

En esta guía, verás:
- Qué es un Scraper de Crunchbase y cómo funciona
- Qué datos puede recopilar automáticamente de Crunchbase
- Cómo crear un script de scraping de Crunchbase con Python
- Por qué es posible que necesite una solución más avanzada para extraer datos del sitio
¡Empecemos!
¿Qué es un Scraper de Crunchbase?
Un scraper de Crunchbase es una herramienta automatizada diseñada para extraer datos de las páginas web de Crunchbase. Navega por el sitio, identifica la información deseada y la recopila mediante el Scraping web.
Crunchbase emplea medidas avanzadas contra los bots y el scraping para proteger sus datos. Como resultado, un Scraper eficaz para Crunchbase debe incluir características como la representación de JavaScript, la Resolución de CAPTCHA y la suplantación de huellas digitales del navegador.
Qué datos extraer de Crunchbase
A continuación se muestra una lista de los datos que se pueden recuperar automáticamente de Crunchbase mediante Scraping web:
- Información de la empresa: nombre, descripción, sector, ubicación de la sede, fecha de fundación, estado (por ejemplo, activa, adquirida) y más.
- Datos de financiación: importe total de la financiación, rondas de financiación, inversores y mucho más.
- Personas clave: fundadores, ejecutivos, miembros, funciones y cargos, y más.
- Productos y servicios: descripciones de productos, categorías de productos o servicios ofrecidos, y más.
- Adquisiciones y fusiones: detalles de las empresas adquiridas, fechas y condiciones de las adquisiciones, y más.
- Datos financieros y de mercado: estimaciones de ingresos, número de empleados, etc.
- Noticias y eventos: comunicados de prensa, hitos o eventos significativos, y más
- Competidores: lista de empresas competidoras y más
Cómo crear un Scraper de Crunchbase en Python
En esta sección del tutorial, aprenderás a crear un Scraper de Crunchbase utilizando Python. El objetivo es desarrollar un script que pueda recopilar automáticamente datos de la página de Bright Data Crunchbase:
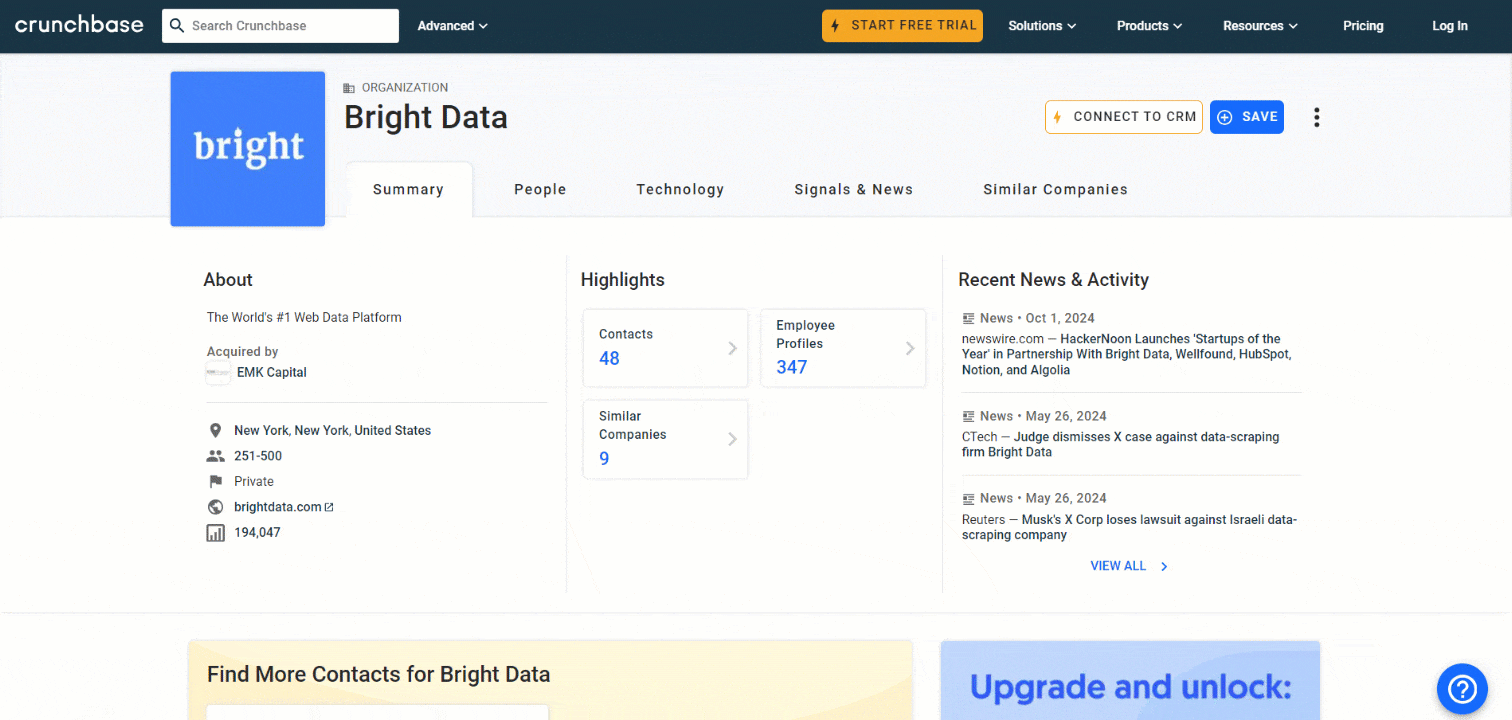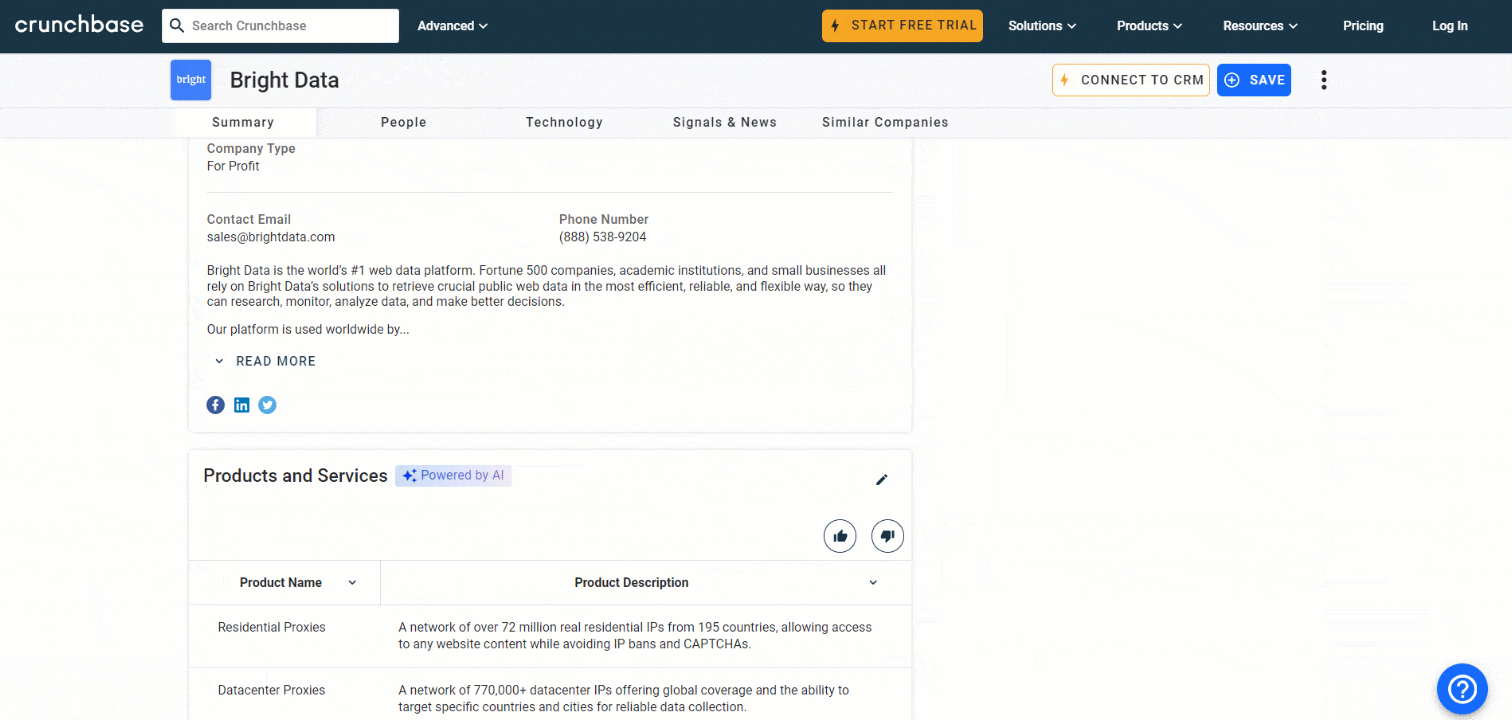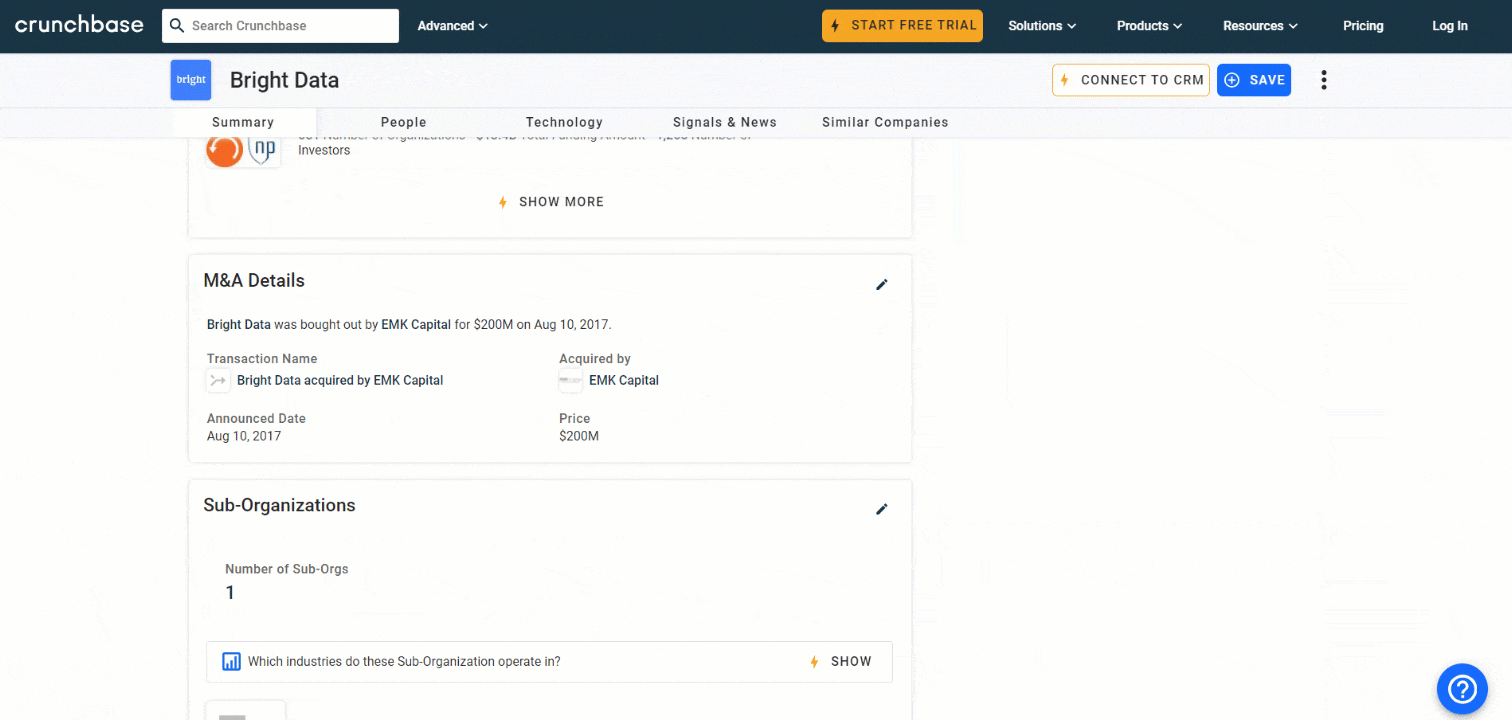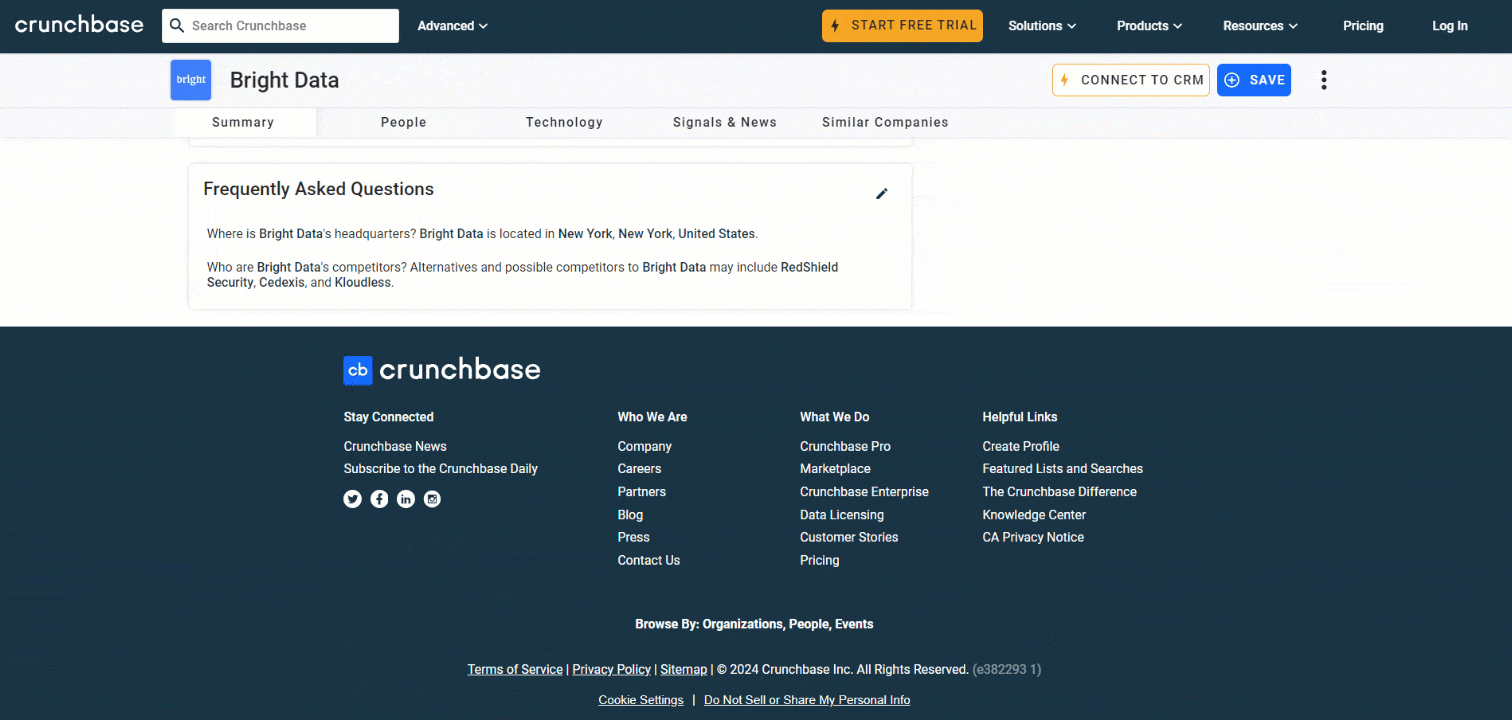
Sigue los pasos que se indican a continuación para ver cómo extraer datos de Crunchbase con Python.
Paso n.º 1: crear un proyecto Python
En primer lugar, asegúrate de tener Python 3+ instalado en tu equipo. Si no es así, descárgalo desde el sitio web oficial y sigue las instrucciones.
Crea un directorio para tu Scraper de Crunchbase en Python:
mkdir crunchbase-scraperLa carpeta crunchbase-scraper contendrá su bot de rastreo.
Abre la carpeta del proyecto en tu IDE de Python favorito, como PyCharm Community Edition o Visual Studio Code con la extensión Python.
A continuación, cree un archivo scraper.py dentro de la carpeta del proyecto. Ese archivo contendrá la lógica de rastreo de Crunchbase.
Ahora, inicializa un entorno virtual Python. Si eres usuario de macOS o Linux, ejecuta:
python3 -m venv envDe forma equivalente, en Windows, ejecuta:
python -m venv envEsto añadirá un directorio env a tu proyecto.
En este momento, tu proyecto debería tener la siguiente estructura:

Activa el entorno virtual con este comando:
source env/bin/activateO, en Windows:
envScriptsactivate¡Genial! Ahora tienes un proyecto Python en el que puedes instalar dependencias locales.
Ten en cuenta que puedes ejecutar tu script con:
python3 Scraper.pyO, en Windows:
python Scraper.pyPaso n.º 2: Determinar e instalar las bibliotecas de scraping
Ahora debe averiguar qué bibliotecas de scraping son las más adecuadas para extraer datos de Crunchbase. Comience por realizar una solicitud HTTP GET a la página web de destino utilizando un cliente HTTP de escritorio. Este es el resultado que obtendrá:
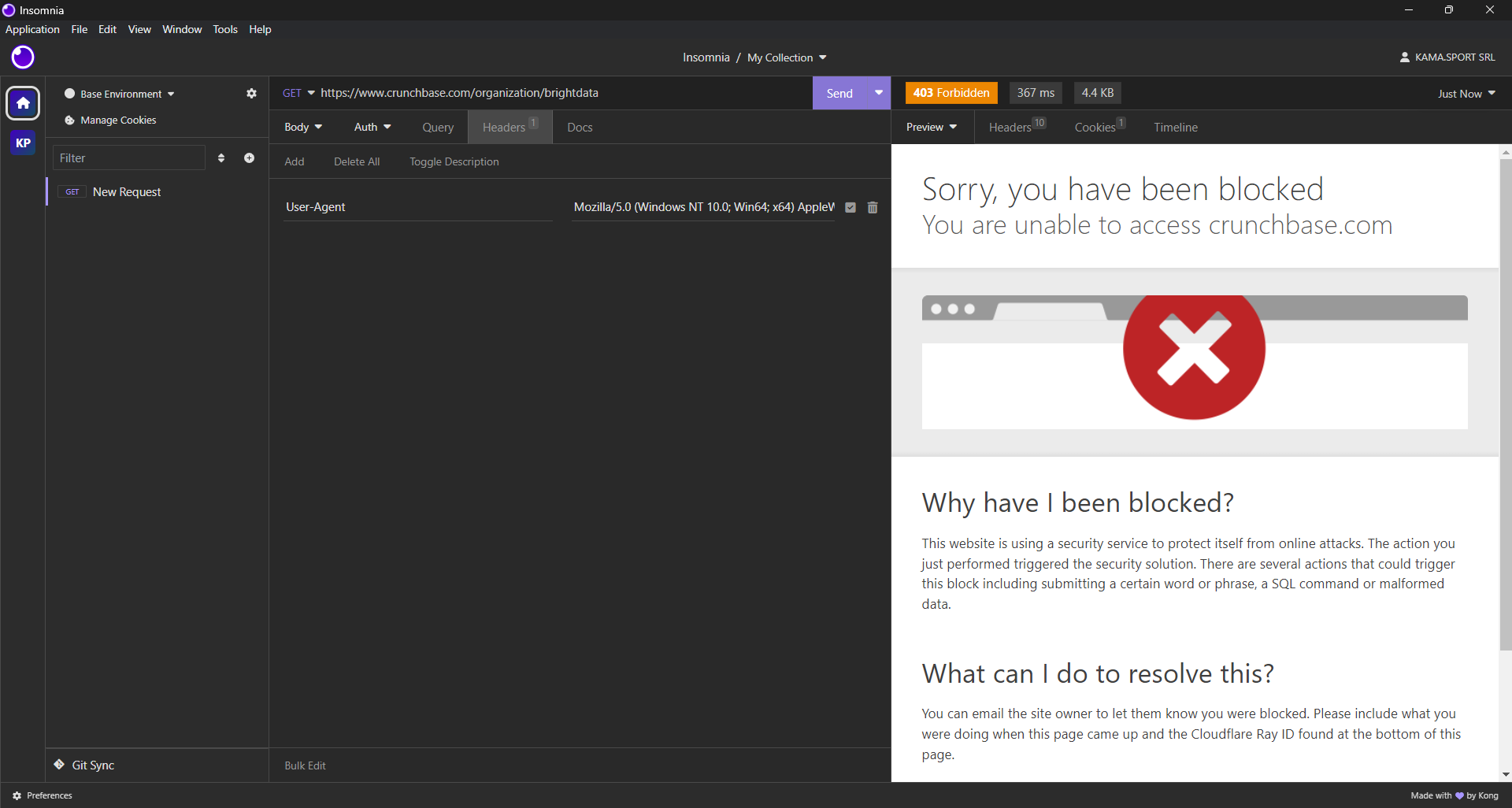
Como puede ver, Crunchbase bloquea su solicitud, incluso si utiliza encabezados de navegador realistas. En otras palabras, necesitará una herramienta de automatización del navegador para extraer datos de Crunchbase de forma eficaz. Obtenga más información en nuestro artículo sobre los mejores navegadores sin interfaz gráfica.
Para Python, Selenium es una de las herramientas de automatización de navegadores sin interfaz más populares. En concreto, le permite indicar a un navegador que realice interacciones específicas y extraiga datos de páginas dinámicas.
Para instalar Selenium, utilice el paquete pip selenium. En un entorno virtual Python activado, ejecute el siguiente comando:
pip install -U seleniumA continuación, importe Selenium en su archivo scraper.py con la siguiente línea:
from selenium import webdriver¡Genial! Ahora tienes todo lo que necesitas para realizar el Scraping web en Crunchbase.
Paso n.º 3: Visite la página de destino
Inicializa una instancia de Chrome WebDriver y utiliza el método get() para indicar al navegador controlado que visite la página deseada:
driver = webdriver.Chrome()
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)A continuación, no olvide cerrar WebDriver y liberar los recursos del navegador con:
driver.quit()Actualmente, su script de Scraper de Crunchbase contendrá:
from selenium import webdriver
# inicializar el controlador para controlar una instancia de Chrome
# en modo encabezado
driver = webdriver.Chrome()
# navegar a la página deseada de Crunchbase
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)
# lógica de rastreo...
# cerrar el controlador y liberar los recursos del navegador
driver.quit()Si lo ejecutas, verás la siguiente página durante una fracción de segundo antes de que el script termine:
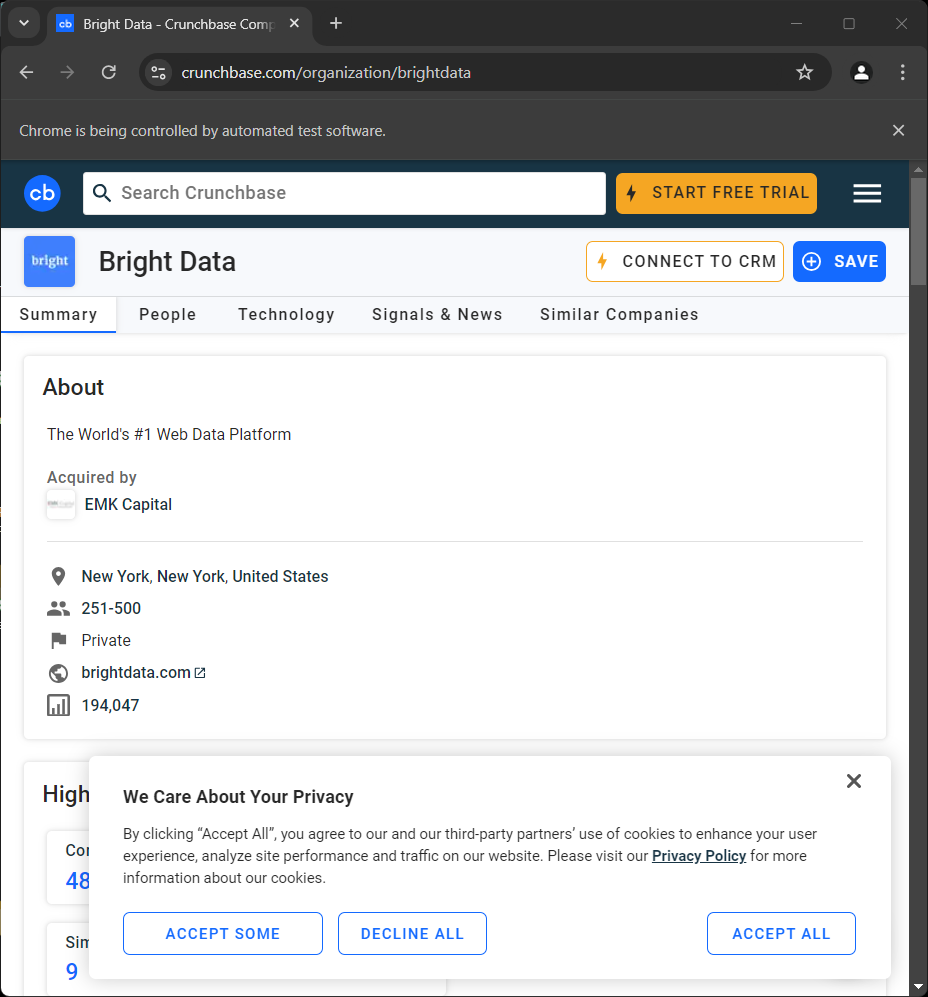
El mensaje «Chrome está siendo controlado por un software de prueba» indica que Selenium está funcionando en Chrome según lo previsto.
Por lo general, los navegadores de los scripts de scraping de Selenium se inician en modo sin interfaz gráfica para ahorrar recursos. Desafortunadamente, Crunchbase tiene un avanzado sistema de detección de bots que bloquea los navegadores sin interfaz gráfica. Por lo tanto, es necesario mantener el navegador en modo con interfaz gráfica. Como alternativa, puede intentar utilizar Playwright Stealth para eludir estos mecanismos de detección.
Paso n.º 4: gestionar la ventana emergente de cookies
Si es un usuario europeo, la página mostrará la siguiente ventana emergente de cookies después de unos segundos:
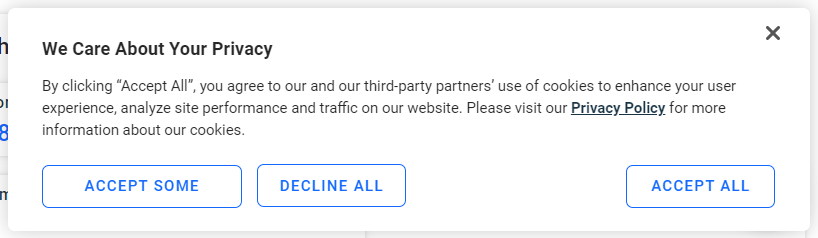
Si no haces clic en el botón «Aceptar todo», no podrás interactuar con la página. Inspecciona el botón:
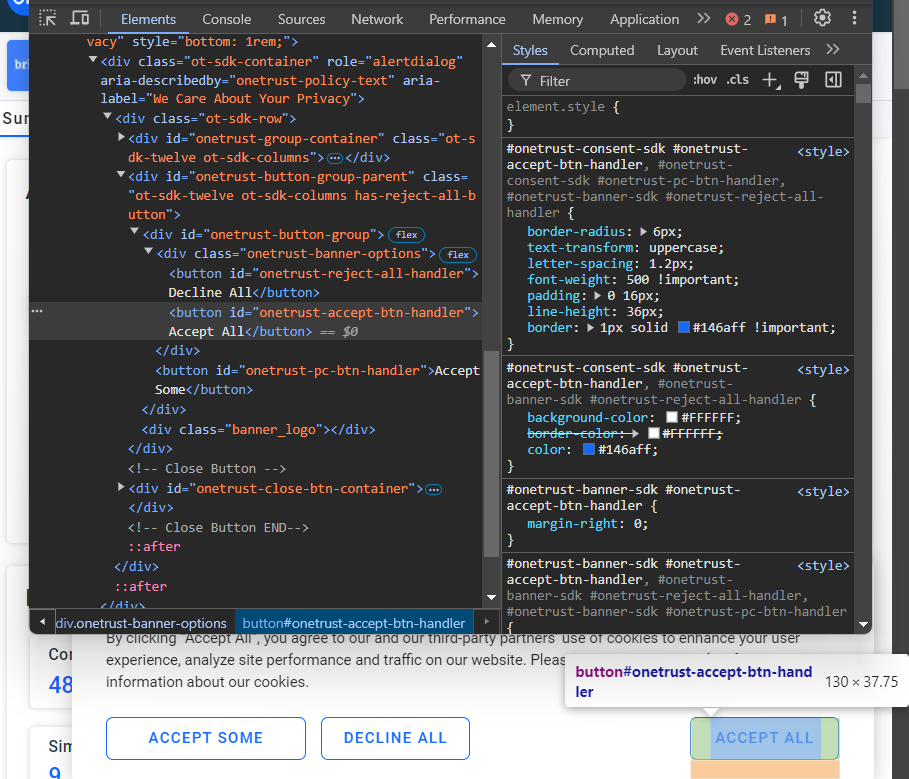
Verás que puedes seleccionarlo con el selector CSS #onetrust-accept-btn-handler.
Ahora, escribe una función que espere hasta 60 segundos a que el botón «Aceptar todo» aparezca en la página y se pueda pulsar, y luego haz clic en él:
def handle_cookie_banner(driver, seconds=60):
try:
# espera el número de segundos indicado para que aparezca en la página el botón «Aceptar todo»
# del banner de cookies
accept_button = WebDriverWait(driver, seconds).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))
)
# hacer clic en el banner mediante JavaScript para evitar
# errores ElementClickInterceptedException
driver.execute_script("arguments[0].click();", accept_button)
print("Se ha hecho clic en el botón 'Aceptar todo'")
except:
print("No se ha encontrado el botón 'Aceptar todo' en {segundos} segundos")Tenga en cuenta que:
- El bloque
try ... exceptes necesario porque es posible que la ventana emergente de cookies no aparezca en la página. En ese caso,WebDriverWait generaráunaexcepción NoSuchElementException, que será detectada porexcept. - Se hace clic en «Aceptar todo» mediante JavaScript y no a través del método
click(). El motivo es que el botón HTML aparece lentamente con una animación de fundido. Por lo tanto, si intenta hacer clic en él conclick(), es posible que obtenga unaexcepción ElementClickInterceptedException.
Para que funcione, la función anterior requiere las siguientes importaciones:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import ByAhora puede gestionar la ventana emergente de cookies llamando a:
handle_cookie_banner(driver)¡Fantástico! Prepárese para empezar a extraer datos de la página.
Paso n.º 5: extraer la información «Acerca de»
La primera información que se debe extraer de la tarjeta «Resumen» es la descripción «Acerca de» de la empresa:
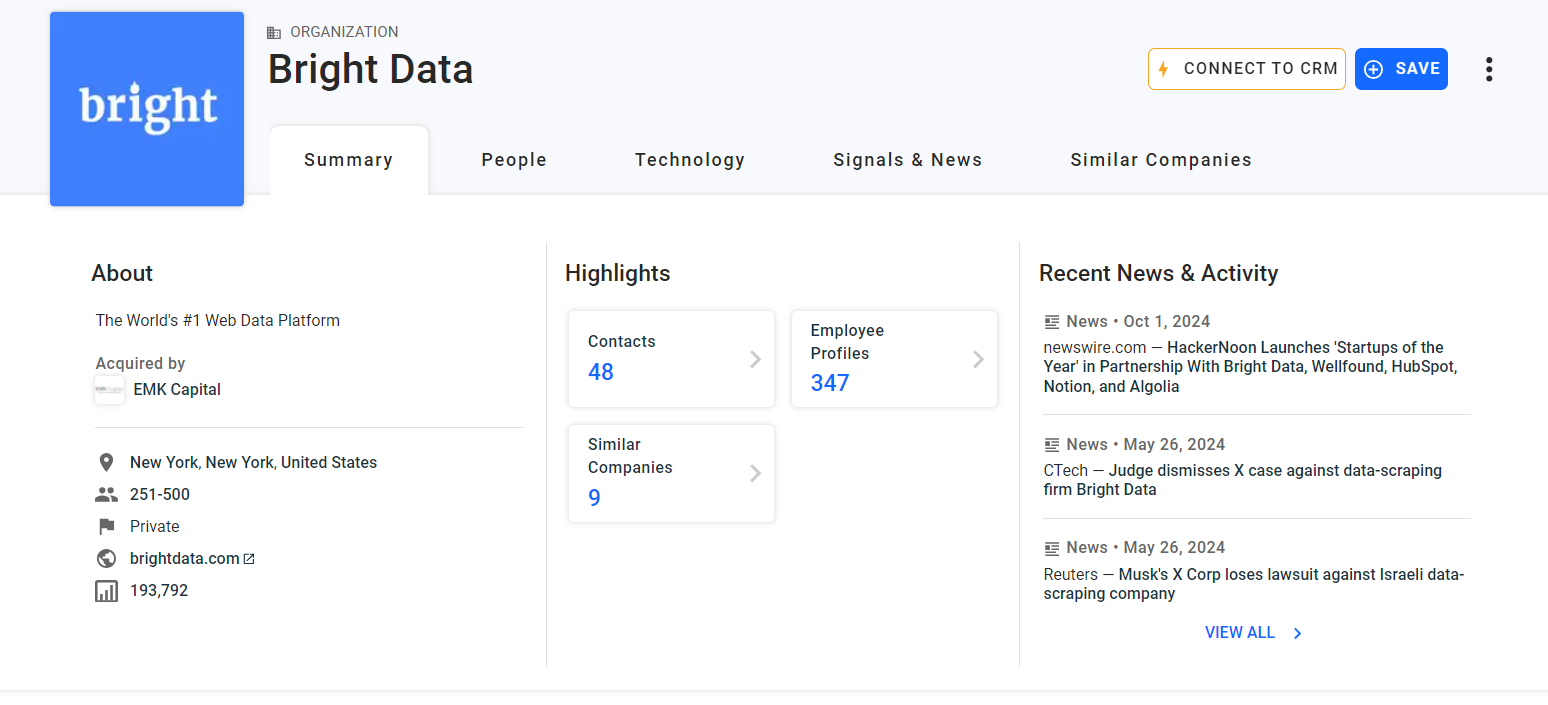
Inspeccione el elemento HTML «Acerca de»:
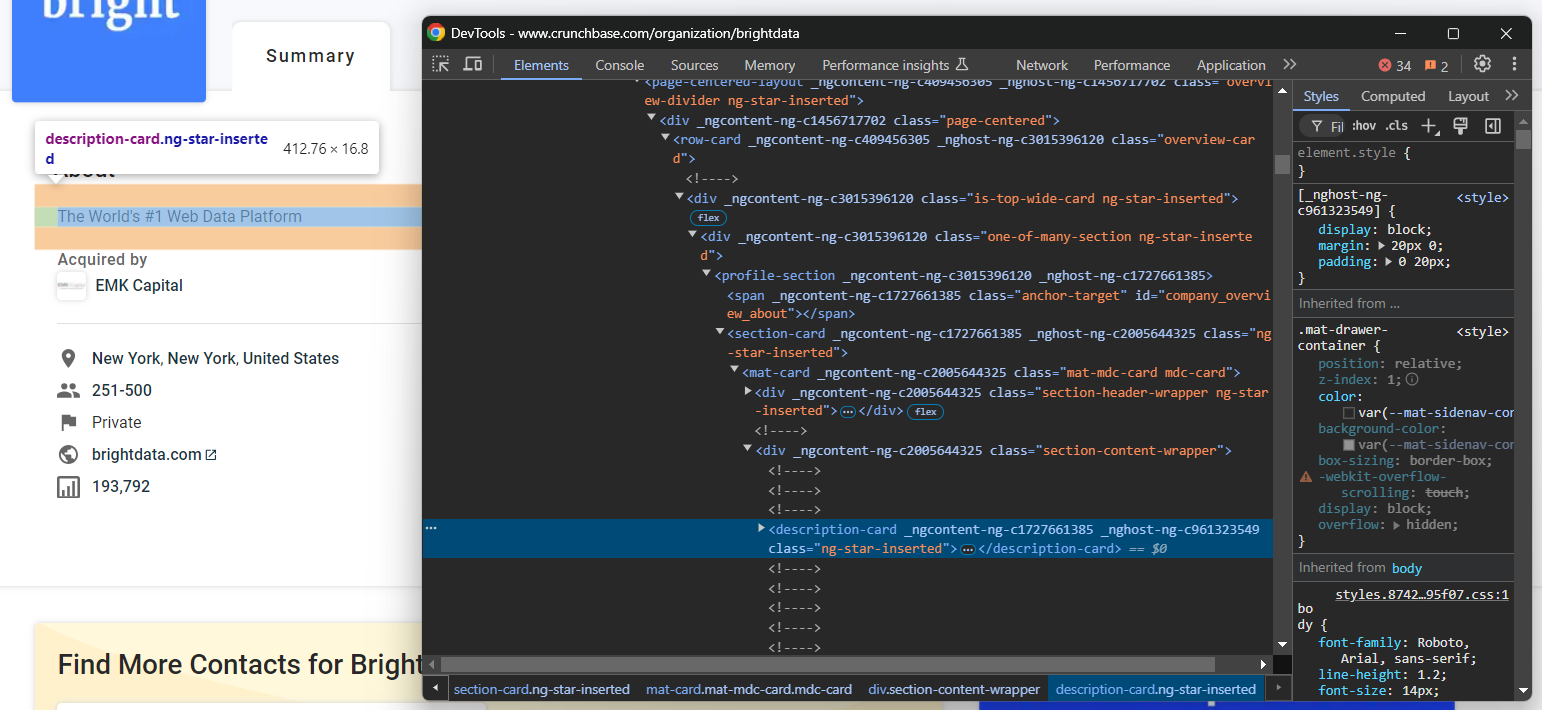
Ten en cuenta que puedes seleccionarlo con el selector CSS siguiente:
profile-section description-cardUtilice el método find_element() para aplicar el selector CSS en la página. A continuación, extraiga el texto dentro del nodo con el atributo de texto:
about_node = driver.find_element(By.CSS_SELECTOR, "profile-section description-card")
about = about_node.textLa variable about ahora contendrá:
«La plataforma de datos web n.º 1 del mundo»¡Ya está!
Paso n.º 6: inspeccionar la estructura de la página
Ahora, concéntrese en la información contenida en la tarjeta «Detalles» de la página:
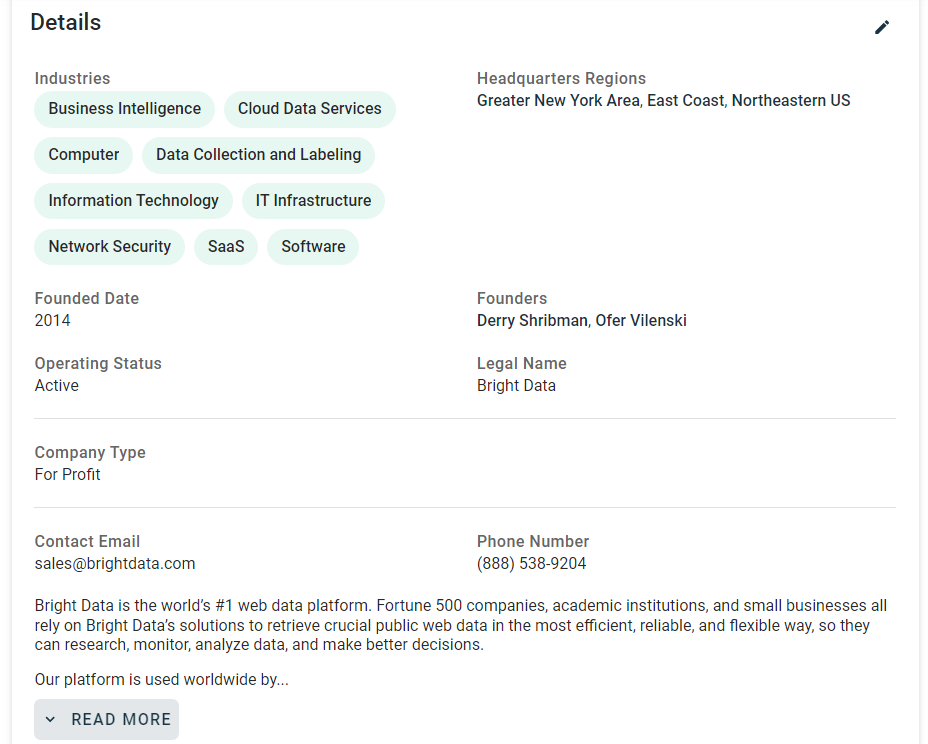
Si inspecciona esta sección, observará que no hay una forma fácil de seleccionar los elementos HTML de los que extraer datos:
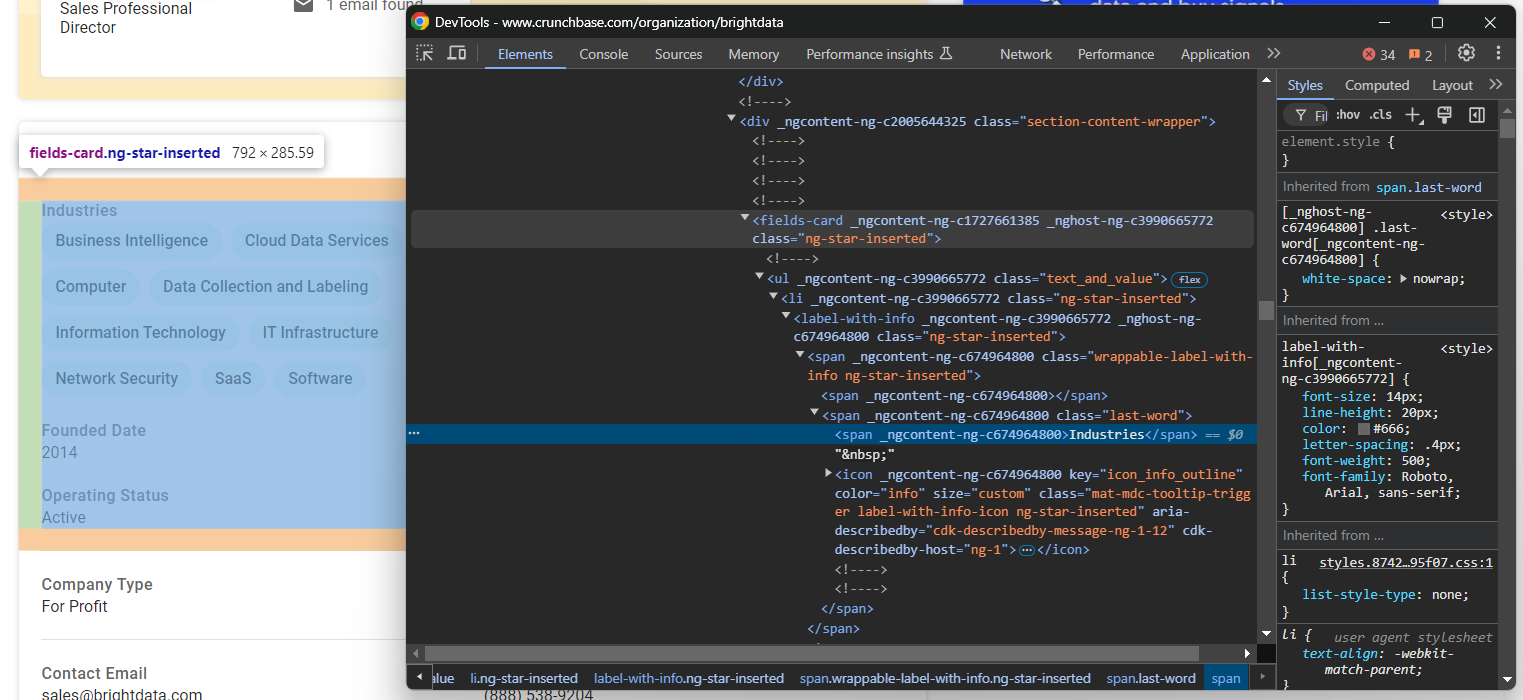
La mayoría de estos nodos tienen atributos HTML aleatorios que probablemente se generan en el momento de la compilación. Estos atributos cambian después de cada implementación, por lo que no se puede confiar en ellos para la selección de nodos. Además, muchos de estos elementos no están marcados con clases o ID únicas.
Un enfoque eficaz para seleccionar los elementos de interés es centrarse en sus etiquetas. Por ejemplo, puede seleccionar el nodo fields-card que contiene la información de las industrias identificando qué fields-card tiene un nodo label-with-info que contiene la cadena «Industries».
Esta técnica se utilizará para extraer datos de esta sección. Por lo tanto, tiene sentido centralizar la lógica en una función:
def find_parent_node_based_on_child_node_text(parent_nodes_selector, child_node_selector, text):
# seleccionar todos los nodos padres
parent_nodes = driver.find_elements(By.CSS_SELECTOR, parent_nodes_selector)
# iterar a través de los nodos padres para encontrar el que
# cuyo nodo hijo específico contenga el texto deseado
for parent_node in parent_nodes:
try:
# obtener el nodo hijo específico dentro del nodo padre actual
child_node = parent_node.find_element(By.CSS_SELECTOR, child_node_selector)
# comprobar si contiene el texto deseado
if text.upper() in child_node.text.upper():
return parent_node
except:
continue
return NoneUtiliza la función anterior para seleccionar el nodo «Industries» de la tarjeta de campos con:
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")¡Genial! Ahora será mucho más fácil extraer datos de Crunchbase.
Paso n.º 7: extraer los datos de la empresa
Inspeccione el nodo «Industries»:
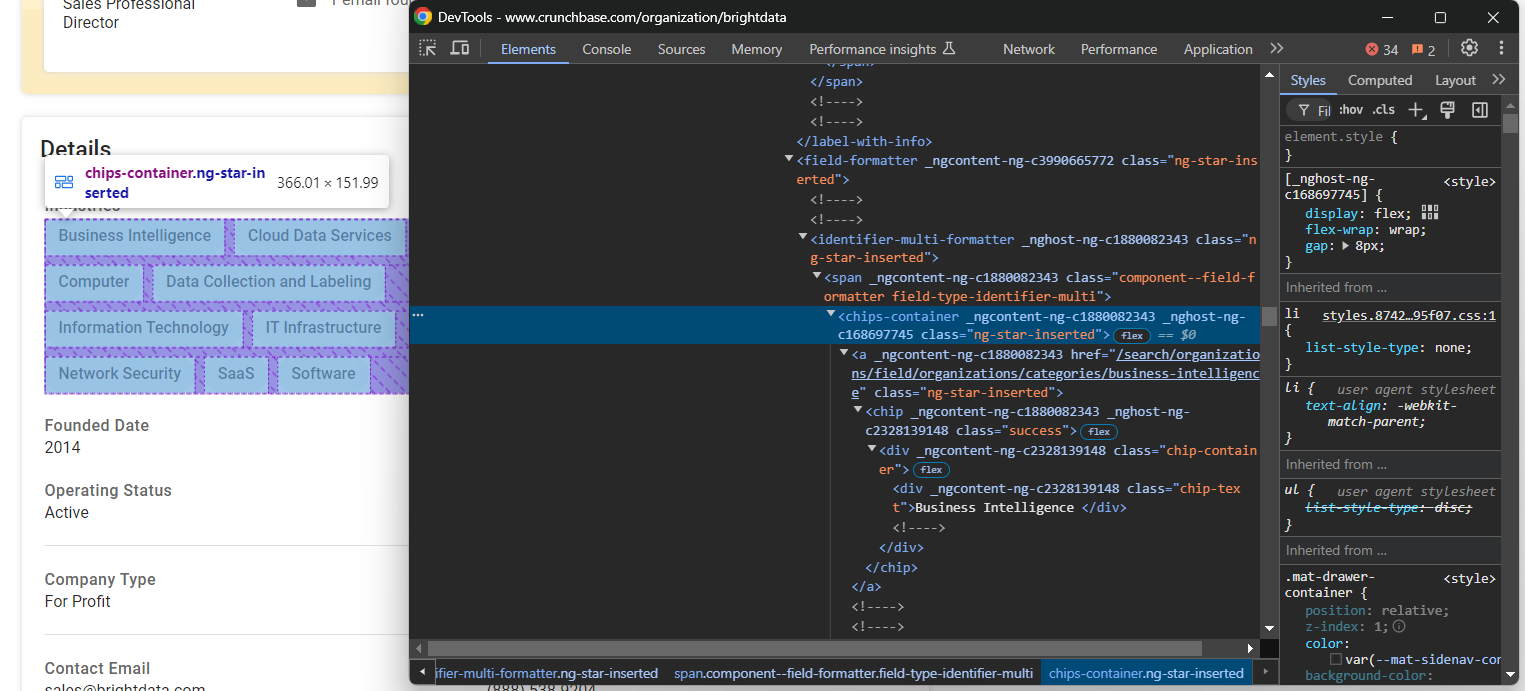
Que almacena las industrias en las que opera la empresa almacenadas en chips-container a nodes. Selecciónelos todos, itere sobre ellos y extraiga los datos:
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")
industries_nodes = industries_parent_node.find_elements(By.CSS_SELECTOR, "chips-container a")
industries = []
for industry_node in industries_nodes:
industries.append(industry_node.text)Ahora, centrémonos en el elemento «Founded Date» (Fecha de fundación):
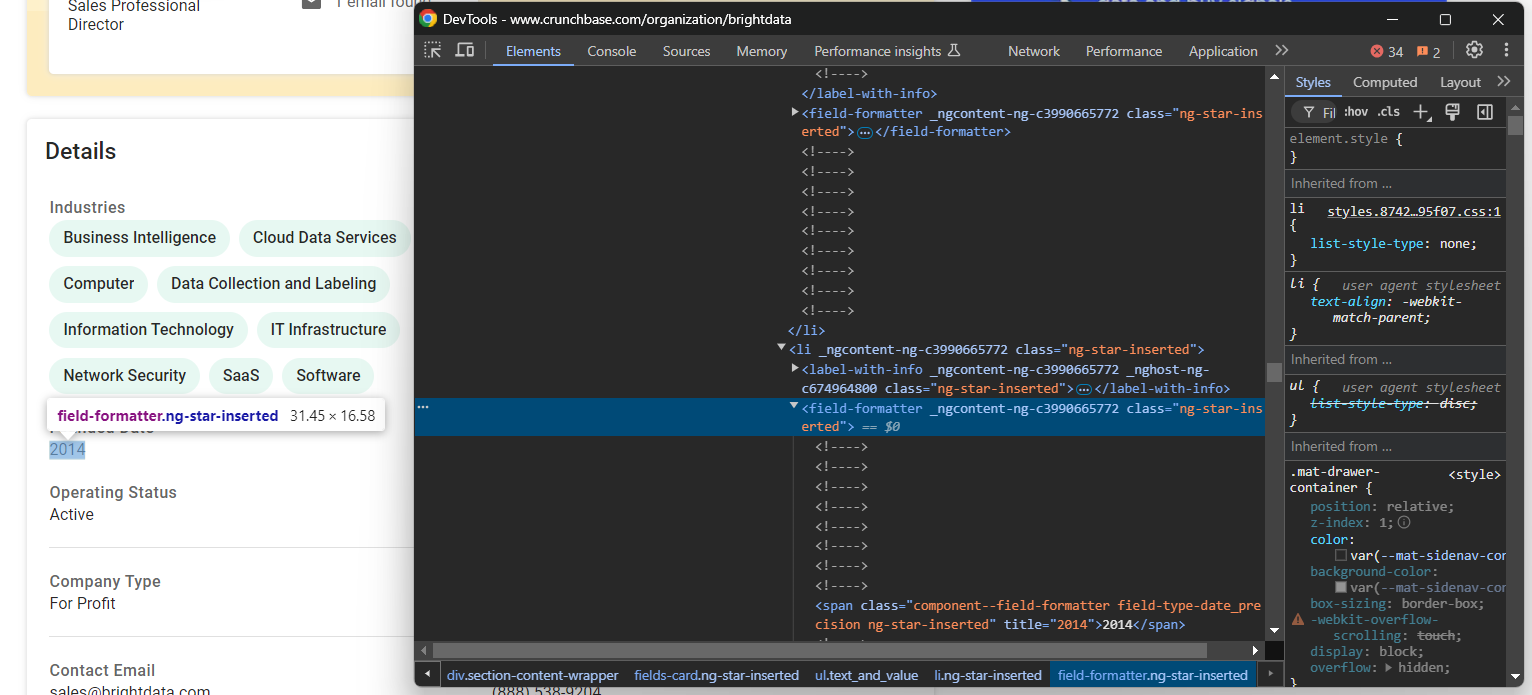
En este caso, la lógica de extracción es más sencilla, ya que solo hay que extraer el texto del elemento field-formatter dentro del nodo padre fields-card li:
founded_date_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Founded Date")
founded_date_node = founded_date_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
founded_date = founded_date_node.textLa misma lógica se puede aplicar a la mayoría de los demás elementos de detalles de la empresa:
company_type_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Company Type")
company_type_node = company_type_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
company_type = company_type_node.text
operating_status_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Operating Status")
operating_status_node = operating_status_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
operating_status = operating_status_node.text
headquarters_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Regiones de la sede central")
headquarters_node = headquarters_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
headquarters = headquarters_node.text
nodo_padre_nombre_legal = encontrar_nodo_padre_basado_en_texto_nodo_hijo("campos-tarjeta li", "etiqueta-con-información", "Nombre legal")
nodo_nombre_legal = nodo_padre_nombre_legal.encontrar_elemento(By.CSS_SELECTOR, "formateador-de-campos")
nombre_legal = nodo_nombre_legal.texto
contact_email_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Correo electrónico de contacto")
contact_email_node = contact_email_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
contact_email = contact_email_node.text
phone_number_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Número de teléfono")
phone_number_node = phone_number_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
phone_number = phone_number_node.textOtro nodo que requiere especial atención es el elemento «Fundadores»:
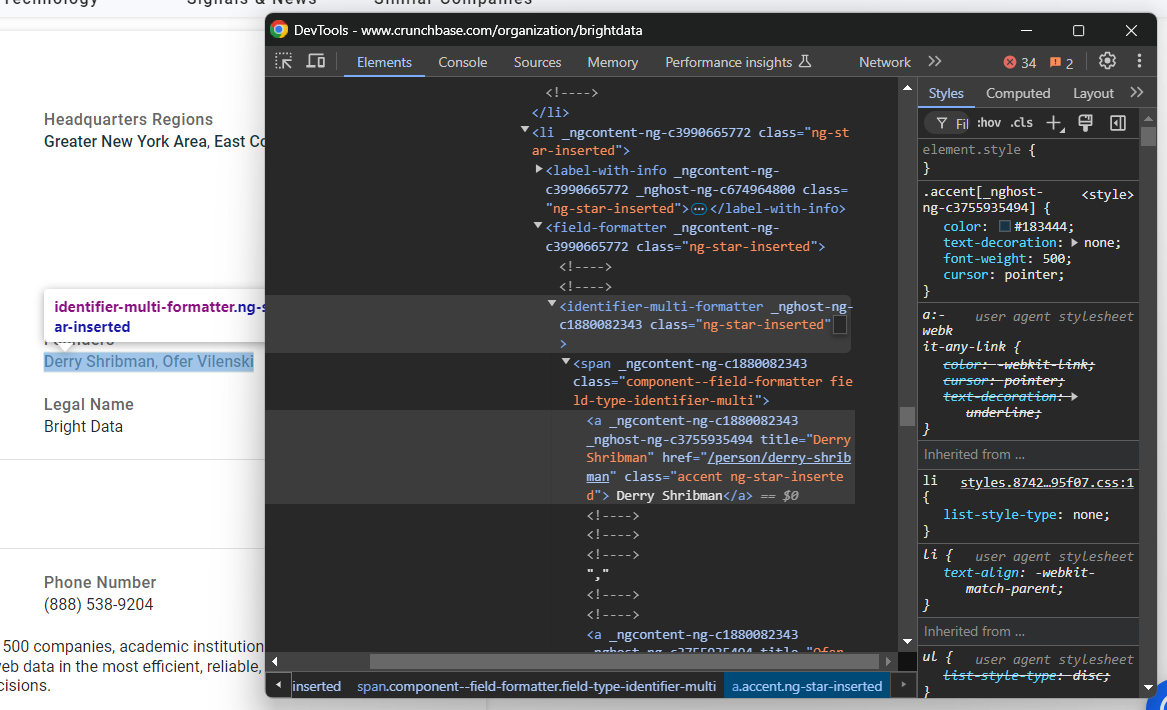
En este caso, es necesario iterar sobre los nodos identifier-multi-formatter a y extraer datos de ellos:
founders_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Founders")
founders_nodes = founders_parent_node.find_elements(By.CSS_SELECTOR, "identifier-multi-formatter a")
founders = []
for founders_node in founders_nodes:
founders.append(founders_node.text)Por último, echa un vistazo al nodo de descripción al final de la sección «Detalles»:
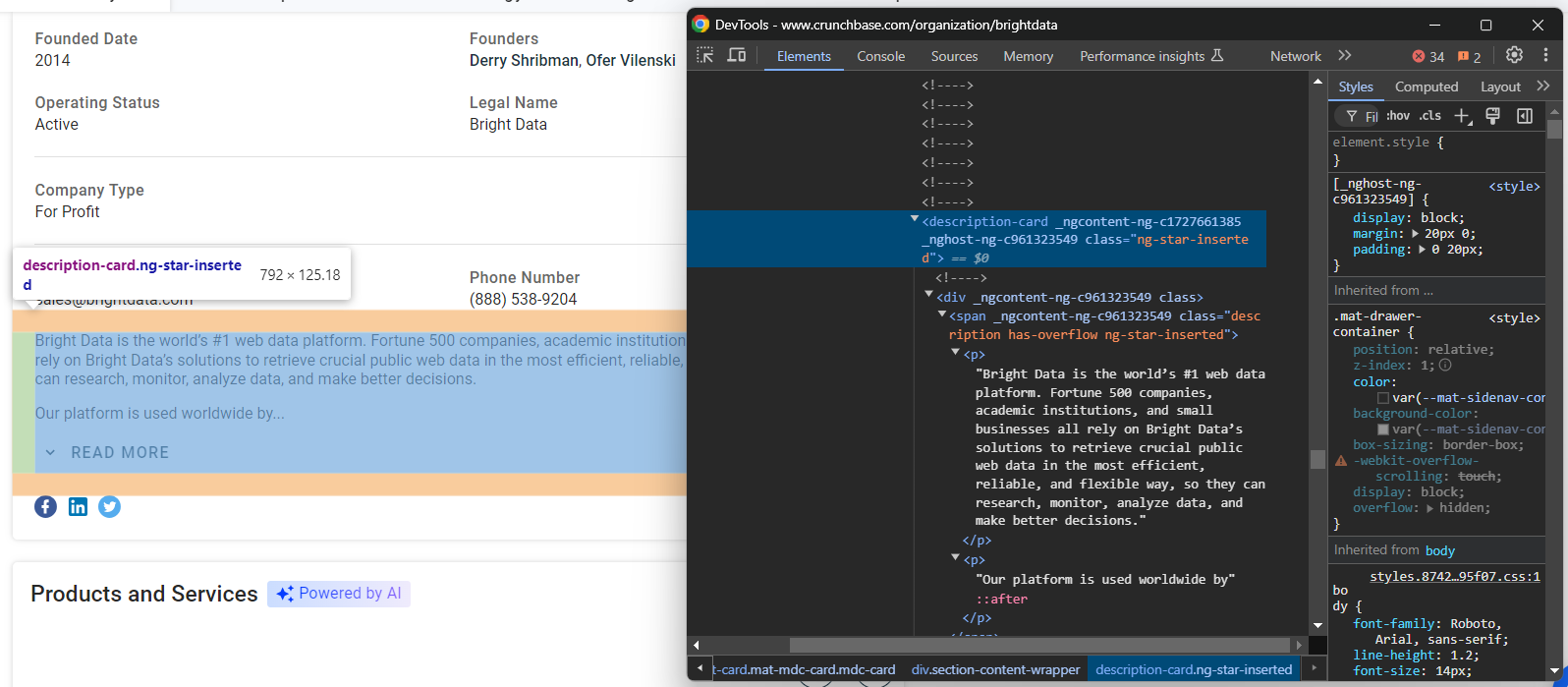
Extraiga estos datos con:
description_node = driver.find_element(By.CSS_SELECTOR, "section-card description-card")
description = description_node.text¡Increíble! Tu Scraper de Crunchbase está casi completo.
Paso n.º 8: extrae la tabla de productos y servicios
Otra información que vale la pena recopilar es la lista de productos y servicios que ofrece la empresa:
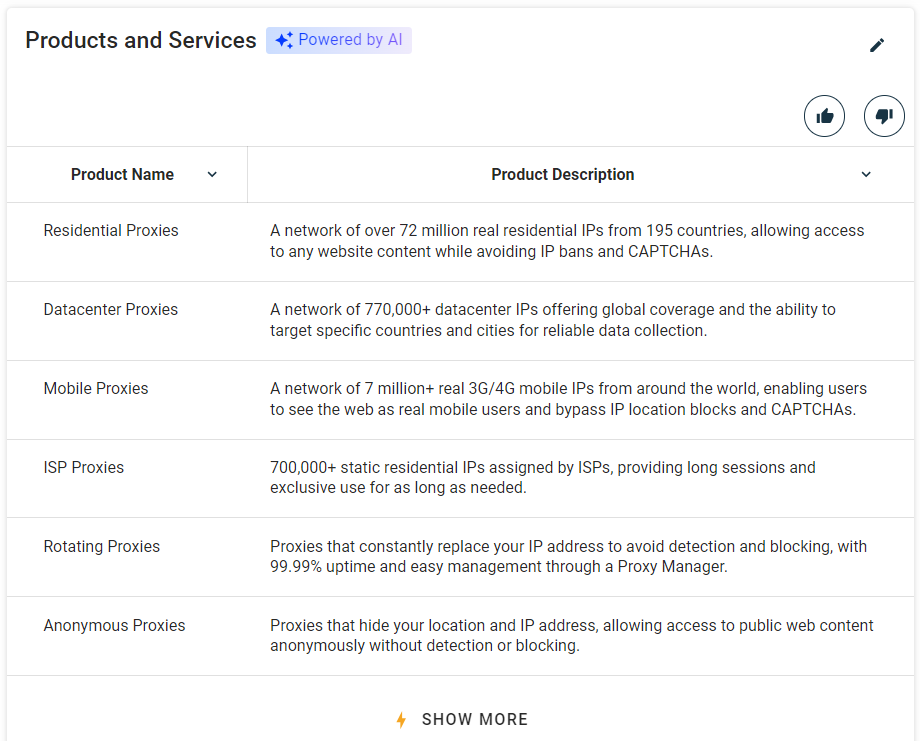
Seleccione la sección «Productos y servicios» utilizando la función definida anteriormente:
products_parent_node = find_parent_node_based_on_child_node_text("profile-section", ".section-title", "Products and Services")A continuación, extrae los datos de la tabla con:
productos = []
para fila en filas_de_la_tabla_de_productos:
# extraiga el nombre y la descripción de las columnas de cada fila
nombre = fila.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text
descripción = fila.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
producto = {
"nombre": nombre,
"descripción": descripción
}
productos.append(producto)¡Impresionante! La lógica de extracción de Crunchbase está completa.
Paso n.º 9: Exportar los datos extraídos
Rellena un diccionario de empresas con los datos extraídos:
company = {
"about": about,
"industries": industries,
"founded_date": founded_date,
"company_type": company_type,
"operating_status": estado_operativo,
"headquarters": sede,
"founders": fundadores,
"email": correo_electrónico,
"phone": número_de_teléfono,
"description": descripción,
"products": productos
}A continuación, expórtalo a un archivo company.json:
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)Primero, open() crea un archivo de salida company.json. A continuación, json.dump() transforma company en su representación JSON y lo escribe en el archivo de salida.
Recuerda importar json desde la biblioteca estándar de Python:
import jsonPaso n.º 10: Ponlo todo junto
Este es el archivo scraper.py final:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import json
def find_parent_node_based_on_child_node_text(parent_nodes_selector, child_node_selector, text):
# seleccionar todos los nodos padres
parent_nodes = driver.find_elements(By.CSS_SELECTOR, parent_nodes_selector)
# iterar a través de los nodos padres para encontrar el que
# cuyo nodo hijo específico contiene el texto deseado
for parent_node in parent_nodes:
try:
# obtener el nodo hijo específico dentro del nodo padre actual
child_node = parent_node.find_element(By.CSS_SELECTOR, child_node_selector)
# comprueba si contiene el texto deseado
if text.upper() in child_node.text.upper():
return parent_node
except:
continue
return None
def handle_cookie_popup(driver, seconds=60):
try:
# esperar el número de segundos indicado a que aparezca en la página el botón «Aceptar todo»
# de la ventana emergente de cookies
accept_button = WebDriverWait(driver, seconds).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))
)
# hacer clic en la ventana emergente mediante JavaScript para evitar
# errores ElementClickInterceptedException
driver.execute_script("arguments[0].click();", accept_button)
print("Se ha hecho clic en el botón 'Aceptar todo'")
except:
print("No se ha encontrado el botón 'Aceptar todo' en {seconds} segundos")
# inicializar el controlador para controlar una instancia de Chrome
# en modo encabezado
driver = webdriver.Chrome()
# navegar a la página deseada de Crunchbase
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)
# gestionar la ventana emergente de cookies, si está presente
handle_cookie_popup(driver)
# lógica de scraping
about_node = driver.find_element(By.CSS_SELECTOR, "profile-section description-card")
about = about_node.text
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")
industries_nodes = industries_parent_node.find_elements(By.CSS_SELECTOR, "chips-container a")
industries = []
for industry_node in industries_nodes:
industries.append(industry_node.text)
founded_date_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Founded Date")
founded_date_node = founded_date_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
founded_date = founded_date_node.text
company_type_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Company Type")
company_type_node = company_type_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
company_type = company_type_node.text
operating_status_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Estado operativo")
operating_status_node = operating_status_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
operating_status = operating_status_node.text
headquarters_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Regiones de la sede central")
headquarters_node = headquarters_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
headquarters = headquarters_node.text
fundadores_nodo_padre = encontrar_nodo_padre_basado_en_texto_nodo_hijo("campos-tarjeta li", "etiqueta-con-información", "Fundadores")
fundadores_nodos = fundadores_nodo_padre.encontrar_elementos(By.CSS_SELECTOR, "identificador-multi-formateador a")
fundadores = []
for founders_node in founders_nodes:
founders.append(founders_node.text)
legal_name_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Legal Name")
legal_name_node = legal_name_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
legal_name = legal_name_node.text
contact_email_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Contact Email")
contact_email_node = contact_email_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
contact_email = contact_email_node.text
phone_number_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Phone Number")
phone_number_node = phone_number_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
phone_number = phone_number_node.text
description_node = driver.find_element(By.CSS_SELECTOR, "section-card description-card")
description = description_node.text
productos_nodo_padre = encontrar_nodo_padre_basado_en_texto_nodo_hijo("sección-perfil", ".sección-título", "Productos y servicios")
filas_tabla_productos = productos_nodo_padre.encontrar_elementos(By.CSS_SELECTOR, "tabla tbody tr")
# extraer la tabla de productos
productos = []
for row in products_table_rows:
# extraer el nombre y la descripción de las columnas de cada fila
name = row.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text
description = row.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
producto = {
"nombre": nombre,
"descripción": descripción
}
productos.append(producto)
# rellenar un diccionario con los datos extraídos
empresa = {
"acerca de": acerca de,
"industrias": industrias,
"fecha_fundación": fecha_fundación,
"company_type": company_type,
"operating_status": operating_status,
"headquarters": headquarters,
"founders": founders,
"email": contact_email,
"phone": phone_number,
"description": description,
"products": products
}
# exportar los datos extraídos a un archivo JSON
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
# cerrar el controlador y liberar los recursos del navegador
driver.quit()¡Con poco más de 100 líneas de código, acabas de crear un Scraper de Crunchbase en Python!
Ejecuta el script con el siguiente comando:
python3 script.pyO, en Windows:
python script.pyAparecerá un archivo company.json en la carpeta de tu proyecto. Ábrelo y verás:
{
"about": "La plataforma de datos web n.º 1 del mundo",
"industries": [
"Inteligencia empresarial",
"Servicios de datos en la nube",
"Informática",
"Recopilación y etiquetado de datos",
"Tecnología de la información",
"Infraestructura de TI",
"Seguridad de redes",
"SaaS",
"Software"
],
"founded_date": "2014",
«tipo_de_empresa»: «Con fines de lucro»,
«estado_operativo»: «Activo»,
«sede»: «Área metropolitana de Nueva York, costa este, noreste de EE. UU.»,
«fundadores»: [
«Derry Shribman»,
«Ofer Vilenski»
],
«email»: «[email protected]»,
«phone»: «(888) 538-9204»,
«description»: «Proxies que ocultan tu ubicación y dirección IP, permitiéndote acceder a contenido web público de forma anónima sin ser detectado ni bloqueado.»,
"productos": [
{
"nombre": "Proxies residenciales",
"descripción": "Una red de 400M+ monthly IPs residenciales reales de 195 países, que permite acceder a cualquier contenido web evitando las prohibiciones de IP y los CAPTCHA."
},
{
"name": "Proxies de centros de datos",
"description": "Una red de más de 770 000 IP de centros de datos que ofrece cobertura global y la posibilidad de dirigirse a países y ciudades específicos para una recopilación de datos fiable."
},
{
"name": "Proxies móviles",
"description": "Una red de más de 7 millones de IP móviles 3G/4G reales de todo el mundo, que permite a los usuarios ver la web como usuarios móviles reales y eludir los bloqueos de ubicación de IP y los CAPTCHA."
},
{
"name": "Proxy ISP",
"description": "Más de 700 000 IPs residenciales estáticas asignadas por los ISP, que proporcionan sesiones largas y uso exclusivo durante el tiempo que sea necesario."
},
{
"name": "Proxies rotativos",
"description": "Proxies que sustituyen constantemente su dirección IP para evitar la detección y el bloqueo, con un tiempo de actividad del 99,99 % y una fácil gestión a través de un gestor de proxies."
},
{
"name": "Proxies anónimos",
"description": "Proxies que ocultan su ubicación y dirección IP, lo que le permite acceder a contenido web público de forma anónima sin ser detectado ni bloqueado."
}
]
}Estos son los datos disponibles en la página de la empresa Bright Data en Crunchbase.
¡Et voilà! Acabas de aprender a hacer Scraping web en Crunchbase utilizando Python.
Desbloquea los datos de Crunchbase con facilidad
Crunchbase proporciona una gran cantidad de datos valiosos, pero también toma medidas exhaustivas para protegerlos de los Scrapers y los bots automatizados. Al interactuar con el sitio utilizando un navegador sin interfaz gráfica o al realizar determinadas acciones, es posible que te encuentres con páginas 403 Forbidden o CAPTCHAs.
Como primer paso, puedes consultar nuestra guía sobre cómo evitar los CAPTCHA en Python. Sin embargo, Crunchbase emplea soluciones avanzadas adicionales contra el scraping que podrían seguir provocando bloqueos.
Sin las herramientas adecuadas, el scraping de Crunchbase puede convertirse rápidamente en una experiencia lenta y frustrante. La mejor solución es la API dedicada Crunchbase Scraper de Bright Data. ¡Recupere datos de Crunchbase sin que le bloqueen!
Conclusión
En este tutorial paso a paso, ha aprendido qué es un Scraper de Crunchbase y los tipos de datos que puede recuperar. También ha visto cómo crear un script de Python para extraer datos generales de empresas de Crunchbase, lo que solo requirió unas 150 líneas de código.
El problema es que Crunchbase adopta medidas estrictas contra los bots y los scripts automatizados. Los CAPTCHA, las huellas digitales del navegador y las prohibiciones de IP son solo algunas de las defensas utilizadas para evitar el scraping. Olvídate de todos esos retos con nuestra API Crunchbase Scraper.
Si el Scraping web no es lo tuyo, pero sigues interesado en los datos de Crunchbase, ¡explora nuestros Conjuntos de datos de Crunchbase!
Hable con uno de nuestros expertos para descubrir cuál de las soluciones de Bright Data se adapta mejor a sus necesidades.





