

En esta guía, verá lo siguiente:
- Qué son los sitios con mucho JavaScript.
- Desafíos y métodos para rasparlos mediante la renderización del navegador.
- Cómo funciona la interceptación de llamadas AJAX y sus limitaciones.
- La solución moderna para el scraping de sitios web con mucho JavaScript.
Sumerjámonos.
¿Qué es un sitio web con mucho JavaScript?
En el ámbito del web scraping, un sitio es “JavaScript-heavy” cuando los datos a recoger no están en el documento HTML inicial devuelto por el servidor. En su lugar, el contenido real se obtiene dinámicamente y se representa mediante JavaScript en el navegador del usuario.
La forma en que un sitio utiliza JavaScript afecta directamente al modo en que debe proceder para extraer sus datos. Normalmente, los sitios basados en JavaScript siguen estos tres patrones principales:
- Aplicaciones de una sola página (SPA): Una SPA es una página web que se basa en JavaScript para actualizar secciones específicas con nuevos contenidos del servidor. En otras palabras, toda la aplicación web es una única página web que no se recarga con cada interacción del usuario.
- Interacciones dirigidas por el usuario: El contenido aparece sólo después de realizar acciones específicas. Algunos ejemplos son los botones “cargar más” y la paginación dinámica.
- Datos asíncronos: Muchos sitios cargan primero un diseño de página básico para ganar velocidad, y luego hacen llamadas en segundo plano utilizando AJAX para obtener datos. Este mecanismo es habitual para actualizaciones en directo, como la actualización de las cotizaciones bursátiles sin recargar la página.
Rastreo de sitios con mucho JavaScript mediante renderización completa del navegador
Las herramientas de automatización de navegadores permiten escribir scripts que inician y controlan los navegadores web. Esto les permite ejecutar el JavaScript necesario para renderizar completamente una página. A continuación, puede utilizar la selección de elementos HTML y las API de extracción de datos que proporcionan estas herramientas para extraer los datos que necesita.
Este es el enfoque fundamental para el scraping de sitios con mucho JavaScript, y aquí lo presentaremos con las siguientes secciones:
- Cómo funcionan las herramientas de automatización.
- Qué son los modos “sin cabeza” y “con cabeza”.
- Retos y soluciones con este enfoque.
- Las herramientas de automatización de navegadores más utilizadas.
Cómo funcionan las herramientas de automatización
Las herramientas de automatización del navegador utilizan un protocolo (por ejemplo, CDP o BiDi) para enviar órdenes directamente al navegador. En términos más sencillos, exponen una API completa para emitir comandos como “navega a esta URL”, “encuentra este elemento” y “haz clic en este botón”.
El navegador ejecuta esos comandos en la página, ejecutando cualquier JavaScript necesario para las interacciones descritas en su script de scraping. La herramienta de automatización del navegador también puede acceder al DOM(Document Object Model) renderizado. Ahí es donde puede encontrar los datos que va a raspar.
Navegadores “Headless” frente a “Headful
Cuando automatizas un navegador, tienes que decidir cómo debe ejecutarse. Normalmente, se elige entre dos modos:
- De cabeza: El navegador se inicia con su interfaz gráfica completa, igual que cuando lo abre un usuario humano. Puedes ver la ventana del navegador en tu pantalla y observar cómo tu script hace clic, teclea y navega en tiempo real. Esto es útil para confirmar visualmente que su script funciona como se espera. También puede hacer que tu automatización se parezca más a la actividad de un usuario real para los sistemas anti-bot. Por otro lado, ejecutar un navegador con una interfaz gráfica de usuario consume muchos recursos (todos sabemos lo hambrientos de memoria que pueden llegar a ser los navegadores), lo que ralentiza tu web scraping.
- Sin cabeza: El navegador se ejecuta en segundo plano sin interfaz visible. Utiliza menos recursos del sistema y es mucho más rápido. Este es el estándar para los scrapers de producción, especialmente cuando se ejecutan cientos de instancias paralelas en un servidor. En el lado negativo, si no se configura con cuidado, un navegador sin interfaz gráfica puede parecer sospechoso. Descubre los mejores navegadores sin interfaz del mercado.
Retos y soluciones de la renderización en navegador
Automatizar un navegador es sólo el primer paso cuando se trata de sitios web con JavaScript. Al raspar tales sitios, inevitablemente se enfrentará a dos categorías principales de desafíos, incluyendo:
- Navegación compleja: Los scripts de scraping deben ser algo más que simples seguidores de comandos. Hay que programarlos para que gestionen todo el recorrido del usuario. Esto significa escribir código para el scraping de flujos de navegación complejos, como esperar a que se cargue el nuevo contenido y gestionar el desplazamiento infinito. El scraping de sitios con mucho JavaScript incluye la gestión de formularios multipágina, menús desplegables y mucho más.
- Evadir lossistemas anti-bot: Cuando no se aplica correctamente, la automatización del navegador es una bandera roja que los sistemas anti-bot pueden detectar. Para tener éxito en un escenario de scraping con herramientas de automatización del navegador, su scraper debe parecer humano de alguna manera abordando desafíos como:
- Huella digital del navegador: Los anti-bots analizan cientos de puntos de datos del navegador del cliente para crear una firma única. Esto incluye su cadena User-Agent, resolución de pantalla, fuentes instaladas, capacidades de renderizado WebGL y más. Claramente, una configuración de automatización por defecto es fácilmente identificable. Establecer un User-Agent sin encabezado es un gran consejo. También puedes necesitar herramientas especializadas como undetected-chromedriver, que modifica varias opciones del navegador para que parezca el navegador de un usuario normal.
- Análisis del comportamiento: Los anti-bots también observan cómo interactúa el scraper con la página. Un script que pulsa un botón 5 milisegundos después de cargar una página obviamente no es humano. Si el comportamiento se marca como robótico, el sistema de defensa puede prohibirlo.
- CAPTCHAs: Los CAP TCHAs suelen ser el último obstáculo para los métodos de scraping que se basan en la automatización del navegador. Esto se debe a que los scripts de automatización estándar no pueden resolverlos de forma autónoma. Para superarlo, es necesario integrar servicios de resolución de CAPTCHA.
Para más información, consulte nuestra guía sobre el scraping de sitios dinámicos.
Los mejores marcos de automatización de navegadores
Los tres marcos dominantes para la automatización de navegadores son:
- Playwright: Es un framework moderno de Microsoft. Está diseñado desde cero para manejar las complejidades de los sitios modernos. Esto lo convierte en la mejor opción para nuevos proyectos de scraping. Está disponible en JavaScript, Python, C# y Java, con soporte de lenguajes adicionales proporcionados por la comunidad. Esto hace que el web scraping con Playwright sea una buena opción para la mayoría de los desarrolladores.
- Selenium: Es el titán de código abierto de la automatización web. Su mayor fortaleza reside en su versatilidad. En particular, es compatible con casi todos los lenguajes de programación y navegadores, y cuenta con un ecosistema amplio y maduro. Esta es la razón por la que Selenium se utiliza en gran medida como herramienta de automatización de navegadores para scraping.
- Puppeteer: Es una librería desarrollada por Google que proporciona control granular sobre Chrome y navegadores basados en Chromium a través del CDP(Chrome DevTools Protocol). Ahora también es compatible con Firefox. Con esta librería, puedes aparecer como un usuario normal simulando el comportamiento del usuario en un navegador controlado. Esto hace que Puppeteer sea ampliamente utilizado para el web scraping.
Vea cómo se comparan estas soluciones (y otras) en nuestro repositorio sobre las mejores herramientas de automatización del navegador.
Método alternativo: Replicación de llamadas AJAX
En lugar de asumir el coste de renderizar toda una página web visual en el navegador, puedes adoptar un enfoque detectivesco. Lo que puedes hacer en su lugar es identificar las llamadas directas a la API que el front-end del sitio web hace a su back-end y replicarlas tú mismo.
Estas llamadas a la API suelen devolver los datos sin procesar que el sitio renderiza posteriormente en la página, por lo que puede dirigirse a ellos directamente. Esta técnica se basa en la imitación de llamadas AJAX y se conoce comúnmente como API web scraping.
Veamos cómo funciona.
Funcionamiento de la replicación de llamadas AJAX
La replicación AJAX es una técnica práctica de scraping. La idea central es evitar la renderización de toda la página imitando las peticiones de red (normalmente llamadas AJAX) que la aplicación web realiza para obtener datos de su backend.
A grandes rasgos, esto implica dos pasos principales:
- Fisgonear: Abra las herramientas de desarrollo de su navegador (normalmente la pestaña “Red” con el filtro “Fetch/XHR” activado) e interactúe con el sitio web. Observa qué llamadas a la API se realizan en segundo plano cuando se cargan nuevos datos. Por ejemplo, durante el desplazamiento infinito o al hacer clic en los botones “Cargar más”.
- Reproducir: Una vez identificada la solicitud API correcta, anote su URL, método HTTP (GET, POST, etc.), cabeceras y carga útil (si la hubiera). A continuación, reproduzca esta solicitud en su script de scraping utilizando un cliente HTTP como Requests en Python.
Esos puntos finales de API suelen devolver datos en un formato estructurado, casi siempre JSON. Esto es una gran ventaja, ya que puedes acceder a los datos JSON sin la molestia adicional de analizar HTML.
Por ejemplo, eche un vistazo a la llamada a la API realizada por un sitio que utiliza el desplazamiento infinito para cargar más datos:
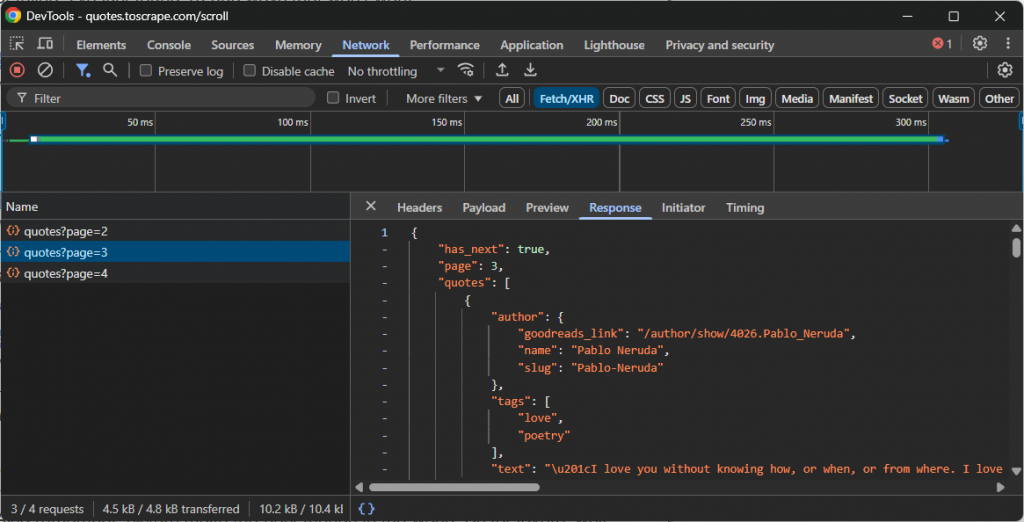
En este caso, puede escribir un sencillo script de scraping que reproduzca la anterior llamada a la API de desplazamiento infinito y, a continuación, acceda a los datos.
Principales retos a la hora de interceptar llamadas AJAX
Cuando funciona, este método es rápido, eficaz y sencillo. Aun así, plantea algunos problemas:
- Cargas útiles ofuscadas: La API podría requerir cargas útiles cifradas o no devolver JSON limpio y legible. Podría tratarse de una cadena cifrada que una función JavaScript específica sabe descifrar. Se trata de una medida anti-scraping que requiere ingeniería inversa.
- Puntos finales y cabeceras dinámicos: Los puntos finales de la API y la forma de llamarlos (por ejemplo, estableciendo las cabeceras adecuadas, añadiendo la carga útil correcta, etc.) cambian con el tiempo. El principal reto de esta solución es que cualquier evolución en la API romperá el raspador. Esto requiere el mantenimiento del código para restaurar la funcionalidad, lo que es un problema común con la mayoría (pero no todos, como vamos a ver) de los enfoques de raspado web.
- Huella digital TLS: Los anti-bots más avanzados analizan el “TLS handshake”, que es la firma digital del programa. Pueden discriminar fácilmente entre una petición de Chrome y una de un script estándar de Python. Para evitarlo, se necesitan herramientas especializadas que puedan suplantar la firma TLS de un navegador.
Un enfoque moderno para el scraping de sitios con mucho JavaScript: Agentes de raspado de navegadores basados en IA
Los métodos descritos hasta ahora siguen enfrentándose a grandes retos. Una solución más moderna para el scraping de sitios con mucho JavaScript requiere un cambio de paradigma. La idea es pasar de escribir comandos imperativos a definir objetivos declarativos utilizando agentes de navegador impulsados por IA.
Un navegador agente es un navegador integrado con un LLM que comprende el contenido, el contexto y el diseño visual de la página. Esto cambia radicalmente la forma de abordar el raspado web, especialmente en sitios con mucho JavaScript.
Estos sitios suelen requerir complejas interacciones del usuario para cargar los datos que usted desea. Tradicionalmente, usted tendría que inyectar lógica para replicar esas interacciones en sus scripts. Este enfoque es intrínsecamente frágil y requiere mucho mantenimiento. El problema es que cada vez que cambia el flujo del usuario, es necesario actualizar manualmente la lógica de automatización.
Gracias a los agentes de navegación basados en IA, puede evitar todo eso. Un simple aviso descriptivo puede impulsar una automatización eficaz que se adapta incluso cuando cambia la interfaz de usuario o el flujo del sitio. Esta flexibilidad es una gran ventaja y abre la puerta a muchas otras posibilidades de automatización, razón por la cual la IA agéntica está ganando terreno rápidamente.
Ahora bien, no importa lo potente que sea tu biblioteca de agentes de navegador de IA, tu lógica de scraping sigue dependiendo de los navegadores normales. Esto significa que sigue siendo vulnerable a problemas como la huella digital del navegador y los CAPTCHA. El escalado de estas soluciones también resulta difícil debido a los límites de velocidad y las prohibiciones de IP.
La verdadera solución es una plataforma de scraping basada en la nube y preparada para la IA que se integre con cualquier biblioteca de agentes y esté diseñada para evitar que se bloquee. Esto es exactamente lo que ofrece Agent Browser de Bright Data.
Agent Browser le permite ejecutar flujos de trabajo basados en IA en navegadores remotos que nunca se bloquean. Es infinitamente escalable, admite los modos headless y headful y funciona con la red proxy más fiable del mundo.
Conclusión
En este artículo, aprendiste qué son los sitios web con JavaScript pesado, y los desafíos y soluciones comunes para raspar datos de ellos. Cada implementación descrita viene con sus limitaciones, pero la que brilla es usar un navegador agente.
Como ya se ha comentado, el Navegador de Agentes de Bright Data permite resolver todos los problemas habituales de scraping a la vez que se integra con las bibliotecas de IA agéntica más populares.
Si utiliza agentes de raspado de IA avanzados, necesita herramientas fiables para recuperar, validar y transformar el contenido web. Para todas estas capacidades y más, explore la infraestructura de IA de Bright Data.
Cree una cuenta de Bright Data y pruebe todos nuestros productos y servicios para el desarrollo de agentes de IA.





