

En esta guía aprenderás:
- Qué es Pipedream y por qué utilizarlo.
- La razón por la que debería integrarlo con un plugin de scraping incorporado.
- Ventajas de la integración de Pipedream con la arquitectura de scraping de Bright Data.
- Un tutorial paso a paso para crear un flujo de trabajo de web scraping con Pipedream.
¡Vamos a ello!
Pipedream de un vistazo: Automatice e integre con facilidad
Pipedream es una plataforma para crear y ejecutar flujos de trabajo que conectan varias aplicaciones y proveedores de terceros. En concreto, proporciona funcionalidades tanto sin código como de bajo código. Gracias a esas capacidades, puedes automatizar procesos e integrar sistemas a través de componentes preconstruidos o código personalizado.
A continuación se desglosan sus principales características:
- Generador visual de flujos de trabajo: Define flujos de trabajo mediante una interfaz visual, conectando componentes preconstruidos para aplicaciones populares. Actualmente, ofrece integraciones para más de 2700 aplicaciones.
- Sin código/con poco código: No requiere conocimientos técnicos. Aún así, para necesidades complejas, las aplicaciones de Pipedream pueden incorporar nodos de código personalizados. Los lenguajes de programación compatibles son Node.js, Python, Go y Bash.
- Arquitectura basada en eventos: Los flujos de trabajo se activan por eventos como HTTP/webhooks, hora programada, correos electrónicos entrantes, etc. De este modo, el flujo de trabajo permanece inactivo y no consume recursos hasta que se produce un evento desencadenante específico.
- Ejecución sin servidor: La funcionalidad principal de Pipedream gira en torno a su tiempo de ejecución sin servidor. Esto significa que no necesitas aprovisionar o gestionar servidores. Pipedream ejecuta flujos de trabajo en un entorno escalable y bajo demanda.
- IA que crea flujos de trabajo: Deal with String, una IA dedicada a escribir agentes personalizados que solo requieren que insertes indicaciones. También puedes utilizarla si no estás particularmente familiarizado con Pipedream. Puede escribir un aviso y dejar que la IA construya un flujo de trabajo por usted.
¿Por qué no codificarlo? Ventajas de una integración de scraping lista para usar
Pipedream soporta acciones de código. Estas te permiten escribir scripts completos desde cero en tu lenguaje preferido (entre los soportados). Técnicamente, esto significa que podrías construir un bot de raspado completamente dentro de Pipedream usando estos nodos.
Por otro lado, hacerlo no simplifica necesariamente el proceso de creación de un flujo de trabajo de scraping. Seguirá enfrentándose a los retos y obstáculos habituales relacionados con las protecciones anti-scraping.
Por lo tanto, es más práctico, eficaz y rápido confiar en un plugin de scraping integrado que maneje estas complejidades por usted. Esa es precisamente la experiencia que ofrece la integración de Bright Data en Pipedream.
A continuación encontrará una lista de las razones más importantes para confiar en el plugin de raspado Bright Data listo para usar:
- Autenticación sencilla: Pipedream almacena de forma segura tu clave API de Bright Data (necesaria para la autenticación) y te proporciona una fácil usabilidad. No necesitas escribir ningún código personalizado para la autenticación, y te aseguras de no exponer tu clave.
- Superar los sistemas anti-bot: Bajo el capó, las API de Bright Data manejan todos los desafíos de raspado web, desde la rotación de proxy y la gestión de IP hasta la resolución de CAPTCHAs y el análisis sintáctico de datos. De este modo, garantiza que su flujo de trabajo Pipedream reciba datos web coherentes y de alta calidad.
- Datos estructurados: Tras el scraping, obtendrá datos estructurados y organizados sin necesidad de escribir ninguna línea de código. El plugin se encarga de estructurar los datos por ti.
Principales ventajas de combinar Pipedream con el plugin Bright Data
Cuando conecta las capacidades de automatización de Pipedream con Bright Data, puede:
- Acceda a datos frescos: El objetivo del web scraping es recuperar datos de la web, y Bright Data le ayuda con ello. Sin embargo, los datos cambian con el tiempo. Por lo tanto, si no quiere que sus análisis queden obsoletos, debe seguir extrayendo datos nuevos. Aquí es donde la potencia de Pipedream resulta útil (por ejemplo, mediante la programación de desencadenadores).
- Integra la IA en tus flujos de trabajo de scraping: Pipedream se integra con varios LLM, como ChatGPT y Gemini. Esto le permite automatizar varias tareas que requerirían horas de trabajo manual. Por ejemplo, podría crear un flujo de trabajo de GAR para supervisar una lista de productos de la competencia en un sitio de comercio electrónico.
- Simplificar los tecnicismos: Los sitios web emplean sofisticadas técnicas de bloqueo anti-scraping que se actualizan casi todas las semanas. La integración de Bright Data elude los bloqueos por usted, ya que se encarga de todas las soluciones anti-bot.
Es hora de ver la integración de Bright Data en acción en un flujo de trabajo de scraping de Pipedream.
Construya un flujo de trabajo de scraping potenciado por IA con Pipedream y Bright Data: Tutorial paso a paso
En esta sección guiada, aprenderá a crear un flujo de trabajo de Pipedream que utilice Bright Data para recuperar datos de un producto de Amazon. En concreto, la página de destino será:
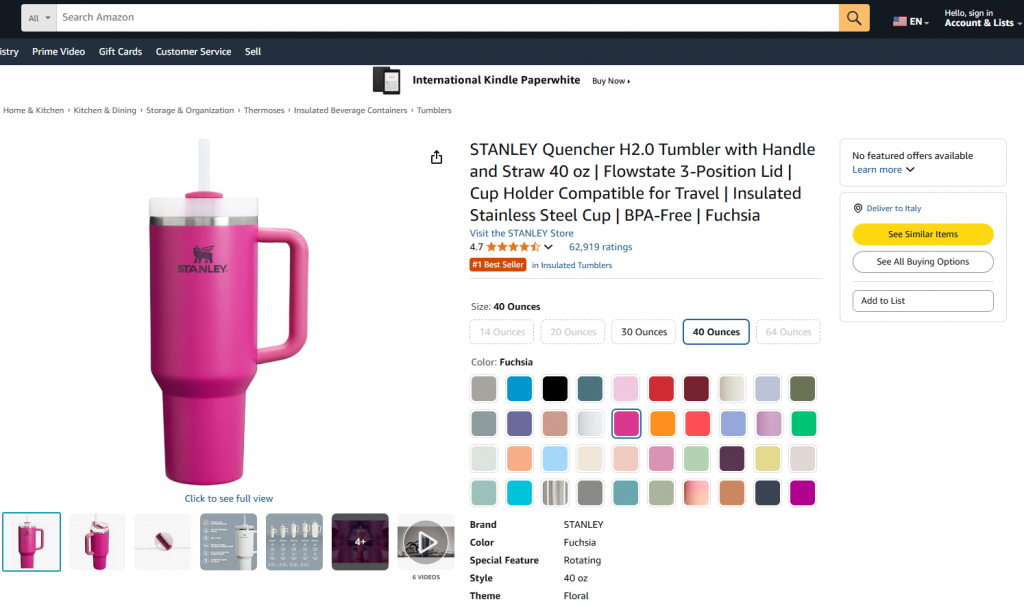
El objetivo es mostrarle cómo crear un flujo de trabajo Pipedream que haga lo siguiente:
- Recupera los datos de la página web de destino mediante la integración de Bright Data.
- Introduce los datos en un LLM.
- Pide al LLM que analice los datos y elabore un resumen del producto a partir de ellos.
Siga los pasos que se indican a continuación para aprender a crear, probar y desplegar un flujo de trabajo de este tipo en Pipedream.
Requisitos
Para reproducir este tutorial, necesitas
- Una cuenta Pipedream (una cuenta gratuita es suficiente).
- Una clave API de Bright Data.
- Una clave API de OpenAI.
Si aún no los tienes, utiliza los enlaces anteriores y sigue las instrucciones para configurarlo todo.
También ayuda tener estos conocimientos para seguir el tutorial:
- Familiaridad con la infraestructura y los productos de Bright Data (especialmente la API Web Scraper).
- Conocimientos básicos de procesamiento de IA (por ejemplo, LLM).
- Conocimiento del funcionamiento de los disparadores y las llamadas a la API mediante webhooks.
Paso 1: Crear un nuevo flujo de trabajo de Pipedream
Inicie sesión en su cuenta de Pipedream y vaya a su panel de control. A continuación, cree un nuevo flujo de trabajo haciendo clic en el botón “Nuevo flujo de trabajo”:
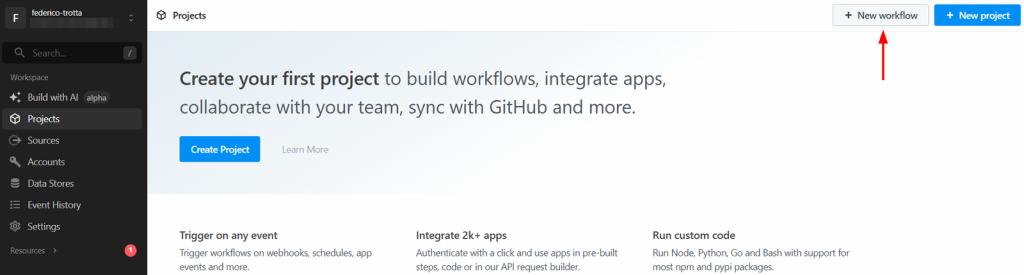
El sistema le pedirá que cree un nuevo proyecto. Dele un nombre y haga clic en el botón “Crear proyecto” cuando haya terminado:
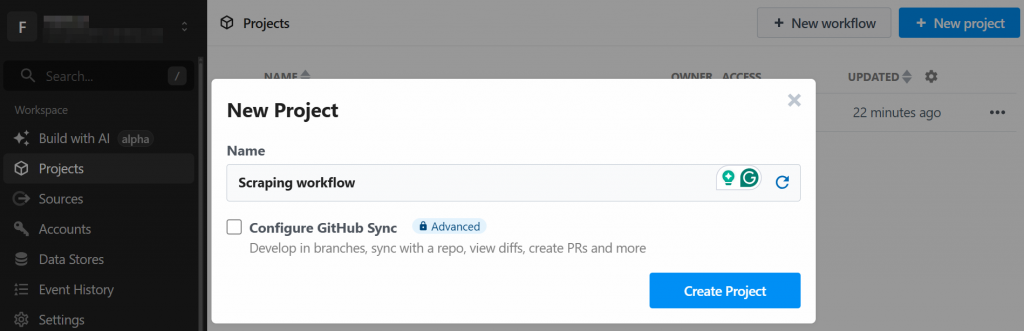
La herramienta le pedirá que asigne un nombre al flujo de trabajo y que defina su configuración. Puede dejar los ajustes como están y pulsar el botón “Crear flujo de trabajo” al final:
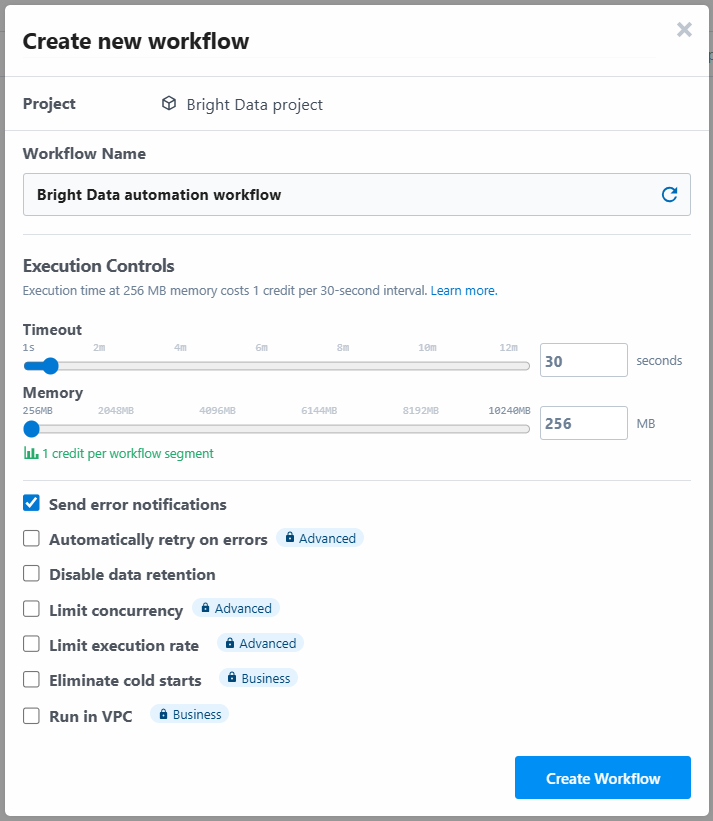
A continuación se muestra cómo aparece la interfaz de usuario de su nuevo flujo de trabajo:
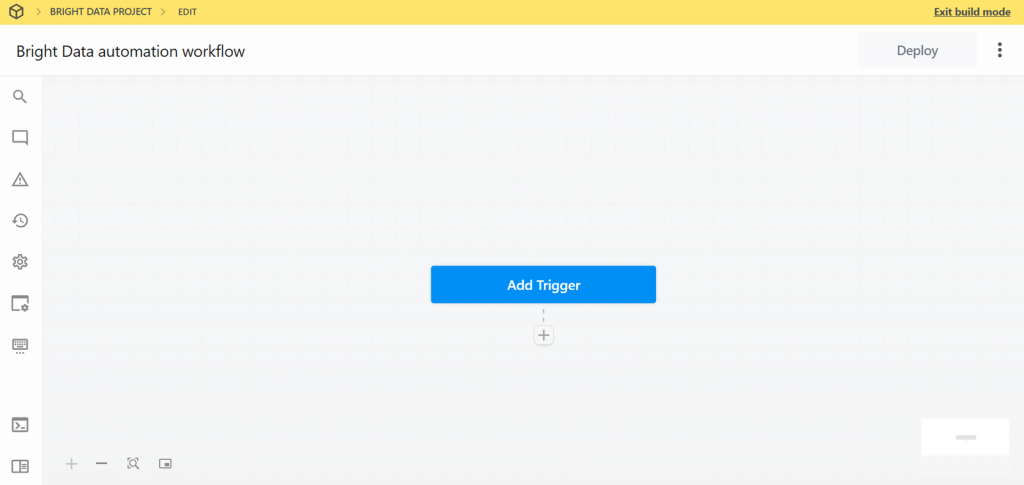
Muy bien. Ha creado un nuevo flujo de trabajo en Pipedream. Ahora estás listo para añadirle integraciones de plugins.
Paso 2: Añadir un activador
En Pipedream, cada flujo de trabajo comienza con un disparador. Al hacer clic en “Añadir activador”, se mostrarán los activadores que puede elegir:
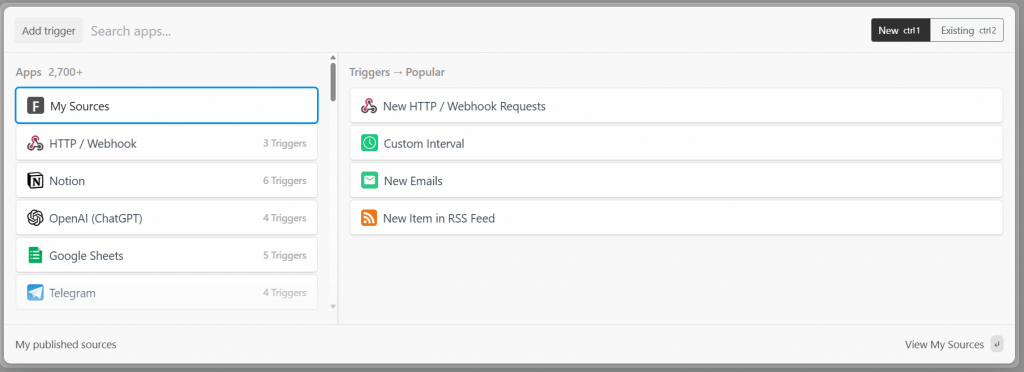
En este caso, seleccione el activador “Nuevas solicitudes HTTP/Webhook”, necesario para conectar con Bright Data. Deje los datos del marcador de posición como están y haga clic en el botón “Guardar y continuar”:
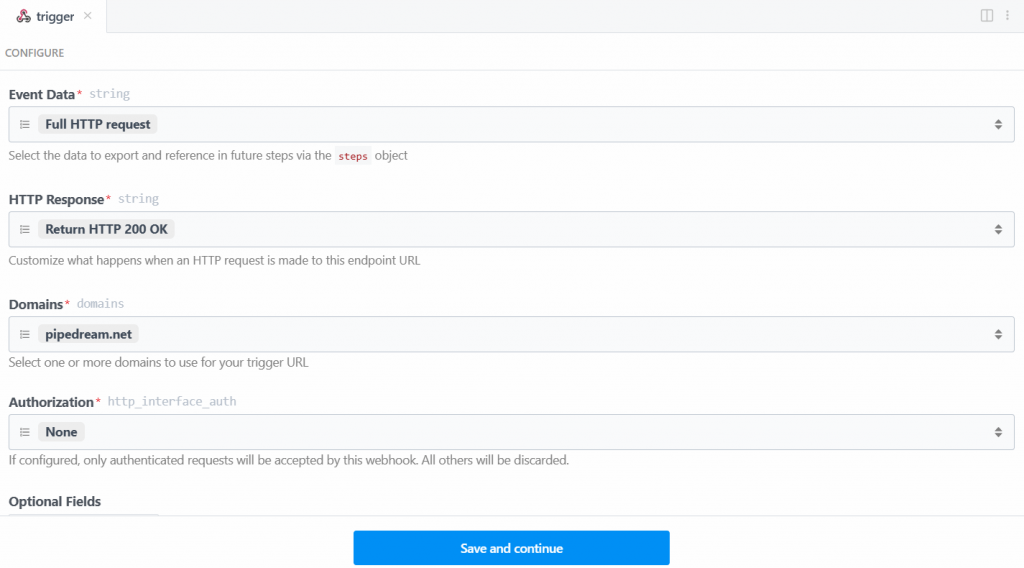
Para que el disparador funcione, tienes que generar un evento. Para ello, haga clic en “Generar evento de prueba”:
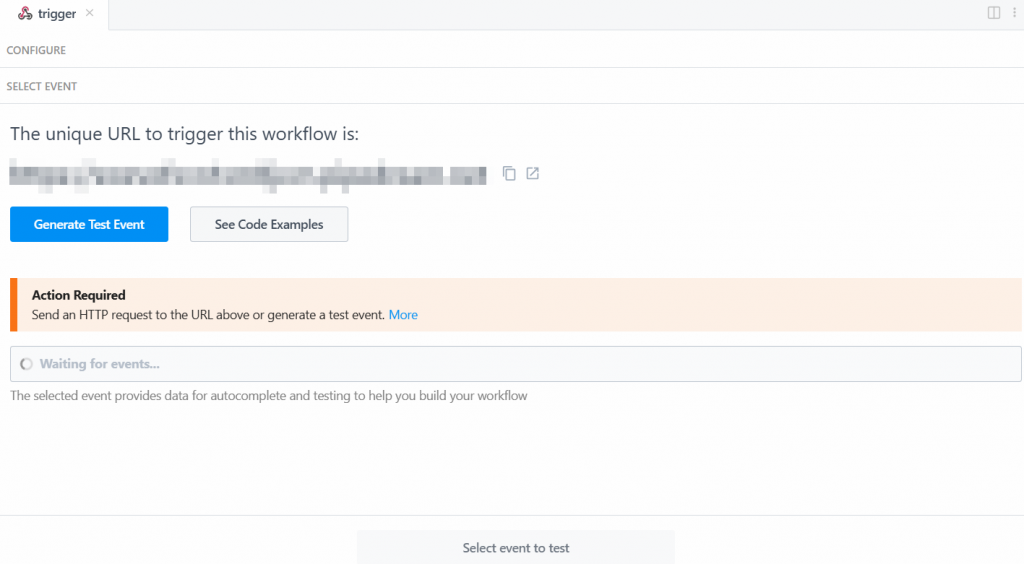
El sistema le proporciona un valor predefinido de un evento de prueba de la siguiente manera:
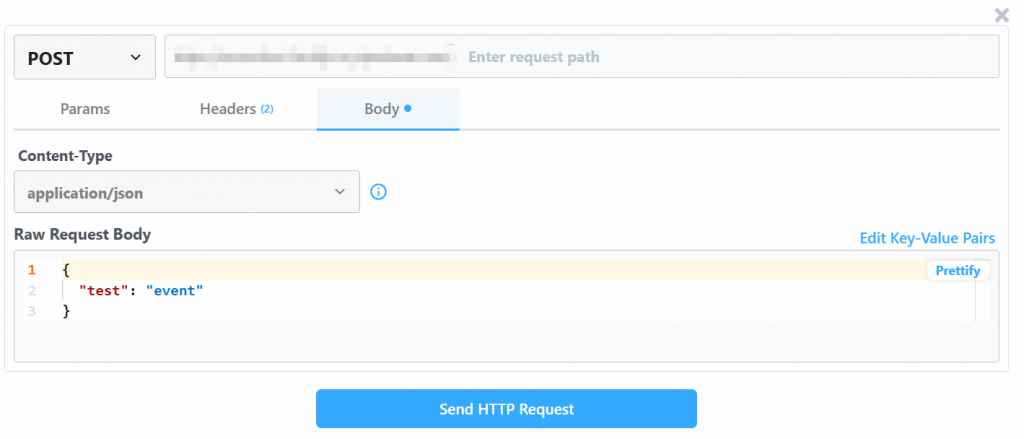
Cambia el valor de “Raw Request Body” por:
{
"url": "https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8",
"zipcode": "94107",
"language": ""
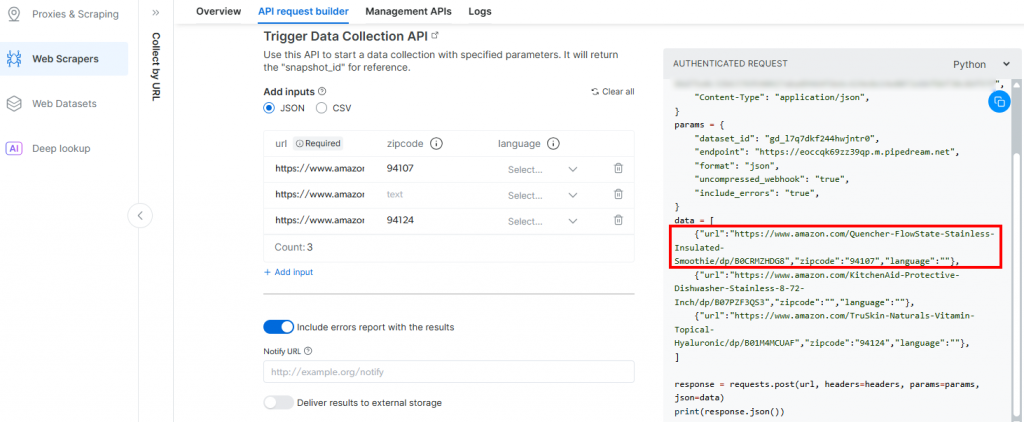
}La razón es que el disparador generado por Pipedream iniciará la llamada a la API de Amazon Scraper de Bright Data. El punto final (que se configurará más adelante) requiere datos de entrada en ese formato específico de carga útil. Puede verificarlo comprobando la sección “API Request Builder” del raspador “Collect by URL” en Aamzon Web Scrapers de Bright Data:
Vuelve a la ventana de Pipedream, cuando hayas terminado, haz clic en el botón “Enviar petición HTTP”. Si todo va según lo esperado, verá un mensaje de éxito en la sección de resultados. El disparador también se coloreará de verde:
Perfecto. El disparador para iniciar la integración de Bright Data en el flujo de trabajo de raspado de Pipedream se ha configurado correctamente. Ahora está listo para añadir una acción.
Paso nº 3: Añadir el paso de acción Bright Data
Después del disparador, puede añadir un paso de acción en el flujo de trabajo de Pipedream. Lo que quieres ahora es conectar el paso Bright Data al disparador. Para ello, haga clic en el signo “+” debajo del activador y busque “bright data”:
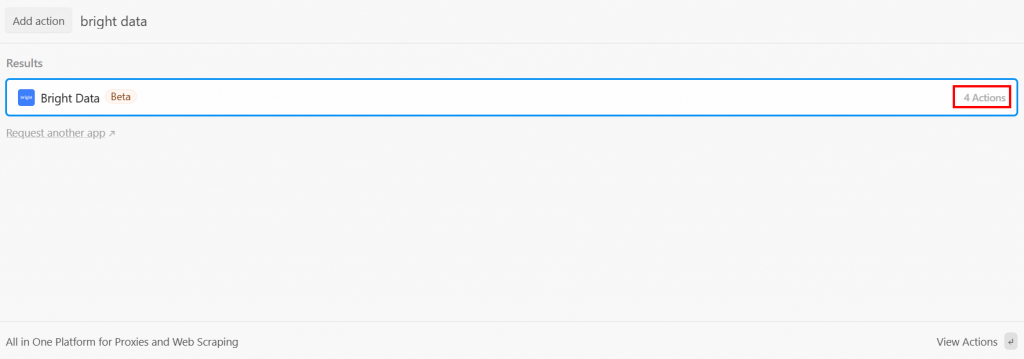
Pipedream le ofrece varias acciones del plugin Bright Data. Selecciónalo para verlas todas:
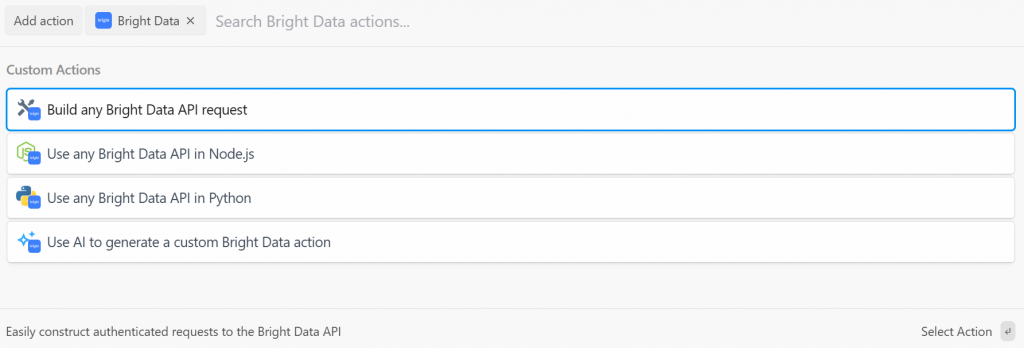
Las opciones que tienes son:
- Creecualquier solicitud de API de Bright Data: Cree solicitudes autenticadas a las API de Bright Data.
- Utilice cualquier API de Bright Data en Node.js/Python: Conecte su cuenta de Bright Data a Pipedream y personalice las solicitudes en Node.js/Python.
- Utilizar AI para generar una acción personalizada de Bright Data: Pida a la IA que genere un código personalizado para Bright Data.
Para este tutorial, seleccione la opción “Utilizar cualquier API de Bright Data en Python”. Esto es lo que verá:
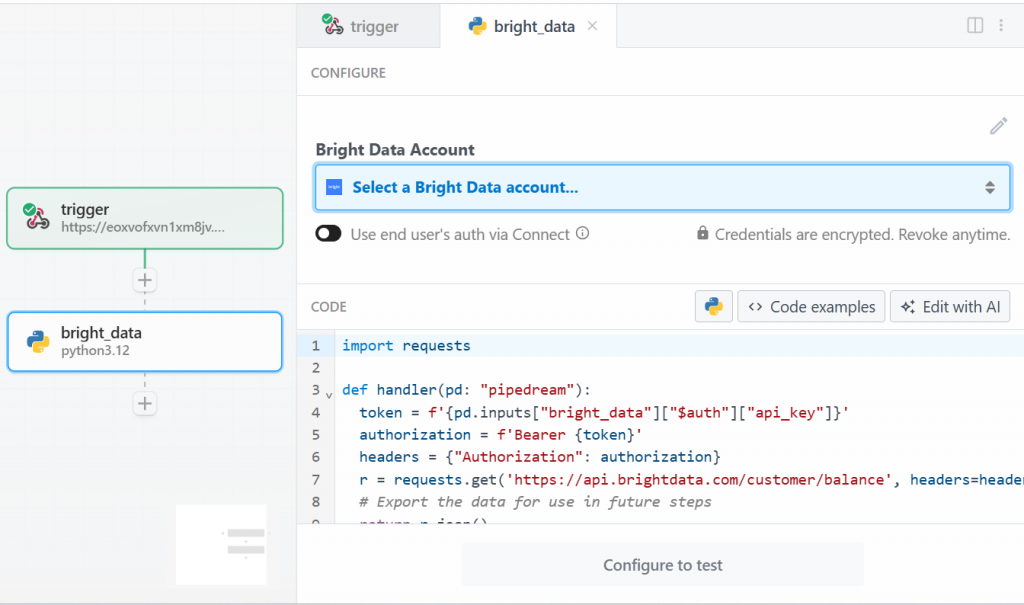
En primer lugar, haga clic en “Seleccionar una cuenta de Bright Data” en “Cuenta de Bright Data” y añada su clave API de Bright Data. Si aún no lo ha hecho, asegúrese de seguir la guía oficial para configurar una clave API de Bright Data.
A continuación, elimine el código de la sección “CÓDIGO” y escriba lo siguiente:
import requests
import json
import time
def handler(pd: "pipedream"):
# Retrieve the Bright Data API key from Pipedream's authenticated accounts
api_key = pd.inputs["bright_data"]["$auth"]["api_key"]
# Get the target Amazon product URL from the trigger data
amazon_product_url = pd.steps["trigger"]["event"]["body"]["url"]
# Configure the Bright Data API request
brightdata_api_endpoint = "https://api.brightdata.com/datasets/v3/trigger"
params = { "dataset_id": "gd_l7q7dkf244hwjntr0", "include_errors": "true" }
payload_data = [{"url": amazon_product_url}]
headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" }
# Initiate the data collection job
print(f"Triggering Bright Data dataset with URL: {amazon_product_url}")
trigger_response = requests.post(brightdata_api_endpoint, headers=headers, params=params, json=payload_data)
# Check if the trigger request was successful
if trigger_response.status_code == 200:
response_json = trigger_response.json()
# Extract the snapshot ID, which is needed to poll for results.
snapshot_id = response_json.get("snapshot_id")
# Handle cases where the trigger is successful but no snapshot ID is provided
if not snapshot_id:
print("Trigger successful, but no snapshot_id was returned.")
return {"error": "Trigger successful, but no snapshot_id was returned.", "response": response_json}
# Begin polling for the completed snapshot using its ID
print(f"Successfully triggered. Snapshot ID is {snapshot_id}. Now starting to poll for results.")
final_scraped_data = poll_and_retrieve_snapshot(api_key, snapshot_id)
# Return the final scraped data from the workflow
return final_scraped_data
else:
# If the trigger failed, log the error and exit the Pipedream workflow
print(f"Failed to trigger. Error: {trigger_response.status_code} - {trigger_response.text}")
pd.flow.exit(f"Error: Failed to trigger Bright Data scrape. Status: {trigger_response.status_code}")
def poll_and_retrieve_snapshot(api_key, snapshot_id, polling_timeout=20):
# Construct the URL for the specific snapshot
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
# Set the authorization header for the API request
headers = { "Authorization": f"Bearer {api_key}" }
print(f"Polling snapshot for ID: {snapshot_id}...")
# Loop until the snapshot is ready
while True:
response = requests.get(snapshot_url, headers=headers)
# If status is 200, the data is ready
if response.status_code == 200:
print("Snapshot is ready. Returning data...")
return response.json()
# If status is 202, the data is not ready yet. Wait and retry
elif response.status_code == 202:
print(f"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
# If any other status code is received, an error occurred.
else:
print(f"Polling failed! Error: {response.status_code}")
print(response.text)
return {"error": "Polling failed", "status_code": response.status_code, "details": response.text}Este código hace lo siguiente:
- La función
handler() gestiona el flujo de trabajo a nivel de Pipedream. Esto:- Recupera la clave API de Bright Data, después de haberla almacenado en Pipedream.
- Configura la solicitud de Bright Data API en el lado de la URL de destino, el ID del conjunto de datos y todos los datos específicos necesarios para ello.
- Gestiona la respuesta. Si algo va mal, verás los errores en los registros de Pipedream.
- La función
poll_and_retrieve_snapshot() sondea la API de datos de Bright para obtener una instantánea hasta que está lista. Cuando está lista, devuelve los datos solicitados. Si algo va mal, gestiona los errores y los muestra en los registros.
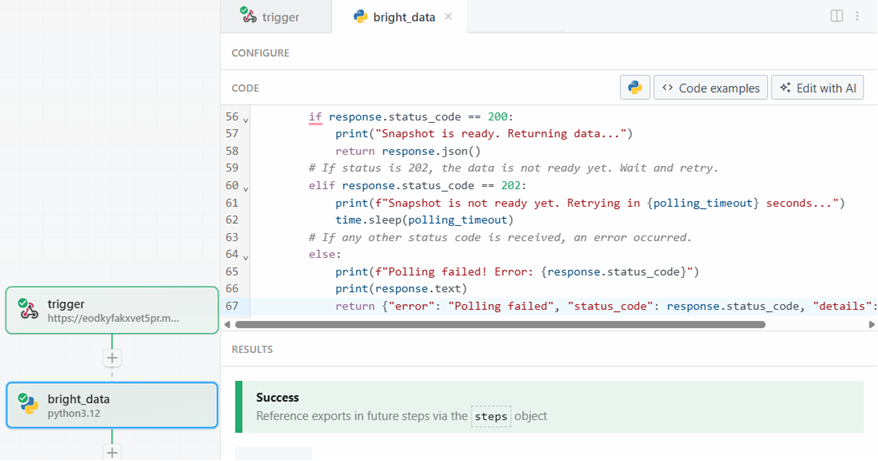
Cuando esté listo, haga clic en el botón “Probar”. Verá un mensaje de éxito en la sección “RESULTADOS”, y el paso de acción Bright Data se coloreará de verde:
En la sección “Exportaciones”, dentro de “RESULTADOS”, puede ver los datos raspados:
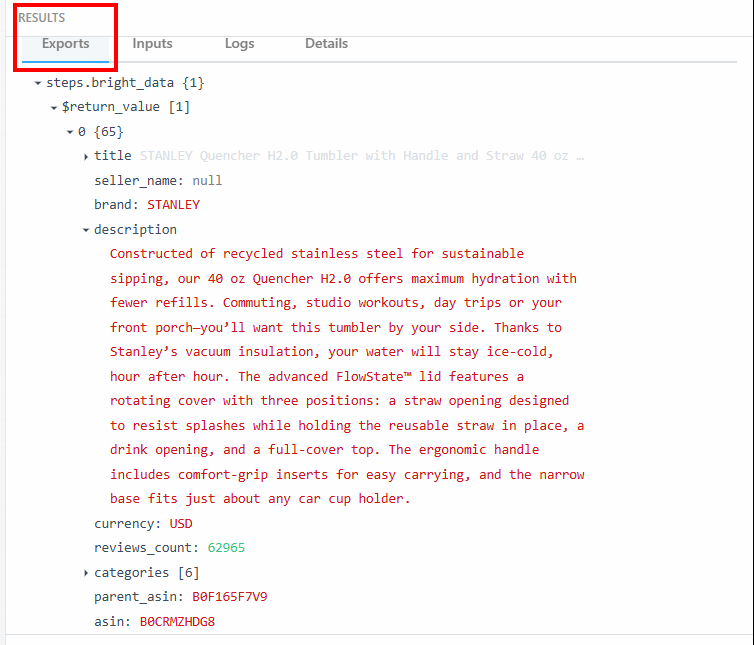
A continuación se muestran los datos en forma de texto:
steps.bright_data{
$return_value{
0{
"title":"STANLEY Quencher H2.0 Tumbler with Handle and Straw 40 oz | Flowstate 3-Position Lid | Cup Holder Compatible for Travel | Insulated Stainless Steel Cup | BPA-Free | Fuchsia",
"seller_name":"null",
"brand":"STANLEY",
"description":"Constructed of recycled stainless steel for sustainable sipping, our 40 oz Quencher H2.0 offers maximum hydration with fewer refills. Commuting, studio workouts, day trips or your front porch—you’ll want this tumbler by your side. Thanks to Stanley’s vacuum insulation, your water will stay ice-cold, hour after hour. The advanced FlowState™ lid features a rotating cover with three positions: a straw opening designed to resist splashes while holding the reusable straw in place, a drink opening, and a full-cover top. The ergonomic handle includes comfort-grip inserts for easy carrying, and the narrow base fits just about any car cup holder.",
"currency":"USD",
"reviews_count":"62965",
..OMITTED FOR BREVITY...
}
}
}Utilizará estos datos y su estructura en el siguiente paso del flujo de trabajo.
¡Genial! Has raspado correctamente los datos de destino gracias a la acción Bright Data en Pipedream.
Paso 4: Añadir el paso de acción OpenAI
Los datos de los productos de Amazon han sido extraídos con éxito por la integración de Beight Data. Ahora, puede introducirlos en un LLM. Para ello, añada una nueva acción haciendo clic en el botón “+” y busque “openai”. Aquí, puedes elegir entre diferentes opciones:

Selecciona la opción “Build any OpenAI (ChatGPT) API request” y, a continuación, selecciona la opción “Chat”:
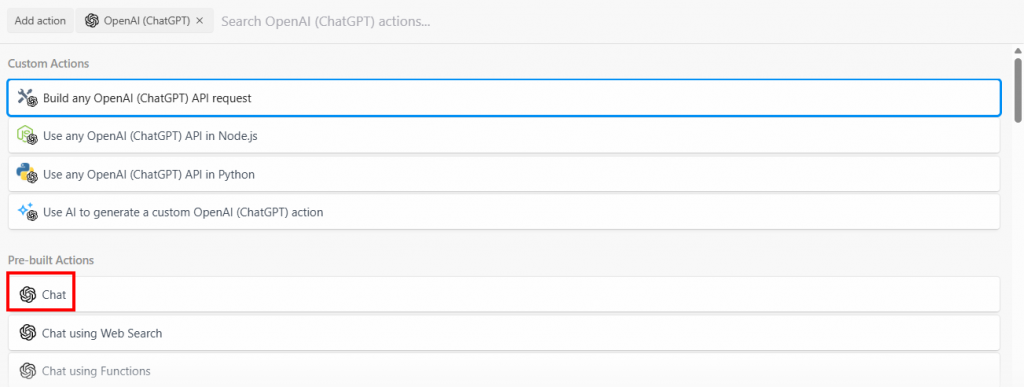
A continuación se muestra la sección de configuración de este paso de acción:
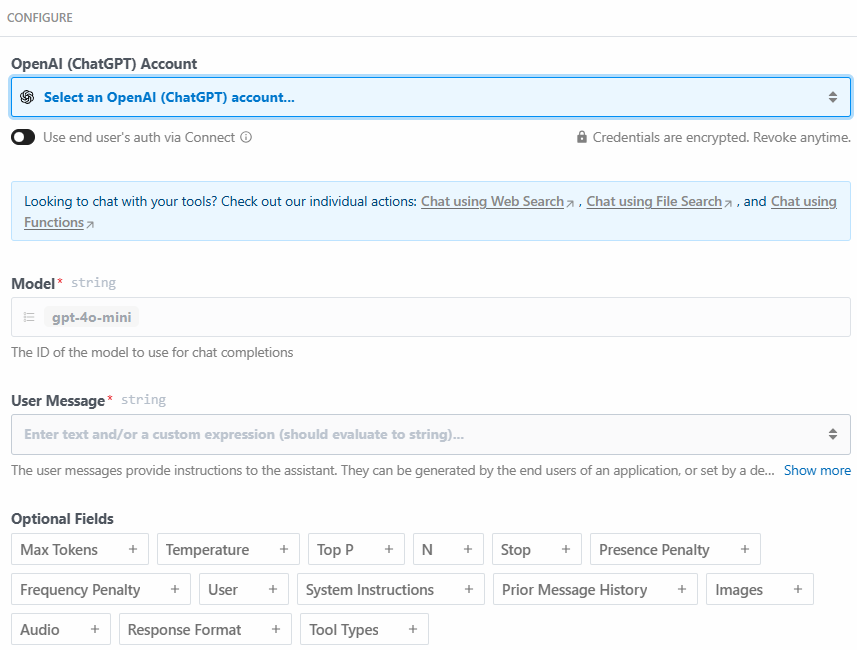
Haz clic en “Seleccionar una cuenta OpenAI (ChatGPT)…” para añadir tu clave API de la plataforma OpenAI. A continuación, escribe el siguiente mensaje en la sección “Mensaje de usuario”:
Act as an expert product analyst. Consider the following data from an Amazon product page:
PRODUCT TITLE:
{{steps.bright_data.$return_value[0].title}}
BRAND:
{{steps.bright_data.$return_value[0].brand}}
DESCRIPTION:
{{steps.bright_data.$return_value[0].description}}
REVIEWS COUNT
{{steps.bright_data.$return_value[0].reviews_count}}
Based on this data, provide a concise summary of the product that should entice potential customers to buy it. The summary should include what the product is, and its most important features.El indicador pide al LLM que:
- Actúa como un analista experto en productos. Esto es importante porque, con esta instrucción, el LLM se comportará como lo haría un analista experto en productos. Esto ayuda a que su respuesta sea específica para el sector.
- Tenga en cuenta los datos extraídos por el paso Bright Data, como el título del producto y la descripción. Esto ayuda al LLM a centrarse en los datos específicos que necesita.
- Proporcione un resumen del producto, basado en los datos raspados. La pregunta también es específica sobre lo que debe contener el resumen. Aquí es donde verás el poder de la IA-automatización para el resumen de productos. El LLM creará un resumen del producto, basado en los datos obtenidos, actuando como un especialista en el producto.
Puede recuperar el título del producto con {{steps.bright_data.$return_value[0].title}} porque, como se especifica en el paso anterior, la estructura de los datos de salida por el paso de acción Bright Data es:
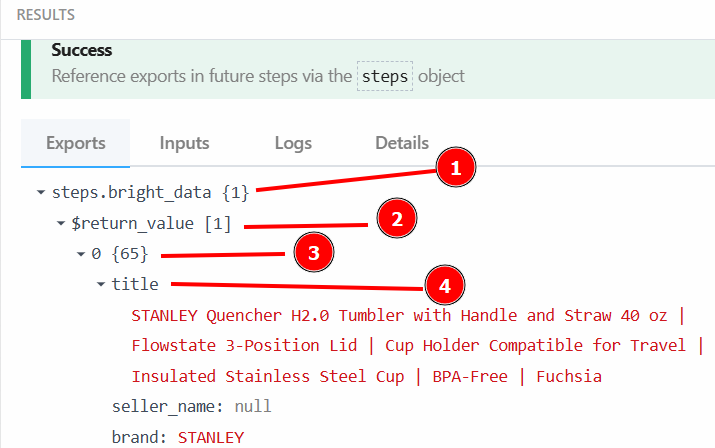
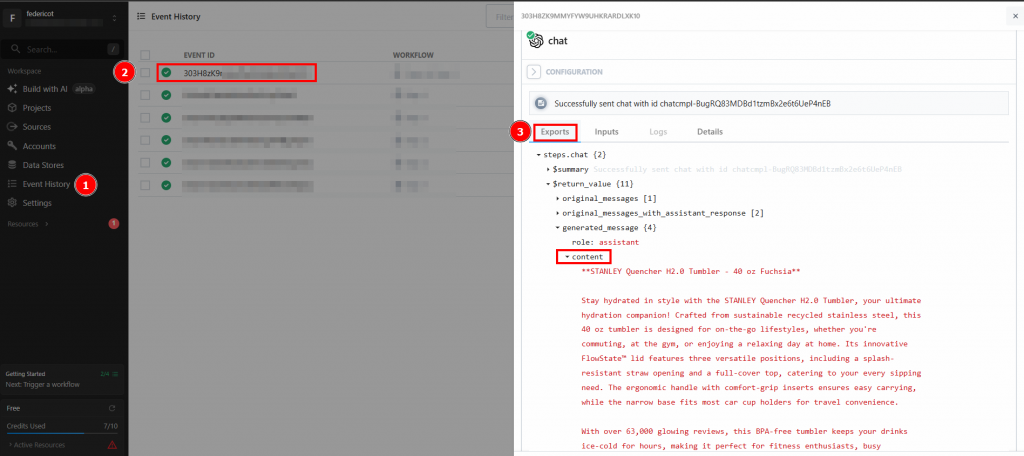
Después de hacer clic en “Probar”, encuentre la salida del LLM en la sección “RESULTADOS” del paso de acción OpenAI Chat en “Mensaje generado” > “contenido”:
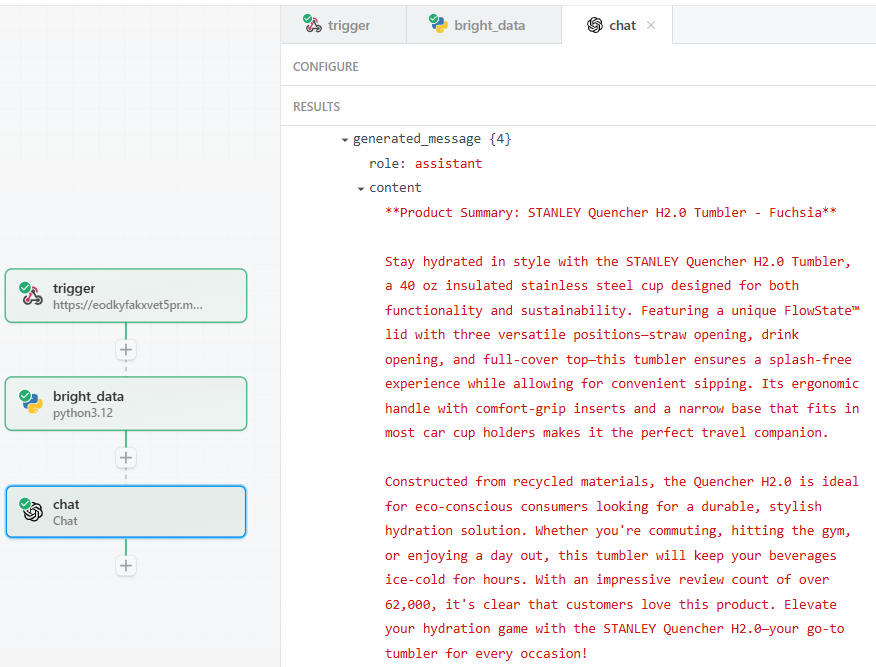
A continuación se muestra un posible resultado textual:
**Product Summary: STANLEY Quencher H2.0 Tumbler - Fuchsia**
Stay hydrated in style with the STANLEY Quencher H2.0 Tumbler, a 40 oz insulated stainless steel cup designed for both functionality and sustainability. Featuring a unique FlowState™ lid with three versatile positions—straw opening, drink opening, and full-cover top—this tumbler ensures a splash-free experience while allowing for convenient sipping. Its ergonomic handle with comfort-grip inserts and a narrow base that fits in most car cup holders makes it the perfect travel companion.
Constructed from recycled materials, the Quencher H2.0 is ideal for eco-conscious consumers looking for a durable, stylish hydration solution. Whether you're commuting, hitting the gym, or enjoying a day out, this tumbler will keep your beverages ice-cold for hours. With an impressive review count of over 62,000, it's clear that customers love this product. Elevate your hydration game with the STANLEY Quencher H2.0—your go-to tumbler for every occasion!Como puede ver, el LLM proporcionó el resumen del producto, actuando como especialista en el mismo. El resumen informa exactamente de lo que pide la solicitud:
- Qué es el producto.
- Algunas de sus características importantes.
La razón por la que quieres extraer datos exactos -como el recuento de valoraciones- es para estar seguro de que el LLM no está alucinando. El resumen dice que las valoraciones superan las 62’000. Si quieres ver el número exacto, puedes verificarlo en el campo “contenido” de los resultados:
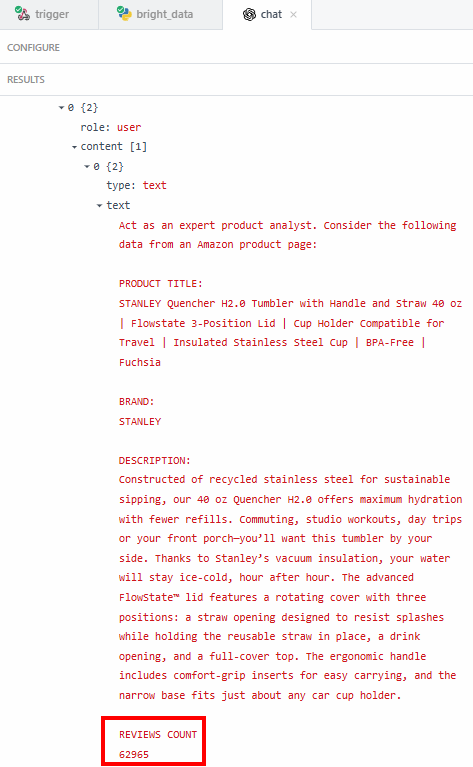
A continuación, tienes que comprobar si ese número coincide con el que aparece en la página de producto de Amazon.
Por último, si alguna vez has intentado hacer scraping en grandes sitios de comercio electrónico como Amazon, sabrás lo difícil que es hacerlo por tu cuenta. Por ejemplo, es posible que te encuentres con el famoso CAPTCHA de Amazon, que puede bloquear la mayoría de los scrapers:
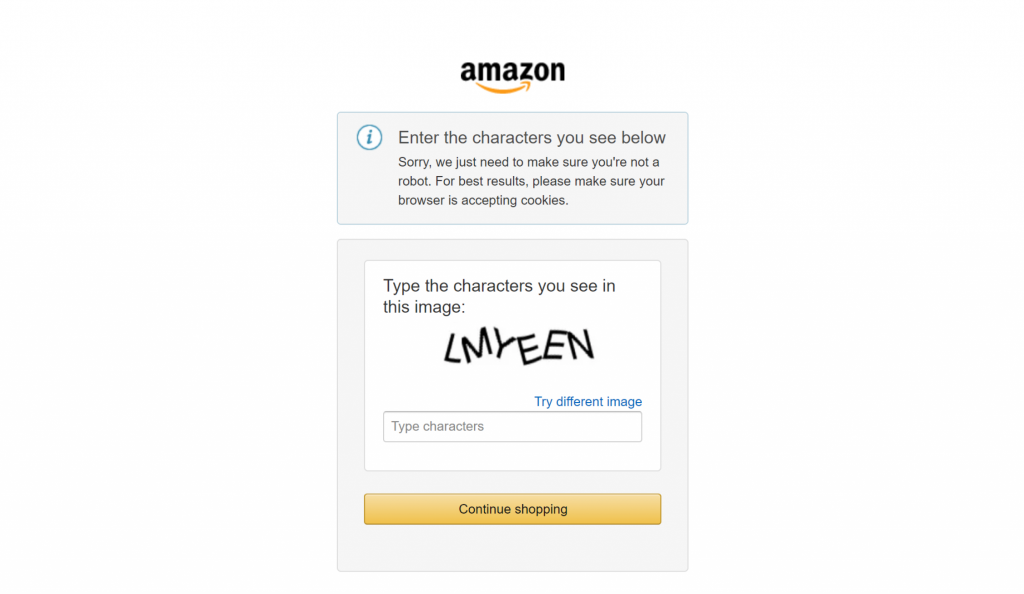
Aquí es donde la integración de Bright Data marca la diferencia en sus flujos de trabajo de scraping. Gestiona todas las medidas anti-scraping entre bastidores y se asegura de que el proceso de recuperación de datos funcione sin problemas.
Estupendo. Ha probado con éxito el paso LLM. Ahora está listo para desplegar el flujo de trabajo.
Paso 5: Despliegue del flujo de trabajo
Para desplegar su flujo de trabajo, haga clic en uno de los botones “Desplegar”:
A continuación se muestra lo que verá después del despliegue:
Para ejecutar todo el flujo de trabajo, haga clic en “Generar evento”:
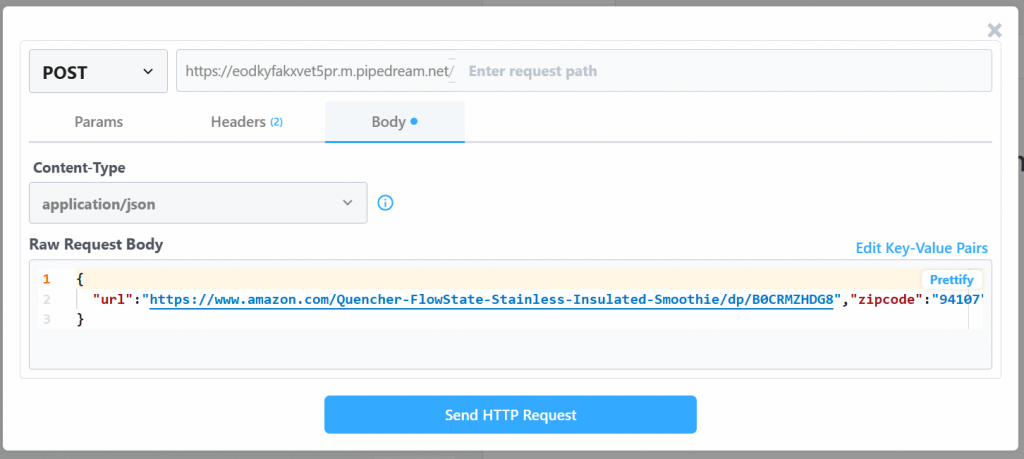
Haga clic en “Enviar solicitud HTTP” para activar el flujo de trabajo, y éste se ejecutará por completo. Para ver los resultados de los flujos de trabajo desplegados, vaya a “Historial de eventos” en la página de inicio. Seleccione el flujo de trabajo de su interés y vea los resultados en “Exportaciones”:
¡Et voilà! Ha creado y desplegado su primer flujo de trabajo de scraping en Pipedream utilizando Bright Data.
Conclusión
En esta guía, ha aprendido a crear un flujo de trabajo de raspado web automatizado utilizando Pipedream. Ha visto de primera mano cómo la interfaz intuitiva de la plataforma, combinada con la integración de scraping de Bright Data, facilita la creación de sofisticados pipelines de scraping en cuestión de minutos.
El principal reto de cualquier automatización basada en datos es garantizar un flujo constante de datos limpios y fiables. Pipedream proporciona el motor de automatización y programación, mientras que la infraestructura de IA de Bright Data se encarga de las complejidades del web scraping y proporciona datos listos para usar. Esta sinergia le permite centrarse en la creación de valor a partir de los datos, en lugar de en los obstáculos técnicos de su adquisición.
Cree una cuenta gratuita en Bright Data y empiece hoy mismo a experimentar con nuestras herramientas de datos preparadas para la IA.






