

En esta guía aprenderás:
- Qué es Agno y por qué es una opción excelente para construir flujos de trabajo agénticos.
- Por qué el web scraping desempeña un papel tan valioso en los agentes de IA.
- Cómo integrar Agno con sus herramientas Bright Data incorporadas para crear un agente de raspado web.
Sumerjámonos.
¿Qué es Agno?
Agno es un framework completo en Python para construir sistemas multiagente que aprovechan la memoria, el conocimiento y el razonamiento avanzado. Permite la creación de agentes de IA sofisticados para una amplia gama de casos de uso. Estos van desde simples agentes que utilizan herramientas hasta equipos de agentes colaborativos con estado y determinismo.
Agno es independiente del modelo, tiene un alto rendimiento y sitúa el razonamiento en el centro de su diseño. Admite entradas y salidas multimodales, orquestación compleja de múltiples agentes, búsqueda integrada de agentes con bases de datos vectoriales y gestión completa de memoria/sesión.
En el momento de escribir este artículo, Agno es una de las bibliotecas de código abierto más populares para crear agentes de IA, con más de 29.000 estrellas en GitHub:
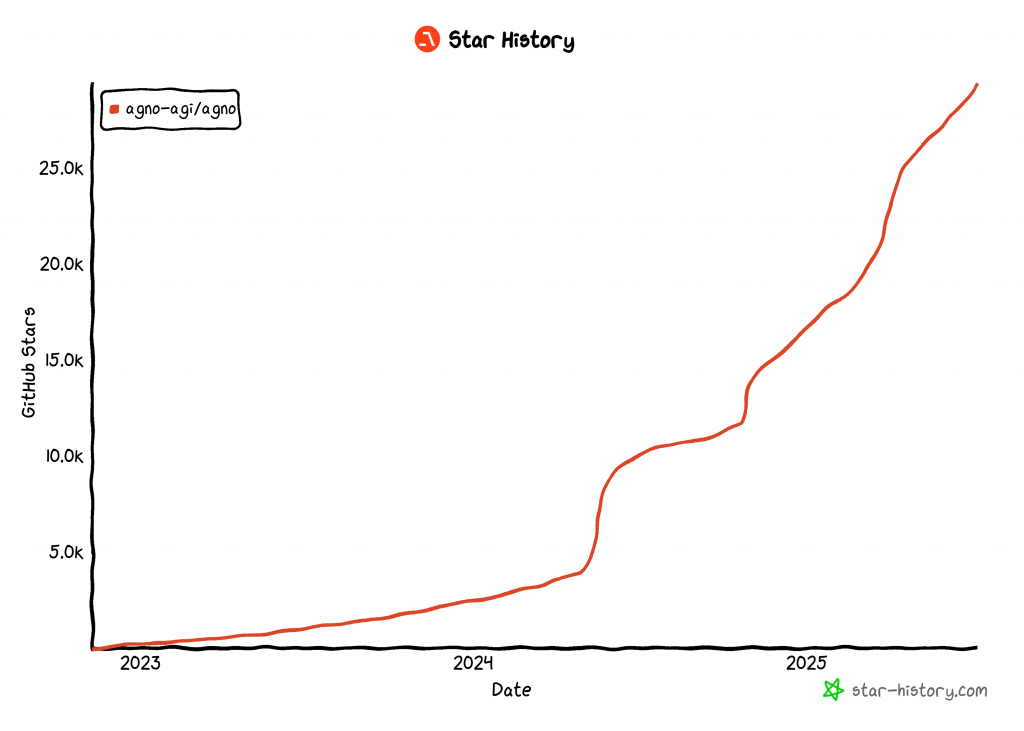
Su rápido ascenso pone de manifiesto lo rápido que Agno está ganando adeptos en la comunidad de desarrolladores y de IA.
Por qué es tan útil el raspado web agentico
El web scraping tradicional se basa en la escritura de reglas rígidas de análisis sintáctico de datos para extraer datos de páginas web específicas. ¿Cuál es el problema? Los sitios cambian con frecuencia su estructura, lo que significa que tiene que actualizar constantemente su lógica de raspado. Esto conlleva unos costes de mantenimiento elevados y unos procesos frágiles.
Por eso, el raspado web con IA está ganando adeptos. En lugar de elaborar scripts de análisis personalizados, puede utilizar un modelo de IA para extraer datos directamente del HTML de una página web con una simple solicitud. Este enfoque es tan popular que recientemente han surgido muchas herramientas de AI scraping.
Sin embargo, el raspado web de IA se vuelve aún más potente cuando se integra en una arquitectura de IA agéntica. En concreto, se puede crear un agente dedicado al web scraping al que se puedan conectar otros agentes de IA. Esto es posible en flujos de trabajo multiagente o a través de protocolos de IA como A2A de Google.
Agno hace posible todo lo anterior. Permite crear agentes de raspado de IA autónomos o complejos ecosistemas multiagente. Sin embargo, los LLM normales no están diseñados para un raspado web competente. A menudo no consiguen conectarse a sitios con fuertes defensas contra bots o, peor aún, pueden “alucinar” y devolver datos falsos.
Para hacer frente a estas limitaciones, Agno se integra de forma nativa con Bright Data a través de herramientas de scraping específicas. Con estas herramientas, su agente de IA puede extraer datos frescos y estructurados de cualquier sitio web.
Para evitar bloqueos e interrupciones, Bright Data supera por usted retos como la huella digital TLS, la huella digital de navegadores y dispositivos, los CAPTCHA, las protecciones de Cloudflare, etc. Una vez recuperados los datos, se introducen en el LLM para su interpretación y análisis, siguiendo las instrucciones de su tarea original.
Descubra cómo integrar las herramientas de Bright Data en un agente Agno para realizar un scraping web de alto nivel.
Cómo integrar Bright Data Tools para Web Scraping en Agno
En esta sección paso a paso, verá cómo utilizar Agno para construir un agente AI de web scraping. Integrando las herramientas de Bright Data, dotará a su agente Agno de la capacidad de raspar datos de cualquier página web.
Siga las instrucciones siguientes para crear su agente de raspado Bright Data en Agno.
Requisitos previos
Para seguir este tutorial, asegúrate de tener lo siguiente:
- Python 3.7 o superior instalado localmente (recomendamos utilizar la última versión).
- Una clave API de Bright Data.
- Una clave API para un proveedor de LLM compatible (en este caso, utilizaremos Gemini porque su uso a través de la API es gratuito, pero cualquier proveedor de LLM compatible servirá).
No se preocupe si aún no tiene una clave API de Bright Data o una clave API de Gemini. Le explicaremos cómo crearlas en los pasos siguientes.
Paso nº 1: Configuración del proyecto
Abra un terminal y cree un nuevo directorio para su proyecto de agente Agno AI, que utilizará Bright Data para el web scraping:
mkdir agno-web-scraperLa carpeta agno-web-scraper contendrá todo el código Python para su agente Agno de scraping.
A continuación, navega hasta el directorio del proyecto y configura un entorno virtual dentro de él:
cd agno-web-scraper
python -m venv venvAhora, carga el proyecto en tu IDE de Python favorito. Recomendamos Visual Studio Code con la extensión Python o PyCharm Community Edition.
Dentro de la carpeta del proyecto, crea un nuevo archivo llamado scraper.py. La estructura de directorios debe ser la siguiente:
agno-web-scraper/
├── venv/
└── scraper.pyActive el entorno virtual en su terminal. En Linux o macOS, ejecute:
source venv/bin/activateDe forma equivalente, en Windows, ejecute este comando:
venv/Scripts/activateEn los siguientes pasos, se le guiará a través de la instalación de los paquetes de Python necesarios. Si prefieres instalar todo ahora, en el entorno virtual activado, ejecuta:
pip install agno python-dotenv google-genai requestsNota: Estamos instalando google-genai porque este tutorial utiliza Gemini como proveedor LLM. Si planeas usar un LLM diferente, asegúrate de instalar la librería apropiada para ese proveedor.
¡Ya está todo listo! Ahora tiene un entorno de desarrollo Python listo para construir un flujo de trabajo de scraping agentic utilizando Agno y Bright Data.
Paso nº 2: Configurar las variables de entorno Lectura
Su agente de raspado Agno se conectará a servicios de terceros como Bright Data y Gemini a través de integraciones API. Para mantener la seguridad, evite codificar sus claves API directamente en su código Python. En su lugar, guárdelas como variables de entorno.
Para facilitar la carga de variables de entorno, adopta la biblioteca python-dotenv. Con tu entorno virtual activado, instálala ejecutando:
pip install python-dotenvA continuación, en su archivo scraper.py, importe la biblioteca y llame a load_dotenv() para cargar sus variables de entorno:
from dotenv import load_dotenv
load_dotenv()Esta función permite a tu script leer variables desde un archivo local .env. Adelante, crea un archivo .env en la raíz del directorio de tu proyecto:
agno-web-scraper/
├── venv/
├── .env # <-----------
└── scraper.py¡Maravilloso! Ahora está preparado para manejar de forma segura sus secretos de integración utilizando variables de entorno.
Paso nº 3: Configurar Bright Data
Las herramientas de Bright Data integradas en Agno le dan acceso a varias soluciones de recopilación de datos. En este tutorial, nos centraremos en la integración de estos dos productos específicos de scraping:
- API Web Unlocker: Una API de scraping avanzada que supera las protecciones contra bots, proporcionando acceso a cualquier página web en formato Markdown.
- API de raspado web: Puntos finales especializados para extraer de forma ética datos frescos y estructurados de sitios web populares, como LinkedIn, Amazon y muchos otros.
Para utilizar estas herramientas, es necesario:
- Configure la solución Web Unlocker en su cuenta de Bright Data.
- Obtenga su token de Bright Data API para autenticar las solicitudes a las API de Web Unlocker y Web Scraper.
Para ello, siga las siguientes instrucciones
En primer lugar, si aún no tiene una cuenta de Bright Data, regístrese gratuitamente. Si ya la tiene, inicie sesión y abra su panel de control. A continuación, haga clic en el botón “Obtener productos proxy”:
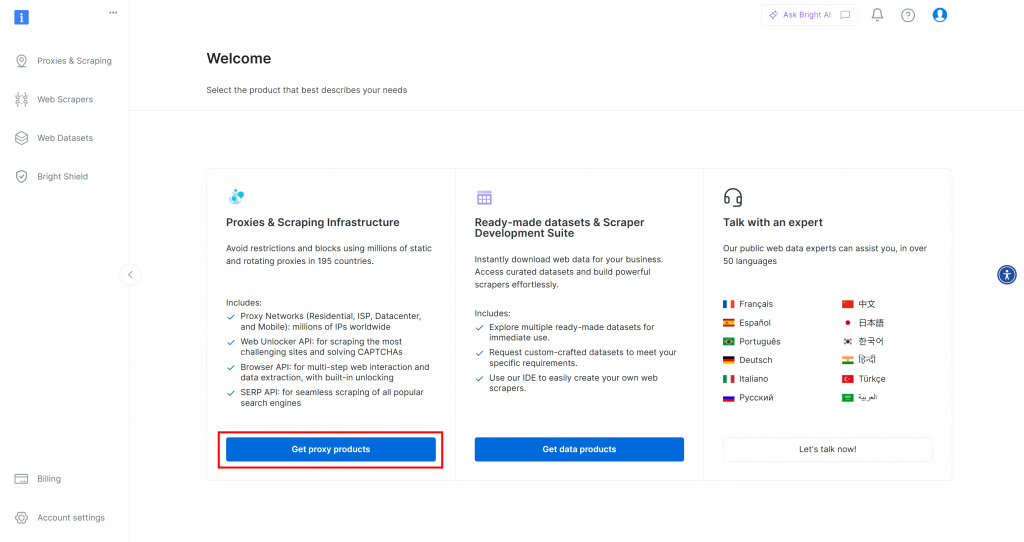
Será redirigido a la página “Proxies & Scraping Infrastructure”:
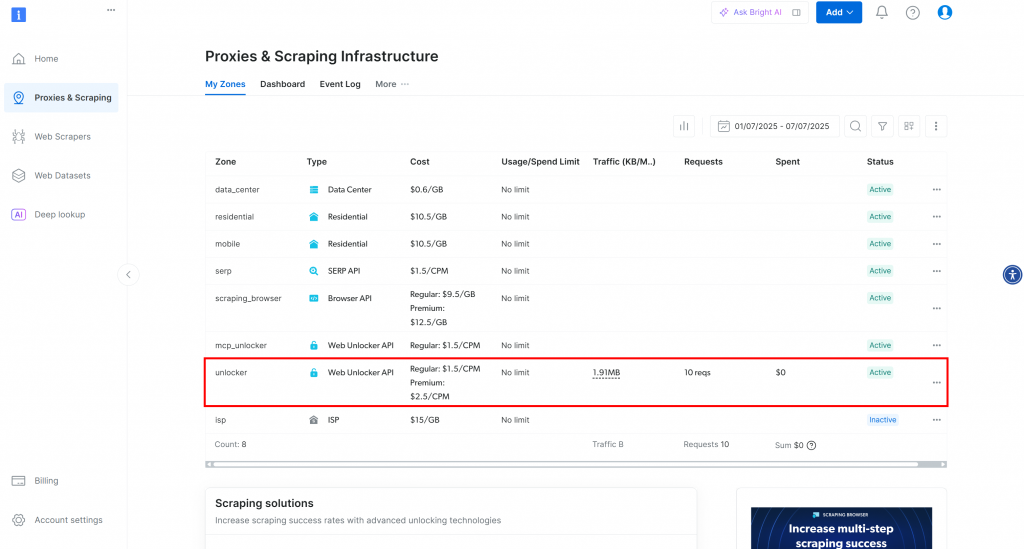
En esta página verá las soluciones de Bright Data ya configuradas. En este ejemplo, se ha activado una zona Web Unloker. El nombre de esa zona es “unblocker” (lo necesitará más adelante cuando lo integre en su script).
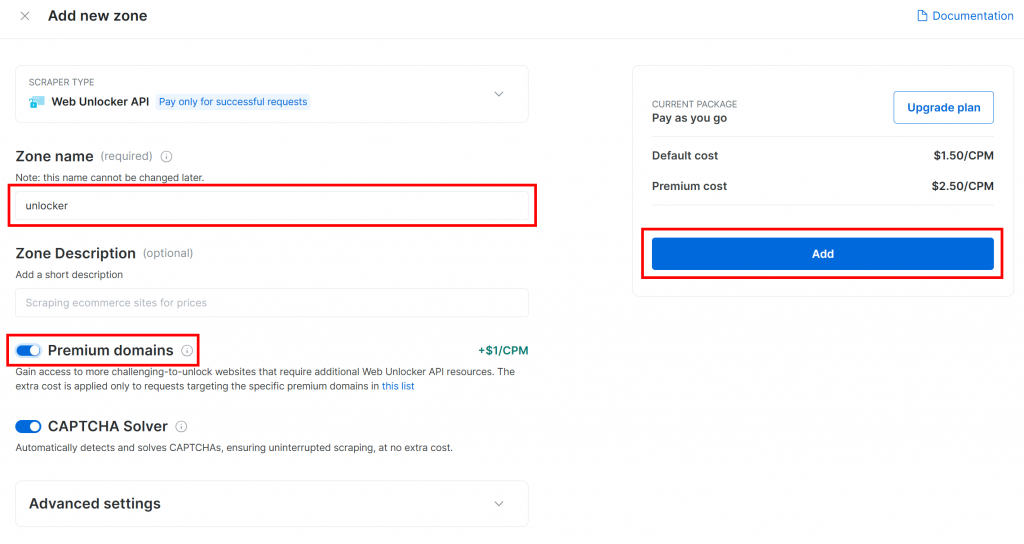
Si aún no dispone de una zona Web Unlocker, desplácese hasta la tarjeta “Web Unlocker API” y haga clic en “Crear zona”:
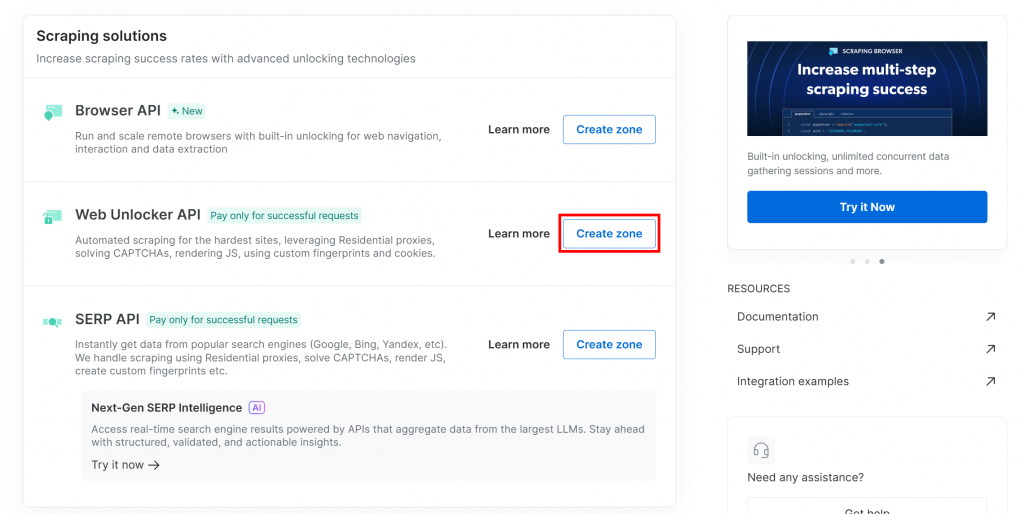
Dale un nombre a tu zona (como “desbloqueador”), activa las funciones avanzadas para un mejor rendimiento y pulsa el botón “Añadir”:
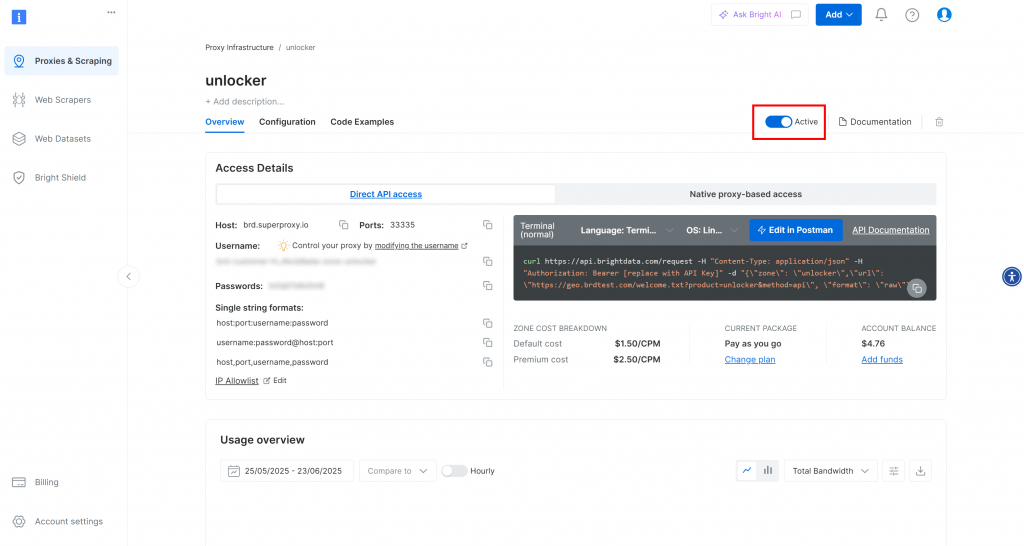
Accederá a la página de su nueva zona. Asegúrese de que el conmutador está en estado “Activo”, lo que confirma que el producto está listo para su uso:
Ahora, siga la documentación oficial de Bright Data para generar su clave API. Una vez que la tenga, añádala a su archivo .env de la siguiente forma:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Sustituya el por el valor real de su clave API.
¡Perfecto! Ha llegado el momento de integrar las herramientas de Bright Data en su script de agente Agno para el agentic web scraping.
Paso nº 4: Integrar las herramientas Agno Bright Data Tools para Web Scraping
En la carpeta de su proyecto, con el entorno virtual activado, instale Agno ejecutando:
pip install agnoTenga en cuenta que el paquete agno ya incluye soporte integrado para las herramientas de Bright Data. Por lo tanto, no necesita ningún paquete adicional específico de integración.
El único paquete adicional necesario es la biblioteca Python Requests, que las herramientas de Bright Data utilizan para llamar a los productos que configuró anteriormente a través de la API. Instale requests con:
pip install requestsEn su archivo scraper.py, importe las herramientas de raspado de Bright Data de agno:
from agno.tools.brightdata import BrightDataToolsA continuación, inicializa las herramientas así:
bright_data_tools = BrightDataTools(
web_unlocker_zone="unlocker", # Replace with your Web Unlocker API zone name
search_engine=False,
)Sustituya "unlocker" por el nombre real de su zona Bright Data Web Unlocker.
Tenga en cuenta también que search_engine está establecido en False, ya que en este ejemplo no estamos utilizando la herramienta SERP API, que se centra exclusivamente en el raspado web.
Consejo: En lugar de codificar los nombres de zona, puede cargarlos desde su archivo .env. Para ello, añada esta línea a su archivo .env:
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>"Sustituya el marcador de posición por el nombre real de su zona de Web Unlocker. A continuación, puede eliminar el argumento web_unlocker_zone de BrightDataTools. La clase recogerá automáticamente el nombre de zona de su entorno.
Nota: Para conectarse a Bright Data, BrightDataTools busca su clave API en la variable de entorno BRIGHT_DATA_API_KEY. Por eso la hemos añadido a su archivo .env en el paso anterior.
¡Increíble! Integre Gemini para potenciar su flujo de trabajo Agno web scraping agentic.
Paso 5: Configurar el modelo LLM desde Gemini
Es hora de conectarse a Gemini, el proveedor LLM elegido en este tutorial. Empieza instalando el paquete google-genai:
pip install google-genaiA continuación, importa la clase de integración Gemini de Agno:
from agno.models.google import GeminiAhora, inicializa tu modelo LLM así:
llm_model = Gemini(id="gemini-2.5-flash")En el fragmento anterior, gemini-2.5-flash es el nombre del modelo Gemini que desea que utilice su agente. Siéntete libre de reemplazarlo por cualquier otro modelo Gemini soportado (sólo ten en cuenta que algunos de ellos no son libres de usar vía API).
Bajo el capó, la biblioteca google-genai espera que tu clave API Gemini se almacene en una variable de entorno llamada GOOGLE_API_KEY. Para configurarla, añade la siguiente línea a tu archivo .env:
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"Sustituya el con su clave de API real. Si aún no tiene una, siga la guía oficial para generar una clave API Gemini.
Nota: Si desea conectarse a un proveedor de LLM diferente, consulte la documentación oficial para obtener instrucciones de configuración.
¡Fantástico! Ahora tiene todos los componentes básicos que necesita para construir su agente de raspado Agno.
Paso nº 6: Definir el agente de raspado
En su archivo scraper.py, configure su agente de raspado Agno de la siguiente manera:
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)Esto crea un objeto Agente Agno que utiliza su LLM configurado para procesar solicitudes y aprovecha las herramientas de Bright Data para el raspado web.
No olvide añadir esta importación al principio de su expediente:
from agno.agent import AgentEstupendo. Sólo queda enviar una consulta a su agente y exportar los datos obtenidos.
Paso 7: Consultar al agente de raspado Agno
Lea el prompt de la CLI y páselo a su agente de scraping Agno para su ejecución:
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)La primera línea utiliza la función input() de Python para leer un prompt escrito por el usuario. El prompt debe describir la tarea de scraping o la pregunta que quiere que su agente maneje. La segunda línea [llama a run()] en el agente para procesar el prompt y ejecutar la tarea](https://docs.agno.com/agents/run#running-your-agent).
Para mostrar la respuesta bien formateada en su terminal, utilice:
pprint_run_response(response)Importa esta función de ayuda de Agno de la siguiente manera:
from agno.utils.pprint import pprint_run_responsepprint_run_response imprime la respuesta del agente de IA. Pero probablemente también quiera extraer y guardar los datos sin procesar devueltos por la herramienta Bright Data. Hagámoslo en el siguiente paso.
Paso 8: Exportar los datos obtenidos
Cuando ejecuta una tarea de scraping, su agente de scraping web Agno llama entre bastidores a las herramientas de Bright Data configuradas. Asegurarse de que su script también exporta los datos sin procesar devueltos por estas herramientas añade mucho valor a su flujo de trabajo. La razón es que puede reutilizar esos datos para otros escenarios (por ejemplo, análisis de datos) o casos de uso adicionales del agente.
Actualmente, su agente de raspado tiene acceso a estos dos métodos de herramientas de BrightDataTools:
scrape_as_markdown(): Raspa cualquier página web y devuelve el contenido en formato Markdown.web_data_feed(): Recupera datos JSON estructurados de sitios populares como LinkedIn, Amazon, Instagram, etc.
Por lo tanto, dependiendo de la tarea, la salida de datos raspados puede estar en formato Markdown o JSON. Para ambos casos, puede leer la salida sin procesar del resultado de la herramienta en response.tools[0].result. A continuación, intente parsearlo como JSON. Si eso falla, tratará los datos raspados como Markdown.
Implementa la lógica anterior con estas líneas de código:
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data) No olvides importar json de la biblioteca estándar de Python:
import jsonMuy bien. El flujo de trabajo de su agente de raspado web Agno ya está completo.
Paso 9: Póngalo todo junto
Este es el código final de tu archivo scraper.py:
from dotenv import load_dotenv
from agno.tools.brightdata import BrightDataTools
from agno.models.google import Gemini
from agno.agent import Agent
from agno.utils.pprint import pprint_run_response
import json
# Load the environment variables from the .env file
load_dotenv()
# Configure the Bright Data tools for Agno integration
bright_data_tools = BrightDataTools(
web_unlocker_zone="web_unlocker", # Replace with your Web Unlocker API zone name
search_engine=False, # As the SERP API tool is not required in this use case
)
# The LLM that will be used by the AI scraping agent
llm_model = Gemini(id="gemini-2.5-flash")
# Define your Agno agent with Bright Data tools
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)
# Print the agent response in the terminal
pprint_run_response(response)
# Export the scraped data
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data)En menos de 50 líneas de código, ha construido un flujo de trabajo de scraping basado en IA que puede extraer datos de cualquier página web. Este es el poder de combinar Bright Data con Agno para el desarrollo de agentes.
Paso nº 10: Ejecute su agente de raspado Agno
En su terminal, inicie su agente de raspado web Agno ejecutando:
python scraper.pySe le pedirá que introduzca una solicitud. Intente algo como:
Give me a short summary from "https://www.reuters.com/sports/formula1/hulkenberg-rids-himself-unwanted-record-239th-attempt-2025-07-06/"Debería ver un resultado similar a este:
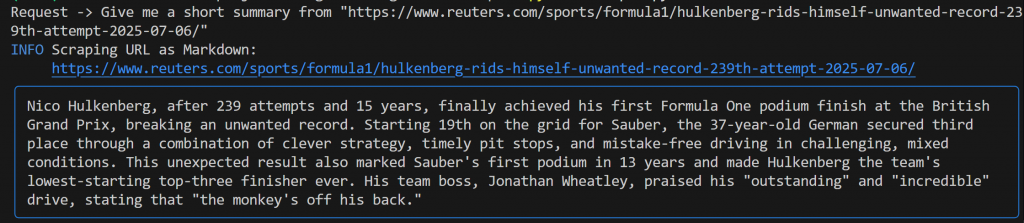
Esta salida incluye:
- El mensaje original que envió.
- Un registro que muestra qué herramienta de Bright Data se utilizó para el scraping. En este caso, confirma que se invocó
scrape_as_markdown(). - Un resumen con formato Markdown generado por Gemini, resaltado por un rectángulo azul.
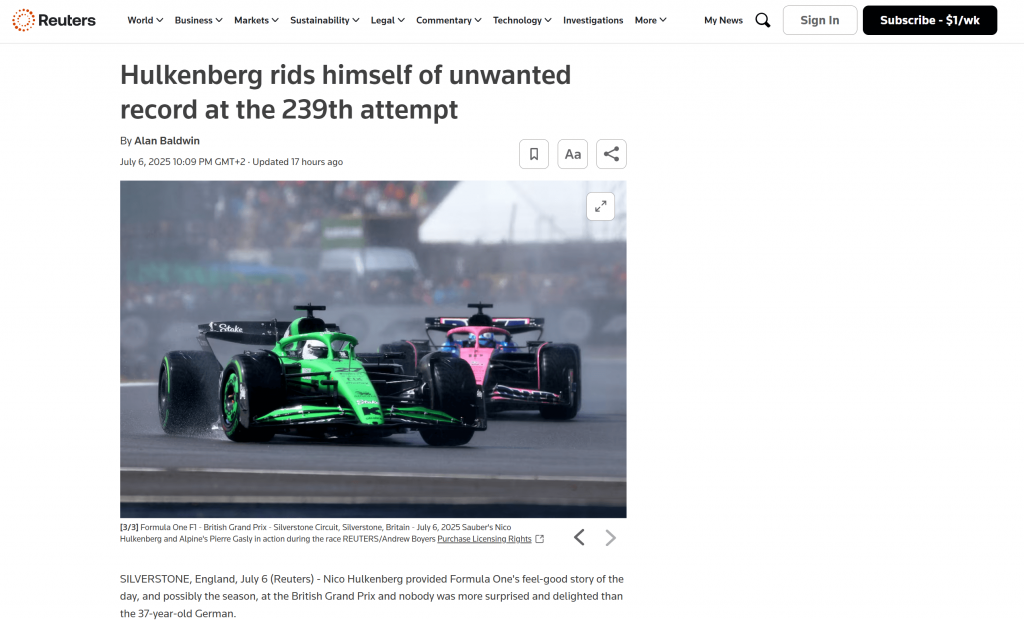
Si miras dentro de la carpeta raíz de tu proyecto, verás un nuevo archivo llamado output.md. Ábrelo en cualquier visor Markdown y obtendrás una versión Markdown del contenido de la página raspada:

Como puede ver, la salida Markdown de Bright Data captura con precisión el contenido de la página web original:
Ahora, intente lanzar su agente de raspado de nuevo con una solicitud diferente, más específica:
Summarize the main features of the product on this Amazon page: "https://www.amazon.com/PlayStation%C2%AE5-console-slim-PlayStation-5/dp/B0CL61F39H/" Esta vez, el resultado podría ser el siguiente:
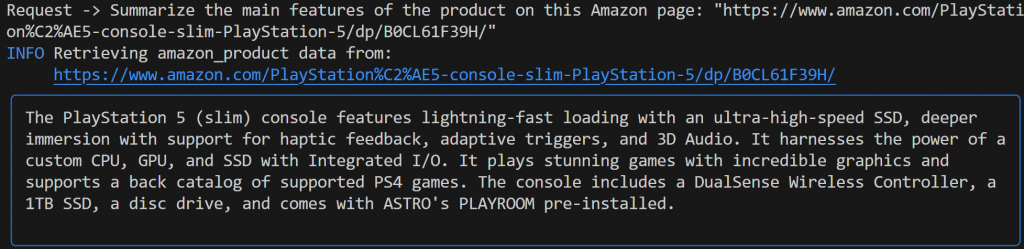
Observe cómo el agente Agno de Gemini elige automáticamente la herramienta web_data_feed, que está correctamente configurada para el scraping estructurado de páginas de productos de Amazon.
Como resultado, ahora encontrará un archivo output.json en la carpeta de su proyecto. Ábrelo y pega su contenido en cualquier visor JSON:
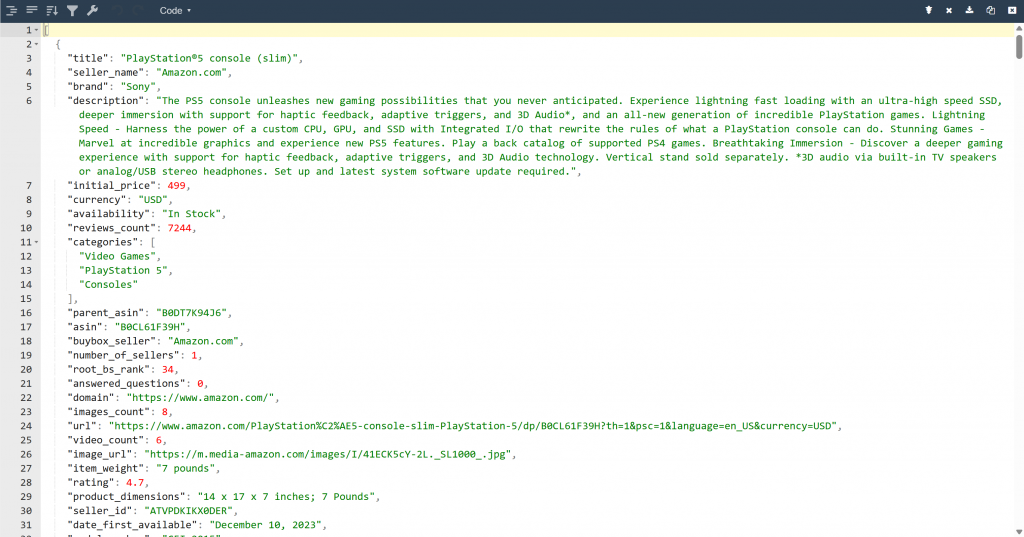
Fíjese en lo bien que la herramienta Bright Data ha extraído datos JSON estructurados de esta página de Amazon:
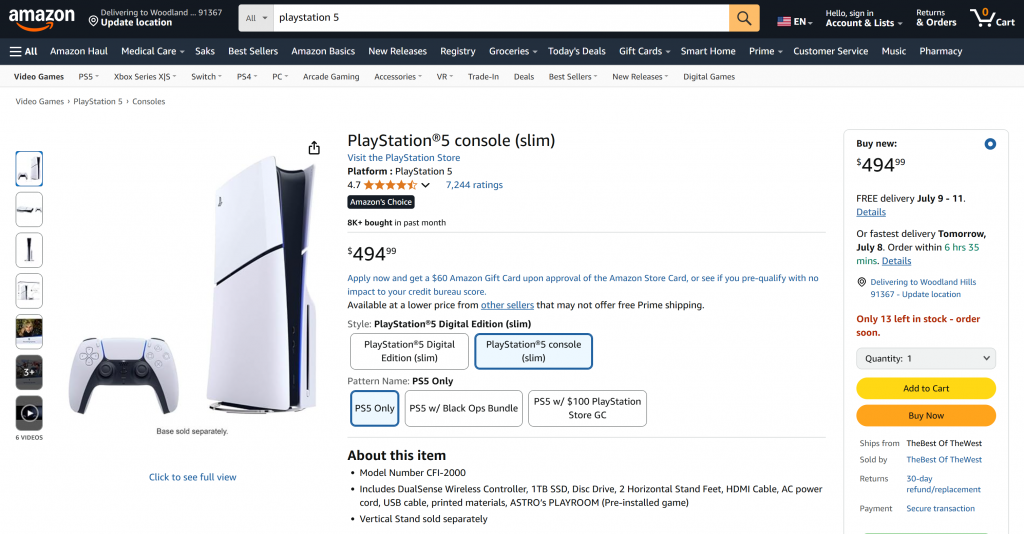
Ambos ejemplos muestran cómo su agente puede ahora recuperar datos de prácticamente cualquier página web. Esto es cierto incluso para sitios complejos como Amazon, que son famosos por sus duras defensas anti-scraping (como el famoso CAPTCHA de Amazon).
¡Et voilà! Acaba de experimentar un scraping web sin fisuras en su agente de IA, impulsado por las herramientas de Bright Data y Agno.
Próximos pasos
El agente de web scraping que acaba de construir con Agno es sólo el principio. A partir de aquí, puedes explorar varias formas de ampliar y mejorar tu proyecto:
- Incorpore una capa de memoria: Utilice la base de datos vectorial nativa de Agno para almacenar los datos que su agente recopila a través de Bright Data. Esto proporciona a su agente memoria a largo plazo, allanando el camino para casos de uso avanzados como RAG agentic.
- Creeuna interfaz fácil de usar: Cree una interfaz web o de escritorio sencilla para que los usuarios puedan chatear con su agente de forma natural y conversacional (similar a la interacción con ChatGPT o Gemini). Esto hace que su herramienta de scraping sea mucho más accesible.
- Explore integraciones más ricas: Agno ofrece una variedad de herramientas y capacidades que pueden ampliar las habilidades de su agente mucho más allá del scraping. Sumérgete en la documentación de Agno para inspirarte sobre cómo conectar más fuentes de datos, utilizar diferentes LLM u orquestar flujos de trabajo de agente de varios pasos.
Conclusión
En este artículo, has aprendido a utilizar Agno para construir un agente de IA para el web scraping. Esto fue posible gracias a la integración de Agno con las herramientas de Bright Data. Estas equipan al LLM elegido con el poder de extraer datos de cualquier sitio web.
Ten en cuenta que este es sólo un ejemplo sencillo. Si desea desarrollar agentes más avanzados, necesitará soluciones para obtener, validar y transformar datos web en tiempo real. Eso es específicamente lo que puede encontrar en la infraestructura de Bright Data AI.
Cree una cuenta gratuita en Bright Data y empiece a experimentar con nuestras herramientas de scraping preparadas para la IA.




