

En esta guía, verás:
- Lo que ofrece NVIDIA NeMo Framework, especialmente para crear agentes de IA utilizando NVIDIA NeMo Agent Toolkit.
- Cómo integrar Bright Data en un agente de IA NAT utilizando herramientas personalizadas a través de LangChain.
- Cómo conectar un flujo de trabajo de NVIDIA NeMo Agent Toolkit a Bright Data Web MCP.
¡Empecemos!
Introducción al marco NVIDIA NeMo
El marco NVIDIA NeMo es una plataforma de desarrollo de IA completa y nativa de la nube, diseñada para crear, personalizar e implementar modelos de IA generativa, incluidos LLM y modelos multimodales.
Ofrece herramientas integrales para todo el ciclo de vida de la IA, desde el entrenamiento y el ajuste fino hasta la evaluación y la implementación. NeMo también aprovecha el entrenamiento distribuido a gran escala e incluye componentes para tareas como la curación de datos, la evaluación de modelos y la implementación de medidas de seguridad.
Cuenta con el respaldo de una biblioteca Python de código abierto con más de 16 000 estrellas en GitHub e imágenes Docker dedicadas.
Kit de herramientas NVIDIA NeMo Agent
El kit de herramientas NVIDIA NeMo Agent (abreviado «NAT»), que forma parte del marco NVIDIA NeMo, es un marco de código abierto para crear, optimizar y gestionar sistemas complejos de agentes de IA.
Ayuda a conectar diversos agentes y herramientas en flujos de trabajo unificados con una profunda observabilidad, perfilado y análisis de costes, actuando como «director» de operaciones multiagente y ayudando a escalar las aplicaciones de IA.
NAT hace hincapié en la composibilidad, tratando a los agentes y las herramientas como llamadas a funciones modulares. También proporciona funciones para identificar cuellos de botella, automatizar evaluaciones y gestionar sistemas de IA agenticos de nivel empresarial.
Para obtener más información, consulte:
Conectando LLM y datos en tiempo real con las herramientas de Bright Data
El kit de herramientas NVIDIA NeMo Agent proporciona la flexibilidad, la personalización, la observabilidad y la escalabilidad necesarias para crear y gestionar proyectos de IA de nivel empresarial. Ofrece a las organizaciones la capacidad de orquestar flujos de trabajo de IA complejos, conectar múltiples agentes y supervisar el rendimiento y los costes.
Sin embargo, incluso las aplicaciones NAT más sofisticadas se enfrentan a las limitaciones inherentes de los LLM. Entre ellas se incluyen el conocimiento obsoleto debido a los datos de entrenamiento estáticos y la falta de acceso a información web en tiempo real.
La solución consiste en integrar el flujo de trabajo de NVIDIA NeMo Agent Toolkit con un proveedor de datos web para IA, como Bright Data.
Bright Data ofrece herramientas para el Scraping web, la búsqueda, la automatización del navegador y mucho más. Estas soluciones permiten a su sistema de IA recuperar datos útiles en tiempo real y liberar todo su potencial para aplicaciones empresariales.
Cómo conectar Bright Data a un agente de IA NVIDIA NeMo
Una forma de aprovechar las capacidades de Bright Data en un agente de IA NVIDIA NeMo es creando herramientas personalizadas a través del kit de herramientas NeMo Agent.
Esas herramientas se conectarán a los productos de Bright Data a través de funciones personalizadas impulsadas por LangChain (o cualquier otra integración compatible con bibliotecas de creación de agentes de IA).
Siga las instrucciones que se indican a continuación.
Requisitos previos
Para seguir este tutorial, necesita:
- Python 3.11, 3.12 o 3.13 instalado localmente.
- Una cuenta de Bright Data configurada para la integración con las herramientas oficiales de LangChain.
- Una cuenta NVIDIA NIM con una clave API configurada.
No se preocupe por configurar las cuentas de Bright Data y NVIDIA NIM en este momento, ya que se le guiará a través de ese proceso en capítulos específicos.
Nota: En caso de problemas durante la instalación o mientras ejecuta el kit de herramientas, asegúrese de estar en una de las plataformas compatibles.
Paso n.º 1: Recupera tu clave API de NVIDIA NIM
La mayoría de los flujos de trabajo de NVIDIA NeMo Agent requieren una variable de entorno NVIDIA_API_KEY. Esta es necesaria para autenticar la conexión con los LLM de NVIDIA NIM detrás del flujo de trabajo.
Para recuperar su clave API, comience por crear una cuenta NVIDIA NIM (si aún no tiene una). Inicie sesión y haga clic en la imagen de su cuenta en la esquina superior derecha. Seleccione la opción «Claves API»:
Llegará a la página Claves API. Haga clic en el botón «Generar clave API» para crear una nueva clave: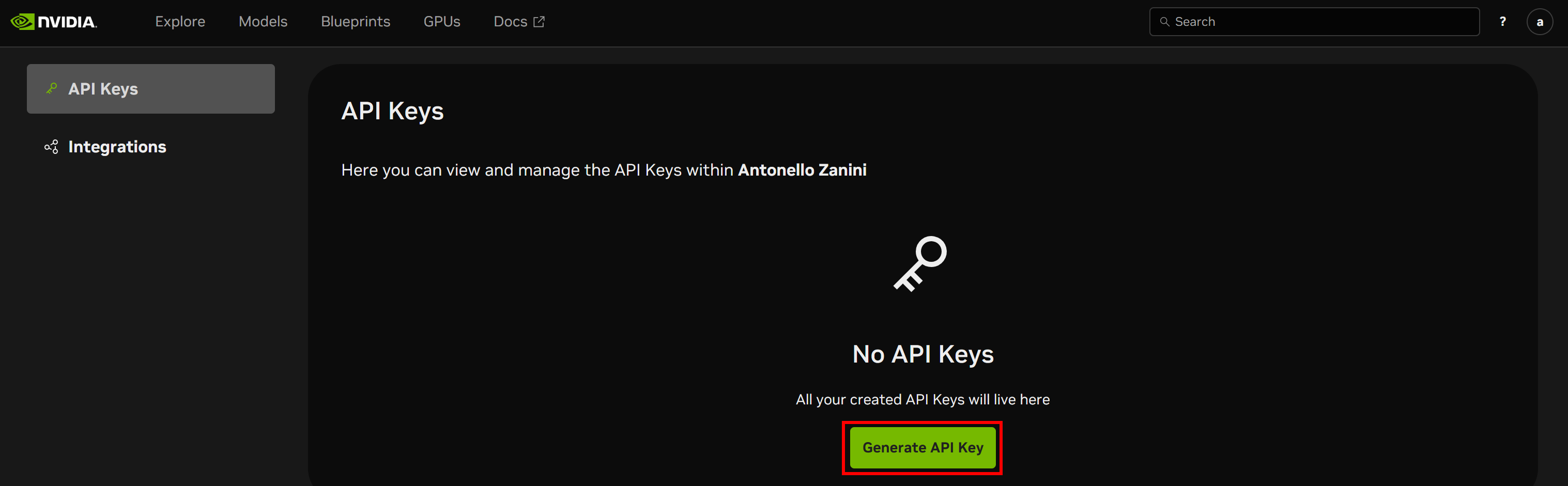
Asigne un nombre a su clave API y haga clic en «Generar clave»: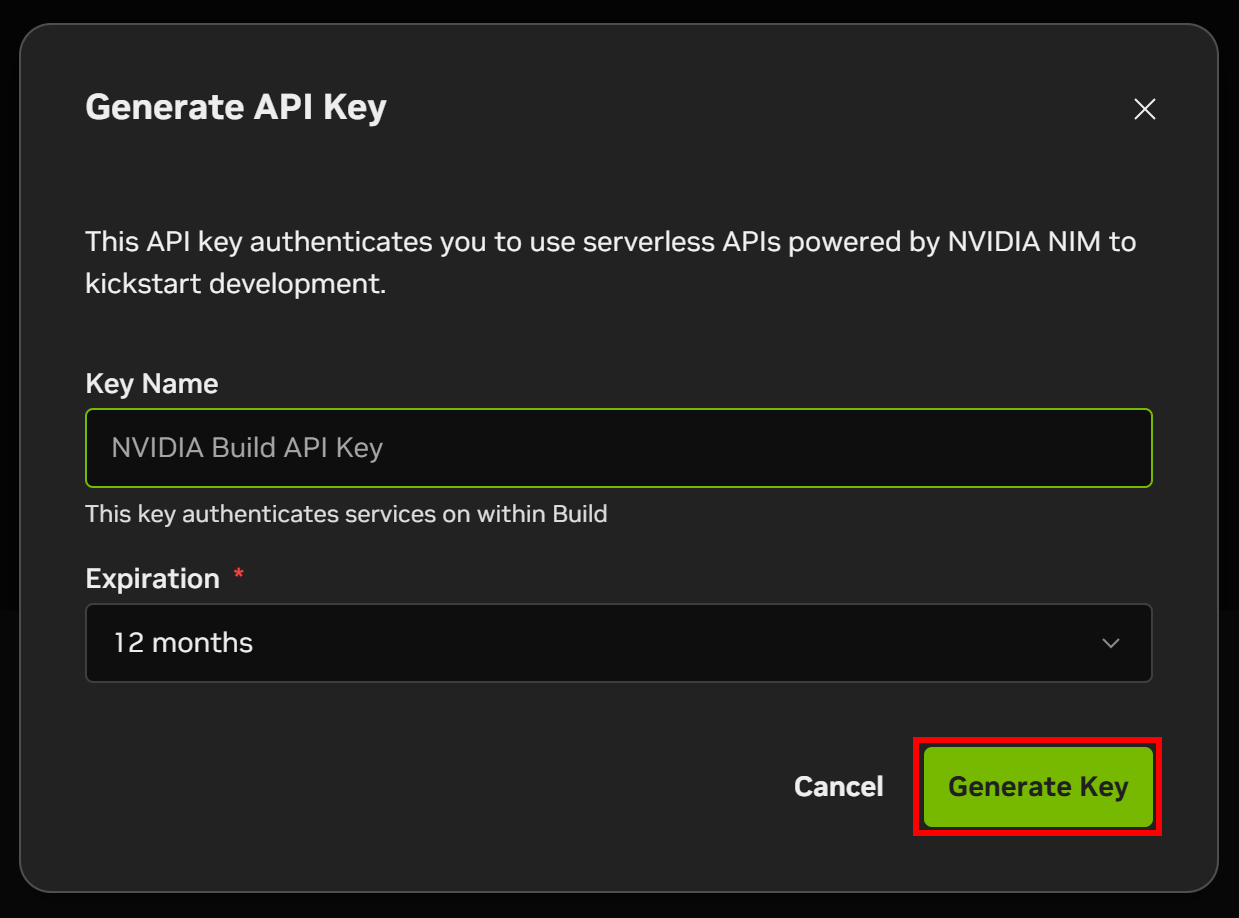
Aparecerá una ventana modal con su clave API. Haga clic en el botón «Copiar clave API» y guarde la clave en un lugar seguro, ya que la necesitará en breve.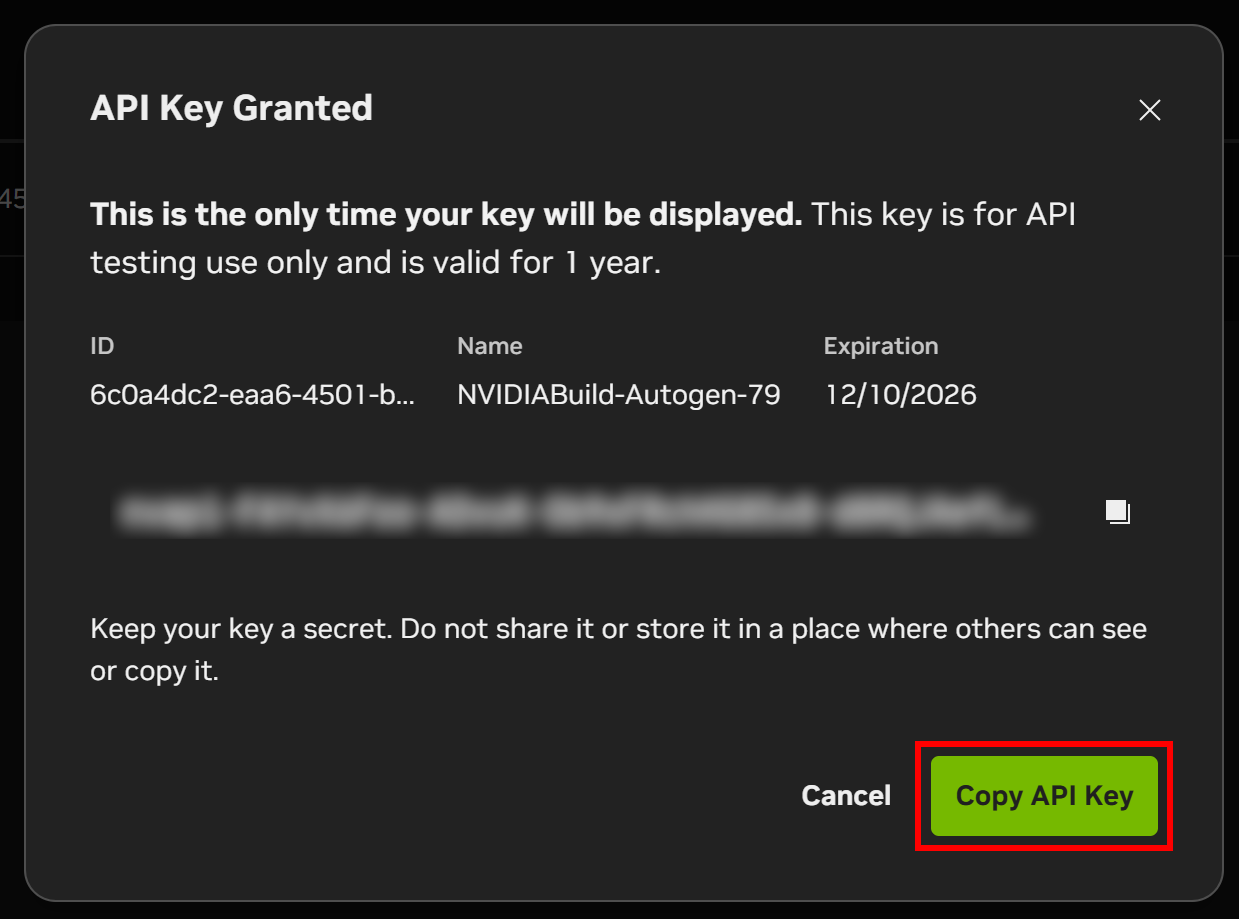
¡Bien hecho! Ya está listo para instalar NVIDIA NeMo Agent Toolkit y empezar a utilizarlo.
Paso n.º 2: configurar un proyecto NVIDIA NeMo
Para instalar la última versión estable de NeMo Agent Toolkit, ejecute:
pip install nvidia-natNeMo Agent Toolkit tiene muchas dependencias opcionales que se pueden instalar junto con el paquete principal. Estas dependencias opcionales se agrupan por marco de trabajo.
Una vez instalado, debería tener acceso al comando nat. Compruebe que funciona ejecutando:
nat --versionDebería ver un resultado similar a este:
nat, versión 1.3.1A continuación, cree una carpeta raíz para su aplicación NVIDIA NeMo. Por ejemplo, llámela «bright_data_nvidia_nemo»:
mkdir bright_data_nvidia_nemoDentro de esta carpeta, cree un flujo de trabajo de NeMo Agent llamado «web_data_workflow» utilizando:
nat workflow create --workflow-dir bright_data_nvidia_nemo web_data_workflow Nota: Si aparece el error «El cliente no tiene los privilegios necesarios», ejecute el comando como administrador.
Si se ejecuta correctamente, debería ver registros como:
Instalando el flujo de trabajo «web_data_workflow»...
Flujo de trabajo «web_data_workflow» instalado correctamente.
Flujo de trabajo «web_data_workflow» creado correctamente en <su_ruta>Su carpeta de proyecto bright_data_nvidia_nemo/web_data_workflow ahora tendrá la siguiente estructura:
bright_data_nvidia_nemo/web_data_workflow/
├── configs -> src/web_data_workflow/configs
├── data -> src/text_file_ingest/data
├── pyproject.toml
└── src/
├── web_data_workflow.egg-info/
└── web_data_workflow/
├── __init__.py
├── configs/
│ └── config.yml
├── datos/
├── __init__.py
├── register.py
└── web_data_workflow.pyEsto es lo que representa cada archivo y carpeta:
configs/→src/web_data_workflow/configs: Enlace simbólico para facilitar el acceso a la configuración del flujo de trabajo.data/→src/text_file_ingest/data: Enlace simbólico para almacenar datos de muestra o archivos de entrada.pyproject.toml: Archivo de metadatos y dependencias del proyecto.src/: Directorio del código fuente.web_data_workflow.egg-info/: Carpeta de metadatos creada por las herramientas de empaquetado de Python.web_data_workflow/: Módulo principal del flujo de trabajo.__init__.py: Inicializa el módulo.configs/config.yml: Archivo de configuración del flujo de trabajo donde se define el comportamiento en tiempo de ejecución (configuración LLM, definiciones de funciones/herramientas, tipo y configuración del agente, orquestación del flujo de trabajo, etc.).
data/: Directorio para almacenar datos específicos del flujo de trabajo, entradas de muestra o archivos de prueba.register.py: Módulo de registro para conectar sus funciones personalizadas con NAT.web_data_workflow.py: Archivo de muestra que define herramientas personalizadas.
Abra el proyecto en su IDE de Python favorito y dedique un tiempo a familiarizarse con los archivos generados.
Verá que la definición del flujo de trabajo se encuentra en el siguiente archivo:
bright_data_nvidia_nemo/web_data_workflow/web_data_workflow/configs/config.ymlÁbrelo y verás la siguiente configuración YAML:
funciones:
current_datetime:
_type: current_datetime
web_data_workflow:
_type: web_data_workflow
prefijo: «Hola:»
llms:
nim_llm:
_type: nim
nombre_del_modelo: meta/llama-3.1-70b-instruct
temperatura: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [current_datetime, web_data_workflow]Esto define un flujo de trabajo del agente ReAct impulsado por el modelo meta/llama-3.1-70b-instruct de NVIDIA NIM, con acceso a:
- La herramienta integrada
current_datetime. - La herramienta personalizada
web_data_workflow.
En concreto, la herramienta web_data_workflow se define en:
bright_data_nvidia_nemo/web_data_workflow/web_data_workflow/web_data_workflow.pyEsa herramienta de muestra toma una entrada de texto y la devuelve con un prefijo predefinido (por ejemplo, «Hola:»).
¡Genial! Ahora ya tiene un flujo de trabajo listo con NAT.
Paso n.º 3: Prueba el flujo de trabajo actual
Antes de personalizar el flujo de trabajo generado, es recomendable dedicar algo de tiempo a familiarizarse con él y comprender cómo funciona. Esto facilitará la adaptación del flujo de trabajo para integrarlo con Bright Data.
Comience navegando a la carpeta del flujo de trabajo en su terminal:
cd ./bright_data_nvidia_nemo/web_data_workflowAntes de ejecutar el flujo de trabajo, debe establecer la variable de entorno NVIDIA_API_KEY. En Linux/macOS, ejecute:
export NVIDIA_API_KEY="<SU_NVIDIA_API_KEY>"De forma equivalente, en Windows PowerShell, ejecute:
$Env:NVIDIA_API_KEY="<SU_NVIDIA_API_KEY>"Reemplace el marcador de posición <SU_NVIDIA_API_KEY> por la clave API de NVIDIA NIM que obtuvo anteriormente.
Ahora, pruebe el flujo de trabajo con el comando nat run de la siguiente manera:
nat run --config_file configs/config.yml --input "¡Hola! ¿Qué tal?"Esto carga el archivo config.yml (a través del enlace simbólico configs/ ) y envía el mensaje «¡Hola! ¿Qué tal?».
Debería ver un resultado como este: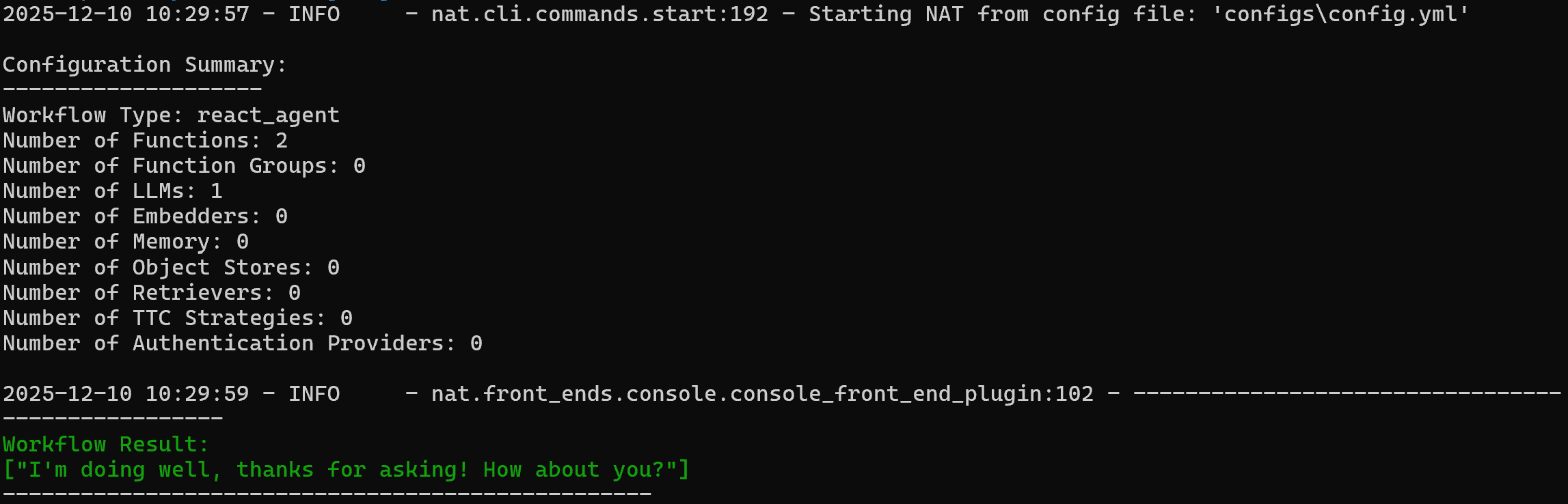
Tenga en cuenta que el agente respondió con:
Estoy bien, gracias por preguntar. ¿Y tú?Para verificar que la herramienta web_data_workflow personalizada funciona, prueba con un mensaje como este:
nat run --config_file configs/config.yml --input «Use la herramienta web_data_workflow en 'World!'»Dado que la herramienta web_data_workflow está configurada con el prefijo «Hello:», el resultado esperado es:
Resultado del flujo de trabajo:
['Hello: World!']Observa cómo el resultado coincide con el comportamiento esperado: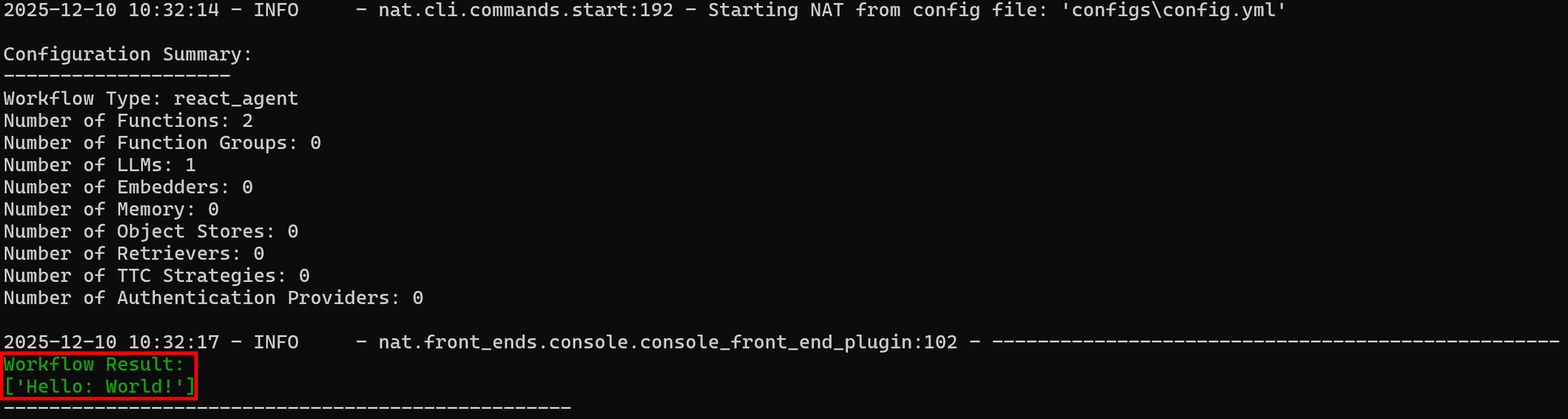
¡Genial! Su flujo de trabajo NAT funciona perfectamente. Ahora está listo para integrarlo con Bright Data.
Paso n.º 4: Instalar las herramientas LangChain Bright Data
Una de las características peculiares del kit de herramientas NVIDIA NeMo Agent es que funciona con otras bibliotecas de IA, como LangChain, LlamaIndex, CrewAI, Agno, Microsoft Semantic Kernel, Google ADK y muchas otras.
Para simplificar la integración con Bright Data, en lugar de reinventar la rueda, utilizaremos las herramientas oficiales de Bright Data para LangChain.
Para obtener más información sobre estas herramientas, consulte la documentación oficial o estas entradas del blog:
Prepárese para utilizar LangChain dentro del kit de herramientas NVIDIA NeMo Agent instalando las siguientes bibliotecas:
pip install «nvidia-nat[langchain]» langchain-brightdataLos paquetes necesarios son:
«nvidia-nat[langchain]»: un subpaquete para integrar LangChain (o LangGraph) con el kit de herramientas NeMo Agent.langchain-brightdata: proporciona integraciones de LangChain para el conjunto de herramientas de recopilación de datos web de Bright Data. Permite a los agentes de IA recopilar resultados de motores de búsqueda, acceder a sitios web con restricciones geográficas o protegidos contra bots y extraer datos estructurados de plataformas populares como Amazon, LinkedIn y muchas otras.
Para evitar problemas durante la implementación, asegúrese de que el archivo pyproject.toml de su proyecto incluya:
dependencies = [
"nvidia-nat[langchain]~=1.3",
"langchain-brightdata~=0.1.3",
]Nota: Ajuste las versiones de estos paquetes según sea necesario para su proyecto.
¡Genial! Ahora su flujo de trabajo de NVIDIA NeMo Agent puede integrarse con las herramientas de LangChain para simplificar las conexiones con Bright Data.
Paso n.º 5: Prepare la integración de Bright Data
Las herramientas LangChain Bright Data funcionan conectándose a los servicios Bright Data configurados en su cuenta. Las dos herramientas que se muestran en este artículo son:
BrightDataSERP: obtiene resultados de motores de búsqueda para localizar páginas web normativas relevantes. Se conecta a la API SERP de Bright Data.BrightDataUnblocker: accede a cualquier sitio web público, incluso si está restringido geográficamente o protegido por medidas antibots. Esto ayuda al agente a extraer contenido de páginas web individuales y aprender de ellas. Se conecta a la API Web Unblocker de Bright Data.
Para utilizar estas herramientas, necesita una cuenta de Bright Data con una zona API SERP y una zona Web Unblocker API configuradas. ¡Vamos a configurarlas!
Si aún no tiene una cuenta de Bright Data, cree una nueva. De lo contrario, inicie sesión y acceda a su panel de control. A continuación, vaya a la página «Proxies y scraping» y consulte la tabla «Mis zonas»: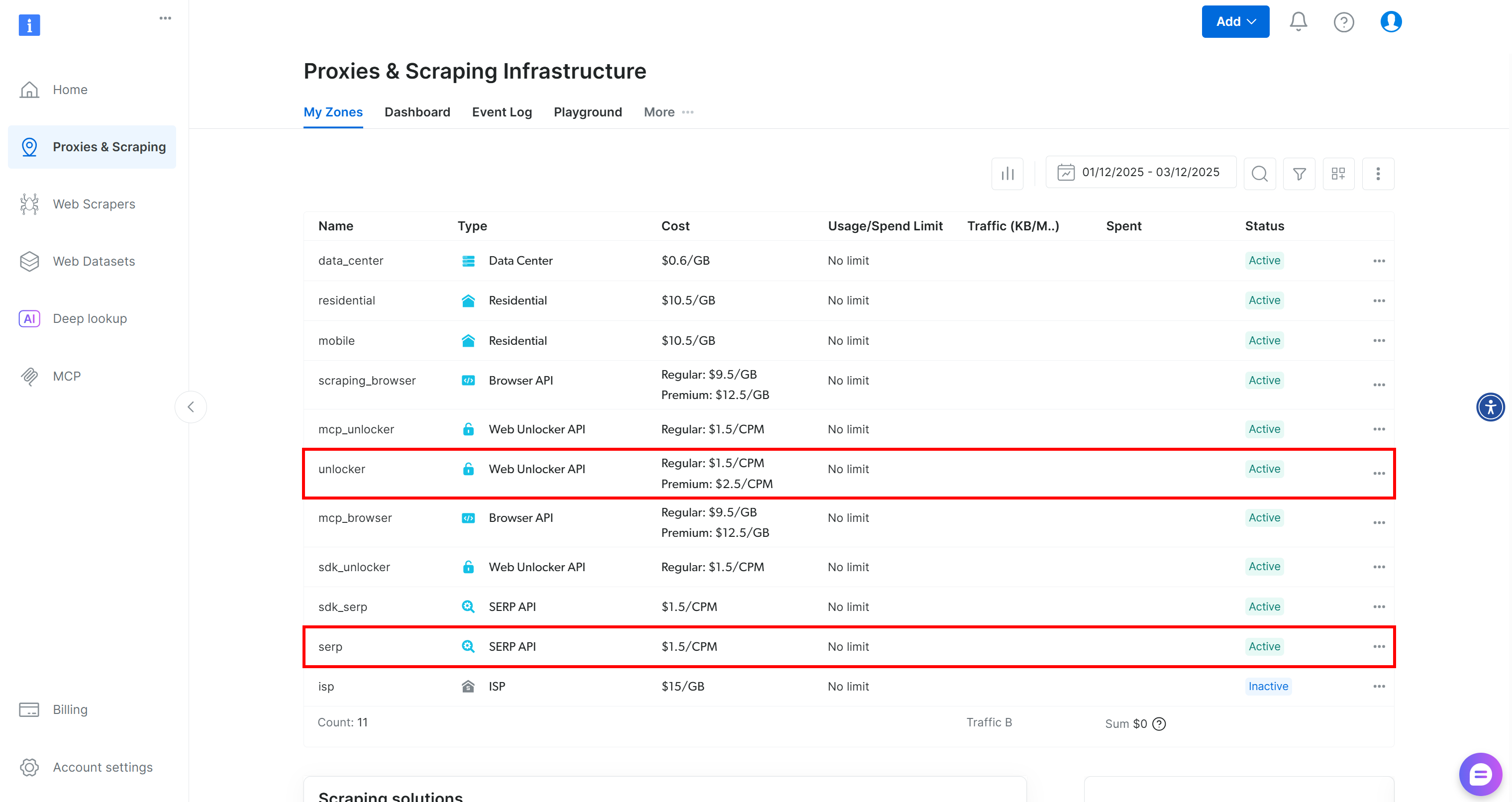
Si la tabla ya contiene una zona API Web Unlocker llamada «unlocker» y una zona API SERP llamada «serp», ya está listo. Esto se debe a que:
- La herramienta
BrightDataSERPLangChain se conecta automáticamente a una zona API SERP llamadaserp. - La herramienta
BrightDataUnblockerLangChain se conecta automáticamente a una zona API de Web Unblocker llamadaweb_unlocker.
Si faltan estas dos zonas, debe crearlas. Desplácese hacia abajo en las tarjetas «Unblocker API» y «API SERP» y, a continuación, haga clic en los botones «Crear zona». Siga el asistente para añadir las dos zonas con los nombres requeridos: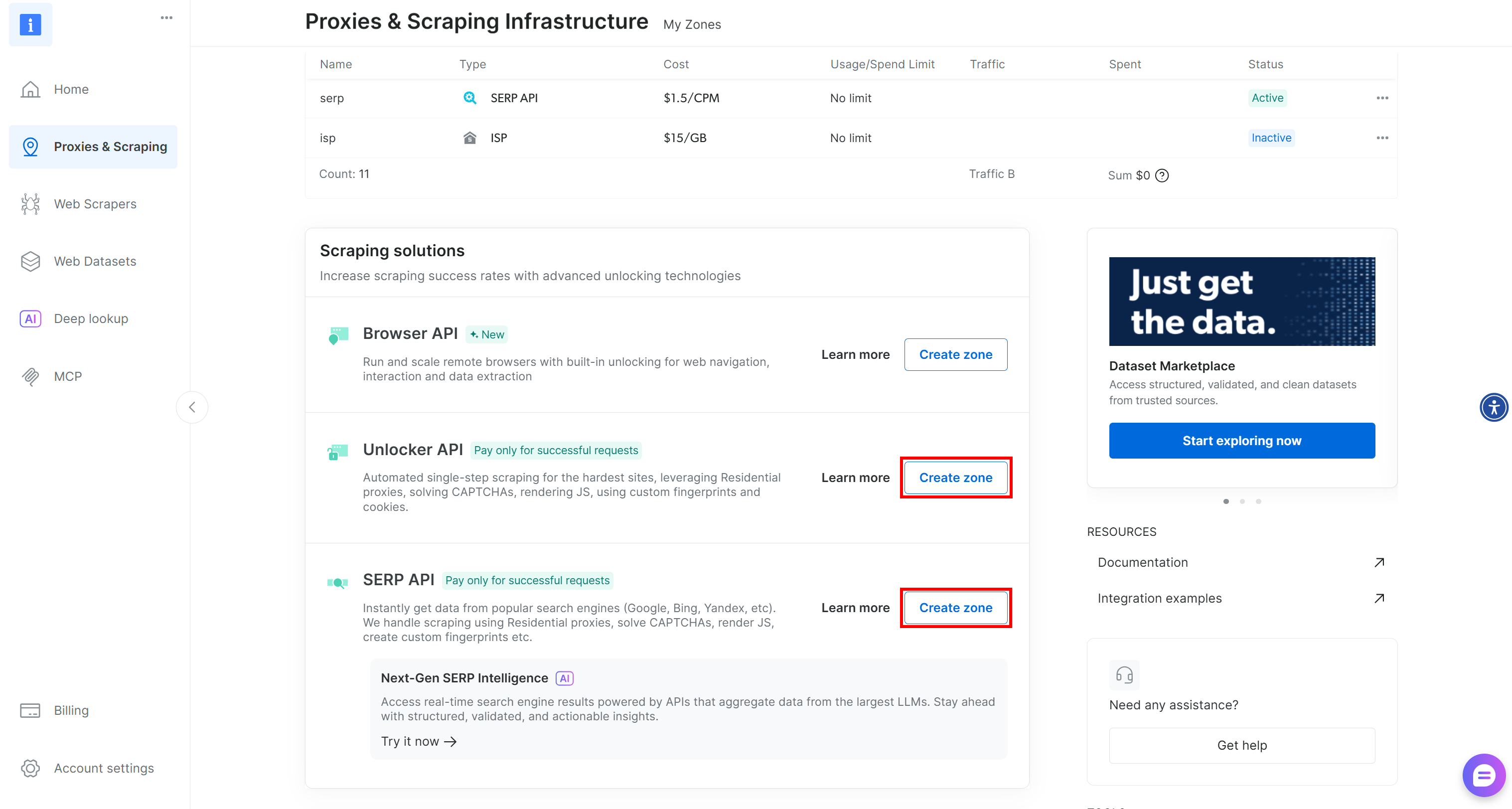
Para obtener instrucciones paso a paso, consulte estas páginas de documentación:
Por último, debe indicar a las herramientas LangChain Bright Data cómo autenticarse con su cuenta. Genere su clave API de Bright Data y guárdela como variable de entorno:
export BRIGHT_DATA_API_KEY="<SU_CLAVE_DE_API_DE_BRIGHT_DATA>"O, en PowerShell:
$Env:BRIGHT_DATA_API_KEY="<SU_CLAVE_API_DE_BRIGHT_DATA>"¡Genial! Ahora ya tiene todos los requisitos previos para conectar su agente NVIDIA NeMo a Bright Data a través de las herramientas LangChain.
Paso n.º 6: definir las herramientas personalizadas de Bright Data
Ahora ya tiene todos los componentes necesarios para crear nuevas herramientas en el flujo de trabajo de NVIDIA NeMo Agent Toolkit. Estas herramientas permitirán al agente interactuar con la API SERP y la API Web Unblocker de Bright Data, lo que le permitirá buscar en la web y extraer datos de cualquier página web pública.
Comience añadiendo un archivo bright_data.py a la carpeta src/ de su proyecto:
Defina una herramienta personalizada para interactuar con la API SERP de la siguiente manera:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/bright_data.py
from pydantic import Field
from typing import Optional
from nat.builder.builder import Builder
from nat.builder.function_info import FunctionInfo
from nat.cli.register_workflow import register_function
from nat.data_models.function import FunctionBaseConfig
import json
class BrightDataSERPAPIToolConfig(FunctionBaseConfig, name="bright_data_serp_api"):
"""
Configuración para la herramienta API SERP de Bright Data.
Requiere BRIGHT_DATA_API_KEY.
"""
api_key: str = Field(
default="",
description="Tu clave API de Bright Data utilizada para solicitudes SERP."
)
# Parámetros SERP predeterminados (anulaciones opcionales)
search_engine: str = Field(
default="google",
description="Motor de búsqueda para consultar (predeterminado: google)."
)
country: str = Field(
default="us",
description="Código de país de dos letras para resultados localizados (predeterminado: us)."
)
language: str = Field(
default="en",
description="Código de idioma de dos letras (predeterminado: en)."
)
search_type: Optional[str] = Field(
default=None,
description="Tipo de búsqueda: Ninguno, 'shop', 'isch', 'nws', 'jobs'."
)
device_type: Optional[str] = Field(
default=None,
description="Tipo de dispositivo: Ninguno, 'mobile', 'ios', 'android'."
)
parse_results: Opcional[bool] = Campo(
predeterminado=Ninguno,
descripción="Si se debe devolver JSON estructurado en lugar de HTML sin procesar."
)
@register_function(config_type=BrightDataSERPAPIToolConfig)
async def bright_data_serp_api_function(tool_config: BrightDataSERPAPIToolConfig, builder: Builder):
import os
from langchain_brightdata import BrightDataSERP
# Establecer la clave API si falta
if not os.environ.get("BRIGHT_DATA_API_KEY"):
if tool_config.api_key:
os.environ["BRIGHT_DATA_API_KEY"] = tool_config.api_key
async def _bright_data_serp_api(
query: str,
search_engine: Optional[str] = None,
country: Optional[str] = None,
language: Optional[str] = None,
search_type: Optional[str] = None,
device_type: Optional[str] = None,
parse_results: Optional[bool] = None,
) -> str:
"""
Realiza una consulta de búsqueda en tiempo real utilizando la API SERP de Bright Data.
Argumentos:
query (str): El texto de la consulta de búsqueda.
search_engine (str, opcional): Motor de búsqueda que se va a utilizar (por defecto: google).
country (str, opcional): Código de país para obtener resultados localizados.
language (str, opcional): código de idioma para resultados localizados.
search_type (str, opcional): tipo de búsqueda (por ejemplo, None, 'isch', 'shop', 'nws').
device_type (str, opcional): tipo de dispositivo (por ejemplo, None, 'mobile', 'ios').
parse_results (bool, opcional): si se debe devolver JSON estructurado.
Devuelve:
str: resultados de búsqueda con formato JSON.
"""
serp_client = BrightDataSERP(
bright_data_api_key=os.environ["BRIGHT_DATA_API_KEY"]
)
payload = {
"query": query,
"search_engine": search_engine o tool_config.search_engine,
"country": country o tool_config.country,
"language": language o tool_config.language,
"search_type": search_type o tool_config.search_type,
"device_type": device_type o tool_config.device_type,
"parse_results": (
parse_results
si parse_results no es None
else tool_config.parse_results
),
}
# Eliminar parámetros establecidos explícitamente como None
payload = {k: v for k, v in payload.items() if v is not None}
results = serp_client.invoke(payload)
return json.dumps(results)
yield FunctionInfo.from_fn(
_bright_data_serp_api,
description=_bright_data_serp_api.__doc__,
)
Este fragmento define una herramienta personalizada NVIDIA NeMo Agent llamada bright_data_serp_api. En primer lugar, es necesario definir una clase BrightDataSERPAPIToolConfig, que especifica los argumentos necesarios y los parámetros configurables compatibles con la API SERP para Google (por ejemplo, la clave API, el motor de búsqueda, el país, el idioma, el tipo de dispositivo, el tipo de búsqueda, si los resultados deben realizarse mediante Parseo en JSON, etc.).
A continuación, se registra una función personalizada bright_data_serp_api_function() como función de flujo de trabajo de NeMo. La función comprueba que la clave API de Bright Data esté configurada en el entorno y, a continuación, define una función asíncrona _bright_data_serp_api().
_bright_data_serp_api() construye una solicitud de búsqueda utilizando el cliente BrightDataSERP de LangChain, la invoca y devuelve los resultados en formato JSON. Por último, expone la función al marco NeMo Agent a través de FunctionInfo, que contiene todos los metadatos necesarios para que el agente llame a la función.
Nota: Devolver los resultados como JSON proporciona una salida de cadena estandarizada. Se trata de un truco útil, teniendo en cuenta que las respuestas de la API SERP pueden variar (JSON analizado, HTML sin procesar, etc.) en función de los argumentos configurados.
Del mismo modo, puede definir una herramienta bright_data_web_unlocker_api en el mismo archivo con:
class BrightDataWebUnlockerAPIToolConfig(FunctionBaseConfig, name="bright_data_web_unlocker_api"):
"""
Configuración para la herramienta Bright Data Web Unlocker.
Permite acceder a páginas con restricciones geográficas o protegidas contra bots utilizando
Bright Data Web Unlocker.
Requiere BRIGHT_DATA_API_KEY.
"""
api_key: str = Field(
default="",
description="Clave API de Bright Data para Web Unlocker."
)
country: str = Field(
default="us",
description="Código de país de dos letras simulado para la solicitud (por defecto: us)."
)
data_format: str = Field(
default="html",
description="Formato de contenido de salida: 'html', 'markdown' o 'screenshot'."
)
zone: str = Field(
default="unblocker",
description='Zona de Bright Data que se va a utilizar (predeterminado: "unblocker").'
)
@register_function(config_type=BrightDataWebUnlockerAPIToolConfig)
async def bright_data_web_unlocker_api_function(tool_config: BrightDataWebUnlockerAPIToolConfig, builder: Builder):
import os
import json
from typing import Optional
from langchain_brightdata import BrightDataUnlocker
# Establecer variable de entorno si es necesario
if not os.environ.get("BRIGHT_DATA_API_KEY") and tool_config.api_key:
os.environ["BRIGHT_DATA_API_KEY"] = tool_config.api_key
async def _bright_data_web_unlocker_api(
url: str,
country: Optional[str] = None,
data_format: Optional[str] = None,
) -> str:
"""
Accede a una URL con restricciones geográficas o protegida contra bots utilizando Bright Data Web Unlocker.
Argumentos:
url (str): URL de destino a recuperar.
country (str, opcional): Anula el país simulado.
data_format (str, opcional): Formato de contenido de salida («html», «markdown», «screenshot»).
Devuelve:
str: El contenido recuperado del sitio web de destino.
"""
unlocker = BrightDataUnlocker()
result = unlocker.invoke({
"url": url,
"country": country o tool_config.country,
"data_format": data_format o tool_config.data_format,
"zone": tool_config.zone,
})
return json.dumps(result)
yield FunctionInfo.from_fn(
_bright_data_web_unlocker_api,
description=_bright_data_web_unlocker_api.__doc__,
)
Ajuste los valores predeterminados de los argumentos para ambas herramientas según sus necesidades.
Recuerde que BrightDataSERP y BrightDataUnlocker intentan leer la clave API de la variable de entorno BRIGHT_DATA_API_KEY (que ya ha configurado anteriormente, por lo que ya está todo listo).
A continuación, importe estas dos herramientas añadiendo la siguiente línea a register.py:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/register.py
# ...
from .bright_data import bright_data_serp_api_function, bright_data_web_unlocker_api_functionLas dos herramientas no están disponibles para su uso en el archivo config.yml. El motivo es que el archivo pyproject.toml generado automáticamente contiene:
[project.entry-points.'nat.components']
web_data_workflow = "web_data_workflow.register"Esto le indica al comando nat: «Al cargar el flujo de trabajo web_data_workflow, busca componentes en el módulo web_data_workflow.register ».
Nota: Del mismo modo, puede crear una herramienta para BrightDataWebScraperAPI para integrarla con las API de Scraping web de Bright Data. Esto dota al agente de la capacidad de recuperar fuentes de datos estructurados de sitios web populares como Amazon, Instagram, LinkedIn, Yahoo Finance y muchos otros.
¡Ya está! Solo queda actualizar el archivo config.yml para que el agente se conecte a estas dos nuevas herramientas.
Paso n.º 7: Configurar las herramientas de Bright Data
En config.yml, importe las herramientas de Bright Data y páselas al agente con:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/configs/config.yml
funciones:
# Definir y personalizar las herramientas personalizadas de Bright Data
bright_data_serp_api:
_type: bright_data_serp_api
bright_data_web_unlocker_api:
_type: bright_data_web_unlocker_api
data_format: markdown
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct # Reemplazarlo por un modelo de IA listo para empresas
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [bright_data_serp_api, bright_data_web_unlocker_api] # Configure las herramientas de Bright Data
Para utilizar las herramientas definidas anteriormente:
- Añádalas en la sección
de funcionesdel archivoconfig.yml. Tenga en cuenta que puede personalizarlas a través de los argumentos expuestos por sus clasesFunctionBaseConfig. Por ejemplo, la herramientabright_data_web_unlocker_apise ha configurado para devolver datos en formato Markdown, que es unformato excelentepara que los agentes de IA los procesen. - Enumere las herramientas dentro del campo
tool_namesen el bloquede flujo de trabajopara que el agente pueda llamarlas.
¡Fantástico! Su agente React, impulsado por meta/llama-3.1-70b-instruct, ahora tiene acceso a ambas herramientas personalizadas basadas en LangChain:
bright_data_serp_apibright_data_web_unlocker_api
Nota: En este ejemplo, el LLM está configurado como un modelo NVIDIA NIM. Considere la posibilidad de cambiar a un modelo más orientado a la empresa en función de sus necesidades de implementación.
Paso n.º 8: Prueba el flujo de trabajo del kit de herramientas NVIDIA Nemo Agent
Para verificar que el flujo de trabajo de NVIDIA NeMo Agent Toolkit ahora puede interactuar con las herramientas de Bright Data, necesita una tarea que active tanto la búsqueda web como la extracción de datos web.
Por ejemplo, imagine que su empresa desea supervisar los nuevos productos y precios de la competencia para respaldar la inteligencia empresarial. Si su competidor es Nike, podría escribir un mensaje como:
Busca en la web los últimos modelos de zapatillas Nike. De los resultados de búsqueda obtenidos, selecciona hasta tres de las páginas web más relevantes, dando prioridad a las páginas oficiales de Nike. Accede a estas páginas y recupera su contenido en formato Markdown. Para cada modelo de zapatilla encontrado, proporciona el nombre, el estado de lanzamiento, el precio, la información clave y un enlace a la página oficial de Nike (si está disponible).Asegúrate de que las variables de entorno NVIDIA_API_KEY y BRIGHT_DATA_API_KEY estén definidas y, a continuación, ejecuta tu agente con:
nat run --config_file configs/config.yml --input «Busca en la web las últimas zapatillas Nike. De los resultados de búsqueda obtenidos, selecciona hasta tres de las páginas web más relevantes, dando prioridad a las páginas oficiales de Nike. Accede a estas páginas y recupera su contenido en formato Markdown. Para los modelos de zapatillas encontrados, proporciona el nombre, el estado de lanzamiento, el precio, la información clave y un enlace a la página oficial de Nike (si está disponible).»El resultado inicial será algo así: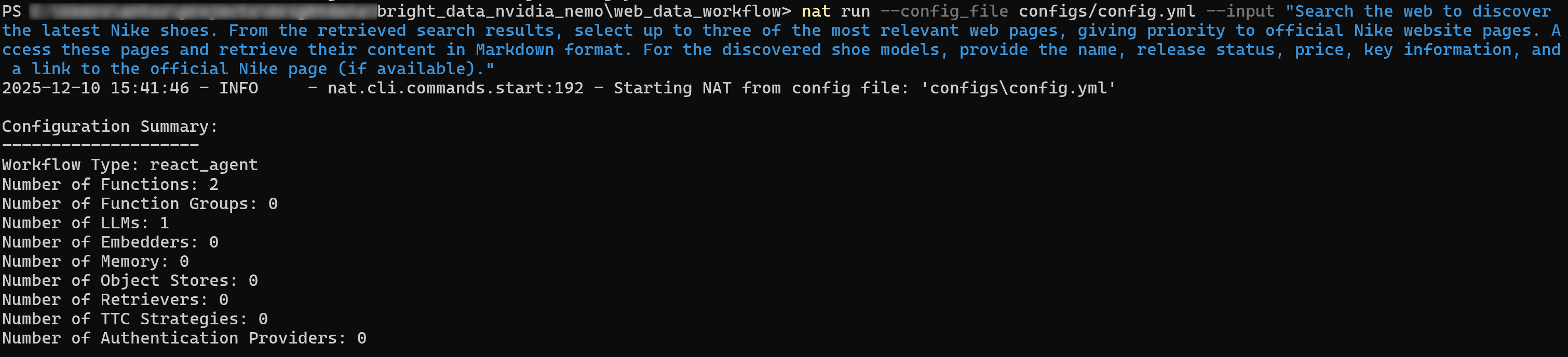
Si habilitas el modo detallado (establece verbose: true en el bloque de flujo de trabajo ), verás que el agente realiza los siguientes pasos:
- Llama a la API SERP con consultas como «últimas zapatillas Nike» y «nuevas zapatillas Nike».
- Seleccionar las páginas más relevantes, dando prioridad a la página oficial de Nike«Nuevas zapatillas».
- Utilizar la herramienta API Web Unlocker para acceder a la página seleccionada y extraer su contenido en formato Markdown.
- Procesar los datos extraídos y producir una lista estructurada de resultados:
[Air Jordan 11 Retro «Gamma» - Zapatillas para hombre](https://www.nike.com/t/air-jordan-11-retro-gamma-mens-shoes-DYkD1oXL/CT8012-047)
Estado del lanzamiento: Próximamente.
Colores: 1.
Precio: 235 $.
[Air Jordan 11 Retro «Gamma» - Zapatillas para niños grandes](https://www.nike.com/t/air-jordan-11-retro-gamma-big-kids-shoes-LJyljnZt/378038-047)
Estado del lanzamiento: Próximamente.
Colores: 1.
Precio: 190 $.
# Omitido por brevedad...Estos resultados coinciden exactamente con lo que encontrarías en la página «Zapatillas nuevas» de Nike: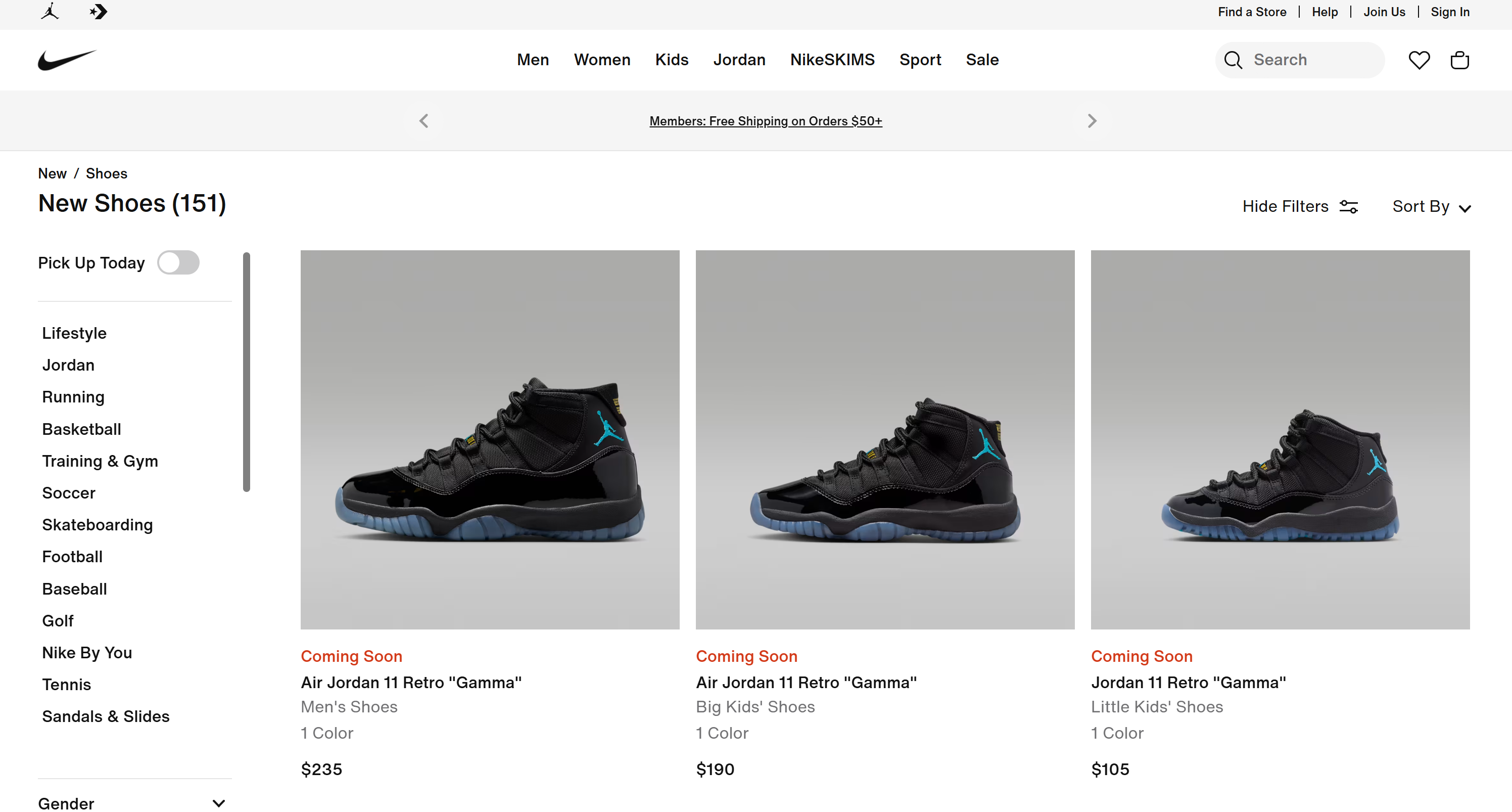
¡Misión cumplida! El agente de IA buscó de forma autónoma en la web, seleccionó las páginas adecuadas, las rastreó y extrajo información estructurada sobre los productos. ¡Nada de esto sería posible sin la integración de las herramientas de Bright Data en su flujo de trabajo NAT!
Recuerde que la inteligencia empresarial agencial es solo uno de los muchos casos de uso que permiten las soluciones de Bright Data cuando se combinan con NVIDIA NeMo Agent Toolkit. Pruebe a ajustar la configuración de la herramienta, integrar herramientas adicionales o cambiar la solicitud de entrada para explorar más escenarios.
Conecta NVIDIA NeMo Agent Toolkit con Bright Data a través de Web MCP
Otra forma de integrar NVIDIA NeMo Agent Toolkit con los productos de Bright Data es conectándolo a Web MCP. Para obtener más detalles, consulta la documentación oficial.
Web MCP proporciona acceso a más de 60 herramientas creadas sobre la plataforma de automatización web y recopilación de datos de Bright Data. Incluso en su nivel gratuito, ya puede tener acceso a dos potentes herramientas:
| Herramienta | Descripción |
|---|---|
search_engine |
Obtén resultados de Google, Bing o Yandex en formato JSON o Markdown. |
scrape_as_markdown |
Extrae cualquier página web en Markdown limpio, evitando las medidas anti-bot. |
Pero Web MCP realmente destaca con el modo Pro. Este nivel premium no es gratuito, pero desbloquea la extracción de datos estructurados para las principales plataformas, como Amazon, Zillow, LinkedIn, YouTube, TikTok, Google Maps y más, además de herramientas adicionales para acciones automatizadas del navegador.
Nota: Para la configuración del proyecto y los requisitos previos, consulte el capítulo anterior.
Ahora, veamos cómo utilizar Web MCP de Bright Data dentro del kit de herramientas NVIDIA NeMo Agent.
Paso n.º 1: Instalar el paquete NVIDIA NAT MCP
Como se ha mencionado anteriormente, el kit de herramientas NVIDIA NeMo Agent es modular. El paquete básico proporciona la base y las capacidades adicionales se añaden a través de extensiones opcionales.
Para la compatibilidad con MCP, el paquete necesario es nvidia-nat[mcp]. Instálelo con:
pip install nvidia-nat[mcp]Ahora, su agente NVIDIA NeMo Agent Toolkit puede conectarse a servidores MCP. En concreto, para garantizar un rendimiento y una fiabilidad de nivel empresarial, se conectará al Web MCP de Bright Data mediante comunicación HTTP remota streamable a través del servidor remoto gestionado.
Paso n.º 2: Configurar la conexión remota a Web MCP
En su config.yml, configure la conexión al servidor Web MCP remoto de Bright Data utilizando el protocolo HTTP Streamable:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/configs/config.yml
function_groups:
bright_data_web_mcp:
_type: mcp_client
server:
transport: streamable-http
url: "https://mcp.brightdata.com/mcp?token=<YOUR_BRIGHT_DATA_API_KEY>&pro=1" tool_call_timeout: 600
auth_flow_timeout: 300
reconnect_enabled: true
reconnect_max_attempts: 3
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct # Reemplácelo con un modelo de IA listo para empresas.
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [bright_data_web_mcp]
Esta vez, en lugar de definir herramientas en el bloque de funciones, se utilizan grupos de funciones. Esto configura la conexión Web MCP y recupera el conjunto completo de herramientas MCP del servidor remoto. A continuación, el grupo se pasa al agente a través del campo tool_names, al igual que las herramientas individuales.
La URL de Web MCP incluye el parámetro de consulta &pro=1. Esto habilita el modo Pro, que es opcional pero muy recomendable para uso empresarial, ya que desbloquea el conjunto completo de herramientas de extracción de datos estructurados, no solo las básicas.
Paso n.º 3: Verificar la conexión Web MCP
Ejecute su agente NVIDIA NeMo con una nueva solicitud. En los registros iniciales, debería ver que el agente carga todas las herramientas expuestas por Web MCP: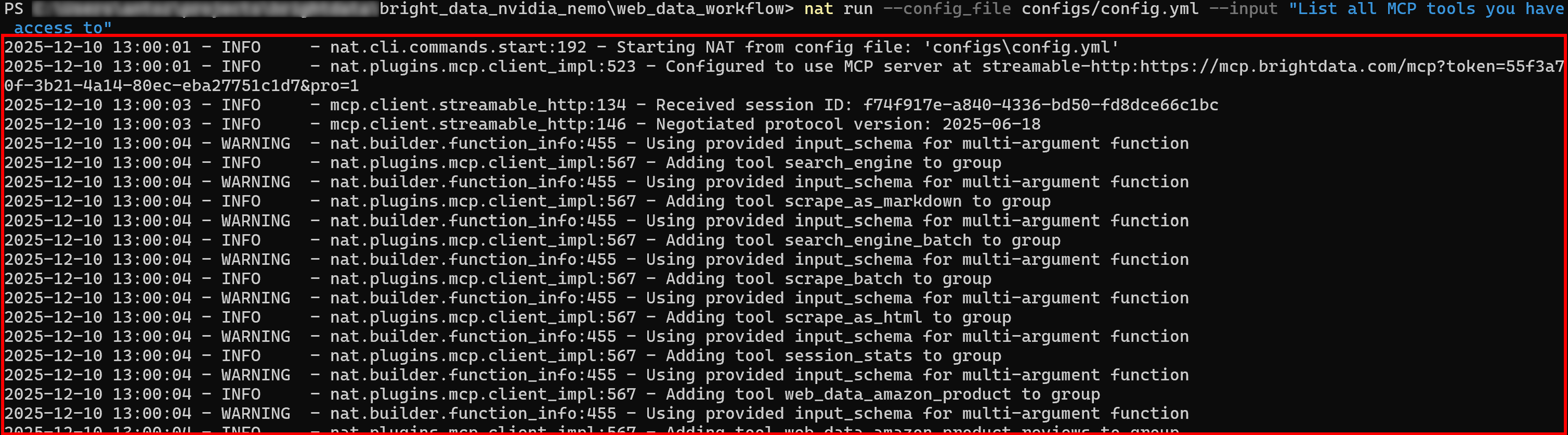
Si el modo Pro está habilitado, se cargarán inicialmente las más de 60 herramientas.
A continuación, los registros de resumen de configuración mostrarán un único grupo de funciones, como era de esperar: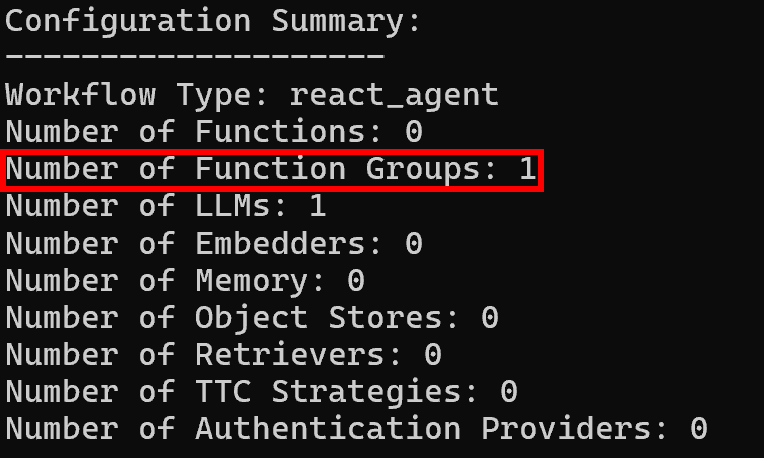
¡Et voilà! Su flujo de trabajo de NVIDIA NeMo Agent Toolkit ahora tiene acceso completo a todas las capacidades que ofrece Bright Data Web MCP.
Conclusión
En esta entrada del blog, ha aprendido a integrar Bright Data con NVIDIA NeMo Agent Toolkit, ya sea a través de herramientas personalizadas impulsadas por LangChain o a través de Web MCP.
Estas configuraciones abren la puerta a búsquedas web en tiempo real, extracción de datos estructurados, acceso a fuentes web en directo e interacciones web automatizadas dentro de los flujos de trabajo NAT. Aprovecha el conjunto completo de servicios de Bright Data para IA, ¡liberando todo el potencial de sus agentes de IA!
¡Regístrese hoy mismo en Bright Data y comience a integrar nuestras herramientas de datos web preparadas para la IA!




