

Este tutorial le enseñará a crear un script de Scraping web en Kotlin. En concreto, aprenderá:
- Por qué Kotlin es un lenguaje ideal para extraer datos de un sitio web.
- Cuáles son las mejores bibliotecas de scraping de Kotlin.
- Cómo crear un Scraper Kotlin desde cero.
¡Empecemos!
¿Es Kotlin una opción viable para el Scraping web?
Resumen: ¡Sí, lo es! ¡Y puede que incluso sea mejor que Java!
Kotlin es un lenguaje de programación de uso general, multiplataforma y de tipado estático cuya biblioteca estándar depende de la biblioteca de clases de Java. Lo que hace especial a Kotlin es su enfoque conciso y divertido de la codificación. Cuenta con el respaldo de Google, que lo ha elegido como su lenguaje preferido para el desarrollo de Android.
Gracias a su interoperabilidad con la JVM, es compatible con todas las bibliotecas de scraping de Java. Por lo tanto, puedes aprovechar el vasto ecosistema de bibliotecas de Java, pero con una sintaxis más concisa e intuitiva. ¡Es una situación en la que todos ganan!
Además, Kotlin incluye algunas bibliotecas nativas, entre las que se encuentran analizadores HTML y bibliotecas de automatización de navegadores, que simplifican la extracción de datos. ¡Descubra algunas de las más populares!
Las mejores bibliotecas de Scraping web de Kotlin
Aquí tienes una lista de algunas de las mejores bibliotecas de Scraping web para Kotlin:
- skrape{it}: una biblioteca de pruebas HTML/XML y Scraping web basada en Kotlin para el parseo y la interpretación de HTML. Incluye varios extractores de datos que permiten a skrape{it} actuar tanto como un analizador HTML tradicional como un navegador de scraping sin interfaz gráfica para la representación DOM del lado del cliente.
- chrome-reactive-kotlin: un cliente de protocolo DevTools de bajo nivel escrito en Kotlin para controlar programáticamente el navegador basado en Chromium.
- ksoup: una biblioteca Kotlin ligera inspirada en Jsoup. Ksoup proporciona métodos para analizar HTML, extraer etiquetas HTML, atributos y texto, y codificar y descodificar entidades HTML.
No olvides que Kotlin es interoperable con Java. Esto significa que puedes utilizar cualquier otra biblioteca de Scraping web en Java. Una de ellas es Jsoup, uno de los analizadores HTML más populares que existen. Obtén más información en nuestra guía sobre Scraping web con Jsoup.
Requisitos
Sigue las instrucciones que se indican a continuación para configurar tu entorno Kotlin de Scraping web.
Configurar el entorno
Para escribir y ejecutar una aplicación Kotlin en tu máquina, necesitas tener instalado localmente un JDK (Java Development Kit). Descarga la última versión LTS del JDK desde el sitio web de Oracle, ejecuta el instalador y sigue las instrucciones del asistente de instalación. En el momento de escribir este artículo, es Java 21.
A continuación, necesitará una herramienta para gestionar las dependencias y compilar su aplicación Kotlin. Tanto Gradle como Maven son excelentes opciones, por lo que puede elegir libremente su herramienta de compilación Java favorita. Dado que Gradle es compatible con Kotlin como lenguaje DSL (lenguaje específico de dominio), nos decantaremos por Gradle. Tenga en cuenta que puede seguir fácilmente el tutorial incluso si es usuario de Maven.
Descarga Maven o Gradle e instálalo. Gradle es especialmente sensible a la versión de Java, así que asegúrate de descargar el paquete adecuado. La versión de Gradle compatible con Java 21 es la 8.5 o superior.
Por último, necesitarás un IDE de Kotlin. Visual Studio Code con la extensión Kotlin Language e IntelliJ IDEA Community Edition son dos excelentes opciones gratuitas.
¡Listo! ¡Ya tienes un entorno preparado para Kotlin!
Crear un proyecto Kotlin
Crea una carpeta para tu proyecto de Scraping web en Kotlin e introdúcela en la terminal:
mkdir KotlinWebScraper
cd KotlinWebScraperAquí hemos llamado al directorio KotlinWebScraper, pero puedes ponerle el nombre que quieras.
A continuación, ejecuta el siguiente comando en la carpeta del proyecto para crear una aplicación Gradle:
gradle init --type kotlin-applicationDurante el procedimiento, se le harán algunas preguntas. Debe elegir «Kotlin» como DSL del script de compilación y darle a su aplicación un nombre de paquete adecuado, como com.kotlin.scraper. Para las demás preguntas, las respuestas predeterminadas deberían ser adecuadas.
Esto es lo que verá al final del proceso de inicialización:
Seleccionar DSL del script de compilación:
1: Kotlin
2: Groovy
Introducir selección (predeterminado: Kotlin) [1..2] 1
Nombre del proyecto (predeterminado: KotlinWebScraper):
Paquete fuente (predeterminado: kotlinwebscraper): com.kotlin.scraper
Introducir la versión de Java de destino (mín. 8) (predeterminado: 21):
¿Generar compilación utilizando nuevas API y comportamiento (algunas características pueden cambiar en la próxima versión menor)? (predeterminado: no) [sí, no]
> Tarea :init
Para obtener más información sobre Gradle, explore nuestras muestras en https://docs.gradle.org/8.5/samples/sample_building_kotlin_applications.html
CONSTRUCCIÓN EXITOSA en 2 m 10 s
2 tareas ejecutables: 2 ejecutadas¡Fantástico! La carpeta KotlinWebScraper ahora contendrá un proyecto Gradle.
Abra la carpeta en su IDE de Kotlin, espere a que se completen las tareas en segundo plano necesarias y eche un vistazo al archivo principal App.kt dentro del paquete com.kotlin.scraper. Esto es lo que debería contener:
/*
* Este archivo fuente Kotlin fue generado por la tarea «init» de Gradle.
*/
package com.kotlin.scraping.demo
class App {
val greeting: String
get() {
return "Hello World!"
}
}
fun main() {
println(App().greeting)
}Este es un script Kotlin sencillo que imprime «Hello World!» en la terminal.
Para comprobar que funciona, ejecute el script con el siguiente comando Gradle:
./gradlew runEspera a que se compile y ejecute el proyecto, y verás lo siguiente:
> Tarea :app:run
¡Hola mundo!
CONSTRUCCIÓN EXITOSA en 3 s.
3 tareas procesables: 2 ejecutadas, 1 actualizadaPuede ignorar los mensajes de registro de Gradle. Céntrese en el mensaje «¡Hola mundo!», que es exactamente el resultado que esperaba del script. En otras palabras, su configuración de Kotlin funciona según lo previsto.
¡Es hora de realizar el Scraping web con Kotlin!
Crear un script de Scraping web con Kotlin
En esta sección paso a paso, verás cómo crear un Scraper web en Kotlin. En concreto, aprenderás a definir un script automatizado que extrae datos del sitio de rascado Quotes.
A alto nivel, el script de Scraping web de Kotlin que está a punto de codificar hará lo siguiente:
- Conectarse a la página de destino.
- Seleccionará los elementos HTML de las citas en la página.
- Extraerá los datos deseados de ellos.
- Repetirá esta operación para todas las citas de los sitios, visitando cada página de paginación.
- Exportará los datos recopilados en formato CSV.
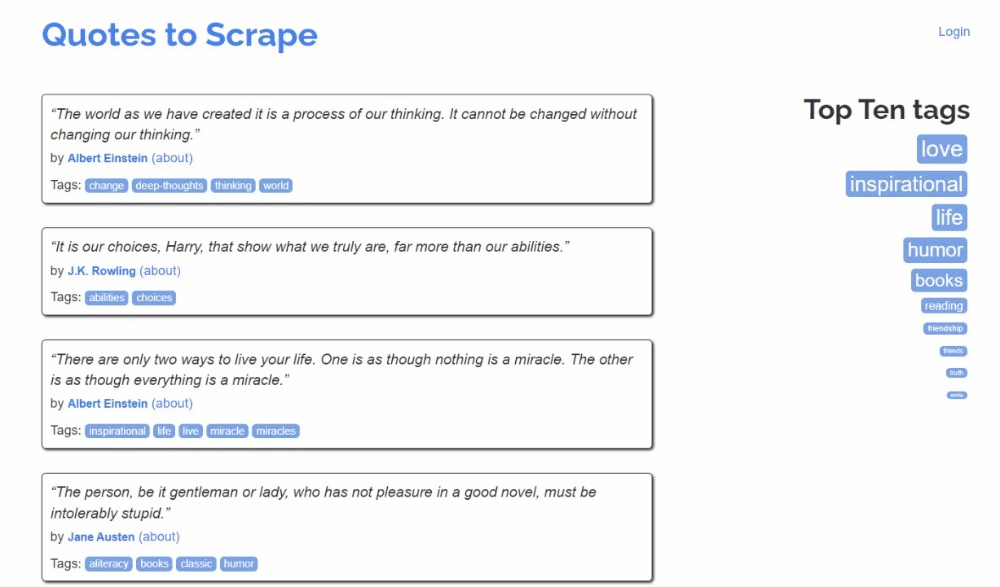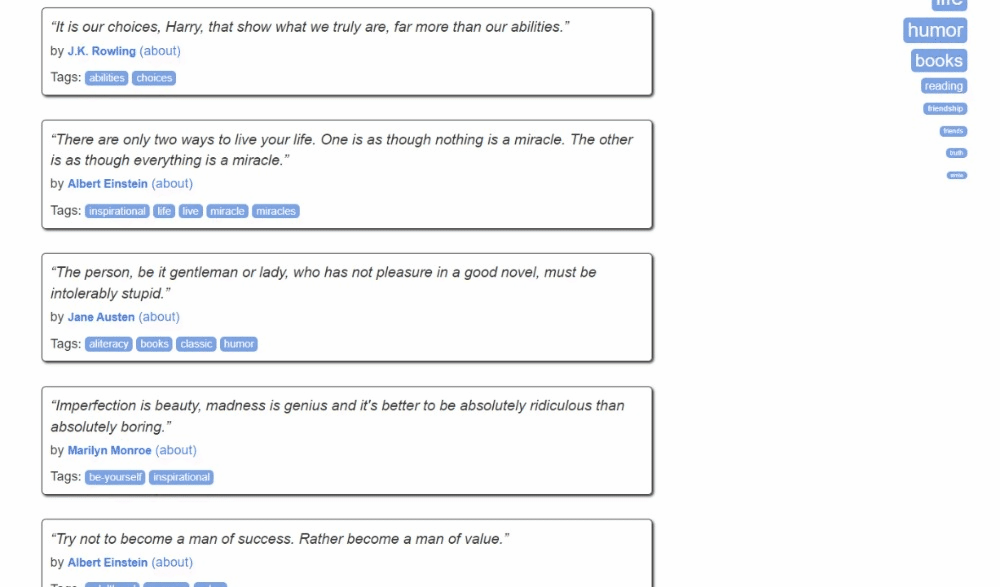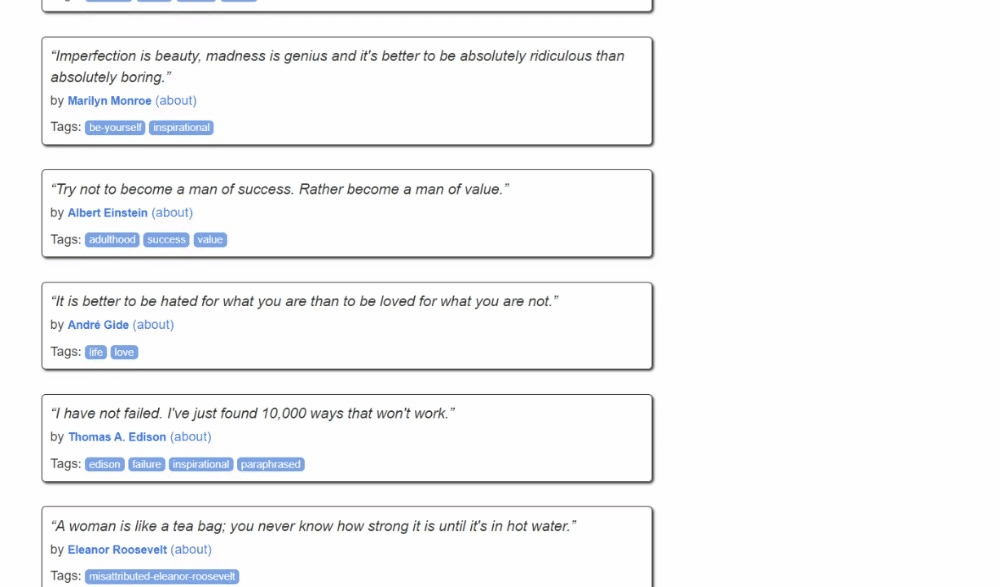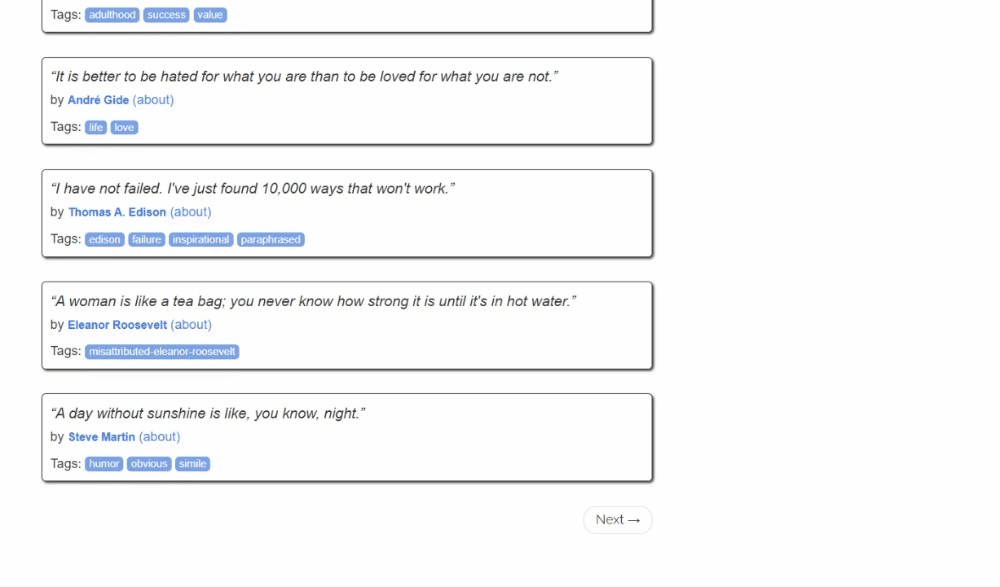
Así es como se ve el sitio de destino:
Siga los pasos que se indican a continuación y descubra cómo realizar el Scraping web en Kotlin.
Paso 1: Instalar la biblioteca de scraping
Lo primero que debe hacer es averiguar qué bibliotecas de Scraping web de Kotlin se adaptan mejor a sus objetivos. Para ello, debe inspeccionar el sitio de destino.
Visita el sitio sandbox Quotes To Scrape en tu navegador. Haz clic con el botón derecho en una sección en blanco y selecciona la opción «Inspeccionar» para abrir DevTools. Ve a la pestaña «Red», vuelve a cargar la página y explora la sección «Fetch/XHR».
Esto es lo que debería ver:
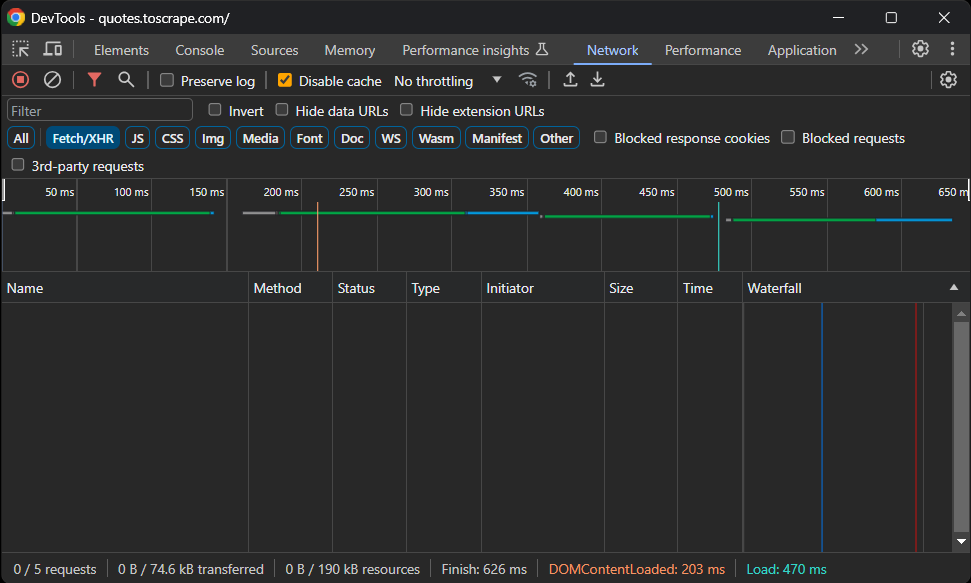
¡No hay solicitudes AJAX! En otras palabras, la página de destino no recupera datos dinámicamente a través de JavaScript. Esto significa que el servidor devuelve páginas a los clientes con todos los datos de interés incrustados en el código HTML.
Por lo tanto, una biblioteca de parseo HTML será suficiente. Puedes seguir utilizando una herramienta de automatización del navegador, pero cargar y renderizar la página en un navegador solo supondría una sobrecarga de rendimiento y no aportaría ningún beneficio real.
Por lo tanto, skrape{it} será una excelente opción para lograr el objetivo de Scraping web. Añádalo a las dependencias de su proyecto con esta línea en el objeto dependencies de su archivo build.gradle.kts:
implementation("it.skrape:skrapeit:1.2.2")Por otro lado, si es usuario de Maven, añada estas líneas a la etiqueta <dependencies> de su pom.xml:
<dependency>
<groupId>it.skrape</groupId>
<artifactId>skrapeit</artifactId>
<version>1.2.2</version>
</dependency>Si utilizas IntelliJ IDEA, el IDE mostrará un botón para recargar las dependencias del proyecto e instalar la nueva biblioteca. Haz clic en él para instalar skrape{it}.
De forma equivalente, puede instalar manualmente la nueva dependencia con este comando Gradle:
./gradlew build --refresh-dependenciesEl proceso de instalación puede tardar un poco, así que ten paciencia.
A continuación, prepárese para utilizar skrape{it} en su script App.kt añadiendo las siguientes importaciones:
import it.skrape.core.*
import it.skrape.fetcher.*No olvide que kkrape{it} incluye muchos extractores de datos. Aquí los hemos importado todos para simplificar. Al mismo tiempo, solo necesitará HttpFetcher, un cliente HTTP clásico que envía una solicitud HTTP a la URL dada y devuelve una respuesta analizada.
¡Genial! ¡Ahora tienes todo lo necesario para realizar Scraping web con Kotlin!
Paso 2: Descarga la página de destino y realiza el parseo de su HTML
En App.kt, elimina la clase App y añade las siguientes líneas en la función main() para conectarte a la página de destino utilizando skrape{it}:
skrape(HttpFetcher) {
// realiza una solicitud HTTP GET a la URL especificada
request {
url = "https://quotes.toscrape.com/"
}
}En segundo plano, skrape{it} utilizará la clase HttpFetcher mencionada anteriormente para realizar una solicitud HTTP GET sincrónica a la URL dada.
Si desea asegurarse de que el script funciona como se desea, añada la siguiente sección en la definición de skrape(HttpFetcher):
response {
// obtener el código fuente HTML e imprimirlo
htmlDocument {
print(html)
}
}Esto le indica a skrape{it} qué hacer con la respuesta del servidor. En concreto, accede a la respuesta analizada y, a continuación, imprime el código HTML de la página.
Tu script de scraping App.kt Kotlin ahora debería contener:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
fun main() {
skrape(HttpFetcher) {
// realiza una solicitud HTTP GET a la URL especificada
request {
url = "https://quotes.toscrape.com/"
}
response {
// obtener el código fuente HTML e imprimirlo
htmlDocument {
print(html)
}
}
}
}Ejecute el script y se imprimirá:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Citas para extraer</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<body>
<!-- omitido por brevedad... -->Ese es exactamente el código HTML de la página de destino. ¡Bien hecho!
Paso 3: Inspeccionar el contenido de la página
El siguiente paso sería definir la lógica de extracción. Pero, ¿cómo puedes hacerlo sin saber cómo seleccionar los elementos de la página? Por eso es importante dar un paso más e inspeccionar la estructura de la página de destino.
Vuelve a abrir Quotes To Scrape en tu navegador. Haz clic con el botón derecho del ratón en un elemento de cita y selecciona «Inspeccionar» para abrir DevTools como se muestra a continuación:
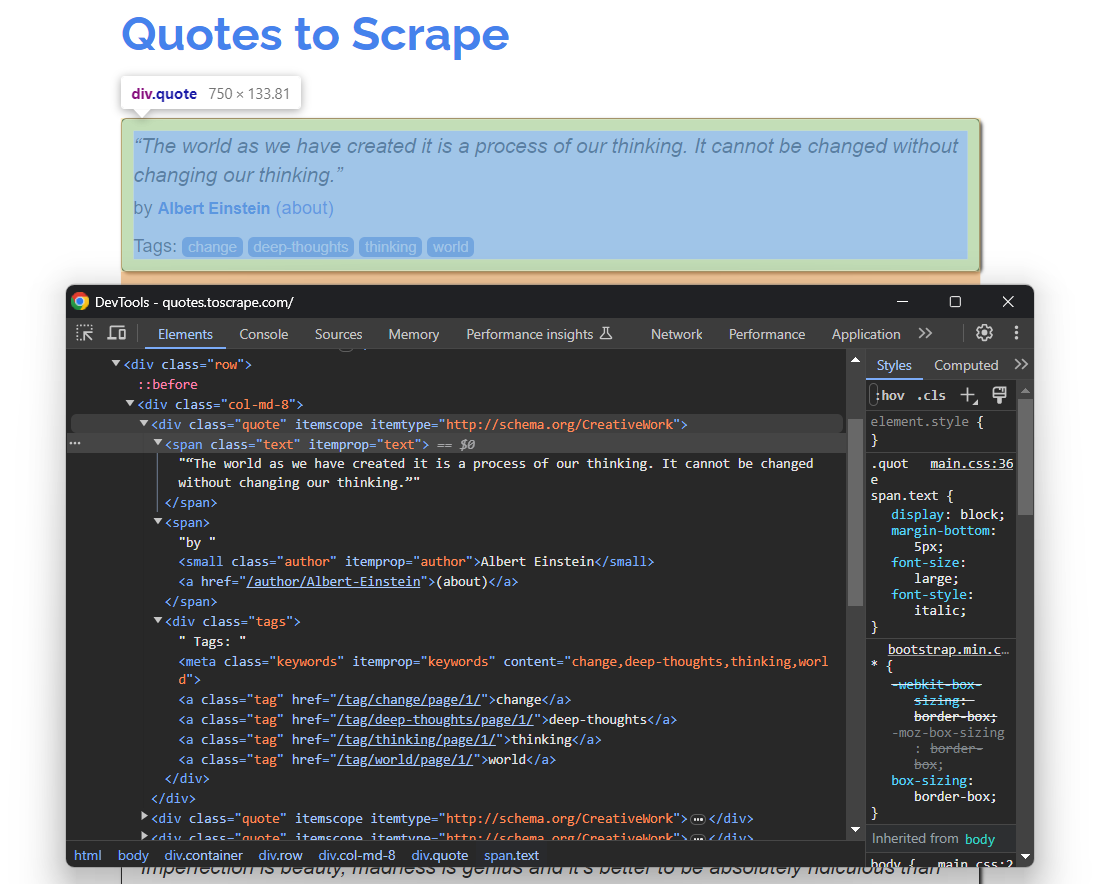
Aquí puede observar que cada tarjeta de cita es un elemento HTML .quote que envuelve:
- Un elemento .text con el texto de la cita.
- Un elemento .author con el nombre del autor.
- Varios elementos .tag, cada uno de los cuales muestra una sola etiqueta.
Ten en cuenta que no todas las citas tienen la sección de etiquetas:

Los selectores CSS anteriores le ayudarán a seleccionar los elementos DOM deseados de la página para extraer datos de ellos. También necesitará una clase donde almacenar estos datos. Por lo tanto, añada la siguiente definición de clase Quote en la parte superior de su script Kotlin de Scraping web:
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}Dado que la página contiene varias citas, instancie una lista de objetos Quote en main():
val quotes: MutableList<Quote> = ArrayList()Al final del script, quotes contendrá todas las citas recopiladas del sitio.
¡Utilice lo que ha comprendido y definido aquí para implementar la lógica de scraping en el siguiente paso!
Paso 4: Implementa la lógica de scraping
skrape{it} tiene una forma peculiar de seleccionar nodos HTML en una página. Para aplicar un selector CSS en la página, debes definir una sección dentro de htmlDocument con el mismo nombre que el selector CSS:
skrape(HttpFetcher) {
// sección de solicitud...
response {
htmlDocument {
// seleccionar todos los elementos HTML «.quote» de la página
«.quote» {
// lógica de scraping...
}
}
}
}Dentro de la sección «.quote», puede definir una sección findAll. Esta contendrá la lógica que se aplicará a cada nodo HTML de cita seleccionado con el selector CSS especificado. En cambio, findFirst solo le proporcionará el primer elemento seleccionado.
Entre bastidores, todas estas secciones no son más que funciones lambda de Kotlin. Por eso, puede acceder al elemento DOM único con él en una sección forEach dentro de findAll. Si no está familiarizado con ello, es el nombre implícito de un parámetro único en una lambda.
Sigue una lógica similar, pero basada en métodos y atributos. A continuación, puede implementar la lógica de scraping para extraer los datos deseados de cada cita, instanciar un objeto Quote y añadirlo a la lista de citas de la siguiente manera:
".quote" {
findAll {
forEach {
// lógica de scraping en un único elemento de cita
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch(e: ElementNotFoundException) {
null
}
// crear un objeto Quote y añadirlo a la lista
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}Gracias al atributo text, puedes recuperar el texto interno de un elemento HTML. Dado que no todos los elementos HTML de cita contienen etiquetas, debes gestionar la excepción ElementNotFoundException. Esta excepción la lanza findAll cuando el selector CSS dado no coincide con ningún nodo de la página.
Importa ElementNotFoundException con:
import it.skrape.selects.ElementNotFoundException
Reúna todos los fragmentos y registre los datos contenidos en la matriz de citas:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
import it.skrape.selects.ElementNotFoundException
// define una clase para representar los datos extraídos en Kotlin
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}
fun main() {
// dónde almacenar los datos extraídos
val quotes: MutableList<Quote> = ArrayList()
skrape(HttpFetcher) {
// realizar una solicitud HTTP GET a la URL especificada
request {
url = "https://quotes.toscrape.com/"
}
response {
htmlDocument {
// seleccionar todos los elementos HTML «.quote» de la página
«.quote» {
findAll {
forEach {
// lógica de recopilación en un único elemento de cita
val text = it.findFirst(«.text»).text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch(e: ElementNotFoundException) {
null
}
// crear un objeto Quote y añadirlo a la lista
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}
}
}
}
// registra los datos recopilados
for (quote in quotes) {
println("Texto: ${quote.text}")
println("Autor: ${quote.author}")
println("Etiquetas: ${quote.tags.joinToString("; ")}")
println()
}
}Observe el uso de joingToString() para fusionar la lista de etiquetas en una cadena separada por comas.
Si ejecuta el script, obtendrá lo siguiente:
Texto: «El mundo tal y como lo hemos creado es un proceso de nuestro pensamiento. No se puede cambiar sin cambiar nuestra forma de pensar».
Autor: Albert Einstein.
Etiquetas: cambio; pensamientos profundos; pensamiento; mundo.
# omitido por brevedad...
Texto: «Un día sin sol es como, ya sabes, la noche».
Autor: Steve Martin.
Etiquetas: humor; obvio; símil.¡Vaya! ¡Acabas de aprender a realizar Scraping web con Kotlin!
Paso 5: Añadir la lógica de rastreo
Acabas de extraer datos de una sola página, pero la lista de citas se extiende a lo largo de varias páginas. Si te desplazas hacia abajo hasta el final de la página, verás un botón «Siguiente →» con un enlace a la página siguiente:
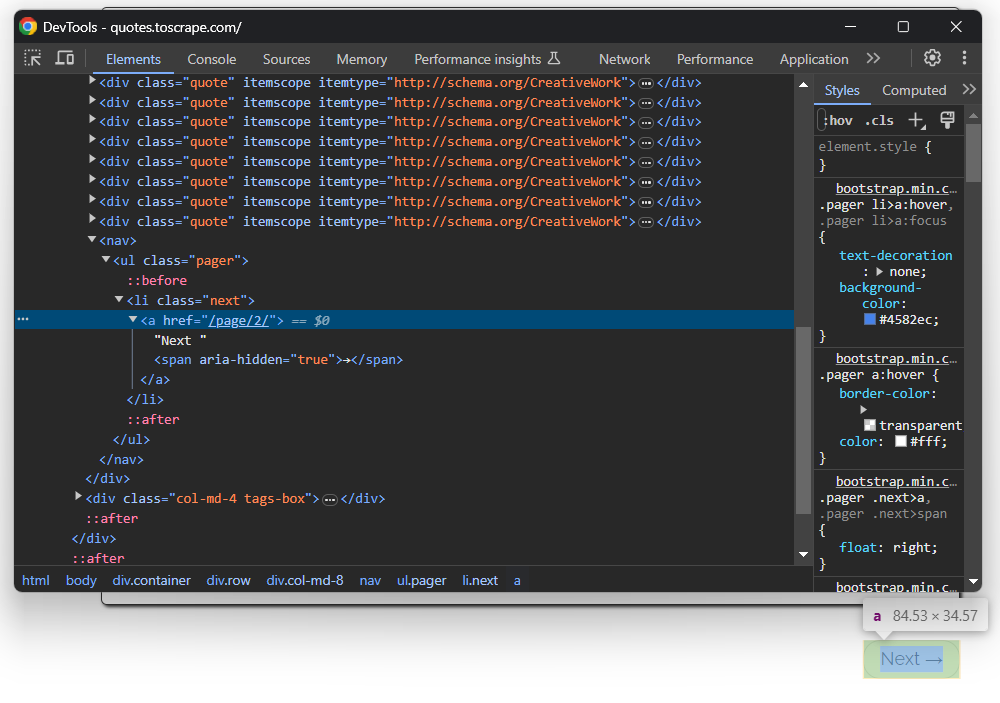
Esto es así en todas las páginas excepto en la última:
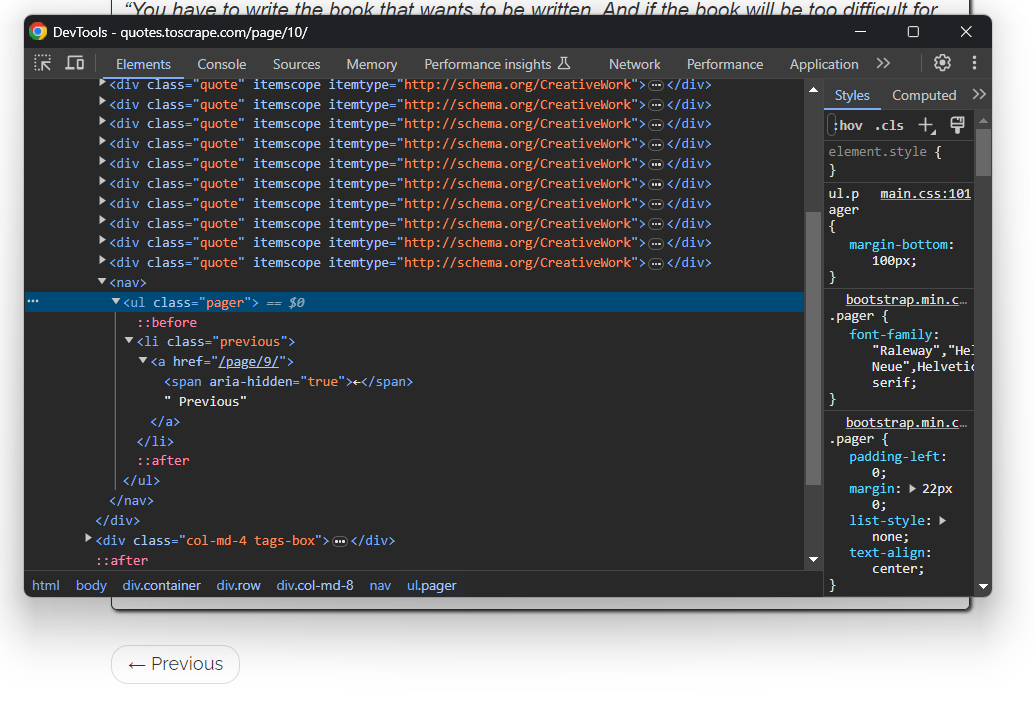
Para realizar el rastreo web en Kotlin y extraer cada cita del sitio, debes hacer lo siguiente:
- Extraer todas las citas de la página actual.
- Seleccionar el elemento «Siguiente →», si está presente, y extraer de él la URL de la página siguiente.
- Repetir el primer paso en la nueva página.
Implementar el algoritmo anterior de la siguiente manera:
En lugar de extraer una sola página y luego detenerse, el script ahora se basa en un bucle while. Este continúa iterando hasta que no hay más páginas que extraer. Eso ocurre cuando el selector CSS .next a genera una excepción ElementNotFoundException, lo que significa que el botón «Siguiente →» no está en la página y, por lo tanto, se encuentra en la última página de paginación del sitio.
Ten en cuenta que la sección htmlDocument puede contener varias secciones de selectores CSS. Cada una se ejecutará en el orden especificado. Si vuelves a ejecutar el script Kotlin de Scraping web, las citas almacenarán ahora las 100 citas del sitio.
¡Genial! La lógica de rastreo y Scraping web de Kotlin está lista. Solo queda eliminar el código de registro con la lógica de exportación de datos.
Paso 7: Exportar los datos extraídos a CSV
Los datos recopilados se almacenan actualmente en una lista de objetos Quote. Imprimirlos en la terminal es útil, pero exportarlos a CSV es la mejor manera de sacarles el máximo partido. Esto permitirá a otros miembros de su equipo filtrar, leer y analizar esos datos.
Kotlin te proporciona todo lo que necesitas para crear un archivo CSV y rellenarlo, pero el uso de una biblioteca lo hace todo más fácil. Una biblioteca nativa de Kotlin muy popular para leer y escribir archivos CSV es kotlin-csv.
Añádala a las dependencias de su proyecto en build.gradle.kts:
implementation("com.github.doyaaaaaken:kotlin-csv-jvm:1.9.3")O si utilizas Maven:
<dependency>
<groupId>com.github.doyaaaaaken</groupId>
<artifactId>kotlin-csv-jvm</artifactId>
<version>1.9.3</version>
</dependency>Instala la biblioteca e impórtala en tu archivo App.kt:
import com.github.doyaaaaaken.kotlincsv.dsl.*Ahora puedes exportar citas a un archivo CSV con solo unas pocas líneas de código:
val header = listOf("quote", "author", "tags")
val csvContent: List<List<String>> = quotes.map { quote ->
listOf(
quote.text,
quote.author,
quote.tags.joinToString("; ")
)
}
csvWriter().open("quotes.csv") {
writeRow(header)
writeRows(csvContent)
}Ten en cuenta que List<String> es la forma en que se representa un registro CSV en kotlin-csv. Primero, define un registro para la fila del encabezado. A continuación, convierte las citas a los datos deseados. Después, inicializa un escritor CSV, crea un archivo quotes.csv y rellénalo con writeRow() y writeRows().
¡Ya está! Solo queda echar un vistazo al código final de su script de Scraping web en Kotlin.
Paso 8: Ponlo todo junto
Este es el código final de su Scraper Kotlin:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
import it.skrape.selects.ElementNotFoundException
import com.github.doyaaaaaken.kotlincsv.dsl.*
// define una clase para representar los datos extraídos en Kotlin
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}
fun main() {
// dónde almacenar los datos extraídos
val quotes: MutableList<Quote> = ArrayList()
// la URL de la siguiente página a visitar
var nextUrl: String? = "https://quotes.toscrape.com/"
// hasta que haya una página que visitar
while (nextUrl != null) {
skrape(HttpFetcher) {
// realizar una solicitud HTTP GET a la URL especificada
request {
url = nextUrl!!
}
response {
htmlDocument {
// seleccionar todos los elementos HTML «.quote» de la página
«.quote» {
findAll {
forEach {
// lógica de scraping en un único elemento de cita
val text = it.findFirst(«.text»).text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch (e: ElementNotFoundException) {
null
}
// crear un objeto Quote y añadirlo a la lista
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}
// lógica de rastreo
try {
".next a" {
findFirst {
nextUrl = "https://quotes.toscrape.com" + attribute("href")
}
}
} catch (e: ElementNotFoundException) {
nextUrl = null
}
}
}
}
}
// crear un archivo «quotes.csv» y rellenarlo
// con los datos extraídos
val header = listOf("quote", "author", "tags")
val csvContent: List<List<String>> = quotes.map { quote ->
listOf(
quote.text,
quote.author,
quote.tags.joinToString("; ")
)
}
csvWriter().open("quotes.csv") {
writeRow(header)
writeRows(csvContent)
}
}¿Puedes creerlo? Gracias a skrape{it}, puedes recuperar datos de todo un sitio web con menos de 100 líneas de código.
Ejecuta tu script Kotlin de Scraping web con:
./gradlew runTen paciencia mientras el Scraper revisa cada página del sitio de destino. Cuando haya terminado, aparecerá un archivo quotes.csv en el directorio raíz de tu proyecto. Ábrelo y deberías ver los siguientes datos:
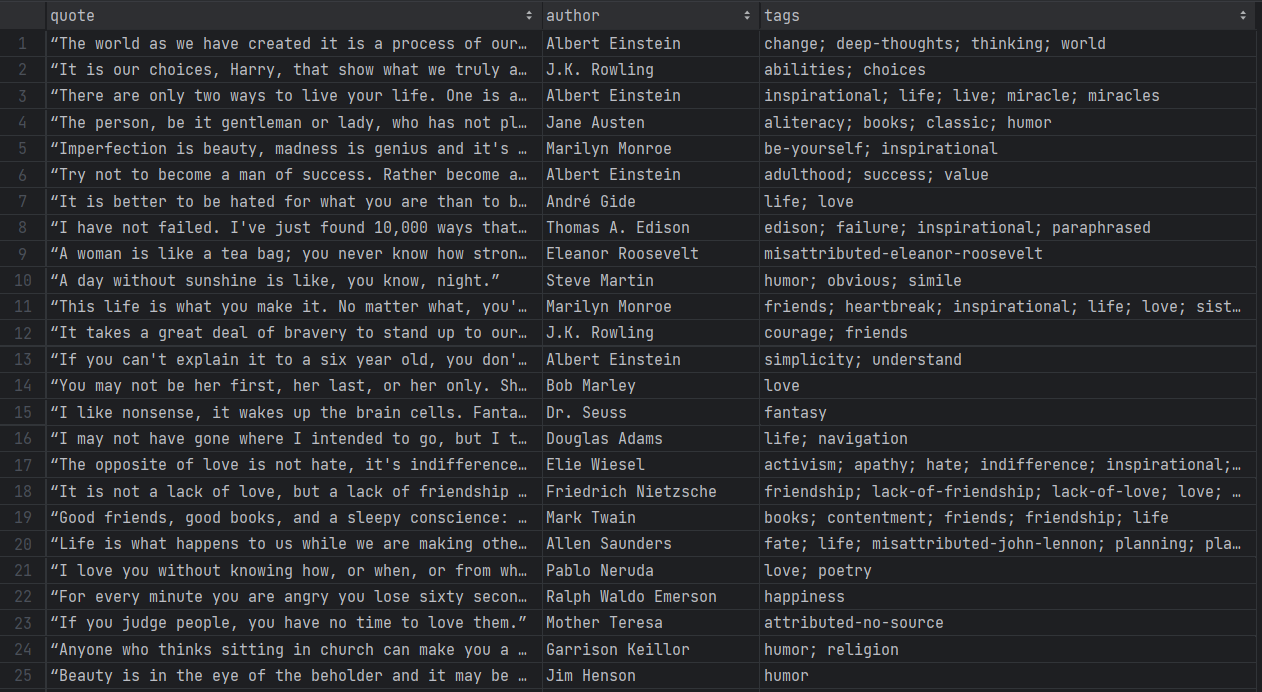
¡Et voilà! Empezaste con datos no estructurados en páginas online y ahora los tienes en un archivo CSV fácil de explorar.
Evita las prohibiciones de IP en Kotlin con un Proxy
Al realizar Scraping web con Kotlin, uno de los mayores retos es que las tecnologías antibots te bloqueen. Estos sistemas pueden detectar la naturaleza automatizada de tu script y bloquear tu IP. De esta forma, detienen tu operación de scraping.
¿Cómo evitarlo? ¡Con un Proxy web!
Sigue los pasos que se indican a continuación y aprende a integrar un Proxy de Bright Data en Kotlin.
Configurar un Proxy en Bright Data
Bright Data es el mejor servidor proxy del mercado, que supervisa miles de servidores proxy en todo el mundo. Cuando se trata de la rotación de IP, el mejor tipo de proxy es el Proxy residencial.
Para empezar, si ya tienes una cuenta, inicia sesión en Bright Data. Si no es así, crea una cuenta gratuita. Obtendrás acceso al siguiente panel de control de usuario:
Haz clic en el botón «Ver productos Proxy» como se muestra a continuación:
Se le redirigirá a la siguiente página «Proxies e infraestructura de scraping»:
Desplácese hacia abajo, busque la tarjeta «Proxies residenciales» y haga clic en el botón «Empezar»:
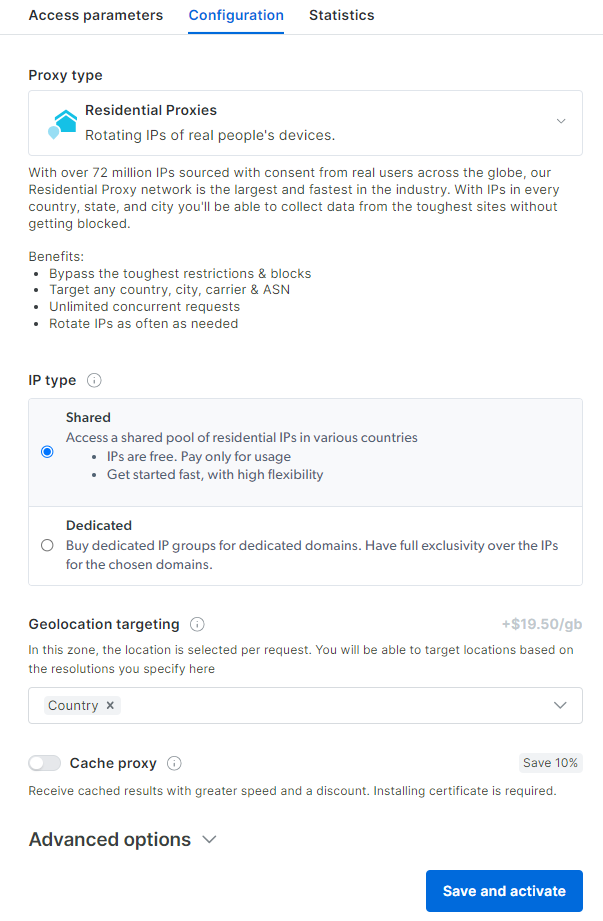
Llegará al panel de configuración del Proxy residencial. Siga el asistente guiado y configure el servicio de Proxy según sus necesidades. Si tiene alguna duda sobre cómo configurar el Proxy, no dude en ponerse en contacto con el servicio de asistencia 24/7.
Vaya a la pestaña «Parámetros de acceso» y recupere el host, el puerto, el nombre de usuario y la contraseña de su Proxy de la siguiente manera:
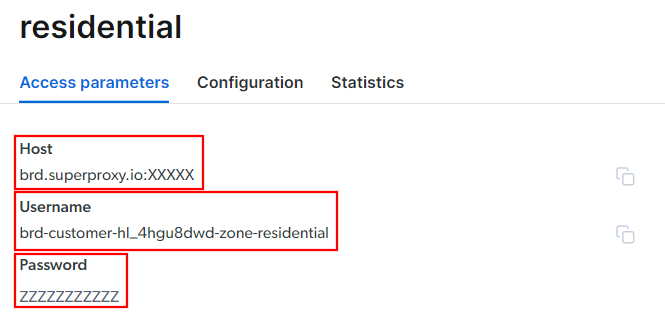
Ten en cuenta que el campo «Host» ya incluye el puerto.
Eso es todo lo que necesita para crear la URL del Proxy y utilizarla en skrape{it}. Reúna toda la información y cree una URL con la siguiente sintaxis:
<Nombre de usuario>:<Contraseña>@<Host>Por ejemplo, en este caso sería:
brd-customer-hl_4hgu8dwd-zona-residential:[email protected]:XXXXXActive «Proxy activo», siga las últimas instrucciones y ¡ya está listo para empezar!

Integra el Proxy en Kotlin
El fragmento de código para la integración de Bright Data en skrape{it} tendrá el siguiente aspecto:
skrape(HttpFetcher) {
request {
url = "https://quotes.toscrape.com/"
proxy = proxyBuilder {
type = Proxy.Type.HTTP
host = "brd.superproxy.io"
port = XXXXX
}
authentication = basic {
username = "brd-customer-hl_4hgu8dwd-zona-residential"
password = "ZZZZZZZZZZ"
}
}
// ...
}Como puede ver, todo se reduce al uso de las opciones de Proxy y solicitud de autenticación. A partir de ahora, skrape{it} realizará la solicitud a la URL especificada a través del Proxy de Bright Data. ¡Adiós a las prohibiciones de IP!
Mantenga su operación de Scraping web con Kotlin ética y respetuosa
El scraping web es una forma eficaz de recopilar datos útiles para diversos casos de uso. Ten en cuenta que el objetivo final es recuperar esos datos, no dañar el sitio de destino. Por lo tanto, debes abordar esta tarea con las precauciones adecuadas.
Sigue los consejos que se indican a continuación para realizar Scraping web con Kotlin de forma responsable:
- Céntrate solo en la información disponible públicamente: concéntrate en recuperar datos que sean de acceso público en el sitio. Evita las páginas protegidas por credenciales de inicio de sesión u otras formas de autorización. El scraping de datos privados o confidenciales sin el permiso adecuado es poco ético y puede acarrear consecuencias legales.
- Respete el archivo robots.txt: cada sitio tiene un archivo robots.txt que define las reglas sobre cómo los rastreadores automatizados deben acceder a sus páginas. Para mantener prácticas de scraping éticas, debe cumplir con esas directrices. Obtenga más información en nuestra guía robots.txt para el Scraping web.
- Limite la frecuencia de sus solicitudes: realizar demasiadas solicitudes en poco tiempo provocará una sobrecarga del servidor, lo que afectará al rendimiento del sitio para todos los usuarios. Esto también podría desencadenar medidas de limitación de velocidad y bloquearle el acceso. Por este motivo, evite saturar el servidor de destino añadiendo retrasos aleatorios a sus solicitudes.
- Compruebe y cumpla con los términos de servicio del sitio: antes de extraer datos de un sitio, revise sus términos de servicio. Estos pueden contener información sobre derechos de autor, derechos de propiedad intelectual y directrices sobre cómo y cuándo utilizar sus datos.
- Confíe en herramientas de scraping fiables y actualizadas: seleccione proveedores de confianza y opte por herramientas y bibliotecas que estén bien mantenidas y se actualicen periódicamente. Solo así podrá asegurarse de que se ajustan a los últimos principios éticos de scraping de Kotlin. Si tiene alguna duda, consulte nuestro artículo sobre cómo elegir el mejor servicio de Scraping web.
Conclusión
En esta guía, ha visto por qué Kotlin es un lenguaje ideal para el Scraping web, especialmente en comparación con Java. También ha visto una lista de las mejores bibliotecas de Scraping de Kotlin. A continuación, ha aprendido a utilizar skrape{it} para crear un Scraper que extrae datos de varias páginas de un sitio web real. Como ha podido comprobar, el Scraping web con Kotlin es sencillo y solo requiere unas pocas líneas de código.
El principal reto para tu operación de scraping son las soluciones anti-bot. Los sitios web adoptan estos sistemas para proteger sus datos de los scripts automatizados, bloqueándolos antes de que puedan acceder a sus páginas. Eludirlos no es fácil y requiere herramientas avanzadas. Afortunadamente, ¡Bright Data te tiene cubierto!
Estos son algunos de los productos de scraping que ofrece Bright Data:
- API de Scraper web: API fáciles de usar para el acceso programático a datos web estructurados de docenas de dominios populares.
- Navegador de scraping: un navegador controlable basado en la nube que ofrece capacidades de renderización de JavaScript mientras gestiona las huellas digitales del navegador, los CAPTCHA, los reintentos automatizados y mucho más por ti. Se integra con las bibliotecas de navegadores de automatización más populares, como Playwright y Puppeteer.
- Web Unlocker: una API de desbloqueo que puede devolver sin problemas el HTML sin procesar de cualquier página, eludiendo cualquier medida antirraspado.
¿No quiere ocuparse del Scraping web, pero sigue interesado en los datos en línea? ¡Explore los Conjuntos de datos listos para usar de Bright Data!




