

En este artículo, aprenderás:
- Si los datos sintéticos son realmente el futuro del entrenamiento de IA y ML.
- Qué son los datos web del mundo real, sus tipos principales y cómo recopilarlos a escala.
- Qué son los datos sintéticos, cómo pueden categorizarse y cómo se generan con éxito.
- El impacto de los datos sintéticos vs reales en términos de costo, privacidad, robustez y calidad de distribución.
- Cómo la elección de datos afecta el pipeline de entrenamiento de IA y el rendimiento del modelo.
- Por qué un enfoque híbrido que combine ambos tipos de datos suele ser la estrategia más eficaz.
- Los pros y contras de cada enfoque.
¡Comencemos.
¿Son los Datos Sintéticos el Futuro de la IA/ML, o los Datos Web Siguen Siendo Relevantes?
Las leyes de escala de la IA muestran que el rendimiento tiende a mejorar a medida que los modelos se entrenan con más parámetros, más cómputo y, fundamentalmente, más datos. En otras palabras, los modelos más grandes requieren conjuntos de datos exponencialmente mayores para mantener las mejoras de rendimiento.
Históricamente, los datos web reales han sido la base del entrenamiento moderno de IA, pero los datos web de alta calidad son finitos. Elon Musk afirmó famosamente que las empresas de IA se han quedado sin datos de entrenamiento y han “agotado” la suma del conocimiento humano disponible para el entrenamiento de modelos.
Además, los datos web están cada vez más duplicados y son costosos de recopilar, limpiar y validar legalmente. Esto también destaca la importancia de seleccionar proveedores de conjuntos de datos web que ofrezcan conjuntos de datos optimizados para IA, actualizados regularmente y conformes con la privacidad.
Estas presiones están acelerando el interés en fuentes de datos alternativas, particularmente los datos sintéticos. Según Gartner, para 2030 se espera que los datos sintéticos superen a los datos del mundo real en el entrenamiento de modelos de IA. La firma atribuye este cambio a requisitos de privacidad más estrictos, escasez de datos del mundo real y organizaciones que buscan alternativas de menor costo que reduzcan los riesgos legales y de cumplimiento.
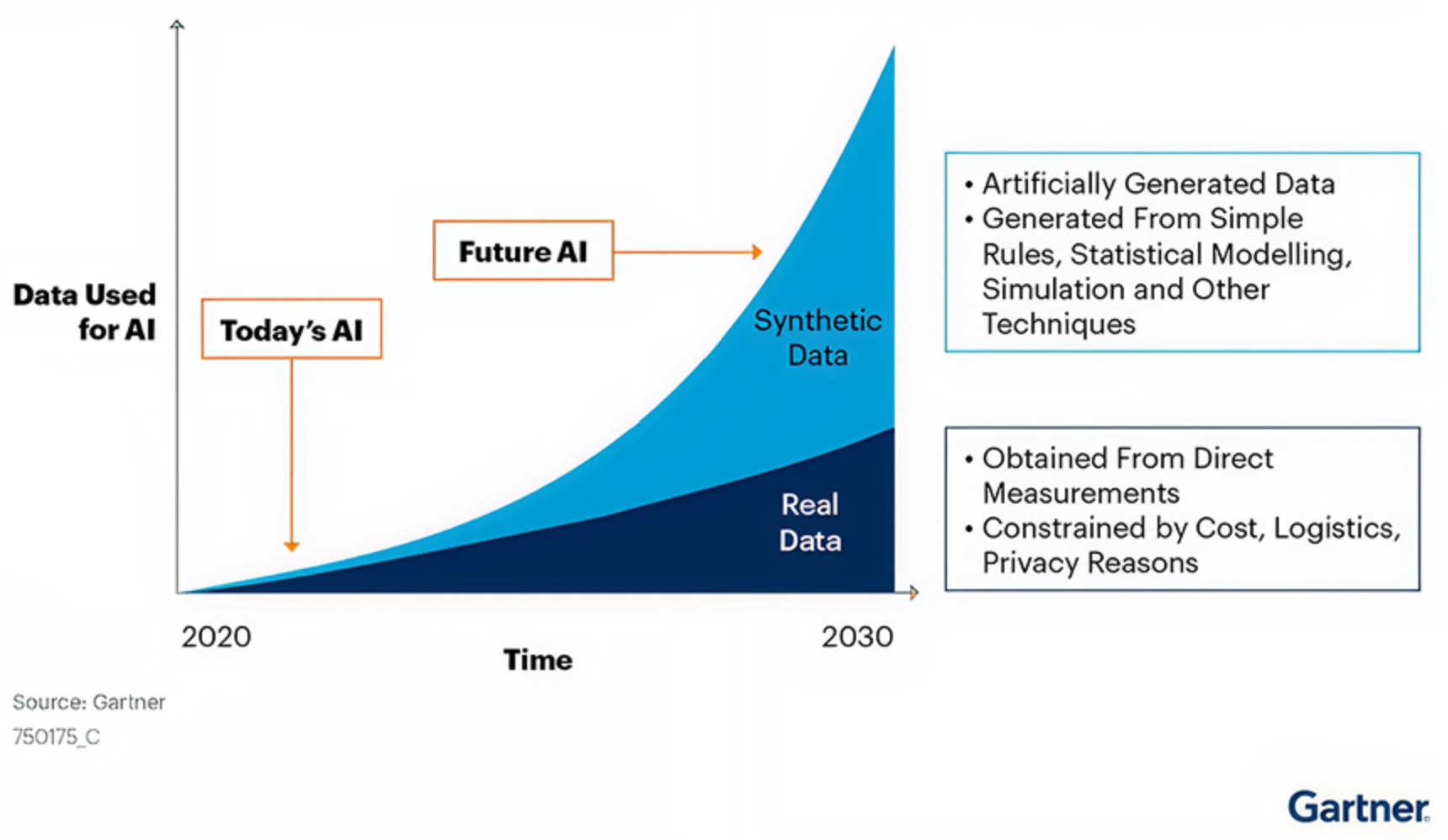
Al mismo tiempo, esta predicción debe considerarse como una estimación y no como una inevitabilidad. Internet continúa generando enormes volúmenes de contenido, con aproximadamente 402 millones de terabytes de datos web creados cada día.
Para ponerlo en perspectiva, GPT-3 fue entrenado con aproximadamente 45 terabytes de texto sin procesar antes del filtrado. Esta comparación sugiere que los datos generados por humanos a escala web siguen siendo vastos y muy relevantes para el entrenamiento de IA.
Como resultado, es poco probable que el futuro del entrenamiento de IA dependa exclusivamente de datos sintéticos. En cambio, muchos expertos en aprendizaje automático esperan un enfoque híbrido, un tema que examinaremos más adelante en este artículo.
Datos Sintéticos vs Datos Web Reales: Comparando los Dos Paradigmas de Datos
En los siguientes capítulos, aprenderás qué son los datos sintéticos y los datos web reales, qué ofrecen y cómo se comparan en múltiples aspectos del entrenamiento de modelos de IA. Comenzaremos con los datos web reales, ya que son más naturales de comprender, y luego pasaremos a los datos sintéticos.
Para una comparación inmediata de alto nivel, echa un vistazo a la tabla de datos sintéticos vs datos web reales a continuación:
| Datos Web Reales | Datos Sintéticos | |
|---|---|---|
| Definición | Datos recopilados de fuentes web reales | Datos generados artificialmente que imitan distribuciones del mundo real usando modelos o reglas |
| Ejemplos | Páginas web, foros, artículos de noticias, páginas de productos, PDFs, etc. | Texto generado por LLM, imágenes GAN, entornos de robótica simulados, conjuntos de datos basados en reglas, etc. |
| Objetivo principal | Capturar la complejidad del mundo real y el comportamiento natural | Aumentar la escala, cobertura y controlabilidad |
| Tipos de datos | No estructurados (texto, imágenes), semiestructurados (JSON, XML) | Estructurados, semiestructurados, no estructurados (texto, imagen, audio, vídeo) |
| Cómo se obtiene | Principalmente scraping web | Generación por LLM, GANs, VAEs, sistemas basados en reglas, motores de simulación |
| Riesgo de privacidad | Mayor (PII, se requiere cumplimiento) | Bajo (sin datos de usuarios reales si se genera correctamente) |
| Calidad de datos | Ruidosos, inconsistentes, pero auténticos | Limpios, estructurados, pero pueden incluir artefactos o alucinaciones |
| Distribución | Distribución natural del mundo real | Controlada, pero puede introducir sesgo sintético o desplazamiento |
| Robustez | Fuerte generalización a entradas del mundo real | Fuerte para escenarios específicos, generalización más débil |
| Cobertura de cola larga | Presente de forma natural pero dispersa | Puede generarse explícitamente y sobremuestrearse |
| Riesgo de sesgo | Refleja el sesgo del mundo real | Puede amplificar o introducir nuevos sesgos |
| Rol típico en el pipeline | Preentrenamiento, ajuste fino, evaluación | Preentrenamiento, aumento, generación de casos extremos |
| Riesgos | Escasez de datos, restricciones de cumplimiento, ruido | Brecha sintético-real, colapso del modelo, patrones alucinados |
¡Ahora es momento de adentrarse en los dos paradigmas de datos que dan forma al entrenamiento moderno de IA!
Explorando el Mundo de los Datos Web Reales
Aquí cubriremos todo lo que necesitas saber sobre los datos web reales para el entrenamiento de modelos de IA.
¿Qué Son los Datos Web?
Los datos web son información recopilada de páginas web y otras fuentes web públicas, principalmente mediante scraping web. Incluyen contenido no estructurado como texto, imágenes, código, metadatos y documentos (p. ej., PDFs), así como datos semiestructurados como JSON y XML.
Tipos de Datos Web
Existen muchas categorías posibles de datos web. Sin embargo, a alto nivel, especialmente en el contexto de la IA, es útil distinguir entre dos tipos principales:
- Datos web históricos: Generalmente recopilados mediante pipelines de scraping web, luego limpiados, enriquecidos, deduplicados y agregados en conjuntos de datos estructurados en formatos como CSV, JSON y Parquet. Estos conjuntos de datos se usan para el preentrenamiento y el ajuste fino de modelos.
- Datos web en vivo: Recuperados en tiempo real desde páginas web mediante scraping o APIs. Reflejan la información más actualizada disponible en internet. Esto los hace especialmente útiles para fundamentar las respuestas de la IA y para los sistemas RAG, donde la actualidad y la precisión factual son fundamentales.
Juntas, estas dos formas de datos web cumplen roles complementarios en los sistemas de IA modernos.
Cómo Obtener Datos Web
Para obtener datos web para el entrenamiento de IA/ML, necesitas un pipeline de scraping web escalable. Construirlo internamente requiere una experiencia técnica significativa.
Implica manejar una amplia gama de desafíos anti-scraping como el bloqueo de IPs, la resolución de CAPTCHA y los limitadores de velocidad. Además, requiere sólidas capacidades de ingeniería de datos para la limpieza, deduplicación y normalización. Por ello, las empresas prefieren recurrir a plataformas de datos web dedicadas, como Bright Data.
Bright Data ofrece un ecosistema integral para la recopilación y entrega de datos web. Lo que lo distingue es su red de proxies residenciales de más de 400M en 195 países, que admite la recopilación de datos web altamente escalable y concurrente. Esta infraestructura de nivel empresarial también cumple con el GDPR y el CCPA, junto con otros estándares de privacidad y seguridad.
La oferta de Bright Data para datos web incluye:
- Marketplace de datos web: Una colección de más de 350 conjuntos de datos listos para usar que cubren más de 250 dominios (incluyendo Reddit, Amazon, LinkedIn, Yahoo Finance y muchos otros). Estos conjuntos de datos abarcan más de 17 petabytes de datos web y están optimizados para el entrenamiento de ML y aplicaciones de IA. Se entregan en múltiples formatos, como JSON, CSV y Parquet, mediante entrega en la nube y otros métodos de distribución.
- Productos de scraping web: Un conjunto de soluciones basadas en API para la extracción de datos web en vivo:
– API Web Unlocker: Supera bloqueos y CAPTCHAs para garantizar el acceso a datos en cualquier página web.
– API SERP: Entrega resultados estructurados y en tiempo real de motores de búsqueda como Google, Bing, Yandex y otros.
– API Discover: Devuelve un conjunto clasificado y en vivo de URLs de la web pública, listas para su procesamiento posterior.
– API Crawl: Realiza rastreo escalable de sitios web y extracción estructurada de datos.
– APIs Scraper: Cubren más de 120 sitios web para la extracción directa de datos estructurados de dominios populares.
Bright Data también ofrece servicios gestionados para la adquisición de datos llave en mano. Estos permiten a las organizaciones centrarse en el desarrollo de modelos en lugar de en la ingeniería de datos.
Adentrándose en el Mundo de los Datos Sintéticos
En este capítulo, explorarás el uso de datos sintéticos para el entrenamiento de modelos de IA/ML.
¿Qué Son los Datos Sintéticos?
Los datos sintéticos son información generada artificialmente que replica los patrones estadísticos y las características de los datos del mundo real. En lugar de ser recopilados a partir de eventos reales, se producen de forma artificial.
Tipos de Datos Sintéticos
Los datos sintéticos pueden categorizarse:
- Por composición y nivel de privacidad:
– Completamente sintéticos: Generados íntegramente desde cero usando modelos de aprendizaje automático entrenados con datos reales. Como no contienen puntos de datos originales, ofrecen el mayor nivel de protección de la privacidad.
– Parcialmente sintéticos: Toman un conjunto de datos real existente y reemplazan solo los atributos sensibles (como nombres, direcciones o números de seguridad social) con valores artificiales. Esto preserva tendencias específicas de los datos mientras anonimiza la PII.
– Híbridos: Combinan registros reales anonimizados con registros generados artificialmente. Se usan comúnmente para “sobremuestrear” o enriquecer conjuntos de datos creando artificialmente eventos raros (p. ej., añadiendo registros sintéticos de fraude a un conjunto de datos bancarios).
- Por estructura de datos:
– Datos estructurados: Datos cuantitativos altamente organizados presentados en formatos tabulares.
– Datos no estructurados: Formatos de datos cualitativos o con gran cantidad de contenido multimedia. Incluye texto sintético, imágenes generadas artificialmente, vídeo y audio.
Cómo Producir Datos Sintéticos
A alto nivel, los datos sintéticos pueden generarse mediante tres enfoques predominantes:
- Generados completamente por IA: Creados usando modelos como GANs (Redes Generativas Adversariales), VAEs (Autoencoders Variacionales) o LLMs. Estos sistemas aprenden la distribución subyacente de conjuntos de datos reales y luego generan muestras completamente nuevas que se asemejan a los datos originales sin copiarlos directamente.
- Generación basada en reglas: Donde los datos se producen usando reglas predefinidas escritas por humanos, restricciones o lógica de negocio. Esto garantiza consistencia estricta, corrección estructural y comportamiento controlado, lo que lo hace útil para sistemas que requieren salidas predecibles.
- Datos simulados o ficticios: Generados mediante simulaciones físicas o de comportamiento. Se usan comúnmente en entornos como la conducción autónoma o la robótica, donde los gemelos digitales y los motores de física crean escenarios realistas de “qué pasaría si”.
Impacto de los Datos Sintéticos vs Datos Web Reales en el Entrenamiento de Modelos de IA/ML
Comparemos ahora varios aspectos para comprender las consecuencias del uso de datos sintéticos vs datos web reales para el entrenamiento de IA.
Distribución de Datos y Realismo
Los datos web se aproximan estrechamente a una distribución natural de datos. Capturan la complejidad inherente del lenguaje y el comportamiento humano tal como aparece en el mundo real. Esto aporta beneficios importantes, incluyendo correlaciones naturales entre características, casos extremos auténticos, estilos lingüísticos diversos y ruido realista como errores humanos, ambigüedad e inconsistencias.
Sin embargo, los datos web del mundo real también son inherentemente desordenados. A menudo están desequilibrados, duplicados, son difíciles de curar a escala y pueden contener contenido de baja calidad o spam que requiere un filtrado exhaustivo.
En contraste, los datos sintéticos representan una distribución controlada. Están diseñados y generados intencionalmente, lo que permite a los profesionales dar forma a las propiedades del conjunto de datos de manera precisa. Esto permite distribuciones de clases equilibradas, cobertura dirigida de escenarios específicos, generación de eventos raros y aprendizaje curricular estructurado.
Al mismo tiempo, los datos sintéticos introducen riesgos importantes, incluyendo el desplazamiento de distribución, artefactos poco realistas, colapso de modos y sobre-regularización cuando el generador está demasiado restringido.
Importante: Un concepto central del aprendizaje automático en este sentido es la brecha sintético-real, similar al problema sim-a-real en robótica. Los modelos entrenados en gran medida con datos sintéticos pueden tener un rendimiento inferior con entradas realistas porque la distribución generada no coincide completamente con la realidad.
Cobertura de Cola Larga
Los datos web reales incluyen naturalmente una amplia gama de conocimientos. Esto incluye hechos oscuros, eventos raros y casos extremos inesperados que emergen orgánicamente de la actividad humana. Sin embargo, estos ejemplos de cola larga son inherentemente escasos. Por definición, los eventos raros aparecen con poca frecuencia, lo que dificulta que los modelos aprendan patrones robustos a partir de ellos durante el entrenamiento.
Por otro lado, puedes usar datos sintéticos para generar explícitamente escenarios raros o subrepresentados. De esta manera, puedes abordar brechas específicas en un conjunto de datos y mejorar la cobertura donde los datos reales son insuficientes. Los ejemplos incluyen errores de código raros e idiomas con pocos recursos.
Una ventaja importante del uso de datos sintéticos para la cobertura de cola larga es la capacidad de sobremuestrear eventos raros. Esto puede ayudar a reducir el desequilibrio de clases y mejorar el rendimiento del modelo en casos infrecuentes pero importantes. Sin embargo, si los escenarios raros están artificialmente sobrerrepresentados, las prioridades aprendidas por el modelo pueden distorsionarse.
Por ejemplo, si los casos de exploits de ciberseguridad están muy sobremuestreados en datos sintéticos, el modelo puede comenzar a sobreestimar su probabilidad en entornos del mundo real. Por ello, una calibración cuidadosa es fundamental para garantizar que la generación sintética de cola larga mejore la cobertura sin introducir distribuciones poco realistas.
Consideraciones de Costo y Privacidad
Como se mencionó anteriormente, las empresas raramente construyen su propia infraestructura de scraping web y conjuntos de datos. En cambio, dependen de proveedores de datos de terceros como Bright Data, que abstraen el rastreo, el desbloqueo, la limpieza y la entrega. Esto cambia fundamentalmente tanto la estructura de costos como las concesiones de privacidad en la adquisición de datos.
A continuación, se presenta una descripción simplificada del modelo de precios de Bright Data para la recopilación de datos web:
| Precio | Planes personalizados para empresas | Cumplimiento GDPR | Cumplimiento CCPA | Cumplimiento con regulaciones SEC | |
|---|---|---|---|---|---|
| Conjuntos de datos | Desde $0.001 hasta $0.0025 por registro | ✔️ | ✔️ | ✔️ | ✔️ |
| APIs de scraping web | $1-$1.5/1K resultados | ✔️ | ✔️ | ✔️ | ✔️ |
Bright Data también ofrece servicios de anotación de datos, ayudando a las organizaciones a reducir aún más la dependencia de la ingeniería de datos interna. Es importante destacar que sus datos están alineados con marcos de privacidad, lo que ayuda a reducir el riesgo legal y regulatorio.
Sin tales proveedores de datos web, tendrías que gestionar internamente el desarrollo de infraestructura, el mantenimiento continuo y la compleja gobernanza de PII, material protegido por derechos de autor y datos de comportamiento sensibles.
Con los datos sintéticos, los costos principales provienen del cómputo de inferencia y el acceso a modelos maestros o APIs. Desde una perspectiva de privacidad, los datos generados artificialmente ofrecen una ventaja inherente. Dado que se generan en lugar de recopilarse de personas reales, los datos sintéticos eliminan naturalmente la exposición a información de identificación personal.
Ahora bien, la elección correcta entre datos sintéticos y datos web reales depende de los requisitos de calidad, la escala, las restricciones de privacidad y el caso de uso objetivo. Dependiendo de estos factores, cualquiera de los enfoques puede ser más o menos rentable que el otro.
Factores de Calidad de los Datos
Los datos web generalmente proporcionan una supervisión débil. Los modelos aprenden de señales que ocurren naturalmente, como la predicción del siguiente token, metadatos y contenido generado por humanos. El problema es que los datos reales son ruidosos y pueden contener desinformación, contradicciones, spam, opiniones sesgadas y formato inconsistente.
Por el contrario, los datos sintéticos ofrecen mayor control sobre la calidad y la supervisión. Pueden proporcionar etiquetas perfectamente formateadas, salidas estructuradas, razonamiento paso a paso y ejemplos verificados automáticamente. Por ejemplo, los conjuntos de datos sintéticos pueden incluir respuestas matemáticamente verificadas o fragmentos de código validados mediante pruebas unitarias. Esto mejora la consistencia y facilita el entrenamiento dirigido.
El principal riesgo con los datos sintéticos es que su calidad está fundamentalmente limitada por la calidad del modelo generador, el algoritmo o el enfoque subyacente. Las alucinaciones generadas o los errores factuales pueden propagarse al conjunto de datos final, haciendo que los modelos aprendan patrones incorrectos con confianza. Del mismo modo, los sesgos ocultos presentes en los sistemas de generación también pueden ser heredados por los modelos posteriores. En el lado positivo, los datos sintéticos admiten una alineación más sólida y un ajuste de seguridad.
Generalización y Robustez
Una de las preguntas más importantes en el aprendizaje automático es qué tan bien generaliza un modelo a entradas no vistas. En otros términos, ¿qué fuente de datos conduce a una mejor robustez bajo el desplazamiento de distribución: los datos web del mundo real o los datos sintéticos?
Los datos web tienden a lograr una robustez sólida, ya que reflejan el comportamiento humano, el lenguaje y el ruido que ocurren de forma natural. Esto mejora el rendimiento en entradas fuera de distribución y mejora la transferencia de dominio, particularmente cuando los modelos se despliegan en entornos impredecibles.
En cambio, los datos sintéticos son más adecuados para la optimización dirigida. Permiten diseñar con precisión ejemplos de entrenamiento para habilidades específicas, casos extremos o escenarios raros.
Consideraciones Clave al Entrenar IA con Datos Sintéticos o Datos Web Reales
Ahora que conoces las diferencias entre los datos sintéticos y los datos web, estás listo para ver las implicaciones prácticas del uso de cada enfoque en el entrenamiento de modelos de IA.
Pipelines de Entrenamiento de Datos
Cuando se utilizan datos web, el pipeline generalmente sigue estos pasos:
- Rastreo: Recopilar datos sin procesar de sitios web usando sistemas de scraping a gran escala o bots de scraping web personalizados en múltiples dominios.
- Deduplicación: Eliminar contenido duplicado o casi duplicado para reducir la redundancia y mejorar la diversidad y eficiencia del conjunto de datos.
- Detección de idioma: Identificar el idioma de cada muestra y filtrar o segmentar el conjunto de datos según los requisitos de idioma objetivo.
- Puntuación de calidad: Evaluar y clasificar el contenido usando heurísticas o modelos para filtrar información de baja calidad o irrelevante.
- Filtrado de toxicidad: Detectar y eliminar contenido dañino, inseguro o inapropiado para garantizar la seguridad y el cumplimiento del entrenamiento.
- Eliminación de PII y descontaminación: Eliminar información de identificación personal y eliminar la contaminación de fuentes sensibles o no deseadas.
En cuanto a los pipelines de datos sintéticos, los pasos están más orientados a la generación:
- Generación de prompts: Diseñar prompts o plantillas que definan la estructura, tarea o escenario para la creación de datos sintéticos.
- Muestreo del modelo: Generar salidas candidatas usando modelos generativos como LLMs, GANs u otros sistemas.
- Verificación: Validar las salidas usando comprobaciones automatizadas, reglas o herramientas externas para garantizar la corrección y consistencia.
- Filtrado: Eliminar muestras de baja calidad, inconsistentes o alucinadas que no cumplen los estándares predefinidos.
- Puntuación de recompensa: Asignar puntuaciones de calidad o preferencia para clasificar y seleccionar los mejores ejemplos sintéticos.
- Refinamiento iterativo: Mejorar la calidad de los datos mediante ciclos repetidos de generación, filtrado y remuestreo para mejorar la robustez.
Como puedes ver, los pipelines de datos web reales se centran en limpiar entradas ruidosas del mundo real. En cambio, los pipelines sintéticos se orientan más al control y la validación de las salidas generadas. Por último, una vez producido el conjunto de datos de entrenamiento, puedes proceder con el entrenamiento del modelo de IA.
Comparación de Rendimiento
La pregunta final es si los datos sintéticos pueden superar a los datos web del mundo real.
Un reciente artículo sobre IA para Ingeniería de Requisitos (AI4RE) sugiere que los conjuntos de datos generados por LLM pueden ser una alternativa sólida cuando los datos reales son escasos o difíciles de acceder. Los resultados empíricos muestran que los modelos entrenados exclusivamente con datos sintéticos pueden superar a los entrenados únicamente con conjuntos de datos de autoría humana. En detalle, se observaron mejoras de hasta +37% en precisión y +30% en exhaustividad en comparación con las líneas base de solo datos reales.
Dicho esto, esta no es una conclusión binaria ni absoluta. La evidencia no sugiere que los datos sintéticos deban reemplazar completamente a los datos reales, sino que el mejor rendimiento a menudo se logra mediante un enfoque híbrido. ¡Aprende más al respecto!
Datos Sintéticos + Datos Web del Mundo Real: Por Qué un Enfoque Híbrido Funciona Mejor
El debate entre datos sintéticos y datos web del mundo real ya no se trata de elegir uno sobre el otro, sino de cómo combinarlos.
Evidencia reciente muestra que las configuraciones híbridas que combinan datos sintéticos y reales logran ganancias de hasta +85% en precisión y una duplicación de la exhaustividad en comparación con el uso exclusivo de datos web del mundo real.
Al mismo tiempo, múltiples estudios e informes de la industria destacan que mezclar ingenuamente muestras sintéticas y reales puede en realidad degradar el rendimiento debido a la falta de coincidencia en la distribución, la redundancia o la amplificación del sesgo. Esto deja claro que las ganancias de rendimiento dependen de un diseño cuidadoso del conjunto de datos en lugar de una simple acumulación de datos.
Una pregunta abierta clave es la proporción óptima entre datos sintéticos y reales. No existe una respuesta universal. Algunos profesionales adoptan una división 80/20 al estilo Pareto (principalmente datos reales con aumento sintético), mientras que otros prefieren mezclas más equilibradas como 60/40, dependiendo de la complejidad de la tarea, el riesgo del dominio y la disponibilidad de datos.
Del mismo modo, la ubicación de los datos sintéticos en el pipeline importa. La práctica de la industria guía una estrategia por etapas: preentrenamiento con mucho contenido sintético para cobertura, seguido de ajuste fino con datos reales para la fundamentación y la evaluación.
En última instancia, los pipelines híbridos funcionan mejor porque combinan fortalezas complementarias. Los datos sintéticos proporcionan escala y cobertura de casos extremos, mientras que los datos web reales garantizan fidelidad, realismo y evaluación confiable en entornos de producción.
Datos Web Reales vs Datos Sintéticos: Pros y Contras
Como sección de resumen, consulta las ventajas y desventajas de los dos paradigmas de datos.
Datos Web Reales
👍 Pros:
- Captura patrones y ruido auténticos del mundo real
- Sólido punto de referencia para evaluación y validación
- Reduce el riesgo de sesgo sintético o artefactos
👎 Contras:
- Costoso y tardado de recopilar y etiquetar
- Puede estar limitado por restricciones de privacidad y regulatorias
- Puede estar desequilibrado o incompleto
Datos Sintéticos
👍 Pros:
- Altamente escalable y rápido de generar
- Puede simular eventos raros y casos extremos
- Admite pipelines de entrenamiento que preservan la privacidad
👎 Contras:
- Riesgo de brecha de dominio vs datos del mundo real
- Requiere validación cuidadosa y control de calidad
- Puede carecer de diversidad en comparación con datos reales, lo que lleva al sobreajuste en artefactos sintéticos
Datos Web Reales + Datos Sintéticos
👍 Pros:
- Combina escala (sintética) con realismo (datos reales)
- A menudo logra el mejor rendimiento en la práctica
- Mayor robustez en casos extremos y casos normales
👎 Contras:
- Requiere un equilibrio y ajuste cuidadoso de las proporciones
- Riesgo de degradación del rendimiento si se mezclan incorrectamente
- Diseño y mantenimiento del pipeline más complejos
Conclusión
En este artículo sobre datos sintéticos vs datos web reales, aprendiste el impacto de usar datos del mundo real o generados artificialmente para el entrenamiento de modelos de IA/ML. Como siempre ocurre en estas situaciones, no hay un único ganador. El enfoque correcto depende de tu presupuesto específico, habilidades técnicas y objetivos de rendimiento.
Independientemente de la configuración, los datos web siguen desempeñando un papel central en el entrenamiento de modelos de IA, ya sea para el preentrenamiento o el ajuste fino final. Su amplia cobertura y su fundamentación en el mundo real lo hacen esencial. Sin embargo, algunas empresas prefieren optar por enfoques con mayor peso sintético. La razón principal es la complejidad de construir y mantener internamente pipelines de recuperación de datos web.
Aquí es donde Bright Data puede ayudar. Con una infraestructura de nivel empresarial, altamente escalable y conforme, proporciona:
- Conjuntos de datos web: Más de 350 conjuntos de datos listos para usar con miles de millones de registros, ya recopilados, curados y optimizados para casos de uso de entrenamiento de IA.
- Productos de scraping web: Soluciones basadas en API para acceder a datos web frescos de muchos sitios a escala.
Además, Bright Data ofrece servicios de anotación de datos. Proporciona soluciones de etiquetado escalables, precisas y personalizables para casos de uso de NLP, visión por computadora y reconocimiento de voz.
¡Descubre todas las soluciones de Bright Data para IA!
¡Crea una cuenta de Bright Data de forma gratuita y explora nuestras soluciones de datos web!





