

En esta guía aprenderás:
- Qué es Ferret y qué ofrece como biblioteca declarativa de web scraping
- Cómo configurarlo para uso local en un entorno Go
- Cómo utilizarlo para recoger datos de un sitio web estático
- Cómo utilizarlo para scrapear un sitio dinámico
- Principales limitaciones de Ferret y cómo solventarlas
Sumerjámonos.
Introducción a Ferret para Web Scraping
Antes de verlo en acción, explore qué es Ferret, cómo funciona, qué ofrece y cuándo utilizarlo.
¿Qué es el hurón?
Ferret es una biblioteca de código abierto escrita en Go. Su objetivo es simplificar la extracción de datos de páginas web mediante un enfoque declarativo. En concreto, se abstrae de las complejidades técnicas de análisis y extracción mediante el uso de su propio lenguaje declarativo personalizado: el Ferret Query Language (FQL).
Con casi 6k estrellas en GitHub, Ferret es una de las librerías de web scraping más populares para Go. Se puede incrustar y es compatible con el raspado web estático y dinámico.
FQL: Lenguaje de consulta Ferret para Web Scraping declarativo
El Ferret Query Language (FQL) es un lenguaje de consulta de propósito general, fuertemente inspirado en el AQL de ArangoDB. Aunque es capaz de mucho más, FQL se utiliza principalmente para extraer datos de páginas web.
FQL sigue un enfoque declarativo, lo que significa que se centra en qué datos recuperar en lugar de cómo recuperarlos. Al igual que AQL, comparte similitudes con SQL. Pero, a diferencia de AQL, FQL es estrictamente de sólo lectura. Tenga en cuenta que cualquier forma de manipulación de datos debe realizarse utilizando funciones incorporadas específicas.
Para más información sobre sintaxis FQL, palabras clave, construcciones y tipos de datos soportados, consulte la página de documentación de FQL.
Casos prácticos
Como se destaca en la página oficial de GitHub, los principales casos de uso de Ferret incluyen:
- Pruebas de interfaz de usuario: Automatice las pruebas en aplicaciones web simulando las interacciones del navegador y validando que los elementos de la página se comportan y renderizan correctamente en diferentes escenarios.
- Aprendizaje automático: Extraer datos estructurados de páginas web y utilizarlos para crear conjuntos de datos de alta calidad. A continuación, pueden utilizarse para entrenar o validar modelos de aprendizaje automático de forma más eficaz. Vea cómo utilizar el web scraping para el aprendizaje automático.
- Analítica: Recoge y agrega datos web -como precios, opiniones o actividad de los usuarios- para generar información, seguir tendencias o crear cuadros de mando.
Al mismo tiempo, hay que tener en cuenta que los posibles casos de uso del web scraping van mucho más allá de estos ejemplos.
Empezar con Ferret
Ahora que sabes lo que es Ferret, estás listo para verlo en acción tanto en páginas web estáticas como dinámicas. Si no estás familiarizado con la diferencia entre ambas, lee nuestra guía sobre contenido estático vs dinámico en web scraping.
Vamos a configurar un entorno para utilizar Ferret para el web scraping.
Requisitos previos
Asegúrese de tener instalado lo siguiente en su máquina local:
- Vaya a
- Docker
Para verificar que Golang está instalado y listo, ejecute el siguiente comando en el terminal:
go versionDebería ver un resultado similar a este:
go version go1.24.3 windows/amd64Si obtiene un error, instale Golang y configúrelo para su sistema operativo.
Del mismo modo, compruebe que Docker está instalado y configurado correctamente para su sistema.
Crear el Proyecto Hurón
Ahora, cree una carpeta para su proyecto de web scraping Ferret y navegue dentro de ella:
mkdir ferret-web-scraping
cd ferret-web-scrapingDescarga el Ferret CLI para tu sistema operativo y descomprímelo directamente en la carpeta ferret-web-scraping/. Comprueba que funciona ejecutando:
./ferret helpLa salida debería ser:
Usage:
ferret [flags]
ferret [command]
Available Commands:
browser Manage Ferret browsers
config Manage Ferret configs
exec Execute a FQL script or launch REPL
help Help about any command
update
version Show the CLI version information
Flags:
-h, --help help for ferret
-l, --log-level string Set the logging level ("debug"|"info"|"warn"|"error"|"fatal") (default "info")
Use "ferret [command] --help" for more information about a command.A continuación, abra la carpeta del proyecto en su IDE favorito, como Visual Studio Code. Dentro de la carpeta del proyecto, crea un archivo llamado scraper.fql:
ferret-web-scraping/
├── ferret
├── CHANGELOG.md
├── LICENSE
├── README.md
└── scraper.fql # <-- The FQL file for web scraping in Ferretscraper.fql contendrá su lógica declarativa FQL para el web scraping.
Configuración de Ferret Docker Setup
Para utilizar todas las funciones de Ferret, debe tener Chrome o Chromium instalado localmente o ejecutándose dentro de Docker. La documentación oficial recomienda ejecutar Chrome/Chromium en un contenedor Docker.
Puedes usar cualquier imagen headless basada en Chromium, pero se recomienda la de montferret/chromium. Recupérala con:
docker pull montferret/chromiumA continuación, ejecute esa imagen Docker con este comando:
docker run -d -p 9222:9222 montferret/chromiumNota: Si desea ver lo que está sucediendo en el navegador durante la ejecución de sus scripts FQL, inicie Chrome en su máquina host con la depuración remota activada con:
chrome.exe --remote-debugging-port=9222Raspar un sitio estático con Ferret
Siga los siguientes pasos para aprender a utilizar Ferret para scrapear un sitio web estático. En este ejemplo, la página de destino será el sitio sandbox “Books to Scrape“:
El objetivo es extraer información clave de cada libro de la página utilizando el enfoque declarativo de Ferret a través de FQL.
Paso nº 1: Conectarse al sitio de destino
En scraper.fql, utilice la función DOCUMENTO para conectarse a la página de destino:
LET doc = DOCUMENT("https://books.toscrape.com/")LET permite definir una variable en FQL. Tras esa instrucción, doc contendrá el HTML de la página de destino.
Paso nº 2: Seleccionar todos los elementos del libro
En primer lugar, familiarícese con la estructura de la página web de destino visitándola en su navegador e inspeccionándola. En concreto, haz clic con el botón derecho del ratón en un elemento del libro y selecciona la opción “Inspeccionar” para abrir las DevTools:
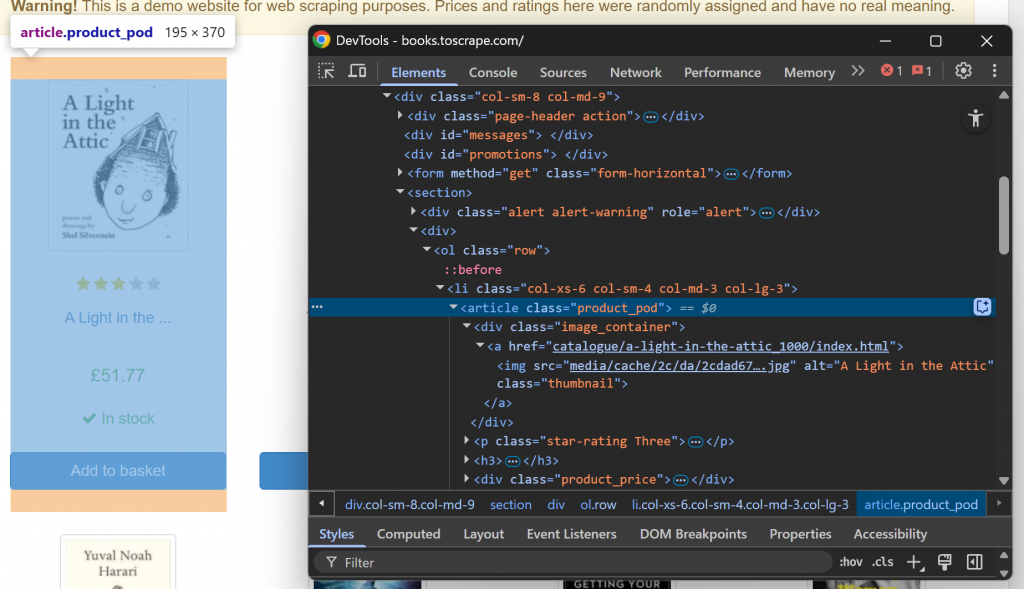
Tenga en cuenta que cada elemento libro es un nodo
. Seleccione todos los elementos libro con la función ELEMENTS():
LET book_elements = ELEMENTS(doc, "section article")ELEMENTS() aplica al documento el selector CSS pasado como segundo argumento. En otras palabras, selecciona los elementos HTML deseados en la página.
Itere sobre la lista de elementos seleccionados y prepárese para aplicarles la lógica de raspado:
FOR book_element IN book_elements
// book scraping logic...¡Increíble! Es hora de iterar sobre cada elemento del libro y extraer datos de cada uno.
Paso nº 3: Extraer datos de cada presupuesto
Ahora, inspeccione un único elemento HTML libro:
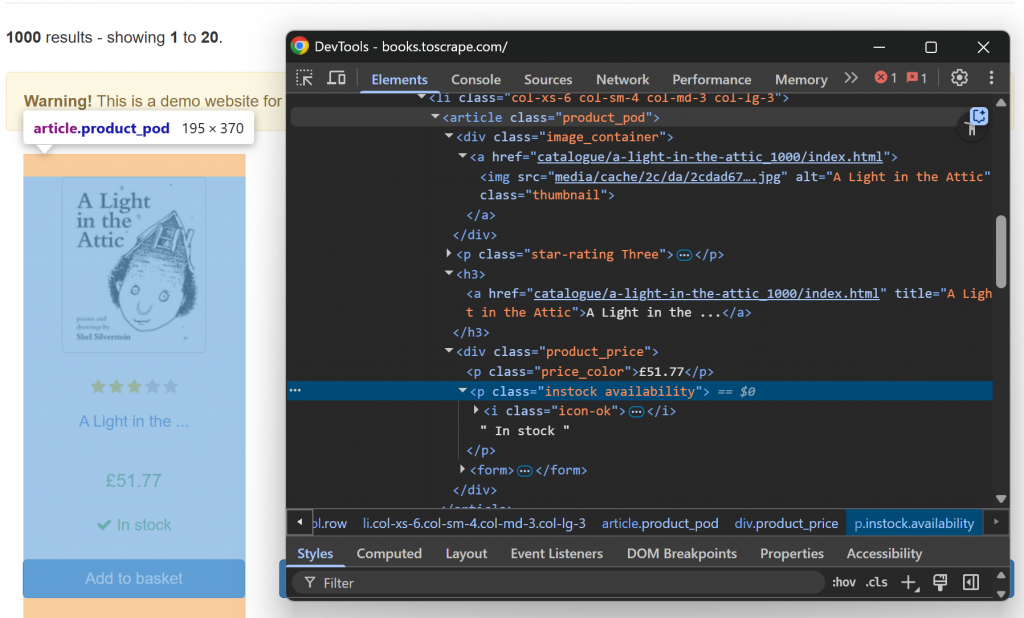
Tenga en cuenta que puede raspar:
- La URL de la imagen del atributo
srcdel elemento.image_container img. - El título del libro a partir del atributo
titledel elementoh3 a. - La URL a la página del libro desde el atributo
hrefdel nodoh3 a. - El precio del libro del texto de
.price_color. - La información de disponibilidad del texto
del .instock.
Implementa esta lógica de análisis de datos con:
LET image_element = ELEMENT(book_element, ".image_container img")
LET title_element = ELEMENT(book_element, "h3 a")
LET price_element = ELEMENT(book_element, ".price_color")
LET availability_element = ELEMENT(book_element, ".instock")
RETURN {
image_url: base_url + image_element.attributes.src,
title: base_url+ title_element.attributes.title,
book_url: title_element.attributes.href,
price: TRIM(INNER_TEXT(price_element)),
availability: TRIM(INNER_TEXT(availability_element))
}Donde base_url es una variable definida fuera del bucle for:
LET base_url = "https://books.toscrape.com/"En el código anterior:
ELEMENT()permite seleccionar un único elemento de la página utilizando un selector CSS.attributeses un atributo especial que tienen todos los objetos devueltos porELEMENT(). Contiene los valores de los atributos HTML del elemento actual.INNER_TEXT()devuelve el texto contenido en el elemento actual.TRIM()elimina los espacios en blanco iniciales y finales.
¡Fantástico! Lógica de raspado estático completada.
Paso 4: Póngalo todo junto
Tu archivo scraper.fql debería tener este aspecto:
// connect to the target site
LET doc = DOCUMENT("https://books.toscrape.com/")
// select the book HTML elements
LET book_elements = ELEMENTS(doc, "section article")
// the base URL of the target site
LET base_url = "https://books.toscrape.com/"
// iterate over each book element and apply the scraping logic
FOR book_element IN book_elements
// select all info elements
LET image_element = ELEMENT(book_element, ".image_container img")
LET title_element = ELEMENT(book_element, "h3 a")
LET price_element = ELEMENT(book_element, ".price_color")
LET availability_element = ELEMENT(book_element, ".instock")
// scrape the data of interest
RETURN {
image_url: base_url + image_element.attributes.src,
title: base_url+ title_element.attributes.title,
book_url: title_element.attributes.href,
price: TRIM(INNER_TEXT(price_element)),
availability: TRIM(INNER_TEXT(availability_element))
}Como puede ver, la lógica de raspado se centra más en qué datos extraer que en cómo extraerlos. ¡Ese es el poder del web scraping declarativo con Ferret!
Paso 5: Ejecutar el script FQL
Ejecute su script Ferret con:
./ferret exec scraper.fqlEn el terminal, la salida será:
[{"availability":"In stock","book_url":"catalogue/a-light-in-the-attic_1000/index.html","image_url":"https://books.toscrape.com/media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg","price":"£51.77","title":"https://books.toscrape.com/A Light in the Attic"},{"availability":"In stock","book_url":"catalogue/tipping-the-velvet_999/index.html","image_url":"https://books.toscrape.com/media/cache/26/0c/260c6ae16bce31c8f8c95daddd9f4a1c.jpg","price":"£53.74","title":"https://books.toscrape.com/Tipping the Velvet"},
// omitted for brevity...
,{"availability":"In stock","book_url":"catalogue/its-only-the-himalayas_981/index.html","image_url":"https://books.toscrape.com/media/cache/27/a5/27a53d0bb95bdd88288eaf66c9230d7e.jpg","price":"£45.17","title":"https://books.toscrape.com/It's Only the Himalayas"}]Se trata de una cadena JSON que contiene todos los datos del libro recogidos de la página web. Para una aproximación no declarativa al análisis de datos, echa un vistazo a nuestra guía sobre web scraping con Go.
Misión cumplida.
Scrapear un sitio dinámico con Ferret
Ferret también soporta el raspado de sitios web dinámicos que requieren la ejecución de JavaScript. En esta sección de la guía, el sitio de destino será la versión con JavaScript retardado del sitio “Quotes to Scrape“:

La página utiliza JavaScript para inyectar dinámicamente elementos de cita en el DOM tras un breve retardo. Este escenario requiere la ejecución de JavaScript, de ahí la necesidad de renderizar la página en un navegador. (Esa también es la razón por la que previamente configuramos un contenedor Docker Chromium).
¡Siga los pasos que se indican a continuación para aprender a manejar páginas web dinámicas con Ferret!
Paso 1: Conéctese a la página de destino en el navegador
Utilice las siguientes líneas para conectarse a la página de destino a través de un navegador headless:
LET doc = DOCUMENT("https://quotes.toscrape.com/js-delayed/?delay=2000", {
driver: "cdp"
})Nótese el uso del campo driver en la función DOCUMENT(). Eso es lo que le dice a Ferret que renderice la página en la instancia Headless Chroumium configurada a través de Docker.
Paso 2: Esperar a que los elementos de destino estén en la página
Visite la página de destino en su navegador, espere a que se carguen los elementos de la cita e inspeccione uno de ellos:
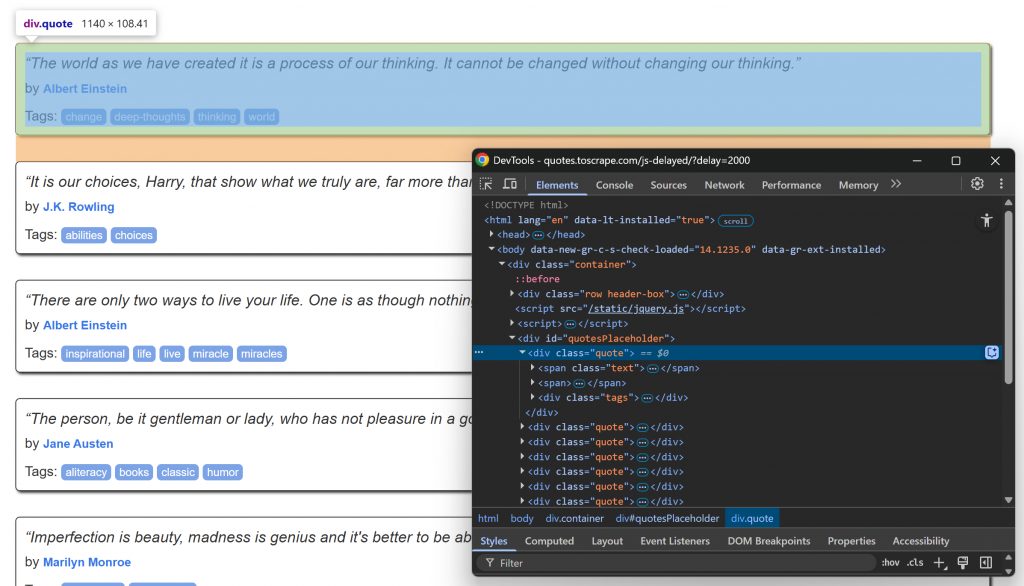
Observe cómo los elementos de cita pueden seleccionarse utilizando el selector CSS .quote. Estos elementos de cita se renderizarán mediante JavaScript tras un breve retardo, por lo que deberá esperar a que aparezcan.
Utilice la función WAIT_ELEMENT() en Ferret para esperar a que los elementos de la cita aparezcan en la página:
// wait up to 5 seconds for the quote elements to be on the page
WAIT_ELEMENT(doc, ".quote", 5000)Se trata de una construcción esencial para el scraping de páginas web dinámicas que dependen de JavaScript para mostrar el contenido.
Paso 3: Aplicar la lógica de raspado
Ahora, céntrate en la estructura HTML de los elementos info dentro de un nodo .quote:
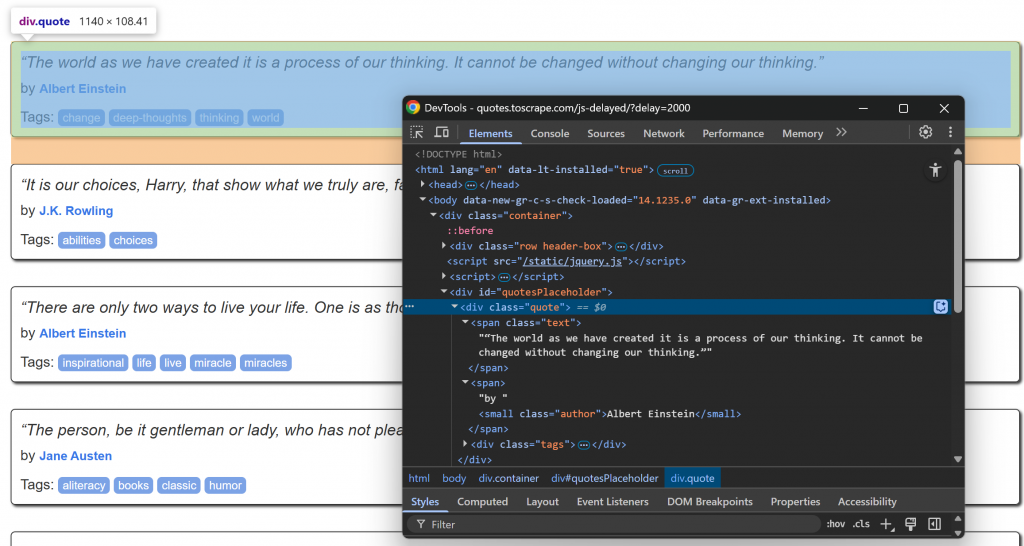
Tenga en cuenta que puede raspar:
- El texto de la cita de
.quote - El autor de
.author
Implementar la lógica de raspado web Ferret con:
// select the quote HTML elements
LET quote_elements = ELEMENTS(doc, ".quote")
// iterate over each quote element and apply the scraping logic
FOR quote_element IN quote_elements
// select all info elements
LET text_element = ELEMENT(quote_element, ".text")
LET author_element = ELEMENT(quote_element, ".author")
// scrape the data of interest
RETURN {
quote: TRIM(INNER_TEXT(text_element)),
author: TRIM(INNER_TEXT(author_element))
} ¡Impresionante! Lógica de análisis completada.
Paso 4: Montarlo todo
El archivo scraper.fql debe contener:
// connect to the target site via the Chromium headless instance
LET doc = DOCUMENT("https://quotes.toscrape.com/js-delayed/?delay=2000", {
driver: "cdp"
})
// wait up to 5 seconds for the quote elements to be on the page
WAIT_ELEMENT(doc, ".quote", 5000)
// select the quote HTML elements
LET quote_elements = ELEMENTS(doc, ".quote")
// iterate over each quote element and apply the scraping logic
FOR quote_element IN quote_elements
// select all info elements
LET text_element = ELEMENT(quote_element, ".text")
LET author_element = ELEMENT(quote_element, ".author")
// scrape the data of interest
RETURN {
quote: TRIM(INNER_TEXT(text_element)),
author: TRIM(INNER_TEXT(author_element))
}Como se puede ver, esto no es muy diferente de la secuencia de comandos para un sitio estático. Una vez más, la razón es que Ferret utiliza un enfoque declarativo para el web scraping.
Paso 5: Ejecutar el código FQL
Ejecute su script de raspado Ferret con:
./ferret exec scraper.fqlEsta vez, el resultado será:
[{"author":"Albert Einstein","quote":"“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”"},{"author":"J.K. Rowling","quote":"“It is our choices, Harry, that show what we truly are, far more than our abilities.”"},{"author":"Albert Einstein","quote":"“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”"},{"author":"Jane Austen","quote":"“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”"},{"author":"Marilyn Monroe","quote":"“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”"},{"author":"Albert Einstein","quote":"“Try not to become a man of success. Rather become a man of value.”"},{"author":"André Gide","quote":"“It is better to be hated for what you are than to be loved for what you are not.”"},{"author":"Thomas A. Edison","quote":"“I have not failed. I've just found 10,000 ways that won't work.”"},{"author":"Eleanor Roosevelt","quote":"“A woman is like a tea bag; you never know how strong it is until it's in hot water.”"},{"author":"Steve Martin","quote":"“A day without sunshine is like, you know, night.”"}]¡Et voilà! Ese es exactamente el contenido estructurado recuperado de la página renderizada con JavaScript.
Limitaciones del método de raspado web declarativo Ferret
Ferret es sin duda una herramienta potente y una de las pocas que adopta un enfoque declarativo del web scraping. Sin embargo, tiene al menos tres grandes inconvenientes:
- Documentación deficiente y actualizaciones poco frecuentes: Aunque la documentación oficial incluye texto útil, carece de referencias completas a la API. Esto dificulta la creación de scripts complejos. Además, el proyecto no recibe actualizaciones periódicas, lo que significa que puede quedarse atrás con respecto a las técnicas modernas de scraping.
- No hay soporte para eludir el anti-scraping: Ferret no ofrece mecanismos incorporados para manejar CAPTCHAs, límites de tasa u otras defensas avanzadas anti-scraping. Esto lo hace inadecuado para el scraping de sitios más protegidos.
- Expresividad limitada: FQ, el Ferret Query Language, está aún en fase de desarrollo y no ofrece el mismo nivel de flexibilidad o control que herramientas de scraping más modernas como Playwright o Puppeteer.
Estas limitaciones no pueden resolverse fácilmente mediante simples integraciones. Además, no hay que olvidar que el objetivo principal de Ferret es recuperar datos web. Por lo tanto, la solución es considerar una alternativa más robusta.
La infraestructura de IA de Bright Data incluye un conjunto de servicios avanzados diseñados para la extracción fiable e inteligente de datos web. Estos le permiten recuperar datos de cualquier sitio web y a escala.
Conclusión
En este tutorial, aprendiste cómo usar Ferret para el raspado web declarativo en Go. Como se ha demostrado, esta biblioteca le permite extraer datos de páginas estáticas y dinámicas, centrándose en qué recuperar, en lugar de cómo recuperarlo.
El problema es que Ferret tiene varias limitaciones, por lo que podría no ser la mejor solución que existe. Si buscas una forma más ágil y escalable de recuperar datos web, considera adoptar las API de Web Scraper:puntos finales dedicadosa extraer datos web frescos, estructurados y totalmente compatibles de más de 120 sitios web populares.
Regístrese hoy mismo para obtener una cuenta gratuita de Bright Data y pruebe nuestra potente infraestructura de raspado web.




