

En esta guía de Scrapy vs Requests, verás:
- Qué son Scrapy y Requests
- Una comparación entre Scrapy y Requests para el Scraping web
- Una comparación entre Scrapy y Requests en un escenario de paginación
- Limitaciones comunes entre Scrapy y Requests en escenarios de Scraping web
¡Empecemos!
¿Qué es Requests?
Requestses una biblioteca de Python para enviar solicitudes HTTP. Se utiliza ampliamente en el Scraping web, generalmente junto con bibliotecas de Parseo HTML comoBeautifulSoup.
Las características clave de Requests para el Scraping web incluyen:
- Compatibilidad con métodos HTTP: puedes utilizar todos los métodos HTTP principales, como
GET,POST,PUT,PATCHyDELETE, que son esenciales para interactuar con páginas web y API. - Encabezados personalizados: establece encabezados personalizados (por ejemplo,
User-Agenty otros) para imitar un navegador real o gestionar la autenticación básica. - Gestión de sesiones: el objeto
requests.Session()permite conservar las cookies y los encabezados en varias solicitudes. Esto resulta útil para extraer datos de sitios web que requieren inicio de sesión o mantener estados de sesión. - Tiempo de espera y gestión de errores: puede establecer tiempos de espera para evitar solicitudes pendientes y gestionar excepciones para un rastreo robusto.
- Compatibilidad con proxies: puede enrutar sus solicitudes a través de proxies, lo que resulta útil para eludir las prohibiciones de IP y acceder a contenido con restricciones geográficas.
¿Qué es Scrapy?
Scrapyes un marco de Scraping web de código abierto escrito en Python. Está diseñado para extraer datos de sitios web de forma rápida, eficiente y escalable.
Scrapy proporciona un marco completo para rastrear sitios web, extraer datos y almacenarlos en varios formatos (por ejemplo, JSON, CSV, etc.). Es especialmente útil para proyectos de Scraping web a gran escala, ya que puede manejar tareas de rastreo complejas y solicitudes simultáneas respetando las reglas de rastreo.
Las características clave de Scrapy para el Scraping web incluyen:
- Rastreo web integrado: Scrapy está diseñado para ser unrastreador web. Esto significa que puede seguir los enlaces de una página web automáticamente, lo que le permite extraer múltiples páginas o sitios completos con un mínimo esfuerzo.
- Solicitudes asíncronas: utiliza una arquitectura asíncrona para gestionar múltiples solicitudes simultáneamente. Eso lo hace mucho más rápido quelos clientes HTTP de Pythoncomo
requests. - Selectores para la extracción de datos: Scrapy ofrece la posibilidad de extraer datos de HTML mediante el uso de XPaths y selectores CSS.
- Middleware para la personalización: admite middleware para personalizar la forma en que se gestionan las solicitudes y las respuestas.
- Limitación automática: puede limitar automáticamente las solicitudes para evitar sobrecargar el servidor de destino. Esto significa que puede ajustar la velocidad de rastreo en función de los tiempos de respuesta y la carga del servidor.
- Gestión
de robots.txt: respeta elarchivorobots.txtpara el Scraping web, lo que garantiza que sus actividades de rastreo cumplan con las normas del sitio. - Rotación de proxies y agentes de usuario: Scrapy admitelarotación de proxiesy
agentes de usuarioa través de middlewares, lo que ayuda a evitar las prohibiciones y la detección de IP.
Scrapy vs Requests: comparación de características para el Scraping web
Ahora que ya sabe qué son Requests y Scrapy, es el momento de hacer una comparación en profundidad de sus usos para el Scraping web:
| Característica | Scrapy | Requests |
|---|---|---|
| Caso de uso | Proyectos de scraping a gran escala y complejos | Tareas de Scraping web más sencillas y prototipos |
| Solicitudes asíncronas | Compatibilidad integrada con solicitudes asíncronas | Sin compatibilidad integrada |
| Rastreo | Sigue automáticamente los enlaces y rastrea varias páginas | Requiere implementación manual para el rastreo |
| Extracción de datos | Compatibilidad integrada con selectores XPath y CSS | Requiere bibliotecas externas para gestionar la extracción de datos |
| Concurrencia | Gestiona múltiples solicitudes simultáneamente de forma predeterminada | Requiere integraciones externas para gestionar las solicitudes concurrentes |
| Middleware | Middlewares personalizables para gestionar Proxies, reintentos y encabezados | Sin middleware integrado |
| Limitación | Limitación automática integrada para evitar la sobrecarga de los servidores | Sin limitación integrada |
| Rotación de proxies | Admite rotación de proxies a través de middlewares | Requiere implementación manual |
| Gestión de errores | Mecanismos de reintento integrados para solicitudes fallidas | Requiere implementación manual |
| Descargas de archivos | Admite descargas de archivos, pero requiere una configuración adicional | Soporte sencillo y directo para la descarga de archivos |
Casos de uso
Scrapy es un marco completo de Scraping web para proyectos de extracción a gran escala y complejos. Es ideal para tareas que implican el rastreo de múltiples páginas, solicitudes simultáneas y exportación de datos en formatos estructurados.
Por otro lado, Requests es una biblioteca que gestiona solicitudes HHTP. Por lo tanto, es más adecuada para tareas sencillas como recuperar una sola página web, interactuar con API o descargar archivos.
Solicitudes asíncronas y concurrencia
Scrapy se basa enTwisted, un marco de trabajo de redes impulsado por eventos para Python. Eso significa que puede gestionar solicitudes asíncronas y múltiples de forma concurrente, lo que lo hace mucho más rápido para el scraping a gran escala.
Requests, en cambio, no admite solicitudes asíncronas o concurrentes de forma nativa. Si desea realizar solicitudes HTTP asíncronas, puede integrarlo conGRequests.
Rastreo
Cuando la configuraciónROBOTSTXT_OBEYse establece enTrue, Scrapy leerá el archivorobots.txt, seguirá automáticamente los enlaces permitidos en una página web y rastreará las páginas permitidas.
Requests no tiene capacidades de rastreo integradas, por lo que es necesario definir manualmente los enlaces y realizar solicitudes adicionales.
Extracción de datos
Scrapy ofrece compatibilidad integrada para extraer datos medianteselectores XPath y CSS, lo que facilita el parseo de HTML y XML.
Requests no incluye ninguna capacidad de extracción de datos. Es necesario utilizar bibliotecas externas comoBeautifulSoup para el parseo y la extracción de datos.
Middleware
Scrapy ofrece middlewares personalizables para gestionarProxies,reintentos,encabezados y mucho más. Esto lo hace muy extensible para tareas de rastreo avanzadas.
Por el contrario, Requests no ofrece compatibilidad con middleware, por lo que es necesario implementar manualmente funciones comola rotación de proxieso los reintentos.
Limitación
Scrapy incluye una función de limitación automática integrada que se utiliza para ajustar la velocidad de rastreo en función de los tiempos de respuesta y la carga del servidor. De este modo, se evita saturar el servidor de destino con solicitudes HTTP.
Requests no tiene una función de limitación integrada. Si desea implementar la limitación, debe añadir manualmente retrasos entre las solicitudes, por ejemplo, utilizando el método time.sleep().
Rotación de proxies
Scrapy admite la rotación de proxies a través de middlewares, lo que facilita evitar las prohibiciones de IP y rastrear sitios de forma anónima.
Requests no ofrece una función de rotación de proxies integrada. Si desea gestionar proxies conrequests, deberá configurarlos manualmente y escribir una lógica personalizada,tal y como se explica en nuestra guía.
Gestión de errores
Scrapy incluye mecanismos de reintento integrados paralas solicitudes fallidas, lo que lo hace robusto para manejar errores de red o problemas del servidor.
Por el contrario, Requests requiere que gestione manualmente los errores y las excepciones, por ejemplo, utilizando el bloquetry-except. Considere también bibliotecas comoretry-requests.
Descargas de archivos
Scrapy admite la descarga de archivos a través deFilesPipeline, pero requiere una configuración adicional para gestionar archivos grandes o streaming.
Requests proporciona una compatibilidad con la descarga de archivos sencilla y directa con el parámetro stream=True en el método requests.get().
Scrapy vs Requests: comparación de las dos bibliotecas en un escenario de paginación
Ahora ya sabe qué son Requests y Scrapy. ¡Prepárese para ver una comparación paso a paso en un tutorial para un escenario específico de Scraping web!
Nos centraremos en mostrar una comparación entre estas dos bibliotecas en un escenario de paginación.El manejo de la paginación en el Scraping webrequiere una lógica personalizada para seguir enlaces y extraer datos en varias páginas.
El sitio de destino seráQuotes to Scrape, que ofrece citas de autores famosos en diferentes páginas:

El objetivo del tutorial es mostrar cómo utilizar Scrapy y Requests para recuperar las citas de todas las páginas. Comenzaremos con Requests, ya que puede ser más complejo de usar que Scrapy.
Requisitos
Para replicar los tutoriales de Scrapy y Requests, debe tener instaladoPython 3.7 o superioren su equipo.
Cómo utilizar Requests para el Scraping web
En este capítulo, aprenderás a utilizar Requests para extraer todas las citas del sitio web de destino.
Ten en cuenta que no puedes usar Requests solo para extraer datos directamente de páginas web. También necesitarás unanalizador HTML como BeautifulSoup.
Paso n.º 1: configuración del entorno e instalación de dependencias
Supongamos que la carpeta principal de su proyecto se llama requests_scraper/. Al final de este paso, la carpeta tendrá la siguiente estructura:
requests_scraper/
├── requests_scraper.py
└── venv/
Donde:
requests_scraper.pyes el archivo Python que contiene todo el códigovenv/contiene el entorno virtual
Puedes crear el directoriodel entorno virtualvenv/de la siguiente manera:
python -m venv venv
Para activarlo, en Windows, ejecuta:
venvScriptsactivate
De forma equivalente, en macOS y Linux, ejecute:
source venv/bin/activate
Ahora puede instalar las bibliotecas necesarias con:
pip install requests beautifulsoup4
Paso n.º 2: configuración de las variables
Ahora ya está listo para empezar a escribir código en el archivo requests_scraper.py.
En primer lugar, configure las variables de la siguiente manera:
base_url = "https://quotes.toscrape.com"
all_quotes = []
Aquí ha definido:
base_urlcomo la URL inicial del sitio web que se va a extraerall_quotescomo una lista vacía utilizada para almacenar todas las cotizaciones a medida que se extraen
Paso n.º 3: crear la lógica de rastreo
Puedes implementar la lógica de rastreo y extracción con el siguiente código:
url = base_url
while url:
# Enviar una solicitud GET a la página actual
response = requests.get(url)
# Analizar el código HTML de la página
soup = BeautifulSoup(response.text, "html.parser")
# Buscar todos los bloques de citas
quotes = soup.select(".quote")
for quote in quotes:
text = quote.select_one(".text").get_text(strip=True)
author = quote.select_one(".author").get_text(strip=True)
tags = [tag.get_text(strip=True) for tag in quote.select(".tag")]
all_quotes.append({
"text": text,
"author": author,
"tags": ",".join(tags)
})
# Buscar el botón «Siguiente»
next_button = soup.select_one("li.next")
if next_button:
# Extrae la URL del botón «Siguiente» y
# la establece como la siguiente página que se va a extraer
next_page = next_button.select_one("a")["href"]
url = base_url + next_page
else:
url = None
Este código:
- Instancia un bucle
whileque continuará ejecutándose hasta que se extraigan todas las páginas - Bajo el bucle
while:soup.``select``()intercepta todos los elementos HTML de citas de la página. El HTML de la página está estructurado de manera que cada elemento de cita tiene una clase llamadaquote.- El ciclo
foritera todas las clasesde citaspara extraer el texto, el autor y las etiquetas de las citas con los métodos de extracción de Beautiful Soup. Aquí, se necesita una lógica personalizada para las etiquetas, ya que cada elemento de cita puede contener más de una etiqueta.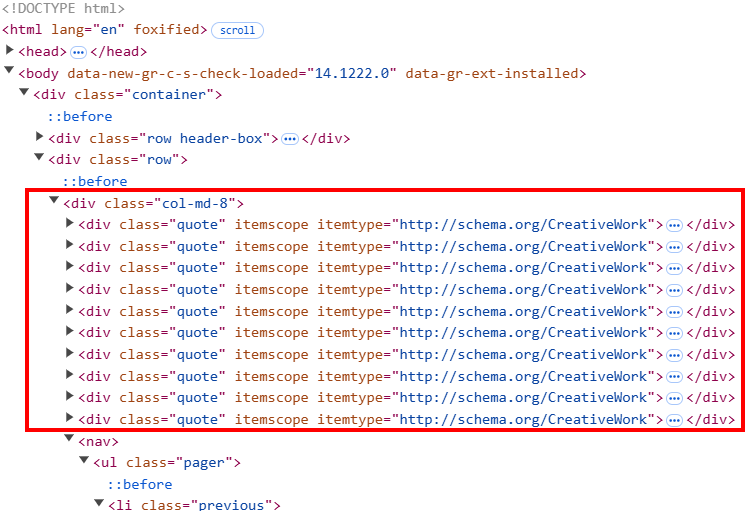
- Después de extraer toda la página, el script busca el botón
siguiente. Si el botón existe, extrae el enlace a la página siguiente. A continuación, la URL base se actualiza para que sea la siguiente mediante la variableurl = base_url + next_page. Cuando el proceso llega a la última página, la siguiente URL se establece enNoney el proceso finaliza.
Paso n.º 4: añadir los datos a un archivo CSV
Ahora que ha extraído todos los datos, puede añadirlos a un archivo CSV como se muestra a continuación:
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
writer.writerows(all_quotes)
Esta parte del script utiliza la bibliotecacsvpara:
- Especificar el nombre del archivo CSV de salida como
quotes.csv. - Abrir el CSV en modo de escritura (
mode="w") y:- Escribir la fila de encabezado en el CSV
- Escribir todas las citas recopiladas en el archivo.
Paso n.º 5: Ponlo todo junto
Este es el código completo para la parte del tutorial dedicada a Scrapy vs Requests:
import requests
from bs4 import BeautifulSoup
import csv
# URL del sitio web
base_url = "https://quotes.toscrape.com"
# Lista para almacenar todas las citas
all_quotes = []
# Empieza a recopilar desde la primera página
url = base_url
while url:
# Envía una solicitud GET a la página actual
response = requests.get(url)
# Analiza el código HTML de la página
soup = BeautifulSoup(response.text, "html.parser")
# Buscar todos los bloques de citas
quotes = soup.select(".quote")
for quote in quotes:
text = quote.select_one(".text").get_text(strip=True)
author = quote.select_one(".author").get_text(strip=True)
tags = [tag.get_text(strip=True) for tag in quote.select(".tag")]
all_quotes.append({
"text": text,
"author": author,
"tags": ",".join(tags)
})
# Buscar el botón «Siguiente»
next_button = soup.select_one("li.next")
if next_button:
# Extrae la URL del botón «Siguiente» y
# la establece como la siguiente página que se va a extraer
next_page = next_button.select_one("a")["href"]
url = base_url + next_page
else:
url = None
# Guardar las citas en un archivo CSV
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
writer.writerows(all_quotes)
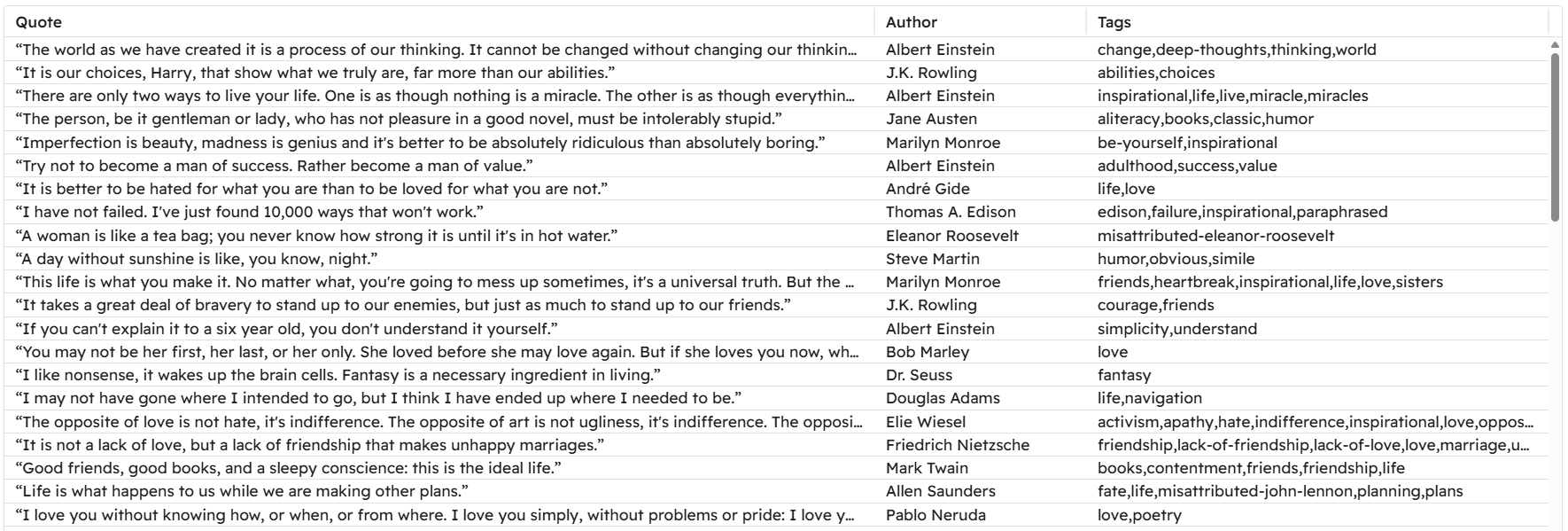
Ejecuta el script anterior:
python requests_scraper.py
Aparecerá un archivoquotes.csven la carpeta del proyecto:
Cómo utilizar Scrapy para el Scraping web
Ahora que ya ha aprendido a utilizar Requests para el Scraping web, está listo para ver cómo utilizar Scrapy con la misma página de destino y el mismo objetivo.
Paso n.º 1: configuración del entorno e instalación de dependencias
Supongamos que quieres llamar a la carpeta principal de tu proyecto scrapy_scraper/.
En primer lugar, crea y activa un entorno virtual como se ha mostrado anteriormente e instala Scrapy:
pip install scrapy
Inicia Scrapy para rellenar la carpeta principal con archivos predefinidos dentro de quotes_scraper/ con:
scrapy startproject quotes_scraper
Esta es la estructura resultante de tu proyecto:
scrapy_scraper/
├── quotes_scraper/ # Carpeta principal del proyecto Scrapy
│ ├── __init__.py
│ ├── items.py # Define la estructura de datos para los elementos extraídos
│ ├── middlewares.py # Middlewares personalizados
│ ├── pipelines.py # Se encarga del posprocesamiento de los datos extraídos
│ ├── settings.py # Configuración del proyecto
│ └── spiders/ # Carpeta para todas las arañas
├── venv/
└── scrapy.cfg # Archivo de configuración de Scrapy
Paso n.º 2: definir los elementos
El archivo items.py define la estructura de los datos que desea extraer. Dado que desea recuperar las citas, los autores y las etiquetas, defínalos de la siguiente manera:
import scrapy
class QuotesScraperItem(scrapy.Item):
quote = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
Paso n.º 3: definir la araña principal
Dentro de la carpeta spiders/, cree los siguientes archivos Python:
__init__.py, que marca el directorio como un paquete Pythonquotes_spider.py
El archivo quotes_spider.py contiene la lógica de scraping real:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import QuotesScraperItem
class QuotesSpider(CrawlSpider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["https://quotes.toscrape.com/"]
# Definir reglas para seguir los enlaces de paginación
rules = (
Rule(LinkExtractor(restrict_css="li.next a"), callback="parse_item", follow=True),
)
def parse_item(self, response):
# Extraer citas, autores y etiquetas
for quote in response.css("div.quote"):
item = QuotesScraperItem()
item["quote"] = quote.css("span.text::text").get()
item["author"] = quote.css("small.author::text").get()
item["tags"] = quote.css("div.tags a.tag::text").getall()
yield item
El fragmento anterior define la clase QuotesSpider() que hace lo siguiente:
- Define la URL que se va a rastrear.
- Define la regla para la paginación con la clase
Rule(), lo que permite al rastreador seguir todas las páginas siguientes. - Extrae la cita, el autor y la etiqueta con el método
parse_item().
Paso n.º 4: definir la configuración
Añadir los datos a un CSV requiere algunas configuraciones especiales en Scrapy. Para ello, abra el archivo settings.py y añada las siguientes variables al archivo:
FEED_FORMAT = "csv"
FEED_URI = "quotes.csv"
Esto es lo que hacen estos ajustes:
FEED_FORMATdefine el formato de salida del archivo (que puede ser de diferentes tipos).FEED_URIdefine el nombre del archivo de salida
Paso n.º 5: Ejecutar el rastreador
Los archivos Python que no se mencionan en los pasos anteriores no son útiles para este tutorial, por lo que puede dejarlos con los datos predeterminados.
Para iniciar el rastreador, vaya a la carpeta quotes_scraper/:
cd quotes_scraper
A continuación, ejecute el rastreador:
scrapy crawl quotes
Este comando instancia la clase QuotesSpider() en el archivo quotes_spider.py, que es el que inicia el rastreador. El archivo CSV final que obtienes es idéntico al que obtuviste con Requests y BeautifulSoup.
Por lo tanto, este ejemplo muestra:
- Cómo Scrapy es más adecuado para proyectos grandes debido a su naturaleza.
- Cómo la gestión de la paginación es más fácil con Scrapy, ya que solo hay que gestionar una regla en lugar de escribir una lógica personalizada, como en el caso anterior.
- Cómo añadir datos a un archivo CSV es más sencillo con Scrapy. Esto se debe a que solo hay que añadir dos ajustes en lugar de crear la lógica personalizada clásica que se crearía al escribir un script de Python que lo hiciera.
Limitaciones comunes entre Scrapy y Requests
Aunque Scrapy y Requests se utilizan ampliamente en proyectos de Scraping web, tienen algunas desventajas.
En concreto, una de las limitaciones comunes a las que están sujetas todas las bibliotecas o marcos de scraping esla prohibición de IP. Ya has aprendido que Scrapy proporciona limitación, lo que ayuda a ajustar la velocidad a la que se solicita el servidor. Sin embargo, a menudo eso no es suficiente para evitar que tu IP sea prohibida.
La solución para evitar que tu IP sea bloqueada es implementar Proxies en tu código. ¡Veamos cómo!
Uso de Proxy con Requests
Si quieres utilizar un único Proxy en Requests, utiliza la siguiente lógica:
Proxy = {
"http": "<HTTP_PROXY_URL>",
"https": "<HTTPS_PROXY_URL>"
}
response = requests.get(url, proxies=Proxy)
Para obtener más información sobre los proxies y la rotación de proxies en las solicitudes, lee estas guías de nuestro blog:
- Guía para usar un Proxy con Python Requests
- Cómo utilizar proxies para rotar direcciones IP en Python
Uso de Proxy en Scrapy
Si desea implementar un único Proxy en su código, añada la siguiente configuración al archivo settings.py:
# Configurar un único Proxy
HTTP_PROXY = "<PROXY_URL>"
# Habilitar HttpProxyMiddleware y deshabilitar UserAgentMiddleware predeterminado
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
Esta configuración enrutará todas las solicitudes a través del Proxy especificado. Obtenga más información en nuestraguía de integración de proxies de Scrapy.
Si, por el contrario, desea implementar proxies rotativos, puede utilizar labibliotecascrapy-rotating-proxies. Del mismo modo, puede utilizar un Proxy residencial con rotación automática.
Si busca proxies fiables, tenga en cuenta que la red de proxies de Bright Data cuenta con la confianza de empresas de la lista Fortune 500 y más de 20 000 clientes en todo el mundo. Esta amplia red incluye:
- Proxies residenciales: más de 72 millones de IPs residenciales en más de 195 países.
- Proxy de centro de datos: más de 770 000 IP de centros de datos.
- Proxy ISP: más de 700 000 IP de ISP.
- Proxy móvil: más de 7 millones de IP móviles.
Conclusión
En esta entrada del blog Scrapy vs Requests, has aprendido cuál es el papel de las dos bibliotecas en el Scraping web. Has explorado sus características para la recuperación de páginas y la extracción de datos, y has comparado su rendimiento en un escenario de paginación real.
Requests requiere más lógica manual, pero ofrece una mayor flexibilidad para casos de uso personalizados, mientras que Scrapy es ligeramente menos adaptable, pero proporciona la mayoría de las herramientas necesarias para el scraping estructurado.
También has descubierto sus limitaciones, como las posibles prohibiciones de IP y los problemas con el contenido restringido geográficamente. Afortunadamente, estos retos se pueden superarutilizando Proxieso soluciones de Scraping web dedicadas, comolos Web Scrapers de Bright Data.
Los Scrapers se integran a la perfección tanto con Scrapy como con Requests, lo que te permite extraer datos públicos de los principales sitios web sin restricciones.
¡Crea hoy mismo una cuenta gratuita en Bright Data para explorar nuestras API de Proxy y Scraper y comienza tu prueba gratuita!





