
En esta entrada del blog, verás:
- Qué es la escucha social y por qué es valiosa.
- Por qué la IA agentiva es el mejor enfoque para llevarla a cabo.
- Los principales obstáculos para utilizar la IA en la escucha en redes sociales, especialmente a través de agentes.
- Cómo superarlos con herramientas de scraping de redes sociales específicas y preparadas para agentes.
- Una guía paso a paso para crear un flujo de trabajo de escucha social con agentes en LangChain, impulsado por las herramientas de scraping de redes sociales de Bright Data.
- Lo que necesitas para convertir este ejemplo en un flujo de trabajo agentico listo para producción.
- Ejemplos de flujos de trabajo agenticos reales para la escucha en redes sociales.
¡Empecemos!
Escucha social: qué es, cómo funciona y ejemplos
La escucha social es el proceso de monitorizar y analizar conversaciones digitales para comprender lo que la gente dice sobre una marca, un producto, un anuncio, un sector o un tema específico.
Va más allá del simple seguimiento de menciones. La escucha social ayuda a descubrir tendencias, medir el sentimiento y comprender cómo se siente realmente el público externo. Su objetivo final es generar insights que sirvan de base para el marketing, las decisiones de producto y la atención al cliente.
A grandes rasgos, la escucha social suele seguir un proceso de dos pasos:
- Monitorización: Seguimiento de las plataformas de redes sociales en busca de menciones, comentarios y conversaciones relacionadas con un tema objetivo (por ejemplo, la competencia, tu marca, palabras clave relevantes, etc.).
- Análisis: Interpretar esos datos para comprender lo que está sucediendo, identificar patrones y tomar medidas para mejorar los resultados u obtener información más detallada.
Por ejemplo, una empresa podría estudiar debates sin filtrar en Reddit, en comunidades especializadas, para descubrir puntos débiles o solicitudes de nuevas funciones. Del mismo modo, una marca puede analizar los comentarios y hashtags de Instagram para evaluar el compromiso y la percepción de la marca.
Por qué un flujo de trabajo de IA agentiva es ideal para la escucha social
Los flujos de trabajo tradicionales de escucha social suelen ser estáticos, basados en una serie de componentes que alimentan los datos desde la entrada hasta la salida en un proceso fijo.
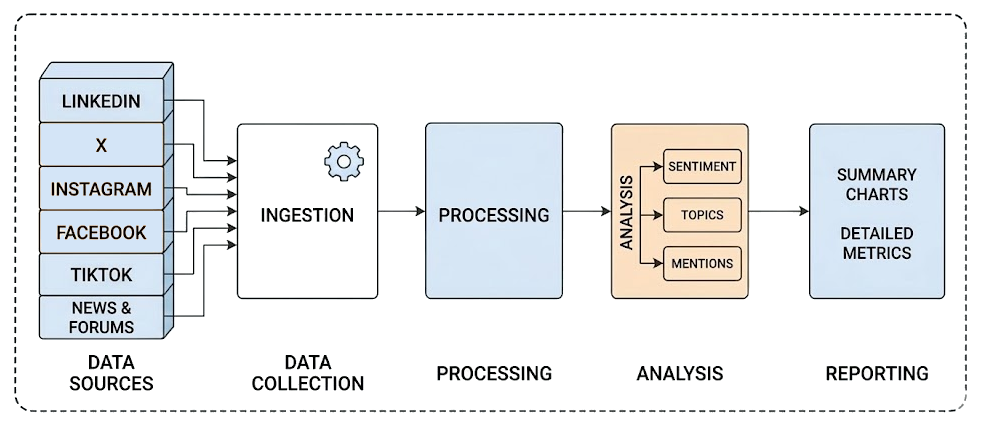
Ese enfoque funciona bien para muchos procesos de análisis de datos, pero tiene dificultades con los datos de las redes sociales. La razón es que interpretar el contexto y adaptarse continuamente a nuevas conversaciones es extremadamente complicado. ¡Aquí es donde la IA, especialmente a través de flujos de trabajo agenticos, encaja a la perfección!
Un flujo de trabajo de escucha social basado en agentes transforma ese flujo de datos pasivo en un motor de inteligencia activo. Al fin y al cabo, a diferencia de los flujos estáticos, los agentes de IA pueden actuar de forma autónoma.
Por ejemplo, si un agente detecta un pico inusual en el sentimiento en Reddit, puede investigar de forma proactiva los hilos relacionados en X o Threads para encontrar la causa raíz. Además, puede llevar a cabo una investigación más profunda en el propio Reddit (o, potencialmente, incluso en Google) para comprender qué está sucediendo.
En concreto, las principales ventajas de un flujo de trabajo de escucha social basado en agentes son:
- Análisis profundo de la opinión: más allá de limitarse a asignar etiquetas de «positivo/neutral/negativo», la IA entiende el sarcasmo y el contexto cultural. Esto proporciona una visión de alta fidelidad de los datos de entrada, especialmente en lo que respecta a la opinión y la interacción.
- Investigación autónoma: los agentes pueden buscar de forma proactiva tendencias emergentes o profundizar en conversaciones en curso sin necesidad de una intervención manual constante.
- Integración multiplataforma: los flujos de trabajo basados en agentes pueden monitorizar múltiples redes simultáneamente, agregando información en una única vista procesable.
Al pasar de los flujos de trabajo fijos al razonamiento agentico, puedes empezar a escuchar de verdad las redes sociales. Este cambio da lugar a un sistema dinámico que evoluciona tan rápido como la propia conversación, sin necesidad de modificar los elementos del flujo de trabajo.
Retos de la escucha en redes sociales con IA
No hay duda de que la IA ha facilitado considerablemente la escucha social, especialmente a la hora de comprender el «porqué». Los modelos avanzados de IA/ML pueden analizar el sentimiento, predecir posibles tendencias e incluso interpretar matices. Sin embargo, sigue existiendo un gran reto: ¿cómo recopilar datos de redes sociales de forma fiable y a gran escala?
La idea principal es conectar el flujo de trabajo de su agente directamente a las API de las plataformas sociales (si están disponibles). Sin embargo, las API oficiales pueden ser caras, estar sujetas a límites de velocidad y pueden incluir restricciones sobre cómo se pueden procesar los datos recuperados. Además, las respuestas de las API pueden cambiar con el tiempo o ser incompletas. Por estas razones, las API a menudo no son una opción práctica, y muchos equipos recurren en su lugar al Scraping web.
Aun así, el scraping de redes sociales es intrínsecamente difícil por varias razones:
- Complejidad y cambios de las plataformas: los sitios web de redes sociales evolucionan constantemente, con patrones interactivos y de navegación complejos y muy dinámicos. Esto convierte el parseo de datos en una tarea difícil.
- Medidas anti-bot: los CAPTCHAs, las verificaciones humanas y los límites de velocidad requieren estrategias sofisticadas para la rotación de IP, la gestión de huellas digitales y mucho más.
- Fragmentación de los datos: los datos se encuentran dispersos en múltiples plataformas (X, Instagram, Threads, TikTok, Reddit, LinkedIn, YouTube, Facebook, etc.), lo que dificulta la creación de un conjunto de datos unificado de redes sociales.
Incluso cuando se tiene acceso a herramientas fiables de scraping de redes sociales, siguen existiendo dos obstáculos adicionales:
- Compatibilidad de las herramientas: la herramienta de scraping debe ser compatible con la biblioteca de IA o el flujo de trabajo de agente que planees utilizar.
- Usabilidad de los datos: Los datos extraídos deben estar estructurados, limpios y entregados en un formato que la IA pueda comprender fácilmente. Los retrasos, el formato inconsistente o los campos de datos que faltan pueden reducir la eficacia de los flujos de trabajo agenticos y aumentar el riesgo de alucinaciones. Descubre los mejores formatos de datos para la IA agentica.
Así pues, aunque la IA transforma la escucha social, el verdadero cuello de botella reside en la adquisición de datos.
Herramientas preparadas para la IA para una escucha social agentiva sólida y escalable
Sabes que permitir que los agentes de IA accedan a datos fiables de las redes sociales es el principal obstáculo en los flujos de trabajo de escucha social agentiva. Por lo tanto, la solución es clara: los agentes necesitan acceso a herramientas fiables y preparadas para la empresa para el rastreo de redes sociales.
Cuando los agentes de IA las invocan de forma autónoma, estas herramientas obtienen datos optimizados para la IA de plataformas de redes sociales seleccionadas. Los datos obtenidos constituyen la base para que la IA analice, razone y extraiga conclusiones. El reto es encontrar buenas herramientas, ya que sin ellas te enfrentarás a los típicos problemas de fiabilidad y escalabilidad asociados al Scraping web.
Por lo tanto, las herramientas de scraping de redes sociales preparadas para agentes deben:
- Ser muy sólidas, con altas tasas de éxito y un tiempo de inactividad mínimo.
- Admitir solicitudes simultáneas para gestionar grandes volúmenes de datos.
- Devolver el contenido en formatos ideales para la ingesta de LLM, como JSON o Markdown.
- Integrarse a la perfección con la biblioteca de agentes de IA elegida, ya sea LangChain, LlamaIndex, CrawlAI, Agno, Dify o marcos similares.
- Gestionar medidas anti-bot, incluyendo límites de velocidad, rotación de IP, CAPTCHAs y otras protecciones.
- Ser compatible con múltiples plataformas de redes sociales.
Esto es precisamente lo que ofrece Bright Data a través de su servicio Social Media Scraper. ¡Veámoslo con más detalle!
Herramientas de scraping de redes sociales preparadas para IA de Bright Data
Bright Data es la plataforma líder en recopilación de datos web y ocupa el primer puesto entre los principales proveedores de datos de redes sociales. Entre sus soluciones de scraping preparadas para IA, Social Media Scraper destaca por sus flujos de trabajo basados en agentes:
- Alcanza una fiabilidad del 99,99 % y una tasa de éxito del 99,95 %, lo que garantiza un flujo continuo de datos para los agentes de IA con un tiempo de inactividad mínimo.
- Diseñado para escalar, admite una alta concurrencia gracias a una red de Proxies de 150 millones de direcciones IP en 195 países.
- Permite el scraping masivo de hasta 5000 páginas de redes sociales simultáneamente, lo que permite a los agentes gestionar grandes cantidades de datos.
- Devuelve formatos estructurados y preparados para LLM, como JSON y Markdown, optimizados para una rápida ingesta, razonamiento y procesamiento de IA posterior.
- Ofrece integraciones oficiales con más de 70 marcos y soluciones de IA, además de API nativas para implementaciones personalizadas.
- Gestiona automáticamente los retos relacionados con la protección contra bots y el scraping.
- Es compatible con las principales plataformas, como Facebook, Instagram, LinkedIn, TikTok, X, Pinterest, Quora, YouTube, Threads, Reddit, Vimeo y muchas más.
- El modelo de pago por éxito garantiza la rentabilidad, lo que hace que la recopilación de datos a gran escala impulsada por IA sea predecible y económica.
Nota: Esta solución también está disponible de forma nativa a través del servidor Web MCP de Bright Data, lo que permite una integración simplificada en flujos de trabajo de agentes.
Cómo crear un agente de escucha social con el respaldo de Bright Data
En esta sección guiada, verás cómo empezar con un agente de escucha social sencillo. Este se creará en LangChain y se conectará a Gemini, pero cualquier otro marco de agentes de IA y proveedor de LLM funcionará.
Nota: Si desea instrucciones prácticas sobre cómo utilizar las soluciones de Bright Data para crear una aplicación basada en IA para la escucha social, consulte el seminario web«Creación de una aplicación de escucha social basada en IA».
¡Sigue los pasos que se indican a continuación!
Requisitos previos
Para seguir este tutorial, asegúrate de tener:
- Python 3.10 instalado localmente.
- Una cuenta de Bright Data con una clave API lista.
- Una clave API de Gemini (o una clave API de cualquier otro proveedor de LLM compatible con LangChain).
- Conocimientos básicos sobre el funcionamiento de los agentes de LangChain.
Echa un vistazo a la guía oficial para configurar tu clave API de Bright Data. Guárdala en un lugar seguro, ya que la necesitarás para conectar tu agente de LangChain a Bright Data utilizando las herramientas oficiales de LangChain–Bright Data.
Para obtener más información sobre la integración de Bright Data con LangChain, consulta las siguientes entradas del blog:
Paso n.º 1: Configura tu proyecto de LangChain
Crea un nuevo proyecto de Python para tu agente de escucha social:
mkdir agentic-social-listening
cd agentic-social-listeningEn la carpeta del proyecto, crea un entorno virtual y actívalo:
python -m venv .venv
source .venv/bin/activate # o en Windows: .venvScriptsactivateAñade un archivo agent.py, que contendrá la lógica de tu agente de escucha social. La estructura de tu proyecto debería tener este aspecto:
agentic-social-listening/
├── .venv/
└── agent.pyEn el entorno virtual activado, instala las bibliotecas necesarias:
pip install langchain langchain-google-genai langchain-brightdataEstas son:
langchain: simplifica la creación de agentes de IA.langchain-google-genai: conecta tu agente a Gemini a través de la integraciónChatGoogleGenerativeAI.langchain-brightdata: conecta tu agente LangChain a las soluciones de scraping de Bright Data a través de la integración oficial, tal y como se explica en la documentación.
¡Genial! Carga la carpeta del proyecto en tu IDE de Python favorito y prepárate para desarrollar un flujo de trabajo de escucha social con agentes.
Paso n.º 2: Define el flujo de trabajo del agente
Supongamos que quieres crear un agente de escucha social que supervise el sentimiento y las menciones en dos publicaciones (una en Instagram y otra en TikTok) para el mismo anuncio. Aunque las publicaciones difieren, el anuncio subyacente es idéntico.
Este es un ejemplo interesante porque muestra cómo un agente puede rastrear la interacción en múltiples plataformas para una sola campaña, identificar el sentimiento superpuesto y específico de cada plataforma, y detectar menciones de productos o solicitudes promocionales.
En este caso, utilizaremos un anuncio de Nike. Así es como aparece en Instagram: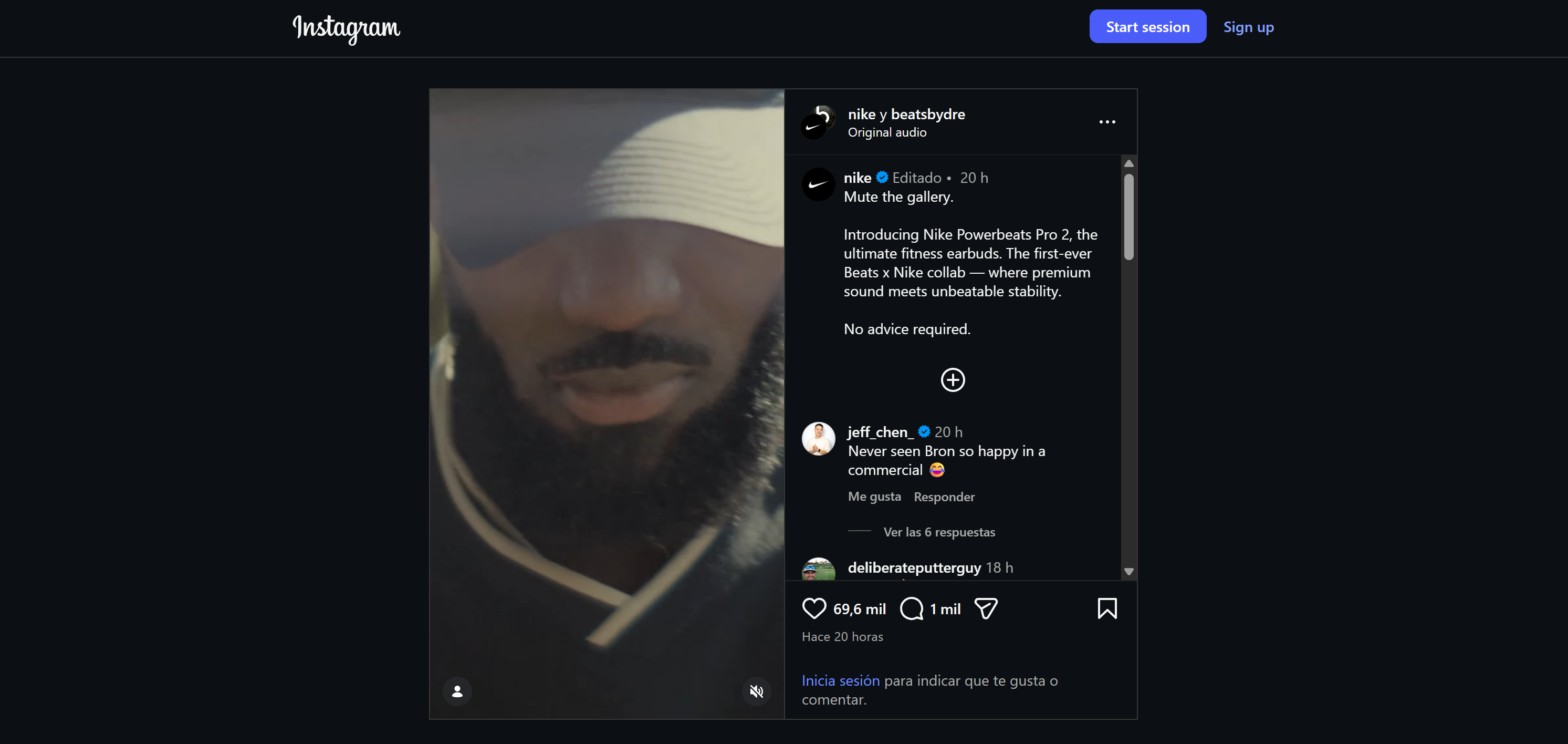
Y así es como aparece en TikTok: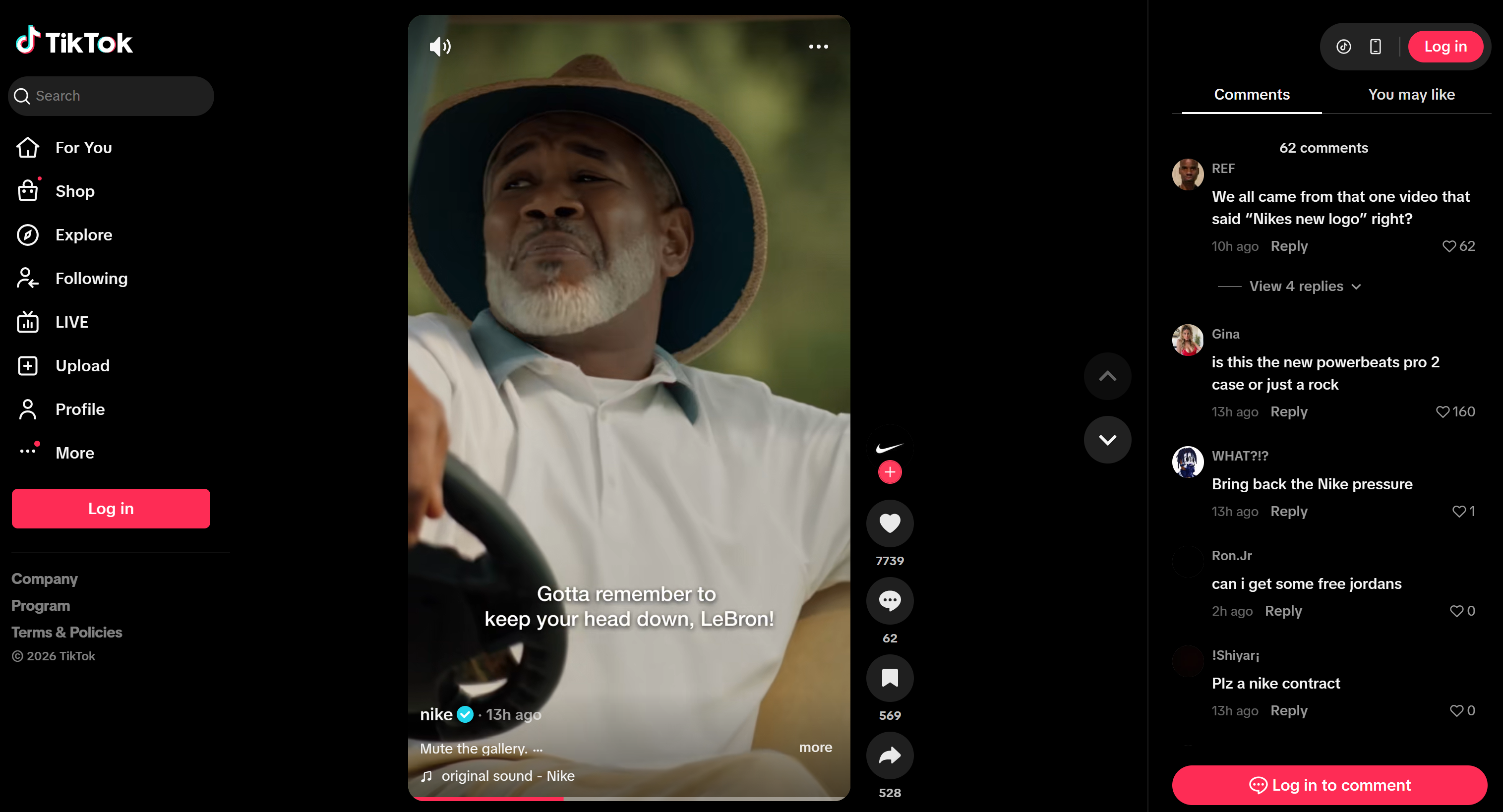
La idea es dejar que el agente de IA utilice la API Social Media Scraper de Bright Data para recopilar comentarios de ambas publicaciones. A continuación, analizará y procesará esos datos a través de su cerebro LLM impulsado por Gemini. Esto completa un flujo de trabajo básico de escucha social con agentes.
Nota: Esto es solo un ejemplo, suponiendo que ya dispones de las publicaciones en redes sociales de interés. En un escenario listo para producción, las herramientas de Bright Data se pueden utilizar para buscar en la web, realizar un seguimiento de cuentas completas de redes sociales y gestionar la escucha social multiplataforma a gran escala.
¡Todo listo! Es hora de desarrollar el agente.
Paso n.º 3: Implementar el agente
Para crear el agente de escucha social presentado anteriormente, añade las siguientes líneas de código a agent.py:
# pip install langchain langchain-google-genai langchain-brightdata
from langchain_brightdata import BrightDataWebScraperAPI
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain.agents import create_agent
# Sustituye por tus claves API reales
GOOGLE_API_KEY = "<TU_CLAVE_API_DE_GOOGLE>"
BRIGHT_DATA_API_KEY = "<SU_CLAVE_API_DE_BRIGHT_DATA>"
# Inicialice el motor LLM
llm = ChatGoogleGenerativeAI(
model="gemini-3-flash-preview",
google_api_key=GOOGLE_API_KEY
)
# Inicializar la herramienta API Bright Data Web Scraper
web_scraper_api_tool = BrightDataWebScraperAPI(
bright_data_api_key=BRIGHT_DATA_API_KEY
)
# Crear un agente ReAct con acceso a las API de Bright Data Scraping web
agent = create_agent(llm, [web_scraper_api_tool])
# Definir una consulta sencilla de escucha social
prompt = """
Eres un experto en escucha social.
Objetivos:
- Instagram Reel: "https://www.instagram.com/nike/reel/DV_PTxKDueO/"
- Vídeo de TikTok: "https://www.tiktok.com/@nike/video/7618336096694406414"
Tarea:
1. Utiliza la API Social Media Scraper de Bright Data para recopilar todos los comentarios de las publicaciones objetivo.
2. Genera un informe en Markdown que resuma la interacción y el sentimiento.
3. Resalta los comentarios que mencionen otros productos de Nike, promociones o solicitudes interesantes de los usuarios para su análisis posterior.
"""
# Transmite la salida paso a paso del agente
for step in agent.stream(
{
"messages": prompt
},
stream_mode="values",
):
step["messages"][-1].pretty_print()Esto es lo que hace el código:
- Lee las credenciales para acceder a las API de Gemini y Bright Data (en producción, léelas de los entornos).
- Crea un motor de IA impulsado por Gemini para procesar y analizar datos de redes sociales.
- Conecta el agente a las API de scraping de Bright Data (incluida la API Social Media Scraper) a través de la herramienta LangChain
BrightDataWebScraperAPI. - Utiliza la función
create_agent()para definir un agente ReAct que pueda llamar a las herramientas de scraping de Bright Data de forma dinámica. - Indica al agente los objetivos (publicaciones de Instagram y TikTok) y las tareas (recopilación de comentarios, análisis de sentimiento, generación de informes y marcado de menciones clave).
- Inicia el agente y transmite el resultado al terminal.
¡Misión cumplida! Ya has implementado un flujo de trabajo sencillo con agentes para la escucha social.
Paso n.º 4: Probar el agente
Ejecuta el agente con:
python agent.pyVerás que el agente ejecuta la herramienta bright_data_web_scraper (tal y como se esperaba):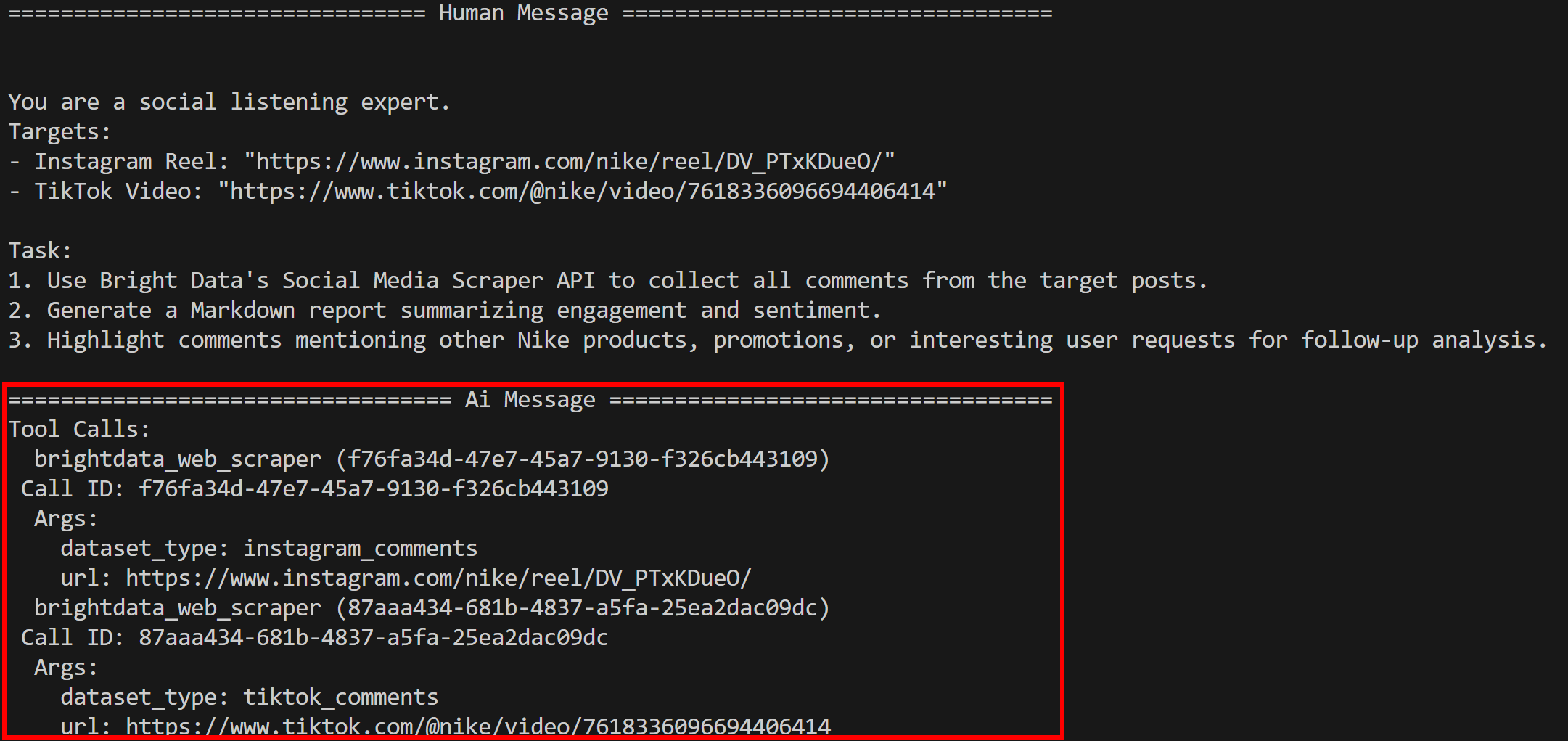
En concreto, llama a las herramientas subyacentes instagram_comments y tiktok_comments. En realidad, estas se basan en el Scraper de comentarios de Instagram y el Scraper de comentarios de TikTok de Bright Data.
Los resultados de las herramientas se devuelven en formato JSON, conteniendo todos los comentarios extraídos de las dos publicaciones: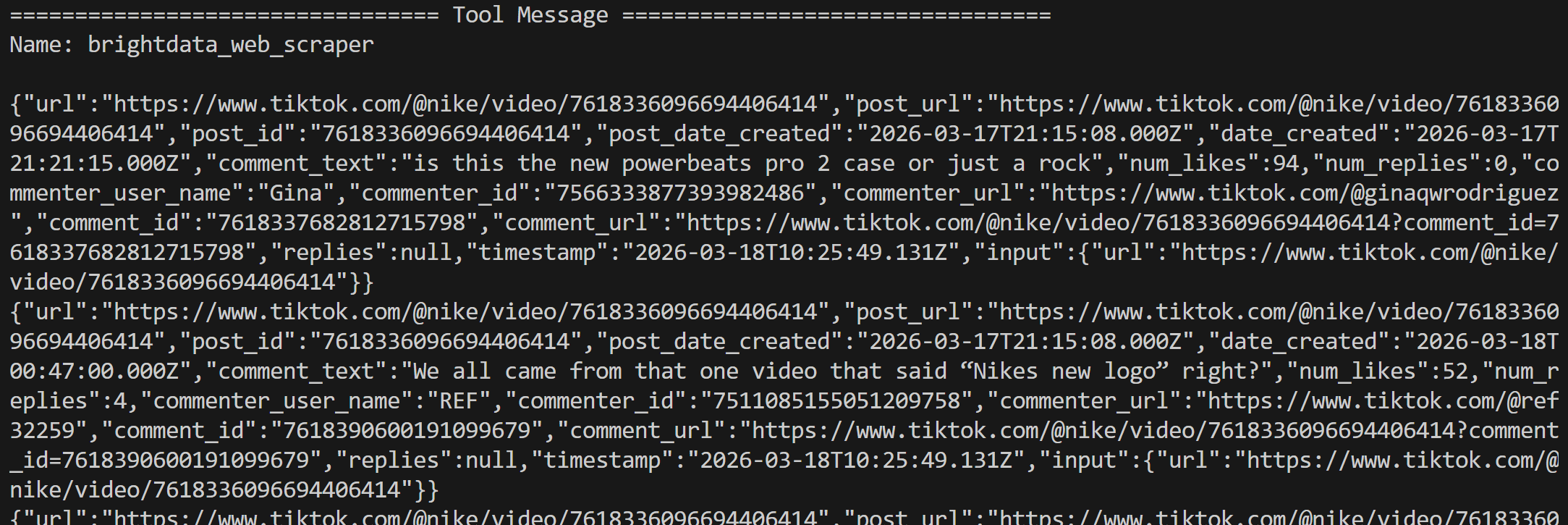
A continuación, el agente procesa los comentarios para el análisis de redes sociales según las instrucciones y genera un informe en Markdown: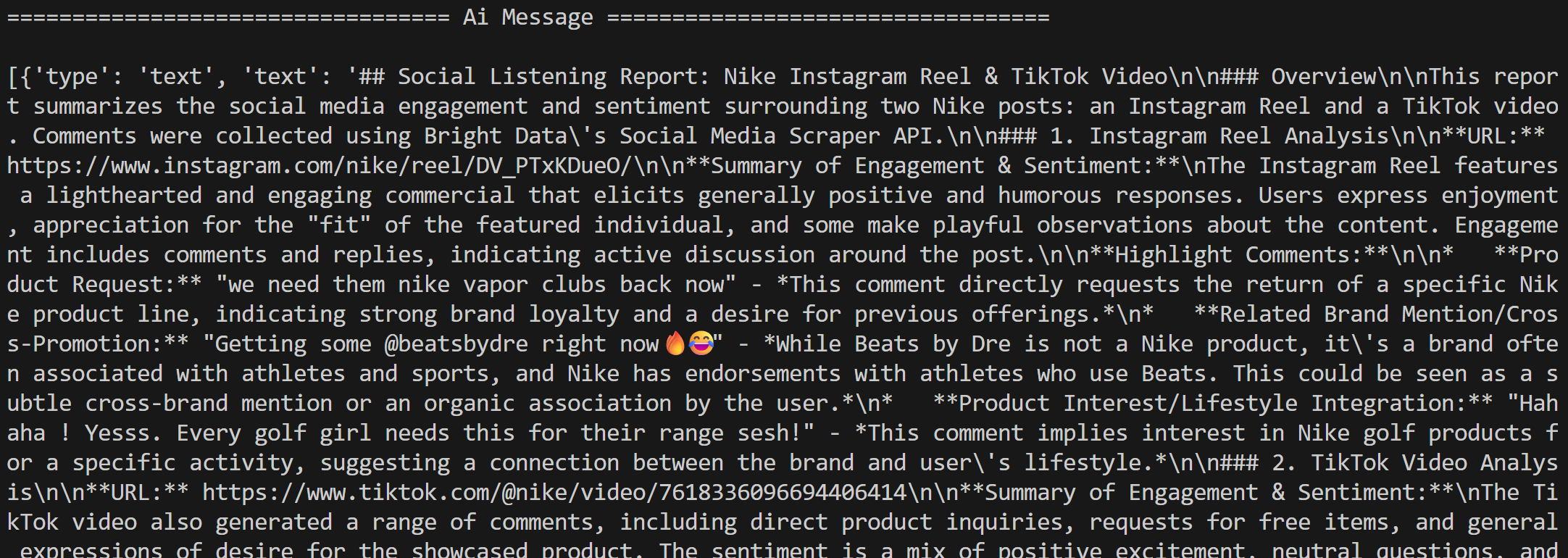
Cuando se visualiza en un renderizador Markdown, el informe tiene este aspecto: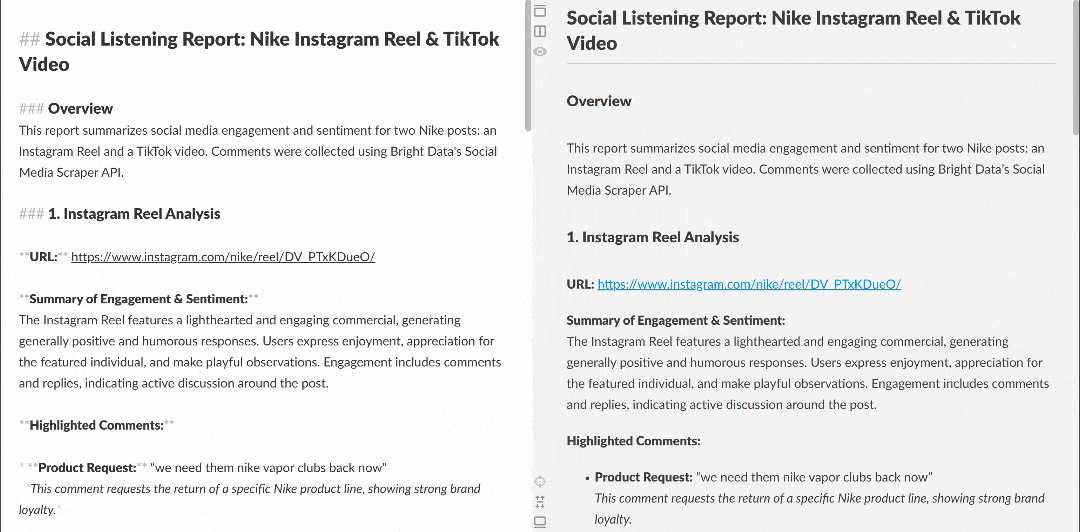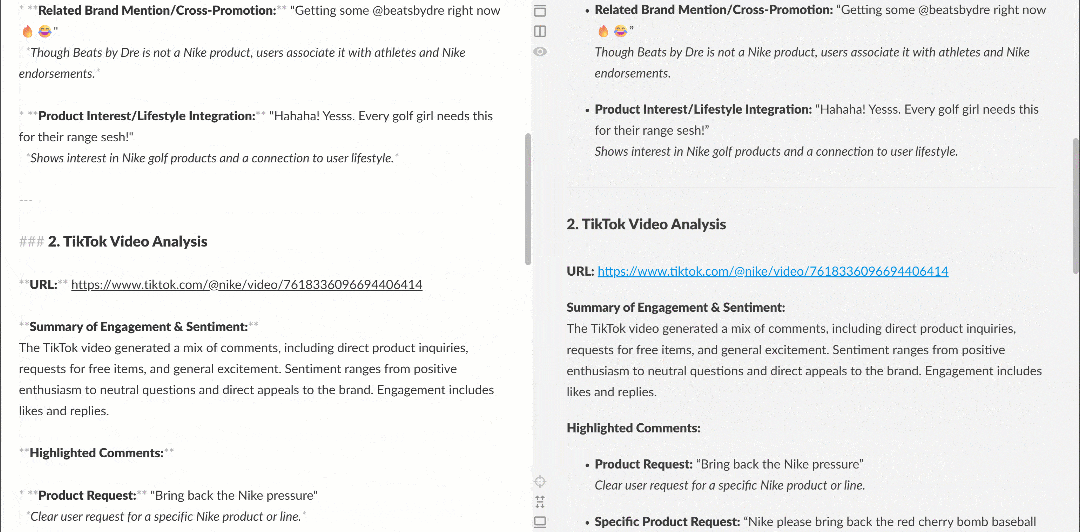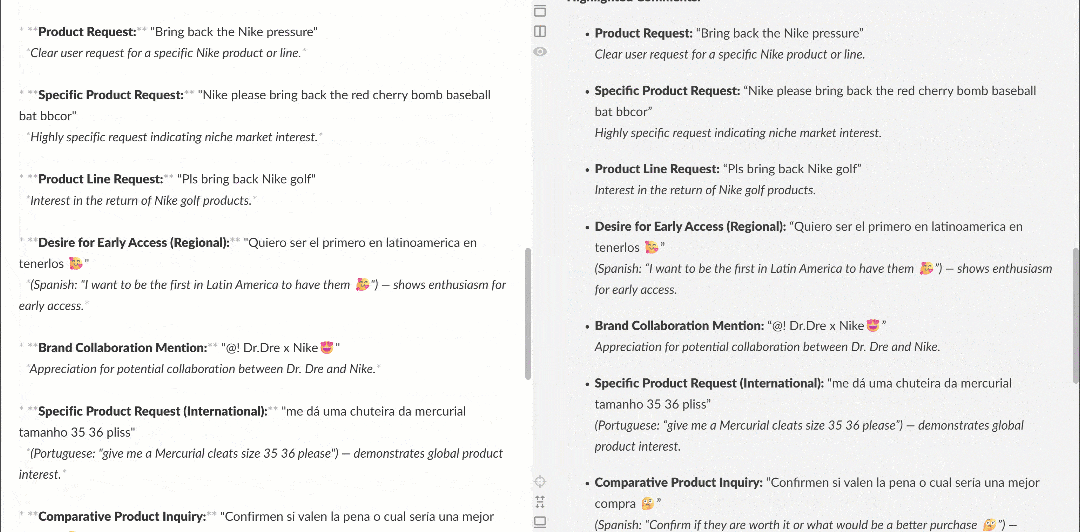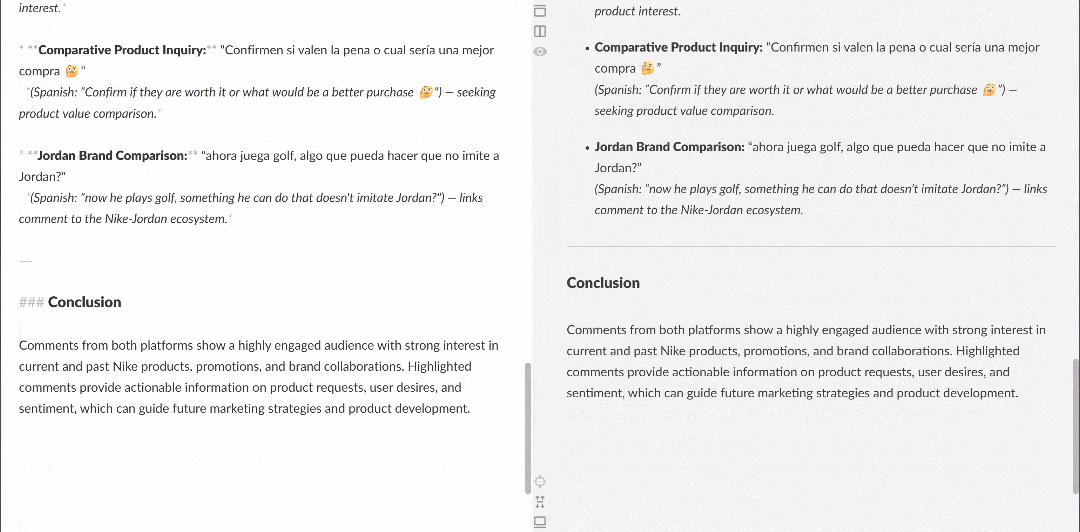
Obsérvese cómo contiene información interesante, como que varios usuarios piden a Nike que recupere Nike Golf o que se centre más en los productos de golf. Estos son detalles que un flujo de trabajo básico de análisis de sentimiento podría haber pasado por alto.
Además, si se produce un error, o si el agente determina que los datos recuperados son insuficientes para cumplir el objetivo, obtendrá automáticamente comentarios adicionales o repetirá las llamadas a las herramientas de Bright Data. Esto hace que el agente sea totalmente autónomo.
¡Et voilà! Acabas de aprender a crear un flujo de trabajo de escucha en redes sociales basado en Bright Data en LangChain.
Flujos de trabajo basados en agentes listos para producción para la escucha en redes sociales
El capítulo anterior mostró cómo crear un agente de escucha social sencillo. Sin embargo, un flujo de trabajo con agentes listo para producción es mucho más complejo. ¡Veamos cómo diseñarlo y los pasos para implementarlo!
Arquitectura
En los flujos de trabajo de escucha social con agentes, confiar en múltiples agentes de IA especializados suele producir mejores resultados que utilizar un único agente monolítico. Cada agente debe centrarse en una responsabilidad distinta, y una posible configuración con agentes es:
- Agente de recuperación de datos: recopila publicaciones, comentarios, perfiles o métricas de interacción de múltiples plataformas de redes sociales a través de herramientas como Social Media Scraper de Bright Data.
- Agente de análisis: procesa los datos recopilados para extraer tendencias, opiniones y otros insights procesables, transformando el contenido social sin procesar en inteligencia significativa.
- Agente de informes/salida: formatea los datos analizados en paneles de control, resúmenes o archivos (JSON, CSV) para facilitar su uso por parte de personas u otros sistemas de IA.
- Agente de coordinación: supervisa el flujo de trabajo, garantizando traspasos fluidos, evaluando la calidad de los resultados e iterando los procesos automáticamente cuando se necesitan mejoras o una recopilación de datos adicional.
Hoja de ruta
Teniendo en cuenta los cuatro agentes, implemente un flujo de trabajo basado en agentes para la escucha social de la siguiente manera:
- Elige la pila de agentes de IA: Selecciona en función de los tipos de agentes necesarios, las integraciones de herramientas y la facilidad de orquestación del flujo de trabajo.
- Añada los agentes: cree cuatro agentes provisionales dentro del marco de agentes de IA elegido.
- Integre herramientas de scraping de redes sociales: conceda al agente de recuperación de datos acceso al Social Media Scraper de Bright Data o a scrapers de redes sociales específicos.
- Configure las tareas de recuperación de datos: Indique al agente de recuperación de datos que recupere los datos de redes sociales necesarios.
- Analice los datos recopilados: indique al agente de análisis que procese el texto, el sentimiento, las tendencias y las métricas de interacción.
- Genera informes estructurados: Indica al agente de informes que produzca el resultado deseado basándose en los datos analizados.
- Coordina y repite: implementa el agente de coordinación para supervisar los resultados, activar ciclos repetidos, etc.
- Diseña el bucle de agentes: conecta los cuatro agentes (Recuperación de datos → Análisis → Informes → Coordinación).
- Automatizar la programación del flujo de trabajo: configurar ejecuciones periódicas para una escucha social continua.
Ejemplos de flujos de trabajo de escucha social con agentes
Teniendo en cuenta la hoja de ruta de agentes de IA presentada anteriormente, puedes crear varios flujos de trabajo de escucha de redes sociales basados en agentes. ¡Aquí tienes algunos ejemplos!
Monitorización del sentimiento hacia la marca
Los agentes de IA rastrean continuamente las menciones de su marca en las plataformas sociales. Utilizando el Social Media Scraper de Bright Data, los agentes recopilan publicaciones, comentarios y reacciones, y luego analizan el sentimiento, detectan tendencias emergentes y señalan picos negativos, lo que permite una gestión proactiva de la reputación.
Análisis de la competencia
Los agentes de IA monitorizan hashtags, palabras clave y debates en los comentarios de TikTok, X, Reddit y YouTube. A continuación, la IA detecta estrategias de contenido, el rendimiento de las campañas y los patrones de interacción de la audiencia, lo que le ayuda a ajustar su propia estrategia en tiempo real.
Descubrimiento y previsión de tendencias
Los agentes de IA supervisan hashtags, palabras clave y debates en TikTok, X y Reddit. Las API de Scraper de Bright Data proporcionan datos estructurados y preparados para LLM para que los agentes detecten tendencias al alza, pronostiquen la popularidad y orienten las decisiones de marketing o de producto.
Detección y respuesta ante crisis
Los agentes vigilan los repuntes repentinos de sentimiento negativo o las publicaciones virales en múltiples redes. Con el Social Media Scraper de Bright Data, la IA puede alertar a los equipos de inmediato, redactar respuestas adaptadas al contexto o activar flujos de trabajo de escalado automatizados.
Análisis de la retroalimentación de las campañas
Los agentes de IA recopilan reacciones de los usuarios, comentarios y métricas de publicaciones de Facebook, Instagram, YouTube u otras plataformas. Gracias a los Scrapers de Bright Data, los agentes obtienen los datos que necesitan para hacer un seguimiento del éxito de las campañas y optimizar las estrategias de comunicación.
Conclusión
En este artículo, has aprendido qué es la escucha en redes sociales, en qué consiste y por qué los flujos de trabajo automatizados son la mejor forma de implementarla. También has adquirido una comprensión clara de los retos que conlleva y de cómo superarlos utilizando herramientas de scraping de redes sociales preparadas para la IA.
Bright Data facilita la escucha en redes sociales a través de un Scraper de redes sociales específico, de nivel empresarial y fácil de integrar. Esto le permite crear flujos de trabajo basados en agentes escalables para la escucha en redes sociales (y otros casos de uso de marketing en redes sociales) sin perder fiabilidad ni rendimiento.
¡Crea hoy mismo una cuenta gratuita en Bright Data y explora nuestras soluciones de recopilación de datos web preparadas para la IA!
Preguntas frecuentes
¿Cuál es la diferencia entre la escucha social y la monitorización social?
La monitorización de redes sociales rastrea «qué» ha ocurrido mediante la recopilación de notificaciones, «me gusta» y métricas. Por el contrario, la escucha social analiza el «por qué» al examinar el sentimiento y las tendencias que hay detrás de esas conversaciones para orientar la estrategia a largo plazo.
¿Cuál es la diferencia entre el análisis de sentimiento y la escucha social?
El análisis de sentimiento evalúa las emociones u opiniones en el texto, como si son positivas, negativas o neutras. La escucha social es más amplia: supervisa las conversaciones en todas las plataformas para rastrear tendencias, la percepción de la marca y los comentarios de los clientes, a menudo utilizando el análisis de sentimiento como una de sus herramientas.
¿Se puede utilizar un agente de IA para la escucha social?
Sí, los agentes de IA pueden utilizarse para la escucha social. De hecho, son ideales para esta tarea debido a su capacidad para adaptarse a situaciones cambiantes o inesperadas, algo típico del panorama de las redes sociales, en constante evolución.
¿Qué herramientas necesita una IA para acceder a la escucha social?
Los agentes de IA para la escucha social requieren herramientas para recopilar datos de las redes sociales. Al integrarse con Scrapers como el Social Media Scraper de Bright Data, los agentes pueden monitorizar múltiples plataformas a gran escala, proporcionando inteligencia procesable en tiempo real.
¿En qué plataformas de redes sociales tiene sentido aplicar el social listening?
Las plataformas de redes sociales más relevantes para el scraping con fines de escucha social mediante agentes son X, Reddit, Threads, Facebook, Instagram, LinkedIn, TikTok, Quora, Pinterest, YouTube y Vimeo.




