

En esta guía aprenderás:
- La definición de un conjunto de datos
- Las mejores formas de crear Conjuntos de datos
- Cómo crear un conjunto de datos en Python
- Cómo crear un conjunto de datos en R
¡Empecemos!
¿Qué es un conjunto de datos?
Un conjunto de datos es una recopilación de datos relacionados con un tema, asunto o sector específico. Los conjuntos de datos pueden abarcar diversos tipos de información, como números, texto, imágenes, vídeos y audio, y pueden almacenarse en formatos como CSV, JSON, XLS, XLSX o SQL.
Básicamente, un conjunto de datos comprende datos estructurados orientados a un propósito concreto.
Las 5 mejores estrategias para crear un Conjunto de datos
Explora las 5 mejores estrategias para crear Conjuntos de datos, analizando cómo funcionan y sus ventajas e inconvenientes.
Estrategia n.º 1: externalizar la tarea
Establecer y gestionar una unidad de negocio para la creación de Conjuntos de datos puede no ser factible ni práctico. Esto es especialmente cierto si se carece de los recursos internos o del tiempo necesarios. En tal caso, una estrategia eficaz para la creación de Conjuntos de datos es externalizar la tarea.
La subcontratación consiste en delegar el proceso de creación de Conjuntos de datos a expertos externos o agencias especializadas, en lugar de gestionarlo internamente. Este enfoque le permite aprovechar las habilidades de profesionales u organizaciones con experiencia en la recopilación, limpieza y formateo de datos.
¿A quién debe subcontratar la creación de Conjuntos de datos? Muchas empresas ofrecen Conjuntos de datos listos para usar o servicios de recopilación de datos personalizados. Para obtener más detalles, consulte nuestra guía sobre los mejores sitios web de Conjuntos de datos.
Estos proveedores utilizan técnicas avanzadas para garantizar que los datos recuperados sean precisos y estén formateados según sus especificaciones. Si bien la externalización le permite centrarse en otros aspectos importantes de su negocio, es esencial seleccionar un socio fiable que cumpla con sus expectativas de calidad.
Ventajas:
- No tiene que preocuparse por nada.
- Conjuntos de datos de cualquier sitio web en cualquier formato
- Datos históricos o recientes
Contras
- No tienes control total sobre el proceso de recuperación de datos
- Posibles problemas de cumplimiento de la normativa GDPR y CCPA
- Puede que no sea la solución más rentable
Estrategia n.º 2: recuperar datos de API públicas
Muchas plataformas, desde redes sociales hasta sitios de comercio electrónico, ofrecen API públicas que exponen una gran cantidad de datos. Por ejemplo, la API de X da acceso a información sobre cuentas públicas, publicaciones y respuestas.
La recuperación de datos de API públicas es una técnica eficaz para crear Conjuntos de datos. El motivo es que esos puntos finales devuelven datos en un formato estructurado, lo que facilita la generación de un conjunto de datos a partir de sus respuestas. No es de extrañar que las API sean una de las mejores estrategias para la obtención de datos.
Al aprovechar estas API, se pueden recopilar rápidamente grandes volúmenes de datos fiables directamente desde plataformas consolidadas. La principal desventaja es que hay que respetar los límites de uso y las condiciones de servicio de la API.
Ventajas:
- Acceso a datos oficiales
- Integración sencilla en cualquier lenguaje de programación
- Obtención de datos estructurados directamente de la fuente
Desventajas:
- No todas las plataformas tienen API públicas
- Debe cumplir con las limitaciones impuestas por el proveedor de la API
- Los datos devueltos por estas API pueden cambiar con el tiempo
Estrategia n.º 3: Busque datos abiertos
Los datos abiertos son conjuntos de datos que se comparten abiertamente con el público de forma gratuita. Estos datos se utilizan principalmente en investigaciones y artículos científicos, pero también pueden servir para necesidades empresariales, como el análisis de mercado.
Los datos abiertos son fiables, ya que proceden de fuentes acreditadas, como gobiernos, organizaciones sin ánimo de lucro e instituciones académicas. Estas organizaciones ofrecen repositorios de datos abiertos que abarcan una amplia gama de temas, como tendencias sociales, estadísticas sanitarias, indicadores económicos, datos medioambientales y mucho más.
Entre los sitios web más populares donde se pueden obtener datos abiertos se incluyen:
- Data.gov: un repositorio completo de datos federales de EE. UU.
- Portal de datos abiertos de la Unión Europea: ofrece Conjuntos de datos de toda Europa.
- Datos abiertos del Banco Mundial: proporciona datos económicos y de desarrollo a nivel mundial.
- Datos de la ONU: presenta una variedad de Conjuntos de datos sobre indicadores sociales y económicos globales.
- Registro de datos abiertos en AWS: una plataforma para descubrir y compartir Conjuntos de datos disponibles a través de los recursos de AWS.
Los datos abiertos son una forma popular de crear Conjuntos de datos, ya que eliminan la necesidad de recopilarlos al proporcionar datos de libre acceso. No obstante, debe revisar la calidad, la integridad y los términos de la licencia de los datos para asegurarse de que cumplen los requisitos de su proyecto.
Ventajas:
- Datos gratuitos
- Conjuntos de datos completos, grandes y listos para usar
- Conjuntos de datos respaldados por fuentes fiables, como organismos gubernamentales
Inconvenientes:
- Por lo general, solo proporciona acceso a datos históricos
- Requieren cierto trabajo para obtener información útil para su negocio
- Es posible que no encuentres los datos que te interesan
Estrategia n.º 4: descargar Conjuntos de datos de GitHub
GitHub aloja numerosos repositorios que contienen Conjuntos de datos para diversos fines, que van desde el aprendizaje automático y la ciencia de datos hasta el desarrollo de software y la investigación. Estos Conjuntos de datos son compartidos por personas y organizaciones para recibir comentarios y contribuir a la comunidad.
En algunos casos, estos repositorios de GitHub también incluyen código para procesar, analizar y explorar los datos.
Algunos repositorios destacados de los que se pueden obtener repositorios son:
- Awesome Public Datasets: una colección seleccionada de Conjuntos de datos de alta calidad de diversos ámbitos, como las finanzas, el clima y los deportes. Sirve como centro para encontrar Conjuntos de datos relacionados con temas o sectores específicos.
- Conjuntos de datos de Kaggle: Kaggle, una destacada plataforma para concursos de ciencia de datos, aloja algunos de sus conjuntos de datos en GitHub. Los usuarios pueden crear conjuntos de datos de Kaggle a partir de los repositorios de GitHub con solo unos pocos clics.
- Otros repositorios de datos abiertos: varias organizaciones y grupos de investigación utilizan GitHub para alojar Conjuntos de datos abiertos.
Estos repositorios ofrecen conjuntos de datos preexistentes que se pueden utilizar o adaptar fácilmente para satisfacer sus necesidades. Para acceder a ellos, solo hay que ejecutar un comando git clone o hacer clic en el botón «Descargar».
Ventajas:
- Conjuntos de datos listos para usar
- Código para analizar e interactuar con los datos
- Muchas categorías diferentes de datos entre las que elegir
Inconvenientes:
- Posibles problemas con las licencias
- La mayoría de estos repositorios no están actualizados
- Datos genéricos, no adaptados a sus necesidades
Estrategia n.º 5: cree su propio conjunto de datos con Scraping web
El scraping web es el proceso de extraer datos de páginas web y convertirlos a un formato utilizable.
La creación de conjuntos de datos mediante el Scraping web es un enfoque muy popular por varias razones:
- Acceso a gran cantidad de datos: la web es la mayor fuente de datos del mundo. El scraping web le permite aprovechar este amplio recurso y recopilar información que quizá no esté disponible por otros medios.
- Flexibilidad: puede elegir qué datos recuperar, el formato en el que producir los Conjuntos de datos y controlar la frecuencia con la que se actualizan los datos.
- Personalización: adapte la extracción de datos a sus necesidades específicas, como la extracción de datos de nichos de mercado o temas especializados que no están cubiertos por los Conjuntos de datos públicos.
Así es como funciona normalmente el Scraping web:
- Identifica el sitio de destino.
- Inspeccione sus páginas web para diseñar una estrategia de extracción de datos
- Cree un script para conectarse a las páginas de destino.
- Realice el parseo del contenido HTML de las páginas
- Seleccionar los elementos DOM que contienen los datos de interés
- Extraiga los datos de estos elementos
- Exportar los datos recopilados al formato deseado, como JSON, CSV o XLSX.
Tenga en cuenta que el script para realizar el Scraping web se puede escribir en prácticamente cualquier lenguaje de programación, como Python, JavaScript o Ruby. Obtenga más información en nuestro artículo sobre los mejores lenguajes para el Scraping web. Además, eche un vistazo a las mejores herramientas para el Scraping web.
Dado que la mayoría de las empresas saben lo valiosos que son sus datos, incluso si son de acceso público en su sitio web, los protegen con tecnologías antibots. Estas soluciones pueden bloquear las solicitudes automatizadas realizadas por sus scripts. Vea cómo eludir estas medidas en nuestro tutorial sobre cómo realizar Scraping web sin ser bloqueado.
Además, si tienes curiosidad por saber en qué se diferencia el Scraping web de la obtención de datos de API públicas, echa un vistazo a nuestro artículo sobre Scraping web frente a API.
Ventajas:
- Datos públicos de cualquier sitio web
- Tienes control sobre el proceso de extracción de datos
- Solución rentable que funciona con la mayoría de los lenguajes de programación
Desventajas:
- Las soluciones antibots y antiscraping pueden impedirte acceder
- Requiere cierto mantenimiento
- Puede requerir una lógica de agregación de datos personalizada
Cómo crear Conjuntos de datos en Python
Python es un lenguaje líder en ciencia de datos y, por lo tanto, es una opción popular para crear Conjuntos de datos. Como verás, crear un conjunto de datos en Python solo requiere unas pocas líneas de código.
Aquí nos centraremos en extraer información sobre todos los Conjuntos de datos disponibles en el mercado de Conjuntos de datos de Bright Data:
¡Siga el tutorial guiado para lograr el objetivo!
Para obtener instrucciones más detalladas, consulte nuestra guía de Scraping web con Python.
Paso 1: Instalación y configuración
Supondremos que tiene Python 3+ instalado en su máquina y que tiene un proyecto Python configurado.
En primer lugar, debe instalar las bibliotecas necesarias para este proyecto:
- requests: para enviar solicitudes HTTP y recuperar los documentos HTML asociados a las páginas web.
- Beautiful Soup: para el parseo de documentos HTML y XML y la extracción de datos de páginas web.
- pandas: para manipular datos y exportarlos a Conjuntos de datos CSV.
Abra el terminal en el entorno virtual activado en la carpeta de su proyecto y ejecute:
pip install requests beautifulsoup4 pandasUna vez instaladas, puede importar estas bibliotecas a su script de Python:
import requests
from bs4 import BeautifulSoup
import pandas as pdPaso 2: Conéctese al sitio de destino
Recupere el HTML de la página de la que desea extraer datos. Utilice la biblioteca requests para enviar una solicitud HTTP al sitio de destino y recuperar su contenido HTML:
url = 'https://brightdata.com/products/Conjuntos de datos'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)Para obtener más información, consulte nuestra guía sobre cómo configurar un agente de usuario en solicitudes de Python.
Paso 3: Implementar la lógica de scraping
Con el contenido HTML en mano, realice el parseo con BeautifulSoup y extraiga los datos que necesite. Seleccione los elementos HTML que contienen los datos de interés y obtenga los datos de ellos:
# analizar el HTML recuperado
soup = BeautifulSoup(response.text, 'html.parser')
# dónde almacenar los datos extraídos
data = []
# lógica de extracción
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})Paso 4: Exportar a CSV
Utiliza pandas para convertir los datos extraídos en un DataFrame y exportarlos a un archivo CSV.
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)Paso 5: Ejecutar el script
Tu script Python final contendrá estas líneas de código:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# realizar una solicitud GET al sitio de destino con un agente de usuario personalizado
url = 'https://brightdata.com/products/Conjuntos de datos'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)
# analizar el HTML recuperado
soup = BeautifulSoup(response.text, 'html.parser')
# dónde almacenar los datos extraídos
data = []
# lógica de extracción
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})
# exportar a CSV
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)Ejecútalo y aparecerá el siguiente archivo dataset.csv en la carpeta de tu proyecto:
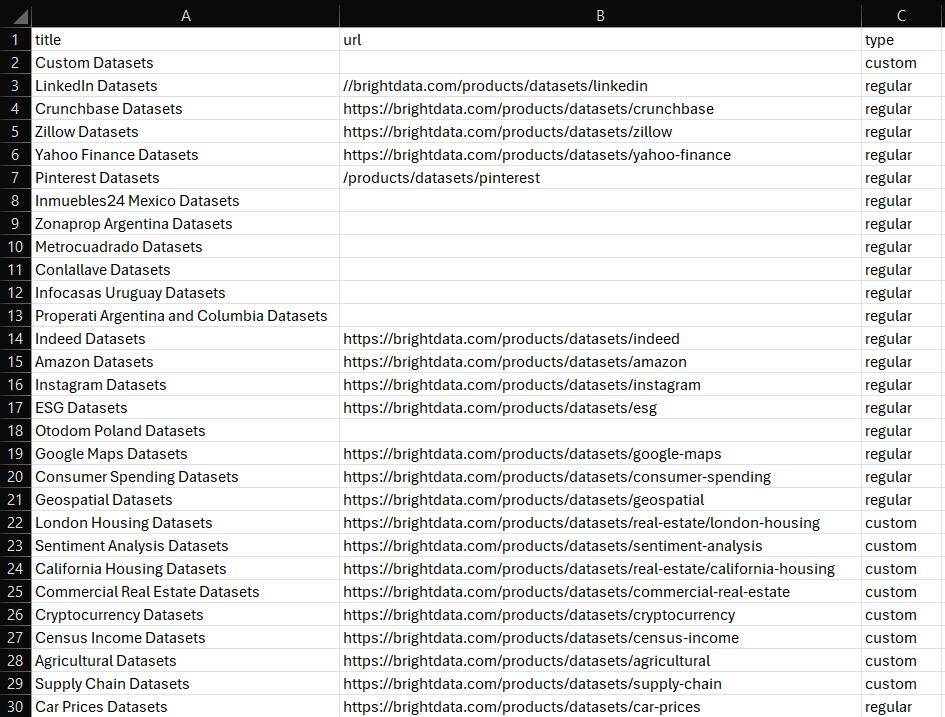
¡Et voilà! Ahora ya sabes cómo crear Conjuntos de datos en Python.
Cómo crear un conjunto de datos en R
R es otro lenguaje muy utilizado por investigadores y científicos de datos. A continuación se muestra el script equivalente, según lo que vimos antes en Python, para crear un Conjunto de datos en R:
library(httr)
library(rvest)
library(dplyr)
library(readr)
# realizar una solicitud GET al sitio de destino con un agente de usuario personalizado
url <- "https://brightdata.com/products/Conjuntos de datos"
headers <- add_headers(`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
response <- GET(url, headers)
# analizar el HTML recuperado
page <- read_html(response)
# dónde almacenar los datos extraídos
data <- tibble()
# lógica de extracción
dataset_elements <- page %>%
html_nodes(".datasets__loop .datasets__item--wrapper")
for (dataset_element in dataset_elements) {
title <- dataset_element %>%
html_node(".datasets__item .datasets__item--title") %>%
html_text(trim = TRUE)
url_item <- dataset_element %>%
html_node(".datasets__item .datasets__item--title a")
url <- if (!is.null(url_item)) {
html_attr(url_item, "href")
} else {
""
}
type <- dataset_element %>%
html_attr("aria-label", "regular") %>%
tolower()
data <- bind_rows(data, tibble(
title = title,
url = url,
type = type
))
}
# exportar a CSV
write_csv(data, "dataset.csv")Para obtener más información, siga nuestro tutorial sobre Scraping web con R.
Conclusión
En esta entrada del blog, ha aprendido a crear Conjuntos de datos. Ha comprendido qué es un conjunto de datos y ha explorado diferentes estrategias para crearlo. También ha visto cómo aplicar la estrategia de Scraping web en Python y R.
Bright Data opera una red de Proxies grande, rápida y fiable, que presta servicio a muchas empresas de la lista Fortune 500 y a más de 20 000 clientes. Se utiliza para recuperar datos de la web de forma ética y ofrecerlos en un amplio mercado de Conjuntos de datos, que incluye:
- Conjuntos de datos empresariales: datos de fuentes clave como LinkedIn, CrunchBase, Owler e Indeed.
- Conjuntos de datos de comercio electrónico: datos de Amazon, Walmart, Target, Zara, Zalando, Asos y muchos más.
- Conjuntos de datos inmobiliarios: datos de sitios web como Zillow, MLS y otros.
- Conjuntos de datos de redes sociales: datos de Facebook, Instagram, YouTube y Reddit.
- Conjuntos de datos financieros: datos de Yahoo Finance, Market Watch, Investopedia y otros.
Si estas opciones predefinidas no satisfacen sus necesidades, considere nuestros servicios de recopilación de datos personalizados.
Además, Bright Data ofrece una amplia gama de potentes herramientas de scraping, incluidas las API Web Scraper y el Navegador de scraping.
Regístrese ahora y descubra cuáles de los productos y servicios de Bright Data se adaptan mejor a sus necesidades.




