En esta guía aprenderás:
- Por qué debe conocer la diferencia entre contenido estático y dinámico
- Qué es el contenido estático, cómo detectarlo, qué herramientas utilizar para rasparlo y los retos que plantea
- Qué es el contenido dinámico, cómo identificarlo, qué herramientas son las más adecuadas para el scraping y los obstáculos que puede encontrar
- Tabla comparativa de contenidos estáticos y dinámicos en el contexto del web scraping
Sumerjámonos.
Introducción al contenido estático frente al dinámico en el Web Scraping
Cuando se trata de web scraping, hay una diferencia significativa en el enfoque dependiendo de si el contenido que desea extraer es estático o dinámico. Esta distinción afecta en gran medida a la forma de analizar, procesar y extraer los datos.
Por regla general, las secciones o páginas optimizadas para SEO tienden a ser estáticas. En cambio, las secciones muy interactivas o las que requieren actualizaciones en directo suelen ser dinámicas. Sin embargo, en la mayoría de los casos, la realidad es más compleja que eso.
Las páginas web modernas suelen ser híbridas, lo que significa que incluyen tanto contenido estático como dinámico. Por tanto, calificar una página entera de “estática” o “dinámica” no suele ser correcto. Es más preciso decir que el contenido específico de la página es estático o dinámico.
Para complicar aún más las cosas, aunque una página de un sitio sea estática, otra página del mismo sitio puede ser dinámica. Al igual que una página web puede contener ambos tipos de contenido, un sitio web puede ser una colección de páginas estáticas y dinámicas.
Así que, con esto en mente, prepárate para profundizar en la siguiente comparación entre contenido estático y dinámico.
Contenido estático
Vamos a repasar todo lo que necesitas saber sobre el contenido estático de las páginas web y cómo rasparlo.
¿Qué es el contenido estático?
El contenido estático se refiere a todos los elementos de una página web que están incrustados directamente en el documento HTML devuelto por el servidor. En otras palabras, no requiere renderizado del lado del cliente ni recuperación adicional de datos por parte del navegador. Por tanto, todo está ya presente en la respuesta HTML inicial.
Normalmente incluye elementos de interfaz de usuario, texto, imágenes y otros contenidos que no cambian a menos que se actualice el código fuente del servidor. Incluso si el servidor obtiene datos dinámicamente de bases de datos o API antes de generar el documento HTML para enviarlo al cliente, el contenido sigue considerándose estático desde la perspectiva del cliente. La razón es que no es necesario ningún procesamiento posterior en el navegador.
Cómo saber si una página web utiliza contenido estático
Como se mencionó en la introducción, es raro que los sitios web modernos sean 100% estáticos. Después de todo, la mayoría de las páginas web incluyen algún nivel de interactividad del lado del cliente. Así que la verdadera cuestión no es si una página es totalmente estática o dinámica, sino qué partes de la página utilizan contenido estático.
Para determinar si un contenido es estático, hay que inspeccionar el documento HTML en bruto devuelto por el servidor. Tenga en cuenta que esto no es lo mismo que lo que ve en su navegador. El navegador muestra el DOM renderizado, que puede ser modificado por JavaScript después de cargar la página.
Hay dos formas sencillas de comprobar si una página utiliza contenido estático y de identificar qué elementos son estáticos:
- Ver fuente de la página
- Utilizar un cliente HTTP
Para aplicar el primer enfoque, haga clic con el botón derecho del ratón en una zona en blanco de la página y seleccione la opción “Ver origen de la página”:

El resultado será el HTML original devuelto por el servidor:

Por ejemplo, en este caso, puede ver que los elementos de cita ya están presentes en este HTML. Por lo tanto, se puede asumir con seguridad que son estáticos.
El segundo enfoque consiste en realizar una simple petición GET a la URL de la página utilizando un cliente HTTP:

De nuevo, esto muestra el HTML sin procesar devuelto por el servidor. Dado que los clientes HTTP no pueden ejecutar JavaScript, no tienes que preocuparte por los cambios en el DOM. Aún así, como veremos pronto, tu petición puede ser bloqueada por el servidor debido a las protecciones anti-bot. Por lo tanto, se recomienda utilizar el método “Ver el código fuente de la página”.
Herramientas para el scraping de contenido estático
El raspado de contenido estático es sencillo porque está incrustado directamente en el código fuente HTML de la página. A continuación se ofrece una descripción básica del proceso:
- Recupere el documento HTML realizando una petición GET a la URL de la página utilizando un cliente HTTP simple.
- Analiza la respuesta utilizando un analizador HTML.
- Extraiga los elementos deseados utilizando selectores CSS, XPath o estrategias similares proporcionadas por el analizador HTML.
Si buscas herramientas para el scraping de contenidos, consulta nuestras guías detalladas sobre:
Puede encontrar un ejemplo completo relacionado con el sitio “Quotes to Scrape” -cuyo HTML se mostró en una sección anterior- en nuestro tutorial sobre web scraping con Python.
Algunas pilas de scraping populares para recuperar contenido estático incluyen:
- Python: Requests+ Beautiful Soup, HTTPX + Beautiful Soup, AIOHTTP + Beautiful Soup
- JavaScript: Axios + Cheerio, Node Fetch + Cheerio, Fetch API + Cheerio
- PHP: cURL + DomCrawler, Guzzle + DomCrawler, cURL + Simple HTML DOM Parser
- C#: HttpClient + HtmlAgilityPack, HttpClient + AngleSharp
“BeautifulSoup es más rápido y utiliza menos memoria que Selenium. No ejecuta JavaScript, ni hace otra cosa que parsear HTML y trabajar con su DOM.” – Discusión en Reddit
Desafíos del scraping de contenidos estáticos
El principal reto del scraping de contenidos estáticos reside en realizar la petición HTTP correcta para recuperar el documento HTML. Muchos servidores están configurados para servir contenidos sólo a navegadores reales, por lo que pueden bloquear tu petición si carece de ciertas cabeceras o falla las comprobaciones de huellas TLS.
Para evitar estos problemas, debe configurar manualmente las cabeceras HTTP adecuadas para el web scraping. Como alternativa, utilice un cliente HTTP avanzado que pueda simular el comportamiento del navegador, como cURL Impersonate.
De lo contrario, para una solución profesional que no dependa de trucos incómodos o soluciones en su código, considere usar el Desbloqueador Web. Se trata de un endpoint que devuelve el HTML de cualquier página web, independientemente de los mecanismos de defensa implementados por el servidor.
Además, si envías demasiadas peticiones desde la misma dirección IP, puedes provocar una limitación de velocidad o incluso un bloqueo de IP. Para evitarlo, integra proxies rotatorios para distribuir tus peticiones entre múltiples IPs. Consulta nuestra guía sobre cómo evitar bloqueos de IP con proxies.
Contenido dinámico
Continuemos esta guía de contenido estático vs dinámico explorando cómo el contenido dinámico es cargado o renderizado por las páginas web y cómo rasparlo.
¿Qué es el contenido dinámico?
En las páginas web, el contenido dinámico se refiere a cualquier contenido que se carga o representa en el lado del cliente, ya sea durante la carga inicial de la página o después de la interacción del usuario. Esto incluye datos obtenidos mediante tecnologías como AJAX y WebSockets, así como contenido incrustado en JavaScript y renderizado en tiempo de ejecución en el navegador.
En particular, el contenido dinámico no forma parte del documento HTML original devuelto por el servidor. Esto se debe a que se añade a la página después de la ejecución de JavaScript. Eso significa que no será visible a menos que la página se renderice en un navegador, que es el único tipo de herramienta que puede ejecutar JavaScript.
Cómo saber si una página web utiliza contenido dinámico
La forma más sencilla de saber si una página es dinámica o no es seguir el método inverso utilizado para detectar contenido estático. Si el documento HTML devuelto por el servidor no contiene el contenido que se ve en la página, entonces existe algún mecanismo para recuperar o renderizar ese contenido dinámicamente en el cliente.
Lo contrario no funciona necesariamente. Si hay algún contenido en el HTML devuelto por el servidor, eso no significa que la página sea totalmente estática. Ese contenido puede ser obsoleto, y el cliente podría actualizarlo dinámicamente una vez o periódicamente después de que se cargue la página. Este suele ser el caso de las páginas que muestran actualizaciones en directo, por ejemplo.
En general, para ver si una página incluye contenido dinámico, puede recargar la página o repetir la acción del usuario que provoca la aparición del contenido mientras inspecciona la sección “Red” en las DevTools de su navegador:
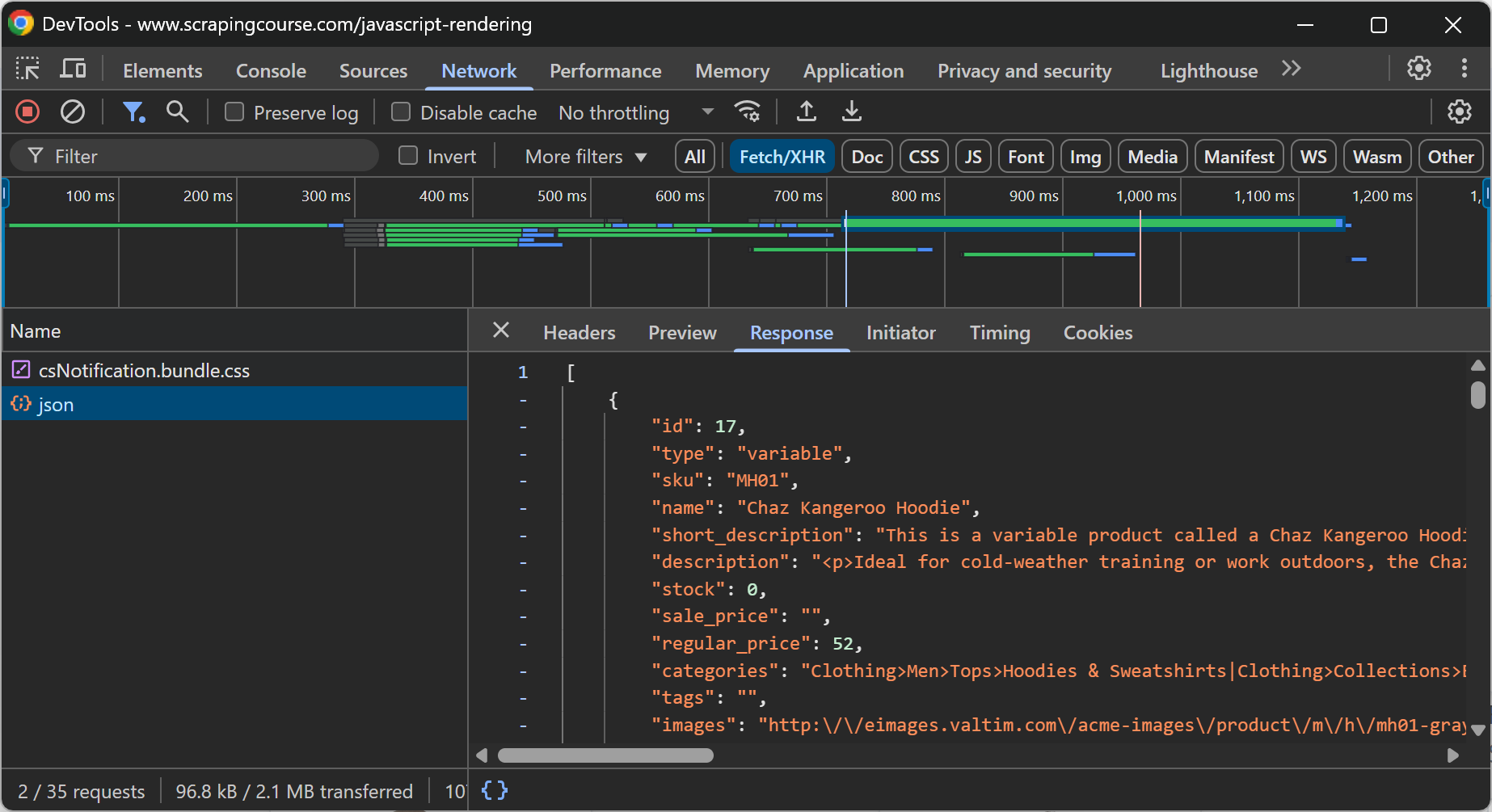
Por ejemplo, en la página web anterior, está claro que los datos de comercio electrónico se recuperan dinámicamente en el cliente mediante una llamada a la API realizada a través de AJAX.
Otra posible fuente de contenido dinámico son las aplicaciones web construidas como SPA(Single-Page Applications). Estas se basan en tecnologías frontales como React, que dependen en gran medida de la renderización de JavaScript. Por lo tanto, si el DOM que ves en DevTools es muy diferente del HTML devuelto por el servidor, entonces la página es dinámica.
Herramientas para el scraping de contenidos dinámicos
El contenido dinámico requiere la ejecución de JavaScript para ser renderizado o recuperado. Dado que solo los navegadores pueden ejecutar JavaScript, las opciones para extraer contenido dinámico suelen limitarse a herramientas de automatización de navegadores como Playwright, Selenium y Puppeteer.
Estas herramientas exponen API que permiten controlar mediante programación un navegador real. Como resultado, el raspado web de contenido dinámico requiere estos tres pasos:
- Indique al navegador que navegue a la página de destino.
- Esperar a que aparezca un contenido dinámico específico en la página.
- Seleccione y extraiga ese contenido utilizando las API de selección de nodos y extracción de datos que proporcionan.
Para más orientación, lea nuestro artículo sobre cómo scrapear sitios web dinámicos en Python.
Retos del raspado dinámico de contenidos
El scraping de contenidos dinámicos es mucho más difícil que el de contenidos estáticos. En primer lugar, porque es posible que tenga que simular las interacciones del usuario en su código para replicar todas las acciones necesarias para acceder al contenido. Eso puede ser un problema cuando se trata de sitios que tienen una navegación compleja.
En segundo lugar, porque las páginas web dinámicas a menudo implementan medidas avanzadas anti-scraping y anti-bot como CAPTCHAs, retos JavaScript, huellas digitales del navegador, etc.
Además, ten en cuenta que las herramientas de automatización de navegadores deben instrumentar el navegador para poder controlarlo. Esos cambios en la configuración del navegador pueden ser suficientes para que los sistemas anti-bot avanzados te detecten como un bot. Esto es especialmente cierto cuando se controla el navegador en modo headless para ahorrar recursos.
Una solución de código abierto para estos problemas es utilizar bibliotecas de automatización del navegador con funciones de evasión anti-bot integradas, como SeleniumBase, Undetected ChromeDriver, Playwright Stealth o Puppeteer Stealth.
Sin embargo, estas soluciones sólo abordan la punta del iceberg y están sujetas a todos los problemas destacados en el scraping de contenido estático, como las prohibiciones de IP, los problemas de reputación de IP y más. Por ello, el enfoque más eficaz es utilizar una solución como Bright Data’s Scraping Browser, que:
- Se integra con Puppeteer, Playwright, Selenium y cualquier otra herramienta de automatización de navegadores
- Se ejecuta en la nube y se amplía infinitamente
- Funciona con una red proxy de más de 150 millones de IP
- Funciona en modo cabeza llena para evitar la detección sin cabeza
- Capacidad integrada para resolver CAPTCHA
- Cuenta con funciones anti-bot de primer orden
Contenido estático frente a contenido dinámico para Web Scraping: Tabla comparativa
Esta es una tabla resumen en la que se comparan los contenidos estáticos y dinámicos para el web scraping:
| Aspecto | Contenido estático | Contenido dinámico |
|---|---|---|
| Definición | Contenido incrustado directamente en la respuesta HTML inicial del servidor | Contenido cargado o generado mediante JavaScript después de que la página se haya cargado |
| Visibilidad en HTML | Visible en el documento HTML devuelto por el servidor | No visible en el documento HTML inicial |
| Localización del renderizado | Renderizado en el servidor | Renderizado del lado del cliente |
| Métodos de detección | – Opción “Ver el código fuente de la página – Inspeccionar HTML en un cliente HTTP |
– Comprobar las diferencias entre el HTML fuente y el DOM renderizado – Inspeccione la pestaña “Red” de DevTools |
| Casos de uso común | – Contenido orientado a SEO – Listados informativos sencillos |
– Actualizaciones en directo – Cuadros de mando específicos para cada usuario – Contenido SPA |
| Dificultad de raspado | Fácil | De medio a duro |
| Enfoque de raspado | Cliente HTTP + analizador HTML | Herramientas de automatización del navegador |
| Rendimiento | Rápido, ya que no hay necesidad de renderizado JS | Lento, ya que implica renderizar páginas en el navegador y esperar a que los elementos se carguen. |
| Principales retos del raspado | – Huella digital TLS – Limitación de velocidad – Prohibición de IP |
– CAPTCHAs – Flujos de navegación/interacción complejos – Desafíos JS |
| Herramientas recomendadas para evitar bloqueos | Proxies, Web Unlocker | Navegador de raspado |
| Ejemplo de pila | Peticiones + Sopa Hermosa | Playwright, Selenium o Puppeteer |
Si desea consultar una lista de herramientas de scraping en lenguajes de programación específicos que cubren ambos escenarios, eche un vistazo a las guías que figuran a continuación:
- Las mejores bibliotecas JavaScript de web scraping
- Las mejores bibliotecas Python de web scraping
- Las 7 mejores bibliotecas PHP de web scraping
- Las 7 mejores bibliotecas de web scraping en C#
Conclusión
En este artículo, has comprendido las diferencias entre el contenido estático y el dinámico de las páginas web, con especial atención al web scraping. Has aprendido qué son estos dos tipos de contenido, en qué se diferencian y cómo manejarlos cuando se analizan datos web.
Independientemente de si se trata de contenidos estáticos o dinámicos, las cosas pueden complicarse debido a las medidas anti-scraping y anti-bot. Ahí es donde entra Bright Data, que ofrece un conjunto completo de herramientas para cubrir todas sus necesidades de scraping:
- Servicios proxy: Varios tipos de proxies para eludir las restricciones geográficas, con más de 150 millones de IP[1].
- Navegador de raspado: Un navegador compatible con Playright, Selenium-, Puppeter con capacidades de desbloqueo integradas.
- APIs de Web Scraper: API preconfiguradas para extraer datos estructurados de más de 100 dominios importantes.
- Desbloqueador Web: Una API todo en uno que maneja el desbloqueo de sitios en sitios con protecciones anti-bot.
- API SERP: Una API especializada que desbloquea los resultados de los motores de búsqueda y extrae datos SERP completos de los principales motores de búsqueda[2].
Cree una cuenta de Bright Data y pruebe nuestros productos de scraping con una versión de prueba gratuita.