
Si estás creando una aplicación de generación aumentada por recuperación (RAG), necesitas datos actualizados sobre tu tema, no un PDF estático de un tutorial. Pero extraer artículos reales implica barreras antibots y solicitudes bloqueadas. Incluso con los datos, aún tienes que fragmentar, incrustar, indexar y configurar la recuperación.
Este tutorial hace todo eso. Bright Data encuentra y extrae artículos sobre cualquier tema, Weaviate los almacena y los busca, y tú obtienes respuestas con citas en un solo script de Python.
En resumen
Convierte cualquier tema en una base de conocimientos en la que se puedan realizar búsquedas y obtener respuestas a preguntas, alimentada por datos web en tiempo real en lugar de datos de entrenamiento obsoletos.
- La API SERP de Bright Data encuentra las URL de artículos reales sobre tu tema; Web Unlocker los extrae (incluso de sitios protegidos contra bots).
- Weaviate vectoriza automáticamente fragmentos a través de Cohere, los indexa con búsqueda híbrida y genera respuestas citadas en una sola llamada a la API
- Ejecuta
python3 pipeline.py, introduce un tema y obtén respuestas RAG citadas en cuestión de minutos. - Código fuente completo en GitHub: clónalo y ejecútalo
Consigue tus claves API y pruébalo con tu propio tema.
Así es como se ve el resultado final:

Ejecuta el proceso en 3–5 minutos
Si ya tienes claves API, ejecuta el pipeline ahora:
# 1. Clona el repositorio (requiere Python 3.10+)
git clone https://github.com/triposat/weaviate-bright-data-rag.git
cd weaviate-bright-data-rag
# 2. Instala las dependencias
pip3 install -r requirements.txt
# 3. Crea tu archivo .env
cp .env.example .env
# Edita .env e introduce tus claves API (consulta «Obtener tus claves API» más abajo)
# 4. Ejecútalo
python3 pipeline.pyEl pipeline solicita un tema y detecta automáticamente tus zonas de Bright Data. Busca y extrae artículos reales. Los fragmenta y los almacena en Weaviate (vectorizados automáticamente a través de Cohere), ejecuta consultas de demostración y pasa a modo interactivo para que puedas realizar tus propias preguntas.
Consigue tus claves API (gratis para empezar)
Necesitas 3 claves API: 1 de cada servicio. Cohere y Weaviate no requieren tarjeta de crédito; Bright Data te ofrece crédito de prueba gratuito al registrarte.
1. Clave API de Bright Data
Crea una clave API y dos zonas:
- Regístrate en brightdata.com
- Ve a Configuración de la cuenta → Usuarios y claves API
- Crea una nueva clave API → cópiala → pégala como el valor
BRIGHT_DATA_API_TOKENen tu archivo.env
El pipeline también necesita 2 zonas: API SERP y Web Unlocker. Comprueba si ya las tienes en Proxies y scraping → Mis zonas. Si no las ves, créalas:
- Ve a Proxy y scraping → selecciona Mis zonas
- Selecciona Añadir → elige el tipo de zona API SERP → ponle cualquier nombre (por ejemplo,
serp) → guarda - Selecciona Añadir de nuevo → elige el tipo de zona API de Unlocker → ponle cualquier nombre (por ejemplo,
unlocker) → guarda
No es necesario copiar los nombres de las zonas ni las contraseñas. El proceso utiliza tu clave API para detectarlos automáticamente.
2. Clave API de Cohere (gratuita)
Cohere se encarga tanto de la integración como de la generación en este proceso:
- Ve a dashboard.cohere.com
- Regístrate con Google, GitHub o tu correo electrónico; no necesitas tarjeta de crédito
- Tu clave API de prueba aparece en el panel de control: cópiala
- El plan de prueba tiene un límite de uso, pero es generoso (la ejecución automatizada utiliza menos de 20 llamadas; cada pregunta interactiva añade 2 más)
3. Credenciales de Weaviate Cloud (gratis)
Crea un clúster de prueba gratuito para almacenar y consultar tus vectores:
- Ve a console.weaviate.cloud
- Regístrate con Google o GitHub
- Selecciona Crear clúster → elige Sandbox (Gratis) → elige una región → crea
- Espera unos 30 segundos y, a continuación, selecciona tu clúster → pestaña «Detalles»
- Copia el punto final REST (la URL de tu clúster) y la clave API
Nota: Los clústeres Sandbox caducan a los 14 días. Si tu clúster caduca, crea uno nuevo y actualiza la URL y la clave en tu archivo .env. Vuelve a ejecutar pipeline.py para volver a importar tus datos.
Una vez que tengas las 3 claves, vuelve a la sección «Ejecuta el pipeline en 3–5 minutos» y sigue los pasos de clonación/instalación.
Cómo funciona el pipeline de RAG de principio a fin
El pipeline consta de 4 pasos: recopilación de datos, procesamiento, almacenamiento de vectores y generación:
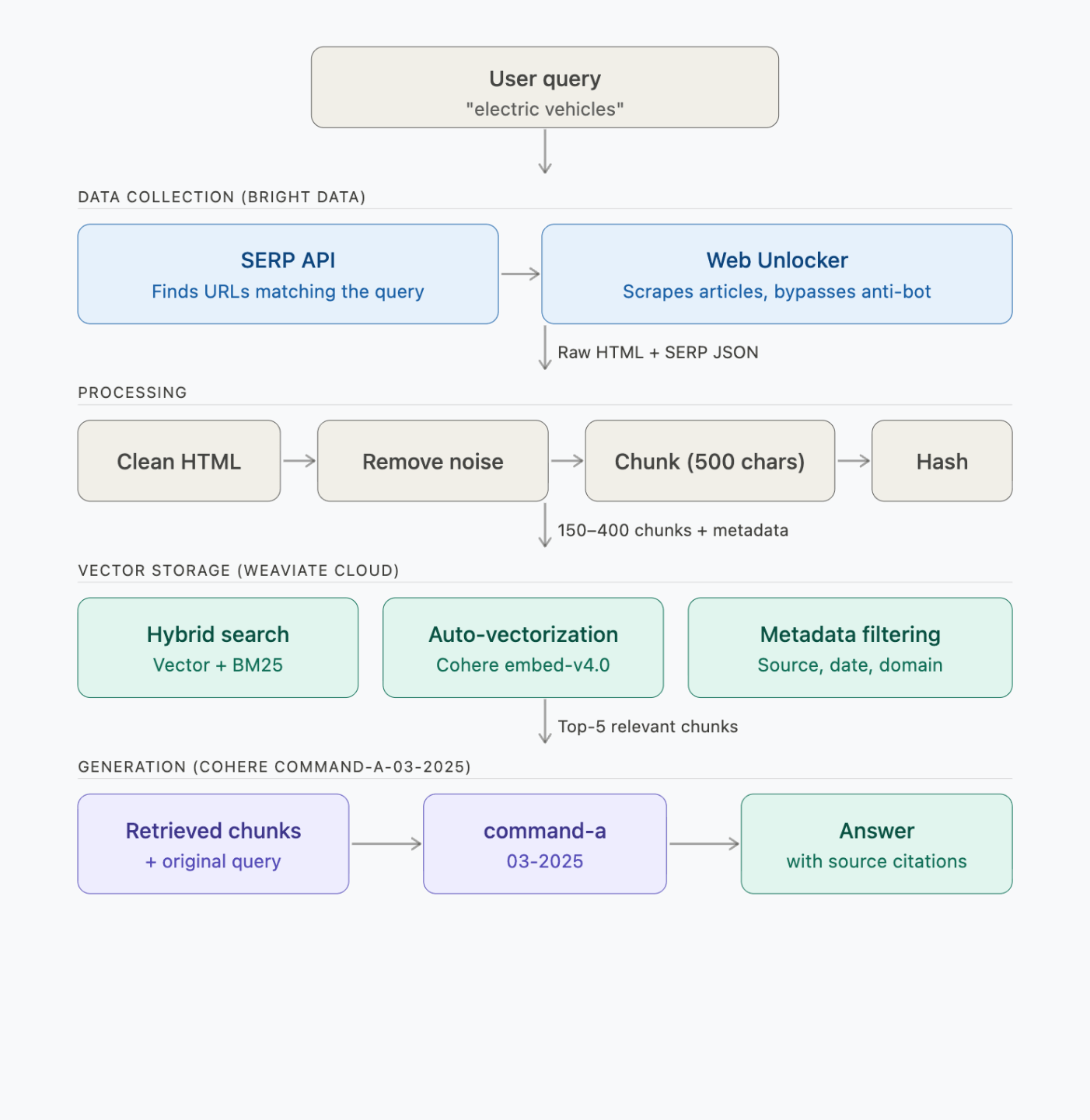
Cada paso realiza estas llamadas a la API:
| Paso | Qué se ejecuta | Tiempo | Llamadas a la API |
|---|---|---|---|
| 1. Buscar + extraer | Bright Data SERP + Web Unlocker | ~2–3 min | 2 SERP + 6 solicitudes de scraping |
| 2. Procesar + fragmentar | Local (BeautifulSoup + chunker) | <1 s | 0 |
| 3. Incrustar + almacenar | Weaviate → Cohere embed-v4.0 | ~30–60 s | ~150–400 incrustaciones (por lotes) |
| 4. Consulta (3 demostraciones) | Weaviate → Cohere command-a-03-2025 | ~5 s/consulta | 1 búsqueda + 1 generación por consulta |
Qué hace Bright Data en el proceso
Bright Data es una plataforma de datos web. En este proceso, desempeña dos funciones:
| Producto | Qué hace en este proceso |
|---|---|
| API SERP | Introduces un tema, la API SERP busca en Google y devuelve URL de artículos reales; no se necesitan URL codificadas |
| Web Unlocker | Recopila 6 artículos por tema, incluyendo sitios con protección antibots; de 200 000 a 1,8 millones de caracteres cada uno |
Este proceso utiliza la API SERP y Web Unlocker. Para conocer otros métodos de recopilación de datos, consulta la lista completa de productos de Bright Data.
¿Por qué utilizar Bright Data para RAG?
Estos son algunos puntos importantes a tener en cuenta al extraer datos para RAG:
- Extracción fiable. Web Unlocker gestiona automáticamente los reintentos, la rotación de IP y la huella digital del navegador, por lo que el proceso no se bloquea en páginas con protección antibots durante la ejecución.
- Salida preparada para LLM. La API Crawl devuelve Markdown limpio en lugar de HTML sin procesar, lo que elimina el preprocesamiento para las tuberías de incrustación (este tutorial utiliza Web Unlocker + BeautifulSoup, pero la API Crawl es una opción más rápida si no necesitas HTML sin procesar).
- Escalabilidad. Este tutorial extrae 6 artículos. En producción, es posible que necesites 6000. La infraestructura de IA de Bright Data admite el scraping simultáneo a esa escala sin que tengas que realizar cambios en el código.
- Cumplimiento normativo. Bright Data cumple con el GDPR y la CCPA, y requiere la verificación de identidad antes de conceder acceso completo a la red.
Qué hace Weaviate en el proceso
Weaviate es una base de datos vectorial de código abierto. Realiza la recuperación y la generación en una sola llamada a la API, por lo que no es necesario llamar al LLM por separado.
Aquí, Weaviate almacena los fragmentos extraídos y los vectoriza a través de Cohere. Cuando realizas una consulta, ejecuta una búsqueda híbrida y genera una respuesta a través de su API de búsqueda generativa.
| Característica | Cómo funciona en este proceso |
|---|---|
| Búsqueda híbrida | Combina vectores semánticos (70 %) con la coincidencia de palabras clave BM25 (30 %) mediante un parámetro alfa ajustable |
| Búsqueda generativa integrada | Recupera los 5 fragmentos principales y genera respuestas citadas en una sola llamada a generate.hybrid() |
| Vectorización automática | Weaviate llama automáticamente a la API de incrustación de Cohere durante la importación; no es necesario escribir ningún código de incrustación |
| Filtrado de metadatos | Almacena la URL de origen, el dominio, la marca de tiempo de la extracción y el tipo de contenido junto con cada fragmento |
Weaviate a gran escala
Weaviate también cuenta con características que este proceso no utiliza, pero que son importantes a gran escala:
- Licencia BSD de 3 cláusulas: puedes alojarlo tú mismo o crear una bifurcación si es necesario
- Múltiples opciones de implementación: Weaviate Cloud (entorno de pruebas gratuito), Dedicated Cloud, Kubernetes autohospedado
- Multitenencia: más de 50 000 usuarios por nodo para aplicaciones SaaS
- Cuantización rotacional: compresión vectorial 4x con un 98-99 % de recuperación
Crea el pipeline RAG paso a paso
Cada paso que se muestra a continuación presenta la lógica principal de pipeline.py. El código fuente completo se encuentra en GitHub.
Configuración del proyecto e importaciones
Empieza importando las dependencias y cargando las credenciales desde tu archivo .env:
import os
import sys
import time
import hashlib
import requests
import urllib3
from urllib.parse import quote
from datetime import datetime, timezone
from dotenv import load_dotenv
from bs4 import BeautifulSoup
import weaviate
from weaviate.classes.init import Auth
from weaviate.classes.config import Configure, Property, DataType
urllib3.disable_warnings()
load_dotenv()
# Cargar credenciales desde .env
COHERE_API_KEY = os.getenv("COHERE_API_KEY")
WEAVIATE_URL = os.getenv("WEAVIATE_URL")
WEAVIATE_API_KEY = os.getenv("WEAVIATE_API_KEY")
BD_API_TOKEN = os.getenv("BRIGHT_DATA_API_TOKEN")
COLLECTION_NAME = "WebResearch"
def clean_url(url):
"""Corregir artefactos nbsp en las URL (debido a problemas de codificación en algunos sitios web)."""
cleaned = url.replace("nbsp", "-")
while "--" in cleaned:
cleaned = cleaned.replace("--", "-")
return cleaned
def clean_generated_text(text):
"""Limpia el texto generado por el LLM para su visualización en la terminal."""
text = text.replace("**", "")
text = text.replace("nbsp", "-")
while "--" in text:
text = text.replace("--", "-")
return textAntes de hacer nada, el proceso comprueba que todas las credenciales necesarias estén configuradas en tu archivo .env:
def validate_env():
"""Comprueba que todas las variables de entorno necesarias estén configuradas."""
missing = []
if not BD_API_TOKEN:
missing.append("BRIGHT_DATA_API_TOKEN")
if not COHERE_API_KEY:
missing.append("COHERE_API_KEY")
if not WEAVIATE_URL:
missing.append("WEAVIATE_URL")
if not WEAVIATE_API_KEY:
missing.append("WEAVIATE_API_KEY")
if missing:
print("ERROR: Faltan variables de entorno en el archivo .env:")
for var in missing:
print(f" - {var}")
# ... imprime un ejemplo del formato .env ...
print("nConsulte la entrada del blog para saber cómo obtener cada clave (todas son gratuitas para empezar).")
sys.exit(1)No es necesario configurar nombres de zona ni contraseñas: el proceso las detecta automáticamente a partir de tu clave API:
def discover_bright_data_credentials():
"""
Detecta automáticamente las credenciales del Proxy de Bright Data a partir de la clave API.
Funciona con cualquier cuenta de Bright Data. No se necesitan valores fijos.
"""
headers = {"Authorization": f"Bearer {BD_API_TOKEN}"}
# 1. Obtener zonas activas
zones = requests.get(
"https://api.brightdata.com/zone/get_active_zones", headers=headers
).json()
# Seleccionar la primera zona de cada tipo (si hay varias, establecer el nombre explícitamente)
zone_names = {}
for z in zones:
if z["type"] not in zone_names:
zone_names[z["type"]] = z["name"]
# «unblocker» es el nombre de la API del producto Web Unlocker
unlocker_zone = zone_names.get("unblocker")
serp_zone = zone_names.get("serp")
# 2. Obtener las contraseñas de las zonas
unlocker_pwd = requests.get(
f"https://api.brightdata.com/zone/passwords?zone={unlocker_zone}",
headers=headers,
).json()["passwords"][0]
serp_pwd = requests.get(
f"https://api.brightdata.com/zone/passwords?zone={serp_zone}",
headers=headers,
).json()["passwords"][0]
# 3. Obtener el ID de cliente (el punto final de costes devuelve {customer_id: cost_data})
cost = requests.get(
f"https://api.brightdata.com/zona/cost?zona={unlocker_zone}",
headers=headers,
).json()
customer_id = list(cost.keys())[0]
return customer_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwdClona el repositorio, añade tu clave API y el pipeline se encarga del resto.
Paso 1: Busca y extrae artículos con Bright Data
El pipeline utiliza la API SERP para encontrar las URL de los artículos relacionados con tu tema y, a continuación, extrae cada uno de ellos mediante Web Unlocker:
def get_bd_proxy(customer_id, zone, password):
"""Crea la URL del Proxy de Bright Data."""
proxy = f"http://brd-customer-{customer_id}-zone-{zone}:{password}@brd.superproxy.io:33335"
return {"http": Proxy, "https": Proxy}
def search_serp(query, customer_id, zone, password, num=10):
"""Busca en Google a través de la API SERP de Bright Data y devuelve resultados orgánicos."""
proxies = get_bd_proxy(customer_id, zone, password)
# brd_json=1 indica a Bright Data que devuelva JSON estructurado en lugar de HTML sin procesar
search_url = f"https://www.google.com/search?q={quote(query)}&brd_json=1&num={num}"
try:
# verify=False omite la verificación SSL para el Proxy de BD.
# Para producción, instala en su lugar el certificado CA de Bright Data:
# https://docs.brightdata.com/general/account/ssl-certificate
response = requests.get(search_url, proxies=proxies, timeout=30, verify=False)
if response.status_code == 200:
data = response.json()
return [
{
"title": item.get("title", ""),
"url": item.get("link", ""),
"description": item.get("description", ""),
}
for item in data.get("organic", [])
]
except Exception as e:
print(f"Error SERP: {str(e)[:60]}", end=" ", flush=True)
return []search_serp() envía la consulta a través del Proxy SERP de Bright Data y devuelve JSON estructurado (títulos, URL, descripciones). El parámetro brd_json=1 indica a Bright Data que realice el Parseo del HTML de Google y lo convierta en JSON limpio.
A continuación, find_articles_for_topic() ejecuta 2 consultas SERP por tema y filtra los resultados, mientras que scrape_url() recupera cada artículo a través de Web Unlocker:
def find_articles_for_topic(topic, customer_id, serp_zone, serp_pwd):
"""Utiliza la API SERP de Bright Data para encontrar URL de artículos reales sobre un tema."""
search_queries = [
f"{topic} últimas noticias y tendencias",
f"{topic} guía de análisis en profundidad",
]
# Omite los dominios que devuelven contenido que no sea de artículos (vídeos, feeds, redes sociales)
skip_domains = {
"youtube.com", "twitter.com", "x.com", "facebook.com", "instagram.com",
"reddit.com", "linkedin.com", "wikipedia.org", "amazon.com", "tiktok.com",
}
skip_extensions = (".pdf", ".doc", ".ppt", ".xls", ".zip", ".mp4", ".mp3")
all_urls = []
seen_domains = set()
serp_docs = []
for query in search_queries:
results = search_serp(query, customer_id, serp_zone, serp_pwd, num=10)
if results:
# Guardar los títulos y descripciones de los SERP como un documento para que el LLM pueda
# consultar los resúmenes de los artículos incluso si falla el rastreo completo
serp_text = f"Resultados de búsqueda de Google para: {query}nn"
for r in results:
serp_text += f"Título: {r['title']}nURL: {r['url']}n"
serp_text += f"Resumen: {r['description']}nn"
serp_docs.append({
"url": f"https://google.com/search?q={quote(query)}",
"html": serp_text,
"scraped_at": datetime.now(timezone.utc).isoformat(),
"is_serp": True,
})
# Extraer las URL de los artículos (1 por dominio para mayor diversidad)
for r in results:
url = r.get("url", "")
if not url:
continue
domain = url.split("/")[2] if "://" in url else ""
base_domain = ".".join(domain.split(".")[-2:])
if base_domain in skip_domains:
continue
if any(url.lower().endswith(ext) for ext in skip_extensions):
continue
if base_domain in seen_domains:
continue # Un artículo por dominio para garantizar la diversidad
seen_domains.add(base_domain)
all_urls.append(url)
return all_urls[:6], serp_docs # Las 6 primeras URL
def scrape_url(url, customer_id, zone, password, retries=2):
"""Extrae una URL utilizando Bright Data Web Unlocker con reintentos automáticos."""
proxies = get_bd_proxy(customer_id, zona, password)
# No se necesitan encabezados personalizados: Web Unlocker gestiona el User-Agent,
# las cookies y las huellas digitales automáticamente.
for attempt in range(retries + 1):
try:
# verify=False omite la verificación SSL para el Proxy de BD.
# Para producción, instala el certificado CA de Bright Data en su lugar:
# https://docs.brightdata.com/general/account/ssl-certificate
response = requests.get(
url, proxies=proxies, timeout=60, verify=False
)
if response.status_code == 200:
return {
"url": url,
"html": response.text,
"scraped_at": datetime.now(timezone.utc).isoformat(),
}
else:
print(f"HTTP {response.status_code}", end=" → ", flush=True)
except Exception as e:
print(f"Error: {str(e)[:60]}", end=" → ", flush=True)
if attempt < retries:
time.sleep(2)
return Nonecollect_data() combina ambos pasos: SERP encuentra las URL y Web Unlocker las extrae:
def collect_data(topic, customer_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd):
"""Busca artículos sobre el tema a través de SERP y, a continuación, extrae su contenido con Web Unlocker."""
documents = []
# 1. Utilizar la API SERP para encontrar las URL de los artículos
urls_to_scrape, serp_docs = find_articles_for_topic(
topic, customer_id, serp_zone, serp_pwd
)
if not urls_to_scrape:
return []
# 2. Extrae los artículos encontrados con Web Unlocker
for i, url in enumerate(urls_to_scrape):
domain = url.split("/")[2] if "://" in url else url
print(f" ({i+1}/{len(urls_to_scrape)}) {domain}... ", end="", flush=True)
result = scrape_url(url, customer_id, unlocker_zone, unlocker_pwd)
if result:
documents.append(result)
print(f"OK ({len(result['html']):,} caracteres)")
else:
print("FALLO (omitiendo)")
# 3. Añadir resultados SERP como documentos adicionales
documents.extend(serp_docs)
return documentsAl ejecutar con «OpenAI vs Google vs Anthropic IA race» se obtiene este resultado:
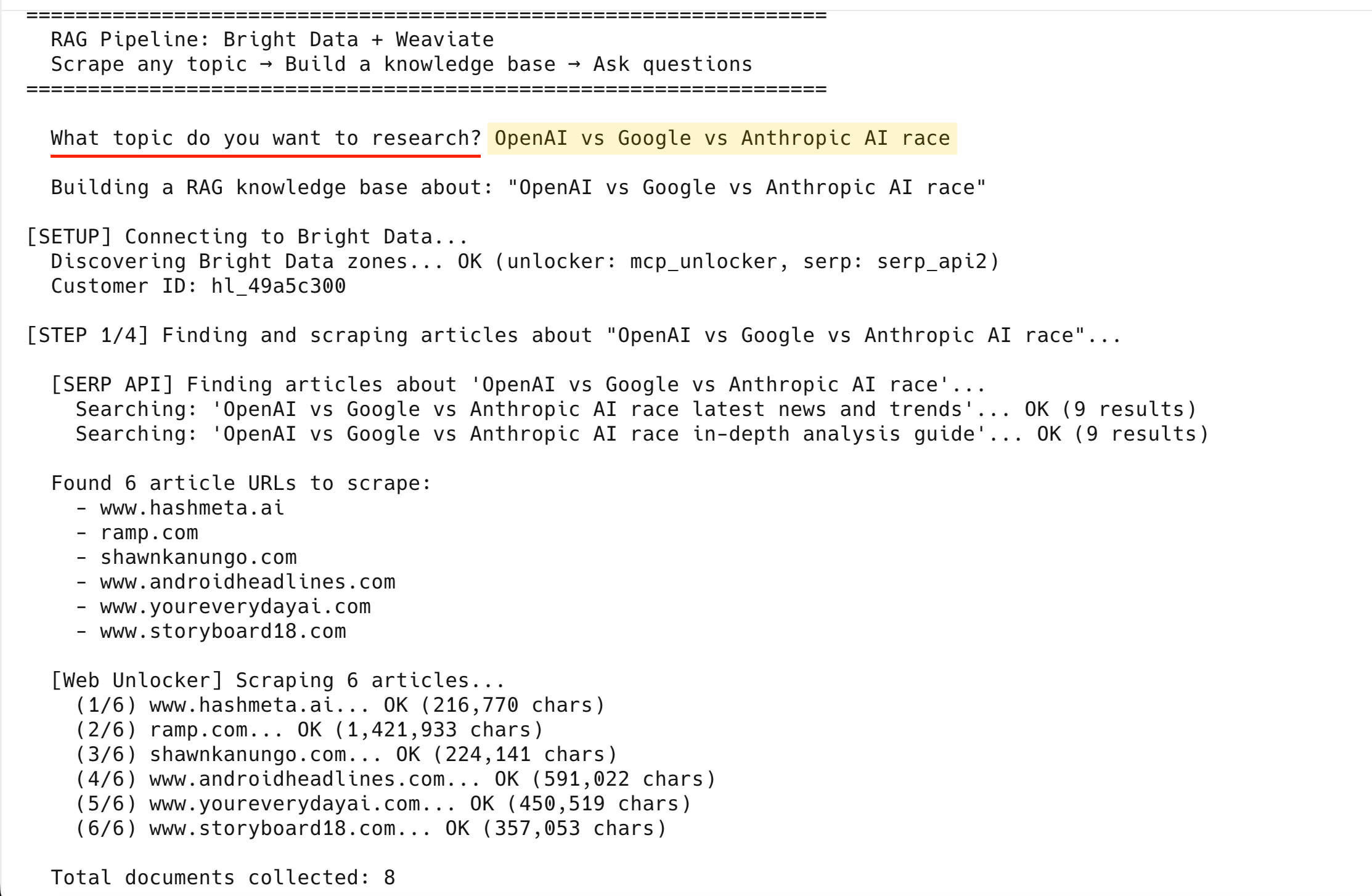
[API SERP] Buscando artículos sobre «OpenAI vs Google vs Anthropic IA race»...
Buscando: «OpenAI vs Google vs Anthropic IA race últimas noticias y tendencias»... OK (9 resultados)
Buscando: «OpenAI vs Google vs Anthropic IA race guía de análisis en profundidad»... OK (9 resultados)
Se han encontrado 6 URL de artículos para extraer:
- www.hashmeta.ai
- ramp.com
- shawnkanungo.com
- www.androidheadlines.com
- www.youreverydayai.com
- www.storyboard18.com
[Web Unlocker] Recopilando 6 artículos...
(1/6) www.hashmeta.ai... OK (216 770 caracteres)
(2/6) ramp.com... OK (1 421 933 caracteres)
(3/6) shawnkanungo.com... OK (224 141 caracteres)
(4/6) www.androidheadlines.com... OK (591 022 caracteres)
(5/6) www.youreverydayai.com... OK (450 519 caracteres)
(6/6) www.storyboard18.com... OK (357 053 caracteres)
Total de documentos recopilados: 8Los 6 se han extraído correctamente: las 2 páginas de resultados SERP elevan el total a 8 documentos.
Si Web Unlocker falla en una URL tras 3 intentos, el proceso la omite y continúa con los artículos restantes.
En este punto, tienes 8 documentos sin procesar (6 artículos + 2 páginas de resultados SERP). Ahora límpialos y divídelos en fragmentos para incrustarlos.
Paso 2: Limpia y divide los datos
El HTML sin procesar contiene aproximadamente un 90 % de ruido. El paso de procesamiento lo depura para obtener texto limpio y lo divide en fragmentos de 500 caracteres (aproximadamente 125 tokens) que se separan en los límites de las frases siempre que sea posible.
El tamaño de los fragmentos controla una compensación fundamental del RAG: los fragmentos más pequeños (200-500 caracteres) proporcionan una recuperación precisa por dato, mientras que los fragmentos más grandes (1000-2000 caracteres) proporcionan al LLM más contexto circundante a costa de resultados de búsqueda con más ruido. El valor predeterminado de 500 caracteres funciona bien para preguntas fácticas («¿Cuál es la tasa de victorias de Anthropic frente a OpenAI en el ámbito empresarial?»). Aumente el tamaño del fragmento a 1500-2000 para consultas que necesiten un contexto más amplio, como resúmenes o comparaciones.
La superposición de 50 caracteres evita la pérdida de información en los límites; sin ella, una frase que abarca dos fragmentos se divide y ninguno de los fragmentos contiene la idea completa.
def clean_html(html, is_serp=False):
"""Elimina el HTML para obtener texto limpio, quitando la navegación, los anuncios y el texto repetitivo."""
if is_serp:
return html # Los resultados SERP ya son texto limpio
soup = BeautifulSoup(html, "html.parser")
# Eliminar elementos superfluos
for tag in soup(["nav", "footer", "header", "script", "style",
"aside", "iframe", "noscript", "svg", "form", "button"]):
tag.decompose()
# Eliminar contenedores comunes de anuncios/cookies/ventanas emergentes
for selector in [".ad", ".ads", ".cookie", ".popup", ".modal", ".sidebar",
"#cookie-banner", "#ad-container", "[role='banner']",
"[role='navigation']", "[role='complementary']"]:
for el in soup.select(selector):
el.decompose()
text = soup.get_text(separator="n", strip=True)
líneas = [línea.strip() for línea in text.splitlines() if línea.strip()]
return "n".join(líneas)
def fragmentar_texto(texto, tamaño_fragmento=500, superposición_fragmentos=50):
"""Divide el texto en fragmentos superpuestos, separándolos por los límites de las oraciones.
La superposición garantiza que las frases en los límites de los fragmentos no se pierdan entre fragmentos."""
if len(text) <= chunk_size:
return [text]
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
# Intenta dividir en los límites de las frases
if end < len(text):
for sep in [". ", ".n", "nn", "n", " "]:
last_sep = text[max(start, end - 100):end].rfind(sep)
if last_sep != -1:
end = max(start, end - 100) + last_sep + len(sep)
break
chunk = text[start:end].strip()
if chunk and len(chunk) > 50:
chunks.append(chunk)
start = end - chunk_overlap
return chunks
def process_documents(documents):
"""Limpia, divide en fragmentos y añade metadatos a todos los documentos."""
all_chunks = []
for doc in documents:
is_serp = doc.get("is_serp", False)
clean_text = clean_html(doc["html"], is_serp=is_serp)
si len(texto_limpio) < 100:
continúa
fragmentos = fragmentar_texto(texto_limpio)
dominio = doc["url"].split("/")[2] si "://" en doc["url"]; de lo contrario, "desconocido"
for i, fragmento in enumerate(fragmentos):
todos_los_fragmentos.append({
"texto": fragmento,
"url_fuente": doc["url"],
"dominio_fuente": dominio,
"fecha_de_recogida": doc["fecha_de_recogida"],
"chunk_index": i,
"total_chunks": len(chunks),
"content_hash": hashlib.md5(chunk.encode()).hexdigest(),
"content_type": "serp_result" si is_serp, si no "article",
})
return all_chunksTras el procesamiento, 8 documentos se convierten en unos 150–400 fragmentos de texto limpio (dependiendo de la longitud del artículo), cada uno con metadatos (URL de origen, dominio, marca de tiempo, hash del contenido).
Paso 3: Incrustar y almacenar en Weaviate
Conéctate a Weaviate Cloud, crea una colección con vectorización Cohere e importa por lotes todos los fragmentos.
def connect_weaviate():
"""Conéctate a Weaviate Cloud con tiempos de espera ampliados."""
client = weaviate.connect_to_weaviate_cloud(
cluster_url=WEAVIATE_URL,
auth_credentials=Auth.api_key(WEAVIATE_API_KEY),
headers={"X-Cohere-Api-Key": COHERE_API_KEY},
additional_config=weaviate.classes.init.AdditionalConfig(
timeout=weaviate.classes.init.Timeout(init=30, query=60, insert=120),
),
skip_init_checks=True, # Evita el tiempo de espera de gRPC en entornos de prueba inactivos
)
if not client.is_ready():
print(" ERROR: El clúster de Weaviate no está listo.")
print(" Comprueba tu WEAVIATE_URL y WEAVIATE_API_KEY en .env")
print(" Asegúrate de que tu clúster de entornos de prueba se está ejecutando en console.weaviate.cloud")
sys.exit(1)
return client
def setup_collection(client):
"""Crea la colección con búsqueda híbrida + configuración generativa."""
# Elimina cualquier colección existente con este nombre; volver a ejecutar con un
# nuevo tema reemplaza la base de conocimientos anterior, no la amplía.
if client.collections.exists(COLLECTION_NAME):
client.collections.delete(COLLECTION_NAME)
print(f" Se ha eliminado la colección existente '{COLLECTION_NAME}'")
client.collections.create(
name=COLLECTION_NAME,
description="Artículos web recopilados a través de Bright Data para RAG",
# Cohere embed-v4.0: vectoriza automáticamente el texto en el momento de la importación
vector_config=Configure.Vectors.text2vec_cohere(
model="embed-v4.0",
),
# Cohere command-a-03-2025: genera respuestas RAG en el momento de la consulta
generative_config=Configure.Generative.cohere(
model="command-a-03-2025",
),
properties=[
Property(name="text", data_type=DataType.TEXT,
description="El contenido de texto del fragmento"),
Property(name="source_url", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="source_domain", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="scraped_at", data_type=DataType.TEXT,
skip_vectorization=True),
Propiedad(nombre="índice_fragmento", tipo_datos=DataType.INT,
omitir_vectorización=True),
Propiedad(nombre="total_fragmentos", tipo_datos=DataType.INT,
omitir_vectorización=True),
Propiedad(nombre="hash_contenido", tipo_datos=DataType.TEXT,
omitir_vectorización=True),
Property(name="content_type", data_type=DataType.TEXT,
skip_vectorization=True),
],
)
print(f" Creada la colección '{COLLECTION_NAME}'")Algunas cosas que vale la pena destacar:
skip_vectorization=Trueen los campos de metadatos: solo se incrusta el campode texto, lo que ahorra llamadas a la API y genera vectores más limpioscontent_hashalmacenado por fragmento: utilícelo para omitir la reincorporación de contenido sin cambios cuando añada lógica de re-raspado incremental (el pipeline actual vuelve a importar datos nuevos en cada ejecución)
Comportamiento al volver a ejecutar: el proceso elimina y vuelve a crear la colección en cada ejecución. Si se ejecuta primero «IA race» y luego «quantum computing», se sustituyen los datos de IA race. Para mantener varios temas, cambie
COLLECTION_NAMEpor un nombre único por tema (por ejemplo,WebResearch_ia_race,WebResearch_quantum).
Más información sobre la preparación de conjuntos de datos vectoriales listos para IA en la guía de Bright Data.
La función store_chunks() inserta por lotes todos los fragmentos en la colección:
def store_chunks(client, chunks):
"""Importa por lotes fragmentos a Weaviate (vectorizados automáticamente a través de Cohere)."""
collection = client.collections.use(COLLECTION_NAME)
with collection.batch.fixed_size(batch_size=50) as batch:
for chunk in chunks:
batch.add_object(properties=chunk)
failed = len(collection.batch.failed_objects) if collection.batch.failed_objects else 0
if failed > 0:
print(f" Primer error: {collection.batch.failed_objects[0].message[:120]}")
return failedbatch.fixed_size(50) importa los lotes para aumentar el rendimiento en lugar de insertarlos uno por uno. En la prueba, todos los fragmentos se importaron sin ningún error. Weaviate llama a Cohere para incrustar cada fragmento en el momento de la importación.
Paso 4: Consulta con búsqueda y generación híbridas
Una vez incrustados e indexados todos los fragmentos, consúltelos utilizando la función rag_query(). Esta llama a generate.hybrid() para realizar la recuperación y la generación en una sola solicitud:
def rag_query(client, question, alpha=0.7, limit=5):
"""Ejecuta una consulta RAG utilizando la búsqueda híbrida de Weaviate + IA generativa."""
collection = client.collections.use(COLLECTION_NAME)
response = collection.generate.hybrid(
query=question,
alpha=alpha, # 0.7 = 70 % semántico, 30 % por palabra clave
limit=limit,
grouped_task=f"""Basándote en los documentos recuperados a continuación, responde a esta pregunta:
"{question}"
Instrucciones:
- Proporcione una respuesta clara y completa
- Cite la URL de la fuente para cada afirmación clave
- Si la información parece desactualizada o contradictoria, indíquelo
- Mantenga la respuesta concisa pero informativa (2-4 párrafos)""",
)
print(f"n P: {question}")
print(f" {'─' * 60}")
if response.generated:
print(f" R: {clean_generated_text(response.generated)}")
else:
print(" R: (No se ha generado ninguna respuesta — comprueba tu clave API de Cohere)")
# Separar las fuentes de los artículos de los fragmentos del resumen SERP
article_sources = []
serp_sources = []
seen_urls = set()
for obj in response.objects:
url = obj.properties.get("source_url", "unknown")
if url in seen_urls:
continue
seen_urls.add(url)
content_type = obj.properties.get("content_type", "")
dominio = obj.properties.get("source_domain", "")
si tipo_contenido == "serp_result":
fuentes_serp.append((dominio, url))
else:
fuentes_artículos.append((dominio, clean_url(url)))
print(f"n Fuentes ({len(response.objects)} fragmentos recuperados):")
for domain, url in article_sources:
print(f" - [{domain}] {url}")
if not article_sources and serp_sources:
print(" (Basado en resúmenes SERP — no se han encontrado fragmentos de artículos coincidentes)")
return responseLa búsqueda vectorial pura podría pasar por alto términos exactos como «GPT-5» o «Claude Code». La búsqueda por palabras clave pura omite contenido semánticamente relacionado. La combinación alpha=0.7 te ofrece ambas cosas. El algoritmo BlockMax WAND de Weaviate mantiene la rapidez del componente de palabras clave BM25 a gran escala.
Con limit=5, la consulta recupera los 5 fragmentos principales: contexto suficiente para una respuesta detallada sin saturar el LLM con ruido. Aumenta a 10 para preguntas amplias que abarquen varios subtemas; reduce a 3 para búsquedas factuales precisas. El parámetro grouped_task envía todos los fragmentos recuperados a Cohere en una sola solicitud para que pueda escribir una única respuesta. La alternativa, single_prompt, genera una respuesta por fragmento, lo que resulta útil para resúmenes por documento, pero no para respuestas que abarcan varias fuentes.
Consulte el resumen de Bright Data sobre API de búsqueda semántica para ver más opciones.
Combina los 4 pasos
La función main() ejecuta el proceso completo. Tú eliges un tema y ella se encarga del resto:
def main():
print("=" * 65)
print(" Pipeline RAG: Bright Data + Weaviate")
print(" Extraer cualquier tema → Crear una base de conocimientos → Hacer preguntas")
print("=" * 65)
# ── Validar el entorno ──
validate_env()
# ── Pedir al usuario un tema ──
print()
try:
topic = input(" ¿Qué tema quieres investigar? ").strip()
except (EOFError, KeyboardInterrupt):
print("n ¡Adiós!")
return
if not topic:
print(" No se ha introducido ningún tema. Saliendo.")
return
print(f'n Creando una base de conocimientos RAG sobre: "{topic}"')
# ── Detectar automáticamente las credenciales de Bright Data ──
print("n[CONFIGURACIÓN] Conectando con Bright Data...")
cust_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd = (
discover_bright_data_credentials()
)
# ── Paso 1: Buscar y extraer artículos sobre el tema ──
print(f'n[PASO 1/4] Buscando y extrayendo artículos sobre "{topic}"...')
documents = collect_data(
topic, cust_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd
)
print(f"n Total de documentos recopilados: {len(documents)}")
if not documents:
print(" ERROR: No se han recopilado documentos. Prueba con otro tema.")
return
# ── Paso 2: Procesar y dividir en fragmentos ──
print("n[PASO 2/4] Procesando y dividiendo los documentos en fragmentos...")
chunks = process_documents(documents)
print(f" Se han creado {len(chunks)} fragmentos a partir de {len(documents)} documentos")
if not chunks:
print(" ERROR: No se han creado fragmentos. Es posible que los documentos sean demasiado cortos.")
return
# ── Paso 3: Almacenar en Weaviate ──
print("n[PASO 3/4] Almacenando en Weaviate (incrustación + indexación)...")
print(" Conectando con Weaviate Cloud...", end=" ", flush=True)
client = connect_weaviate()
print("OK")
print(" Configurando la colección...")
setup_collection(client)
print(f" Importando {len(chunks)} fragmentos (vectorización automática vía Cohere)...")
failed = store_chunks(client, chunks)
print(f" Importados: {len(chunks) - failed} correctos, {failed} fallidos")
# Verificar recuento
collection = client.collections.use(COLLECTION_NAME)
count = collection.aggregate.over_all(total_count=True).total_count
print(f" Total de objetos en Weaviate: {count}")
# ── Paso 4: Consultas de demostración + Modo interactivo ──
print(f'n[PASO 4/4] Consultas RAG sobre "{topic}"...')
print("=" * 65)
demo_queries = [
f"¿Cuáles son las últimas novedades y tendencias en {topic}?",
f"¿Cuáles son los mayores retos y riesgos en {topic}?",
f"¿Cuáles son las perspectivas de futuro para {topic}?",
]
for question in demo_queries:
rag_query(client, question)
print()
# ── Resumen ──
print("=" * 65)
print(" ¡Proceso completado!")
print(f' Tema: "{topic}"')
print(f" - Se han recopilado {len(documents)} fuentes a través de Bright Data")
print(f" - Almacenados {count} fragmentos en Weaviate")
print(f" - Ejecutadas {len(demo_queries)} consultas RAG de demostración")
print("=" * 65)
# ── Modo interactivo ──
print(f'n ¡Tu base de conocimientos sobre "{topic}" está lista!')
print(" Pregunta lo que quieras. Escribe 'quit' para salir.n")
while True:
try:
user_question = input(" Tu pregunta: ").strip()
except (EOFError, KeyboardInterrupt):
print("n ¡Adiós!")
break
if not user_question:
continue
if user_question.lower() in ("quit", "exit", "q"):
print(" ¡Adiós!")
break
rag_query(client, user_question)
print()
client.close()
if __name__ == "__main__":
main()Ejecutarlo:
python3 pipeline.pyRespuestas RAG de la prueba de la carrera de IA
El proceso se ejecutó con el tema «Competencia entre OpenAI, Google y Anthropic IA». Estas son respuestas RAG de muestra de una prueba; tus resultados reflejarán los artículos que estén disponibles cuando lo ejecutes.
Consulta 1: «¿Cuáles son las últimas novedades y tendencias en la carrera entre OpenAI, Google y Anthropic IA?»
La carrera de IA entre OpenAI, Google y Anthropic sigue evolucionando rápidamente, con cada empresa aprovechando sus puntos fuertes únicos. OpenAI mantiene el liderazgo en ingresos y adopción por parte de los consumidores, beneficiándose de su ventaja como pionera. Anthropic está acortando distancias en la adopción empresarial, con herramientas especializadas como Claude Code y una tasa de éxito del 70 % en enfrentamientos directos entre empresas que adquieren servicios de IA. Google aporta recursos computacionales inigualables y una integración perfecta en todo su ecosistema.
Fuentes: shawnkanungo[.]com, hashmeta[.]ia, ramp[.]com
Pregunta 2: «¿Cuáles son los mayores retos y riesgos en la carrera entre OpenAI, Google y Anthropic IA?»
OpenAI se enfrenta al reto de mantener su ritmo de innovación sin perder su independencia, especialmente dado que depende de asociaciones para obtener recursos computacionales. Google lucha contra la inercia burocrática y corre el riesgo de canibalizar su negocio principal de publicidad en búsquedas, ya que la IA conversacional reduce los clics en los anuncios. Anthropic, posicionada como una empresa que antepone la seguridad, debe traducir su enfoque en la interpretabilidad en cuota de mercado en un mercado impulsado por las capacidades.
Fuentes: hashmeta[.]ia, shawnkanungo[.]com
Pregunta 3: «¿Cuáles son las perspectivas de futuro de la carrera entre OpenAI, Google y Anthropic IA?»
OpenAI lidera en ingresos y adopción por parte de los consumidores, con una hoja de ruta que incluye GPT-5 e inversiones para reducir los costes de inferencia. El éxito futuro de Anthropic depende de si surgen requisitos normativos en materia de explicabilidad; sus inversiones tempranas en seguridad e interpretabilidad podrían suponer una ventaja significativa. Google sigue siendo un fuerte competidor, especialmente en la adaptación de herramientas como Gemini para casos de uso específicos y en la integración de la IA en los flujos de trabajo cotidianos.
Fuentes: hashmeta[.]ia, shawnkanungo[.]com
Cada respuesta se basa en artículos recopilados durante esa misma ejecución del proceso. Cada cita apunta a una fuente recopilada en el paso 1; puedes comprobar cualquier afirmación abriendo la URL. Si preguntas algo que los artículos recopilados no cubren, el modelo lo indica o da una respuesta menos detallada.
Tras las consultas de demostración, el proceso pasa a modo interactivo, donde puedes formular tus propias preguntas:

Pasar a producción
Si necesitas esto en producción, necesitarás multitenencia, cumplimiento normativo y controles de costes. (Para tener una visión más amplia, consulta cómo encaja RAG en una pila tecnológica de agentes de IA en producción).
Multitenencia para el aislamiento de datos
Si estás creando RAG para varios clientes, la multitenencia de Weaviate proporciona a cada inquilino un fragmento dedicado con índices vectoriales aislados:
from weaviate.classes.config import Configure
from weaviate.classes.tenants import Tenant
# Habilitar la multitenencia en la colección
collection = client.collections.create(
name="WebContent",
multi_tenancy_config=Configure.multi_tenancy(enabled=True),
# ... vectorizador + configuración generativa
)
# Cada cliente obtiene su propio inquilino aislado
collection.tenants.create([
Tenant(name="customer_a"),
Tenant(name="customer_b"),
Tenant(name="customer_c"),
])
# Recopilar y almacenar datos por inquilino
tenant_collection = collection.with_tenant("customer_a")
with tenant_collection.batch.dynamic() as batch:
for chunk in customer_a_chunks:
batch.add_object(properties=chunk)Un solo nodo admite más de 50 000 clientes activos; un clúster de 20 nodos gestiona un millón.
Optimización de costes
4 técnicas reducen el coste a medida que crecen los datos:
- Cuantificación rotacional de Weaviate: compresión vectorial 4x con una recuperación del 98-99 %.
- Hash de contenido: el campo
content_hashpermite actualizaciones incrementales que omiten la reincorporación de fragmentos sin cambios (véase el paso 3 anterior) skip_vectorization=Trueen los campos de metadatos: incrusta solo lo que importa.- Bright Data Dataset Marketplace: utiliza Conjuntos de datos recopilados previamente en lugar de rastrear dominios comunes.
Esto es importante una vez que se va más allá de un prototipo para un solo usuario.
Errores comunes y cómo solucionarlos
Si te encuentras con un problema, consulta primero esta tabla:
| Problema | Causa | Solución |
|---|---|---|
Weaviate gRPC DEADLINE_EXCEEDED |
El clúster de Sandbox quedó inactivo durante el scraping | Vuelve a ejecutar pipeline.py: el script se volverá a conectar automáticamente. Si el problema persiste, comprueba tu clúster en la consola de Weaviate |
Límite de velocidad de la API de Cohere (429) |
El plan de prueba tiene un límite de velocidad | Espere un minuto y vuelva a intentarlo, o compruebe el uso en el panel de control de Cohere. La ejecución automatizada utiliza menos de 20 llamadas; cada pregunta interactiva añade 2 más |
No se ha encontrado ninguna zona de Web Unlocker |
Tu cuenta de Bright Data no tiene una zona de Web Unlocker | Ve a Bright Data → Proxies y scraping → Mis zonas → crea una zona de Web Unlocker |
No se ha encontrado ninguna zona API SERP |
Tu cuenta de Bright Data no tiene una zona SERP | Ve a Bright Data → Proxies y scraping → Mis zonas → crea una zona API SERP |
ErrorHTTP 403 en todas las URL |
Se han agotado los reintentos de Web Unlocker | Prueba con un tema diferente: algunos sitios especializados utilizan bloqueos anti-bot estrictos. Consulta cómo evitar los CAPTCHAs para ver opciones avanzadas |
El clúster de Weaviate no está listo |
El sandbox ha caducado (límite de 14 días) | Crea un nuevo entorno de pruebas en la consola de Weaviate y actualiza el archivo .env |
| Modelo Cohere no disponible | command-a-03-2025 o embed-v4.0 retirados |
Comprueba los modelos disponibles en docs.cohere.com/docs/models y actualiza el parámetro model= en setup_collection() |
ModuleNotFoundError: No existe ningún módulo llamado «weaviate» |
Dependencias no instaladas | Ejecute pip3 install -r requirements.txt desde el directorio del proyecto |
Si su error no aparece en la lista, compruebe la salida completa: el proceso registra cada paso con detalles.
Casos de uso
La misma arquitectura funciona para cualquier tema. Algunas ideas:
- Inteligencia competitiva: tema: «estrategia de precios del competidor X». El proceso recopila información de los sitios web de la competencia, las páginas de precios y los informes de analistas. A continuación, pregunta: «¿Cómo se comparan los precios para empresas del competidor X con los nuestros?».
- Estudio de mercado: tema: «tendencias fintech en el sudeste asiático». Recopila noticias regionales y publicaciones del sector, lo que te permite preguntar cosas como «¿Cuáles son las principales tendencias emergentes en fintech en el sudeste asiático?».
- Comercio electrónico – tema: «mercado de la moda sostenible». Recopila informes de mercado y estudios de mercado. «¿Qué marcas de moda sostenible están ganando cuota de mercado?».
- Investigación técnica – tema: «mejores prácticas de seguridad de Kubernetes». Recopila blogs técnicos y avisos de seguridad para que puedas preguntar sobre CVE específicos o configuraciones erróneas.
Qué desarrollar a continuación
Este es un prototipo funcional con limitaciones conocidas:
- Reemplaza toda la colección en cada ejecución (sin actualizaciones incrementales): utiliza
content_hashpara añadir diferencias - Solo procesa texto; se descartan las tablas, imágenes y archivos PDF de las páginas rastreadas
- Busca contenido a través de la búsqueda de Google; para URL específicas, pásalas directamente a
scrape_url() - Se ejecuta como una CLI de usuario único
A partir de aquí, puedes:
- Programación: ejecuta el proceso mediante una tarea cron para mantener actualizada tu base de conocimientos
- Multitenencia: asigne a cada cliente su propio fragmento aislado (consulte la sección «Puesta en producción» más arriba)
- Diferentes fuentes de datos: utiliza la API Bright Data Web Scraper para datos estructurados de Amazon o LinkedIn, o la API Crawl para Markdown de sitios completos
- Frontend: envuelve
rag_query()en un punto final de Flask o FastAPI y conecta una interfaz de usuario de chat - RAG agéntico: crear un sistema RAG agéntico que decida por sí mismo cuándo y qué rastrear
- LangChain: porta el pipeline a LangChain con Bright Data para obtener orquestación de cadenas y memoria integradas
Preguntas frecuentes
¿Qué temas funcionan con este pipeline?
Cualquier tema que tenga artículos en la web abierta. El pipeline utiliza la API SERP de Bright Data para buscar tu tema en Google y, a continuación, extrae los resultados principales. Los temas de nicho con menos páginas indexadas devuelven menos artículos, pero el pipeline sigue funcionando: simplemente utiliza lo que encuentra.
¿Cuánto cuesta utilizarlo?
Los tres servicios ofrecen formas gratuitas de empezar. El plan de prueba de Cohere es gratuito y no requiere tarjeta de crédito. Weaviate Cloud ofrece un clúster de prueba gratuito, y Bright Data ofrece una prueba gratuita de la API SERP y Web Unlocker.
¿Puedo utilizar un modelo de incrustación o un LLM diferente?
Sí. Cambia el parámetro del modelo en setup_collection() tanto para las incrustaciones como para la generación. Weaviate es compatible de serie con los vectorizadores de Cohere, OpenAI, Google y Hugging Face. Para cambiar, sustituye text2vec_cohere por text2vec_openai, actualiza el encabezado de la clave API en connect_weaviate() y vuelve a ejecutar el proceso.
¿Cómo mantengo actualizada la base de conocimientos?
Vuelve a ejecutar pipeline.py con el mismo tema. El proceso elimina la colección antigua y crea una nueva con los datos recién extraídos. Para uso en producción, añade una comprobación de content_hash para omitir la reincrustación de fragmentos que no hayan cambiado. Programa el proceso en una tarea cron para actualizar los datos automáticamente en cualquier intervalo.
¿Qué pasa si ya tengo URL para rastrear?
Omita el paso de descubrimiento de SERP. En collect_data(), sustituya la llamada a find_articles_for_topic() por su propia lista de URL y pase cada URL a scrape_url(). El resto del pipeline (división en fragmentos, incrustación, consulta) funciona de la misma manera.
¿Cómo puedo rastrear más de 6 artículos?
Cambia el segmento [:6] al final de find_articles_for_topic() por un número mayor (por ejemplo, [:12]). También puedes añadir más consultas de búsqueda a la lista search_queries para obtener una gama más amplia de resultados. Más artículos significan más tiempo de rastreo y más fragmentos, pero el resto del proceso lo gestiona automáticamente.





