = None,
generar_monitores: bool = True,
) -> ResultadoInvestigación:
"""Realizar una investigación completa del proveedor."""
iniciado_en = datetime.now(UTC).isoformat()
errores = []
risk_assessments = []
monitoring_scripts = []
# Etapa 1: Descubrimiento (API SERP)
print(f"[Descubrimiento] Buscando medios adversos sobre {vendor_name}...")
try:
raw_results = self.discovery.discover_adverse_media(vendor_name, categories)
filtered_results = self.discovery.filter_relevant_results(raw_results, vendor_name)
except Exception as e:
errors.append(f"Discovery failed: {str(e)}")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=datetime.now(UTC).isoformat(),
total_sources_found=0,
total_sources_accessed=0,
risk_assessments=[],
monitoring_scripts=[],
errors=errors,
)
total_sources = sum(len(results) for results in filtered_results.values())
print(f"[Descubrimiento] Se han encontrado {total_sources} fuentes relevantes")
# Etapa 2: Acceso (Web Unlocker)
print(f"[Acceso] Extrayendo contenido de las fuentes...")
all_urls = []
url_to_category = {}
for category, results in filtered_results.items():
for result in results:
all_urls.append(result.url)
url_to_category[result.url] = category
try:
extracted_content = self.access.fetch_multiple(all_urls)
successful_extractions = [c for c in extracted_content if c.success]
except Exception as e:
error_msg = f"Acceso fallido: {str(e)}"
print(f"[Acceso] {error_msg}")
errors.append(error_msg)
successful_extractions = []
print(f"[Acceso] Se han extraído correctamente {len(successful_extractions)} fuentes")
# Etapa 3: Acción - Analizar riesgos (OpenAI)
print(f"[Acción] Analizando riesgos...")
category_content = {}
for content in successful_extractions:
category = url_to_category.get(content.url, "unknown")
if category not in category_content:
category_content[category] = []
category_content[category].append({
"url": content.url,
"title": content.title,
"text": content.text,
})
for category, content_list in category_content.items():
if not content_list:
continue
try:
assessment = self.actions.analyze_risk(vendor_name, category, content_list)
risk_assessments.append(evaluación)
except Exception as e:
errors.append(f"Fallo en el análisis de riesgos para {categoría}: {str(e)}")
# Etapa 3: Acción: generar scripts de supervisión
if generate_monitors and successful_extractions:
print(f"[Acción] Generando scripts de supervisión...")
intentar:
urls_to_monitor = [c.url for c in successful_extractions[:10]]
keywords = [nombre_del_proveedor, «demanda», «quiebra», «fraude»]
script = self.actions.generate_monitoring_script(
nombre_del_proveedor, urls_to_monitor, keywords
)
monitoring_scripts.append(script)
except Exception as e:
errors.append(f"Error al generar el script: {str(e)}")
completed_at = datetime.now(UTC).isoformat()
print(f"[Completo] Investigación finalizada")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=completed_at,
total_sources_found=total_sources,
total_sources_accessed=len(successful_extractions),
risk_assessments=risk_assessments,
monitoring_scripts=monitoring_scripts,
errors=errors,
)
def main():
"""Ejemplo de uso."""
agent = TPRMAgent()
result = agent.investigate("Acme Corp")
print(f"n{'='*50}")
print(f"Investigación completada: {result.vendor_name}")
print(f"Fuentes encontradas: {result.total_sources_found}")
print(f"Fuentes consultadas: {result.total_sources_accessed}")
print(f"Evaluaciones de riesgos: {len(result.risk_assessments)}")
print(f"Scripts de supervisión: {len(result.monitoring_scripts)}")
para evaluación en resultado.evaluaciones_de_riesgo:
imprimir(f"n[{evaluación.categoría.mayúscula()}] Gravedad: {evaluación.gravedad}")
imprimir(f"Resumen: {evaluación.resumen}")
si __nombre__ == "__main__":
main()
El agente coordina las tres capas, gestionando los errores con elegancia y generando un resultado de investigación completo.
Configuración
Cree src/config.py para configurar todos los secretos y claves que necesitaremos para que la aplicación se ejecute correctamente:
import os
from dotenv import load_dotenv
load_dotenv()
class Settings:
# API SERP
BRIGHT_DATA_API_TOKEN: str = os.getenv("BRIGHT_DATA_API_TOKEN", "")
BRIGHT_DATA_SERP_ZONE: str = os.getenv("BRIGHT_DATA_SERP_ZONE", "")
# Web Unlocker
BRIGHT_DATA_CUSTOMER_ID: str = os.getenv("BRIGHT_DATA_CUSTOMER_ID", "")
BRIGHT_DATA_UNLOCKER_ZONE: str = os.getenv("BRIGHT_DATA_UNLOCKER_ZONE", "")
BRIGHT_DATA_UNLOCKER_PASSWORD: str = os.getenv("BRIGHT_DATA_UNLOCKER_PASSWORD", "")
# OpenAI (para análisis de riesgos)
OPENAI_API_KEY: str = os.getenv("OPENAI_API_KEY", "")
# OpenHands (para la generación de scripts agenticos)
LLM_API_KEY: str = os.getenv("LLM_API_KEY", "")
LLM_MODEL: str = os.getenv("LLM_MODEL", "openhands/claude-sonnet-4-5-20260929")
settings = Settings()Creación de la capa API
Con FastAPI, crearás api/main.py para exponer el agente a través de puntos finales REST:
from fastapi import FastAPI, HTTPException, BackgroundTasks
from pydantic import BaseModel
from typing import Optional
import uuid
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent, InvestigationResult
app = FastAPI(
title="TPRM Agent API",
description="Autonomous Third-Party Risk Management Agent",
version="1.0.0",)
investigations: dict[str, InvestigationResult] = {}
agent = TPRMAgent()
class InvestigationRequest(BaseModel):
vendor_name: str
categories: Optional[list[str]] = None
generate_monitors: bool = True
clase InvestigationResponse(BaseModel):
investigation_id: str
status: str
message: str
@app.post("/investigate", response_model=InvestigationResponse)
def start_investigation(
request: InvestigationRequest,
background_tasks: BackgroundTasks,
):
"""Iniciar una nueva investigación de proveedor."""
investigation_id = str(uuid.uuid4())
def run_investigation():
result = agent.investigate(
vendor_name=request.vendor_name,
categories=request.categories,
generate_monitors=request.generate_monitors,
)
investigations[investigation_id] = result
tasks_en_segundo_plano.añadir_tarea(ejecutar_investigación)
devolver RespuestaDeInvestigación(
id_investigación=id_investigación,
estado="iniciada",
mensaje=f"Investigación iniciada para {nombre_proveedor}",
)
@app.get("/investigate/{investigation_id}")
def get_investigation(investigation_id: str):
"""Obtener los resultados de la investigación."""
if investigation_id not in investigations:
raise HTTPException(status_code=404, detail="Investigación no encontrada o aún en curso")
return investigations[investigation_id]
@app.get("/reports/{vendor_name}")
def get_reports(vendor_name: str):
"""Obtener todos los informes de un proveedor."""
vendor_reports = [
result
for result in investigations.values()
if result.vendor_name.lower() == vendor_name.lower()
]
if not vendor_reports:
raise HTTPException(status_code=404, detail="No se han encontrado informes para este proveedor")
return vendor_reports
@app.get("/health")
def health_check():
"""Punto final de comprobación del estado."""
return {"status": "healthy"}Ejecuta la API localmente:
python -m uvicorn API.main:app --reloadVisita http://localhost:8000/docs para explorar la documentación interactiva de la API.
Mejora con la API del navegador (Navegador de scraping)
Para escenarios complejos, como registros judiciales que requieren el envío de formularios o sitios con mucho JavaScript, puede mejorar el agente con la API del navegador de Bright Data (Navegador de scraping). Puede configurarlo de forma similar a la API Web Unlocker y la API SERP.
La API del navegador proporciona un navegador alojado en la nube que se controla a través de Playwright mediante el protocolo Chrome DevTools Protocol (CDP). Esto es útil para:
- Búsquedas en registros judiciales que requieren el envío de formularios y navegación
- Sitios conmucho JavaScript y carga de contenido dinámico
- Flujos de autenticación de varios pasos
- Capturar capturas de pantalla para la documentación de cumplimiento
Configuración
Añade las credenciales de la API del navegador a tu .env:
# API del navegador
BRIGHT_DATA_BROWSER_USER: str = os.getenv("BRIGHT_DATA_BROWSER_USER", "")
BRIGHT_DATA_BROWSER_PASSWORD: str = os.getenv("BRIGHT_DATA_BROWSER_PASSWORD", "")Implementación del cliente del navegador
Cree src/browser.py:
import asyncio
from playwright.async_api import async_playwright
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class BrowserContent:
url: str
title: str
text: str
screenshot_path: Optional[str]
success: bool
error: Optional[str] = None
class BrowserClient:
"""Accede a contenido dinámico utilizando la API del navegador Bright Data (Navegador de scraping).
Úsalo para:
- Sitios con mucho JavaScript que requieren una renderización completa
- Formularios de varios pasos (por ejemplo, búsquedas en registros judiciales)
- Sitios que requieren clics, desplazamiento o interacción
- Captura de capturas de pantalla para documentación de cumplimiento
"""
def __init__(self):
# Crear punto final WebSocket para conexión CDP
auth = f"{settings.BRIGHT_DATA_BROWSER_USER}:{settings.BRIGHT_DATA_BROWSER_PASSWORD}"
self.endpoint_url = f"wss://{auth}@brd.superproxy.io:9222"
async def fetch_dynamic_page(
self,
url: str,
wait_for_selector: Optional[str] = None,
take_screenshot: bool = False,
screenshot_path: Optional[str] = None,
) -> BrowserContent:
"""Obtener contenido de una página dinámica utilizando la API del navegador."""
async with async_playwright() as playwright:
try:
print(f"Conectando con el Navegador de scraping de Bright Data...")
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
print(f"Navegando a {url}...")
await page.goto(url, timeout=120000)
# Esperar a un selector específico si se proporciona
if wait_for_selector:
await page.wait_for_selector(wait_for_selector, timeout=30000)
# Obtener el contenido de la página
title = await page.title()
# Extraer texto
text = await page.evaluate("() => document.body.innerText")
# Hacer una captura de pantalla si se solicita
if take_screenshot and screenshot_path:
await page.screenshot(path=screenshot_path, full_page=True)
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=screenshot_path if take_screenshot else None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def fill_and_submit_form(
self,
url: str,
form_data: dict[str, str],
submit_selector: str,
result_selector: str,
) -> BrowserContent:
"""Rellena un formulario y obtiene resultados, útil para registros judiciales."""
async with async_playwright() as playwright:
try:
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
await page.goto(url, timeout=120000)
# Rellene los campos del formulario
for selector, value in form_data.items():
await page.fill(selector, value)
# Envíe el formulario
await page.click(submit_selector)
# Espere los resultados
await page.wait_for_selector(result_selector, timeout=30000)
title = await page.title()
text = await page.evaluate("() => document.body.innerText")
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def scroll_and_collect(
self,
url: str,
scroll_count: int = 5,
wait_between_scrolls: float = 1.0,
) -> BrowserContent:
"""Maneja páginas de desplazamiento infinito."""
async with async_playwright() as playwright:
try:
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
await page.goto(url, timeout=120000)
# Desplazarse hacia abajo varias veces
for i in range(scroll_count):
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await asyncio.sleep(wait_between_scrolls)
title = await page.title()
text = await page.evaluate("() => document.body.innerText")
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
# Ejemplo de uso para la búsqueda en el registro judicial
async def example_court_search():
client = BrowserClient()
# Ejemplo: Buscar en un registro judicial
result = await client.fill_and_submit_form(
url="https://example-court-registry.gov/search",
form_data={
"#party-name": "Acme Corp",
"#case-type": "civil",
},
submit_selector="#search-button",
result_selector=".search-results",
)
if result.success:
print(f"Found court records: {result.text[:500]}")
else:
print(f"Error: {result.error}")
if __name__ == "__main__":
asyncio.run(example_court_search())Cuándo utilizar la API del navegador frente al Web Unlocker
| Escenario | Uso |
|---|---|
| Solicitudes HTTP simples | Web Unlocker |
| Páginas HTML estáticas | Web Unlocker |
| CAPTCHAs al cargar | Web Unlocker |
| Contenido renderizado con JavaScript | API del navegador |
| Envío de formularios | API del navegador |
| Navegación en varios pasos | API del navegador |
| Se necesitan capturas de pantalla | API del navegador |
Implementación con Railway
Su agente TPRM se puede implementar en producción utilizando Railway o Render, que admiten aplicaciones Python con tamaños de dependencia más grandes.
Railway es la opción más sencilla para implementar aplicaciones Python con dependencias pesadas, como OpenHands SDK. Debe registrarse y crear una cuenta para que esto funcione.
Paso 1: Instalar Railway CLI globalmente
npm i -g @railway/cliPaso 2: Añada un archivo Procfile.
En la carpeta raíz de su aplicación, cree un nuevo archivo Procfile y añada el contenido que se indica a continuación. Esto servirá como configuración o comando de inicio para la implementación
web: uvicorn API.main:app --host 0.0.0.0 --port $PORTPaso 3: Inicie sesión e inicialice Railway en el directorio del proyecto
railway login
railway initPaso 4: Implementar
railway up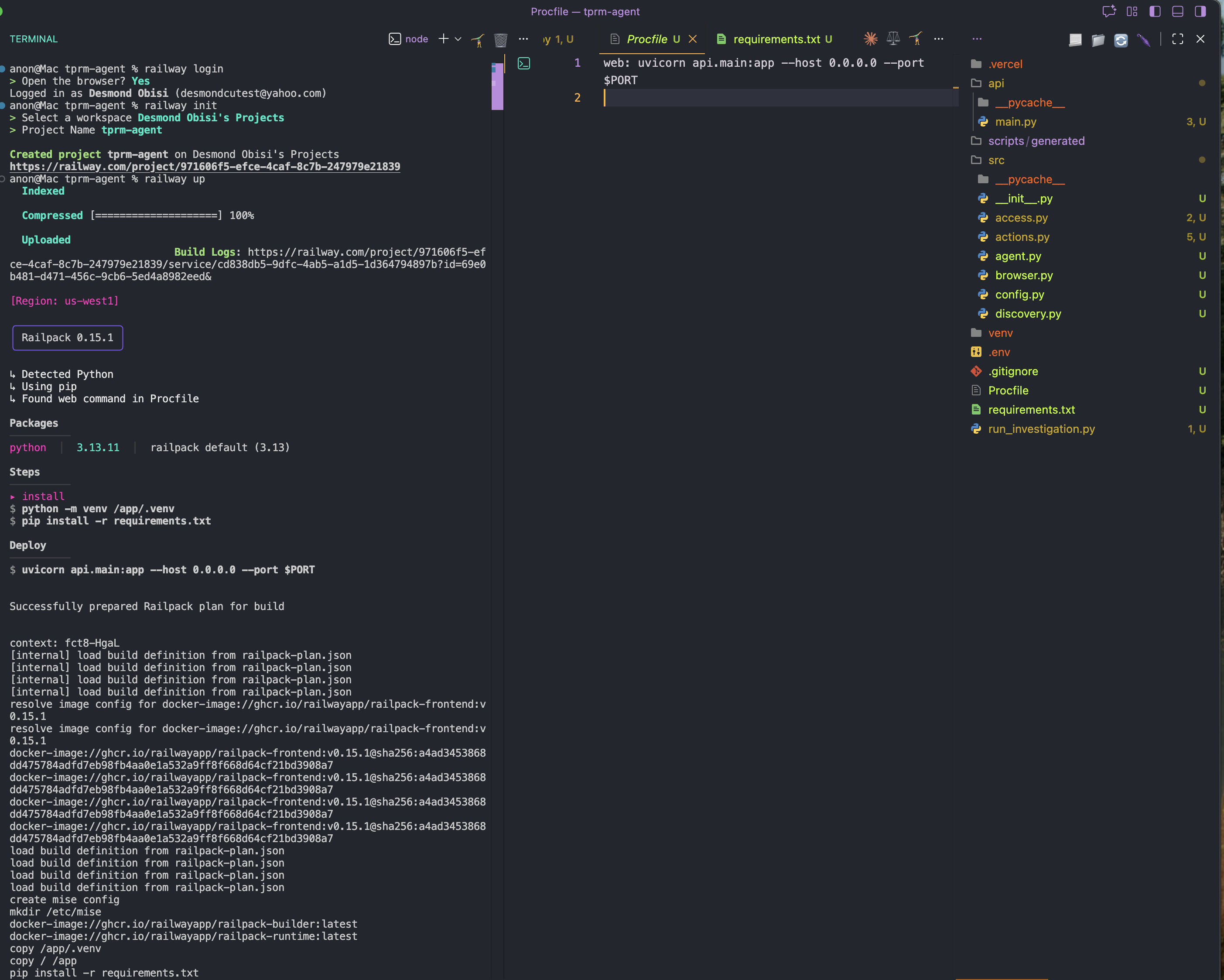
Paso 5: Añadir variables de entorno
Vaya al panel de control de su proyecto Railway → Configuración → Variables compartidas y añada estas variables y sus valores como se muestra a continuación:
BRIGHT_DATA_API_TOKEN
BRIGHT_DATA_SERP_ZONE
BRIGHT_DATA_UNLOCKER_ZONE
OPENAI_API_KEY
LLM_API_KEY
LLM_MODEL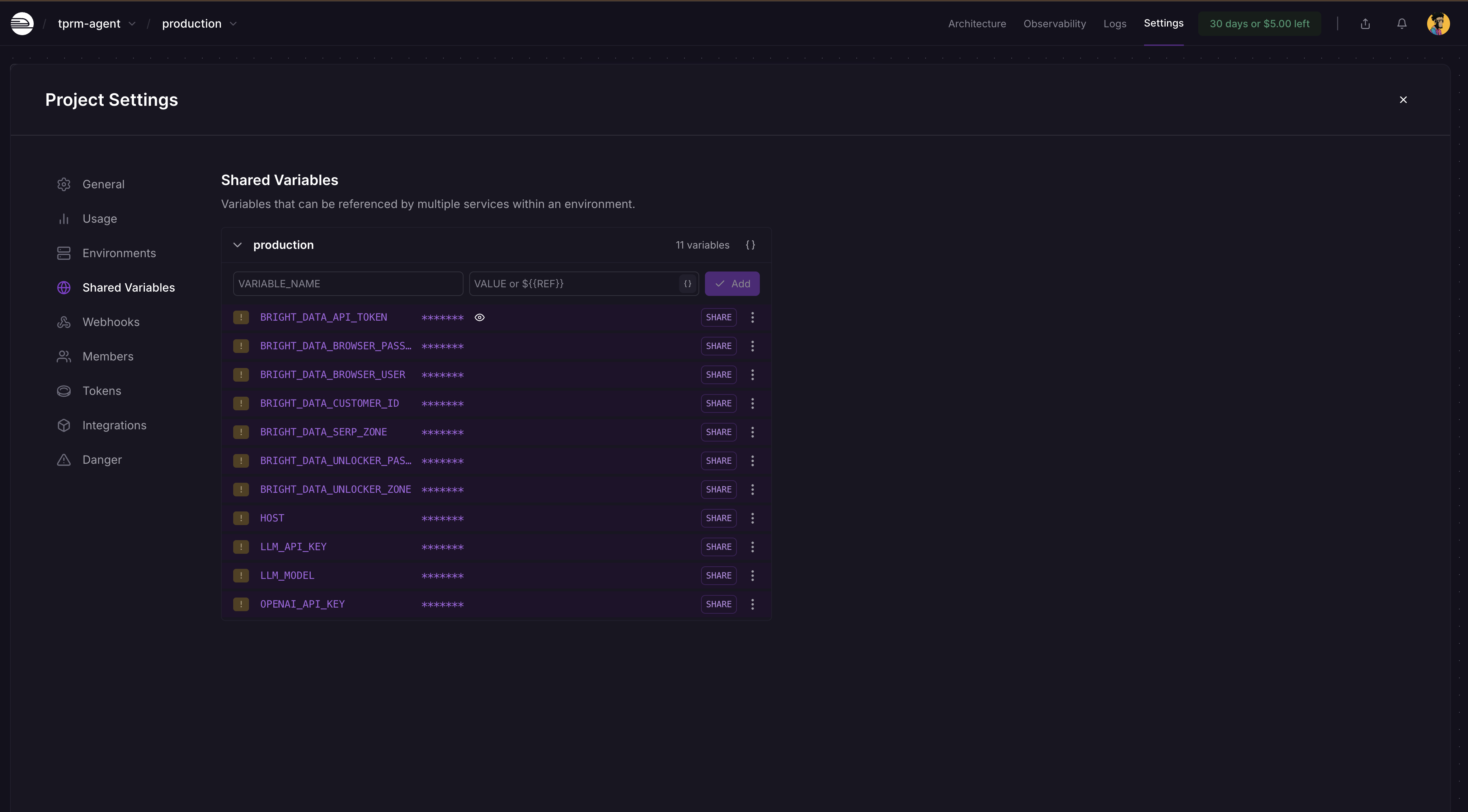
Railway detectará automáticamente los cambios y le pedirá que vuelva a implementar en el panel de control. Haga clic en Implementar y su aplicación se actualizará con los secretos.
Después de la nueva implementación, haga clic en la tarjeta de servicio y seleccione Configuración. Verá dónde generar un dominio, ya que el servicio aún no está disponible públicamente. Haga clic en Generar dominio para obtener su URL pública.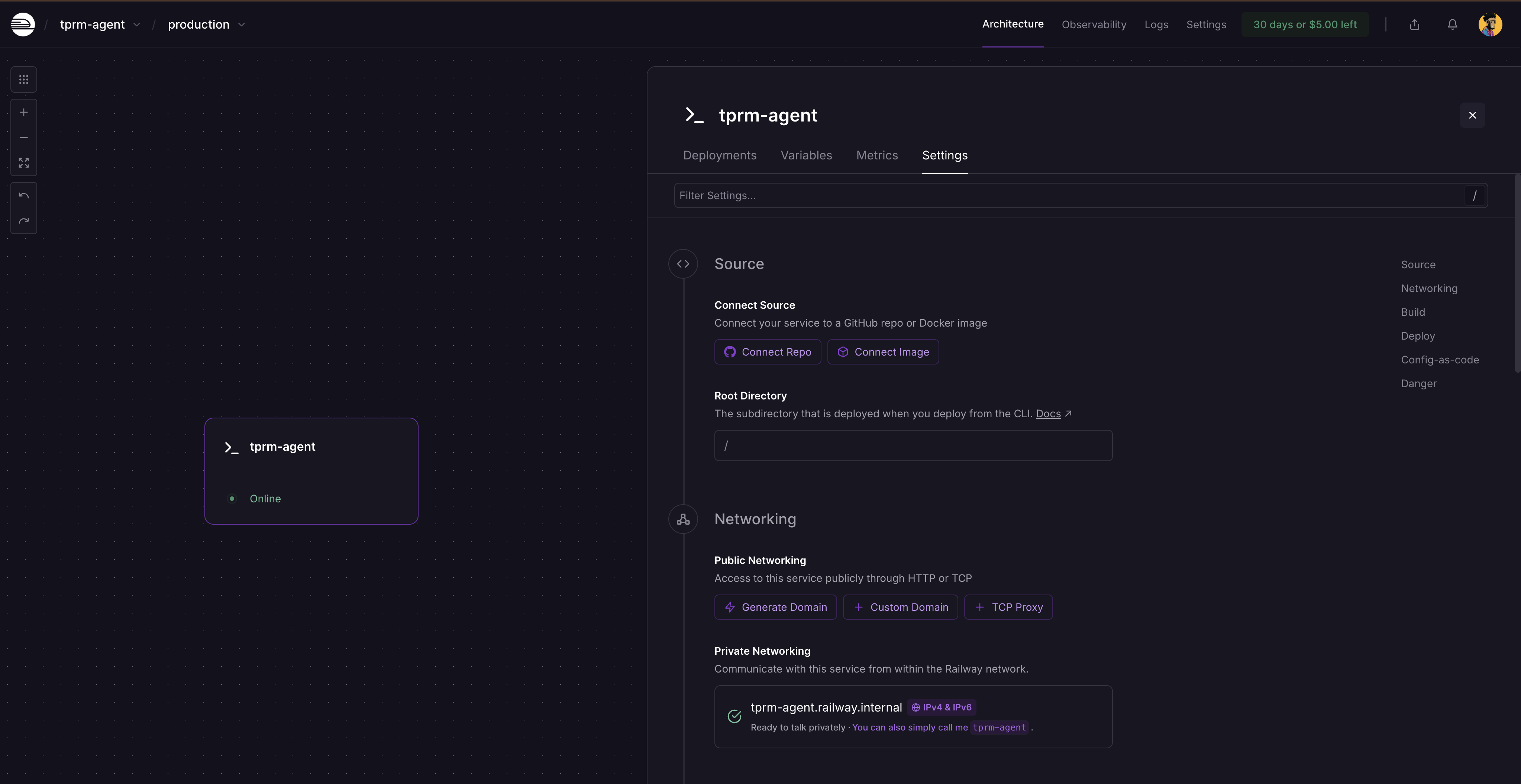
Realización de una investigación completa
Ejecutar localmente con curl
Inicie el servidor FastAPI:
# Active su entorno virtual.
source venv/bin/activate # En Windows: venvScriptsactivate
# Ejecute el servidor.
python -m uvicorn api.main:app --reloadVisite http://localhost:8000/docs para explorar la documentación interactiva de la API.
Realizar solicitudes API
- Inicie una investigación:
curl -X POST "http://localhost:8000/investigate"
-H "Content-Type: application/json"
-d '{
"vendor_name": "Acme Corp",
"categories": ["litigation", "fraud"],
"generate_monitors": true
}'- Esto devuelve un ID de investigación:
{
"investigation_id": "f6af2e0f-991a-4cb7-949e-2f316e677b5c",
"status": "started",
"message": "Investigación iniciada para Acme Corp"
}- Comprobar el estado de la investigación:
curl http://localhost:8000/investigate/f6af2e0f-991a-4cb7-949e-2f316e677b5cEjecutar el agente como un script
Cree un archivo llamado run_investigation.py en la raíz de su proyecto:
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent
def investigate_vendor():
"""Ejecutar una investigación completa del proveedor."""
agent = TPRMAgent()
# Ejecutar investigación
result = agent.investigate(
vendor_name="Acme Corp",
categories=["litigation", "financial", "fraud"],
generate_monitors=True,
)
# Imprimir resumen
print(f"n{'='*60}")
imprimir(f"Investigación completada: {resultado.nombre_proveedor}")
imprimir(f"{'='*60}")
imprimir(f"Fuentes encontradas: {resultado.total_fuentes_encontradas}")
imprimir(f"Fuentes consultadas: {resultado.total_fuentes_consultadas}")
print(f"Evaluaciones de riesgo: {len(result.risk_assessments)}")
print(f"Scripts de supervisión: {len(result.monitoring_scripts)}")
# Imprimir evaluaciones de riesgo
for assessment in result.risk_assessments:
print(f"n{'─'*60}")
print(f"[{assessment.category.upper()}] Gravedad: {assessment.severity.upper()}")
print(f"{'─'*60}")
print(f"Resumen: {assessment.summary}")
print("nConclusiones clave:")
for finding in assessment.key_findings:
print(f" • {hallazgo}")
print("nAcciones recomendadas:")
para acción en evaluación.acciones_recomendadas:
print(f" → {acción}")
# Imprimir información del script de supervisión
para script en resultado.scripts_de_supervisión:
print(f"n{'='*60}")
print(f"Script de supervisión generado")
print(f"{'='*60}")
print(f"Ruta: {script.script_path}")
print(f"Supervisión de {len(script.urls_monitored)} URL")
print(f"Frecuencia: {script.check_frequency}")
# Imprimir errores si los hay
if result.errors:
print(f"n{'='*60}")
print("Errores:")
for error in result.errors:
print(f" ⚠️ {error}")
if __name__ == "__main__":
investigate_vendor()Ejecuta el script de investigación en un nuevo terminal
# Activa tu entorno virtual
source venv/bin/activate # En Windows: venvScriptsactivate
# Ejecuta el script de investigación
python run_investigation.pyEl agente:
- Buscará en Google medios adversos utilizando la API SERP
- Accederá a las fuentes utilizando Web Unlocker
- Analizar el contenido para determinar la gravedad del riesgo utilizando OpenAI
- Generará un script de supervisión en Python utilizando OpenHands SDK que se puede programar a través de cron
Ejecutar el script de supervisión generado automáticamente
Una vez completada la investigación, encontrará un script de supervisión en la carpeta scripts/generated:
cd scripts/generated
python monitor_acme_corp.pyEl script de supervisión utiliza la API Bright Data Web Unlocker para comprobar todas las URL supervisadas y generará el siguiente resultado: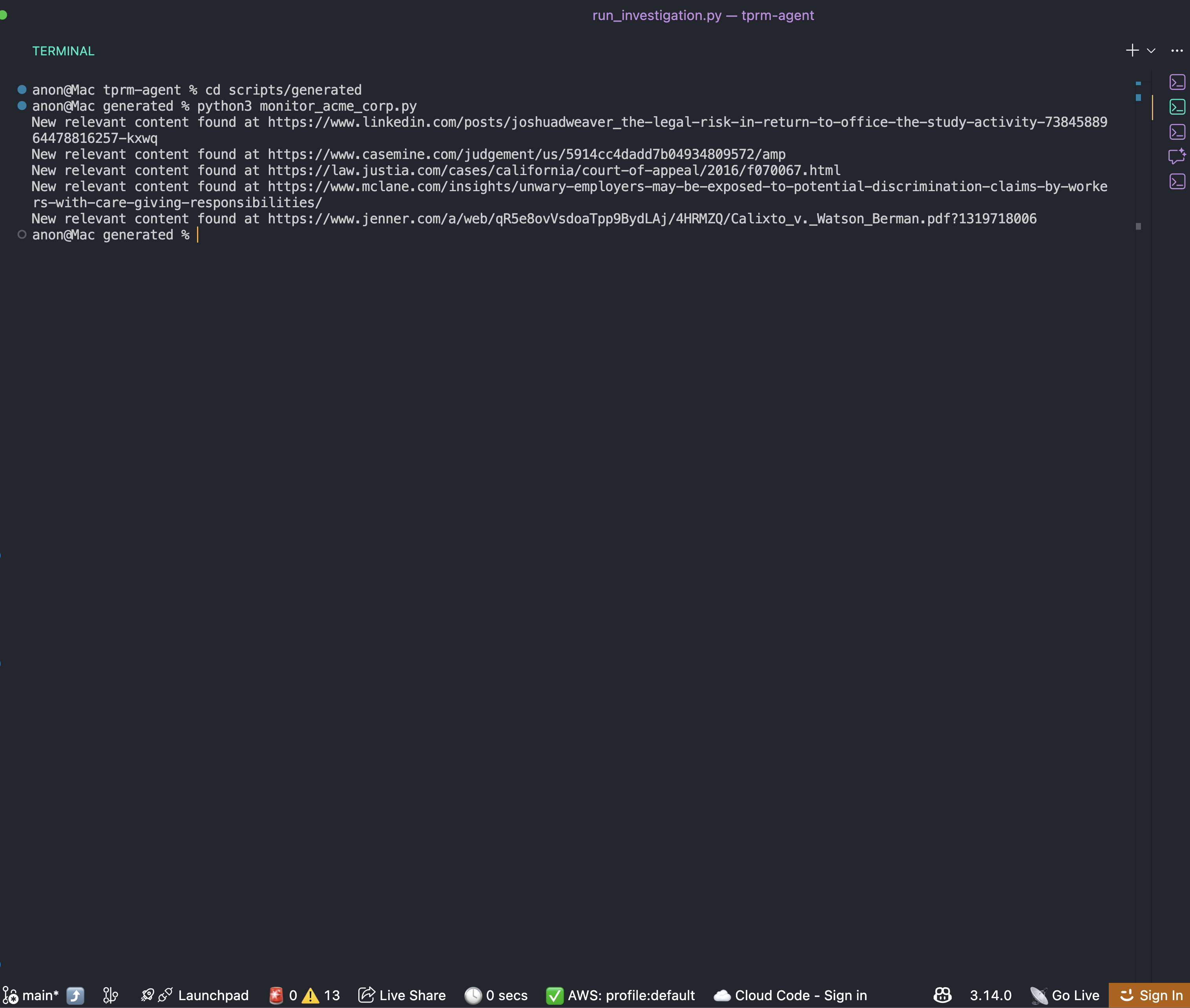
Ahora puede configurar una programación cron para el script como desee para obtener siempre la información correcta y actualizada sobre la empresa.
Conclusión
Ahora dispone de un marco completo para crear un agente TPRM empresarial que automatiza la investigación de medios adversos de los proveedores. Este sistema:
- Detecta señales de riesgo en múltiples categorías utilizando la API SERP de Bright Data
- Accede al contenido utilizando Bright Data Web Unlocker
- Analiza los riesgos utilizando OpenAI y genera scripts de supervisión utilizando OpenHands SDK
- Mejora las capacidades con la API del navegador para escenarios complejos
La arquitectura modular facilita la ampliación:
- Añade nuevas categorías de riesgo actualizando el diccionario
RISK_CATEGORIES - Integración con su plataforma GRC ampliando la capa API
- Amplíe a miles de proveedores utilizando colas de tareas en segundo plano
- Añada búsquedas en registros judiciales utilizando la mejora de la API del navegador
Próximos pasos
Para mejorar aún más este agente, considere lo siguiente:
- Integrar fuentes de datos adicionales: documentos presentados ante la SEC, listas de sanciones de la OFAC, registros corporativos
- Añadir persistencia de la base de datos: almacenar el historial de investigaciones en PostgreSQL o MongoDB
- Implementar notificaciones webhook: alertar a Slack o Teams cuando se detecten proveedores de alto riesgo
- Crear un panel de control: crear una interfaz React para visualizar las puntuaciones de riesgo de los proveedores.
- Programar análisis automatizados: utilizar Celery o APScheduler para la supervisión periódica de los proveedores.






