

Este sistema encuentra nuevos clientes potenciales utilizando inteligencia web en tiempo real, detecta automáticamente señales de compra y genera comunicaciones personalizadas basadas en eventos empresariales reales. Pasa directamente a la acción en GitHub.
Aprenderás:
- Cómo crear sistemas multiagente utilizando CrewAI para tareas de prospección especializadas
- Cómo aprovechar Bright Data MCP para obtener inteligencia en tiempo real sobre empresas y contactos
- Cómo detectar automáticamente eventos desencadenantes como contrataciones, financiaciones y cambios en el liderazgo
- Cómo generar comunicaciones personalizadas basadas en inteligencia empresarial en tiempo real.
- Cómo crear un proceso automatizado desde el descubrimiento de clientes potenciales hasta la integración con CRM
¡Empecemos!
El reto del desarrollo de ventas moderno
El desarrollo de ventas tradicional se basa en la investigación manual, que incluye: saltar entre perfiles de LinkedIn, sitios web de empresas y artículos de noticias para identificar clientes potenciales. Este enfoque requiere mucho tiempo, es propenso a errores y, a menudo, da lugar a listas de contactos obsoletas y a una comunicación mal dirigida.
La integración de CrewAI con Bright Data automatiza todo el flujo de trabajo de prospección, reduciendo las horas de trabajo manual a solo unos minutos.
Lo que estamos creando: un sistema inteligente de desarrollo de ventas
Creará un sistema de IA multiagente que encuentra empresas que se ajustan a su perfil de cliente ideal. Realizará un seguimiento de los eventos desencadenantes que muestran la intención de compra, recopilará información verificada sobre los responsables de la toma de decisiones y creará mensajes de divulgación personalizados utilizando inteligencia empresarial real. El sistema se conecta directamente a su CRM para mantener un canal de ventas cualificado.
Requisitos previos
Configura tu entorno de desarrollo con estos requisitos:
- Instalación dePython 3.11+
- Cuenta de Bright Data con acceso MCP
- Clave API de OpenAI para la generación de IA
- Credenciales de HubSpot CRM para la integración del canal
Configuración del entorno
Cree el directorio de su proyecto e instale las dependencias. Comience por configurar un entorno virtual limpio para evitar conflictos con otros proyectos de Python.
python -m venv ai_bdr_env
source ai_bdr_env/bin/activate # Windows: ai_bdr_envScriptsactivate
pip install crewai "crewai-tools[mcp]" openai pandas python-dotenv streamlit requestsCree la configuración del entorno:
BRIGHT_DATA_API_TOKEN="tu_token_bright_data_api"
OPENAI_API_KEY="tu_clave_openai_api"
HUBSPOT_API_KEY="tu_clave_hubspot_api"Creación del sistema BDR con IA
Ahora vamos a empezar a crear los agentes de IA para nuestro sistema BDR de IA.
Paso 1: Configuración de Bright Data MCP
Cree la base para la infraestructura de scraping web que recopila datos en tiempo real de múltiples fuentes. El cliente MCP se encarga de toda la comunicación con la red de scraping de Bright Data.
Cree un archivo mcp_client.py en el directorio raíz de su proyecto y añada el siguiente código:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call, deduplicate_by_key, extract_domain_from_url
class CompanyDiscoveryInput(BaseModel):
industry: str = Field(description="Sector objetivo para la búsqueda de empresas")
size_range: str = Field(description="Rango de tamaño de la empresa (startup, pequeña, mediana, gran empresa)")
location: str = Field(default="", description="Ubicación geográfica o región")
class CompanyDiscoveryTool(BaseTool):
name: str = "discover_companies"
description: str = "Buscar empresas que cumplan los criterios ICP mediante Scraping web"
args_schema: type[BaseModel] = CompanyDiscoveryInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, industry: str, size_range: str, location: str = "") -> list:
companies = []
search_terms = [
f"{industry} companies {size_range}",
f"{industry} startups {location}",
f"{industry} technology companies"
]
for term in search_terms:
results = self._search_companies(term)
for company in results:
enriched = self._enrich_company_data(company)
if self._matches_icp(enriched, industry, size_range):
companies.append(enriched)
return deduplicate_by_key(companies, lambda c: c.get('domain') or c['name'].lower())
def _search_companies(self, term):
"""Buscar empresas utilizando la búsqueda web real a través de Bright Data."""
try:
companies = []
search_queries = [
f"{term} directory",
f"{term} list",
f"{term} news"
]
for query in search_queries:
try:
results = self._perform_company_search(query)
companies.extend(results)
if len(companies) >= 10:
break
except Exception as e:
print(f"Error en la consulta de búsqueda '{query}': {str(e)}")
continue
return self._filter_unique_companies(companies)
except Exception as e:
print(f"Error al buscar empresas para '{term}': {str(e)}")
return []
def _enrich_company_data(self, company):
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
website_data = safe_mcp_call(self.mcp, 'scrape_company_website', company.get('domain', ''))
employee_count = linkedin_data.get('employee_count') or 150
return {
**company,
'linkedin_intelligence': linkedin_data,
'website_intelligence': website_data,
'employee_count': employee_count,
'icp_score': 0
}
def _matches_icp(self, company, industry, size_range):
score = 0
if industry.lower() in company.get('industry', '').lower():
score += 30
if self._check_size_range(company.get('employee_count', 0), size_range):
score += 25
if company.get('name') and company.get('domain'):
score += 20
company['icp_score'] = score
return score >= 20
def _check_size_range(self, count, size_range):
rangos = {'startup': (1, 50), 'small': (51, 200), 'medium': (201, 1000)}
tamaño_mínimo, tamaño_máximo = rangos.get(rango_tamaño, (0, 999999))
devuelve tamaño_mínimo <= recuento <= tamaño_máximo
def _perform_company_search(self, query):
"""Realizar búsqueda de empresas utilizando Bright Data MCP."""
search_result = safe_mcp_call(self.mcp, 'search_company_news', query)
if search_result and search_result.get('results'):
return self._extract_companies_from_mcp_results(search_result['results'], query)
else:
print(f"No hay resultados MCP para: {query}")
return []
def _filter_unique_companies(self, companies):
"""Filtrar las empresas duplicadas."""
seen_names = set()
unique_companies = []
for company in companies:
name_key = company.get('name', '').lower()
if name_key and name_key not in seen_names:
seen_names.add(name_key)
unique_companies.append(company)
return unique_companies
def _extract_companies_from_mcp_results(self, mcp_results, original_query):
"""Extraer información de la empresa de los resultados de búsqueda de MCP."""
companies = []
for result in mcp_results[:10]:
try:
title = result.get('title', '')
url = result.get('url', '')
snippet = result.get('snippet', '')
company_name = self._extract_company_name_from_result(title, url)
if company_name and len(company_name) > 2:
domain = self._extract_domain_from_url(url)
industry = self._extract_industry_from_query(original_query)
companies.append({
'name': company_name,
'domain': domain,
'industry': industry
})
except Exception as e:
print(f"Error al extraer la empresa del resultado MCP: {str(e)}")
continue
return companies
def _extract_company_name_from_result(self, title, url):
"""Extrae el nombre de la empresa del título o la URL del resultado de la búsqueda."""
import re
if title:
title_clean = re.sub(r'[|-—–].*$', '', title).strip()
title_clean = re.sub(r's+(Inc|Corp|LLC|Ltd|Solutions|Systems|Technologies|Software|Platform|Company)$', '', title_clean, flags=re.IGNORECASE)
if len(title_clean) > 2 and len(title_clean) < 50:
return title_clean
if url:
domain_parts = url.split('/')[2].split('.')
if len(domain_parts) > 1:
return domain_parts[0].title()
return None
def _extract_domain_from_url(self, url):
"""Extraer el dominio de la URL."""
return extract_domain_from_url(url)
def _extract_industry_from_query(self, query):
"""Extraer el sector de la consulta de búsqueda."""
query_lower = query.lower()
industry_mappings = {
'saas': 'SaaS',
'fintech': 'FinTech',
'ecommerce': 'E-commerce',
'healthcare': 'Healthcare',
'ai': 'IA/ML',
'machine learning': 'IA/ML',
'artificial intelligence': 'IA/ML'
}
for keyword, industry in industry_mappings.items():
if keyword in query_lower:
return industry
return 'Technology'
def create_company_discovery_agent(mcp_client):
return Agent(
role='Company Discovery Specialist',
goal='Find high-quality prospects matching ICP criteria',
backstory='Expert at identifying potential customers using real-time web intelligence.',
tools=[CompanyDiscoveryTool(mcp_client)],
verbose=True
)Este cliente MCP gestiona todas las tareas de Scraping web utilizando la infraestructura de IA de Bright Data. Ofrece un acceso fiable a las páginas de empresa de LinkedIn, sitios web corporativos, bases de datos de financiación y fuentes de noticias. El cliente se encarga de la agrupación de conexiones y aborda automáticamente las protecciones antibots.
Paso 2: Agente de descubrimiento de empresas
Transforme los criterios de su perfil de cliente ideal en un sistema de descubrimiento inteligente que encuentre empresas que se ajusten a sus requisitos específicos. El agente busca en múltiples fuentes y mejora los datos de las empresas con inteligencia empresarial.
En primer lugar, cree una carpeta de agentes en la raíz de su proyecto. A continuación, cree un archivo agents/company_discovery.py y añada el siguiente código:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call, deduplicate_by_key, extract_domain_from_url
class CompanyDiscoveryInput(BaseModel):
industry: str = Field(description="Sector objetivo para la búsqueda de empresas")
size_range: str = Field(description="Rango de tamaño de la empresa (startup, pequeña, mediana, gran empresa)")
location: str = Field(default="", description="Ubicación geográfica o región")
class CompanyDiscoveryTool(BaseTool):
name: str = "discover_companies"
description: str = "Buscar empresas que cumplan los criterios ICP mediante Scraping web"
args_schema: type[BaseModel] = CompanyDiscoveryInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, industry: str, size_range: str, location: str = "") -> list:
companies = []
search_terms = [
f"{industry} companies {size_range}",
f"{industry} startups {location}",
f"{industry} technology companies"
]
for term in search_terms:
results = self._search_companies(term)
for company in results:
enriched = self._enrich_company_data(company)
if self._matches_icp(enriched, industry, size_range):
companies.append(enriched)
return deduplicate_by_key(companies, lambda c: c.get('domain') or c['name'].lower())
def _search_companies(self, term):
"""Buscar empresas utilizando la búsqueda web real a través de Bright Data."""
try:
companies = []
search_queries = [
f"{term} directory",
f"{term} list",
f"{term} news"
]
for query in search_queries:
try:
results = self._perform_company_search(query)
companies.extend(results)
if len(companies) >= 10:
break
except Exception as e:
print(f"Error en la consulta de búsqueda '{query}': {str(e)}")
continue
return self._filter_unique_companies(companies)
except Exception as e:
print(f"Error al buscar empresas para '{term}': {str(e)}")
return []
def _enrich_company_data(self, company):
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
website_data = safe_mcp_call(self.mcp, 'scrape_company_website', company.get('domain', ''))
employee_count = linkedin_data.get('employee_count') or 150
return {
**company,
'linkedin_intelligence': linkedin_data,
'website_intelligence': website_data,
'employee_count': employee_count,
'icp_score': 0
}
def _matches_icp(self, company, industry, size_range):
score = 0
if industry.lower() in company.get('industry', '').lower():
score += 30
if self._check_size_range(company.get('employee_count', 0), size_range):
score += 25
if company.get('name') and company.get('domain'):
score += 20
company['icp_score'] = score
return score >= 20
def _check_size_range(self, count, size_range):
rangos = {'startup': (1, 50), 'small': (51, 200), 'medium': (201, 1000)}
min_size, max_size = rangos.get(rango_tamaño, (0, 999999))
return min_size <= recuento <= max_size
def create_company_discovery_agent(mcp_client):
return Agent(
role='Company Discovery Specialist',
goal='Find high-quality prospects matching ICP criteria',
backstory='Expert at identifying potential customers using real-time web intelligence.',
tools=[CompanyDiscoveryTool(mcp_client)],
verbose=True
)El agente de descubrimiento busca en varias fuentes de datos para encontrar empresas que se ajusten a su perfil de cliente ideal. Añade información comercial de LinkedIn y sitios web corporativos para cada empresa. A continuación, filtra los resultados en función de los criterios de puntuación que usted pueda establecer. El proceso de deduplicación mantiene limpias las listas de clientes potenciales, evitando entradas duplicadas.
Paso 3: Activar el agente de detección
Supervise los eventos empresariales que muestran intención de compra y el mejor momento para contactar. El agente analiza los patrones de contratación, los anuncios de financiación, los cambios en la dirección y las señales de expansión para priorizar a los clientes potenciales.
Cree un archivo agents/trigger_detection.py y añada el siguiente código:
from crewai import Agent, Task
from crewai.tools import BaseTool
from datetime import datetime, timedelta
from typing import Any, List
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call
class TriggerDetectionInput(BaseModel):
companies: List[dict] = Field(description="Lista de empresas que se analizarán en busca de eventos desencadenantes")
class TriggerDetectionTool(BaseTool):
name: str = "detect_triggers"
description: str = "Buscar señales de contratación, noticias sobre financiación, cambios en la dirección"
args_schema: type[BaseModel] = TriggerDetectionInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, companies) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
for company in companies:
triggers = []
hiring_signals = self._detect_hiring_triggers(company)
triggers.extend(hiring_signals)
funding_signals = self._detect_funding_triggers(company)
triggers.extend(funding_signals)
señales_de_liderazgo = self._detect_leadership_triggers(empresa)
desencadenantes.extender(señales_de_liderazgo)
señales_de_expansión = self._detect_expansion_triggers(empresa)
desencadenantes.extender(señales_de_expansión)
company['trigger_events'] = triggers
company['trigger_score'] = self._calculate_trigger_score(triggers)
return sorted(companies, key=lambda x: x.get('trigger_score', 0), reverse=True)
def _detect_hiring_triggers(self, company):
"""Detectar desencadenantes de contratación utilizando datos de LinkedIn."""
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
triggers = []
if linkedin_data:
hiring_posts = linkedin_data.get('hiring_posts', [])
recent_activity = linkedin_data.get('recent_activity', [])
if hiring_posts:
triggers.append({
'type': 'hiring_spike',
'severity': 'high',
'description': f"Active hiring detected at {company['name']} - {len(hiring_posts)} open positions",
'date_detected': datetime.now().isoformat(),
'source': 'linkedin_api'
})
if recent_activity:
triggers.append({
'type': 'company_activity',
'severity': 'medium',
'description': f"Aumento de la actividad en LinkedIn en {company['name']}",
'date_detected': datetime.now().isoformat(),
'source': 'linkedin_api'
})
return triggers
def _detect_funding_triggers(self, company):
"""Detectar desencadenantes de financiación mediante la búsqueda de noticias."""
funding_data = safe_mcp_call(self.mcp, 'search_funding_news', company['name'])
triggers = []
if funding_data and funding_data.get('results'):
triggers.append({
'type': 'funding_round',
'severity': 'high',
'description': f"Recent funding activity detected at {company['name']}",
'date_detected': datetime.now().isoformat(),
'source': 'news_search'
})
return triggers
def _detect_leadership_triggers(self, company):
"""Detectar cambios en el liderazgo mediante la búsqueda de noticias."""
return self._detect_keyword_triggers(
company, 'leadership_change', 'medium',
['ceo', 'cto', 'vp', 'hired', 'joins', 'appointed'],
f"Se han detectado cambios en la dirección de {company['name']}"
)
def _detect_expansion_triggers(self, company):
"""Detectar la expansión empresarial mediante la búsqueda de noticias."""
return self._detect_keyword_triggers(
company, 'expansion', 'medium',
['expansion', 'new office', 'opening', 'market'],
f"Expansión empresarial detectada en {company['name']}"
)
def _detect_keyword_triggers(self, company, trigger_type, severity, keywords, description):
"""Método genérico para detectar desencadenantes basados en palabras clave en las noticias."""
news_data = safe_mcp_call(self.mcp, 'search_company_news', company['name'])
triggers = []
if news_data and news_data.get('results'):
for result in news_data['results']:
if any(keyword in str(result).lower() for keyword in keywords):
triggers.append({
'type': trigger_type,
'severity': severity,
'description': description,
'date_detected': datetime.now().isoformat(),
'source': 'news_search'
})
break
return triggers
def _calculate_trigger_score(self, triggers):
severity_weights = {'high': 15, 'medium': 10, 'low': 5}
return sum(severity_weights.get(t.get('severity', 'low'), 5) for t in triggers)
def create_trigger_detection_agent(mcp_client):
return Agent(
role='Trigger Event Analyst',
goal='Identify buying signals and optimal timing for outreach',
backstory='Expert at detecting business events that indicate readiness to buy.',
tools=[TriggerDetectionTool(mcp_client)],
verbose=True
)El sistema de detección de desencadenantes supervisa diversas señales comerciales que muestran la intención de compra y los mejores momentos para la divulgación. Examina los patrones de contratación de las ofertas de empleo de LinkedIn, realiza un seguimiento de los anuncios de financiación en las fuentes de noticias, vigila los cambios en el liderazgo e identifica las actividades de expansión. Cada desencadenante obtiene una puntuación de gravedad que ayuda a priorizar los clientes potenciales en función de la urgencia y el tamaño de la oportunidad.
Paso 4: Agente de investigación de contactos
Busque y verifique la información de contacto de los responsables de la toma de decisiones, teniendo en cuenta las puntuaciones de confianza de diversas fuentes de datos. El agente prioriza los contactos en función de su función y la calidad de los datos.
Cree un archivo agents/contact_research.py y añada el siguiente código:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any, List
from pydantic import BaseModel, Field
import re
from .utils import validate_companies_input, safe_mcp_call, validate_email, deduplicate_by_key
class ContactResearchInput(BaseModel):
companies: List[dict] = Field(description="Lista de empresas para las que investigar contactos")
target_roles: List[str] = Field(description="Lista de funciones objetivo para las que encontrar contactos")
class ContactResearchTool(BaseTool):
name: str = "research_contacts"
description: str = "Buscar y verificar la información de contacto de los responsables de la toma de decisiones utilizando MCP"
args_schema: type[BaseModel] = ContactResearchInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, companies, target_roles) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
if not isinstance(target_roles, list):
target_roles = [target_roles] if target_roles else []
for company in companies:
contactos = []
para rol en roles_objetivo:
contactos_rol = self._search_contacts_by_role(empresa, rol)
para contacto en contactos_rol:
enriquecido = self._enrich_contact_data(contacto, empresa)
si self._validate_contact(enriquecido):
contactos.append(enriquecido)
company['contacts'] = self._deduplicate_contacts(contacts)
company['contact_score'] = self._calculate_contact_quality(contacts)
return companies
def _search_contacts_by_role(self, company, role):
"""Busca contactos por función utilizando MCP."""
contacts = []
search_query = f"{company['name']} {role} LinkedIn contact"
search_result = safe_mcp_call(self.mcp, 'search_company_news', search_query)
if search_result and search_result.get('results'):
contacts.extend(self._extract_contacts_from_mcp_results(search_result['results'], role))
if not contacts:
contact_query = f"{company['name']} {role} email contact"
contact_result = safe_mcp_call(self.mcp, 'search_company_news', contact_query)
if contact_result and contact_result.get('results'):
contacts.extend(self._extract_contacts_from_mcp_results(contact_result['results'], role))
return contacts[:3]
def _extract_contacts_from_mcp_results(self, results, role):
"""Extraer información de contacto de los resultados de búsqueda de MCP."""
contacts = []
for result in results:
try:
title = result.get('title', '')
snippet = result.get('snippet', '')
url = result.get('url', '')
names = self._extract_names_from_text(title + ' ' + snippet)
for name_parts in names:
if len(name_parts) >= 2:
first_name, last_name = name_parts[0], ' '.join(name_parts[1:])
contacts.append({
'first_name': first_name,
'last_name': last_name,
'title': role,
'linkedin_url': url if 'linkedin' in url else '',
'data_sources': 1,
'source': 'mcp_search'
})
if len(contacts) >= 2:
break
except Exception as e:
print(f"Error al extraer el contacto del resultado: {str(e)}")
continue
return contacts
def _extract_names_from_text(self, text):
"""Extraer nombres probables del texto."""
import re
patrones_de_nombres = [
r'b([A-Z][a-z]+)s+([A-Z][a-z]+)b',
r'b([A-Z][a-z]+)s+([A-Z].?s*[A-Z][a-z]+)b',
r'b([A-Z][a-z]+)s+([A-Z][a-z]+)s+([A-Z][a-z]+)b'
]
names = []
for pattern in name_patterns:
matches = re.findall(pattern, text)
for match in matches:
if isinstance(match, tuple):
names.append(list(match))
return names[:3]
def _enrich_contact_data(self, contact, company):
if not contact.get('email'):
contact['email'] = self._generate_email(
contact['first_name'],
contact['last_name'],
company.get('domain', '')
)
contact['email_valid'] = validate_email(contact.get('email', ''))
contact['confidence_score'] = self._calculate_confidence(contact)
return contact
def _generate_email(self, first, last, domain):
if not all([first, last, domain]):
return ""
return f"{first.lower()}.{last.lower()}@{domain}"
def _calculate_confidence(self, contact):
score = 0
if contact.get('linkedin_url'): score += 30
if contact.get('email_valid'): score += 25
si contacto.get('fuentes_de_datos', 0) > 1: puntuación += 20
si todo(contacto.get(f) para f en ['nombre', 'apellido', 'título']): puntuación += 25
devuelve puntuación
def _validate_contact(self, contacto):
requerido = ['nombre', 'apellido', 'título']
return (all(contacto.get(f) for f in requerido) and
contacto.get('confidence_score', 0) >= 50)
def _deduplicate_contacts(self, contactos):
unique = deduplicate_by_key(
contacts,
lambda c: c.get('email', '') or f"{c.get('first_name', '')}_{c.get('last_name', '')}"
)
return sorted(unique, key=lambda x: x.get('confidence_score', 0), reverse=True)
def _calculate_contact_quality(self, contacts):
if not contacts:
return 0
avg_confidence = sum(c.get('confidence_score', 0) for c in contacts) / len(contacts)
high_quality = sum(1 for c in contacts if c.get('confidence_score', 0) >= 75)
return min(avg_confidence + (high_quality * 5), 100)
def create_contact_research_agent(mcp_client):
return Agent(
role='Contact Intelligence Specialist',
goal='Find accurate contact information for decision-makers using MCP',
backstory='Expert at finding and verifying contact information using advanced MCP search tools.',
tools=[ContactResearchTool(mcp_client)],
verbose=True
)El sistema de investigación de contactos identifica a los responsables de la toma de decisiones buscando funciones en LinkedIn y en los sitios web de las empresas. Genera direcciones de correo electrónico utilizando patrones corporativos típicos y comprueba la información de contacto mediante diversos métodos de verificación. El sistema asigna puntuaciones de confianza basadas en la calidad de las fuentes de datos. El proceso de deduplicación mantiene limpias las listas de contactos, priorizándolas según la confianza de la verificación.
Paso 5: Generación inteligente de mensajes
Transforme la inteligencia empresarial en mensajes de divulgación personalizados que mencionen eventos desencadenantes específicos y muestren la investigación. El generador crea varios formatos de mensajes para diferentes canales.
Cree un archivo agents/message_generation.py y añada el siguiente código:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any, List
from pydantic import BaseModel, Field
import openai
import os
class MessageGenerationInput(BaseModel):
companies: List[dict] = Field(description="Lista de empresas con contactos para generar mensajes")
message_type: str = Field(default="cold_email", description="Tipo de mensaje a generar (cold_email, linkedin_message, follow_up)")
class MessageGenerationTool(BaseTool):
name: str = "generate_messages"
description: str = "Crear comunicaciones personalizadas basadas en información sobre la empresa"
args_schema: type[BaseModel] = MessageGenerationInput
client: Any = None
def __init__(self):
super().__init__()
self.client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def _run(self, companies, message_type="cold_email") -> list:
# Asegúrate de que companies sea una lista
if not isinstance(companies, list):
print(f"Advertencia: Se esperaba una lista de empresas, se obtuvo {type(companies)}")
return []
if not companies:
print("No se han proporcionado empresas para la generación de mensajes")
return []
for company in companies:
if not isinstance(company, dict):
print(f"Advertencia: Se esperaba un diccionario de empresas, se obtuvo {type(company)}")
continue
for contact in company.get('contacts', []):
if not isinstance(contact, dict):
continue
mensaje = self._generate_personalized_message(contacto, empresa, tipo_mensaje)
contacto['mensaje_generado'] = mensaje
contacto['puntuación_calidad_mensaje'] = self._calculate_message_quality(mensaje, empresa)
return empresas
def _generate_personalized_message(self, contacto, empresa, tipo_mensaje):
context = self._build_message_context(contact, company)
if message_type == "cold_email":
return self._generate_cold_email(context)
elif message_type == "linkedin_message":
return self._generate_linkedin_message(context)
else:
return self._generate_cold_email(context)
def _build_message_context(self, contact, company):
triggers = company.get('trigger_events', [])
primary_trigger = triggers[0] if triggers else None
return {
'contact_name': contact.get('first_name', ''),
'contact_title': contact.get('title', ''),
'company_name': company.get('name', ''),
'industry': company.get('industry', ''),
'primary_trigger': primary_trigger,
'trigger_count': len(triggers)
}
def _generate_cold_email(self, context):
trigger_text = ""
if context['primary_trigger']:
trigger_text = f"He observado que {context['company_name']} {context['primary_trigger']['description'].lower()}."
prompt = f"""Escribe un correo electrónico frío personalizado:
Contacto: {context['contact_name']}, {context['contact_title']} en {context['company_name']}
Sector: {context['industry']}
Contexto: {trigger_text}
Requisitos:
- Asunto que haga referencia al evento desencadenante.
- Saludo personalizado con el nombre de pila.
- Introducción que demuestre que se ha investigado.
- Breve propuesta de valor.
- Llamada a la acción clara.
- Máximo 120 palabras.
Formato:
ASUNTO: [asunto]
CUERPO: [cuerpo del correo electrónico]"""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=300
)
return self._parse_email_response(response.choices[0].message.content)
def _generate_linkedin_message(self, context):
prompt = f"""Escribe una solicitud de conexión en LinkedIn (máximo 300 caracteres):
Contacto: {context['contact_name']} en {context['company_name']}
Contexto: {context.get('primary_trigger', {}).get('description', '')}
Sé profesional, haz referencia a la actividad de su empresa, no hagas argumentos de venta directos."""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=100
)
return {
'subject': 'Solicitud de conexión en LinkedIn',
'body': response.choices[0].message.content.strip()
}
def _parse_email_response(self, response):
lines = response.strip().split('n')
subject = ""
body_lines = []
for line in lines:
if line.startswith('SUBJECT:'):
subject = line.replace('SUBJECT:', '').strip()
elif line.startswith('BODY:'):
body_lines.append(line.replace('BODY:', '').strip())
elif body_lines:
líneas_cuerpo.append(línea)
return {
'asunto': asunto,
'cuerpo': 'n'.join(líneas_cuerpo).strip()
}
def _calculate_message_quality(self, mensaje, empresa):
puntuación = 0
cuerpo = mensaje.get('cuerpo', '').lower()
if company.get('name', '').lower() in message.get('subject', '').lower():
score += 25
if company.get('trigger_events') and any(t.get('type', '') in body for t in company['trigger_events']):
score += 30
if len(body.split()) <= 120:
score += 20
if any(word in body for word in ['call', 'meeting', 'discuss', 'connect']):
score += 25
return score
def create_message_generation_agent():
return Agent(
role='Personalization Specialist',
goal='Create compelling personalized outreach that gets responses',
backstory='Expert at crafting messages that demonstrate research and provide value.',
tools=[MessageGenerationTool()],
verbose=True
)El sistema de generación de mensajes convierte la inteligencia empresarial en comunicaciones personalizadas. Hace referencia a eventos desencadenantes específicos y muestra investigaciones detalladas. Crea líneas de asunto que se ajustan al contexto, saludos personalizados y propuestas de valor que se adaptan a la situación de cada cliente potencial. El sistema genera varios formatos de mensajes que funcionan bien para diferentes canales. Mantiene la calidad de la personalización constante.
Paso 6: Puntuación de clientes potenciales y gestor de canalizaciones
Califique a los clientes potenciales utilizando diversos factores de inteligencia y, a continuación, exporte automáticamente los clientes potenciales cualificados a su sistema CRM. El gestor prioriza los clientes potenciales en función de su idoneidad, el momento y la calidad de los datos.
Cree un archivo agents/pipeline_manager.py y añada el siguiente código:
from crewai import Agent, Task
from crewai.tools import BaseTool
from datetime import datetime
from typing import List
from pydantic import BaseModel, Field
import requests
import os
from .utils import validate_companies_input
class LeadScoringInput(BaseModel):
companies: List[dict] = Field(description="List of companies to score")
class LeadScoringTool(BaseTool):
name: str = "score_leads"
description: str = "Puntuación de clientes potenciales basada en múltiples factores de inteligencia"
args_schema: type[BaseModel] = LeadScoringInput
def _run(self, companies) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
for company in companies:
score_breakdown = self._calculate_lead_score(company)
company['lead_score'] = score_breakdown['total_score']
company['score_breakdown'] = score_breakdown
company['lead_grade'] = self._assign_grade(score_breakdown['total_score'])
return sorted(companies, key=lambda x: x.get('lead_score', 0), reverse=True)
def _calculate_lead_score(self, company):
breakdown = {
'icp_score': min(company.get('icp_score', 0) * 0.3, 25),
'trigger_score': min(company.get('trigger_score', 0) * 2, 30),
'contact_score': min(company.get('contact_score', 0) * 0.2, 20),
'timing_score': self._assess_timing(company),
'company_health': self._assess_health(company)
}
breakdown['total_score'] = sum(breakdown.values())
return breakdown
def _assess_timing(self, company):
triggers = company.get('trigger_events', [])
if not triggers:
return 0
recent_triggers = sum(1 for t in triggers if 'high' in t.get('severity', ''))
return min(recent_triggers * 8, 15)
def _assess_health(self, company):
score = 0
if company.get('trigger_events'):
score += 5
if company.get('employee_count', 0) > 50:
score += 5
return score
def _assign_grade(self, score):
if score >= 80: return 'A'
elif score >= 65: return 'B'
elif score >= 50: return 'C'
else: return 'D'
class CRMIntegrationInput(BaseModel):
companies: List[dict] = Field(description="Lista de empresas para exportar a CRM")
min_grade: str = Field(default="B", description="Calificación mínima de los clientes potenciales para exportar (A, B, C, D)")
class CRMIntegrationTool(BaseTool):
name: str = "crm_integration"
description: str = "Exportar clientes potenciales cualificados a HubSpot CRM"
args_schema: type[BaseModel] = CRMIntegrationInput
def _run(self, companies, min_grade='B') -> dict:
companies = validate_companies_input(companies)
if not companies:
return {"message": "No companies provided for CRM export", "success": 0, "errors": 0}
qualified = [c for c in companies if isinstance(c, dict) and c.get('lead_grade', 'D') in ['A', 'B']]
if not os.getenv("HUBSPOT_API_KEY"):
return {"error": "HubSpot API key not configured", "success": 0, "errors": 0}
results = {"success": 0, "errors": 0, "details": []}
for company in qualified:
for contact in company.get('contacts', []):
if not isinstance(contact, dict):
continue
result = self._create_hubspot_contact(contact, company)
if result.get('success'):
results['success'] += 1
else:
results['errors'] += 1
results['details'].append(result)
return results
def _create_hubspot_contact(self, contact, company):
api_key = os.getenv("HUBSPOT_API_KEY")
if not api_key:
return {"success": False, "error": "HubSpot API key not configured"}
url = "https://api.hubapi.com/crm/v3/objects/contacts"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
trigger_summary = "; ".join([
f"{t.get('type', '')}: {t.get('description', '')}"
for t in company.get('trigger_events', [])
])
email = contact.get('email', '').strip()
if not email:
return {"success": False, "error": "Se requiere un correo electrónico de contacto", "contact": contact.get('first_name', 'Desconocido')}
propiedades = {
"email": email,
"nombre": contact.get('first_name', ''),
"apellido": contact.get('last_name', ''),
"cargo": contact.get('title', ''),
"empresa": company.get('name', ''),
"website": f"https://{company.get('domain', '')}" if company.get('domain') else "",
"hs_lead_status": "NEW",
"lifecyclestage": "lead"
}
if company.get('lead_score'):
properties["lead_score"] = str(company.get('lead_score', 0))
if company.get('lead_grade'):
properties["lead_grade"] = company.get('lead_grade', 'D')
if trigger_summary:
propiedades["trigger_events"] = resumen_desencadenante[:1000]
si contacto.get('confidence_score'):
propiedades["contact_confidence"] = str(contacto.get('confidence_score', 0))
propiedades["ai_discovery_date"] = datetime.now().isoformat()
intentar:
respuesta = solicitudes.post(url, json={"propiedades": propiedades}, encabezados=encabezados, tiempo de espera=30)
si respuesta.código_estado == 201:
return {
"success": True,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"hubspot_id": response.json().get('id')
}
elif response.status_code == 409:
existing_contact = response.json()
return {
"success": True,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"hubspot_id": existing_contact.get('id'),
"note": "Contacto ya existe"
}
else:
error_detail = response.text if response.text else f"HTTP {response.status_code}"
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"API Error: {error_detail}"
}
except requests.exceptions.RequestException as e:
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"Error de red: {str(e)}"
}
except Exception as e:
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"Error inesperado: {str(e)}"
}
def create_pipeline_manager_agent():
return Agent(
role='Pipeline Manager',
goal='Puntuación de clientes potenciales y gestión de la integración CRM para clientes potenciales cualificados',
backstory='Experto en evaluar la calidad de los clientes potenciales y gestionar el proceso de ventas.',
tools=[LeadScoringTool(), CRMIntegrationTool()],
verbose=True
)El sistema de puntuación de clientes potenciales evalúa a los prospectos en varias áreas, incluyendo su adecuación al perfil del cliente ideal, la urgencia de los eventos desencadenantes, la calidad de los datos de contacto y los factores de tiempo. Proporciona desgloses detallados de las puntuaciones que permiten establecer prioridades basadas en datos y asigna automáticamente calificaciones con letras para una rápida calificación. La herramienta de integración CRM exporta los clientes potenciales cualificados directamente a HubSpot, lo que garantiza que todos los datos de inteligencia estén correctamente formateados para que el equipo de ventas pueda hacer un seguimiento.
Paso 6.1: Utilidades compartidas
Antes de crear la aplicación principal, cree un archivo agents/utils.py con funciones de utilidad compartidas que se utilizan en todos los agentes:
"""
Funciones de utilidad compartidas para todos los módulos de agentes.
"""
from typing import List, Dict, Any
import re
def validate_companies_input(companies: Any) -> List[Dict]:
"""Valida y normaliza la entrada de empresas en todos los agentes."""
if isinstance(companies, dict) and 'companies' in companies:
companies = companies['companies']
if not isinstance(companies, list):
print(f"Advertencia: Se esperaba una lista de empresas, se obtuvo {type(companies)}")
return []
if not companies:
print("No se han proporcionado empresas")
return []
valid_companies = []
for company in companies:
if isinstance(company, dict):
valid_companies.append(company)
else:
print(f"Advertencia: Se esperaba un diccionario de empresas, se obtuvo {type(company)}")
return valid_companies
def safe_mcp_call(mcp_client, method_name: str, *args, **kwargs) -> Dict:
"""Llama de forma segura a los métodos MCP con un manejo de errores coherente."""
try:
method = getattr(mcp_client, method_name)
result = method(*args, **kwargs)
return result if result and not result.get('error') else {}
except Exception as e:
print(f"Error al llamar a MCP {method_name}: {str(e)}")
return {}
def validate_email(email: str) -> bool:
"""Valida el formato del correo electrónico."""
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$'
return bool(re.match(pattern, email))
def deduplicate_by_key(items: List[Dict], key_func) -> List[Dict]:
"""Elimina duplicados de la lista de diccionarios utilizando una función clave."""
seen = set()
unique_items = []
for item in items:
key = key_func(item)
if key and key not in seen:
seen.add(key)
unique_items.append(item)
return unique_items
def extract_domain_from_url(url: str) -> str:
"""Extrae el dominio de la URL con análisis de respaldo."""
if not url:
return ""
try:
from urllib.parse import urlparse
parsed = urlparse(url)
return parsed.netloc
except:
if '//' in url:
return url.split('//')[1].split('/')[0]
return ""También deberá crear un archivo agents/__init__.py vacío para convertir la carpeta agents en un paquete Python.
Paso 7: Coordinación del sistema
Cree la aplicación Streamlit principal que coordina todos los agentes en un flujo de trabajo inteligente. La interfaz proporciona información en tiempo real y permite a los usuarios personalizar los parámetros para diferentes escenarios de prospección.
Cree un archivo ai_bdr_system.py en el directorio raíz de su proyecto y añada el siguiente código:
import streamlit as st
import os
from dotenv import load_dotenv
from crewai import Crew, Process, Task
import pandas as pd
from datetime import datetime
import json
from mcp_client import Bright DataMCP
from agents.company_discovery import create_company_discovery_agent
from agents.trigger_detection import create_trigger_detection_agent
from agents.contact_research import create_contact_research_agent
from agents.message_generation import create_message_generation_agent
from agents.pipeline_manager import create_pipeline_manager_agent
load_dotenv()
st.set_page_config(
page_title="Sistema IA BDR/SDR",
page_icon="🤖",
layout="wide"
)
st.title("🤖 Sistema de agente IA BDR/SDR")
st.markdown("**Prospección en tiempo real con inteligencia multiagente y personalización basada en desencadenantes**")
if 'workflow_results' not in st.session_state:
st.session_state.workflow_results = None
with st.sidebar:
try:
st.image("bright-data-logo.png", width=200)
st.markdown("---")
except:
st.markdown("**🌐 Desarrollado por Bright Data**")
st.markdown("---")
st.header("⚙️ Configuración")
st.subheader("Perfil del cliente ideal")
industria = st.selectbox("Industria", ["SaaS", "FinTech", "Comercio electrónico", "Salud", "IA/ML"])
rango_tamaño = st.selectbox("Tamaño de la empresa", ["startup", "pequeña", "mediana", "gran empresa"])
ubicación = st.text_input("Ubicación (opcional)", placeholder="San Francisco, Nueva York, etc.")
max_companies = st.slider("Número máximo de empresas", 5, 50, 20)
st.subheader("Responsables de la toma de decisiones")
all_roles = ["CEO", "CTO", "VP Engineering", "Head of Product", "VP Sales", "CMO", "CFO"]
target_roles = st.multiselect("Funciones", all_roles, default=["CEO", "CTO", "VP Engineering"])
st.subheader("Configuración de divulgación")
message_types = st.multiselect(
"Tipos de mensajes",
["correo electrónico frío", "mensaje de LinkedIn", "seguimiento"],
default=["correo electrónico frío"]
)
with st.expander("Inteligencia avanzada"):
enable_competitive = st.checkbox("Inteligencia competitiva", value=True)
enable_validation = st.checkbox("Validación de múltiples fuentes", value=True)
min_lead_grade = st.selectbox("Calificación mínima de exportación de CRM", ["A", "B", "C"], index=1)
st.divider()
st.subheader("🔗 Estado de la API")
apis = [
("Bright Data", "BRIGHT_DATA_API_TOKEN", "🌐"),
("OpenAI", "OPENAI_API_KEY", "🧠"),
("HubSpot CRM", "HUBSPOT_API_KEY", "📊")
]
for name, env_var, icon in API:
if os.getenv(env_var):
st.success(f"{icon} {name} Connected")
else:
if name == "HubSpot CRM":
st.warning(f"⚠️ {name} Required for CRM export")
elif nombre == "Bright Data":
st.error(f"❌ {nombre} Falta")
if st.button("🔧 Ayuda de configuración", key="bright_data_help"):
st.info("""
**Configuración de Bright Data requerida:**
1. Obtenga las credenciales del panel de control de Bright Data.
2. Actualice el archivo .env con:
```
BRIGHT_DATA_API_TOKEN=tu_contraseña
WEB_UNLOCKER_ZONE=lum-nombre_de_usuario-del_cliente-zona-nombre_de_la_zona
```
3. Consulte BRIGHT_DATA_SETUP.md para obtener una guía detallada.
**Error actual**: 407 Autenticación no válida = Credenciales incorrectas.
""")
else:
st.error(f"❌ {name} Falta")
col1, col2 = st.columns([3, 1])
with col1:
st.subheader("🚀 Flujo de trabajo de prospección con IA")
if st.button("Iniciar prospección con múltiples agentes", type="primary", use_container_width=True):
claves_necesarias = ["BRIGHT_DATA_API_TOKEN", "OPENAI_API_KEY"]
claves_faltantes = [clave para clave en claves_necesarias si no os.getenv(clave)]
if missing_keys:
st.error(f"Faltan las claves API requeridas: {', '.join(missing_keys)}")
st.stop()
progress_bar = st.progress(0)
status_text = st.empty()
try:
mcp_client = Bright DataMCP()
discovery_agent = create_company_discovery_agent(mcp_client)
trigger_agent = create_trigger_detection_agent(mcp_client)
contact_agent = create_contact_research_agent(mcp_client)
message_agent = create_message_generation_agent()
pipeline_agent = create_pipeline_manager_agent()
status_text.text("🔍 Descubriendo empresas que coinciden con el ICP...")
progress_bar.progress(15)
discovery_task = Task(
description=f"Encontrar {max_companies} empresas en {industry} (tamaño {size_range}) en {location}",
expected_output="Lista de empresas con puntuaciones ICP e inteligencia",
agent=discovery_agent
)
discovery_crew = Crew(
agents=[discovery_agent],
tasks=[discovery_task],
process=Process.sequential
)
companies = discovery_agent.tools[0]._run(industry, size_range, location)
st.success(f"✅ Se han descubierto {len(empresas)} empresas")
status_text.text("🎯 Analizando eventos desencadenantes y señales de compra...")
progress_bar.progress(30)
trigger_task = Task(
description="Detectar picos de contratación, rondas de financiación, cambios en el liderazgo y señales de expansión",
expected_output="Empresas con eventos desencadenantes y puntuaciones",
agent=trigger_agent
)
trigger_crew = Crew(
agents=[trigger_agent],
tasks=[trigger_task],
process=Process.sequential
)
companies_with_triggers = trigger_agent.tools[0]._run(companies)
total_triggers = sum(len(c.get('trigger_events', [])) for c in companies_with_triggers)
st.success(f"✅ Detectados {total_triggers} eventos desencadenantes")
progress_bar.progress(45)
status_text.text("👥 Buscando contactos de responsables de la toma de decisiones...")
contact_task = Task(
description=f"Buscar contactos verificados para los roles: {', '.join(target_roles)}",
expected_output="Empresas con información de contacto de responsables de la toma de decisiones",
agent=contact_agent
)
contact_crew = Crew(
agents=[contact_agent],
tasks=[contact_task],
process=Process.sequential
)
companies_with_contacts = contact_agent.tools[0]._run(companies_with_triggers, target_roles)
total_contacts = sum(len(c.get('contacts', [])) for c in companies_with_contacts)
st.success(f"✅ Se han encontrado {total_contacts} contactos verificados")
progress_bar.progress(60)
status_text.text("✍️ Generando mensajes de contacto personalizados...")
message_task = Task(
description=f"Generar {', '.join(message_types)} para cada contacto utilizando inteligencia de activación",
expected_output="Empresas con mensajes personalizados",
agent=message_agent
)
message_crew = Crew(
agents=[message_agent],
tasks=[message_task],
process=Process.sequential
)
companies_with_messages = message_agent.tools[0]._run(companies_with_contacts, message_types[0])
total_messages = sum(len(c.get('contacts', [])) for c in companies_with_messages)
st.success(f"✅ Generated {total_messages} personalized messages")
progress_bar.progress(75)
status_text.text("📊 Scoring leads and updating CRM...")
pipeline_task = Task(
description=f"Puntuación de clientes potenciales y exportación de la calificación {min_lead_grade}+ a HubSpot CRM",
expected_output="Clientes potenciales puntuados con resultados de integración CRM",
agent=pipeline_agent
)
pipeline_crew = Crew(
agents=[pipeline_agent],
tasks=[pipeline_task],
process=Process.sequential
)
final_companies = pipeline_agent.tools[0]._run(companies_with_messages)
qualified_leads = [c for c in final_companies if c.get('lead_grade', 'D') in ['A', 'B']]
crm_results = {"success": 0, "errors": 0}
if os.getenv("HUBSPOT_API_KEY"):
crm_results = pipeline_agent.tools[1]._run(final_companies, min_lead_grade)
progress_bar.progress(100)
status_text.text("✅ ¡Flujo de trabajo completado con éxito!")
st.session_state.workflow_results = {
'companies': final_companies,
'total_companies': len(final_companies),
'total_triggers': total_triggers,
'total_contacts': total_contacts,
'qualified_leads': len(qualified_leads),
'crm_results': crm_results,
'timestamp': datetime.now()
}
except Exception as e:
st.error(f"❌ Workflow failed: {str(e)}")
st.write("Please check your API configurations and try again.")
if st.session_state.workflow_results:
results = st.session_state.workflow_results
st.markdown("---")
st.subheader("📊 Resultados del flujo de trabajo")
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Empresas analizadas", results['total_companies'])
with col2:
st.metric("Eventos desencadenantes", results['total_triggers'])
con col3:
st.metric("Contactos encontrados", resultados['total_contacts'])
con col4:
st.metric("Clientes potenciales cualificados", resultados['qualified_leads'])
si results['crm_results']['success'] > 0 o results['crm_results']['errors'] > 0:
st.subheader("🔄 Integración con HubSpot CRM")
col1, col2 = st.columns(2)
con col1:
st.metric("Exported to CRM", results['crm_results']['success'], delta="contacts")
with col2:
if results['crm_results']['errors'] > 0:
st.metric("Export Errors", results['crm_results']['errors'], delta_color="inverse")
st.subheader("🏢 Inteligencia empresarial")
for company in results['companies'][:10]:
with st.expander(f"📋 {company.get('name', 'Unknown')} - Grado {company.get('lead_grade', 'D')} (Puntuación: {company.get('lead_score', 0):.0f})"):
col1, col2 = st.columns(2)
with col1:
st.write(f"**Sector:** {company.get('industry', 'Unknown')}")
st.write(f"**Dominio:** {company.get('domain', 'Unknown')}")
st.write(f"**Puntuación ICP:** {company.get('icp_score', 0)}")
triggers = company.get('trigger_events', [])
if triggers:
st.write("**🎯 Eventos desencadenantes:**")
for trigger in triggers:
severity_emoji = {"high": "🔥", "medium": "⚡", "low": "💡"}.get(trigger.get('severity', 'low'), '💡')
st.write(f"{severity_emoji} {trigger.get('description', 'Desencadenante desconocido')}")
with col2:
contacts = company.get('contacts', [])
if contacts:
st.write("**👥 Responsables de la toma de decisiones:**")
for contact in contacts:
confidence = contact.get('confidence_score', 0)
confidence_color = "🟢" if confidence >= 75 else "🟡" if confidence >= 50 else "🔴"
st.write(f"{confidence_color} **{contact.get('first_name', '')} {contact.get('last_name', '')}**")
st.write(f" {contact.get('title', 'Unknown title')}")
st.write(f" 📧 {contact.get('email', 'No email')}")
st.write(f" Confianza: {confidence}%")
message = contact.get('generated_message', {})
if message.get('subject'):
st.write(f" **Asunto:** {message['subject']}")
if message.get('body'):
preview = message['body'][:100] + "..." if len(message['body']) > 100 else message['body']
st.write(f" **Vista previa:** {preview}")
st.write("---")
st.subheader("📥 Exportar y acciones")
col1, col2, col3 = st.columns(3)
with col1:
export_data = []
for company in results['companies']:
for contact in company.get('contacts', []):
export_data.append({
'Company': company.get('name', ''),
'Industry': company.get('industry', ''),
'Lead Grade': company.get('lead_grade', ''),
'Lead Score': company.get('lead_score', 0),
'Trigger Count': len(company.get('trigger_events', [])),
'Contact Name': f"{contact.get('first_name', '')} {contact.get('last_name', '')}",
'Título': contact.get('title', ''),
'Correo electrónico': contact.get('email', ''),
'Confianza': contact.get('confidence_score', 0),
'Asunto': contact.get('generated_message', {}).get('subject', ''),
'Mensaje': contact.get('generated_message', {}).get('body', '')
})
if export_data:
df = pd.DataFrame(export_data)
csv = df.to_csv(index=False)
st.download_button(
label="📄 Descargar informe completo (CSV)",
data=csv,
file_name=f"ai_bdr_prospects_{datetime.now().strftime('%Y%m%d_%H%M')}.csv",
mime="text/csv",
use_container_width=True
)
con col2:
si st.button("🔄 Sincronizar con HubSpot CRM", use_container_width=True):
si no os.getenv("HUBSPOT_API_KEY"):
st.warning("Se requiere la clave API de HubSpot para la exportación de CRM")
else:
con st.spinner("Sincronizando con HubSpot..."):
pipeline_agent = create_pipeline_manager_agent()
new_crm_results = pipeline_agent.tools[1]._run(results['companies'], min_lead_grade)
st.session_state.workflow_results['crm_results'] = new_crm_results
st.rerun()
con col3:
si st.button("🗑️ Borrar resultados", use_container_width=True):
st.session_state.workflow_results = None
st.rerun()
si __name__ == "__main__":
pasarEl sistema de coordinación Streamlit coordina a todos los agentes en un flujo de trabajo eficiente con seguimiento del progreso en tiempo real y ajustes personalizables. Ofrece visualizaciones claras de los resultados con métricas, información detallada de la empresa y opciones de exportación. La interfaz facilita la gestión de operaciones complejas con múltiples agentes a través de un panel intuitivo que los equipos de ventas pueden utilizar sin necesidad de conocimientos técnicos.
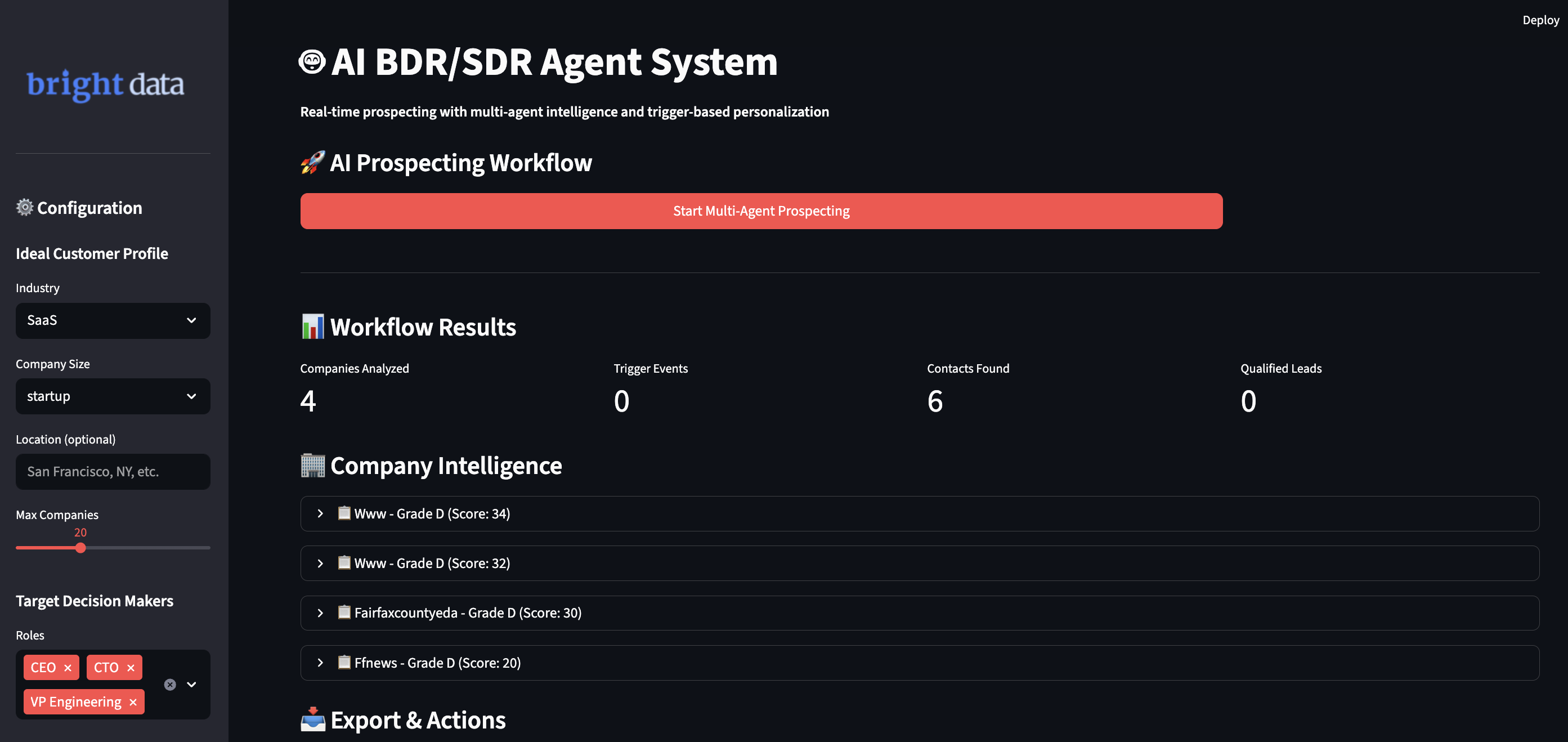
Ejecutar su sistema BDR de IA
Ejecute la aplicación para iniciar flujos de trabajo de prospección inteligente. Abra su terminal y vaya al directorio de su proyecto.
streamlit run ai_bdr_system.py
Verá el flujo de trabajo inteligente del sistema a medida que gestiona sus requisitos:
- Encuentra empresas que coinciden con su perfil de cliente ideal mediante comprobaciones de datos en tiempo real.
- Realiza un seguimiento de los eventos desencadenantes de diversas fuentes para encontrar el mejor momento.
- Busca contactos de responsables de la toma de decisiones utilizando múltiples fuentes y puntuaciones de fiabilidad.
- Crea mensajes personalizados que mencionan información comercial específica.
- Califica automáticamente a los clientes potenciales y añade a los prospectos cualificados a su canal de CRM.
Reflexiones finales
Este sistema BDR con IA muestra cómo la automatización puede optimizar la prospección y la calificación de clientes potenciales. Para mejorar aún más su canal de ventas, considere los productos de Bright Data, como nuestro conjunto de datos de LinkedIn, que ofrece datos precisos de contactos y empresas, así como otros Conjuntos de datos y herramientas de automatización creados para equipos BDR y de ventas.
Explore más soluciones en la documentación de Bright Data.
Cree una cuenta gratuita en Bright Data para empezar a crear sus flujos de trabajo BDR automatizados.





