

En esta guía aprenderá:
- Qué es el Protocolo de Contexto del Modelo (MCP) y por qué es importante para los agentes de IA
- Cómo configurar el servidor MCP de Bright Data con Augment Code
- Cómo utilizar la búsqueda web, el scraping de markdown y las herramientas API SERP
- Cómo navegar por sitios web dinámicos utilizando el Navegador de scraping
- Cómo combinar la codificación de IA con datos web en tiempo real para flujos de trabajo prácticos
Antes de sumergirte en la configuración, es útil comprender las dos tecnologías que vas a conectar.
¿Qué es el Protocolo de contexto del modelo (MCP)?
El MCP es una forma estandarizada para que los modelos de IA se conecten a herramientas y fuentes de datos externas. Piensa en el MCP como el puerto USB-C para los LLM. Al igual que el USB-C te permite conectar cualquier periférico a cualquier dispositivo con un único estándar, el MCP permite a los modelos de IA conectarse a cualquier fuente de datos o herramienta a través de un protocolo unificado.
Antes del MCP, conectar un LLM a herramientas externas significaba crear integraciones personalizadas para cada combinación. ¿Quiere que su agente impulsado por Claude busque en la web? Cree una integración. ¿Cambiar a GPT? Vuelva a crearla. ¿Añadir una nueva fuente de datos? Más código personalizado.
MCP elimina esta complejidad. Define una forma estándar para que los modelos de IA descubran, invoquen y reciban resultados de herramientas externas. Crea un servidor MCP una vez y cualquier cliente compatible con MCP podrá utilizarlo.
Para obtener más información técnica, consulta nuestra guía sobre servidores MCP para el Scraping web.
Ahora que ya entiende cómo MCP estandariza las conexiones entre herramientas, veamos el asistente de codificación de IA que mejorará con el acceso web.
¿Qué es Augment Code?
Augment Code es un asistente de codificación de IA diseñado para bases de código grandes y complejas. A diferencia de las herramientas que se centran en el autocompletado línea por línea, Augment Code indexa todo su proyecto y comprende las dependencias entre archivos.
El diferenciador clave es lo que ellos llaman el motor de contexto. En lugar de limitarse a ofrecer una gran ventana de contexto (más de 200 000 tokens), indexa activamente su base de código y mantiene el conocimiento de la arquitectura de su proyecto. Pídale que refactorice una función y él identificará qué otros archivos importan esa función y necesitan actualizaciones.
Capacidades clave
- Indexación completa del código base. Augment indexa todo tu proyecto, incluidas las dependencias entre múltiples repositorios. Las preguntas extraen el contexto relevante de cualquier parte de tu código base.
- Modo agente. Más allá del chat y el autocompletado, Augment puede ejecutar de forma autónoma tareas de varios pasos. Puedes indicarle que añada el manejo de errores a todas las llamadas a la API y lo aplicará a tu código base archivo por archivo.
- Flexibilidad IDE. Funciona con VS Code, todos los IDE de JetBrains (IntelliJ, PyCharm, WebStorm), Vim/Neovim, y ofrece una herramienta CLI llamada Auggie para flujos de trabajo de terminal.
- Certificaciones de seguridad. Certificado SOC 2 Tipo II y compatible con ISO/IEC 42001.
Augment Code destaca por su capacidad para comprender su código base, pero tiene una limitación importante: no puede ver lo que ocurre en la web en tiempo real. Ahí es donde entra en juego Bright Data.
¿Por qué combinar Bright Data MCP con Augment Code?

La ventana de contexto y las capacidades del agente de Augment Code lo hacen eficaz en tareas complejas de varios pasos. Pero no puede acceder a la web en vivo por sí solo. No puede comprobar si un punto final de la API cambió la semana pasada, verificar las versiones actuales de la biblioteca o recopilar Inteligencia competitiva.
El servidor MCP de Bright Data llena este vacío. El servidor MCP proporciona más de 60 herramientas para el acceso a la web. Según la documentación de Bright Data, esto incluye el acceso a más de 150 millones de IPs residenciales en 195 países.
Al conectarlas, obtienes:
| Categoría | Qué hace | Ejemplos de herramientas |
|---|---|---|
| Búsqueda web | Consultar motores de búsqueda mediante programación | search_engine, search_engine_batch |
| Extracción de páginas | Extraer contenido de cualquier URL | scrape_as_markdown, scrape_as_html |
| Automatización del navegador | Navegar, hacer clic, escribir, desplazarse | scraping_browser_navigate, scraping_browser_click_ref |
| Extracción estructurada | Obtenga JSON limpio de más de 60 plataformas | web_data_amazon_product, web_data_linkedin_profile |
El Navegador de scraping merece atención. A diferencia de las simples solicitudes de recuperación, estas herramientas controlan un navegador real que gestiona la representación de JavaScript, los flujos de inicio de sesión, el desplazamiento infinito y la navegación en varios pasos. Esto es importante para los sistemas agenticos que necesitan interactuar con aplicaciones web modernas.
Cuando probé esta configuración por primera vez, le pedí a Augment que comprobara si la API de OpenAI había realizado algún cambio reciente en su limitación de velocidad. En unos ocho segundos, extrajo la documentación actual, la comparó con la que tenía almacenada en caché localmente y señaló que los límites de tokens por minuto habían cambiado para el punto final GPT-4 Turbo. Esa única consulta me evitó implementar código que habría alcanzado los límites de velocidad en producción.
Ahora que las ventajas están claras, veamos el proceso de configuración real.
Conectar Bright Data con el código de Augment
Requisitos previos
Antes de empezar, asegúrate de que tienes:
- Node.js 18+ instalado
- La extensión Augment Code instalada en VS Code (o su IDE preferido)
- Una cuenta de Bright Data (la configuración se explica más adelante)
No se preocupe si aún no tiene un token API de Bright Data. Le guiaremos a través del proceso de creación en la siguiente sección.
Paso 1: Crea tu cuenta de Bright Data y obtén un token API
Para empezar, necesitarás una cuenta de Bright Data y un token API para la autenticación con el servidor MCP, lo que te llevará unos dos minutos.
- Dirígete a brightdata.com y haz clic en «Prueba gratuita» para crear tu cuenta.
- Una vez que haya iniciado sesión en el panel de control, vaya a Configuración (el icono de engranaje) en la barra lateral izquierda y haga clic en Tokens API.
- Haz clic en «Crear token» y asígnale un nombre descriptivo, como «Augment Code MCP».
- Copie su nuevo token y guárdelo en un lugar seguro. Lo necesitará para el siguiente paso.
Paso 2: Configurar Bright Data MCP en Augment Code
Este tutorial utiliza la extensión Augment Code para Visual Studio Code.
Augment admite tres métodos para añadir servidores MCP: Easy MCP (configuración con un solo clic), el panel de configuración GUI y la importación JSON. Utilizaremos la importación JSON, ya que proporciona un control total sobre las opciones de configuración.
- Abre VS Code y haz clic en el icono de Augment Code en la barra de actividades (barra lateral izquierda).
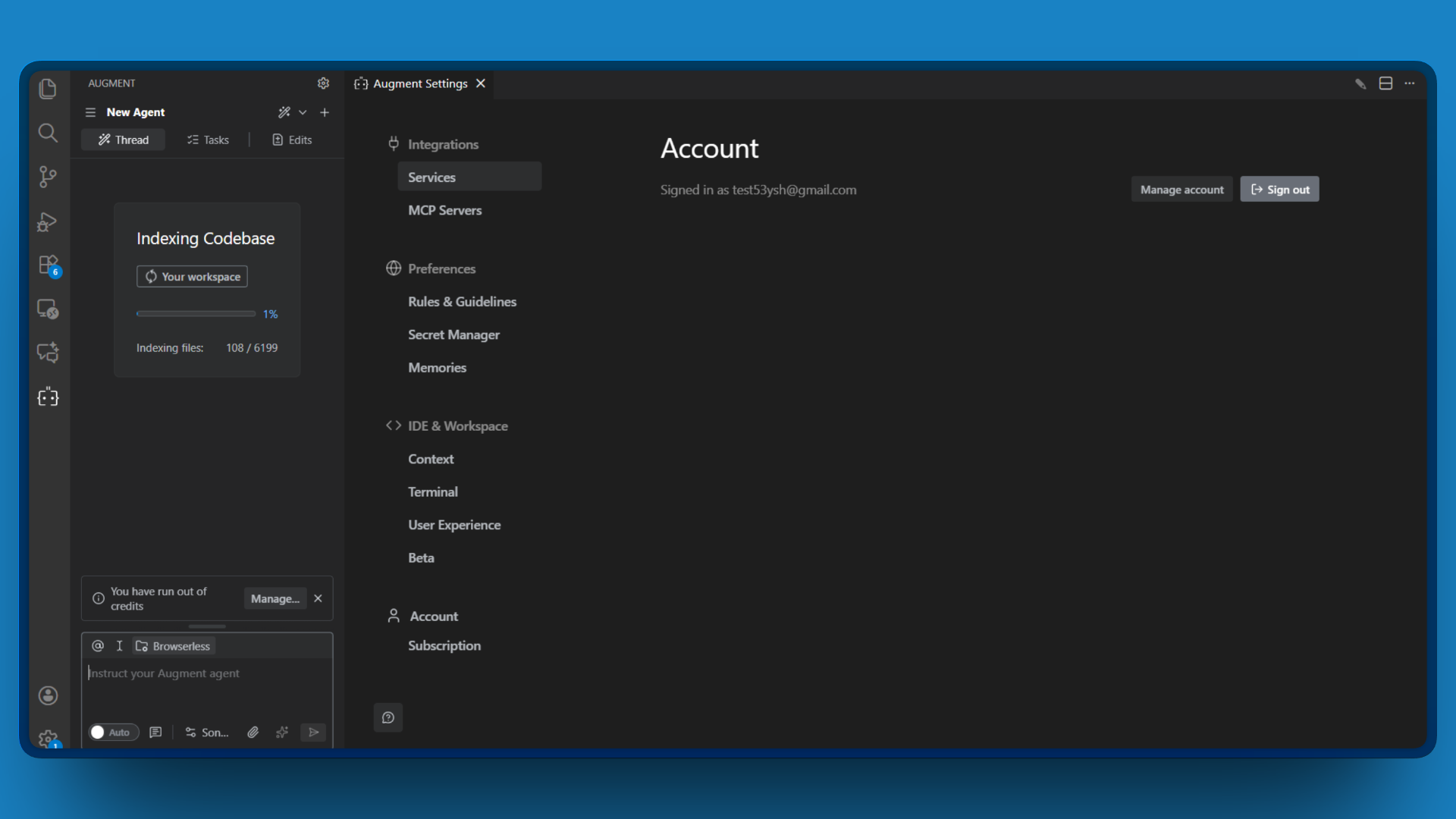
- En el panel Augment, haz clic en el icono de engranaje (Configuración) en la esquina superior derecha. Esto abrirá la página de configuración de Augment en una nueva pestaña.
- Haga clic en la sección Servidores MCP.
- Haga clic en «Importar desde JSON».
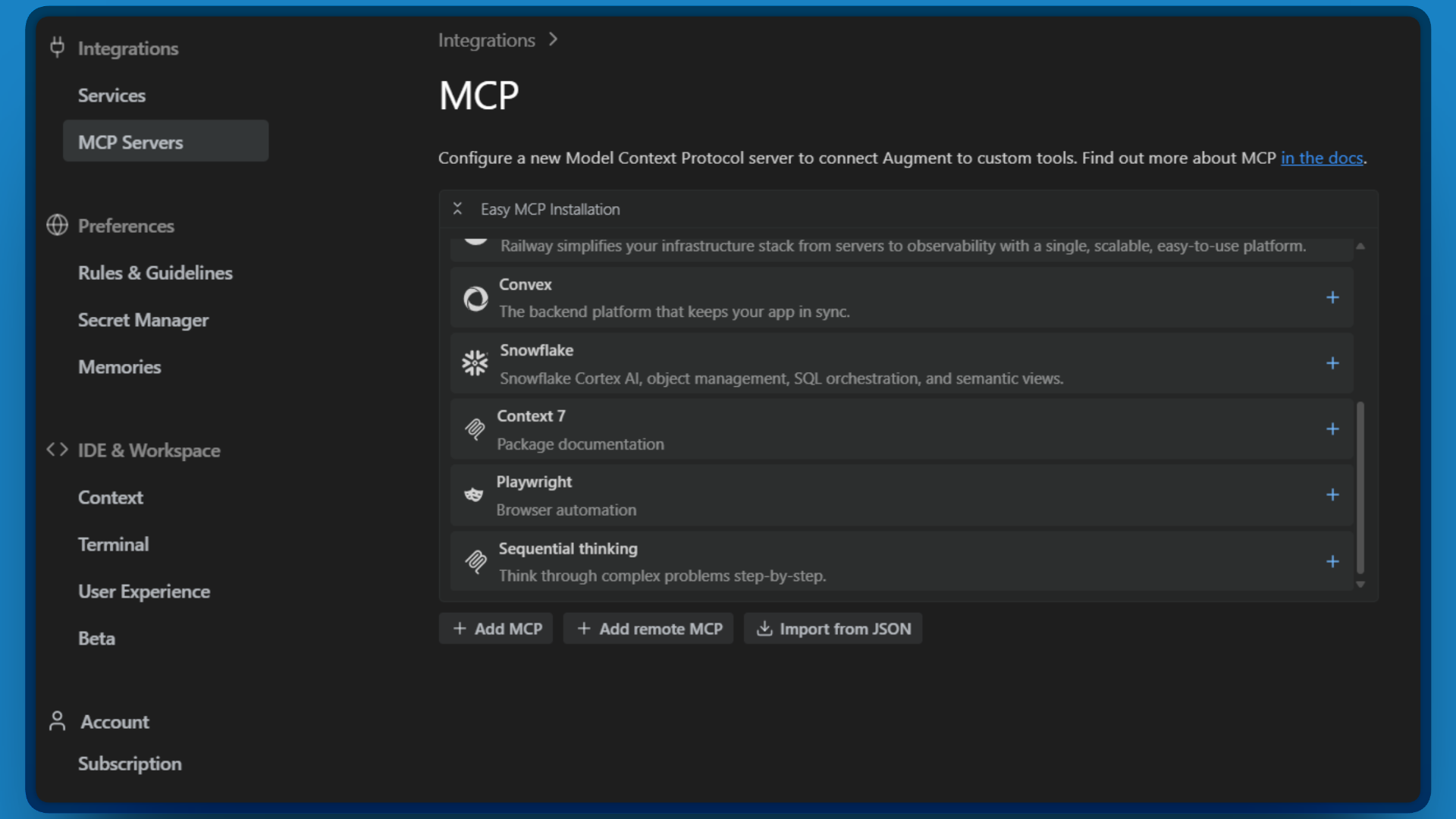
Ahora es el momento de pegar su configuración. Copie el JSON siguiente, sustituyendo<YOUR_API_TOKEN>por el token de Bright Data que ha creado en el paso 1:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": ""
}
}
}
}Reinicie VS Code para asegurarse de que el servidor MCP se inicializa correctamente y, a continuación, su Augment tendrá acceso completo a la infraestructura de scraping web de Bright Data.
Alternativa: configuración del servidor remoto
Si prefiere no ejecutar nada localmente, puede conectarse directamente al servidor alojado de Bright Data utilizando SSE (Server-Sent Events):
{
"mcpServers": {
"Bright Data": {
"url": "https://mcp.brightdata.com/sse?token=&pro=1",
"type": "sse"
}
}
}Este enfoque remoto no requiere ninguna configuración local. El servidor MCP se ejecuta íntegramente en la infraestructura de Bright Data, lo que puede resultar útil si trabaja en un equipo en el que no puede instalar paquetes npm o prefiere minimizar las dependencias locales.
Paso 3: Verificar la conexión
Para verificar la conexión, confirmemos que todo funciona correctamente antes de profundizar en las funciones avanzadas.
- Abre el panel Augment Code en VS Code haciendo clic en el icono Augment de la barra de actividades.
- Inicie un nuevo chat y escriba una solicitud sencilla que requiera acceso a la web, como por ejemplo:
«Busca en la web “nuevas funciones de Python 3.13” y resume los resultados principales».
- Observe cómo Augment Code invoca la herramienta
search_enginey devuelve los resultados de búsqueda actuales.
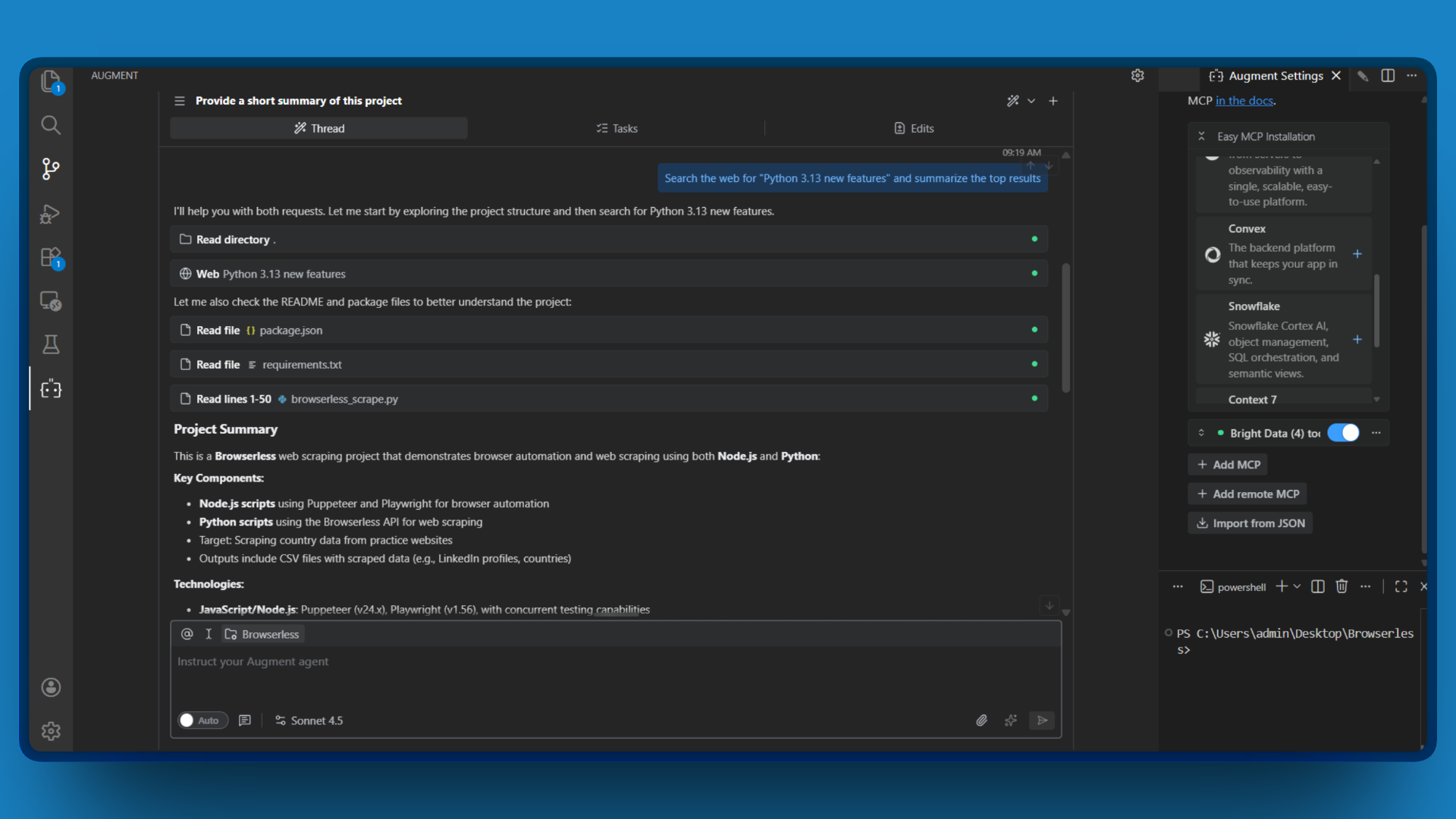
Si ve los resultados de búsqueda extraídos de la web en tiempo real, ¡enhorabuena! Su conexión MCP de Bright Data funciona.
Cuando le pides a Augment Code que busque en la web, este es el proceso:
- Augment Code analiza tu solicitud y determina que necesita datos web
- El cliente MCP (integrado en Augment) consulta al servidor Bright Data MCP las herramientas disponibles
- El servidor MCP devuelve la lista de herramientas, incluida search_engine
- Augment Code invoca search_engine con tu consulta
- Bright Data ejecuta la búsqueda utilizando su API SERP, gestionando automáticamente la geolocalización y las medidas anti-bot
- Los resultados vuelven a través de MCP a Augment Code, que los formatea para usted
Todo este proceso se realiza en segundos. No es necesario salir del IDE.
Una vez verificada la conexión, ya está listo para explorar lo que estas herramientas pueden hacer realmente.
Uso de las herramientas clásicas de Bright Data MCP
Ahora que la conexión está establecida, exploremos las herramientas básicas que funcionan tanto en el modo rápido (gratuito) como en el modo Pro.
Búsqueda web con search_engine
La herramienta search_engine consulta Google, Bing o Yandex y devuelve resultados estructurados. Es perfecta para:
- Investigar la documentación actual de la API cuando necesite los últimos puntos finales
- Encontrar tutoriales recientes o respuestas de Stack Overflow para bibliotecas desconocidas
- Comprobar las versiones actuales de los paquetes antes de añadir dependencias
- Recopilar inteligencia competitiva sobre productos o servicios similares
Por ejemplo, si le indicas a Augment que:
Busque los últimos cambios importantes de Next.js 15 y enuméralos
Augment Code invoca search_engine, procesa los resultados y te ofrece un resumen de los cambios importantes con las fuentes. No es necesario cambiar de pestaña.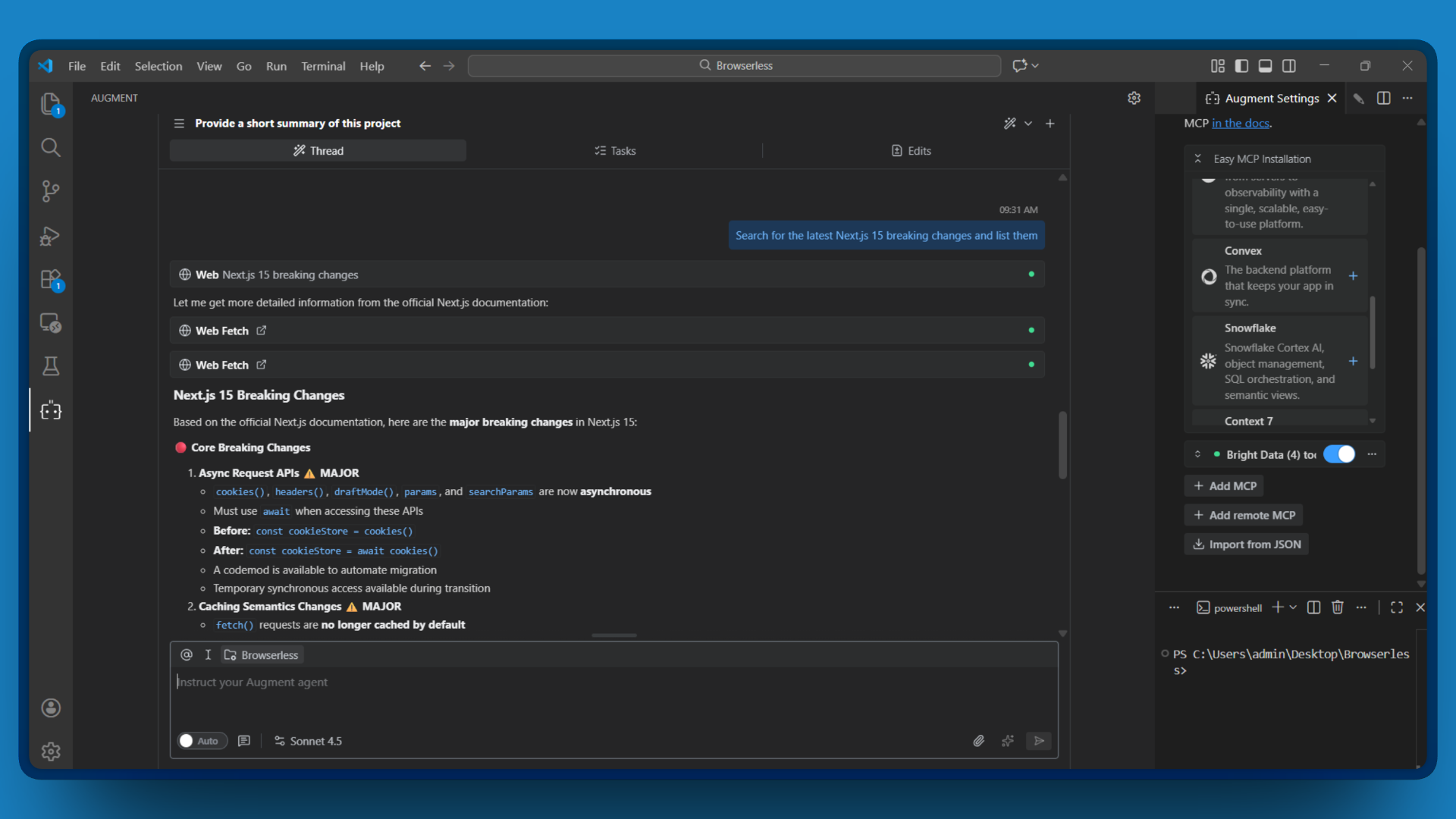
Para búsquedas por lotes (hasta 10 consultas a la vez), el modo Pro desbloquea search_engine_batch.
Rastreo de páginas con scrape_as_markdown
Cuando necesitas el contenido completo de una página específica, scrape_as_markdown lo obtiene y convierte el HTML a Markdown limpio. Esta herramienta utiliza la tecnología Web Unlocker para eludir automáticamente los CAPTCHA y las medidas antibots.
Ejemplo de solicitud:
Extraiga la documentación de la API de Stripe en https://stripe.com/docs/api y explique sus métodos de autenticación.
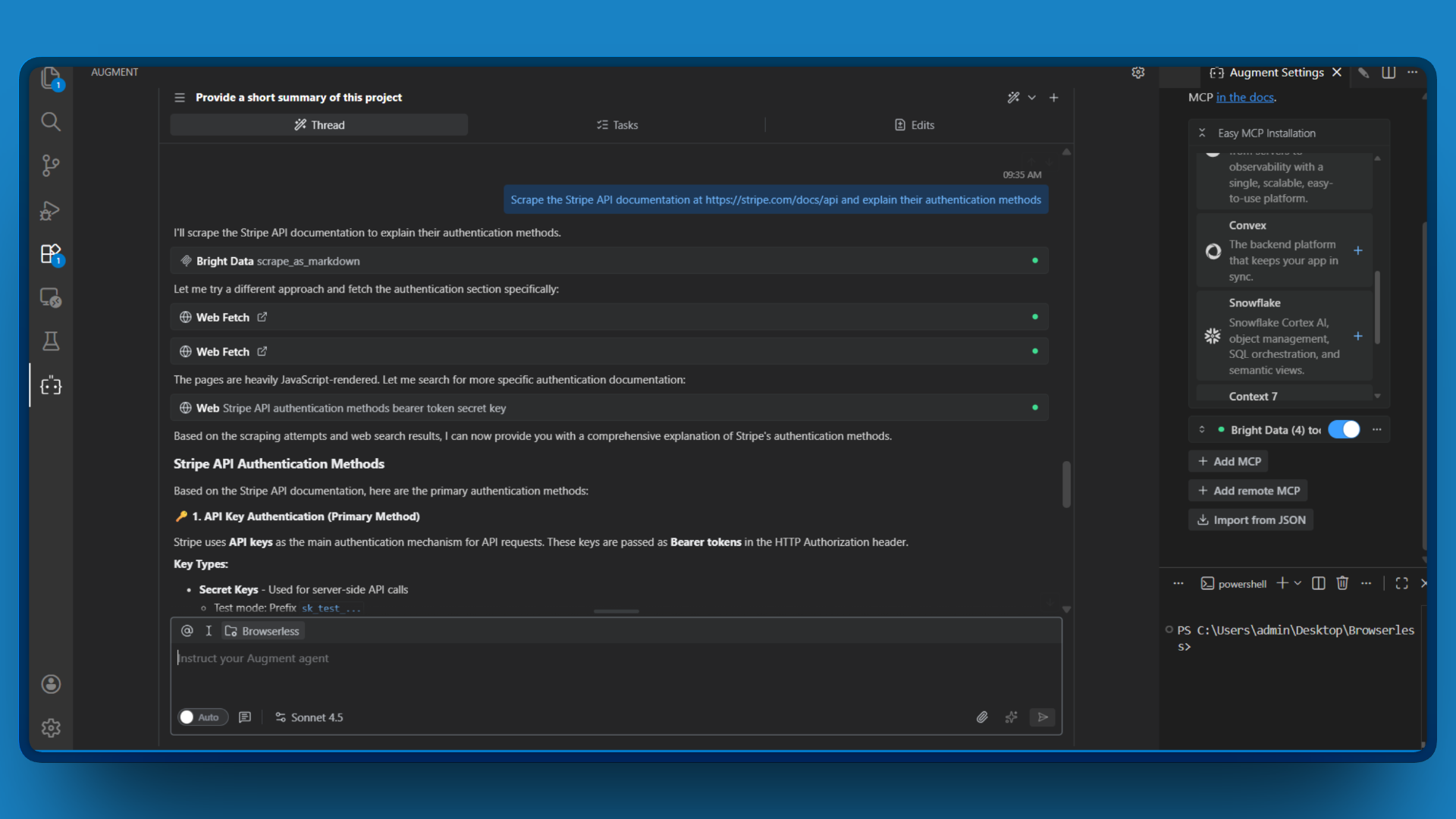
La herramienta devuelve el contenido de la página como Markdown, que Augment Code analiza y resume. Obtienes la información que necesitas sin tener que leer manualmente una documentación densa.
Datos estructurados con API de datos web
En el caso de las plataformas populares, el parseo manual del HTML no es necesario. El modo Pro incluye extractores preconstruidos que devuelven JSON limpio y estructurado.
Ejemplo de solicitud:
Obtenga los detalles del producto de este listado de Amazon: https://www.amazon.com/dp/B0CHX3QBCH
La herramienta web_data_amazon_product devuelve datos estructurados que incluyen el título, el precio, las valoraciones, las reseñas y las especificaciones. No se requiere código de parseo.
Los extractores disponibles cubren más de 60 plataformas, entre las que se incluyen:
- Comercio electrónico: Amazon, Walmart, eBay, Etsy, Best Buy, Google Shopping
- Redes sociales: LinkedIn, Instagram, Facebook, TikTok, X/Twitter, YouTube, Reddit
- Negocios: Crunchbase, ZoomInfo, Zillow, Google Maps
- Finanzas: Yahoo Finance, Reuters
Consulte la lista completa en la documentación de herramientas MCP.
Con múltiples herramientas disponibles, saber cuál utilizar en cada situación le ayudará a trabajar de forma más eficiente.
Elegir la herramienta adecuada
Cada herramienta es adecuada para una situación diferente. Utilice esta tabla para elegir la más adecuada:
| Situación | Herramienta recomendada | Por qué |
|---|---|---|
| Búsqueda rápida de datos | motor de búsqueda |
Rápido, devuelve resultados estructurados, bajo coste |
| Necesita el contenido completo de la página | scrape_as_markdown |
Gestiona medidas anti-bot, devuelve texto limpio |
| La página requiere JavaScript | scraping_browser_navigate |
Renderiza JS, espera contenido dinámico |
| Inicio de sesión o flujo de varios pasos | Navegador de scraping | Puede hacer clic, escribir, gestionar la autenticación |
| Amazon, LinkedIn, etc. | APIweb_data_* |
Devuelve JSON estructurado, sin necesidad de parseo |
| Múltiples búsquedas a la vez | search_engine_batch |
Hasta 10 consultas, más eficiente |
Regla general: comience con la herramienta más sencilla que pueda funcionar. Pase a la automatización del navegador solo cuando los métodos más sencillos fallen.
Incluso con la herramienta adecuada seleccionada, es posible que ocasionalmente se encuentre con problemas. A continuación se explica cómo diagnosticar y solucionar los problemas más comunes.
Solución de problemas comunes
¿Tiene problemas? Estas son las soluciones a los problemas más comunes:
Error «Herramienta no encontrada»
Si Augment Code no encuentra las herramientas de Bright Data, empieza por verificar que tu token API sea correcto y no haya caducado. A continuación, comprueba que la configuración MCP se haya guardado correctamente e intenta reiniciar Augment Code por completo en lugar de solo recargarlo. Si el problema persiste, comprueba los registros de Augment en busca de errores de conexión.
Respuestas lentas
La automatización del navegador lleva naturalmente más tiempo que el simple rastreo, por lo que si las respuestas parecen lentas, hay algunas cosas que debes tener en cuenta. La renderización de JavaScript lleva tiempo porque el Navegador de scraping necesita renderizar completamente las páginas antes de interactuar con ellas. Las páginas complejas con muchos elementos interactivos requieren instantáneas más grandes, lo que también aumenta el tiempo de procesamiento.
Para páginas más sencillas que no requieren interacción, considere la posibilidad de utilizar scrape_as_markdown como alternativa más rápida.
Limitación de velocidad
Si alcanza los límites de velocidad, comience por comprobar su uso en el panel de control de Bright Data. También puede ajustar la variable de entorno RATE_LIMIT en su configuración para gestionar mejor la frecuencia de las solicitudes. Para proyectos exigentes que requieren límites más altos, considere la posibilidad de actualizar su plan.
Más allá de las cuestiones técnicas, la conexión de agentes de IA a la web plantea consideraciones de seguridad que conviene tener en cuenta.
Mejores prácticas de seguridad
Cuando se conectan agentes de IA a la web, la seguridad es importante. Tenga en cuenta estos principios:
- Trate el contenido extraído como no fiable. Nunca ejecute código de páginas extraídas ni pase contenido sin procesar a eval().
- Utilice la extracción estructurada cuando esté disponible. Las herramientas web_data_* devuelven JSON validado, lo que reduce los riesgos de inyección en comparación con el parseo de HTML sin procesar.
- Almacene los tokens de API de forma segura. Utilice variables de entorno, no valores codificados en su código base.
- Revise las acciones del agente. Supervise lo que hace su agente, especialmente en entornos de producción.
Con estas prácticas en marcha, ya está listo para empezar a crear.
Conclusión
El servidor MCP de Bright Data transforma Augment Code de un asistente centrado en el código a un agente con conciencia web capaz de recopilar información en tiempo real. Con más de 60 herramientas para la búsqueda, el scraping, la automatización del navegador y la extracción estructurada (respaldadas por más de 150 millones de IPs residenciales y una tasa de éxito del 99,95 %), su asistente de codificación de IA ahora puede:
- Investigar la documentación actual y las API en vivo
- Recopilar inteligencia competitiva automáticamente
- Automatizar flujos de trabajo complejos de recopilación de datos
- Navegar por sitios web dinámicos con interacciones de varios pasos
El Navegador de scraping es especialmente potente para los sistemas agenticos. Mediante instantáneas ARIA y referencias de elementos estables, su agente gestiona flujos de inicio de sesión, formularios de varios pasos y contenido dinámico que dejarían en evidencia a los enfoques de scraping más simples.
¿Está listo para darle a su asistente de codificación de IA acceso a la web en tiempo real?
Para técnicas más avanzadas, consulte nuestras guías sobre la creación de agentes de IA con LlamaIndex y la integración de MCP con CrewAI.





