

La mayoría de los equipos de datos no fracasan por no poder recopilar datos. Fracasan porque los datos en bruto llegan desordenados, duplicados e inconsistentes, y no existe una forma disciplinada de convertirlos en algo en lo que analistas y modelos puedan confiar. La arquitectura medallion es el patrón que utilizan la mayoría de las plataformas de datos modernas para resolver exactamente ese problema, moviendo los datos a través de tres capas progresivamente más limpias: bronze, silver y gold.
Esta guía explica el patrón tal como un ingeniero de datos necesita entenderlo: cómo se comporta cada capa, cómo se mueven físicamente los datos entre ellas, y dónde entran los datos web de fuentes externas como entrada bronze en bruto.
En este artículo:
- Qué es la arquitectura medallion y por qué Databricks la popularizó
- Qué hacen las capas bronze, silver y gold, y quién las consume
- Cómo se mueven los datos entre capas con formatos de tabla, transacciones ACID y captura de datos de cambios
- Dónde entran los datos externos y web como fuente bronze
- Mejores prácticas, errores comunes y casos de uso donde el patrón es más rentable
¿Qué es la arquitectura medallion?
La arquitectura medallion es un patrón de diseño para organizar datos dentro de un lakehouse de modo que su estructura y calidad mejoren en cada etapa, a medida que fluyen de bronze a silver y a gold. El nombre toma prestada la metáfora de las medallas: los datos entran como bronze en bruto de bajo valor y se refinan en silver más valioso y luego en gold. También se la conoce como arquitectura multi-hop, ya que cada registro da varios saltos antes de estar listo para el consumo.
El patrón fue popularizado por Databricks junto con su paradigma lakehouse y el formato de tabla Delta Lake, que fue de código abierto en 2019. Un lakehouse combina el bajo costo de almacenamiento de un data lake con las características de fiabilidad de un data warehouse, como transacciones ACID y aplicación de esquemas. La arquitectura medallion es el principio organizativo que da a ese lakehouse un flujo claro de confianza. Ahora es una convención multiplataforma: el mismo lenguaje de bronze, silver y gold aparece en la documentación de Databricks, Microsoft Fabric y Snowflake.
La idea central es simple. En lugar de limpiar los datos en un paso opaco, se conserva una copia permanente en bruto y se refina por etapas, donde cada etapa tiene un contrato claro. Esa separación es lo que hace que el patrón sea tan duradero, y es la base de todo lo que se explica a continuación.
Por qué los equipos de datos lo adoptan
La arquitectura medallion se gana su lugar porque resuelve varios problemas a la vez.
Calidad de datos incremental e inspeccionable. La calidad se mejora por etapas en lugar de en una única transformación difícil de razonar. Cada salto tiene un trabajo definido, por lo que cuando algo parece incorrecto sabes qué capa inspeccionar.
Reprocesamiento desde los datos en bruto. Como la capa bronze es un archivo histórico permanente, puedes reconstruir las tablas silver y gold en cualquier momento sin volver al sistema fuente. Si una transformación tiene un error o la lógica de negocio cambia, se reproduce desde bronze en lugar de volver a recopilar datos que pueden ya no estar disponibles.
Linaje y auditabilidad. Bronze preserva el payload original, lo que proporciona un registro forense. Los equipos de cumplimiento y auditoría pueden rastrear cualquier número en un dashboard hasta el registro en bruto exacto del que proviene.
Separación de responsabilidades entre consumidores. Las diferentes capas sirven a diferentes audiencias. Los ingenieros de datos y los equipos de operaciones trabajan en bronze y silver. Los analistas y científicos de datos trabajan en silver. Los analistas de negocio, ejecutivos y aplicaciones consumen gold.
Servicio a múltiples consumidores. Una única entidad silver limpia puede alimentar muchas tablas gold, por lo que finanzas, operaciones y marketing pueden construir sus propias vistas listas para el consumo desde la misma fuente confiable.
Esta es también la razón por la que el patrón se combina naturalmente con una mentalidad ELT. Primero se cargan los datos en bruto y luego se transforman dentro de la plataforma, en lugar de transformar todo antes de que aterrice. Si quieres repasar el flujo de ingesta más amplio, el artículo sobre pipelines ETL y el resumen de arquitectura de pipelines de datos se alinean perfectamente con el modelo medallion.
Las tres capas en detalle
El flujo es lineal en concepto: los datos en bruto aterrizan en bronze, se refinan en silver y se dan forma para el consumo en gold.
flowchart LR
S["External and web sources"] --> B["Bronze: raw, as-is, append-only"]
B --> SI["Silver: cleaned, conformed, deduplicated"]
SI --> G["Gold: aggregated, business-level"]
G --> C["BI, dashboards, ML, applications"]Los datos se refinan progresivamente a medida que se mueven de bronze a silver y a gold.
Capa bronze: en bruto e inmutable
Bronze es la zona de aterrizaje para todo lo que llega de los sistemas fuente externos. Sus tablas reflejan la forma de la fuente tal como está, con algunas columnas de metadatos adicionales que registran detalles como la marca de tiempo de carga y el proceso que escribió la fila. Las prioridades aquí son la velocidad de captura, un archivo histórico duradero de la fuente, un linaje limpio y la opción de reprocesar más tarde sin volver a leer el sistema de origen.
Bronze tiene algunas propiedades definitorias. Contiene el estado en bruto de los datos en su formato original. Se añade de forma incremental y crece con el tiempo. Sirve como única fuente de verdad, preservando la fidelidad de los datos exactamente como llegaron. Está destinado al procesamiento posterior en lugar al acceso directo de los analistas.
Un detalle de implementación clave: en bronze generalmente no se aplican tipos. Databricks recomienda almacenar la mayoría de los campos como string, VARIANT o binario para protegerse contra cambios de esquema inesperados del upstream. En efecto, bronze es schema-on-read. Se captura primero y se interpreta después, que es exactamente lo que se quiere cuando el esquema fuente está fuera de tu control. Las fuentes bronze pueden ser cualquier combinación de entradas de streaming y batch, incluido almacenamiento de objetos en la nube como Amazon S3, Google Cloud Storage y Azure Data Lake Storage, buses de mensajes como Kafka y Kinesis, y sistemas federados.
Capa silver: limpia y conforme
Silver es donde los registros bronze se emparejan, fusionan, conforman y limpian, lo suficiente para dar al negocio una visión coherente y única de sus entidades, conceptos y transacciones principales. Imagina registros maestros de clientes, transacciones deduplicadas y tablas de referencia cruzada. Al reconciliar datos de muchas fuentes en una forma consistente, silver se convierte en la capa que impulsa el análisis de autoservicio, los informes ad-hoc, el análisis avanzado y el aprendizaje automático.
Las operaciones que típicamente ocurren aquí son concretas: aplicación de esquemas, manejo de valores nulos y faltantes, deduplicación, resolución de registros fuera de orden y de llegada tardía, controles de calidad de datos, evolución de esquemas, conversión de tipos y joins. Aquí es también donde se comienza el modelado de datos real, a menudo usando estructuras más normalizadas y de alto rendimiento para escritura. El seguimiento de las métricas de calidad de datos en esta etapa es lo que separa una capa silver confiable de una simple copia glorificada de bronze.
Una buena práctica firme: no escribas en silver directamente desde la ingesta. Si omites bronze y escribes directamente en silver, introduces fallos de cambios de esquema y registros fuente corruptos, y pierdes la capacidad de reproducir. Silver siempre debe incluir al menos una representación validada y no agregada de cada registro, para que el análisis detallado siga siendo posible sin bajar al bronze en bruto.
Capa gold: lista para el negocio
Gold contiene datos listos para el consumo y específicos del proyecto. Los modelos aquí están más desnormalizados y ajustados para lecturas rápidas con menos joins, y aquí es donde aterrizan las transformaciones finales y las reglas de negocio. Es el hogar del trabajo de la capa de presentación: análisis de clientes e inventario, segmentación, informes de ventas y similares. En la práctica, a menudo encontrarás esquemas en estrella al estilo Kimball o data marts al estilo Inmon en esta capa.
Gold representa vistas altamente refinadas que impulsan dashboards, aprendizaje automático y aplicaciones. Los datos suelen estar muy agregados y filtrados a períodos de tiempo o regiones específicas. Dado que un único dominio de negocio raramente encaja en una sola forma, muchos equipos construyen múltiples tablas gold, por ejemplo vistas separadas para finanzas, operaciones y RRHH, todas derivadas de la misma base silver.
La tabla a continuación resume cómo difieren las tres capas.
| Capa | Estado de los datos | Operaciones típicas | Consumidores principales |
|---|---|---|---|
| Bronze | En bruto, tal como está, solo añadir | Ingerir, capturar metadatos, preservar historial | Ingenieros de datos, equipos de auditoría y cumplimiento |
| Silver | Limpio, conforme, deduplicado | Validación, dedup, aplicación de esquemas, joins | Ingenieros de datos, analistas, científicos de datos |
| Gold | Agregado, a nivel de negocio | Agregados finales, reglas de negocio, esquemas en estrella | Desarrolladores BI, ejecutivos, aplicaciones, ML |
Cómo se mueven los datos a través de las capas
La arquitectura medallion es un patrón lógico, pero se basa en un conjunto específico de mecánicas físicas. El panorama completo es el siguiente: muchas fuentes alimentan bronze, los datos se refinan a través de silver y gold dentro del lakehouse, y muchos consumidores leen desde gold.
flowchart LR
subgraph SRC["Sources"]
WEB["Web data via Bright Data"]
DB["Databases and apps"]
MB["Message buses: Kafka, Kinesis"]
end
subgraph LH["Lakehouse: Delta, Iceberg, or Hudi on Parquet"]
BRONZE["Bronze: raw, append-only"] --> SILVER["Silver: cleaned, conformed"] --> GOLD["Gold: business aggregates"]
end
subgraph CON["Consumers"]
BI["BI and dashboards"]
ML["ML and AI"]
APP["Applications"]
end
WEB --> BRONZE
DB --> BRONZE
MB --> BRONZE
GOLD --> BI
GOLD --> ML
GOLD --> APPUna pila medallion de referencia: muchas fuentes aterrizan en bronze, se refinan a través de silver y gold, y sirven a muchos consumidores.
Formatos de tabla y archivo. Las capas se construyen generalmente sobre un formato de tabla abierto encima de archivos Parquet en almacenamiento de objetos en la nube. Delta Lake es el formato nativo en Databricks y Microsoft Fabric: internamente almacena datos como Parquet, pero añade un registro de transacciones y estadísticas que proporcionan fiabilidad y rendimiento más allá del Parquet simple. Apache Iceberg es una alternativa igualmente capaz cuando importa la interoperabilidad entre múltiples motores, y Apache Hudi es una opción sólida para la ingesta intensiva en upserts y captura de datos de cambios. Los tres ofrecen las garantías ACID de las que depende el patrón.
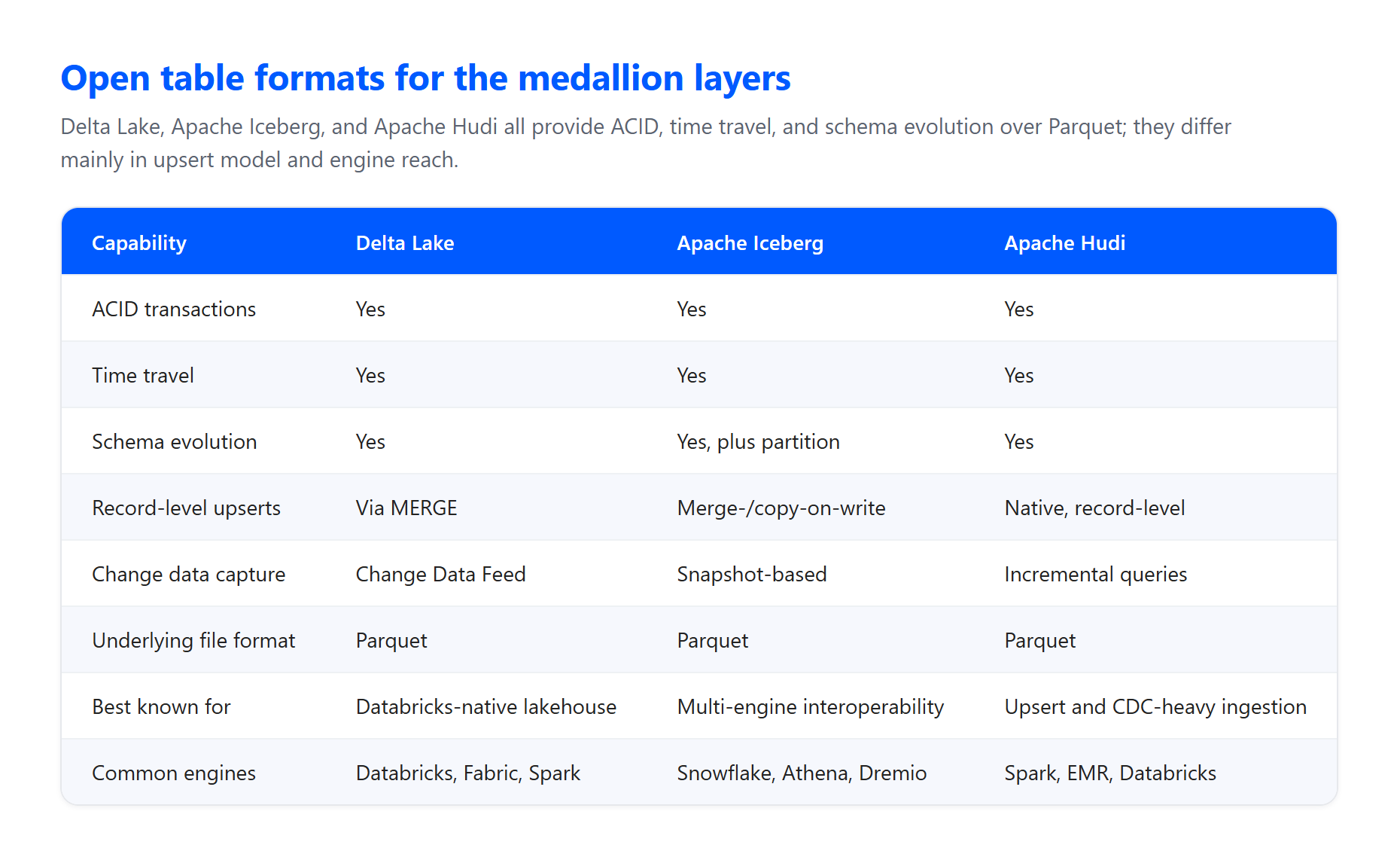
Transacciones ACID. La arquitectura garantiza atomicidad, consistencia, aislamiento y durabilidad a medida que los datos pasan por validaciones y transformaciones. Eso es lo que evita que un trabajo fallido deje una tabla medio escrita y corrupta, lo que importa enormemente cuando muchos pipelines leen y escriben de forma concurrente.
Cargas incrementales y captura de datos de cambios. Raramente se reprocesa todo en cada ejecución. El Change Data Feed de Delta Lake permite que las capas downstream consuman solo lo que cambió. Por ejemplo, puedes habilitar el feed en una tabla silver y usarlo para actualizar incrementalmente los agregados gold sin una actualización completa en cada ejecución. La ingesta incremental en bronze es un equilibrio entre costo y latencia: el streaming continuo tiene la menor latencia y el mayor costo, las cargas incrementales activadas cuestan menos pero añaden latencia, y las cargas batch completas tienen la mayor latencia.
Idempotencia. La ingesta en bronze debe ser idempotente, de modo que volver a ejecutar una carga no cree duplicados ni pierda datos. El diseño de solo añadir más la deduplicación en silver es lo que hace posible la reproducción segura.
Orquestación, batch y streaming. Herramientas como Apache Spark manejan las transformaciones de bronze a silver y de silver a gold, tanto en modos batch como de streaming estructurado. Los marcos declarativos como Spark Declarative Pipelines, las vistas de lago materializadas de Microsoft Fabric y las tareas de Snowflake reducen el código repetitivo para mover datos entre capas. Los orquestadores como Apache Airflow coordinan las ejecuciones. Un ejemplo práctico de este patrón de orquestación, usando Airflow para la programación y Spark para la transformación, se muestra en este tutorial de pipeline con Airflow y Spark, y una variante de streaming en esta guía de Spark Structured Streaming.
Vale la pena señalar que el vocabulario medallion no es universal. El popular marco de transformación dbt estructura los proyectos en capas de staging, intermediate y marts. Las preocupaciones se mapean estrechamente con bronze, silver y gold, pero los nombres son distintos, por lo que no asumas que los dos vocabularios son intercambiables cuando leas la documentación.
Dónde entran los datos web: la capa bronze
Aquí está la parte que la mayoría de los diagramas de arquitectura pasan por alto: ¿de dónde vienen realmente los datos externos y cómo aterrizan en bronze en un estado utilizable?
La capa bronze se define como la zona de aterrizaje para todos los sistemas fuente externos, y Databricks lista explícitamente el almacenamiento de objetos en la nube como S3, GCS y ADLS entre las fuentes bronze válidas. Esa es la costura donde encajan los datos web recopilados externamente. Los precios de la competencia, catálogos de productos, registros públicos de empresas, resultados de búsqueda y datos de reseñas son todos entradas en bruto que pertenecen a bronze en su forma original, con sus peculiaridades e inconsistencias preservadas para que la capa silver las resuelva.
Aquí es exactamente donde opera Bright Data. Bright Data es una plataforma de datos web que recopila datos web públicos a escala y los entrega como archivos estructurados en bruto, lo que la convierte en una fuente natural de la capa bronze. La alineación es directa: los destinos a los que entrega Bright Data son los mismos almacenes de objetos en la nube que las plataformas lakehouse tratan como entradas bronze.
flowchart LR
W["Public web: sites, SERPs, marketplaces"] --> BD["Bright Data ingestion: Web Scraper API, Datasets, Data Firehose"]
BD -->|"JSON, NDJSON, CSV, Parquet"| L["Cloud storage: S3, GCS, Azure, or Snowflake"]
L --> BR["Bronze layer: raw, preserved as source of truth"]
BR --> SV["Silver: clean and conform"]
SV --> GD["Gold: serve analytics and ML"]Los datos web externos entregados por Bright Data aterrizan en el almacenamiento en la nube como la capa bronze, luego fluyen hacia silver y gold.
Hay varias formas de alimentar bronze, dependiendo de si necesitas un flujo de datos por lotes, bajo demanda o continuo:
- La Web Scraper API convierte cualquier sitio en un endpoint de datos estructurados con más de 437 scrapers predefinidos, devolviendo datos como JSON, NDJSON o CSV. Es el disparador bajo demanda para registros bronze frescos.
- Los conjuntos de datos listos para usar proporcionan datos precolectados de cientos de dominios populares, descargables de inmediato o actualizados según un calendario. Este es el camino por lotes hacia bronze.
- El Data Firehose entrega un flujo continuo y en tiempo real de registros web directamente a Amazon S3, un webhook o un stream, lo que se adapta a un patrón de ingesta bronze en streaming.
- La API SERP proporciona resultados estructurados de motores de búsqueda, una entrada bronze común para pipelines de inteligencia competitiva y monitoreo de motores generativos.
- El Navegador de scraping maneja sitios con mucho JavaScript, suministrando datos de páginas renderizadas que la recopilación estática perdería.
- Para feeds de propósito específico, la Company Data API y los conjuntos de datos para IA y LLM curados entregan datos verticales listos para incorporar a un pipeline, mientras que la Web Archive API suministra instantáneas históricas para tablas bronze de series temporales.
La historia de entrega es lo que hace esto limpio. Los conjuntos de datos de Bright Data se exportan como JSON, NDJSON, CSV, XLSX y, de forma importante, Parquet, el formato columnar que las tablas lakehouse usan de forma nativa. Los destinos de entrega incluyen Amazon S3, Google Cloud Storage, Microsoft Azure Blob Storage, Snowflake, Google Cloud Pub/Sub, SFTP, webhook y descarga directa vía API. En la práctica, eso significa que un conjunto de datos programado puede aterrizar en tu bucket bronze de S3 como Parquet de forma recurrente, sin necesidad de escribir código de integración. El Scraper Studio sin código amplía esto aún más, permitiéndote construir un scraper visualmente y cargar la salida directamente en S3, GCS, Azure, BigQuery o Snowflake.
Dos principios mantienen esto fiel al patrón medallion. Primero, preserva el payload en bruto. Aterriza la salida del proveedor en bronze exactamente como se entregó, incluyendo los campos que aún no usas, para conservar el registro forense completo. Segundo, normaliza en silver, no en bronze. Los formatos de fecha, moneda, mapeo de campos y deduplicación entre fuentes pertenecen al salto silver, independientemente de cómo el proveedor externo estructuró sus datos. Si estás decidiendo entre las rutas por lotes y bajo demanda, la comparación de conjuntos de datos frente a APIs de scraping web es un buen punto de partida, al igual que el artículo sobre datos estructurados frente a no estructurados.
La fiabilidad importa aquí más que en ningún otro lugar, porque una fuente bronze que falla silenciosamente envenena todas las capas superiores. Bright Data informa una tasa de éxito promedio del 98,44% en un benchmark independiente de once proveedores, respaldado por una red de proxies residenciales de más de 400 millones de IPs obtenidas éticamente y un objetivo de tiempo de actividad del 99,99%. Para equipos con requisitos de gobernanza, Bright Data mantiene el cumplimiento de GDPR, CCPA, SOC 2 Tipo II e ISO 27001, y recopila solo datos públicamente disponibles, que es el tipo de procedencia que un registro de auditoría en la capa bronze está destinado a capturar.
Un ejemplo práctico: del scrape en bruto a la tabla gold
La teoría es más fácil de confiar cuando puedes ejecutarla. A continuación se muestra un pipeline medallion mínimo sobre una pequeña muestra real de datos de productos web: doce listados recopilados de resultados de búsqueda en vivo de Amazon US y UK en tres categorías. El código es deliberadamente simple, para que el patrón, no las herramientas, sea lo que destaque.
Bronze. Aterriza las filas exactamente como se recopilaron. Los precios siguen siendo cadenas, las monedas están mezcladas y nada se limpia ni se elimina.
import pandas as pd
# Bronze: raw scraped rows, landed as-is with ingestion metadata
bronze = pd.DataFrame(scraped_rows)
bronze["_ingested_at"] = "2026-06-23T00:00:00Z"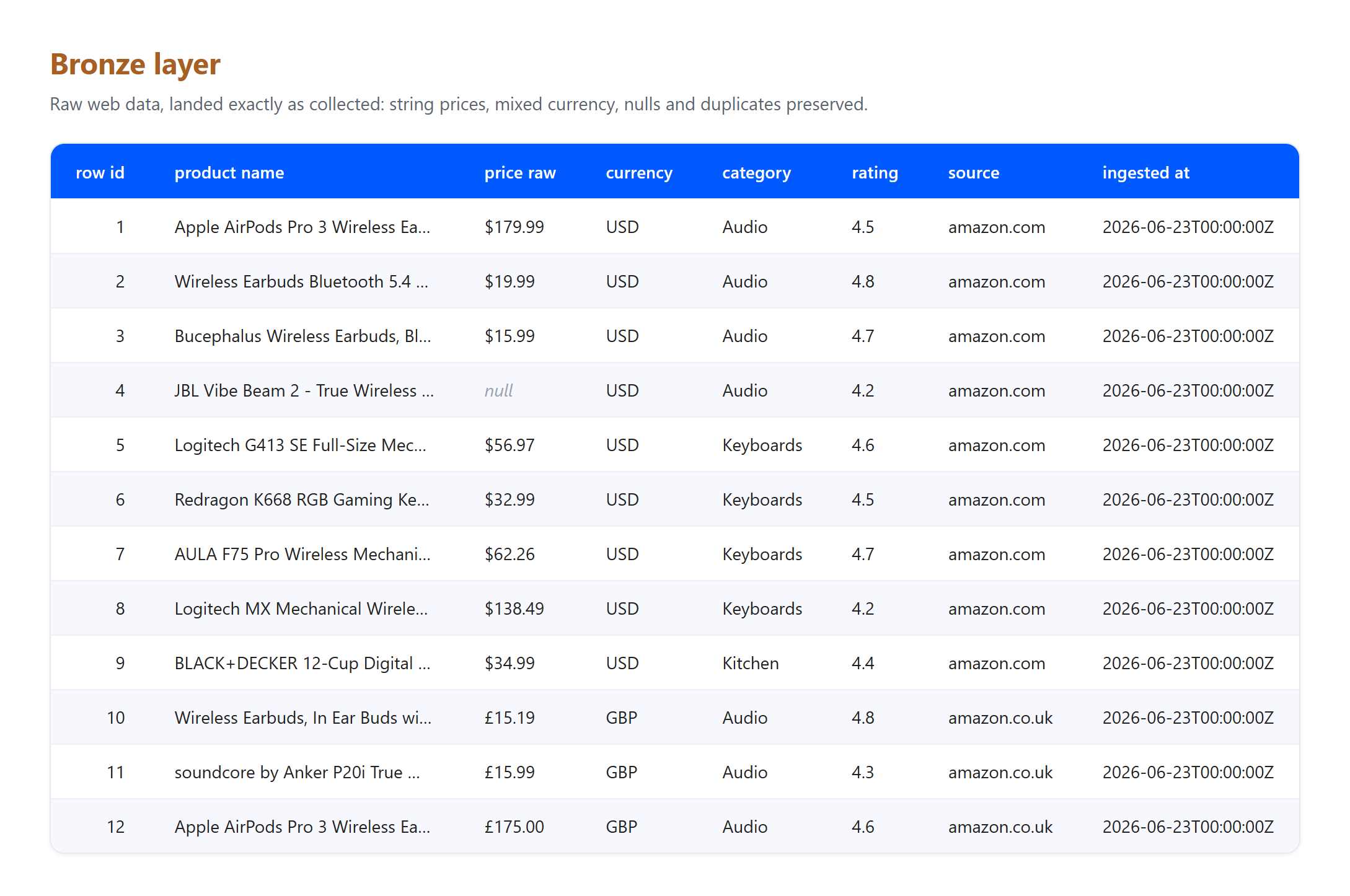
Silver. Parsea los precios a números, normaliza todo a USD, decodifica entidades HTML en los títulos, elimina filas sin precio utilizable y deduplica el mismo producto capturado más de una vez.
import html, re
def to_usd(price_raw, gbp_rate=1.27): # 1.27 is an illustrative fixed rate
if not price_raw:
return None # no price, the row cannot be trusted
is_gbp = "£" in price_raw
value = float(re.sub(r"[^0-9.]", "", price_raw.replace(",", "")))
return round(value * gbp_rate, 2) if is_gbp else round(value, 2)
silver = bronze.copy()
silver["price_usd"] = silver["price_raw"].map(to_usd)
silver["rating"] = silver["rating"].astype(float) # text rating to number
silver["product_name"] = silver["product_name"].map(html.unescape) # & becomes &
silver = silver[silver["price_usd"].notna()] # drop unpriced rows
silver = silver.sort_values("price_usd").drop_duplicates("product_name") # dedup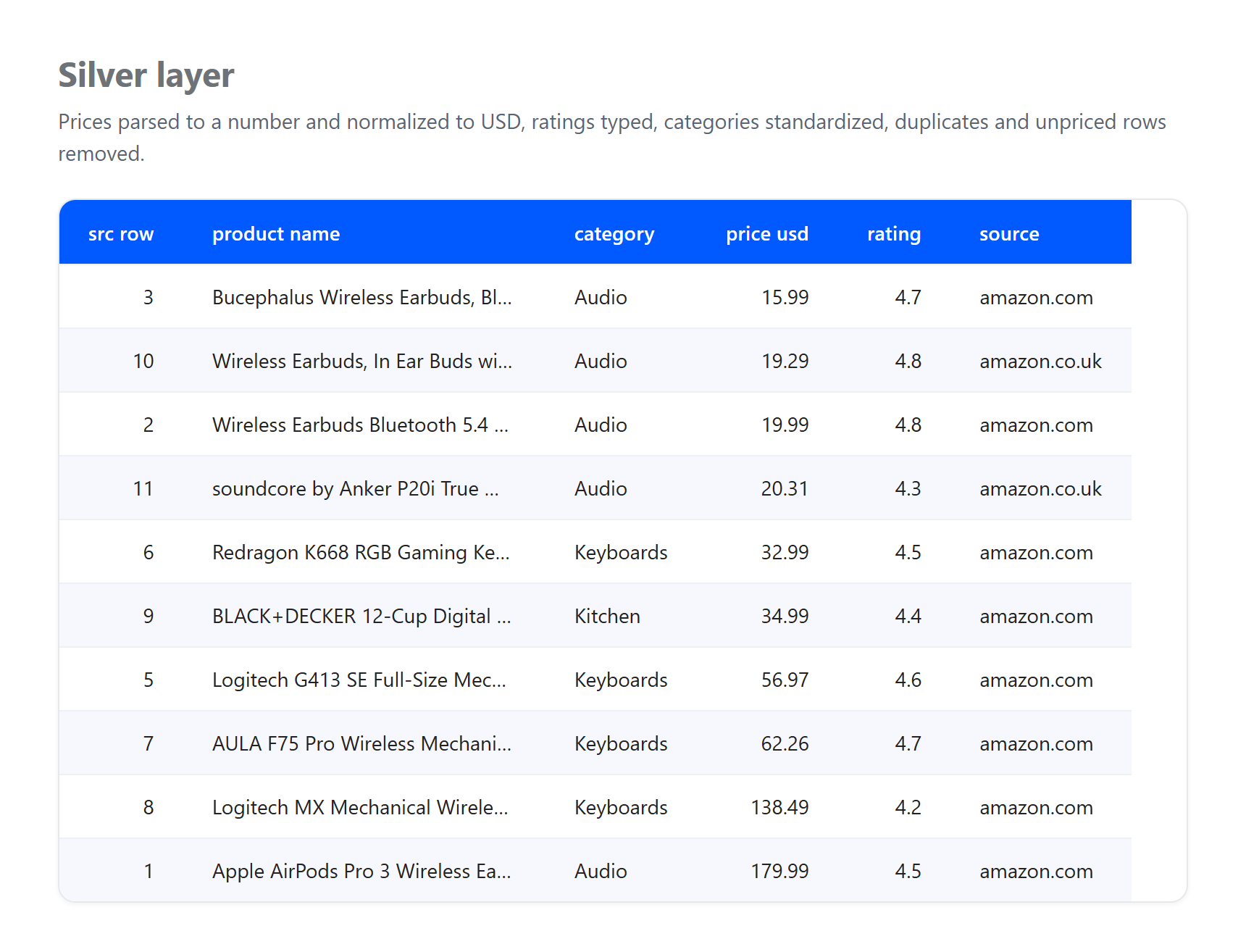
Gold. Agrega los registros limpios en la vista de negocio que realmente consulta un dashboard o modelo.
gold = (
silver.groupby("category")
.agg(
products=("product_name", "count"),
avg_price_usd=("price_usd", "mean"),
min_price_usd=("price_usd", "min"),
max_price_usd=("price_usd", "max"),
avg_rating=("rating", "mean"),
)
.round(2)
.reset_index()
)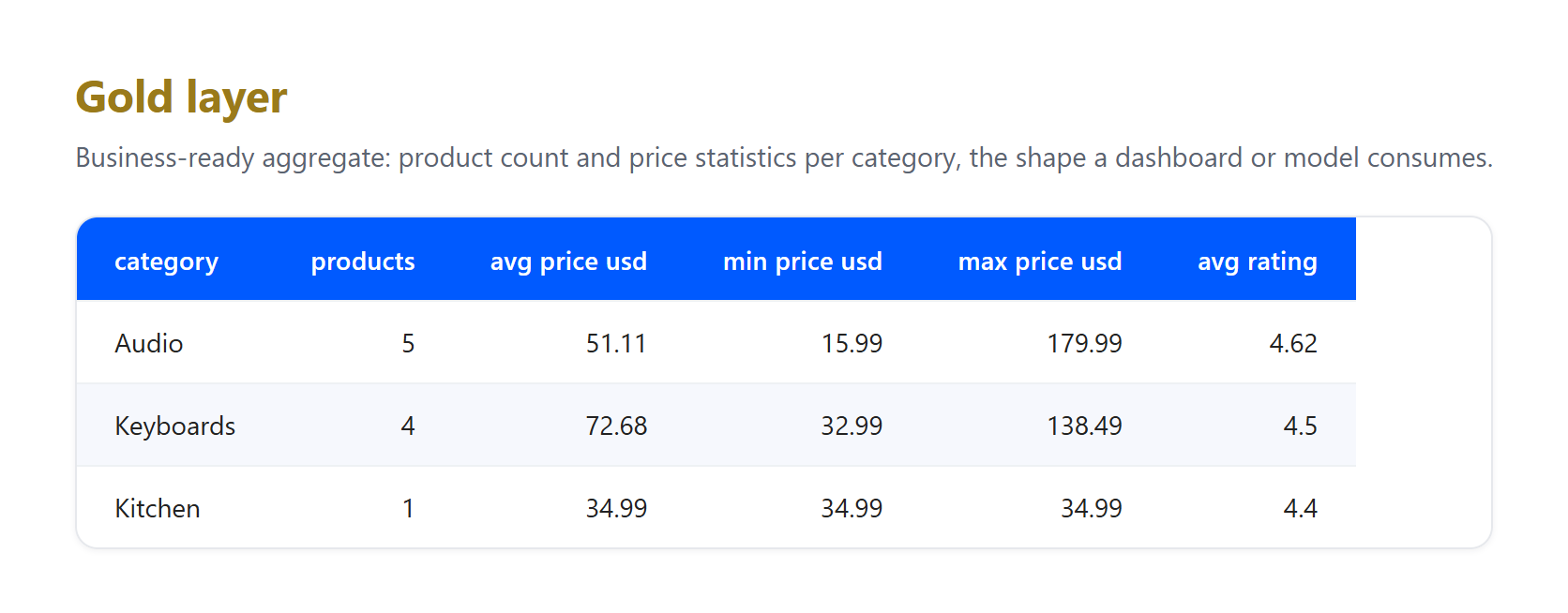
Observa lo que absorbieron las capas, porque es exactamente lo que un pipeline real tiene que enfrentar. Esta es una pequeña muestra real recopilada el 23 de junio de 2026, y la cifra de GBP a USD es una tasa fija ilustrativa, no una conversión en tiempo real. Tres artefactos genuinos llegaron a bronze y se resolvieron en silver: un listado llegó sin precio y fue eliminado, el mismo producto Apple AirPods Pro 3 fue capturado tanto de las páginas de EE. UU. como del Reino Unido y se deduplicó a un único registro, y los títulos con entidades HTML en bruto como & se decodificaron a texto plano. Ninguna de esas limpiezas pertenece a bronze, cuyo único trabajo es preservar lo que llegó. Esa separación de responsabilidades es el punto central del patrón.
El ecosistema de herramientas del lakehouse
El patrón medallion se implementa en un conjunto familiar de herramientas. Ninguna de estas es intercambiable con las demás, pero una arquitectura funcional generalmente combina varias.
- Databricks es la plataforma lakehouse comercial que acuñó tanto el paradigma lakehouse como la arquitectura medallion, con soporte nativo de Delta Lake y herramientas de pipeline declarativas.
- Delta Lake es el formato de tabla de código abierto que añade transacciones ACID, aplicación de esquemas, viaje en el tiempo y captura de datos de cambios sobre Parquet.
- Apache Spark es el motor de cómputo distribuido que ejecuta las transformaciones de bronze a silver y de silver a gold en batch o streaming.
- Apache Iceberg es un formato de tabla abierto preferido cuando múltiples motores necesitan leer las mismas tablas.
- Apache Hudi es un formato de tabla abierto con fuerte soporte de upsert a nivel de registro y extracción incremental, común en capas bronze con muchos cambios.
- Snowflake soporta el patrón de forma nativa, incluyendo tablas Iceberg gestionadas para la capa gold.
- dbt es el marco de transformación SQL-first que muchos equipos utilizan para construir las capas silver y gold.
- Microsoft Fabric implementa la arquitectura medallion de forma nativa en OneLake, estandarizando en Delta Lake.
Si tu plataforma es Snowflake o Google Cloud, las guías de integración de Bright Data con Snowflake Cortex y el flujo de trabajo de Vertex AI más API SERP muestran la transferencia bronze en contexto.
Mejores prácticas
Un puñado de convenciones separa una implementación limpia de una frágil.
- No escribas en silver desde la ingesta. Siempre aterriza los datos en bruto en bronze primero, para que los cambios de esquema y los registros corruptos no puedan romper tus tablas refinadas.
- Mantén bronze con tipos poco estrictos. Almacena la mayoría de los campos como string, VARIANT o binario para que la deriva de esquema del upstream no pierda datos.
- Lee bronze como un stream cuando puedas. Para fuentes de solo añadir, las lecturas en streaming mantienen baja la latencia; reserva las lecturas por lotes para conjuntos de datos pequeños.
- Mantén siempre un registro no agregado en silver. La agregación pertenece a gold, para que silver siga siendo reutilizable para muchos consumidores.
- No fuerces a gold a ser en tiempo real. Gold está optimizado para agregados frecuentemente consultados y actualizados por lotes. Adaptarlo para cargas de trabajo de baja latencia tiende a crear pipelines frágiles y costosos.
- Nombra las tablas por capa. Un espacio de nombres como catalog.bronze.table, catalog.silver.table, catalog.gold.table comunica el nivel de confianza de cualquier tabla de un vistazo.
Errores comunes y críticas
El patrón es robusto, pero se usa mal con suficiente frecuencia como para que los modos de fallo estén bien documentados.
Omitir bronze. Es tentador cuando los datos externos ya parecen limpios, pero omitir bronze elimina el registro de auditoría y la capacidad de reprocesar. La semántica de tu capa silver cambia silenciosamente cuando no hay un registro en bruto detrás de ella.
Tratar silver como gold. Cuando los equipos construyen KPIs de negocio y agregaciones pesadas directamente en silver, los diferentes equipos definen las métricas de manera distinta y no hay una versión autorizada única. Mantén los agregados en gold.
Leer bronze en bruto como si fueran datos de producción. Bronze no está verificado y suele estar desordenado. Apuntar un dashboard hacia él lleva a recuentos duplicados y resultados inconsistentes. Bronze es un registro histórico, no una fuente de verdad para el análisis.
Entrelazamiento entre capas. Cuando los pipelines filtran responsabilidades entre capas, por ejemplo ingestando eventos en bruto directamente en gold, un único cambio de esquema puede propagarse en cascada por toda la pila.
También hay una crítica legítima a aplicar el patrón de forma rígida. Como señaló un análisis, aplicar una estructura rígida de tres capas a todas las fuentes genera ineficiencias cuando ciertos conjuntos de datos no necesitan una limpieza extensa, y la estratificación secuencial añade latencia que los casos de uso en tiempo real pueden no tolerar. La comunidad de profesionales ha respondido proponiendo capas adicionales en algunos diseños, como una zona de aterrizaje pre-bronze o una capa platinum por encima de gold para el servicio operacional y de aprendizaje automático.
La forma saludable de leer todo esto es que la arquitectura medallion es un marco flexible, no un mandato. El propio Databricks afirma que seguir la arquitectura medallion es una mejor práctica recomendada pero no un requisito, y el proyecto Delta Lake la describe como un marco opcional y flexible. Usa el número de capas y la nomenclatura que se adapten a tus patrones de consulta y a tus consumidores.
Casos de uso comunes
El patrón es más rentable donde las entradas en bruto son desordenadas y muchos consumidores necesitan salidas confiables.
- Monitoreo de precios e inteligencia de ecommerce. Los datos de productos y precios recopilados de muchos minoristas aterrizan en bronze tal como están, se normalizan y deduplicen en silver, y alimentan dashboards de seguimiento de precios y surtido en gold.
- Datos de entrenamiento para IA y aprendizaje automático. El texto a escala web y los datos estructurados aterrizan en bruto en bronze, se limpian y deduplicen en silver, y se dan forma a características listas para el modelo en gold. Los pasos prácticos se cubren en esta guía de scraping web para aprendizaje automático, y la estrategia más amplia en el artículo sobre el volante de datos de IA.
- Investigación de mercado y datos alternativos. Las señales externas de muchas fuentes se conforman en silver en una única vista de investigación, luego se agregan en indicadores gold.
- Monitoreo de búsqueda y SERP. Un flujo continuo de resultados de búsqueda fluye hacia bronze, se estructura en silver y se acumula en métricas de visibilidad y cuota de voz en gold.
- Enriquecimiento firmográfico y de clientes. Los feeds de datos de empresas enriquecen los registros internos en la capa silver, produciendo tablas gold para ventas y marketing.
Para la fontanería de ingeniería detrás de estos, los tutoriales sobre AWS Glue ETL, AWS Step Functions, pipelines de Kubeflow, el pipeline de Mage AI y conectar datos web en vivo a Tableau muestran cada uno un camino real de bronze al servicio. Los fundamentos del paso de extracción en sí se cubren en este artículo sobre extracción de datos.
Conclusión
La arquitectura medallion perdura porque da a los equipos un lenguaje compartido para convertir datos en bruto en datos confiables, un salto disciplinado a la vez. Bronze preserva la verdad, silver la hace consistente y gold la hace útil. El patrón solo funciona tan bien como los datos en bruto que lo alimentan, razón por la cual una fuente bronze confiable y bien estructurada no es un detalle sino una base.
Para los datos externos y web, esa base es donde encaja Bright Data: recopilación de nivel de producción entregada como JSON, CSV o Parquet directamente en el almacenamiento en la nube que tu lakehouse ya trata como bronze. ¿Listo para alimentar tu capa bronze con datos web confiables? Inicia una prueba gratuita y observa con qué rapidez los datos web en bruto pueden fluir hacia tu pipeline.
Preguntas frecuentes
P: ¿Qué es la arquitectura medallion en términos simples?
Es una forma de organizar datos en un lakehouse para que se vuelvan más limpios y útiles a medida que se mueven a través de tres capas. Los datos en bruto aterrizan en la capa bronze, se limpian y estandarizan en la capa silver, y se agregan en tablas listas para el negocio en la capa gold. Cada capa tiene un trabajo claro, lo que hace que la calidad de los datos sea más fácil de gestionar y auditar.
P: ¿Cuál es la diferencia entre las capas bronze, silver y gold?
Bronze contiene datos en bruto exactamente como llegaron, de solo añadir y sin transformar, como fuente permanente de verdad. Silver contiene datos limpios y conformes, con deduplicación, aplicación de esquemas y joins aplicados para que los datos sean confiables y consistentes. Gold contiene datos agregados a nivel de negocio, modelados para informes específicos, dashboards, aprendizaje automático y aplicaciones.
P: ¿La arquitectura medallion es lo mismo que ETL?
No, pero están relacionados. ETL describe la extracción, transformación y carga de datos. La arquitectura medallion es un patrón de capas que organiza dónde ocurren esas transformaciones. En un lakehouse generalmente sigue un estilo ELT, donde los datos en bruto se cargan primero en bronze y se transforman por etapas en silver y gold dentro de la plataforma.
P: ¿Siempre necesito las tres capas?
No. Databricks describe la arquitectura medallion como una mejor práctica recomendada, no un requisito. Algunos conjuntos de datos que llegan limpios pueden no necesitar un paso silver extenso, y algunos casos de uso en tiempo real omiten deliberadamente partes del flujo. El número de capas y la nomenclatura deben adaptarse a tus patrones de consulta y consumidores. La principal advertencia es que omitir bronze elimina tu registro de auditoría en bruto y tu capacidad de reprocesar.
P: ¿Qué formato de archivo debo usar para las tablas medallion?
La mayoría de las implementaciones usan un formato de tabla abierto como Delta Lake, Apache Iceberg o Apache Hudi, todos los cuales se apoyan en archivos Parquet en almacenamiento de objetos en la nube. Estos formatos añaden transacciones ACID, aplicación de esquemas y viaje en el tiempo, de los que depende el patrón. Delta Lake es el formato nativo en Databricks y Microsoft Fabric, mientras que Iceberg es común cuando múltiples motores leen las mismas tablas.
P: ¿Cómo encajan los datos externos o web en una arquitectura medallion?
Los datos externos y web son una entrada de la capa bronze. Aterrizas los datos recopilados en bruto, por ejemplo datos de productos, precios, búsquedas o empresas, en su forma original en bronze, luego los normalizas y dedupliceas en silver. Dado que las plataformas lakehouse tratan el almacenamiento de objetos en la nube como S3, GCS y Azure como fuentes bronze válidas, un proveedor como Bright Data puede entregar datos web como JSON, CSV o Parquet directamente en esos almacenes, donde se convierten en la capa bronze.
P: ¿La arquitectura medallion está vinculada a Databricks?
Databricks popularizó el término junto con el paradigma lakehouse y Delta Lake, pero el patrón no es exclusivo de él. El mismo lenguaje de bronze, silver y gold se usa en la documentación de Microsoft Fabric y Snowflake, y los formatos de tabla abiertos subyacentes funcionan en muchos motores. El patrón es una convención general, no el producto de un único proveedor.





