

En este tutorial práctico, aprenderás a extraer datos de Glassdoor utilizando Playwright Python. También aprenderás las técnicas antiescraping empleadas por Glassdoor y cómo Bright Data puede ayudarte. Además, descubrirás la solución de Bright Data que agiliza considerablemente la extracción de datos de Glassdoor.
Olvídate de extraer datos, obtén los datos
¿Quieres saltarte el proceso de extracción y acceder directamente a los datos? Echa un vistazo a nuestro conjunto de datos de Glassdoor.
El conjunto de datos de Glassdoor ofrece una visión general completa de la empresa con reseñas y preguntas frecuentes que proporcionan información sobre los puestos de trabajo y las empresas. Puede utilizar nuestro conjunto de datos de Glassdoor para encontrar tendencias de mercado e información comercial sobre las empresas, así como la percepción y valoración que tienen de ellas los empleados actuales y antiguos. En función de sus necesidades, tiene la opción de adquirir el conjunto de datos completo o un subconjunto personalizado.
Los Conjuntos de datos están disponibles en formatos como JSON, NDJSON, JSON Lines, CSV o Parquet, y también se pueden comprimir opcionalmente en archivos .gz.
¿Es legal extraer datos de Glassdoor?
Sí, es legal extraer datos de Glassdoor, pero debe hacerse de forma ética y de conformidad con los términos de servicio, el archivo robots.txt y las políticas de privacidad de Glassdoor. Uno de los mayores mitos es que extraer datos públicos, como reseñas de empresas y ofertas de empleo, no es legal. Sin embargo, esto no es cierto. Debe hacerse dentro de los límites legales y éticos.
Cómo extraer datos de Glassdoor
Glassdoor utiliza JavaScript para renderizar su contenido, lo que puede complicar la extracción. Para solucionarlo, necesitas una herramienta que pueda ejecutar JavaScript e interactuar con la página web como un navegador. Algunas opciones populares son Playwright, Puppeteer y Selenium. Para este tutorial, utilizaremos Playwright Python.
¡Empecemos a crear el rascador de Glassdoor desde cero! Tanto si eres nuevo en Playwright como si ya estás familiarizado con él, este tutorial te ayudará a crear un rascador web utilizando Playwright Python.
Configuración del entorno de trabajo
Antes de empezar, asegúrate de que tienes lo siguiente configurado en tu equipo:
- sitio web oficial
- Visual Studio Code
A continuación, abra un terminal y cree una nueva carpeta para su proyecto Python, luego navegue hasta ella:
mkdir glassdoor-scraper
cd glassdoor-scraper
Crea y activa un entorno virtual:
python -m venv glassdoorenv
glassdoorenvScriptsactivate
Instala Playwright:
pip install playwright
A continuación, instala los binarios del navegador:
playwright install
Esta instalación puede tardar un poco, así que ten paciencia.
Así es como se ve el proceso de configuración completo:
¡Ya está todo configurado y listo para empezar a escribir su código de scraping de Glassdoor!
Comprender la estructura del sitio web de Glassdoor
Antes de empezar a extraer datos de Glassdoor, es importante comprender su estructura. Para este tutorial, nos centraremos en extraer datos de empresas de una ubicación específica que tengan funciones concretas.
Por ejemplo, si quieres encontrar empresas en la ciudad de Nueva York con puestos relacionados con el aprendizaje automático y una valoración general superior a 3,5, tendrás que aplicar los filtros adecuados a tu búsqueda.
Echa un vistazo a la página de empresas de Glassdoor:
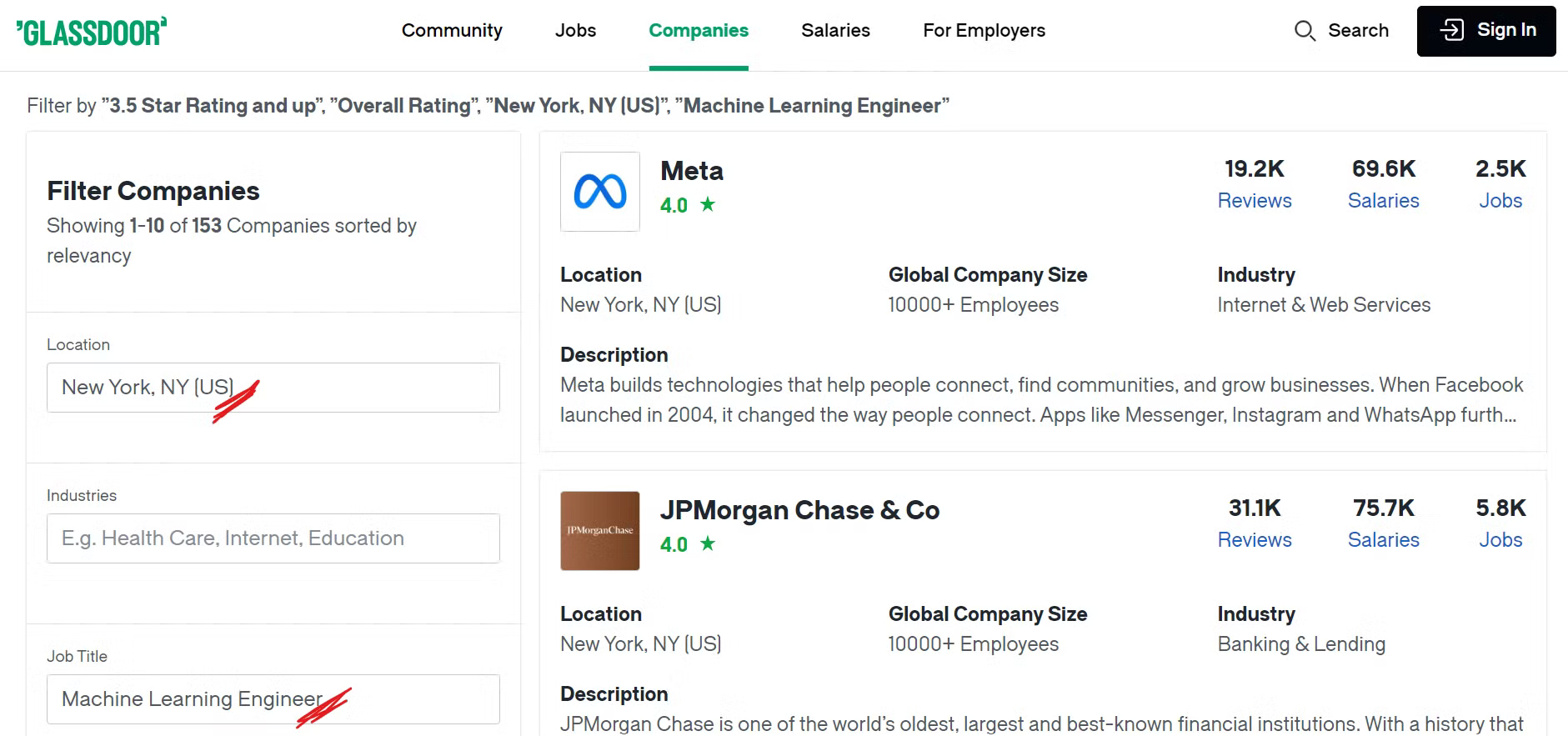
Ahora, puede ver una gran cantidad de empresas enumeradas al aplicar nuestros filtros deseados, y es posible que se pregunte qué datos específicos recopilaremos. ¡Veámoslo a continuación!
Identificación de puntos de datos clave
Para recopilar eficazmente los datos de Glassdoor, es necesario identificar el contenido que se desea extraer.
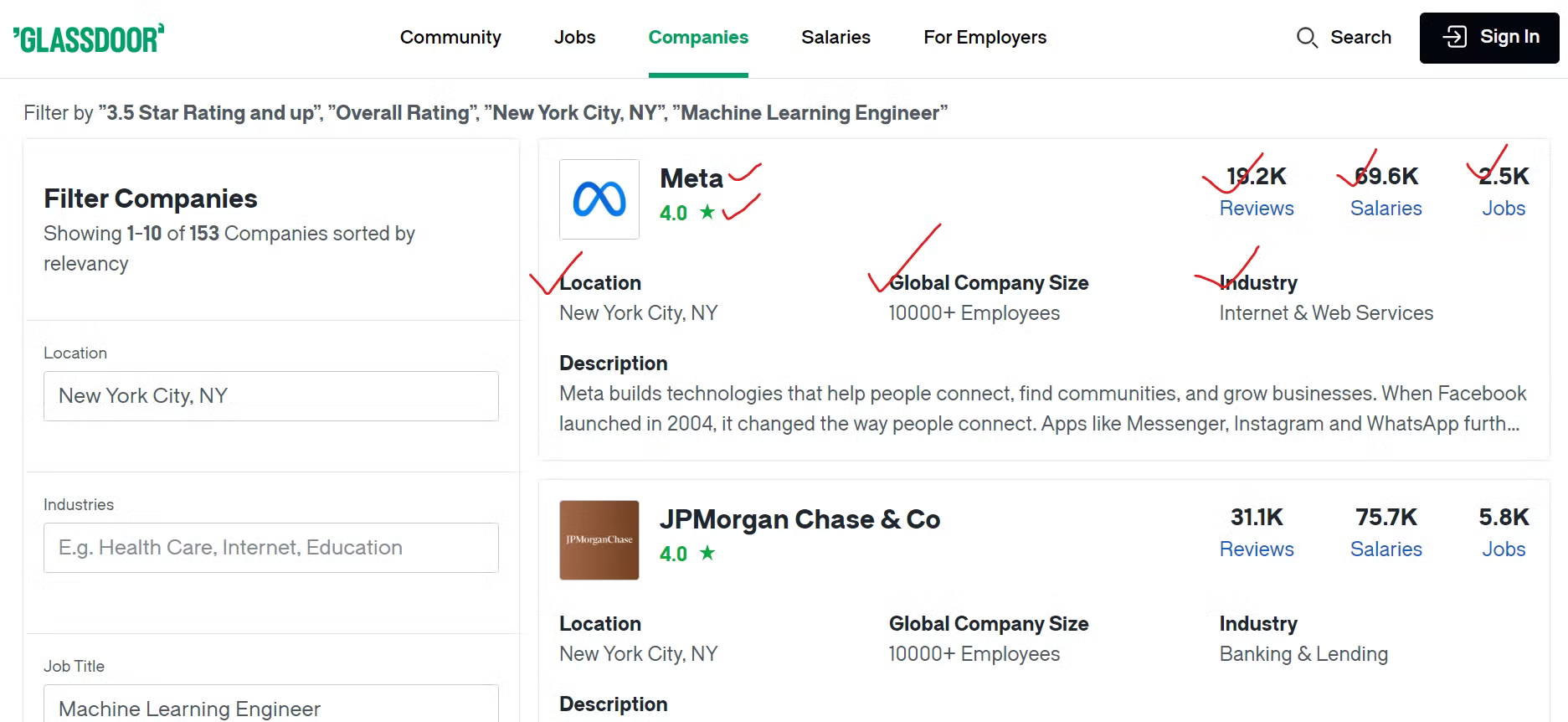
Extraeremos diversos datos sobre cada empresa, como el nombre de la empresa, un enlace a sus ofertas de empleo y el número total de puestos vacantes. Además, extraeremos el número de opiniones de los empleados, el recuento de los salarios comunicados y el sector en el que opera la empresa. También extraeremos la ubicación geográfica de la empresa y el número total de empleados en todo el mundo.
Creación del rascador de Glassdoor
Ahora que ya has identificado los datos que deseas extraer, es el momento de crear el scraper utilizando Playwright Python.
Comience por inspeccionar el sitio web de Glassdoor para localizar los elementos correspondientes al nombre de la empresa y las calificaciones, como se muestra en la imagen siguiente:
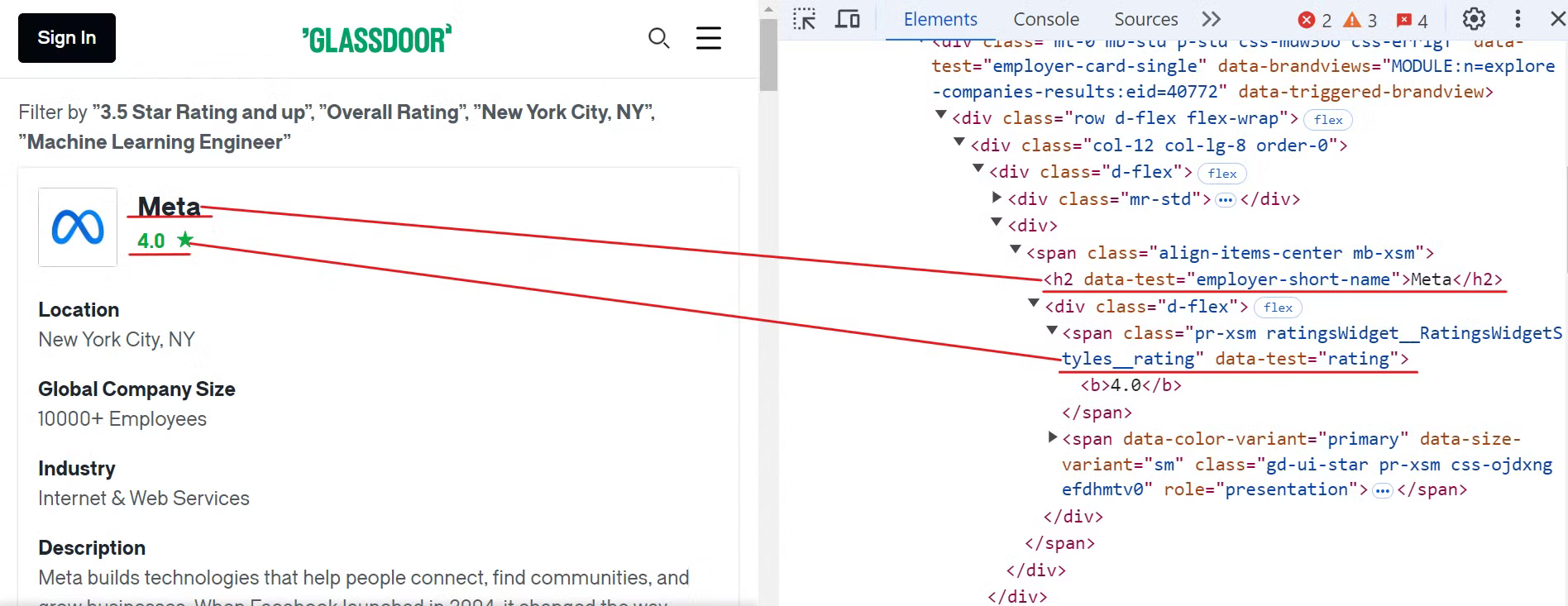
Para extraer estos datos, puede utilizar los siguientes selectores CSS:
[data-test="employer-short-name"]
[data-test="rating"]
Del mismo modo, puede extraer otros datos relevantes utilizando selectores CSS sencillos, como se muestra en la imagen siguiente:
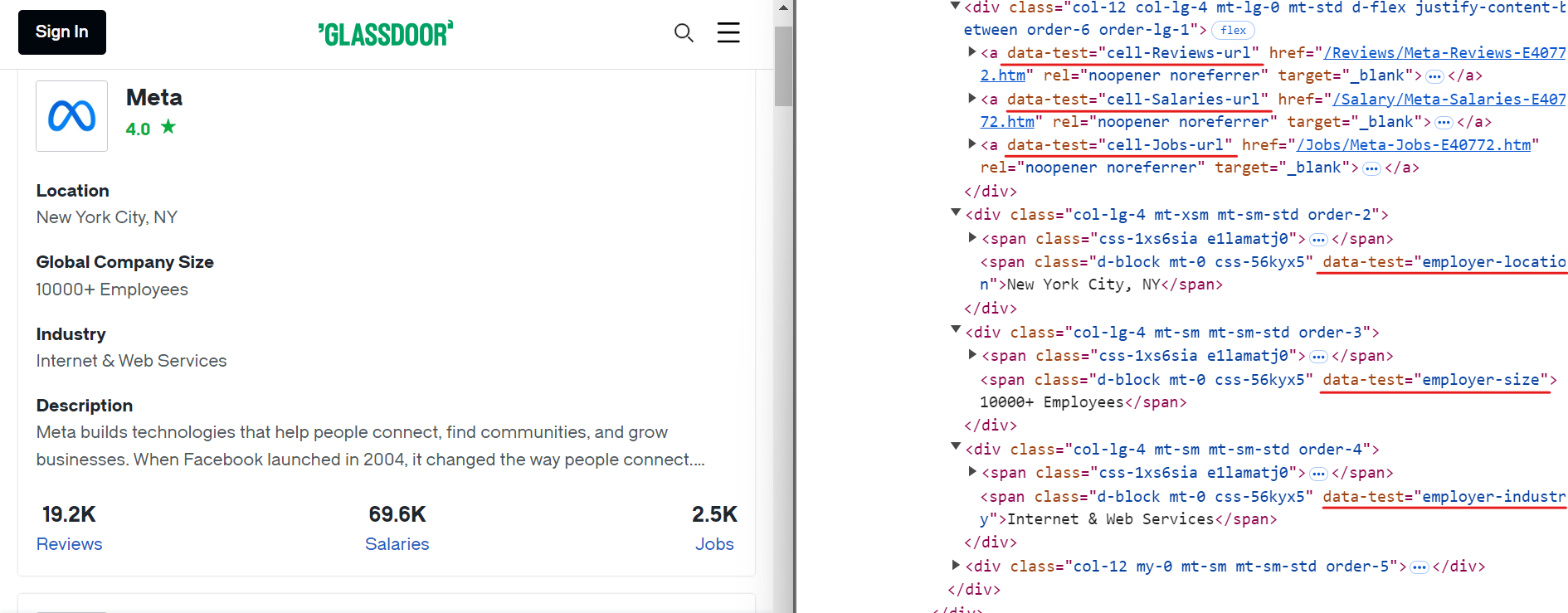
Estos son los selectores CSS que puede utilizar para extraer datos adicionales:
[data-test="employer-location"] /* Ubicación geográfica de la empresa */
[data-test="employer-size"] /* Número de empleados en todo el mundo */
[data-test="employer-industry"] /* Sector en el que opera la empresa */
[data-test="cell-Jobs-url"] /* Enlace a las ofertas de empleo de la empresa */
[data-test="cell-Jobs"] h3 /* Número total de ofertas de empleo */
[data-test="cell-Reviews"] h3 /* Número de opiniones de empleados */
[data-test="cell-Salaries"] h3 /* Recuento de salarios comunicados */
A continuación, crea un nuevo archivo llamado glassdoor.py y añade el siguiente código:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Iniciar una instancia del navegador Chromium.
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Define la URL base y los parámetros de consulta para la búsqueda en Glassdoor
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "Nueva York, NY (EE. UU.)",
"occ": "Ingeniero de aprendizaje automático",
"filterType": "RATING_OVERALL",
}
# Construye la URL completa con los parámetros de consulta y navega hasta ella.
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Inicializa un contador para los registros extraídos.
record_count = 0
# Localizar todas las tarjetas de empresa en la página y recorrerlas para extraer datos.
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extraer los datos relevantes de cada tarjeta de empresa.
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
calificación = await tarjeta.localizador('[data-test="calificación"]').contenido_texto(tiempo_máximo=2000) o "N/A"
ubicación = await tarjeta.localizador('[data-test="ubicación_empleador"]').contenido_texto(tiempo_máximo=2000) o "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# Construye la URL para las ofertas de empleo
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extraer datos adicionales sobre empleos, reseñas y salarios
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Imprimir los datos extraídos
print({
"Company": company_name,
"Rating": rating,
"Jobs URL": jobs_url_path,
"Jobs Count": jobs_count,
"Reviews Count": reviews_count,
"Salaries Count": salaries_count,
"Industry": industry,
"Location": location,
"Global Company Size": global_company_size,
})
record_count += 1
except Exception as e:
print(f"Error al extraer los datos de la empresa: {e}")
print(f"Total de registros extraídos: {record_count}")
# Cerrar el navegador
await browser.close()
# Punto de entrada para el script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
Este código configura un script de Playwright para extraer datos de la empresa aplicando filtros específicos. Por ejemplo, aplica filtros como la ubicación (Nueva York, NY), la calificación (3,5+) y el puesto de trabajo (ingeniero de aprendizaje automático).
A continuación, inicia una instancia del navegador Chromium, navega a la URL de Glassdoor que incluye estos filtros y extrae los datos de cada ficha de empresa de la página. Después de recopilar los datos, imprime la información extraída en la consola.
Y este es el resultado:

¡Buen trabajo!
Todavía hay un problema. Actualmente, el código extrae solo 10 registros, mientras que hay aproximadamente 150 registros disponibles en la página. Esto muestra que el script solo captura datos de la primera página. Para extraer más registros, necesitamos implementar el manejo de la paginación, que se trata en la siguiente sección.
Manejo de la paginación
Cada página de Glassdoor muestra datos de aproximadamente 10 empresas. Para extraer todos los registros disponibles, es necesario gestionar la paginación navegando por cada página hasta llegar al final. Para gestionar la paginación, hay que localizar el botón «Siguiente», comprobar si está habilitado y hacer clic en él para pasar a la página siguiente. Repita este proceso hasta que no haya más páginas disponibles.
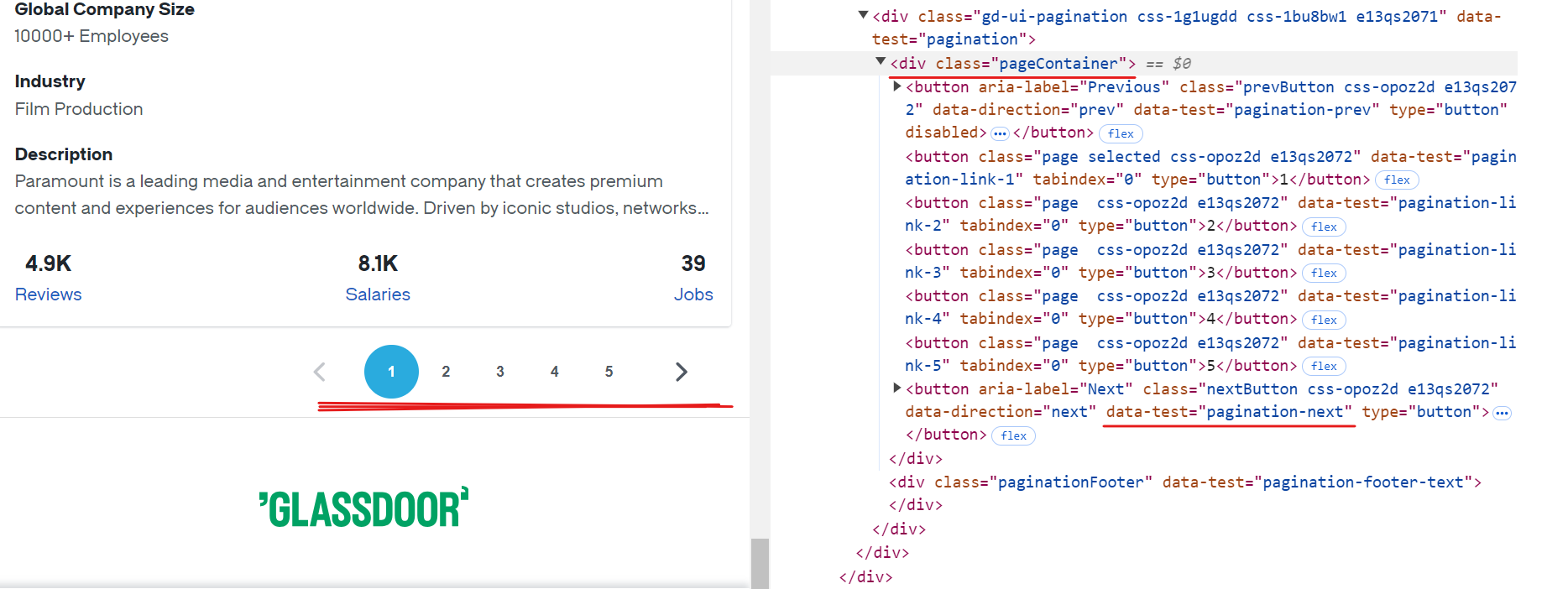
El selector CSS para el botón «Siguiente» es [data-test="pagination-next"], que se encuentra dentro de una etiqueta <div> con la clase pageContainer, como se muestra en la imagen anterior.
A continuación se muestra un fragmento de código que muestra cómo gestionar la paginación:
while True:
# Asegúrate de que el contenedor de paginación sea visible antes de continuar.
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identifica el botón «Siguiente» en la página.
next_button = page.locator('[data-test="pagination-next"]')
# Determina si el botón «Siguiente» está desactivado, sin mostrar más páginas.
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Detén si no hay más páginas para navegar.
# Navegar a la página siguiente
await next_button.click()
await asyncio.sleep(3) # Dar tiempo para que la página se cargue completamente
Aquí está el código modificado:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Iniciar una instancia del navegador Chromium
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Define la URL base y los parámetros de consulta para la búsqueda en Glassdoor
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "Nueva York, NY (EE. UU.)",
"occ": "Ingeniero de aprendizaje automático",
"filterType": "RATING_OVERALL",
}
# Construye la URL completa con los parámetros de consulta y navega hasta ella.
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Inicializar un contador para los registros extraídos
record_count = 0
while True:
# Localizar todas las tarjetas de empresa en la página y recorrerlas para extraer datos
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extraer los datos relevantes de cada tarjeta de empresa
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
calificación = await tarjeta.localizador('[data-test="calificación"]').contenido_texto(tiempo_máximo=2000) o "N/A"
ubicación = await tarjeta.localizador('[data-test="ubicación_empleador"]').contenido_texto(tiempo_máximo=2000) o "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# Construye la URL para las ofertas de empleo
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extrae datos adicionales sobre empleos, reseñas y salarios
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Imprimir los datos extraídos
print({
"Company": company_name,
"Rating": rating,
"Jobs URL": jobs_url_path,
"Jobs Count": jobs_count,
"Reviews Count": reviews_count,
"Salaries Count": salaries_count,
"Industry": industry,
"Location": location,
"Global Company Size": global_company_size,
})
record_count += 1
except Exception as e:
print(f"Error al extraer los datos de la empresa: {e}")
try:
# Asegúrate de que el contenedor de paginación sea visible antes de continuar.
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identifica el botón «Siguiente» en la página.
next_button = page.locator('[data-test="pagination-next"]')
# Determinar si el botón «Siguiente» está desactivado, sin mostrar más páginas
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Detener si no hay más páginas para navegar
# Navegar a la página siguiente
await next_button.click()
await asyncio.sleep(3) # Dar tiempo para que la página se cargue completamente
except Exception as e:
print(f"Error al navegar a la página siguiente: {e}")
break # Salir del bucle en caso de error de navegación
print(f"Total de registros extraídos: {record_count}")
# Cerrar el navegador
await browser.close()
# Punto de entrada para el script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
El resultado es:

¡Genial! Ahora puedes extraer datos de todas las páginas disponibles, no solo de la primera.
Guardar datos en CSV
Ahora que ha extraído los datos, guardémoslos en un archivo CSV para su posterior procesamiento. Para ello, puede utilizar el módulo csv de Python. A continuación se muestra el código actualizado que guarda los datos extraídos en un archivo CSV:
import asyncio
import csv
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Iniciar una instancia del navegador Chromium.
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Define la URL base y los parámetros de consulta para la búsqueda en Glassdoor
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "Nueva York, NY (EE. UU.)",
"occ": "Ingeniero de aprendizaje automático",
"filterType": "RATING_OVERALL",
}
# Construye la URL completa con los parámetros de consulta y navega hasta ella.
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Abre el archivo CSV para escribir los datos extraídos.
with open("glassdoor_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow([
"Empresa", "URL de empleos", "Recuento de empleos", "Recuento de reseñas", "Recuento de salarios",
"Sector", "Ubicación", "Tamaño global de la empresa", "Valoración"
])
# Inicializar un contador para los registros extraídos.
record_count = 0
while True:
# Localizar todas las tarjetas de empresa de la página y recorrerlas para extraer los datos.
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extraer datos relevantes de cada tarjeta de empresa
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# Construye la URL para las ofertas de empleo
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extraer datos adicionales sobre empleos, reseñas y salarios
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Escribir los datos extraídos en el archivo CSV.
writer.writerow([
company_name, jobs_url_path, jobs_count, reviews_count, salaries_count,
industry, location, global_company_size, rating
])
record_count += 1
except Exception as e:
print(f"Error al extraer los datos de la empresa: {e}")
try:
# Asegúrate de que el contenedor de paginación sea visible antes de continuar.
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identifica el botón «Siguiente» en la página.
next_button = page.locator('[data-test="pagination-next"]')
# Determina si el botón «Siguiente» está desactivado, sin mostrar más páginas.
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Detén si no hay más páginas para navegar.
# Navegar a la página siguiente
await next_button.click()
await asyncio.sleep(3) # Dar tiempo para que la página se cargue completamente
except Exception as e:
print(f"Error al navegar a la página siguiente: {e}")
break # Salir del bucle en caso de error de navegación
print(f"Total de registros extraídos: {record_count}")
# Cerrar el navegador
await browser.close()
# Punto de entrada para el script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())
Este código ahora guarda los datos extraídos en un archivo CSV llamado glassdoor_data.csv.
El resultado es:
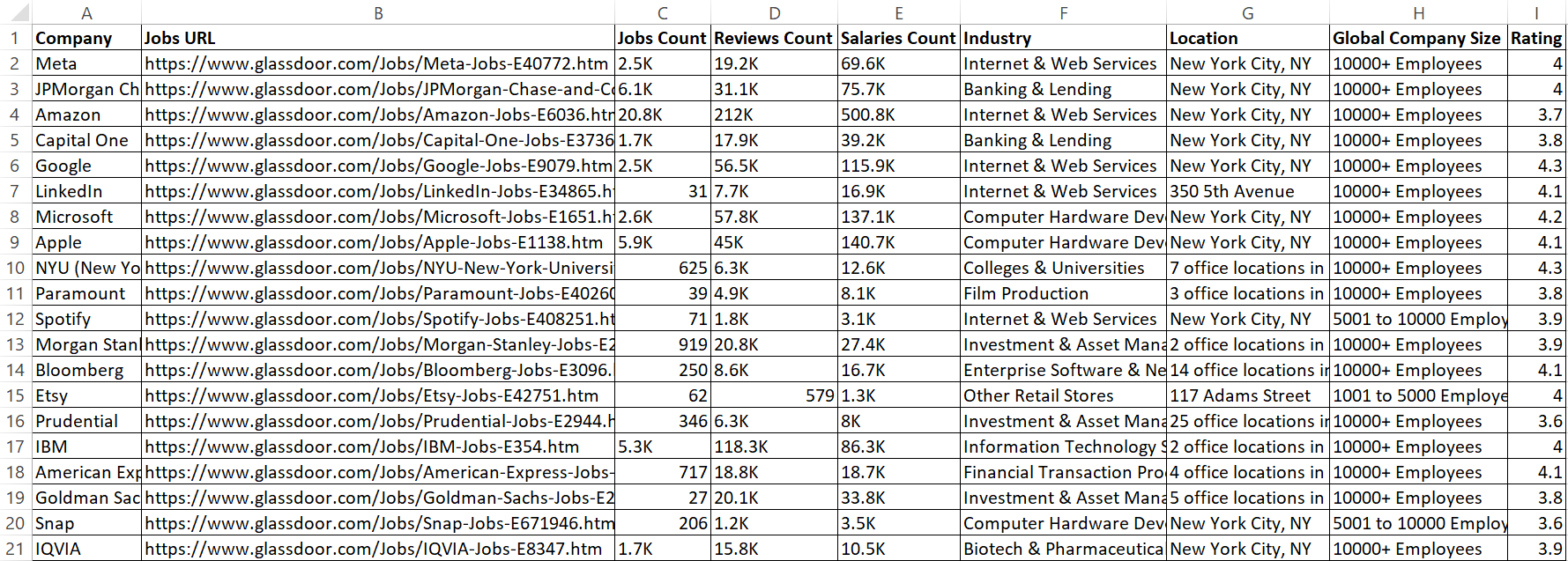
¡Genial! Ahora los datos se ven más limpios y son más fáciles de leer.
Técnicas antiscraping empleadas por Glassdoor
Glassdoor supervisa el número de solicitudes procedentes de una dirección IP durante un periodo determinado. Si las solicitudes superan un límite establecido, Glassdoor puede bloquear temporal o permanentemente la dirección IP. Además, si se detecta una actividad inusual, Glassdoor puede presentar un desafío CAPTCHA, como me ocurrió a mí.
El método descrito anteriormente es adecuado para extraer datos de unos cientos de empresas. Sin embargo, si necesitas extraer datos de miles de ellas, existe un mayor riesgo de que los mecanismos antibots de Glassdoor marquen tu script de extracción automatizada, como me ocurrió a mí al extraer grandes volúmenes de datos.
Extraer datos de Glassdoor puede resultar difícil debido a sus mecanismos antiescraping. Eludir estos mecanismos antibots puede ser frustrante y requerir muchos recursos. Sin embargo, existen estrategias que ayudan a tu scraper a imitar el comportamiento humano y reducir la probabilidad de ser bloqueado. Algunas técnicas comunes incluyen el Proxy rotativo, la configuración de encabezados de solicitud reales, la aleatorización de las tasas de solicitud y mucho más. Si bien estas técnicas pueden mejorar sus posibilidades de éxito en el rastreo, no garantizan un éxito del 100 %.
Por lo tanto, el mejor enfoque para extraer datos de Glassdoor, a pesar de sus medidas antibots, es utilizar una API de Glassdoor Scraper 🚀.
Una alternativa mejor: la API de Glassdoor Scraper
Bright Data ofrece un conjunto de datos de Glassdoor que viene precopilado y estructurado para su análisis, como se ha comentado anteriormente en el blog. Si no desea comprar un conjunto de datos y busca una solución más eficiente, considere la posibilidad de utilizar la API Glassdoor Scraper de Bright Data.
Este potente API está diseñado para extraer datos de Glassdoor sin problemas, gestionando contenido dinámico y eludiendo fácilmente las medidas antibots. Con esta herramienta, puedes ahorrar tiempo, garantizar la precisión de los datos y centrarte en extraer información útil de los datos.
Para empezar a utilizar la API Glassdoor Scraper, siga estos pasos:
En primer lugar, cree una cuenta. Visite el sitio web de Bright Data, haga clic en «Prueba gratuita» y siga las instrucciones de registro. Una vez que haya iniciado sesión, se le redirigirá a su panel de control, donde obtendrá algunos créditos gratuitos.
Ahora, ve a la sección API Web Scraper y selecciona Glassdoor en la categoría de datos B2B. Encontrarás varias opciones de recopilación de datos, como recopilar empresas por URL o recopilar ofertas de empleo por URL.
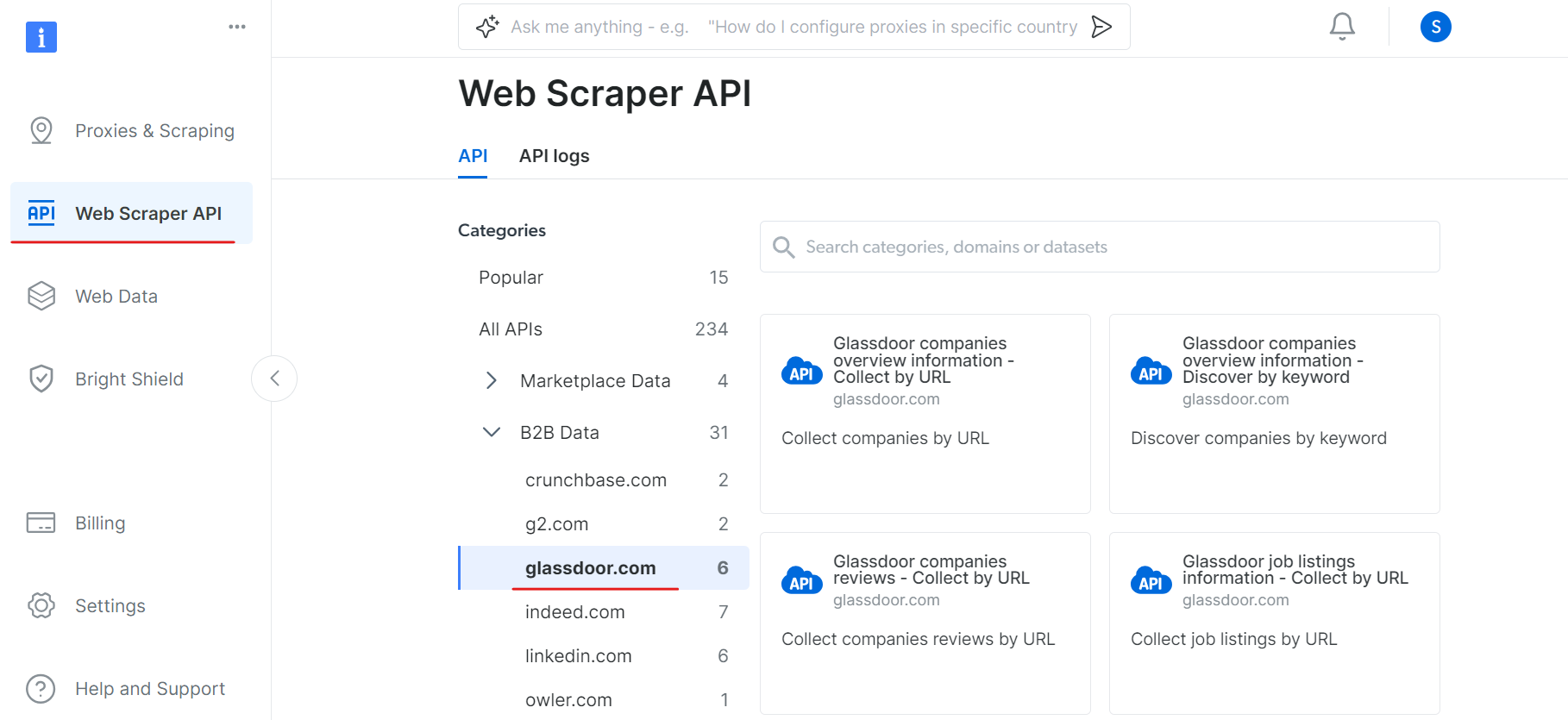
En «Información general de las empresas de Glassdoor», obtenga su token API y copie su ID de conjunto de datos (por ejemplo, gd_l7j0bx501ockwldaqf).
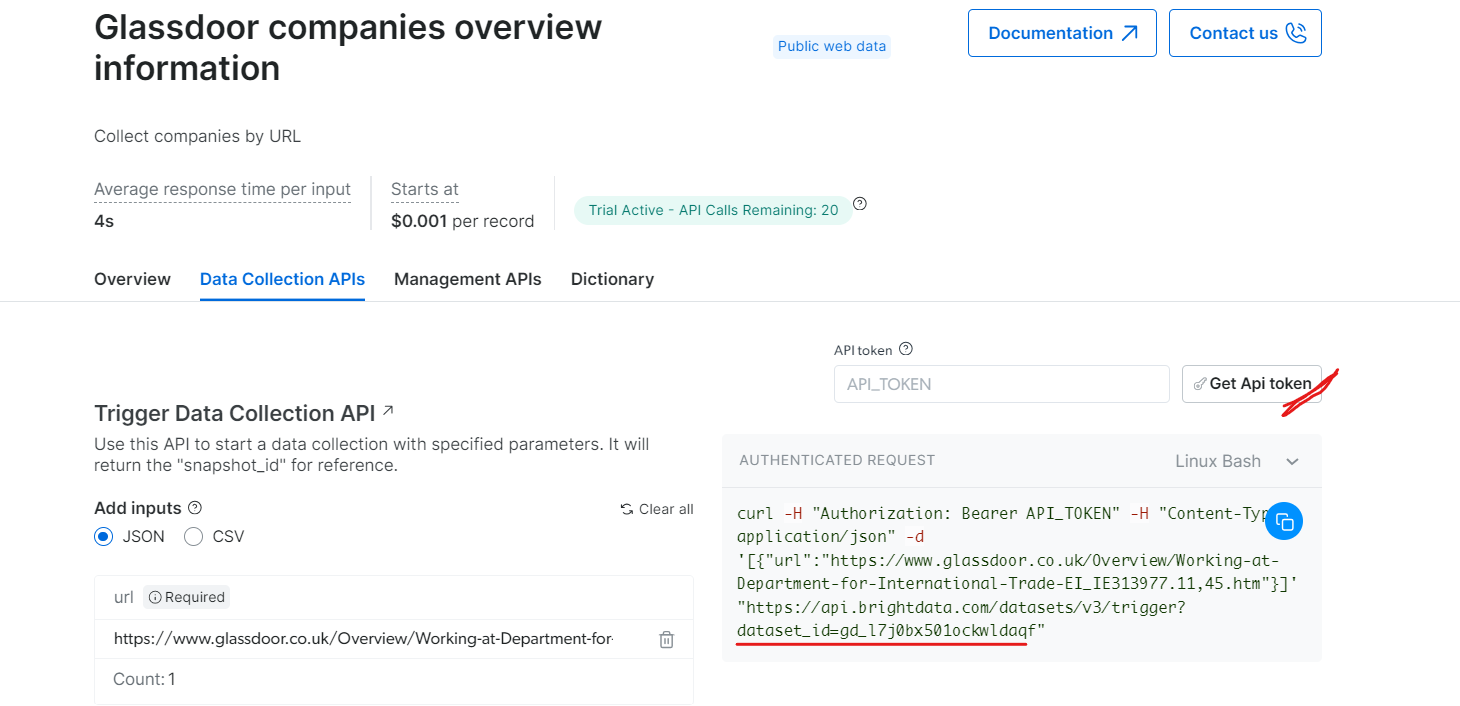
A continuación, se muestra un fragmento de código sencillo que muestra cómo extraer datos de empresas proporcionando la URL, el token API y el ID del conjunto de datos.
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
Activa un conjunto de datos utilizando la API de BrightData.
Argumentos:
api_token (str): El token API para la autenticación.
dataset_id (str): El ID del conjunto de datos que se va a activar.
company_url (str): La URL de la página de la empresa que se va a analizar.
Devuelve:
dict: La respuesta JSON de la API.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/conjuntos_de_datos/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "COMPANY_PAGE_URL"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)
Al ejecutar el código, recibirá un ID de instantánea como se muestra a continuación:

Utilice el ID de instantánea para recuperar los datos reales de la empresa. Ejecute el siguiente comando en su terminal. Para Windows, utilice:
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
Para Linux:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"
Después de ejecutar el comando, obtendrá los datos deseados.
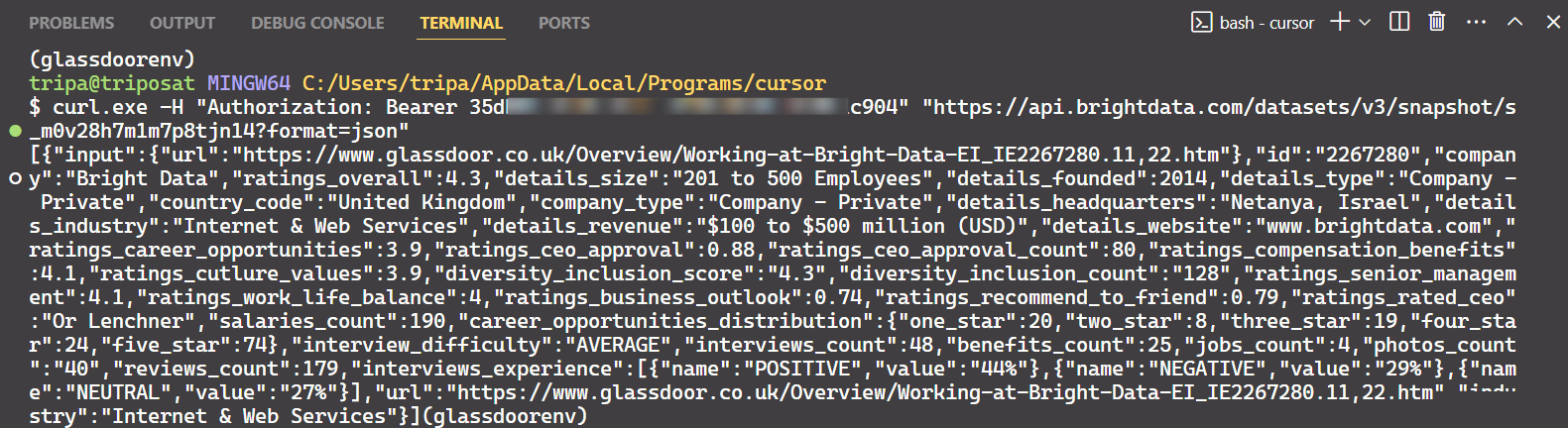
¡Eso es todo lo que hay que hacer!
Del mismo modo, puede extraer varios tipos de datos de Glassdoor modificando el código. He explicado un método, pero hay otras cinco formas de hacerlo. Por lo tanto, le recomiendo que explore estas opciones para extraer los datos que desee. Cada método se adapta a necesidades de datos específicas y le ayuda a obtener los datos exactos que necesita.
Conclusión
En este tutorial, ha aprendido a extraer datos de Glassdoor utilizando Playwright Python. También ha aprendido las técnicas antiescraping empleadas por Glassdoor y cómo eludirlas. Para abordar estos problemas, se ha introducido la API Bright Data Glassdoor Scraper, que le ayuda a superar las medidas antiescraping de Glassdoor y a extraer los datos que necesita sin problemas.
También puedes probar Navegador de scraping, un navegador de última generación que se puede integrar con cualquier otra herramienta de automatización de navegadores. Navegador de scraping puede eludir fácilmente las tecnologías antibots y evitar el rastreo de huellas digitales del navegador. Se basa en funciones como la rotación de agentes de usuario, la rotación de IP y la resolución de CAPTCHA.
Regístrese ahora y pruebe los productos de Bright Data de forma gratuita.






