

Al final de este artículo, comprenderá cómo:
- Utilizar el servicio API Scraper en modo IA de Google de Bright Data
- Aprovechar Skyvern para la automatización de tareas
- Utilizar el servicio API de Bright Data con Skyvern para automatizar tareas web.
- Combinar la automatización y las fuentes de datos para crear un asistente de comercio electrónico.
- Recuperar automáticamente los detalles de los productos del carrito
¡Empecemos!
Aprovecha el servicio API de Bright Data
La base de la automatización del navegador es la capacidad de sortear retos como CAPTCHA, bloqueos de IP y carga dinámica de la web. Aquí es donde Bright Data se vuelve esencial.
Con el Scraper web de Bright Data, que admite más de 120 dominios web, la automatización del navegador es más eficiente y fiable. Gestiona los retos habituales del scraping web, como las prohibiciones de IP, los CAPTCHA, las cookies y otras formas de detección de bots.
Para empezar, regístrese para obtener una prueba gratuita y obtenga su clave API y dataset_id para el dominio que desea rastrear. Una vez que los tenga, estará listo para comenzar.
A continuación se indican los pasos para recuperar datos actualizados de cualquier dominio, como BBC News:
- Cree una cuenta de Bright Data si aún no lo ha hecho. Hay una prueba gratuita disponible.
- Vaya a la página Web Scrapers. En Web Scrapers Library, explore las plantillas de Scraper disponibles.
- Busque el dominio de destino, como BBC News, y selecciónelo.
- En la lista de scrapers de BBC News, seleccione BBC News — collect by URL. Este scraper le permite recuperar datos sin iniciar sesión en el dominio.
- Elija la opción Scraper API. El No-Code Scraper ayuda a recuperar Conjuntos de datos sin código.
- Haga clic en API Request Builder y copie su
clave API,la URL del conjunto de datos de la BBCyel dataset_id. - La
clave APIyel dataset_idson necesarios para habilitar las capacidades de automatización en su flujo de trabajo. Le permiten acceder directamente a las capacidades de Bright Data mientras programa.
¿Qué es Skyvern?
Skyvern es una herramienta de automatización de navegadores basada en IA que utiliza la IA para automatizar tareas dentro de los navegadores web. Combina el aprendizaje automático, el procesamiento del lenguaje natural y la visión artificial para gestionar acciones complejas del navegador.
Skyvern se diferencia de las herramientas de automatización tradicionales, como Selenium y Playwright, en los siguientes aspectos:
- Adaptabilidad a los cambios de la interfaz de usuario: las capacidades de autorreparación permiten a Skyvern adaptarse dinámicamente a los cambios de la interfaz de usuario sin romper los scripts.
- Complejidad del flujo de trabajo: capaz de gestionar flujos de trabajo de varios pasos con razonamiento de IA a través de una sola indicación.
- Reconocimiento visual: utiliza la visión artificial para comprender e interactuar visualmente con los elementos de la interfaz de usuario.
Con estas capacidades, puede utilizar Skyvern para iniciar sesión en sitios de reservas, completar formularios o añadir artículos a carritos de la compra. Cuando se integra con las capacidades de Scraping web de Bright Data, Skyvern puede proporcionar un potente marco para abordar diversas necesidades de automatización web.
Flujo de trabajo de automatización
Por ejemplo, si desea comprar una pieza de automóvil en una tienda online, es posible que desee comparar las opciones disponibles y añadir una automáticamente a su carrito. El flujo de trabajo sería el siguiente:
- La API de Scraper en modo IA de Bright Data obtiene la descripción y los detalles del producto, como el número de pieza, del fabricante especificado.
- Usted revisa el resultado y realiza su selección. Bright Data proporciona una recuperación de datos web rápida y fiable.
- Skyvern utiliza los detalles recuperados de Bright Data para acceder a finditparts.com. A continuación, navega por el sitio, añade los productos seleccionados al carrito y muestra los detalles del carrito y la URL del carrito.
- Continúe directamente con el proceso de pago.
Requisitos
- Conocimientos básicos de programación en Python. Descargue Python aquí
- Una cuenta activa de Bright Data. Regístrese aquí y obtenga su clave API en el correo electrónico de bienvenida
- Conocimientos básicos de JSON y API REST
Configuración del proyecto
Paso 1: Configurar Bright Data
Obtenga su clave API de Bright Data, el ID del conjunto de datos y la URL del modo Google IA siguiendo los mismos pasos descritos en Aprovechar el robusto servicio API de Bright Data para su caso de uso.
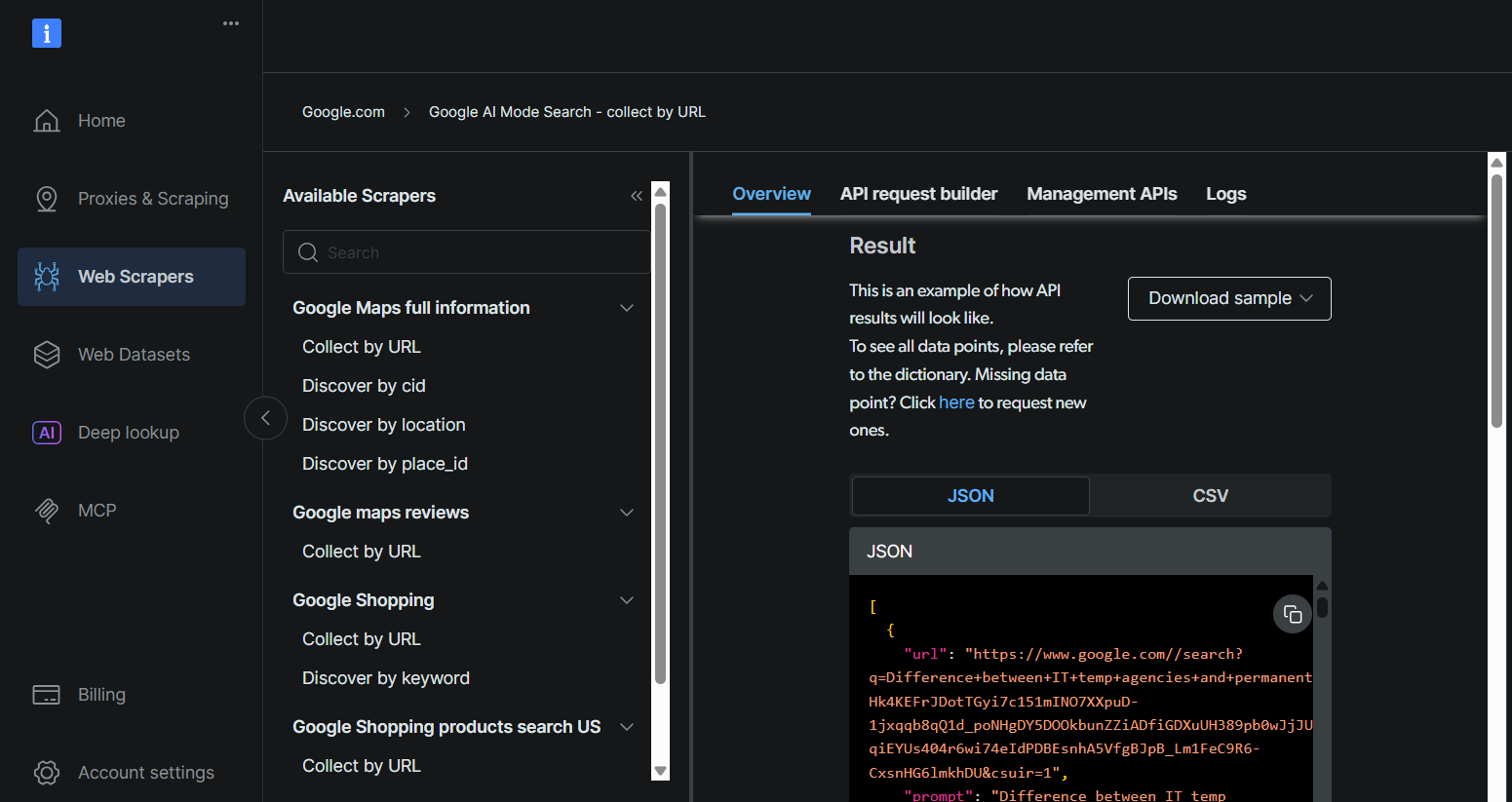
Paso 2: Regístrese en Skyvern Cloud
- Vaya a https://app.skyvern.com/ y regístrese para recibir 5 USD de crédito gratuito.
- Pida al agente de Skyvern que ejecute una tarea para verla en acción. Por ejemplo: navegue a la página de inicio de Hacker News y recupere las tres publicaciones principales.
- Compruebe el historial para seguir el progreso de la tarea. El estado «Completado» indica que la tarea se ha finalizado correctamente.
- Una vez completada, haga clic en la tarea en el historial para ver el resultado, los parámetros y detalles adicionales sobre la tarea.
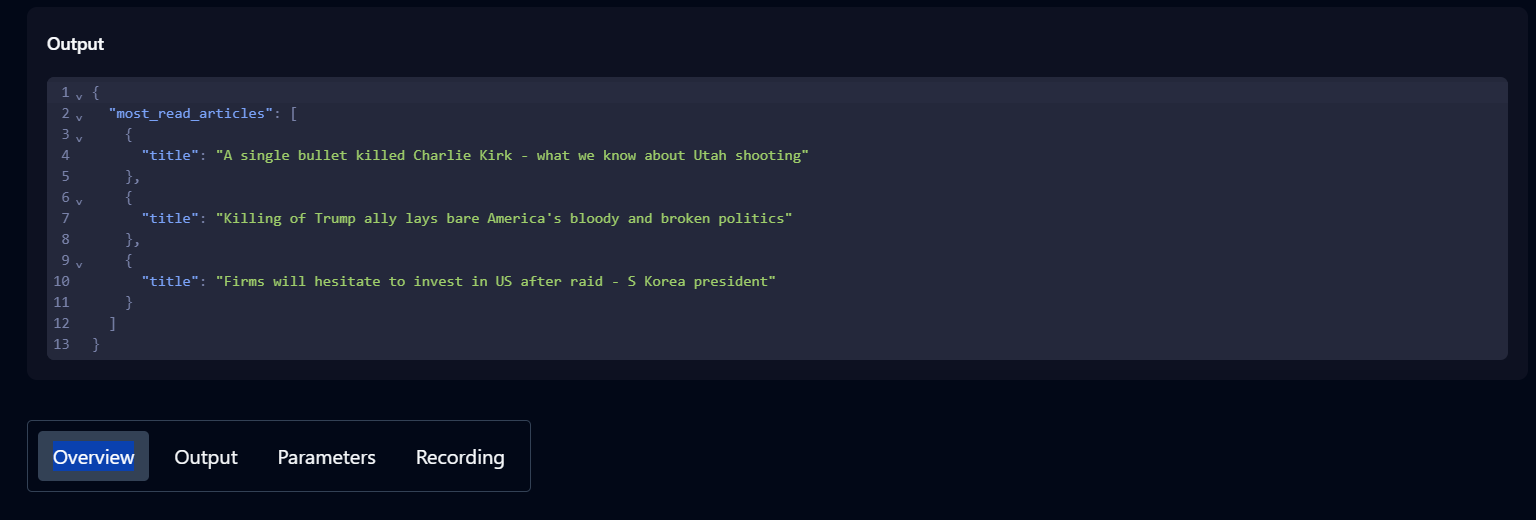
Ahora que Skyvern está configurado, puede comenzar a escribir su script de código.
Paso 3: Instalar Skyvern en su máquina
3.1 Crear un entorno virtual
En la carpeta del proyecto que desees, crea un entorno virtual con Python:
python -m venv .venv
Activa el entorno.
.venvScriptsactivate
3.2 Instalar Skyvern en cualquier dispositivo con
pip install skyvern
Si tienes problemas con la instalación, puedes utilizar el terminal Ubuntu en Windows. Consulta esta publicación para saber cómo configurar el terminal Ubuntu.
Una vez que el terminal esté en funcionamiento, navega hasta el directorio deseado y ejecuta:
pip install uvCrea un entorno virtual con:
uv venv venvA continuación, instala Skyvern con:
uv pip install skyvern3.3 Inicio rápido de Skyvern
Cuando la instalación haya finalizado, ejecute:
skyvern quickstart- Cuando se le pregunte «¿Desea ejecutar Skyvern localmente o en la nube?», escriba «cloud».
- Cuando se le solicite «Enter Skyvern baseURL» (Introduzca la URL base de Skyvern), pulse Intro.
- Escriba «n» en todas las indicaciones de instalación, excepto en la indicación MCP, donde debe escribir «y».
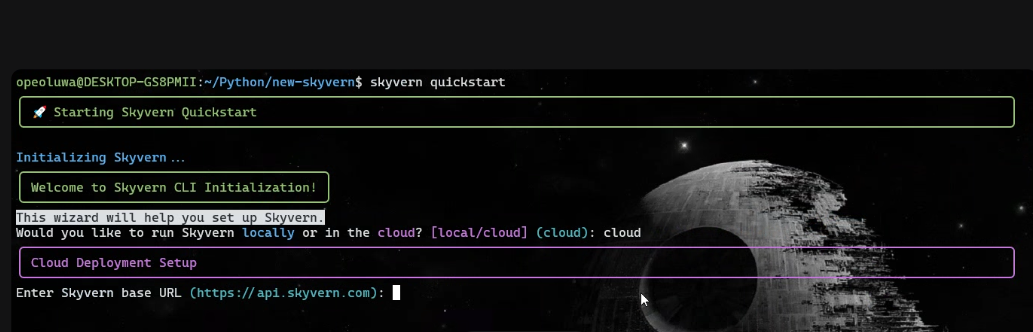
Después de la configuración, ejecute:
skyvern initCree un script de Python llamado app.py.
Paso 4: Recuperar los detalles del producto con Bright Data
4.1 Recupere el número de pieza con Bright Data utilizando este código en app.py:
import asyncio
import requests
import time
import json
def trigger_scraping_job(api_key, data):
"""
Activa una tarea de Conjunto de datos de Bright Data con una lista de diccionarios que contienen url, prompt, country.
Devuelve el snapshot_id si se realiza correctamente.
"""
endpoint = "https://api.brightdata.com/conjuntos_de_datos/v3/trigger"
params = {
"dataset_id": "gd_mcswdt6z2elth3zqr2", # Su ID de conjunto de datos
"include_errors": "true",
}
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(endpoint, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json().get("snapshot_id")
print(f"¡Solicitud realizada con éxito! ID de instantánea: {snapshot_id}")
return snapshot_id
else:
print(f"¡Solicitud fallida! Estado: {response.status_code}")
print(response.text)
return None
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
"""
Sondea el punto final de instantáneas de Bright Data hasta que los datos estén listos.
Guarda la respuesta JSON en un archivo de salida.
"""
snapshot_url = f"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Sondeando instantánea para ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("La instantánea está lista. Descargando...")
snapshot_data = response.json()
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Instantánea guardada en {output_file}")
return
elif response.status_code == 202:
print(f"La instantánea aún no está lista. Reintentando en {polling_timeout} segundos...")
time.sleep(tiempo_de_espera)
else:
print(f"¡Solicitud fallida! Estado: {código_de_estado_respuesta}")
print(respuesta.texto)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "TU_CLAVE_API_BRIGHT_DATA" # Tu clave API
# Coincide exactamente con la estructura de datos JSON de curl
data = [
{
"url": "https://google.com/aimode",
"prompt": "buscar el número de pieza de un sello de rueda en finditparts.com cuyo fabricante sea SKF",
"country": ""
}
]
snapshot_id = trigger_scraping_job(BRIGHT_DATA_API_KEY, data)
if snapshot_id:
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "product.json")La indicación es: «buscar el número de pieza de un sello de rueda en finditparts.com cuyo fabricante sea SKF».
Esto creará un archivo product.json que contiene descripciones de productos y números de pieza del fabricante SKF.
{
"url": "https://www.finditparts.com/products/16775486/skf-45093xt?srcid=CHL01SCL010-Npla-Dmdt-Gusa-Svbr-Mmuu-K16775486-L22",
"title": "www.finditparts.com",
"description": "SKF 45093XT Wheel Seal | FinditParts",
"icon": "https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.finditparts.com&client=AIM&size=128&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"domain": "https://www.finditparts.com",
"cited": true
},
{
"url": "https://www.finditparts.com/products/193780/cr-slash-skf-14115?srcid=CHL01SCL010-Npla-Dmdt-Gusa-Svbr-Mmuu-K193780-L1464",
"title": "www.finditparts.com",
"description": "SKF 14115 Wheel Seal | FinditParts",
"icon": "https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.finditparts.com&client=AIM&size=128&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"domain": "https://www.finditparts.com",
"cited": true
},
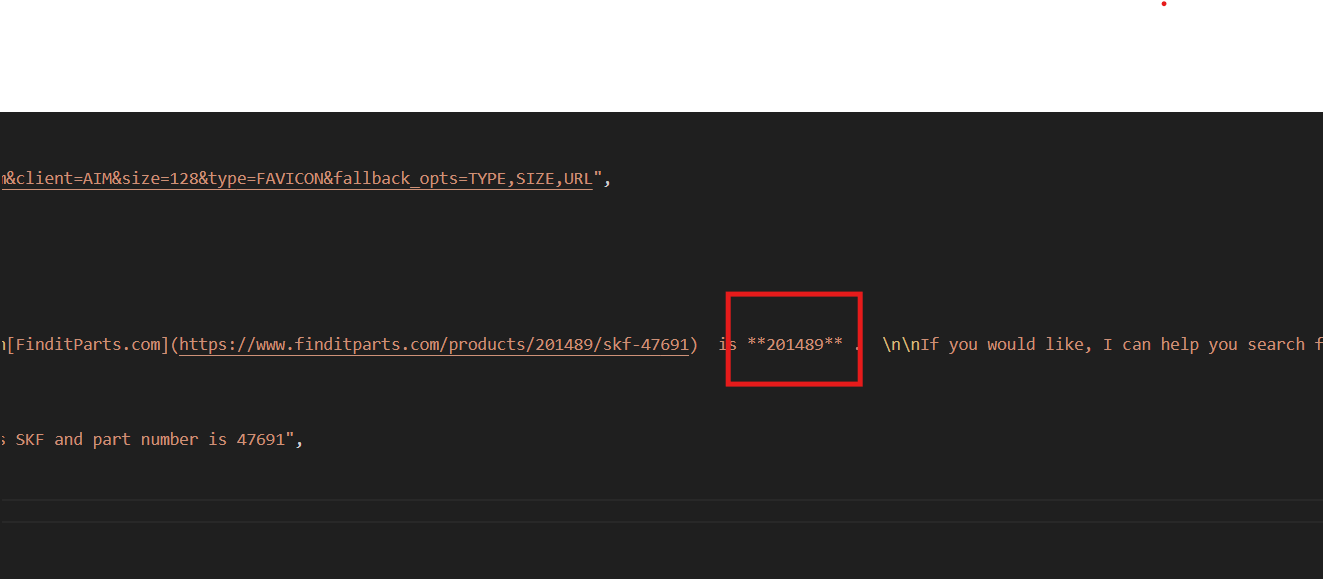
{A continuación, elija su número de pieza preferido (que se encuentra en la descripción) y vuelva a ejecutar el código Bright Data con este mensaje: «Busque el ID del producto para el sello de rueda SKF con el número de pieza 47691».
# Haga coincidir exactamente la estructura de datos JSON de curl.
data = [
{
"url": "https://google.com/aimode",
"prompt": "Buscar el ID del producto para el sello de rueda SKF con número de pieza 47691",
"country": ""
}
]Skyvern necesita el ID del producto para añadir detalles al carrito en finditparts.com (un sitio web de comercio electrónico de piezas de vehículos).
Este proceso generará un archivo product.json con el ID de producto deseado.
Paso 5: Solicitar tareas a Skyvern
En primer lugar, vaya a https://app.skyvern.com/tasks/create/finditparts. Esta URL es un acceso directo para crear tareas en Skyvern.
Haga clic en Configuración avanzada en la sección Contenido base y actualice el ID del producto y solicite su caso de uso.
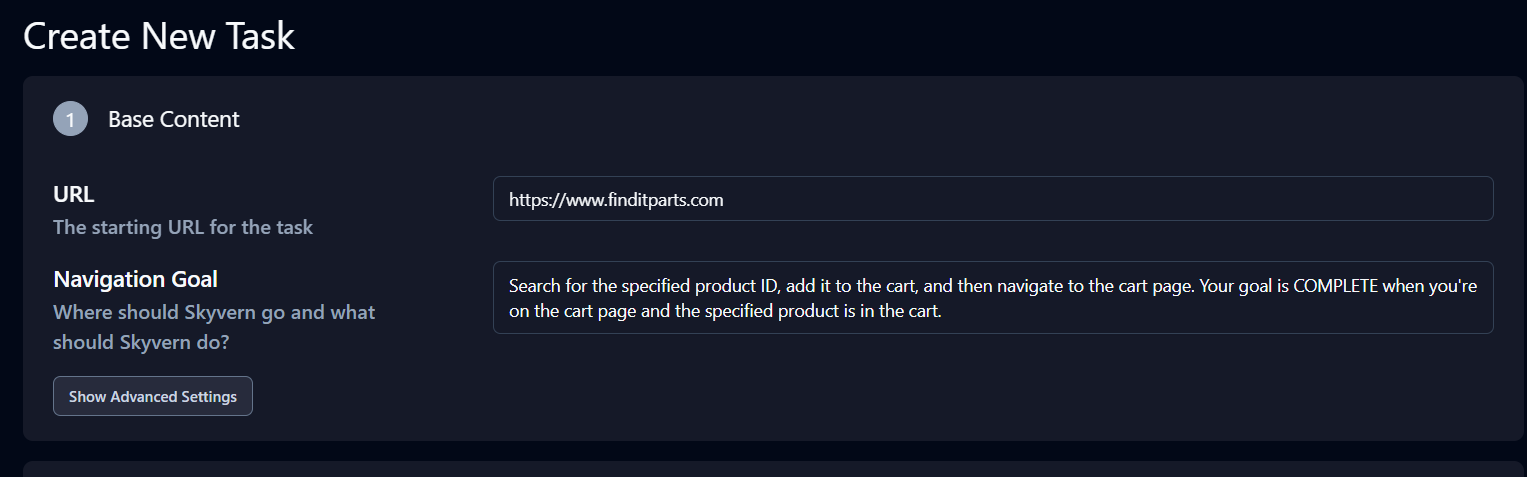
La solicitud es: «Busque el ID de producto especificado, añádalo al carrito y, a continuación, vaya a la página del carrito. Su objetivo se habrá COMPLETADO cuando esté en la página del carrito y el producto especificado se encuentre en el carrito».
La sección Extracción, debajo de Configuración avanzada, también es importante. Modifique el objetivo de extracción de datos a: «Extraiga la URL de la página del carrito y toda la información sobre la cantidad de productos de la página del carrito».
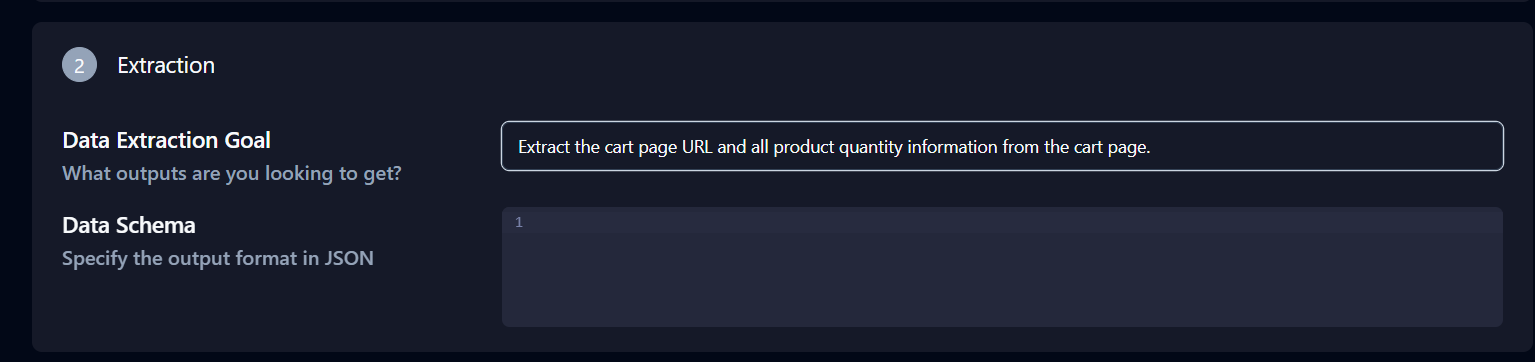
Haga clic en Copiar comando API en la parte inferior de la página, péguelo en su terminal y pulse Intro.
Esto creará un task_id en su terminal y una instancia de la tarea en su Skyvern Cloud. Puede comprobar su estado en Historial para ver si está en cola, en ejecución o completada.

El estado «Completada » significa que la tarea ha finalizado. Ahora puede ver los detalles del carrito y la URL del producto devueltos por Skyvern.
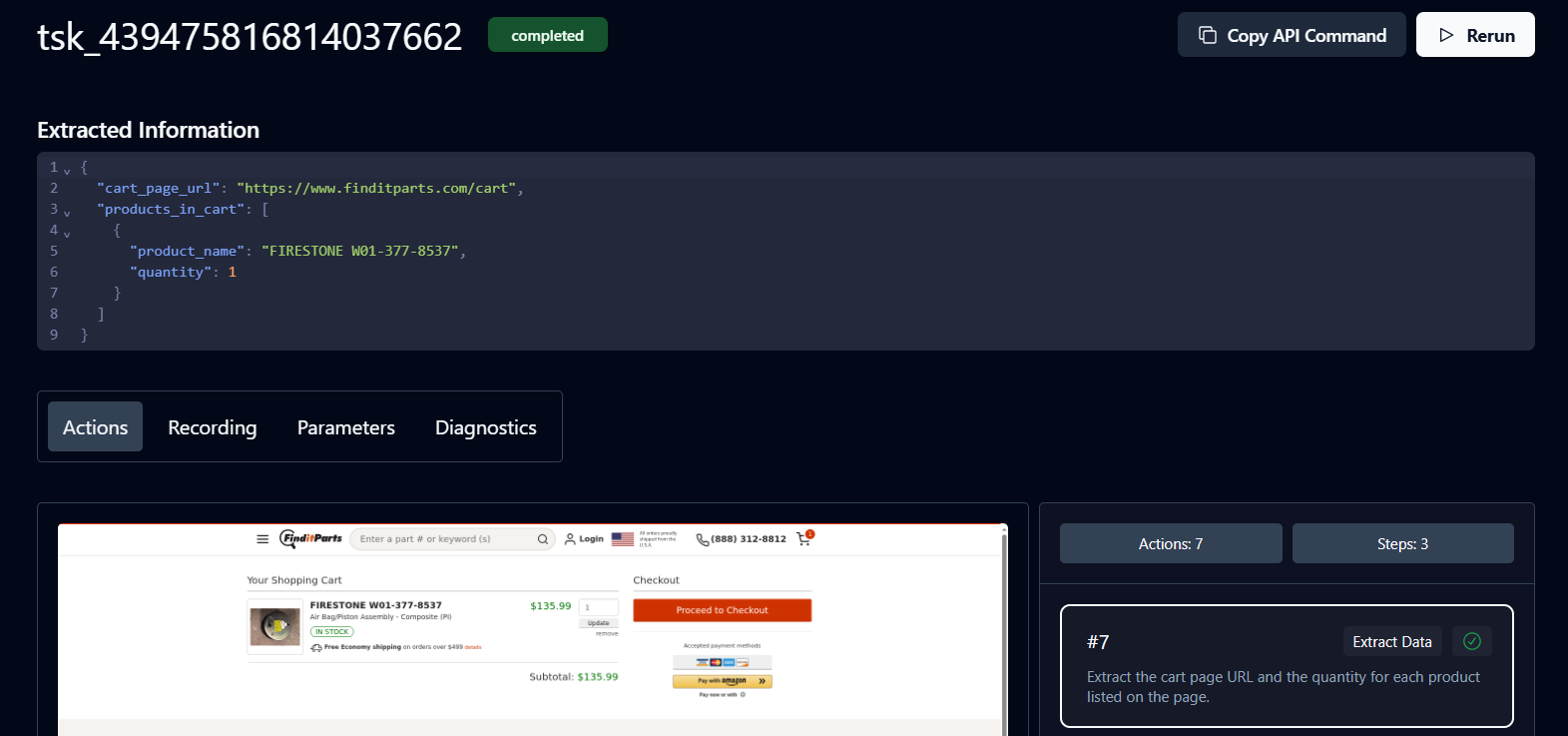
Enhorabuena. Su flujo de trabajo ha finalizado. Haga clic en la URL para proceder con el pago.
Bright Data elimina la necesidad de buscar manualmente productos en línea, ya que le ofrece las opciones directamente en su equipo. Esto le permite seleccionar el mejor producto y automatizar el proceso de compra con Skyvern.
Próximos pasos
Puede ampliar el flujo de trabajo para incluir la adición de varios productos al carrito para su pago y generar un resumen de procesamiento del lenguaje natural (NLP) del total de productos. También puede implementar el flujo de trabajo en la nube para su supervisión continua. Por último, puede integrarlo con Google Calendar para realizar un seguimiento de los descuentos.
Conclusión
En este tutorial, ha aprendido a combinar la API Scraper de Bright Data con Skyvern para automatizar el proceso de búsqueda y compra de productos en línea. Además de la API Scraper, Bright Data ofrece otras herramientas que pueden potenciar sus agentes de IA, como Conjuntos de datos listos para usar adaptados al comercio electrónico, las redes sociales y mucho más, así como el servidor Web MCP para la automatización avanzada de múltiples pasos y el acceso a más de 40 herramientas especializadas. En conjunto, estos productos facilitan la creación de flujos de trabajo impulsados por IA que pueden recopilar, analizar y actuar sobre los datos web de manera eficiente.
Empiece a explorar la suite completa de Bright Data para mejorar sus proyectos de automatización de IA hoy mismo.





