

El modo de IA de Google representa un cambio fundamental en la forma en que se presentan los resultados de búsqueda, ya que ofrece respuestas conversacionales basadas en la IA que sintetizan información de múltiples fuentes. Para las empresas que realizan un seguimiento de su presencia digital, los equipos de inteligencia competitiva y los profesionales de SEO, este nuevo formato de búsqueda crea tanto oportunidades como desafíos para la extracción de datos.
Esta completa guía explica qué es el modo de IA de Google, por qué la extracción de estos datos ofrece un valor empresarial estratégico, los desafíos técnicos a los que te enfrentarás y los enfoques manuales y automatizados para extraer esta información de forma eficaz a gran escala.
¿Qué es el modo Google AI?
Google AI Mode es la nueva experiencia de búsqueda de Google que ofrece respuestas sintetizadas y conversacionales en la parte superior de los resultados, lo que permite a los usuarios hacer preguntas de seguimiento de forma natural. Cada respuesta incluye enlaces destacados a la fuente, lo que facilita el acceso al contenido subyacente.
Bajo el capó, el modo AI aprovecha Gemini junto con los sistemas de búsqueda de Google utilizando un enfoque de “desdoblamiento de consultas”. Esta técnica divide las preguntas en subtemas y ejecuta varias búsquedas relacionadas en paralelo, lo que hace que aparezca más material relevante que el que ofrecen las consultas individuales tradicionales.
Este es un ejemplo de cómo Google AI Mode responde a una consulta de búsqueda con fuentes citadas (a la derecha) en las que los usuarios pueden hacer clic para obtener más información:
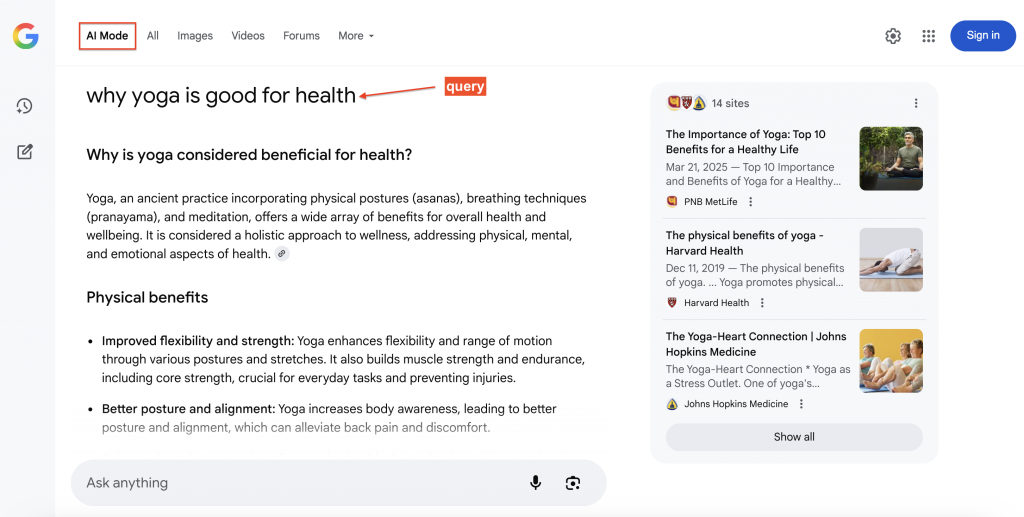
¿Por qué analizar los datos del Modo IA de Google?
Los datos de Google AI Mode proporcionan información cuantificable que influye significativamente en el SEO, el desarrollo de productos y la investigación de la competencia.
- Seguimiento del porcentaje de citas. Supervisa los dominios a los que Google AI hace referencia para tus consultas objetivo, incluido el orden de clasificación y la frecuencia a lo largo del tiempo. Esto indica la autoridad temática y ayuda a medir si las mejoras de contenido conducen a una mayor inclusión de respuestas de IA.
- Inteligencia competitiva. Capture qué marcas, productos o ubicaciones aparecen en las consultas de recomendación y comparación. Esto revela el posicionamiento en el mercado, la dinámica competitiva y los atributos que destacan las respuestas de IA.
- Análisis de brechas de contenido. Compare los hechos clave de las respuestas del modo AI con su contenido existente para identificar oportunidades de crear contenido estructurado como preguntas frecuentes, guías o tablas de datos que obtengan citas.
- Supervisión de la marca. Revise las respuestas generadas por la IA sobre su marca o sector para identificar información obsoleta y actualizar su contenido en consecuencia.
- Investigación y desarrollo. Almacene las respuestas del modo AI con metadatos (marcas de tiempo, ubicaciones, entidades) para alimentar los sistemas internos de AI, apoyar a los equipos de investigación y mejorar las aplicaciones RAG.
Método 1 – scraping manual con automatización del navegador
El scraping del modo de IA de Google requiere una sofisticada automatización del navegador debido a la naturaleza dinámica y con mucho JavaScript del contenido generado por la IA. Los marcos de automatización del navegador, como Playwright, Selenium o Puppeteer, utilizan motores de navegador reales para ejecutar JavaScript, esperar a que se cargue el contenido y reproducir la experiencia de navegación humana, lo cual es importante para capturar respuestas de IA generadas dinámicamente.
Así es como aparece el Modo IA de Google en los resultados de búsqueda:
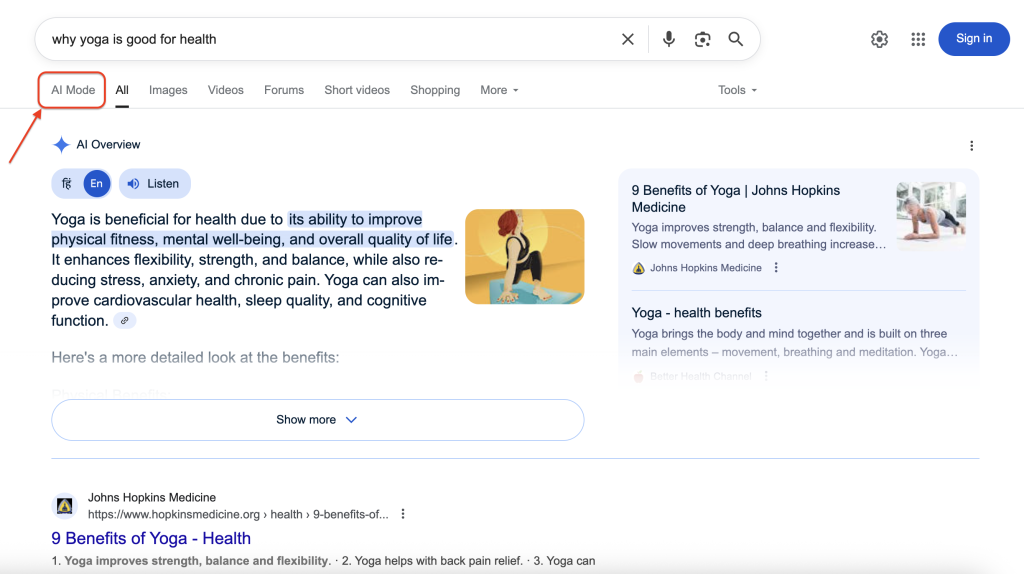
Al hacer clic en Modo IA, se muestra la interfaz de conversación completa con respuestas detalladas y citas de fuentes. Nuestro objetivo es acceder mediante programación a esta información rica y estructurada y extraerla.
Paso 1 – configuración del entorno y requisitos previos
Instale la última versión de Python y, a continuación, las dependencias necesarias. Para este tutorial, instale Playwright ejecutando estos comandos en su terminal:
pip install playwright
instalar playwrightEste comando instala Playwright y descarga los binarios de navegador necesarios (ejecutables de navegador necesarios para la automatización).
Paso 2 – importar dependencias y configuración
Importe las bibliotecas esenciales para la tarea de scraping:
import asyncio
importar urllib.parse
from playwright.async_api import async_playwrightDesglose de bibliotecas:
- asyncio – permite la programación asíncrona para mejorar el rendimiento y las operaciones concurrentes.
- urllib.parse – gestiona la codificación de URL para garantizar que las consultas tengan el formato adecuado para las solicitudes web.
- playwright – proporciona capacidades de automatización del navegador para interactuar con Google como un usuario humano.
Paso 3: arquitectura de la función y parámetros
Define la función principal de scraping con parámetros y valores de retorno claros:
async def scrape_google_ai_mode(query: str, output_path: str = "ai_response.txt") -> bool:Parámetros de la función:
- query – término de búsqueda para enviar a Google AI Mode.
- ruta_de_salida – archivo de destino para guardar la respuesta (por defecto es “ai_response.txt”).
- Devuelve un valor booleano que indica el éxito(True) o el fracaso(False) de la extracción del contenido.
Paso 4 – Construcción de la URL y activación del modo AI
Construye la URL de búsqueda que activa la interfaz del Modo AI de Google:
url = f "https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"Componentes clave:
- urllib.parse.quote_plus(query) – codifica de forma segura la consulta de búsqueda, convirtiendo los espacios en “+” y escapando los caracteres especiales.
- udm=50 – parámetro crítico que activa la interfaz del Modo AI de Google.
Paso 5 – configuración del navegador y antidetección
Inicie una instancia del navegador configurada para evitar la detección manteniendo un comportamiento realista:
async con async_playwright() como pw:
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"])
)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, como Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
)Detalles de la configuración:
- headless=False – muestra la ventana del navegador para depuración (establecer a True para entornos de producción).
- -disable-blink-features=AutomationControlled – elimina los indicadores de detección de automatización.
- User agent – imita un navegador Chrome legítimo en macOS para reducir la probabilidad de detección de bots.
Estas medidas antidetección ayudan a que el scraper parezca un usuario normal navegando por Google en lugar de un script automatizado.
Paso 6: navegación y carga de contenido dinámico
Navega hasta la URL construida y espera a que el contenido dinámico se cargue por completo:
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(2000)Explicación de la estrategia de carga:
- wait_until= “networkidle ” – espera hasta que la actividad de la red se detiene, indicando que la página se ha cargado completamente.
- wait_for_timeout – búfer adicional para la generación de contenido AI.
Paso 7 – localización del contenido y extracción del DOM
Localiza el contenedor DOM específico que aloja el contenido del modo AI de Google:
container = await page.query_selector('div[data-subtree="aimc"]')El selector CSS div[data-subtree=”aimc”] se dirige al AIMC (AI Mode Container) de Google.
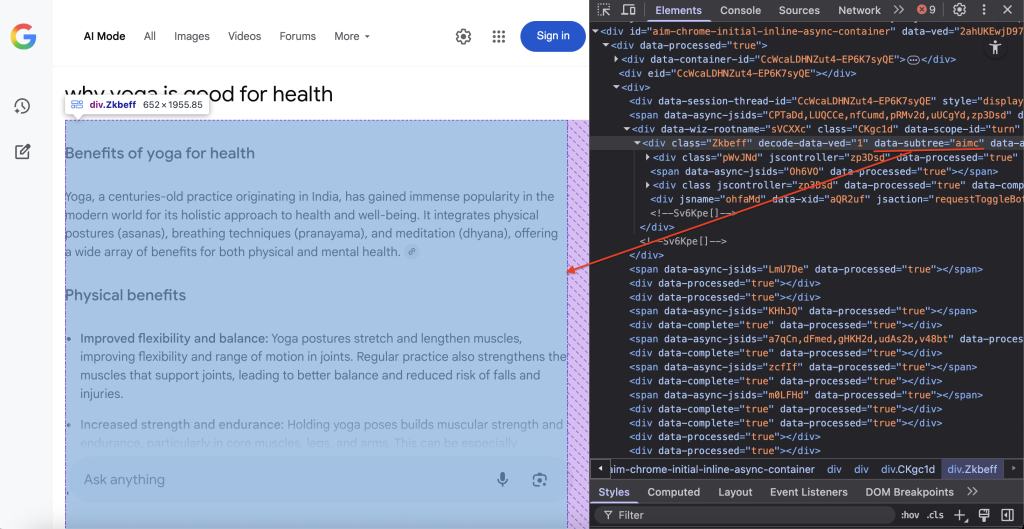
Paso 8 – Extracción y almacenamiento de datos
Extraiga el contenido del texto y guárdelo en el archivo especificado:
if contenedor:
text = (await container.inner_text()).strip()
si texto:
with open(ruta_salida, "w", codificación="utf-8") as f:
f.write(text)
print(f "Guardada respuesta AI a '{ruta_salida}' ({len(texto):,} caracteres)")
await browser.close()
return True
else:
print("Contenedor AI Mode encontrado pero no contiene contenido.")
else:
print("No se ha detectado contenido AI Mode en la página.")
await browser.close()
return FalseFlujo del proceso:
- Verificar que el contenedor AI existe en la página usando DOM querying.
- Extraer el contenido de texto plano sin marcas HTML utilizando inner_text().
- Guardar el contenido en el archivo especificado con codificación UTF-8.
- Cerrar correctamente los recursos del navegador para evitar fugas de memoria.
Paso 9 – Ejecutar la función de scraping
Ejecute la operación de scraping completa llamando a la función con la consulta deseada:
if __name__ == "__main__":
asyncio.run(scrape_google_ai_mode("por qué el yoga es bueno para la salud"))Código completo
Aquí está el código completo combinando todos los pasos:
import asyncio
import urllib.parse
from playwright.async_api import async_playwright
async def scrape_google_ai_mode(
consulta: str, ruta_salida: str = "ai_respuesta.txt"
) -> bool:
url = f "https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"
async con async_playwright() como pw:
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"])
)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, como Gecko) "
"Chrome/139.0.0.0 Safari/537.36"
)
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(1000)
container = await page.query_selector('div[data-subtree="aimc"]')
if contenedor:
text = (await container.inner_text()).strip()
si texto:
with open(ruta_salida, "w", codificación="utf-8") as f:
f.write(text)
print(
f "Guardada respuesta AI a '{ruta_salida}' ({len(texto):,} caracteres)"
)
await navegador.cerrar()
return True
else:
print("AI Mode container found but empty.")
else:
print("No se ha encontrado contenido del modo AI.")
await browser.close()
return False
if __name__ == "__main__":
asyncio.run(scrape_google_ai_mode("por qué el yoga es bueno para la salud"))Cuando se ejecuta correctamente, este script crea un archivo de texto que contiene la respuesta de IA extraída:

Buen trabajo. Has extraído correctamente el contenido del modo de IA de Google.
Desafíos y limitaciones del scraping manual
El scraping manual conlleva importantes retos operativos que se acentúan a mayor escala.
- Detección de robots y verificación CAPTCHA. Google implementa sofisticados mecanismos de detección que identifican patrones de tráfico automatizados. Después de un número limitado de solicitudes, el sistema activa la verificación CAPTCHA, bloqueando de forma efectiva la recopilación de más datos.
- Complejidad de la infraestructura y el mantenimiento. El éxito de las operaciones a gran escala exige diversas técnicas para evitar el bloqueo, como redes proxy residenciales de alta calidad, rotación de agentes de usuario, evasión de huellas dactilares del navegador y sofisticadas estrategias de distribución de solicitudes. Esto genera una sobrecarga técnica y unos costes de mantenimiento considerables.
- Contenido dinámico y cambios de diseño. Google actualiza con frecuencia la estructura de su interfaz, lo que puede romper los analizadores existentes de la noche a la mañana, exigiendo una atención inmediata y actualizaciones de código para mantener la funcionalidad.
- Complejidad del análisis sintáctico. Las respuestas del modo AI contienen estructuras anidadas, citas dinámicas y formatos variables que requieren una lógica de análisis sofisticada. Mantener la precisión en los distintos tipos de respuesta exige pruebas exhaustivas y la gestión de errores.
- Limitaciones de escalabilidad. Los métodos manuales tienen dificultades con el procesamiento masivo, la gestión de solicitudes simultáneas y el rendimiento coherente en distintas regiones geográficas y sectores verticales de búsqueda.
Estas limitaciones ponen de manifiesto por qué muchas organizaciones prefieren soluciones especializadas que gestionen la complejidad de forma profesional. Esto nos lleva a explorar la API Google AI Mode Scraper de Bright Data.
Método 2 – API de Google AI Mode Scraper
La API Google AI Mode Scraper de Bright Data proporciona una solución lista para la producción que elimina la complejidad de mantener una infraestructura de raspado, al tiempo que ofrece fiabilidad y rendimiento de nivel empresarial. La API extrae puntos de datos completos, incluidos el HTML de la respuesta, el texto de la respuesta, los enlaces adjuntos, las citas y 12 campos adicionales.
Características principales
- Gestión antibot y proxy automatizada. La API aprovecha la extensa red de proxy residencial de Bright Data, con más de 150 millones de direcciones IP, combinada con técnicas avanzadas de evasión antibot. Esta infraestructura elimina los encuentros con CAPTCHA y los problemas de bloqueo de IP.
- Salida de datos estructurada. La API proporciona datos con un formato coherente en varios formatos de exportación, incluidos JSON, NDJSON y CSV para opciones de integración flexibles.
- Escalabilidad de nivel empresarial. Creada para operaciones de gran volumen, la API procesa miles de consultas de forma eficaz con un escalado de costes predecible a través de nuestro modelo de precios de pago por resultado satisfactorio.
- Personalización geográfica. La especificación de los países de destino para obtener resultados específicos por ubicación le permite comprender cómo varían las respuestas de la IA en los distintos mercados y grupos demográficos de usuarios.
- Funcionamiento sin mantenimiento. Nuestro equipo supervisa y adapta continuamente el raspador a los cambios de Google. Cuando Google modifica las interfaces del Modo AI o implementa nuevas medidas antibot, las actualizaciones se despliegan automáticamente sin requerir ninguna acción por parte de su equipo de desarrollo.
¿El resultado? una extracción de datos exhaustiva del Modo IA de Google con fiabilidad empresarial y sin gastos de infraestructura.
Primeros pasos con la API de Google AI Mode Scraper
El proceso de implementación implica la configuración de la cuenta y la generación de la clave API para los nuevos usuarios de Bright Data, seguida de la elección del método de integración preferido. Cree su cuenta gratuita de Bright Data y genere su token de autenticación de API en 4 sencillos pasos.
A continuación, vaya a la biblioteca de raspadores web de Bright Data y busque “google” para localizar las opciones de raspadores disponibles. Haga clic en “google.com”.
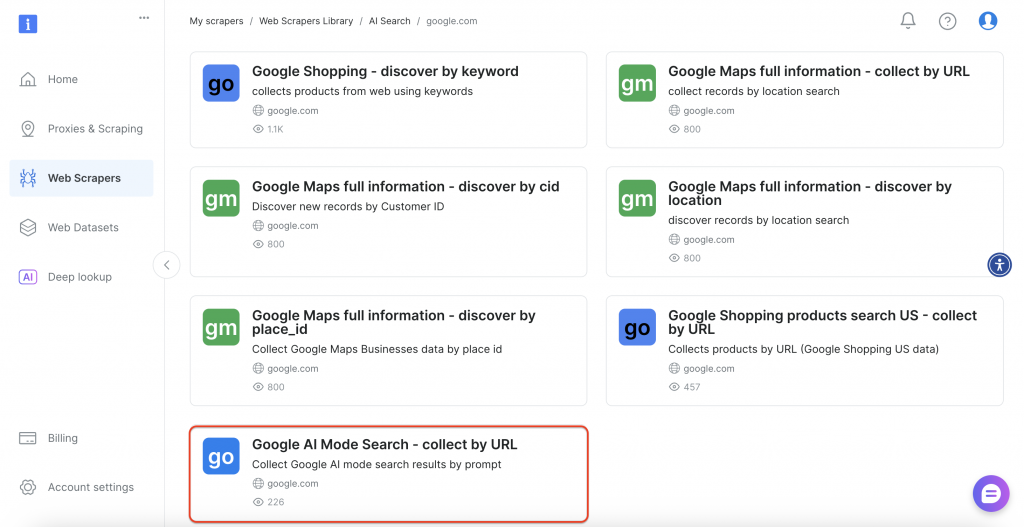
A continuación, seleccione la opción “Google AI Mode Search” de la interfaz.
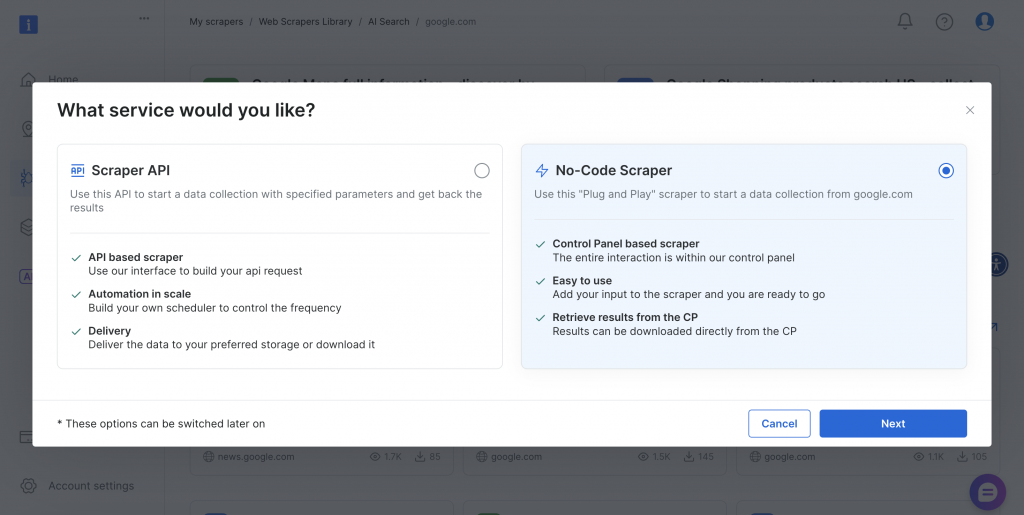
El raspador ofrece métodos de implementación sin código y basados en API para adaptarse a diferentes requisitos técnicos y capacidades de equipo.
Exploremos ambos enfoques.
Raspado interactivo (raspador sin código)
La interfaz basada en web ofrece un enfoque fácil de usar para quienes prefieren no trabajar con código. Puede introducir consultas de búsqueda directamente a través del panel de control o cargar archivos CSV que contengan varias consultas para procesarlas por lotes. La plataforma se encarga de todo automáticamente y entrega los resultados como archivos descargables.
Parámetros obligatorios:
- URL – por defecto https://google.com/aimode (se mantiene constante).
- Pregunta: consulta o pregunta de búsqueda para el análisis de inteligencia artificial de Google.
- País: ubicación geográfica para obtener resultados específicos de una región (opcional).
Configuración adicional:
- Configuración de entrega: seleccione el formato de salida y el método de entrega que prefiera.
- Esquema personalizado: seleccione los campos de datos que desea incluir en la exportación.
- Procesamiento por lotes: procese varias consultas simultáneamente mediante la carga de CSV.
Realicemos una búsqueda sencilla utilizando la pregunta “cómo ayuda la meditación a la salud mental” con “India” como país de destino. Haga clic en el botón “Empezar a recopilar” para iniciar el proceso.
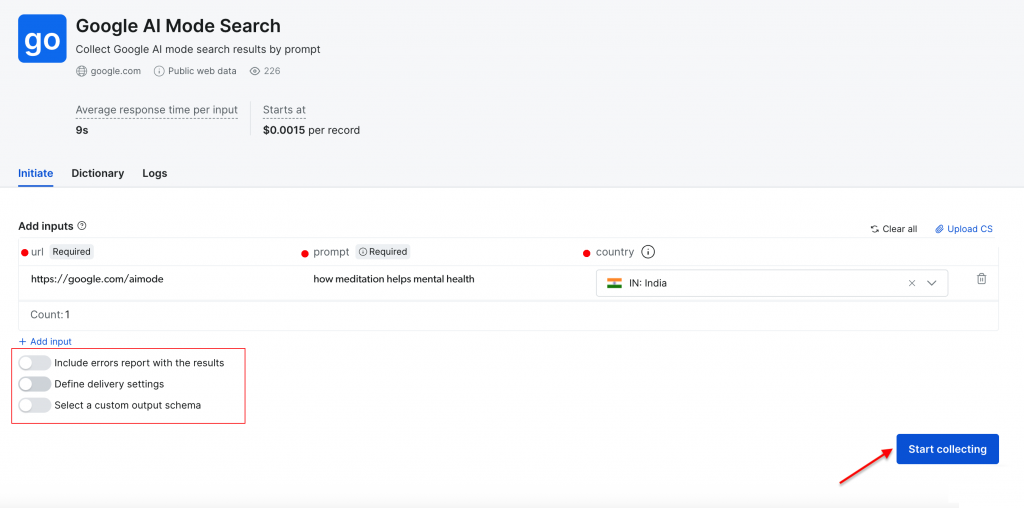
El panel de control ofrece un seguimiento del progreso en tiempo real(Listo, en marcha) y, una vez completado, puedes descargar los resultados en el formato que prefieras.
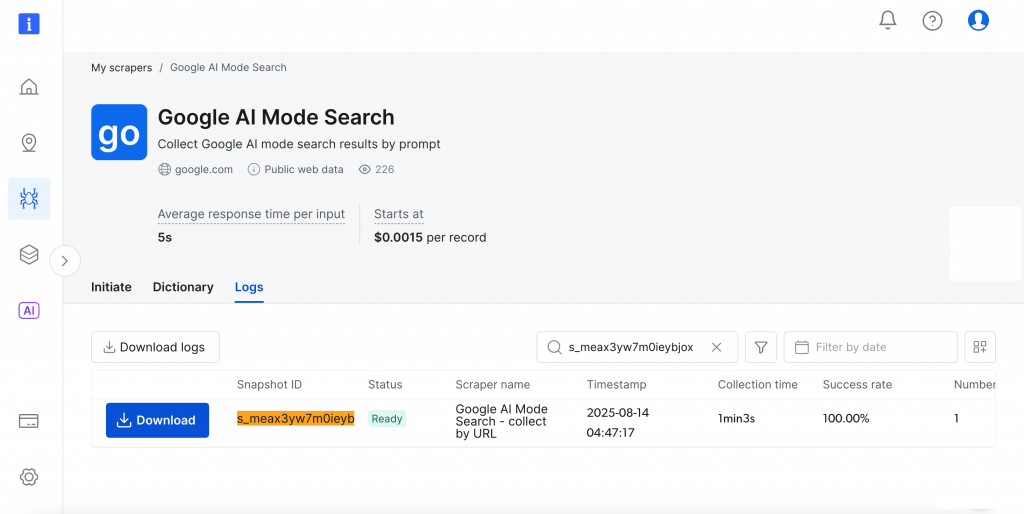
Impresionante, ¿verdad?
Scraping basado en API (Scraper API)
El enfoque programático ofrece una mayor flexibilidad y capacidades de automatización a través de puntos finales de API RESTful. El completo generador de solicitudes API y la interfaz de gestión proporcionan un control total sobre sus operaciones de scraping:
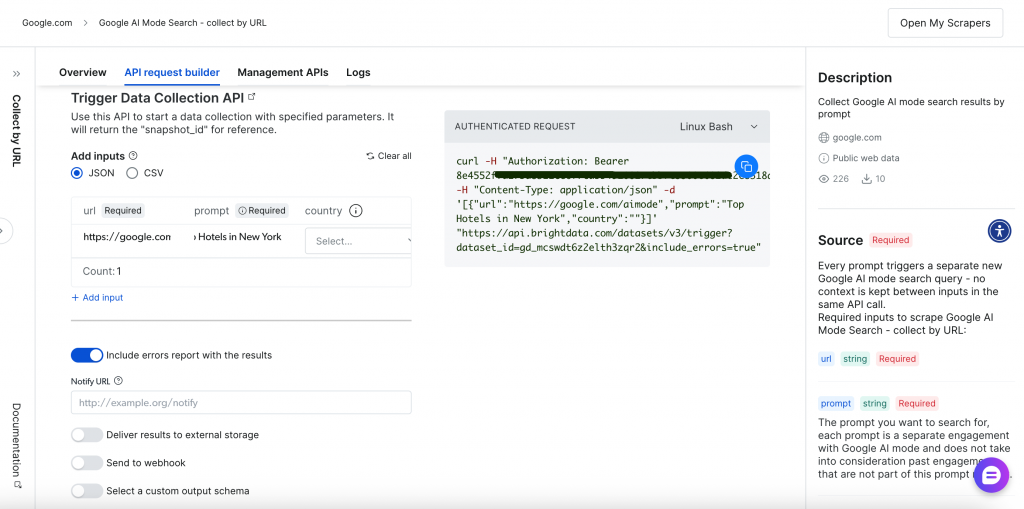
Recorramos el proceso de scraping basado en API.
Paso 1: activación de la recopilación de datos
En primer lugar, active la recopilación de datos mediante uno de estos métodos:
Ejecución de una sola consulta:
curl -H "Autorización: Bearer <YOUR_API_TOKEN>".
-H "Content-Type: application/json"
-d '[
{
"url": "https://google.com/aimode",
"prompt": "consejos de salud para usuarios de ordenador",
"country": "US"
}
]'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"Procesamiento por lotes con carga de CSV:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
-F 'data=@/path/to/your/queries.csv'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"Componentes de la solicitud:
- Autenticación – token de portador en la cabecera para acceso seguro.
- ID del conjunto de datos: identificador específico para el raspador de Google AI Mode.
- Formato de entrada: matriz JSON o archivo CSV que contiene los parámetros de consulta.
- Tratamiento de errores: incluya el parámetro de errores para obtener información completa.
También puede seleccionar el método de entrega a través de webhook para la gestión automatizada de resultados.
Paso 2 – supervisar el progreso del trabajo
Utilice el ID de instantánea devuelto para realizar un seguimiento del progreso de la recopilación:
curl -H "Autorización: Bearer <YOUR_API_TOKEN>"
"https://api.brightdata.com/datasets/v3/progress/<snapshot_id>"La respuesta indica “en ejecución” durante la recopilación de datos y “listo” cuando los resultados están disponibles para su descarga.
Paso 3 – descarga de resultados
Descargue el contenido de la instantánea o envíelo al almacenamiento especificado. Recupere los resultados completos en el formato que prefiera:
curl -H "Autorización: Bearer <YOUR_API_TOKEN>"
"https://api.brightdata.com/datasets/v3/snapshot/<snapshot_id>?format=json"La API devuelve datos estructurados completos para cada consulta:
{
"url": "https://www.google.co.in/search?q=health+consejos+para+usuarios+informáticos&hl=es&udm=50&aep=11&...",
"prompt": "consejos de salud para usuarios de ordenador",
"answer_html": "<html>...respuesta HTML completa...</html>",
"answer_text": "Consejos de salud para usuarios de ordenadornPasar periodos prolongados delante de un ordenador puede provocar diversos problemas de salud, como fatiga visual, dolor musculoesquelético y reducción de la actividad física...",
"enlaces_adjuntos": [
{
"url": "https://www.aao.org/eye-health/tips-prevention/computer-usage",
"text": null,
"position": 1
},
{
"url": "https://uhs.princeton.edu/health-resources/ergonomics-computer-use",
"text": null,
"position": 2
}
],
"citas": [
{
"url": "https://www.ramsayhealth.co.uk/blog/lifestyle/five-healthy-tips-for-working-at-a-computer",
"title": null,
"description": "Ramsay Health Care",
"icon": "https://...icon-url...",
"domain": "https://www.ramsayhealth.co.uk",
"cited": false
},
{
"url": "https://my.clevelandclinic.org/health/diseases/24802-computer-vision-syndrome",
"title": null,
"description": "Clínica Cleveland",
"icon": "https://...icon-url...",
"domain": "https://my.clevelandclinic.org",
"cited": false
}
],
"country": "IN",
"answer_text_markdown": "Consejos de salud para usuarios de ordenador...",
"timestamp": "2026-08-07T05:02:56.887Z",
"input": {
"url": "https://google.com/aimode",
"prompt": "consejos de salud para usuarios de ordenador",
"country": "IN"
}
}Así de sencillo y eficaz
Este sencillo flujo de trabajo de API se integra perfectamente en cualquier aplicación o proyecto. El generador de solicitudes de API de Bright Data también proporciona ejemplos de código en varios lenguajes de programación para facilitar la implementación.
Conclusión
Hemos explorado 2 enfoques: una solución “hágalo usted mismo” utilizando Python y Playwright, y la API llave en mano Google AI Mode Scraper de Bright Data.
En el panorama de las búsquedas, que evoluciona rápidamente y en el que los algoritmos y las interfaces cambian con frecuencia, contar con una infraestructura de raspado sólida y bien mantenida tiene un valor incalculable. La API elimina la necesidad de actualizar constantemente la lógica de análisis sintáctico o de gestionar las restricciones de IP, lo que le permite centrarse por completo en analizar las ricas perspectivas generadas por la IA a partir de los resultados de búsqueda de Google y extraer el máximo valor de los datos.
A continuación
- Amplía tu recopilación de datos de Google. Puesto que ya estás trabajando con el modo de IA de Google, considera la posibilidad de explorar otras fuentes de datos de Google. También disponemos de una guía completa sobre Scraping Google AI Overviews para obtener una cobertura más amplia. Puedes acceder a funciones especializadas para Google Noticias, Mapas, Búsqueda, Tendencias, Opiniones, Hoteles, Vídeos y Vuelos.
- Prueba sin riesgo. Todos los productos principales incluyen opciones de prueba gratuitas, además igualamos los primeros depósitos hasta 500 $. Esto le da espacio para experimentar con las funciones ampliadas antes de comprometerse.
- Amplíe con soluciones integradas. A medida que crezcan sus necesidades, considere el servidor Web MCP, que conecta las aplicaciones AI directamente a los datos web sin necesidad de desarrollo personalizado para cada sitio. Comience ahora con un plan gratuito de 5.000 solicitudes mensuales.
- Infraestructura empresarial cuando esté preparado. Muchos equipos comienzan con proyectos individuales como el suyo y más tarde necesitan una infraestructura sólida para operaciones de mayor envergadura. La plataforma completa proporciona la infraestructura subyacente cuando esté listo para expandirse.
¿No está seguro del siguiente paso? Hable con nuestro equipo: se lo trazaremos.






